计算机编程代码优劣评价系统的设计与研究
2024-01-12李真成
李真成
(天津交通职业学院, 经济管理学院, 天津 300110)
0 引言
目前,高级语言编程开发平台中,对高级语言进行预编译或者试解析,从而发现其语法错误并给出报错,已经成为平台软件功能开发的必要技术。文献[1]提出的技术仅可保障该平台下开发的高级语言程序段的可用性,对其算法优化过程和持续优化结果并不能提供必要辅助。文献[2]指出,近年来使用第三方插件对程序代码做出基于人工智能的算法优化成果评价,成为编程过程服务软件开发中的重要任务。文献[3]通过计算机编程技术对计算机编程代码进行分析,以实现编程工作环境直接对编程代码质量的深度评价,而非传统模式下仅对编程代码的可编译性进行评价,是当前高级语言计算机辅助编程环境搭建工作的重要技术革新方向[4]。
1 数学算法视角下的计算机编程优化任务分解
以往程序员绩效管理中,其代码质量评价标准为代码可编译,可正常运行,导致大部分程序员的代码质量较差,大部分开发工时用于对代码漏洞的修补工作,使开发成本激增。大部分程序开发工作面临“技术绑架”的管理压力[5]。
传统模式下,计算机编程优化的评价指标,主要包括以下三个方面。
第一,代码本身的优化。IT界将计算机代码本身分为两种[6]:一种只有编程者本人能看懂,如果间隔时间过长,其本人也很难看懂,这种代码效率较低,缩进、注释都较为混乱,但企业无法对该编程者取消合作关系;另一种所有编程者对照技术文档都能看懂,这种代码缩进、注释等都实现了标准化,技术文档较为清晰,但每个编程者均不存在不可替代性。所以,对程序员来说,降低代码优化程度,或者说降低代码质量,可以获得更稳定的工作,延长开发时间,获得更高的个人收益。这一利益趋向与开发公司的利益冲突。
第二,资源调用量的优化。不论是个人电脑还是手机、平板电脑等设备,以及各种嵌入设备和工业设备,其自身具有的计算资源有限,在分布式计算、云计算等软件运行环境下,网络带宽资源、内存总线带宽资源、显示总线带宽资源、其他总线带宽资源等,也被用于资源调用量的考察。经过充分优化的数学算法,可以使用有限的资源调用量实现目标功能。
第三,系统运行效率的优化。高级语言的编程过程基本无须直接操作上述硬件资源,即便在C族语言中有ASM命令可以嵌入宏汇编语句,但大部分高级语言保留字均封装了大量可编译信息。优秀的程序员可以充分利用高级语言的循环结构、分支结构等构件算法,有效压缩程序执行过程的计算次数,使程序完成相同计算任务以及同样计算机硬件资源支持条件的前提下,程序可以在最短时间完成计算[7]。
综上,传统评价模式主要包括表1中的评价指标。
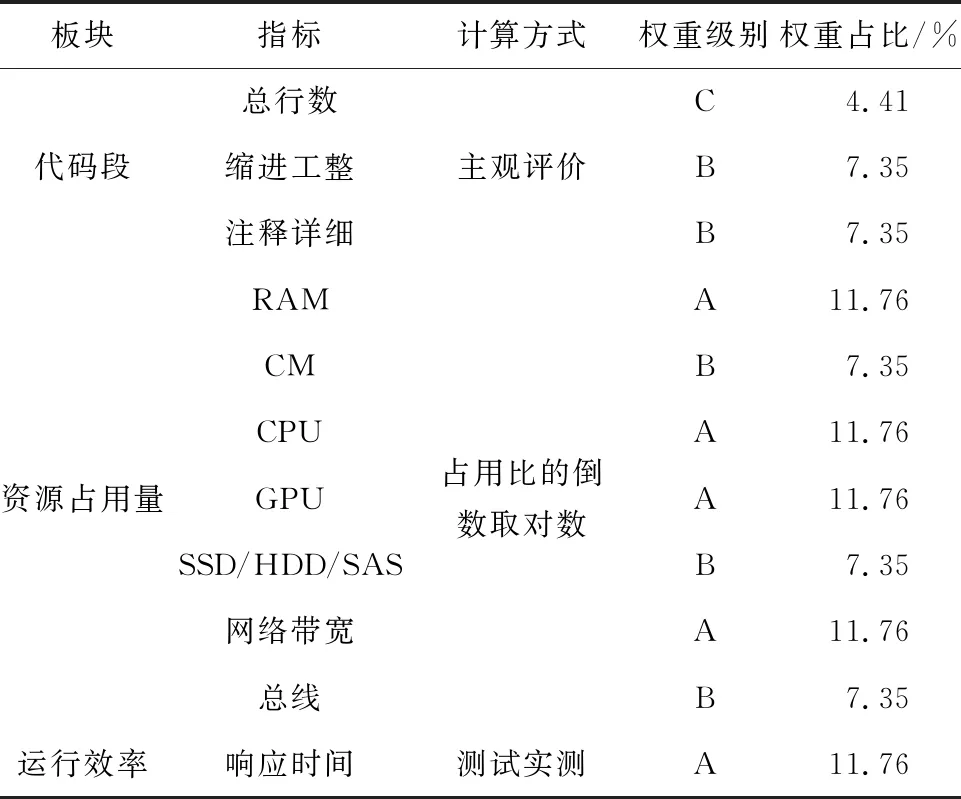
表1 计算机编程优化成果评价因子汇总表
表1中,传统模式下,对代码段本身的优化成果无法客观定义,一般由项目经理、产品经理、测试工程师给出主观评价,进而对各方意见给出加权平均。但因为在程序开发过程中,代码段本身的优化过程属于人事绩效管理中冲突最严重的部分,所以此处需要利用人工智能给出非主观评价结果。
2 用于代码段优化水平整体评价的模糊卷积神经网络设计
该研究的技术路径为使用人工智能系统对代码优劣程度做出包含细节信息的整体评价。其中,人工智能的实现模式为模糊卷积神经网络。因为该研究设计的评价系统需要对大部分开发场景下的编程代码做出评价,所以需要构建计算机编程代码的一般模式并在一般模式下进行数据挖掘分析。
2.1 计算机代码评价标准的一般模式假设
对于软件开发工程来说,计算机编程代码一般分为两个层次。
其一为面向机器编程的宏汇编语言体系(MASM),当前可用的开发平台包括IBM公司推出的ASM开发环境、Borland公司推出的C系列开发环境(TC、C++、VC等)、SUN公司推出的JavaBean开发环境[8]。
其二为面向对象的高级语言编程体系,该编程体系包含了运行在C语言编译架构上的GUI开发体系,解释型代码架构上的伪编译脚本开发体系(B语言架构下的VBS脚本、C语言架构下的C#脚本等),当前开发环境中常用的JSP、PHP脚本代码,部分服务器端开发任务,也采用了这种伪编译解释性代码体系[9]。
2.2 数据模糊化与数据输入
程序代码文本虽然可以结构化为可编译或可解释数字化代码,但其中也包含各种自定义变量名、注释文本等。所以,程序代码文本属于非标准异构数据,应设计数据模糊化算法对代码段进行逐行分析。其分析流程如图1所示。
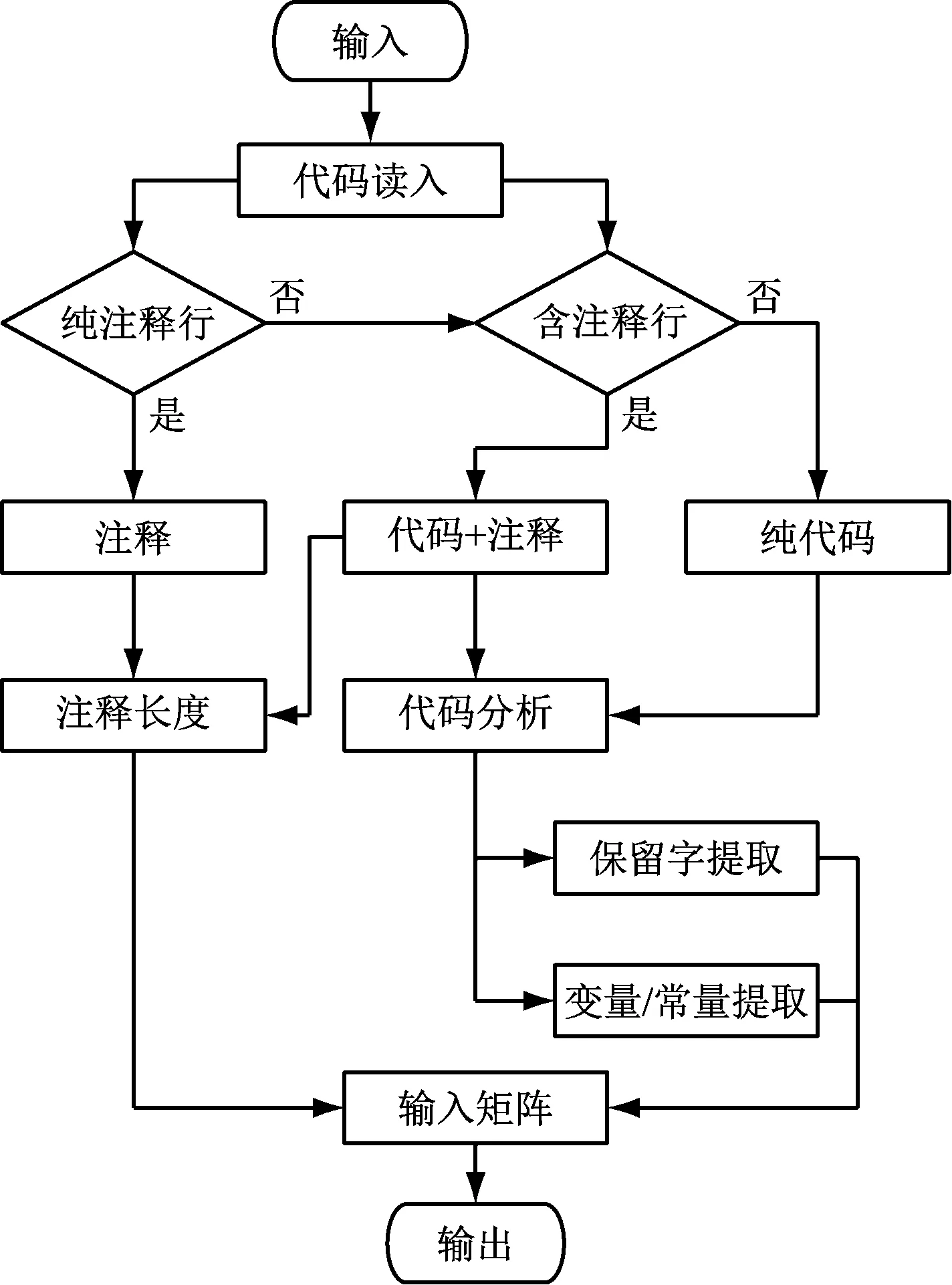
图1 模糊化算法的流程
图1中,逐行读入代码文本,根据代码行的注释标识,分析代码行的分类,统计代码行总字符数和注释字符数,另提取其非注释部分,提取其保留字和变量名,同时分析变量的数据类型。经过该模糊化过程,形成一个二维矩阵,矩阵的第一控制区间(行)为代码段的总行数,对每一行构建一组评价值,作为第二控制区间(列),详见表2。

表2 输入矩阵第二控制区间定义表
表2中,共给出该输入矩阵6列n行,n为代码段的总行数。该输入矩阵的所有元素,均为整型变量(Integer格式)。在输入神经网络时,整型变量将强制转化为双精度浮点型变量(Double格式)进行输入[10]。
2.3 神经网络具体设计
将上述全部数据深度卷积的统一输出结果,与逐行数据之间形成逐行优化结果评价,而为了加强对逐行数据的评价,还需要将被评价行的向前5行和向后5行作为参照行。该神经网络数据流模式详见图2。
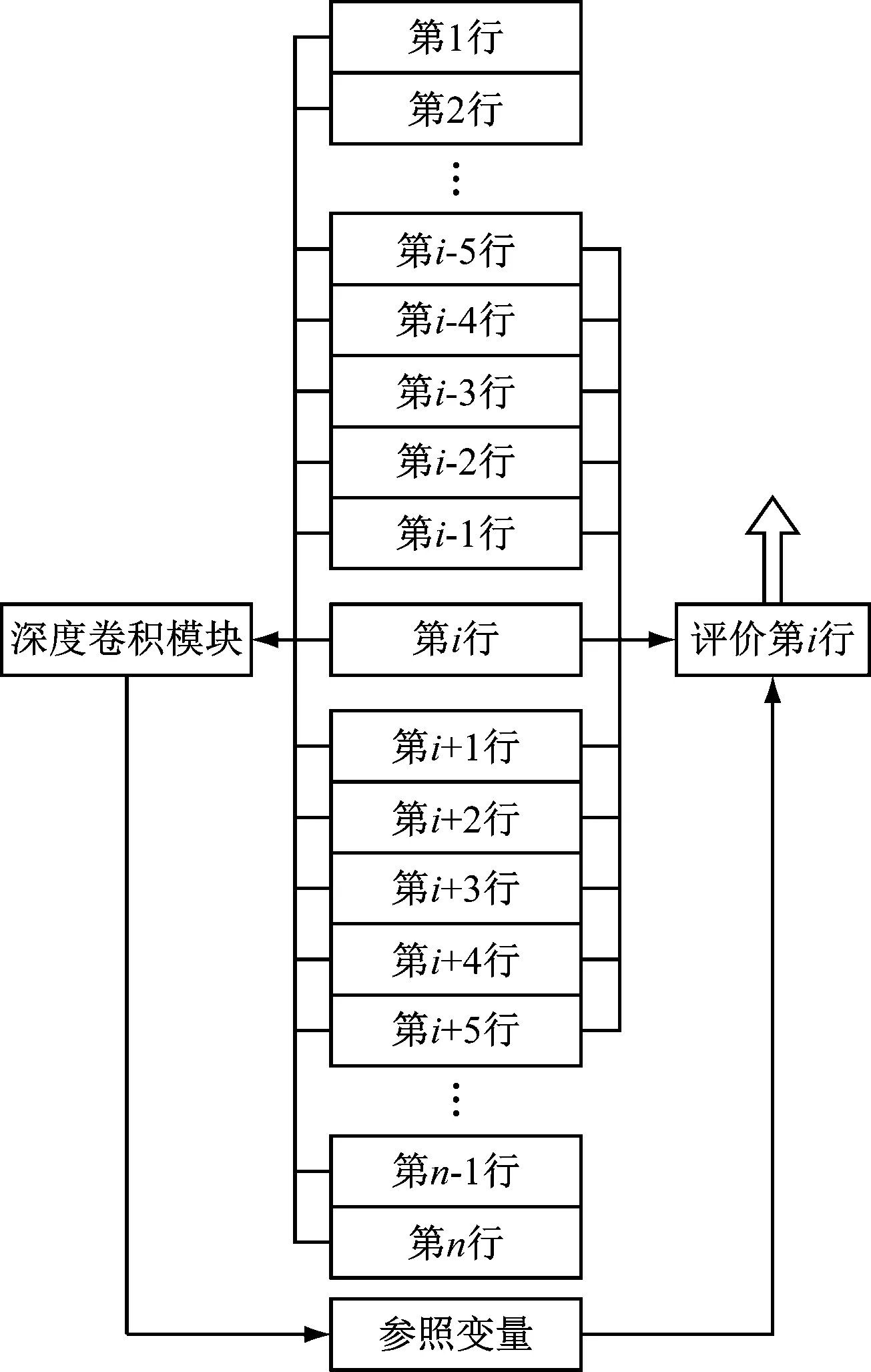
图2 神经网络架构数据流图
图2中,共设计2个神经网络模块。
一个为深度卷积模块,用于对全部模糊化数据进行整体评价,其输入节点量为6×n个。如果程序代码段总行数为3万行,则此处输入数据量为18万个。采用软件自适应法,根据输入数据量构建神经网络的节点量,节点采用六阶多项式回归函数进行节点设计,每层卷积率为35%,卷积至隐藏层末端确保节点数大于5个。
另一个为逐行评价分析模块,其输入节点量包括11×6的矩阵截取段输入,共55个输入项,同时包括上述深度卷积模块输出的参照模块,即逐行评价分析模块共输入56个输入项。该模块分为两段:第一段占用输入层及前3层隐藏层,使用对数回归函数进行节点设计,卷积率为75%;第二段为隐藏层后4层,采用二值化回归函数进行节点设计,卷积率为55%。
神经网络的数据训练中,使所有结果收敛到[0,1]区间内,且评价结果越接近1.000,则认为代码优化程度越高;反之,评价结果越接近0.000,则认为代码优化程度越低。将输出结果构建直方图,直观显示程序员的代码编写水平。
3 计算机编程优化评价分析结果讨论
该算法最终输出1个二值化评价序列,最大为1.000,最小为0.000,且绝大部分数据集中在1.000或0.000附近。该序列每个节点对应代码的每一行,节点数据本身并不能直接反映出代码的优劣,但对整体序列构建直方图后,可以直观观察代码整体的开发质量。
针对前文假设中提出的4个开发目标,该评价结果可以在唯一评价结果中给出统一评价。即该评价结果较高(接近1.000)的评价结果,表示代码综合满足上述4个开发目标;反之,该评价结果较低(接近0.000)的评价结果,表示该代码并不满足上述4个开发目标。某线上购物平台真实开发项目团队30人,其中开发组成员15人,代码规模36万行,分为72个功能文件进行开发,开发模型为螺旋式开发模型。软件试运行期间,使用上述开发团队产出的代码作为原始数据测试该系统执行效果。
3.1 评价结果的特异性表达
使用该算法在Python环境中运行,输入不同程序员的代码成果,对其进行评价,分别对其列出直方图。其中,开发效率较高程序员与开发效率较低程序员的直方图对比结果如图3所示。
图3中,程序员a为在所有程序员中使用深度卷积计算后评价结果最高的人,程序员b是所有程序员中使用深度卷积计算后评价结果最低的人。将开发组成员15人中直接深度卷积结果最低的程序员b(评价结果0.117)与直接深度卷积结果最高的程序员a(评价结果0.935)的直方图结果进行对比,发现程序员a的整段代码中除个别行评价结果小于1.000外,绝大多数行的评价结果均为1.000,反之程序员b的整段代码中除个别评价结果大于0.000外,绝大多数行的评价结果均为0.000。
3.2 非特异性数据的局部特异性表达
为了测试该系统在非特异性程序员的编程代码评价中的表现,在上述165个样本中随机选择2个程序员的评价结果,如图4所示。

图4 非特异性程序员的评价结果对比图
图4中,程序员c和程序员d均为随机选取的在所有程序员中评价结果中等的人。其中,程序员c的综合评价结果为0.496,程序员d的综合评价结果为0.358,系统均给出了较为折中的评价成绩。但是,因为该算法使用了将数据落点推向[0,1]区间两侧的二值化模块,其评价结果相对极端。
在上述2个程序员的评价结果中,部分代码段给出了接近1.000的评价,部分代码给出了接近0.000的评价。该结果难以对代码段做出折中评价,但其优势是可以在直方图中显著表达程序代码的主观质量。
3.3 评价结果的整体表达
综合考察该软件对开发组成员15人的评价结果与开发方技术人员对其代码的人工审核结果。人工审核组包括甲方工程师、项目经理、开发经理、产品经理等。人工审核组共12人,其中软件工程师10人,行政管理人员2人,行政管理人员均有10年以上软件开发工作经验。其审核方式为人工对其代码进行打分,满分10分,最低0分,对比15人的机器评价得分与人工评价得分的统计学关系,得到图5。
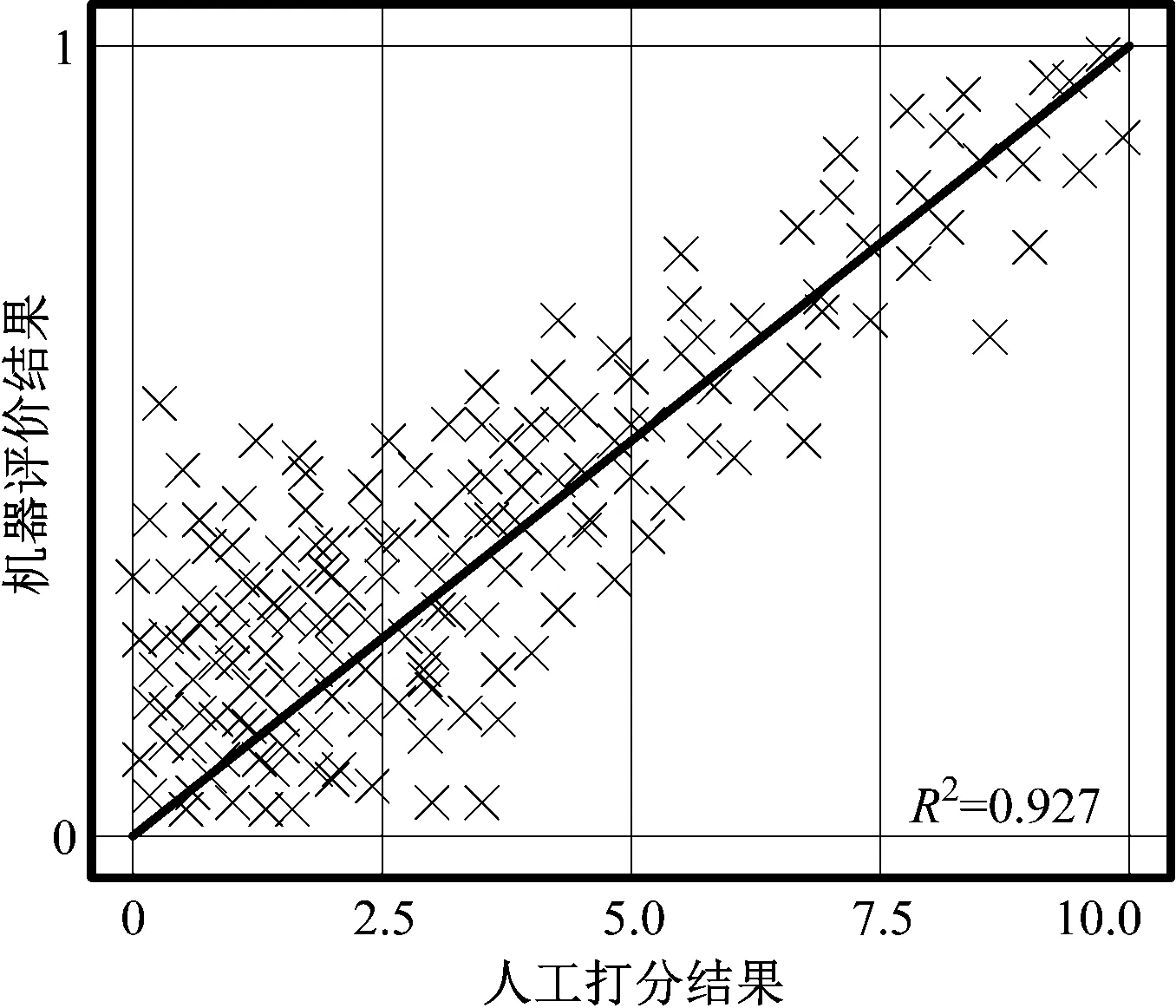
图5 人工打分与机器评价结果的关联关系图
图5中,人工打分结果与机器评价结果的线性相关关联度,以R2值评价,达到0.927,而当R2值达到0.800以上时则认为其存在线性相关关系。其中,R2值的统计学意义是决定系数(coefficient of determination),代表回归平方和与残差平方和的比值。在此评价结果中,发现评价得分较低的程序代码,其人工打分与机器打分的离散度更高,即对质量较差的程序代码,机器打分虽然与人工打分均给出了较低的打分,但二者的差异性较大。考虑到神经网络算法的基本原理,出现这一问题的主要原因为机器打分可以考虑到的质量较差代码的主观因素较少。
4 总结
本研究的评价系统是基于深度卷积模糊神经网络的编程算法优劣的评价结果,与人工打分结果基本一致,且更具有客观性。这一技术对程序开发项目管理的客观绩效模式搭建工作有积极意义。同时,针对编程代码质量进行人工打分过程可能带入评价者的主观因素,可能对质量较低代码给出比机器打分更低的分数。采用机器打分可以给编程能力稍差的编程工作人员更为客观的评价,这也体现出纯客观评价对基层工作人员的基本尊重。后续研究中,通过增加神经网络复杂度提升评价精度,从而帮助程序员实现更高质量的计算机编程代码。
