基于变分模态分解-排列熵-改进鹈鹕优化算法的长短期记忆网络的短期负荷预测
2024-01-10谢文龙张莲王士彬李多杨家豪
谢文龙,张莲,王士彬,李多,杨家豪
(1.重庆理工大学电气与电子工程学院,重庆 400054; 2.国网重庆市电力公司市南供电分公司,重庆 401336)
0 引言
随着社会经济的快速发展,电力需求持续增长,电力市场也日趋复杂多变。“十四五”期间,我国将坚持绿色低碳发展理念,优化调整能源结构,提高能源安全保障水平[1]。2022年夏季,受极端高温、强降雨等自然灾害影响,部分地区出现用电荒,导致供电紧张甚至断电。因此,在当前形势下开展短期电力负荷预测研究不仅可以提高电力系统运行效率、降低运营成本、提升服务水平,还可以丰富相关理论体系和方法论等方面的理论意义[2]。
为了提升电力负荷预测的精确性,需要深刻把握负荷变化的规律性。电力负荷序列呈现出周期性、随机性等特点,实质上构成一类随机的非平稳时间序列。近年来,负荷预测领域将智能算法与神经网络、机器学习相结合,而长短期记忆网络(long short term memory,LSTM)也是公认对时间序列处理最好的模型之一。针对电力负荷序列特点所进行的分解,也成为了提升负荷预测精度和可靠性的重要方法[3]。例如经验模态分解(empirical mode decomposition,EMD)[4]、集合经验模态分解等。上述的LSTM模型和模态分解的方法虽然有效地提升了预测精度,但方法本身存在局限性。LSTM收敛速度过慢,参数选择对于预测结果的精度影响很大[5];EMD容易混叠,生成包含虚假信息的模态分量,会对预测结果产生较大影响;集合经验模态分解[6]采用叠加高斯白噪声的方法,来减少序列外部因素的影响[7],但是处理不当易引入噪声,影响结果准确性。而变分模态分解(variational mode decompostion,VMD)自适应、完全非递归的模态变分和信号处理的方法,克服了EMD模态混叠的问题;除此之外,对序列分解后,如果将模态直接代入模型预测,会导致计算量庞大[8],同时影响预测结果的精度[9]。
针对上述问题,提出了基于VMD-PE-IPOA优化的LSTM预测模型。该模型利用VMD的优点有效地避免了模态混叠;并通过排列熵合并模态,减少了计算规模;然后使用改进鹈鹕优化算法(improved pelican optimization algorithm,IPOA)更高效准确地寻找到最优模型参数;最后使用两份数据集,与不同预测模型和不同优化算法的结果进行对比,验证了本文所提方法的有效性和可靠性。
1 基本原理
1.1 变分模态分解
变分模态分解是一种自适应信号分解方法,在2014年由DRAGOMIRETSKIY等人[10]提出。它可以通过控制每个本征模函数(intrinsic mode function,IMF)的中心频率和带宽来减少模态混叠现象。对原始序列采用模态分解,可以降低复杂度高和非线性强的时间序列非平稳性,分解获得包含多个不同频率尺度且相对平稳的子序列[11]。
VMD的分解过程是变分问题的求解过程,通过迭代找到变分模型的最优解,确定每个模式的带宽和中心频率。因此,VMD可以自适应地分解频域信号,分离每个模式[12]。将原始负荷信号分解成IMF,每个IMF都可表示为:
uk(t)=Akcos[φk(t)]
(1)
(2)
式中:Ak(t)为瞬时幅值,Ak(t)≥0;φk(t)为相位;ωk(t)是瞬时频率。
具体的步骤如下:
1)步骤1,对于每个模态,使用希尔伯特变换计算相关的解析信号以获得单边频谱,并与调谐到相应估计中心频率的指数e-jωkt混合,将模式的频谱移动到基带:
(3)
式中:δ(t)为单位脉冲函数;uk(t)为模态函数。
2)步骤2,在通过解调信号的高斯平滑度估计带宽,即梯度的平方范数。由此产生的约束变分问题如下:
(4)

3)步骤3,为了求解式(4),利用二次惩罚因子α在有限权重下的良好收敛特性,以及拉格朗日乘子λ对约束的严格性,将式(4)的约束性变分问题转化为非约束性问题,得到增广拉格朗日表达式如下:
(5)

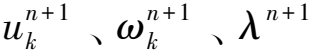
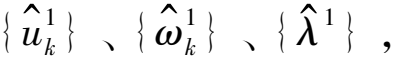
(6)
(7)
(8)

4)步骤4,直到满足式(9),停止迭代,否则返回步骤3。

(9)
式中:N为最大迭代次数;ε为收敛精度。
满足式(9)后,原始信号f被分解为k个模态向量uk(t),最后通过傅里叶反变换到时域。
1.2 排列熵
排列熵(permutation entropy,PE)值是一种用来表征时间序列或者混沌动力系统的复杂程度的无量纲指标[13]。它的计算方法是将时间序列分成若干个子序列,然后对每个子序列进行排序,得到不同的排列模式,再计算每种排列模式出现的概率,最后用信息熵公式求和得到排列熵值[14]。
简单地说,排列熵值的大小表示时间序列或者混沌动力系统的随机程度:熵值越小,说明时间序列或者混沌动力系统越简单、规则;反之,熵值越大,则时间序列或者混沌动力系统越复杂、随机[15]。
对于一组时间序列{X(i),i=1,2,…,N},对其进行相空间重构,得到矩阵Y为
(10)
式中:τ为延迟时间;m为嵌入维数;K为重构空间中重构分量的个数,其中K=N-(m-1)τ。
在矩阵Y中,每一行都是一个重构分量,总共有K个重构分量。将这些重构分量进行升序排列有:
x(i+(j1-1)τ)≤x(i+(j2-1)τ)≤…≤x(i+(jm-1)τ)
(11)
式中:用j1,j2,…,jm来表示Y中各个元素所在列索引。
如若排序过程中,相邻两个值相等,则以这两个值中列索引ji的下标升序排列。如此对于任意一个时间序列重构得的矩阵,矩阵Y就被映射到了一组符号序列:
S(k)=(j1,j2,…,jm),k=1,2,…,K
(12)
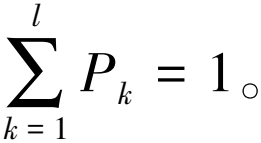
时间序列X(i)的排列熵依照香农熵(Shannon entropy)的形式可定义为:
(13)
Hp(m)最大值为ln(m!),将Hp(m)进行归一化处理为:
H=Hp(m)/lnm!
(14)
在经过归一化处理后,H的取值范围为0≤H≤1,H值的大小反映了时间序列的随机性程度。H值增大,对应着时间序列随机性增强[16]。
在式(10)中,嵌入维数m和延迟时间τ需要提前选取,参数的选取对排列熵的计算结果会产生影响,根据Christoph的研究,嵌入维数m一般取3~7。本文嵌入维数m取为3,延迟时间τ取为1[17]。
PE值的计算能够量化序列X(i)的复杂程度。可以通过比较各模态熵值的大小来比较它们各自的复杂程度。PE值能够有效地反映IMF分量的复杂程度,这为IMF分量的重构和建模简化提供了理论依据[18]。
1.3 LSTM
LSTM神经网络是一种改进的循环神经网络,它通过巧妙的网络结构设计,可以学习时间序列中的长短期依赖信息,从而在处理时间序列数据时表现出色。循环神经网络结构如图1所示,下方的x是输入层,紫色部分s是隐藏层,O是输出层。
LSTM结构如图2所示,记忆单元位于单元的中心,用蓝色圆圈表示。输入为已知数据,输出为预测结果Ot。记忆单元中的三个门用绿色圆圈表示。此外,单元的状态由St表示,每个门的输入是预处理数据Xt和记忆单元的先前状态St-1。图2中的红色是汇合点,表示相乘。

图1 循环神经网络结构

图2 LSTM神经网络结构
输入门:it=σ(W(i)Xt+U(i)St-1)
(15)
遗忘门:ft=σ(W(f)Xt+U(f)St-1)
(16)
输出门:ot=σ(W(o)Xt+U(o)St-1)
(17)

(18)
最终输出:
Ot=ot°tanh(St)
(19)

通过不同门的功能,LSTM的长短时记忆单元在时间序列内部具备捕获复杂相关特征的能力。这种特性避免了传统循环神经网络存在的权重溢出问题,以及梯度消失和梯度爆炸等困扰,从而赋予网络更为优越的性能[19]。
1.4 鹈鹕优化算法
鹈鹕优化算法(pelican optimization algorithm,POA)是一种自然启发的优化算法,旨在解决工程优化问题[20]。相比其他算法,它具有调整参数少、收敛速度快、计算简单等优点[21]。POA基于鹈鹕捕鱼的行为,将搜索空间视为一片湖泊,把要优化的适应度值视为鱼。该算法具有随机初始化、局部搜索和自适应参数调整等特点,可用于多个基准优化问题,并显示出优异的解决方案质量和收敛速度[22]。POA的具体步骤如下:
1)初始化
假设m维空间中有N只鹈鹕,第i只鹈鹕在m维空间中的位置为Xi=(xi,1,xi,2,…,xi,m),N只鹈鹕的位置X表示为:
(20)
式中:Xi代表第i只鹈鹕;xi,m代表第i只鹈鹕在第m个维度上的位置。
在初始化阶段,鹈鹕随机分布在一定范围内,而鹈鹕的位置更新被描述为:
(21)
式中:jlow,jup是鹈鹕的搜索范围,分别代表搜索下界和搜索上界;r代表介于(0,1)之间的随机数。
2)搜索阶段
在搜索阶段,鹈鹕通过在空间中随机搜索来寻找潜在的食物来源。猎物的位置随机生成,每次迭代期间鹈鹕位置随之更新:
(22)
式中:xi,j,P1是第i只鹈鹕在探索阶段之后,在第j维度的新状态;pj是第j维度中猎物的位置;Fp是其适应度值;I是等于1或者2的随机数,参数I影响POA准确探测搜索空间的探索能力。
在鹈鹕搜索阶段结束时,将比较前后两个适应度值,把鹈鹕位置更新为适应度值最小的位置。在此更新过程中,需防止种群移动到非最优位置。
(23)
式中:Xi,p1表示第i只鹈鹕的最新状态;Fi,p1是探索阶段的适应度。
3)定位阶段
在这一阶段鹈鹕会定位猎物位置并开始捕猎。这个过程中的数学模型如下:
(24)
式中:xi,j,P2是第i只鹈鹕在定位阶段之后,在第j维度的新状态;R为常数,等于0.2;R(T-t/T)表示种群成员xi,j的邻域半径,在每个成员附近进行局部搜索以收敛到更好的解;t是当前迭代次数;T是最大迭代次数。
当定位阶段结束后,比较前后的适应度值大小,将鹈鹕位置更新为适应度值最小的位置。
(25)
经过上述搜索阶段和定位阶段调整所有种群成员位置后,根据种群状态和适应度值,更新最佳的捕食策略。随后POA进入下一迭代,重复执行步骤2)搜索阶段和步骤3)定位阶段,直到最大迭代次数。
1.5 改进鹈鹕优化算法
POA相较于其他优化算法有很大优势,但其随机初始优化种群会导致鹈鹕个体的初始解空间分布不均,搜索能力较弱,容易陷入局部最优[23]。为增加种群的丰富度和提高寻优效率,采用Logistic混沌映射初始化种群及融合反向学习和柯西变异策略。改进后的IPOA算法流程如图3所示。

图3 IPOA算法流程
1)Logistic混沌映射初始化种群
从数学形式上看,Logistic映射是一个相对简单的映射方法。经验实践表明,它的混沌系统具有良好的安全性。因此,本文选择使用Logistic映射对种群中的最优个体进行混沌映射,用于生成符合Logistic映射规律的随机数序列。Logistic映射生成的随机数序列用于初始化搜索个体的位置。其表达式如下:
yn(t)=byn(t+1)[1-yn(t-1)]
(26)
式中:yn∈[0,1];t表示迭代次数;b是控制参数,决定了Logistic映射的演变过程,取值范围是1≤b≤4,一般取4,代表系统处于完全混沌状态下。
2)融合柯西变异和反向学习策略
反向学习的核心目标在于以当前解为基础,运用反向学习机制来搜索相应的反向解,并经过评估比较后,保留表现较优的解。为了更有效地实现最优解的搜索,将反向学习策略融入到POA中,数学表征如下:
(27)

(28)
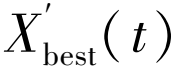
(29)
柯西变异受柯西分布启发,柯西分布概率密度表达式为:

(30)
当a=1时,称为标准柯西分布,记作C(0,1)。将标准柯西分布引入算法中,对目标位置进行更新,其表达式为:
Xi,j,t+1=Xbest(t)+C(0,1)*Xbest(t)
(31)
为了提升算法的优化效能,引入了一种动态选择策略来更新目标位置。在特定概率下,交替采用反向学习策略和柯西变异算子扰动策略,从而灵活地更新目标位置。至于采取何种策略进行目标位置更新,由选择概率Ps决定,其计算公式为:
(32)
式中:θ为调整参数,根据仿真结果,当θ取0.5时,优化结果最好。
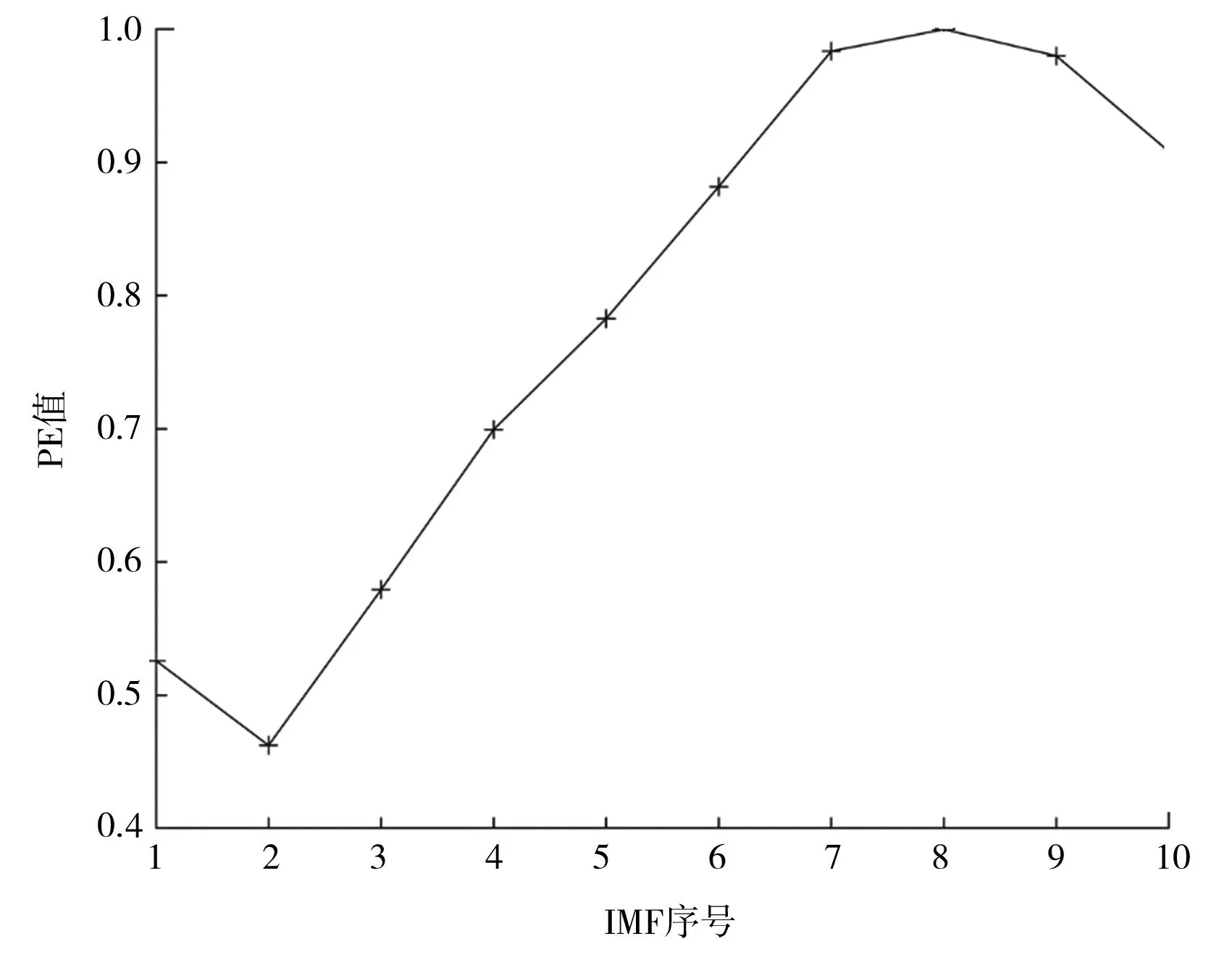
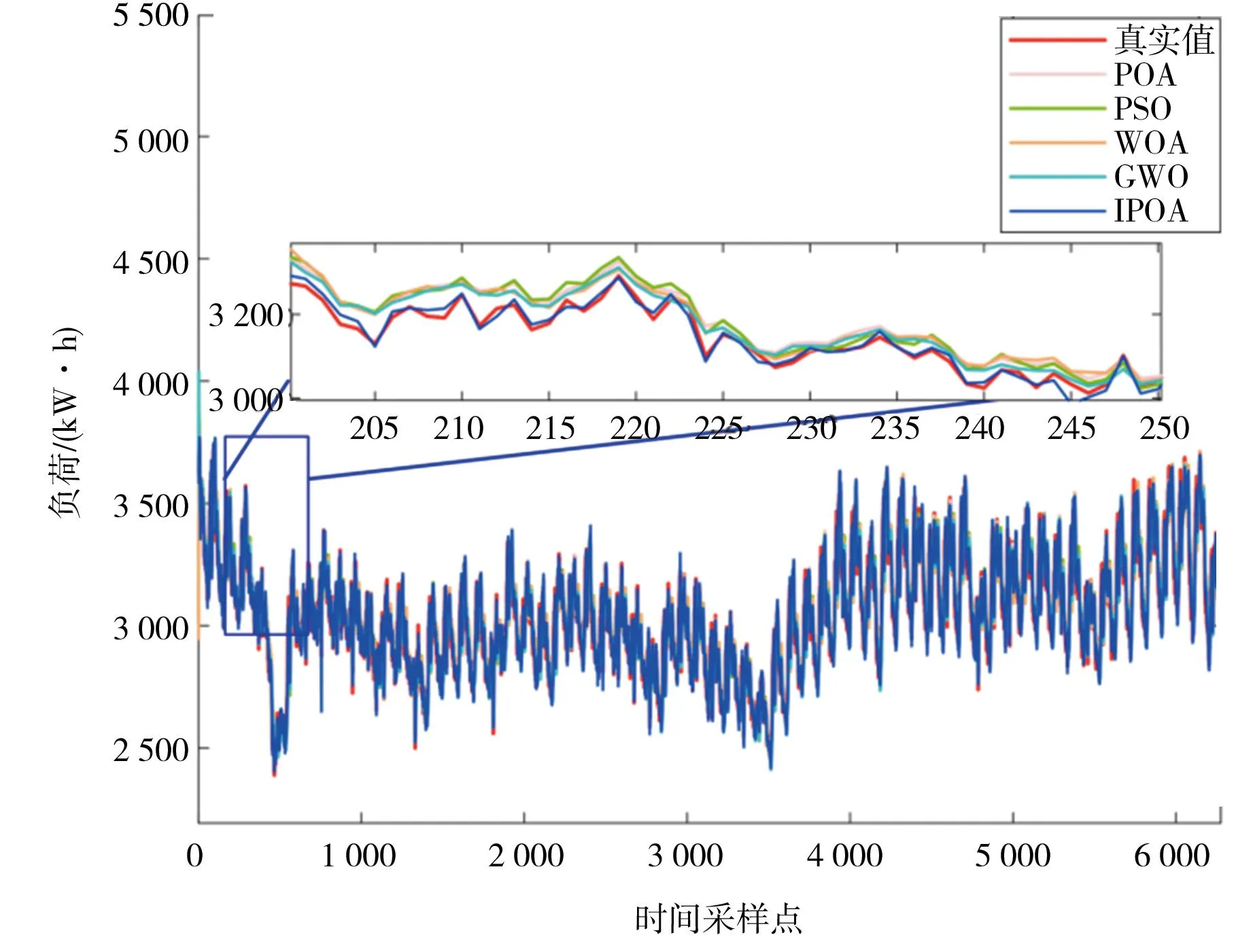
具体选择策略根据结果判断,如果r 虽然上述两种扰动策略可以增强算法脱离局部空间的能力,但经过扰动变异后,新位置的适应度值是否更优并不能直接判断得到结果。因此,引入贪婪规则,在扰动变异更新之后通过比较新旧位置的适应度值来决定是否更新。具体的更新规则可以表达为: (33) 1)第一步:首先确定VMD的模型输入变量K,并对历史负荷数据进行VMD分解,得到各个子模态。 2)第二步:根据排列熵分析结果确定最优模态分量数,并将排列熵值相近的模态进行子模态重组。然后对重组后的模态各自进行预测,形成LSTM的输入样本集。 3)第三步:采用IPOA算法寻找各子序列LSTM模型最优超参数,分别是学习率、隐含层神经元个数、正则化系数。并将最优的LSTM预测模型应用于各自序列的预测中。 4)第四步:最后将各个子序列的预测结果相加,得到最终预测结果。 建模流程如图4所示。 图4 建模流程 在 VMD中,在运行之前需要提前设置好分解的模态数K,过多会引起模式的重叠和附加噪声,若过少则会导致模态分解不完全。因此,设置正确的K值对于VMD处理及去噪至关重要[24]。 为了确定信号的模态数K,可以采用各模态的中心频率值。首先将K值的范围设置在8~12,然后对每个K值进行分解,检查每个K值对应的各模态中心频率是否存在相近的情况。如果存在相近的情况,则说明信号被过分解。经过反复试验,将K值设为10为宜。 若利用LSTM预测模型直接对每一个模态进行预测,会增加计算工作量。为缩小计算规模,利用排列熵理论对每一模态进行复杂度分析,根据分析得到的排列熵值进行合并叠加。为了通过排列熵来量化合并各模态,本文采用以下方式来计算: (34) 当I≤pij时,合并两个模态,形成一个新的子序列,否则就单独列为一个子序列。I为pij两个模态序列的PE值之差。根据式(34)计算可以得到新的子序列。 试验在处理器AMD Ryzen7、显示适配器RTX3060Laptop、内存16G、1TB固态硬盘硬件设备下完成,采用Windows 11的MATLAB2019b建立预测模型。LSTM的种群规模为30,最大迭代次数为200。LSTM求解步长为12,输出长度为1,解法器采用Adam梯度下降算法,激活函数为ReLU,网络迭代200次。 本文以华东某地区地方电网2018年1月1日至9月30日的电力负荷为数据样本[25]。负荷数据采样周期为15 min,每天96组数据,共26 208组数据。负荷曲线如图5所示。本文将前80%的负荷数据作为模型训练样本,将后20%的负荷数据作为预测模型测试样本,并与实际负荷对比。 图5 原始电力负荷数据 本文采用移动平均插值法和移动中位数法填补缺失数据。具体方法是:设定邻近区域,用窗口长度为30的移动均值代替缺失样点的平均值,用移动中位数替换数据中的NaN值。这两种方法适合样点分布均匀、密集且变化缓慢的情况,主要优势在于消除随机干扰、降低噪声、计算简便快速。 验证模型优劣通常用均方根误差ERMSE,平均绝对百分比误差EMAPE,决定系数ER2三个指标来衡量,它们能够有效反映模型预测的精度与拟合程度。具体的计算方式为: (35) (36) (37) 惩罚因子α控制了VMD算法中信号的频带宽度,α越大,则带宽越宽,反之亦然。根据相关文献的介绍和经验,本文将惩罚因子α取3 000。VMD的主要参数设置见表1。 表1 VMD主要参数设置 电力负荷数据进行变分模态分解后,得到的各个模态分量如图 6 所示。可以观察到第1阶模态反映了一定的趋势变化,而后面 9阶模态则呈现出周期性。通过使用模态分解,可以挖掘原始负荷序列中的趋势和周期性,并有助于预测模型更好地理解数据特征,从而降低预测难度。 利用排列熵理论对各个模态的复杂度进行分析,并根据排列熵值将它们合并叠加。这样就避免了直接用LSTM预测模型对每个模态进行预测而产生的大量计算量。 从图7和表2可以直观看出,模态7—9的PE值非常接近,可以把这3个模态合并叠加,生成一个新的序列。模态5则明显和其余模态区别开来,将其单独作为一个序列,新的序列号见表3。 图7 各模态的排列熵 表2 IMF分量的排列熵值 表3 模态组合后新序列号 模态合并如图8所示。从图6和图8的对比中可以看出,合并前后分量减少了4个,这大大降低后续建模的计算量。 图8 模态合并 为评估模型的精确度,将长短期记忆神经网络模型、反向传播神经网络(back propagation neural network,BP)模型、支持向量机回归(support vector regression,SVR)模型与真实值曲线进行对比,预测结果评价函数对比见表4,预测效果对比如图9所示(每15 min进行一次采样)。从预测结果来看,无论是EMAPE、ERMSE还是ER2,LSTM模型均优于BP、SVR预测模型。 表4 不同模型预测效果比较 图9 不同模型预测效果对比 在此基础上,采用经VMD-PE处理得到的6个模态作为样本数据,将训练样本的前80%作为训练集,后20%作为测试集,代入LSTM网络进行训练。利用经IPOA优化超参数后的LSTM网络,为6个模态构建了基于LSTM的预测模型。由表4可知,经过变分模态分解后的LSTM模型精度有所提升。经过PE合并后,各项评价指标精度有较小的提升。在实际模型训练中,训练时长从369.98 s降低至221.99 s,证明通过排列熵组合合并后,在未降低精度的情况下,提高了模型的训练速度。 针对分解并重组后的每个模态,本文引入了POA、粒子群优化(particle swarm optimization,PSO)、鲸鱼优化算法(whale optimization algorithm,WOA)、灰狼优化器(grey wolf optimizer,GWO),以及改进后的IPOA算法来寻找最优的LSTM模型超参数,并将最优的LSTM预测模型应用于各自模态的预测中。最后,将各个模态的预测结果相加,得到最终的负荷预测结果,评价函数和预测效果分别见表5和如图10所示,图10中每15 min进行一次采样。 表5 不同优化算法的LSTM模型预测效果对比 图10 不同优化算法的LSTM模型预测效果对比 分析表4、表5和图9、图10可以看出,在对原始序列数据不进行任何处理的情况下,LSTM模型在处理数据的时候,预测的精度高于BP模型和SVR模型。但是采用单一的LSTM模型预测时,由于历史数据复杂程度高、数据量较大,预测的精度整体偏差。采用VMD-PE-IPOA-LSTM预测方法进行预测后,EMAPE仅为0.865%,ERMSE仅为33.833 kW,ER2也是最接近1的,达到了0.980。整体来看,本文提出的预测方法,其ERMSE和EMAPE都低于其他对比预测方法,预测精度更高,并且基本还原了真实电力负荷曲线的变化趋势。由此可以说明,本文采取的预测模型具有良好的预测效果和性能。 为了进一步验证本文所提方法的有效性和普适性,追加福建某地区的最大用电负荷数据进行预测。以福建某地区地方电网2016年1月1日至12月31日的电力负荷为数据样本。负荷数据采样周期为15 min,每天96组数据,共35 136组数据。将前80%的负荷数据作为模型训练样本,将后20%的负荷数据作为预测模型测试样本,并与实际负荷对比。 根据2.1节和2.2节方法,得到VMD的最优模态分解个数为8个,合并重组得到4个子模态。五种不同模型和不同优化算法的的预测误差对比见表6和表7。 表6 不同模型预测效果比较 表7 不同优化算法的LSTM模型预测效果对比 由表6可以看出,相较于LSTM、BP、SVR这三种单一预测模型,经过VMD-PE处理的LSTM模型仍然在精度和拟合度方面更优。通过分析表7可以发现,在上述基础上,使用优化算法后的模型性能得到了明显地提升,其中IPOA的提升效果最为突出,相较于VMD-PE-LSTM模型,EMAPE提升了59.16%,ERMSE提升了25.12%,ER2也更接近1,预测效果更好。 综合表4—7的信息可以得出,本文所提出的预测模型在不同类型数据下的预测误差均优于其余几种预测模型,能够满足电力负荷短期预测的精度要求,具有普适性。 本文提出了一种基于VMD-PE-IPOA-LSTM的短期负荷预测模型,提高了短期负荷预测精度,并通过试验得到以下结论: 1)通过引入变分模态分解算法,将负荷数据分解为若干个复杂程度较低的模态;通过计算模态分解排列熵的方法,将原模态进行合并重组,挖掘出更多的负荷数据信息,降低预测难度,并对每个模态建立预测模型。各项评价函数表明,该方法提高了模型的整体预测精度。 2)在标准鹈鹕优化算法的基础上引入了Logistic混沌映射、融合柯西变异和反向学习这两种策略进行改进。结果表明,改进策略有效提升了模型的预测精度,验证了本文预测方法的可靠性。 文中所提出的IPOA-LSTM模型有效提高了负荷预测的精度,未来可以考虑更多的输入特征,例如温度、湿度、风速等,进一步提高模型的准确性。2 建立模型

2.1 模态分解个数确定
2.2 模态合并
3 实例分析
3.1 仿真环境
3.2 数据来源

3.3 数据预处理
3.4 评价指标
3.5 模态分解与合并




3.6 VMD-PE-IPOA-LSTM预测模型性能评价



3.7 VMD-PE-IPOA-LSTM模型在其他数据样 本中的应用


4 结论
