症状同期网络的分析方法介绍及R软件实现
2024-01-12朱政余骏雯杨中方胡天天金依霖何加敏
朱政 余骏雯 杨中方 胡天天 金依霖 何加敏
(1.复旦大学护理学院,上海 200032;2.上海市循证护理中心,上海 200032;3.纽约大学护理学院,纽约 10010)
随着信息技术和大数据分析技术的不断发展,以及真实世界复杂科学研究理念的变革,症状网络的概念逐渐突破了以往的研究范式,即聚焦于单个症状并必须控制其他变量。自从2015年Fried等[1]学者在1篇评论文章中首次提出“症状网络”的概念以来,该方法已经在精神病理学、慢性病症状管理、肿瘤长期随访和患者自我管理中得到应用[2-4]。症状网络不仅提供了症状的发生率和严重程度指标,还能通过节点指标和网络指标来反映症状在网络中的关键作用。这种方法在某种意义上拓宽了临床医务人员对症状测量维度的认知,从表观机制层面分析症状共生问题。自从2021年复旦大学团队在中文护理期刊发表了第一篇关于症状网络的研究[5]以来,该方法已成为护理领域研究复杂问题的一种必要分析技术。根据症状数据的类型,症状网络可以分为3类:同期网络,基于横断面症状数据;时态/个体化网络,基于单个个体症状数据;动态网络(dynamic network),基于重复测量的群体面板症状数据。其中,同期网络是最常见的类型。本文将从症状同期网络的定义、常用网络特异性指标以及R软件的实现等方面进行介绍,旨在为推广和规范症状组学领域的研究提供借鉴和参考。
1 症状同期网络的定义和常用网络特异性指标
1.1同期网络的定义 同期网络是指在同一测量时间点上,同一患者群体所表现出的症状所构成的网络。同期网络是基于横断面数据构建的。该网络的构建可以为研究者提供无法解释的症状发生率和严重程度等信息,有助于临床实践者更好地识别某一疾病人群中症状发生的机制和精准干预的靶点。同期网络可以帮助研究者理清复杂情境下的共病和多因多果的症状问题,并对挖掘疾病的特异性靶点起到良好的作用。例如有学者[3]使用来自SCANS数据库的1 065例癌症生存者的横断面数据,对与癌症长期生存有关的13个症状进行了分析,结果发现尽管“疲乏”的发生率和严重程度较高,但它并不是在长期生存中具有核心作用的症状。然而,同期网络仅基于横断面数据,无法建立真正的因果关系。在进行症状的因果推断时,需要结合相应的理论加以解释。
1.2同期网络中常用的网络特异性指标 同期网络的特异性指标可以分为节点指标、网络指标、网络拟合指标和差异性检验指标4类。在本期专刊中的“症状网络的特异性指标”一文中已经详细介绍了各类网络特异性指标的定义和临床意义,在本文中,仅总结了同期网络中常用特异性指标的类型和种类,见表1。

表1 同期网络中常用的网络特异性指标一览
2 症状网络分析内容和R软件的实现
不同网络类型需要采用不同的分析方法。如动态网络可以采用交叉滞后面板网络模型或时变向量自回归模型进行分析。本文将重点介绍同期网络的基础分析内容,并介绍如何使用R软件进行实现。常用症状网络分析方法,见表2。

表2 常用症状网络分析方法一览
2.1数据准备和清理 症状网络分析的数据准备和清理需要注意以下几点问题。(1)症状数据收集:收集患者自我报告或专业人员记录的症状信息。数据收集方式可以包括面对面访谈、问卷调查、电子医疗记录或移动应用等多种形式。(2)症状数据编码:对症状信息进行编码,将其转化为数值型数据,以便进行网络分析。(3)症状数据转化:将症状数据转化为构建症状网络所需的形式,可以提取需要的变量并保存为CSV格式。(4)症状数据整理:由于网络分析不允许存在缺失值,因此需要对收集到的症状数据进行整理,包括去除无效数据或处理缺失数据等操作。(5)设置症状发生率阈值:有些症状的发生率较低,在总样本中只出现1~5次,这可能导致网络分析时出现错误。建议剔除此类症状。

完成数据整理后,需要进行以下步骤:设置工作目录、读取数据,并导入qgraph命令包。qgraph是一个R语言的命令包,主要用于构建同期症状网络图模型。该包的主要功能是利用图形和统计方法来可视化网络数据,以帮助研究者更好地理解网络结构和关系。读取方式,见框1,扫二维码获取框1。
2.2命名和定义群组 如果需要研究多个症状群之间的关系,并且涉及到多个症状,就需要对这些症状进行命名和分类。如果使用了标准化量表,可以根据原量表的维度直接进行分类。但如果原量表没有明确的维度区分,建议先进行因子分析或主成分分析来探索症状群。
2.3可视化 使用qgraph命令包可以将症状网络进行可视化。在示例代码(框1)中,cor(myData)表示症状网络的数据来源,需要使用cor命令来构建相关系数矩阵。layout参数用于指定网络的布局方式,可以选择spring(弹簧布局)或circle(圆形布局)。labels参数用于指定节点的标签,groups参数用于表示节点的分组信息。label.scale参数控制节点标签的大小是否随节点大小的变化而变化,label.cex参数表示标签的大小尺寸,node.width参数表示节点的大小,color参数表示不同群组的颜色。qgraph包含许多其他参数和选项,可参考qgraph命令包的说明文档[8]。症状网络分析可视化结果示例,见图1。
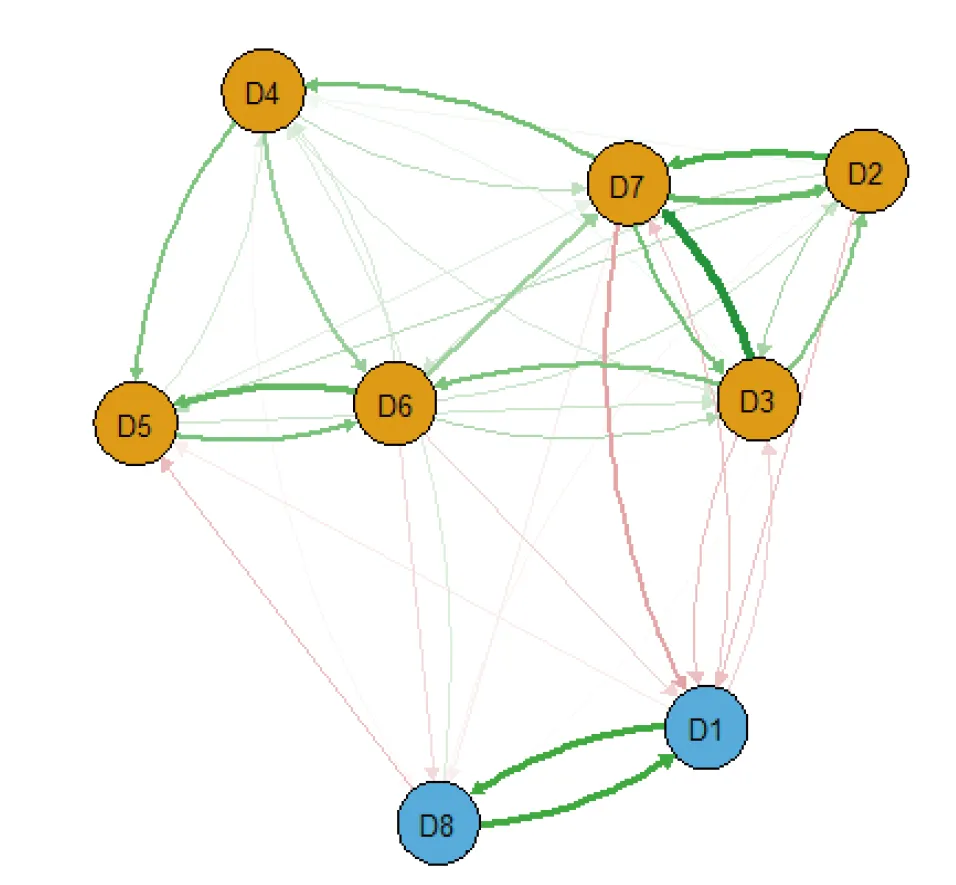
图1 症状网络分析可视化结果示例
2.4中心化指标分析 在症状网络中,中心性指标是用来描述节点在网络中核心地位的重要指标,主要包括强度中心性、紧密中心性和中介中心性。这些指标可以用来确定核心症状(节点),成为临床症状管理和干预的重点。通过针对核心症状进行干预,可以使原本与该节点有关联的其他节点失去“靶点”的效果,并将干预作用传播到核心症状周围的节点,从而最终导致其他症状的缓解或消失。使用Centrality命令可以获取网络中心性指标的数值。其中,强度中心性(Strength)是最具有说服力的指标,数值越大表示该症状在机制上是最核心的症状。在症状网络中,采用spring布局时,核心症状通常位于图形的中央位置。中心化指标分析结果示例,见图2。
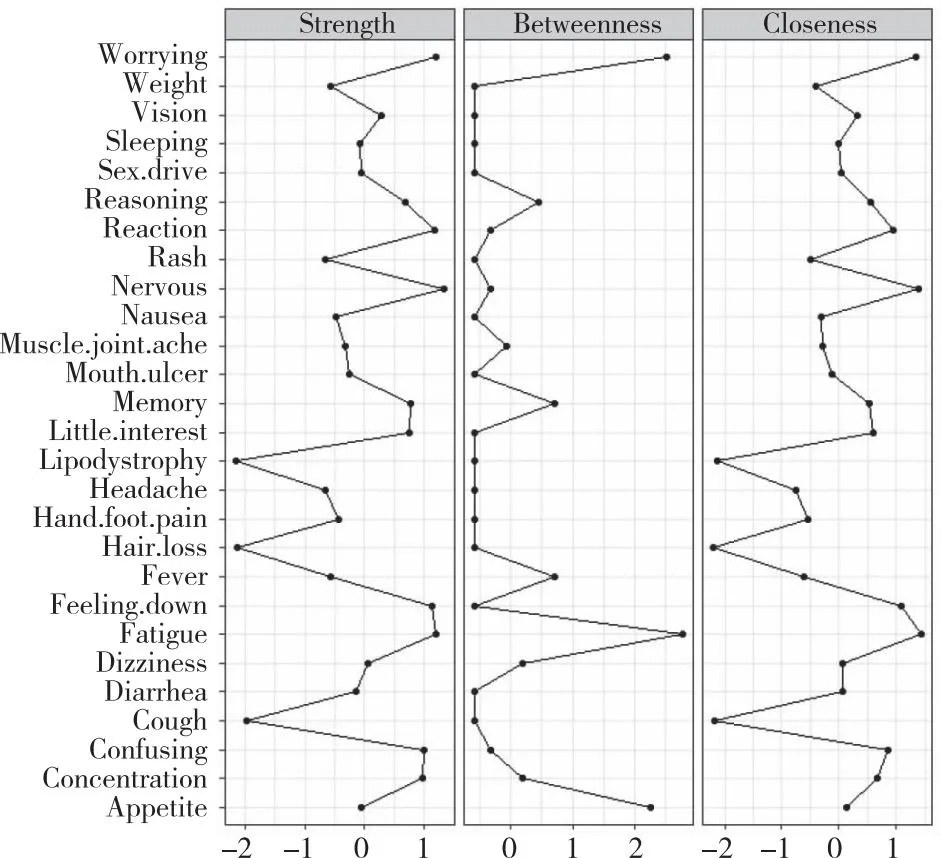
图2 中心化指标分析结果示例
2.5桥梁分析 如果症状在多个症状群之间起到桥梁的作用,可以探索桥梁症状。使用Bridge命令可以获取症状的桥梁中心性指标,其中桥梁强度中心性是最具有说服力的指标。该指标的数值越大,代表该症状在机制层面上可能是连接2个症状群的关键症状。桥梁中心性指标需要结合症状网络进行解释,以明确具体连接哪2个症状群之间的桥梁。
2.6边缘精确性和节点稳定性分析 网络分析的边缘精确性和节点稳定性分析是通过对原始数据进行重复抽样来评估网络结果的可信程度的一种方法。这种方法可以在不同的数据集上评估网络结果的一致性,并确定结果的稳健性和可靠性。常用的分析方法之一是基于自助重采样(bootstrapping)技术,它通过多次随机抽样生成多个数据集,并在每个数据集上重新计算网络指标。然后,通过计算这些指标的平均值、标准误差、置信区间等统计指标来评估网络指标的精确性和稳定性。具体的分析代码可以参考框1中的示例。
在解读边缘精确性分析结果时,常需要考虑2个方面。(1)关注网络指标的平均值和标准误差。网络指标的平均值可以反映网络的整体水平,而标准误差则反映了指标估计的精度。(2)要考虑网络指标的置信区间,即指标值的95%置信区间(CIs)。置信区间可以反映指标的精确性。如果多次抽样得到的网络指标在不同数据集上变化较小,那么置信区间将较窄;反之,如果变化较大,则置信区间较宽。精确性检验结果示例,见图3。
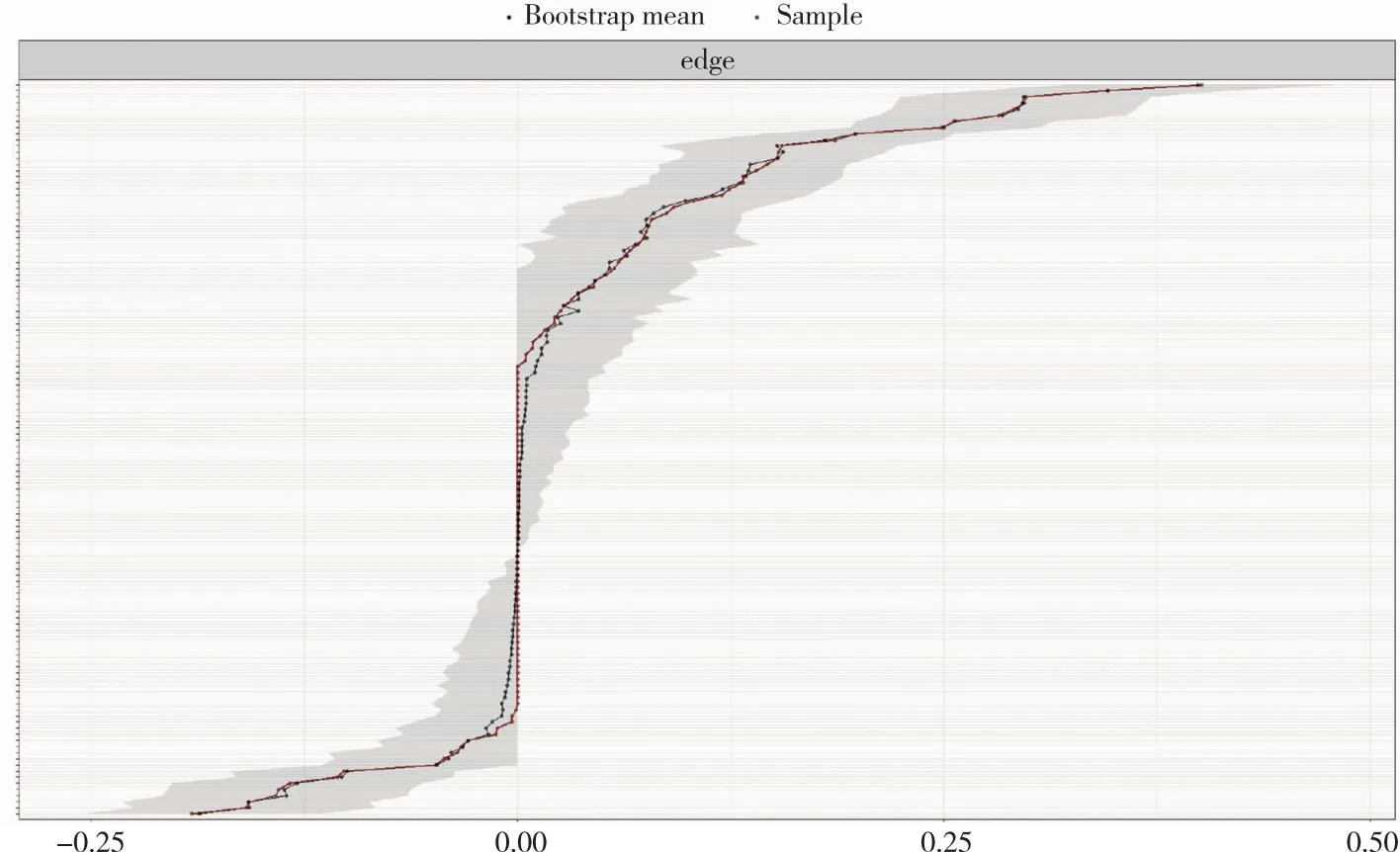
图3 精确性检验结果示例
节点稳定性分析是评估网络中测量结果(例如中心性指标)可靠性和准确性的过程。常用的节点稳定性分析方法包括重复计算和重复抽样。重复计算是指在相同的网络结构和节点属性条件下,多次计算网络指标以评估其稳定性和一致性。如可以使用不同的随机数种子生成多个相同的网络,并计算中心性指标,然后对结果进行比较。如果结果一致,说明该指标的计算较为稳定和可靠。具体的稳定性分析代码可参考框1。对于节点稳定性分析的结果解读,通常需要计算统计指标(如标准误、置信区间和偏差)并绘制直方图和箱线图。标准误越小、置信区间越窄,表示网络指标的计算越稳定。直方图和箱线图可展示网络指标的分布情况,有助于确定异常值和数据的偏斜程度。通常情况下,指标数值>0.25被认为可接受,数值>0.5表示稳定性较好。节点稳定性检验结果,见图4。

图4 节点稳定性检验结果
3 讨论
3.1常见问题解析:同期网络的最小样本量估算 确定网络分析中的最小样本量主要取决于研究问题和网络特性,例如网络的大小和复杂性。并没有一种通用的方法可以直接确定最小样本量,因此最小样本量的确定通常依赖于以下几个因素。(1)研究设计:如果研究设计需要比较不同网络之间的差异,可能需要更大的样本量以确保亚组之间的统计效能。根据研究设计和假设检验的需求,样本量的要求会有所不同。(2)网络的复杂性:对于更大、更复杂的网络,通常需要更大的样本量以捕捉网络的细节和变异。相反,对于小型、简单的网络,可能需要较小的样本量。最小样本量通常需要大于节点数的20倍或250~350例以上[10]。可以通过R软件的netPower计算统计效能[11]。(3)分析方法:不同的网络分析方法对样本量的要求也有所不同。一些方法可能需要大量的数据才能得出可靠的结果,而其他方法可能对数据的数量要求较低。(4)研究目标:如果研究关注网络的全局属性,通常需要更大的样本量来确保对整个网络进行准确的推断。但如果只对网络中的特定部分感兴趣,可能可以使用较小的样本量。(5)节点中心性的稳定性:如果网络的节点中心性稳定性较好,通常可以使用较小的样本量。节点中心性稳定性指标一般要求>0.25才可接受[12]。(6)边缘权重的精确性:如果网络中边缘权重的估计比较准确,那么置信区间将较窄,反之则较宽。边缘权重的精确性会影响对网络结构的准确度。一般来说,样本量的确定需要通过统计效能分析或模拟研究来进行。这需要与有经验的网络分析专家合作来确定合适的样本量。
3.2常见问题解析:检验混杂因素对结果的影响 网络分析中控制混杂因素的影响的方法有多种[13-15],包括(1)控制变量层次建模法:该方法通过将可能影响结果的混杂因素和协变量引入模型中进行控制,以消除这些因素对结果的影响,并检验是否存在混杂因素对模型结论造成影响。通过引入相关变量来控制混杂因素,可以减少其对网络分析结果的干扰。(2)亚组分析:在网络分析中进行亚组分析,例如将参与者按照某个特征(如性别)进行分类,然后对每个亚组分别进行网络分析。这样可以检验混杂因素是否是导致模型结果异质性的重要因素。通过比较亚组之间的网络特性差异,可以评估混杂因素对网络分析结果的影响。(3)基于匹配的方法:这种方法通过将不同群组中的参与者进行匹配,使得群组之间的混杂因素和协变量得到控制,从而减少其对网络分析结果的影响。匹配可以基于一些特征或变量,使得匹配后的群组在混杂因素上更加相似,从而消除混杂因素的影响。
4 小结
本文介绍了症状同期网络分析方法的基本概念和常用网络特异性指标,以及如何使用R软件来实现。症状同期网络分析方法的目的是帮助医护人员更好地理解症状共生的机制,确定症状管理的重点,制定个体化的方案,并促进精准护理的发展。我们希望本文能对初学者了解症状网络分析方法有所帮助,并为该领域的研究者提供一定的参考价值。
