基于改进YOLOv7 的工业指示灯状态检测方法
2024-01-11王国武张振国张苏威
王国武,张振国,胡 辰,康 宏,张苏威
(国电电力内蒙古新能源开发有限公司,内蒙古呼和浩特 010040)
0 引言
随着人工智能和物联网技术的发展,越来越多的工业设备和系统(如开关柜等)需要进行监控和管理。其中,设备状态指示灯作为重要信息来源,常使用包括红、蓝、绿等颜色来展示设备运行状态。然而,一些设备上需要监测的状态灯种类繁多、布局密集,人工检测效率低,检测准确性、实时性难以保证[1]。所以发展更加智能的自动化设备状态灯检测技术对于提高设备监控效率和准确性具有重要意义,能有效避免设备故障或安全事故的发生。
围绕设备状态远程监控和状态自动识别问题,工业上通常采用安装辅助摄像头[2-3]或设计巡检机器人[4-5]采集仪器仪表的图像视频,并在此基础上做进一步识别工作。早期的研究者多通过灰度图、色域转换等方法来构造指示灯特征,进行其位置、颜色及亮灭状态识别。徐波[6]等采用基于灰度处理的图像阈值分割方法,通过多分割阈值和连通区域搜索实现指示灯识别。胡灿林[7]等基于潜在语义模型(Probabilistic Latent Semantic Analysis,PLSA),将图像由RGB 空间映射到11 维颜色属性空间,通过颜色的特征图像识别指示灯状态。杨强、朱红岷[8-9]等通过变换图像的颜色空间提取颜色特征,采用霍夫圆检测或迭代法改变阈值进行位置和状态识别。
随着深度学习在计算机视觉领域的快速发展,越来越多的研究者将深度学习技术应用到工业目标的检测任务领域。目前,目标检测使用较为广泛的深度学习网络是YOLO(You Only Look Once)系列算法。自YOLOv5 系列始就可以将目标定位和识别两大任务一次性完成。在指示灯状态识别方面,YOLO 系列算法也已有应用。完颜幸幸[10]等利用SSD(Single Shot Multibox Detector)和YOLOv2 模型实现指示灯自动识别。杨韵融[11]使用轻量级网络MobileNetv3_large 改进YOLOv3 模型的主干网络,并在预测网络中使用Inverted-bneck-shortcut 结构替换预测网络原1×1 卷积层,尽可能保存指示灯图像原有的信息。舒朗[12]等融合了DenseNet 和YOLOv5,使用自定义的密集连接型Denseblock模块替换YOLOv5s 中的Resunit 模块,提高了识别特征不明显的小目标方面的性能表现。崔昊杨[13]等针对电力设备状态识别提出一种GBYOLOv5m 算法,该方法采用加权双向特征金字塔(BiFPN)结构,增加检测层尺度,利用Ghost Bottleneck 结构替换原主干网络的Bottleneck 复杂结构,实现模型的轻量化。
基于上述研究,提出一种改进的YOLOv7-tiny-CBAM-WIoU算法,旨在保证检测精度的前提下,提高其在边缘设备或云端的快速部署能力。在算法的检测头网络中融入CBAM(Convolutional Block Attention Module,卷积注意力模块),融合通道注意力和空间注意力以增强网络的特征提取能力。此外,为降低模型受低质量数据的影响,引入了基于动态非单调聚焦机制的Wise-iou作为BBR(Bounding Box Regression,边界框回归)损失函数。改进的算法在指示灯实验数据集上具有更高的检测精度和速度,可以满足实际应用的要求。
1 网络模型
1.1 YOLOv7 算法原理
YOLOv7 属于单阶段(One-Stage)目标检测算法,在YOLO算法系列中以更高效的推理速度、更精确的检测准度,在工业界得到广泛的应用。相较于之前的版本,YOLOv7 在不增加推理成本的情况下,极大提高了实时目标检测精度,可有效减少约40%的参数和50%的计算量,从而实现更快的推理速度和更高的检测精度[14]。
基于YOLOv7-tiny 网络进行算法改进,该网络相较于YOLOv7原网络,是一种经剪裁和模型压缩的轻量化版本,主要通过减少卷积层的堆叠、改变激活函数为LeakyRelu 函数缩减模型参数来减少模型大小,以适配边缘设备的部署。YOLOv7-tiny 还采用了一些优化策略,如IoU 感受野、SPP 结构和PANet 结构等,模型拥有较高的检测性能。
1.2 YOLOv7-tiny 模型的结构及原理
YOLOv7-tiny 模型的结构主要分为Input 输入端、Backbone主干网络和Head 输出端3 个部分,与以往YOLO 系列算法不同,YOLOv7 算法将Neck 网络和Head 输出端组合成一个Head 网络结构,使得模型结构更为精简、高效。
YOLOv7-tiny 的整体结构如图1 所示,其中Backbone 网络结构采用了轻量化的卷积架构,该架构仅由若干CBL(Convolutions with Batch Normalization and Leaky ReLU)模块、ELAN-T层以及MPConv 层组成,用于初步的特征提取。Head 网络由以往的Neck 和Head 输出端组合而成,以SPPCSP 层为基准,加入了若干BConv 层、MPConv 层、Catconv 层以及上采样层,用于特征的进一步提取与最终检测结果的输出。

图1 YOLOv7-tiny 网络结构
1.2.1 Input
(1)Mosaic 数据增强:YOLOv7 模型采用的仍是YOLOv5 中使用的Mosaic 数据增强方式[15]。Mosaic 数据增强能够有效地丰富数据集,增加小目标数量,提高网络的鲁棒性。通过随机缩放、裁剪和排布4 张图片来生成Mosaic 图像,可以间接地增大Batch-Size,降低显存需求,从而提高训练速度。
(2)自适应锚定框计算:YOLOv7-tiny 模型训练时,自适应计算出最佳锚定框值,可适应不同的数据集。自适应锚定框计算能够使模型更好地适应不同尺度和长宽比的物体,提高检测精度。在训练阶段,模型输出预测框并计算预测框与真实标签之间的差距,通过反向梯度传播来更新整个网络参数。
(3)自适应图片缩放:为了适应不同尺度的物体,YOLOv7 常用的输入图片尺寸为640×640。在实际使用中,由于输入图片的长宽比和面积不同,需要对其进行缩放填充。YOLOv7 算法采用与YOLOv5 相同的自适应方法来添加最少的黑边到缩放的图片中,以减少信息冗余,提高推理速度。
1.2.2 Backbone
YOLOv7-tiny 的主干网络主要采用轻量级的网络结构,它直接由7 层CBL 层,以及若干MP 层、多层级特征融合模块(ELAN-T)组成,结合空间金字塔池化模块,能够更好地处理不同尺度的目标,并提高模型的检测精度。
1.2.3 Head
YOLOv7 将Neck 部分和Head 部分进行了合并,以SPPCSP为基准,可以分为5 个阶段,其中前4 个阶段包括了卷积层、SPP 层、CSP 层和上采样层,用于提取特征并进行特征融。对引入的SPPCSP 结构,其通过空间金字塔池化和卷积操作,实现了对不同尺度特征的提取和融合,进一步提高了模型的检测性能。最终通过3 个卷积层,用于预测输出每个网格单元格的边界框坐标、物体得分和类别概率。
2 算法改进
为提高轻量化模型部署在边缘设备时的识别精度,对YOLOv7-tiny 模型进行改进,得到YOLOv7-tiny-CBAM-WIoU模型。具体框架为:将CBAM 注意力机制集成入YOLO 检测头部分,分别嵌入在FPN 网络中的两个上采样层后,以提高模型对指示灯特征表达能力;并替换回归框损失函数WIoU(Complete Intersection over Union(CIoU)为Wise Intersection over Union),强化模型对更普通质量的锚定框的学习,减少低质量回归框对模型的影响。最后对融合特征进行目标的定位及分类,输出全部指示灯的具体位置和类别。
2.1 CBAM 注意力机制
注意力机制是指通过学习任务相关的特征,将注意力集中于关键信息上,从而提高模型的性能。常用的注意力机制包括CBAM(Squeeze-and-Excitation(SE),Spatial attention,Channel attention,Self-attention,Convolutional Block Attention Module)等。
其中SE 注意力机制[16]是最常用的注意力机制之一,通过自适应调整通道的权重来增强有益特征和抑制无益特征,从而提高检测的精度和速度;Spatial Attention[17]则通过在空间维度上进行特征加权来强调重要的空间位置,而Channel Attention 则通过在通道维度上进行特征加权来强调重要的通道维度;Selfattention[18]在输入序列中的信息上,自适应计算每个位置的权重,从而提取具有代表性的特征。
为使YOLOv7-tiny 能够有更高精度的预测效果,选取能够结合SE 注意力机制优势和空间注意力的CBAM 引入模型的FPN 中,分别嵌入其两个上采样层之后,以提升模型的性能。
CBAM 是由Sangyun 等人[19]提出的一种创新地将通道和空间注意力相融合的注意力机制。该机制主要由SAM(Channel Attention Module(CAM)和Spatial Attentional Model)两个模块以串联或者并联链接而成,且模块前后顺序并无限制,但是一般情况下以CAM-SAM 模块的串联形式(图2)效果更优,作为一种端到端的通用模块,可以高效集成入卷积神经网络中进行训练。

图2 CBAM 模块结构
其中CAM 模块(图3)利用特征间的通道关系生成通道注意图,采用压缩特征映射空间维度的方法来提高计算通道注意力的速率,并结合最大池化或平均池化的方法提高特征表征力。

图3 CAM 模块结构
而SAM(图4)模块作为通道注意力的补充,利用特征间的空间关系生成空间注意图,沿着通道轴进行池化操作并将之连接在一起,然后通过一个卷积层得到空间维度上的注意力权重。

图4 SAM 模块结构
与SE 注意力模块相比,CBAM 模块在平均池化的同时进行最大池化,并添加了SAM 模块,进一步提高网络对目标的识别能力。通过这些改进和优化,CBAM 模块可以更加全面地提取特征信息,从而提高模型的性能和效率。
2.2 基于动态的非单调焦点机制Wise-IoU
在目标检测中,通常也使用BBR 损失函数对边界框进行优化,在此过程中常用的损失函数有GIoU、DIoU 和CIoU 等。发展到CIoU[20]时,引入了长宽比的概念,可以更精确的评估预测框的位置和长宽比准确度。
其中,IoU表示目标框的IoU 值,ρ2(b,bgt)表示目标框和预测框中心的欧式距离,d 表示目标框和预测框的对角距离,c表示两个框的最小外接矩形对角线的长度,α 是一个可调参数,用于平衡位置回归损失和长宽比损失。公式(1)将目标框的位置和长宽比并入IoU 计算中,以更准确地评估预测框的质量。在较新的目标检测算法中(如YOLOv7),CIoU 是一种常用的回归损失函数,它可以显著提高目标检测的性能和效果。
然而,对于原YOLOv7 模型使用的CIoU 损失函数,考虑到指示灯形态主要呈现为圆形,在重叠目标和长宽比变化部分并不十分明显,但是模型部署到移动或者云端等边缘设备后如果需要重新训练,此时无法保证在该设备采集的数据集质量,因此使用WIoU 损失函数能更有效地提高模型性能。
Wise-IoU(WIoU)是一种基于交并比的损失函数,采用了动态的非单调焦点机制,使用离群度来评估锚定框的质量[21]。该损失函数结合包括动态的非单调焦点机制和智能的梯度增益分配策略,可以大幅度提高模型的鲁棒性,避免过拟合,并提高检测器的整体性能。考虑到良好的回归框损失函数不会对模型训练做过多的干预,于是,基于LIoU 函数构建距离注意力,得到具有两层注意机制的WIoUv1。
其中,Wg、Hg为最小封闭盒的尺寸,WIoU 基于离群度来分配梯度增益,它通过为具有较小离群度的高质量锚定框与低质量锚定框分配较小的梯度增益,将焦点放在普通质量的锚定框上,由此减少低质量样本所产生的有害梯度,提高模型的鲁棒性。
在WIoUv1 的基础上,构造非单调聚焦系数r,得到WIoUv3损失函数:
其中,由于LIoU 是动态的,因此锚定框的质量划分标准也是动态的,这使得WIoUv3 能够随时制定出最符合当前情况的梯度增益分配策略,保持高效率、高精度。本文所使用的损失函数为WIoUv3 版本,其在目标检测中已经有着广泛的应用,并在多种场景下验证有效。
3 实验流程
3.1 数据集处理
3.1.1 设备搭建与数据采集
通过自主搭建状态灯电路,模拟不同箱式变电压器环境下指示灯状态来采集高质量的图像数据。自主搭建设备可以根据具体需求进行灵活调整和优化,以获取更好的数据采样效果。指示灯自锁电路图的搭建实物电路如图5 所示。

图5 指示灯电路示意
其中AC 代表交流电源,SB 代表按钮开关,KM 代表交流接触器,L1、L2 分别是红、绿指示灯。
考虑到实际应用中需要对箱式变电压器状态进行实时监测,基于工业200 万像素级摄像头采集指示灯的视频,并对视频按一定帧率进行抽样分割处理,得到用于模型训练的图像数据。同时,从指示灯各侧面多个角度拍摄红绿灯亮灭4 种组合状态的图像数据(图6),以建立数据集用于模型的后续训练。

图6 指示灯数据示例
3.1.2 数据标注
采用AnyLabeling 标注工具对数据进行标签标注。其基于LabelImg 和Labelme 等标注工具,继续融合了Segment Anything Model 和YOLO 系列模型等智能标签技术,具备快速、准确的标注能力。使用AnyLabeling 标注工具对图像进行标注,快速生成标签信息,从而用于后续的数据分析和模型训练。最终生成标签见表1。

表1 数据类型标签
3.2 实验环境与评估指标
3.2.1 实验环境
研究在Windows11 操作系统上进行了训练和测试,使用AMD Ryzen 5 5600H处理器和NVIDIA GeForce RTX3050 GPU 进行计算。编程开发环境为Python 3.9.0,开发工具为PyCharm。基于PyTorch深度学习框架进行模型训练,并利用CUDA 11.3 进行深度学习环境加速以提高训练效率。
3.2.2 参数设置
在目标检测模型的训练过程中,为了提高模型的性能和效果,进行多次模型参数调优,最终确定最优模型参数,参数配置见表2。

表2 参数配置
3.2.3 评估指标
为了更加准确地评估模型的性能,本文在评估指标方面选用了P(Precision,准确率)、R(Recall,召回率)、AP(Average Precision,平均精度)和mAP(mean Average Precision,平均精度均值)等。具体公式如下:
其中,True Positive(TP)表示实际为正类并且被预测为正类的数量,False Positive(FP)表示实际为负类但被预测为正类的数量,False Negatives(FN)表示实际为正类但被预测为负类的数量,n 为数据集中的类别数。
3.3 模型训练
研究使用自建数据集进行模型的训练。首先对数据集进行预处理,去除了部分异常、分辨率低的图片。为保证训练集、验证集和测试集的合理性,将数据集按照7∶3∶1 的比例进行随机划分。按照YOLOv7 模型的训练要求,针对配置文件进行了优化,包括权重衰减、epoch 值、学习率、批尺寸等实验参数值的调整。模型训练结果显示,在约300 次训练后,模型的训练指标趋于平稳,此时终止训练。
根据训练日志中的统计数据,当参数按照表2 所示的设置进行训练时,得到的训练指标随训练次数变化如图7 所示。
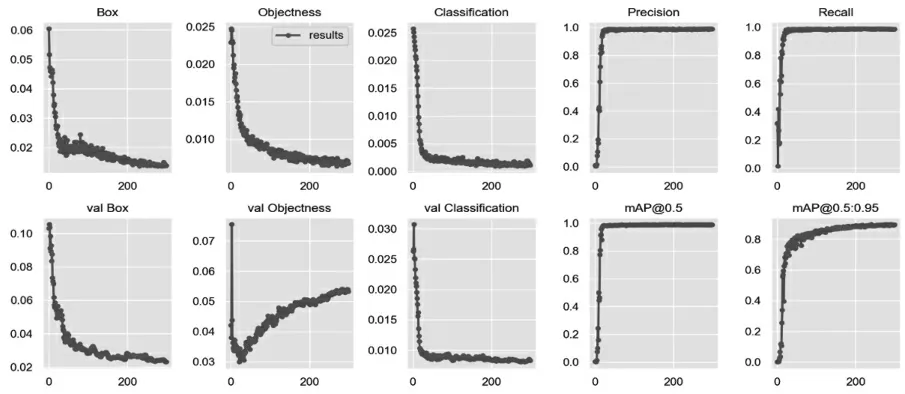
图7 模型性能指标
3.4 消融实验
为了更好的展示YOLOv7-tiny 改进后的检测性能的提升,项目对模型逐步实验,在相同数据集上进行测试,对比了5 组模型在增加不同模块后的检测效果。并对实验结果进行了统计和分析,实验结果对比见表3。

表3 模型训练效果对比
由表3 数据可知,在检测性能提升方面,CBAM 和WIoU 的引入均对模型的检测精度提升有积极的作用。改进前的YOLOv7-tiny在自建数据集上的训练检测平均精度均值(mAP)达到0.904,在引入CBAM 模块之后,模型预测精度提高到0.906,说明模型在添加注意力机制后,对指示灯特征的提取能力得到进一步增强,从而使模型对状态识别更为准确;在改进回归框损失函数为WIoU 后,模型的检测mAP 达到0.908,这是由于WIoU 增加了模型对更关键区域的敏感度,以提高了模型的检测精度。在同时引进两个模块之后,检测模型得到最优结果,mAP 达到0.912,较原YOLOv7-tiny 模型提高了0.8%。
而在检测速率方面,由于WIoU 其结构较原来的CIoU 函数更为简单,参数数量更少,所以减少了模型参数的大小。但对CBAM 模块,其同时考虑了空间注意力模块(SAM)和通道注意力模块(CAM),两者进行串联链接,这使得CBAM 嵌入模型后略微增加了参数量,也较轻微地影响了图片的检测速度。尽管如此,引入这两个模块后,模型对单张图片的检测速度达到了15.1 ms/张,速度提升了近44.3%。此外,改进模型的参数量与原始的YOLOv7-tiny 模型几乎没有变化,验证了改进对检测效果具有显著提升。
除此之外,将改进后的模型与YOLOv7 模型进行对比,可以较明显地观察到,改进模型在参数量减少83.5%的情况下,mAP仍能维持到0.912,并且单张图片检测速度提高63.8%。这表明改进的模型在更加轻量化情况下,检测速率得到显著提升,且仍具有较为稳定和优良的检测性能,适合在算力有限的边缘设备上进行部署。
4 结束语
针对目前开关柜等电力设备状态人工检测效率低下的问题,提出了一种改进YOLOv7 算法的设备状态灯检测方法,通过引入CBAM 注意力机制,以及改进IoU 损失函数为基于动态非单调聚焦的Wise-IoU 函数,提高了模型的目标识别能力和边界框损失的拟合效果。实验结果表明,所提出的算法在自制数据集上展现出了更优的性能,测试集上的准确率、召回率和均值平均精度均有所提升,并且在检测速度方面提升了44.2%。这些结果验证了所提出的算法在检测精度和速度方面的优越性。此外,算法的思路和方法也可以应用到其他领域的图像识别和目标检测任务中,例如自动驾驶、智能安防、医疗影像等领域。通过不断优化和改进,这种方法可以成为一种通用的、高效准确的目标识别和检测方法,为实际场景中的多种应用提供强有力的支持,推动人工智能技术的发展。
