基于高光谱成像和外观特征的祁门工夫红茶质量数字化评判
2024-01-12尹玲玲吴瑞高钰敏卜宜彬李劲丁小莉卫志辰张雨茹任广鑫
尹玲玲,吴瑞,高钰敏,卜宜彬,李劲,丁小莉,卫志辰,张雨茹,任广鑫
(淮南师范学院生物工程学院,安徽淮南 232038)
红茶是世界上最受欢迎的无酒精饮料之一,由茶树的幼嫩枝叶加工而成[1]。 近年来,随着红茶的药用价值和保健作用得到实验的进一步证实,全球红茶消费量持续增长[2]。工夫红茶作为红茶的主要品类之一,是中国特有的一种茶品。其紧细的外形和醇厚的口感深受消费者的喜爱[3]。 一般来说,茶叶的品质与特定的感官特征如颜色、香气、滋味、纹理和形态特征高度相关。茶叶按品质的差异可以划分为不同等级,这取决于其生长条件、收获季节和加工工艺[4]。 在茶产品的实际流通销售中, 大多数消费者无法准确的评估茶叶的质量[5],这为不法商家提供了销售假货或以次充好的可能,给消费者带来了经济损失,也造成了消费者与商家之间的不信任。因此,茶叶质量的稳定性和规范化一直受到消费者的关注。
几十年来, 茶叶质量评价主要采用两种传统方法,即感官品质分析法和湿化学法。感官质量分析是依靠训练有素的评茶员的经验来实现的,缺乏客观的量化[6]。 湿化学分析通过使用精密的仪器,准确测定茶叶中各种化学成分的含量[7]。然而,化学分析具有设备昂贵、样品制备复杂、使用大量化学试剂、成本较高、耗时较长的局限性[8],开发快速、稳定、准确的茶叶品质评价技术势在必行。
目前,基于单一外形色泽、纹理等特征无创判别茶叶质量的评价方法被大量报道[9-12]。 将茶叶色泽和纹理特征进行特征数据融合, 全面衡量祁门工夫红茶品质的方法至今少有文献报道。因此,有必要建立一套基于纹理和色泽等融合特征的茶叶品质快速评价体系与智能感知的新方法。
综上, 探索一种流通过程中工夫红茶外观品质的快速判别方法, 对实现品质等级与外观质量的实时控制至关重要。 祁门红茶的纹理与色泽特征是形成其外在品质的主要指标, 也是重要的感官品质描述语,直接影响其在贸易中的销售价值。而高光谱成像(Hyperspectral imaging, HSI)技术正适用于不同等级祁门工夫红茶外观品质指标与融合数据特征的快速无创检测。
1 材料与方法
1.1 实验材料
研究以祥源茶业股份有限公司提供的祁门槠叶种祁门工夫红茶的七个等级茶产品标准样(特级、一级、二级、三级、四级、五级和六级)为研究对象, 七个等级工夫型红茶样品的主要品质成分含量和感官审评结果分别通过标准方法化验和专业评茶员把关。红茶样品数共计700 份,每个等级茶样数分别为100 份。 样品的七个不同等级(特级、一级、二级、三级、四级、五级和六级)分别以T、C1、C2、C3、C4、C5 和C6 表示。样品的水分含量控制在7%左右。 分析前,将样品存放在真空压缩的铝箔袋中,并在恒温干燥器中保存待用。
1.2 高光谱成像信息采集与处理
采集HSI 数据时, 每个样品称取15±0.5 g 均匀铺于培养皿(φ×h: 9 cm×1 cm)中。 为了获得清晰的图像,分别设置输送带速度、CCD 相机曝光时间和镜头与样品垂直距离三个调试参数为0.98 mm/s、30.01 ms 和23.5 cm。 将茶叶样品放置在移动平台上,通过行扫描的方式进行图像采集。为了去除相机内的噪声和暗电流等因素的干扰, 在进行HSI 数据分析前,需对原始图像进行黑白校正,校正公式如下:
其中Ic是校正后的图像,Iraw是原始图像,Idark是通过完全覆盖摄像头镜头获得的暗参考图像(几乎为0%的反射率),Iwhite是通过反射一个标准的特氟龙白瓷砖获得的白色参考图像(>99.9%的反射率)[13]。
为降低HSI 数据的空间维度, 优化茶样原始图像, 实现冗余数据的消除和数据运行速度的提升, 主成分分析 (Principal component analysis,PCA)被引入,用于数据降维和特征信息提取。 该法将数据以线性变化的方式通过求解最大协方差,由高维度向低维度投影,获得与原始变量线性组合的新变量。由于新变量间相互独立,可消除相邻波长间存在的数据冗余[14]。 高光谱特征波长图像的确定是由前二至三个主成分(Principal component, PC)图像的方差贡献率决定,通过选取PCA 变量线性组合的最大权重系数, 进而在PC 图像中优选出相应波长对应的图像。 HSI 数据的校正和PCA 均由ENVI 4.7 软件实现。
1.3 纹理和色泽特征提取
茶叶的纹理特征和色泽特征能够直接反映其外观品质。 研究采用ENVI 4.7 软件的PCA 模块提取图像纹理信息。 总的来说,PCA 的前几个PCs对图像总体信息做出了主要贡献。首先,计算出前两、三个PC 的累积方差贡献率,得到总变量贡献率大于95%的PC 对应的载荷曲线。 然后,将相应PC 载荷曲线的拐点(即波峰和波谷)作为特征波长,保存特征波长处的灰度图像。 最后,采用灰度统计矩阵 (Grey-level gradient co-occurrence matrix, GLGCM)和灰度共生矩阵(Gray-level cooccurrence matrix, GLCM)两种矩阵统计方法对茶叶图像的纹理特征进行提取和计算[13,15]。GLCM 法提取了指定图像在特征波长下的六个不同的统计参数(即平均值、标准差、相关性、对比度、同质性和能量)。GLGCM 法基于灰度梯度的二阶统计量,计算得到图像的四个纹理统计值(熵、三阶矩、一致性和平滑度)。将获得的上述八个纹理参数和两个统计参数(平均值和标准差)作为茶叶纹理特征变量,用于建立后续的纹理数据鉴别模型。上述纹理参数提取均通过MATLAB R2019b 软件实现。
采用MATLAB R2019b 软件选取样品高光谱RGB 图像中200×200 的像素区间为该图像的感兴趣区域 (Region of interest, ROI), 通过RGB、CIE Lab 和HSV 间的颜色模型变换[10,16],分别提取该区域内的红色(R)、绿色(G)和蓝色(B)通道均值,明度(L*)、红绿度(a*)和黄蓝度(b*)分量均值以及色调(H)、饱和度(S)和亮度(V)均值九个色泽评价参数作为样品的外观颜色特征值, 用于后续的样品质量评价模型的构建。 利用HSI 系统提取色泽特征示意图如图1 所示。
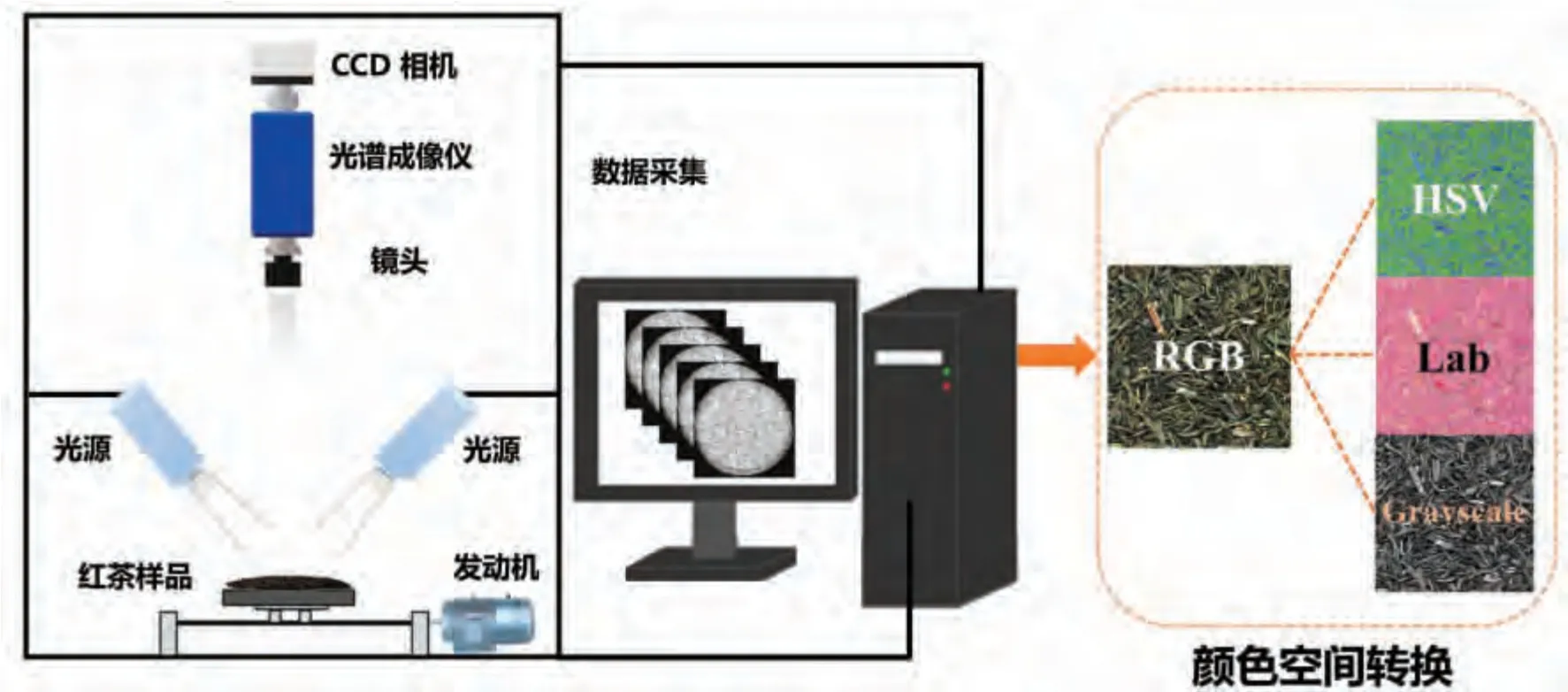
图1 利用HSI 系统提取色泽特征示意图Fig.1 Schematic diagram of color features extraction using HSI system
1.4 多元分析方法
为使模型具备良好的泛化性能, 采用Kennard-Stone (K-S) 方法对样本集特征进行划分。该算法将所有的样本作为校正集的候选样本,计算所有样本的欧氏距离, 选取距离最近和最远的两个样本划入校正集。重复上述步骤,直到获得满足要求的样品数量[17-18]。利用该法可优选出具有代表性的样本划入校正集, 余下的样品划入预测集。
在模型构建中, 研究选用非线性的支持向量机(Support vector machine, SVM)、兼具线性功能的最小二乘支持向量机 (Least squares support vector machine, LSSVM) 和随机森林(Random forest, RF)算法进行建模,并对判别模型效果进行比较,探索出评价茶叶品质的最优模型。
SVM 法是数据分析中常用的多分类器。 该算法基于结构风险最小化原则,试图提高泛化能力,降低预期风险[8]。 SVM 鉴别器以径向基函数(Radial basis function, RBF)为核函数,通过优化两个参数(即惩罚参数c和核参数g)获得良好的预测。参数c用于获得最小训练误差和简化模型;核函数g描述了输入空间到随机高维特征空间的非线性映射[19]。 该方法的具体步骤概述如下:(1)采用留一法交叉验证来优化核心参数 (c和g);(2)采用网格搜索法确定最佳参数对(c和g);(3)根据预测集中正确判别率 (Correct discriminant rate, CDR)的最高输出,建立最佳的SVM 分类模型。
LSSVM 是一种有效的非线性智能学习算法,能够快速解决线性和非线性模式识别问题[7]。该法重点研究了机器学习损失函数, 并将第二范数应用于目标函数的优化问题。 算法使用等式约束代替不等式约束, 将优化问题转化为对一组线性方程组的求解[20-21]。对于任意已知输入输出的非线性样本集, 可以通过探索合适的非线性变换来建立LSSVM 模型,其表达式如下:
在LSSVM 模型中,核函数的选择起着重要的作用。 其核心思想是利用核函数将线性不可分的样本映射到高维空间,解决维数的困扰。考虑特征空间的结构完全由核函数决定, 核函数选择对分类器的开发具有重要意义。在本研究中,RBF 是由专家根据最小误差和先验知识来选择的。 内核函数的描述公式如下:
其中x为m维输入向量,xi为第i个径向基函数的中心,与x具有相同的维数。 γ 为径向基函数核函数的参数。 利用网格搜索法优化了RBF 的正则化参数gam(γ)和sig2(σ2)[4]。 该方法简化了SVM 优化问题的求解,提高了计算效率,促进了SVM 的应用和发展。
RF 算法是基于回归树和分类树的多个决策组合而构建的模型集成方法[22]。 当算法的运行,每棵决策树均进行分类。 以所有决策树中分类结果最多的类别作为最终结果[23]。 算法提出了两个关键参数: 一是决策树的数量 (Number of decision trees, nDT); 二是用于构建决策树的采样特征的数量。 RF 具有不要求变量服从特定统计分布、训练样本少、对过拟合灵敏度低、能够对特征的重要性进行排序等优点[24]。 该方法可以简单概括为如下三个步骤:(1)使用Bagging 方法随机生成T个训练数据子集;(2)每个训练样本被用来生成相应的决策树。 在每个子节点选择属性之前,从M个属性中随机选择m 个属性作为当前节点的拆分属性集, 在M个属性中以最佳拆分方式拆分节点;(3) 每一棵树在不修剪的情况下充分生长,用来测试预测集X中的相应类别,利用T决策树的多数票,对X进行集合分类决策。
为评价判别模型的性能, 用校正集和预测集的CDR 来评估模型的预测能力。 一般来说,一个优秀的判别模型应有较高的CDR 值,其计算方法如下:
其中,NCDR为校正/预测样本的正确估计数,Nt为校正/预测样本的总数。 上述建模算法均由MATLAB 2019b 软件在Windows 8 平台下自主开发。
2 结果与分析
2.1 样品外观品质特征
七个不同等级 (即T、C1、C2、C3、C4、C5 和C6) 的700 份祁门工夫红茶的九个颜色参数(R、G、B、L*、a*、b*、H、S 和V) 的变化情况如图2 所示。 结果显示,随着样本等级的降低,其外观色调(H)和饱和度(S)值降低,其它七个指标值则呈增长的趋势。 结果表明,茶样的等级品质越低,其色泽越暗,纯度越低。祁门红茶样本的纹理特征值的提取过程是利用ENVI 软件中PCA 方法提取前两个PC 图像的累计方差贡献率达95.85%(PC1=92.19%,PC2=3.66%)(见图3), 前两个PCA 载荷曲线的波峰与波谷处的波段被筛选为图像特征波长。 从PC1 和PC2 中获得了三个最佳波长(696.74 nm、752.86 nm 和975.91 nm)。 因此,基于GLCM 和GLGCM 法从上述三个最佳波长的图像ROI 中提取图像纹理特征。 GLCM 法获得的纹理参数包括两个统计值(均值和标准差)×三个波段+四个纹理指标×三个波段×四个方向 (0°、45°、90°和135°),即54 个纹理特征。 GLGCM 方法可得到12 个纹理数据(四个纹理特征×三个波段),总计66 个纹理值,用于后续模型构建。

图2 不同等级祁红样品的色泽特征的分布情况Fig.2 Distribution of the color characteristics of different grades of black tea samples
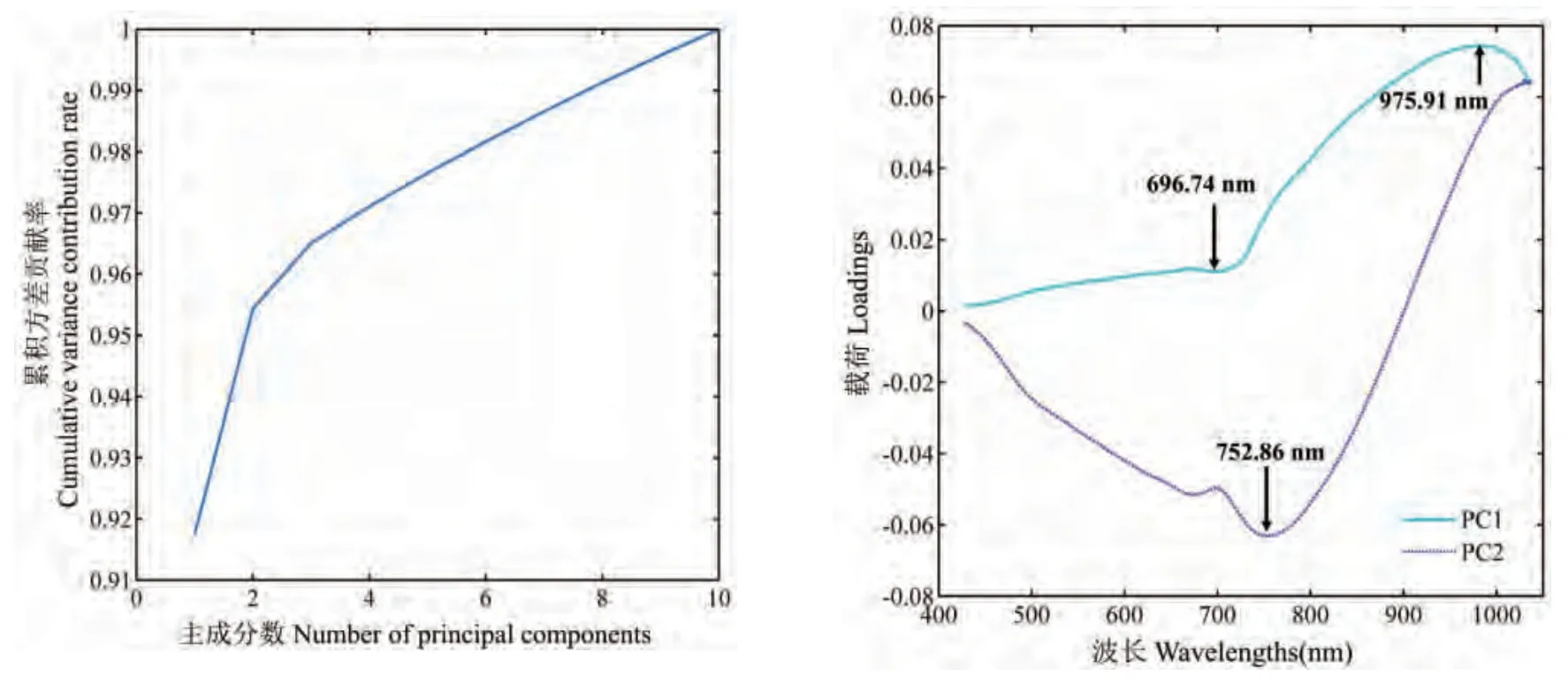
图3 主成分分析的权重系数、载荷和样品的最佳波长的选择Fig.3 PCA weight coefficient, loadings and the selected optimal wavelengths of the samples
2.2 样品集划分与主成分分析
利用K-S 方法将校正集和预测集样本以2∶1的比例进行划分,得到校正集样品数为467,预测集样品数为233。样品集的二维PC 空间分布情况见图4。 图4 结果显示,祁红样品的单一特征(色泽或纹理) 与融合特征的校正集和预测集样品的空间分布相对分散, 且校正集样品分布包含了预测集样品的分布范围。 表明样品集的划分是合理的。

图4 校正集和预测集样本在二维主成分空间中的分布Fig.4 Distributions of the samples from the calibration set and the prediction set in the two-dimensional principal components space
不同等级祁红样品的二维PC 空间分布情况如图5 所示。不同等级样本的单一特征(色泽或纹理)与融合特征PC 得分分布显示,不同等级的样本间重叠性较强, 无论是单一特征还是融合特征均无法将不同等级的样本区分开, 有必要引入线性或非线性的分类算法, 以实现对样本品质等级的准确判别。
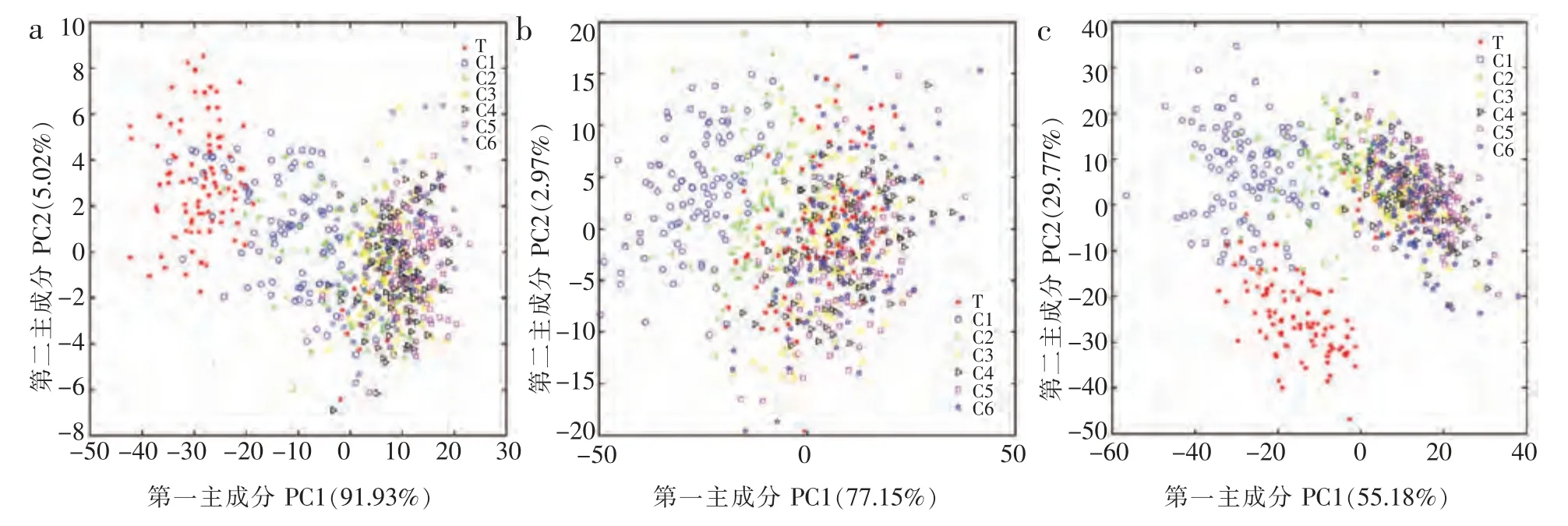
图5 七个等级的样本二维主成分分布图Fig.5 Two-dimensional PC distribution of seven grades of the samples
2.3 外观品质评价模型建立
基于SVM、LSSVM 和RF 智能算法的祁门红茶外观色泽、 纹理及特征融合数据的等级评判模型结果见表1。 模型结果显示,基于色泽、纹理与特征数据融合的祁门红茶等级最优LSSVM 分类模型在校正集和预测集中的CDR 分别为70.88% 、72.96% 、83.51% 、86.27% 和 93.15% 、94.85%。 使用融合特征建立的最佳判别模型性能优于单一纹理与色泽特征所建的模型,且纹理数据的建模效果高于色泽数据构建的模型识别精度。此外,融合数据建立的所有模型的CDR 均高于使用相同分类算法的纹理或色泽模型。实验结果表明,特征融合能够更为有效地反映祁红样本的外观品质属性, 建模精度较基于单一特征(纹理或色泽)的模型更高,对样本的解析更加有优势。
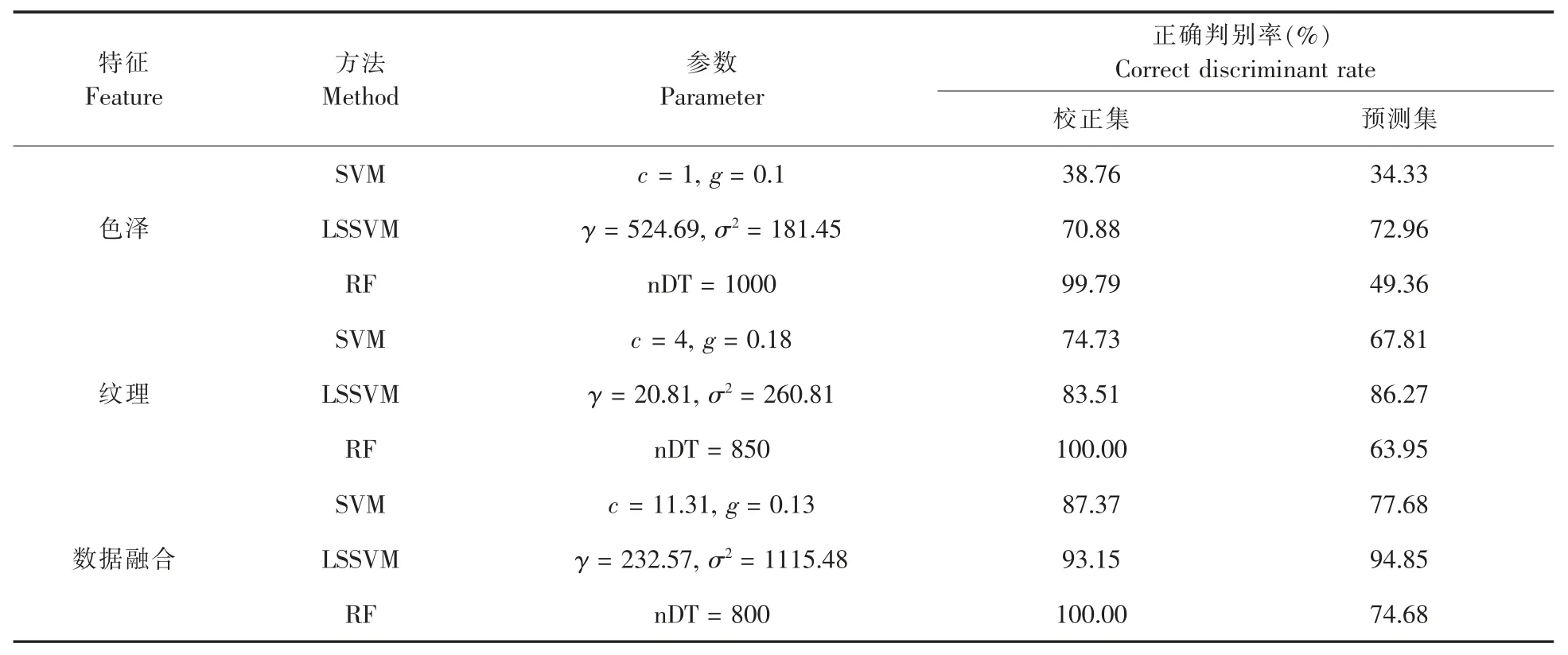
表1 基于色泽、纹理与数据融合特征的祁门工夫红茶等级最佳判别模型结果Table 1 Results of the optimal models of Keemun Congou black tea samples based on color,texture,and data fusion features
3 总结与讨论
研究基于HSI 技术和化学计量学算法, 开发出一套快速、无损的工夫红茶外观品质(色泽、纹理和融合数据)的评判方法。探讨了不同机器学习算法对七个等级的祁门工夫红茶标准样单一外观特征和多信息特征融合的预测能力, 以探求评价模型的最优化。
利用HSI 技术获得祁门红茶样品的色泽和纹理特征数据,比较了基于SVM、RF 和LSSVM 算法对上述茶产品标准样的单一外观特征和融合特征的等级判别模型性能。结果表明,基于融合数据的建模性能优于基于单一特征属性(色泽或纹理)的模型。由单一外观特征的模型性能可知,纹理特征模型精度最高,色泽特征数据的建模效果最差。利用LSSVM 算法构建的特征融合评价模型对祁红样品的预测准确度最高, 预测集判别率达到94.85%。 利用特征融合数据所建模型具有更优的预测能力, 为工夫红茶产品外观品质的快速评判提供了一种行之有效的方法。
在所有分类模型中, 色泽数据模型的预测性能较差。 有可能是对祁门红茶样本外观的等级划分标准更加侧重于对茶叶嫩度高低的审定。 红茶样品的持嫩度不同,其纹理差异较大。色泽特征主要与红茶发酵程度关系紧密。 在标准化的红茶加工工艺模式下,发酵工序具有严格的参数控制,其品质具有较强一致性。因此,不同等级的红茶产品的色泽变化程度没有纹理特征的差异性大, 进而导致色泽数据模型的性能较纹理特征差。
从分类算法的角度看,LSSVM 模型的预测效果优于SVM 模型和RF 模型。LSSVM 模型的优化可以理解为等式约束, 解决了基于训练误差平方的线性方程问题[7]。 在SVM 算法的基础上建立和开发的LSSVM 方法, 能够得到一个更为简单、有效、稳健的模型。 根据相关文献[20],LSSVM 分类器能够有效提高茶叶品质评价模型的计算速度和分类精度。 此外,RF 算法对于输出数值较多的属性可能会产生误差。 综上,LSSVM 分类工具能够提供更好的解决线性和非线性问题的方案, 更加有效地简化问题的复杂性,增强模型性能。
