缺血性脑卒中后抑郁风险预测模型的系统评价▲
2024-01-10杨金盘马秋平张佳琳刘裕君杨春晓
杨金盘 马秋平 张佳琳 刘裕君 杨春晓
广西中医药大学,南宁市 530200
缺血性脑卒中(ischemic stroke,IS)是我国成年人残疾、死亡的主要病因,我国IS患者脑卒中后抑郁(post-stroke depression,PSD)的发病率为20%~40%[1]。PSD可继发于发病后的任何阶段,常伴有兴趣缺失、睡眠紊乱、自责自罪和易疲劳等症状[2]。PSD可影响患者功能康复,延长住院时长,增加治疗成本,甚至增加死亡风险[3-4]。加拿大《最佳实践建议:卒中后抑郁、认知、疲劳》指出,医务人员应重视PSD的早期识别,但目前仍缺乏PSD的特异性评估工具[5]。PSD风险预测模型是以PSD的多病因为基础构建的数理统计模型,可量化IS患者发生PSD的概率[6],为医务人员早期识别PSD高危患者提供有效的评估工具。目前,已有学者开发了IS患者PSD风险预测模型,但文献质量和结果不一,模型的预测效能和适用性有待评价。本研究对IS患者PSD风险预测模型进行系统性评价,以期为医务人员选择合适的PSD高危患者识别模型提供参考。
1 资料与方法
本研究已在PROSPERO平台注册,注册号为CRD42022360733。
1.1 文献纳入与排除标准
1.1.1 纳入标准 (1)研究对象为IS患者,且年龄≥18周岁;(2)研究内容为IS患者PSD风险预测模型,描述了模型构建、验证和评价全过程;(3)研究类型为横断面研究、病例对照研究和队列研究。
1.1.2 排除标准 (1)使用虚拟数据、未标明数据来源或数据不完整,不能获取原文;(2)综述、述评、动物或细胞分子水平研究;(3)学术会议摘要、灰色文献等非正式发表的文献;(4)重复发表的文献;(5)非中英文文献。
1.2 文献检索策略 采用主题词和自由词相结合的方式,检索CINAHL、Embase、Medline、The Cochrane Library、Web of Science、PubMed、中国知网、维普、中国生物医学文献数据库(Chinese Biomedical Literature Database,CBM)和万方数据库中有关IS患者PSD风险预测模型的文献,检索时限为自建库至2022年7月13日。中文检索词:“卒中/中风/脑血管意外/脑血管障碍/脑梗死”“抑郁/卒中后抑郁”“预测模型/预测因素/风险预测/早期预警/风险因素”;英文检索词:“Stroke/Cerebrovascular Accident/Cerebrovascular Apoplexy/Brain Vascular Accident/Acute Cerebrovascular Accident/Cerebrovascular Stroke/Cerebral Infarction” “Depression/Post-stroke Depression/Post Stroke Depression/Poststroke Depression/Depression after Stroke/Depressive Symptoms/Depressive Symptom/Symptom, Depressive/Symptoms,Depressive/Emotional Depression/Depression, Emotional”“Prediction Model/Prognostic Model/Predictive Factors/Risk Prediction/Early-warning/Risk Stratification Model”。
1.3 文献筛选和数据提取 采用EndNote X9软件剔除重复文献。由2名研究者通过阅读文献标题、摘要、全文,按照纳入和排除标准独立筛选文献,意见不一致时,与第3名研究者协商裁决。2名研究者使用预测模型研究系统评价的关键评估和数据提取(Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modelling Studies,CHARMS)清单[7]独立提取数据并交叉核对。提取数据包括第一作者、发表年份、国家、研究对象、研究类型、研究设计、随访时间、预测结局、样本量、缺失数据、预测因子、模型呈现形式、验证方法、建模方法和模型性能等。
1.4 纳入文献的偏倚风险和适用性评价 由2名研究者独立使用预测模型偏倚风险评估工具(Prediction Model Risk of Bias Assessment Tool,PROBAST)[8-9]评价纳入文献的偏倚风险和适用性,并交叉核对结果,意见不一致时,与第3名研究者协商裁决。
1.5 统计学处理 对CHARMS和PROBAST语句中的域和纳入文献结果进行系统评价。
2 结 果
2.1 文献筛选流程与结果 初检共获得相关文献1 597篇,通过阅读文献标题、摘要和全文进行初筛和复筛后,最终纳入文献9篇[10-18],其中中文文献[10,12-15,17]6篇,英文文献[11,16,18]3篇。文献筛选流程与结果见图1。
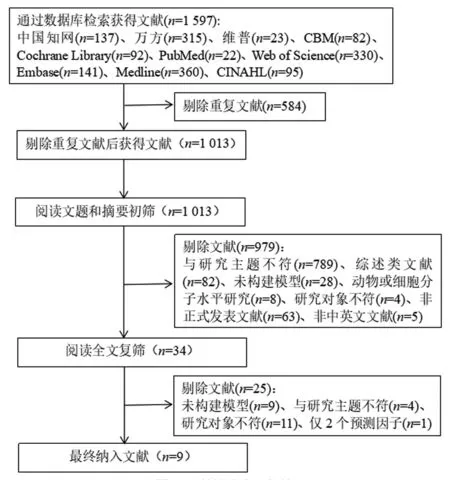
图1 文献筛选流程与结果
2.2 纳入文献的基本特征与预测结果 共纳入横断面研究1个,回顾性研究4个,前瞻性研究4个;文献发表年份为2020年至2022年;纳入文献的结果事件数与协变量个数比(events per independent variable,EPV)均小于10。9篇文献中,6篇[10-12,14-15,17]未报告缺失数据,2篇[16,18]报告了缺失数据并采取多重插补法进行处理,1篇[13]报告研究过程无数据缺失。纳入文献的基本特征与预测结果见表1。
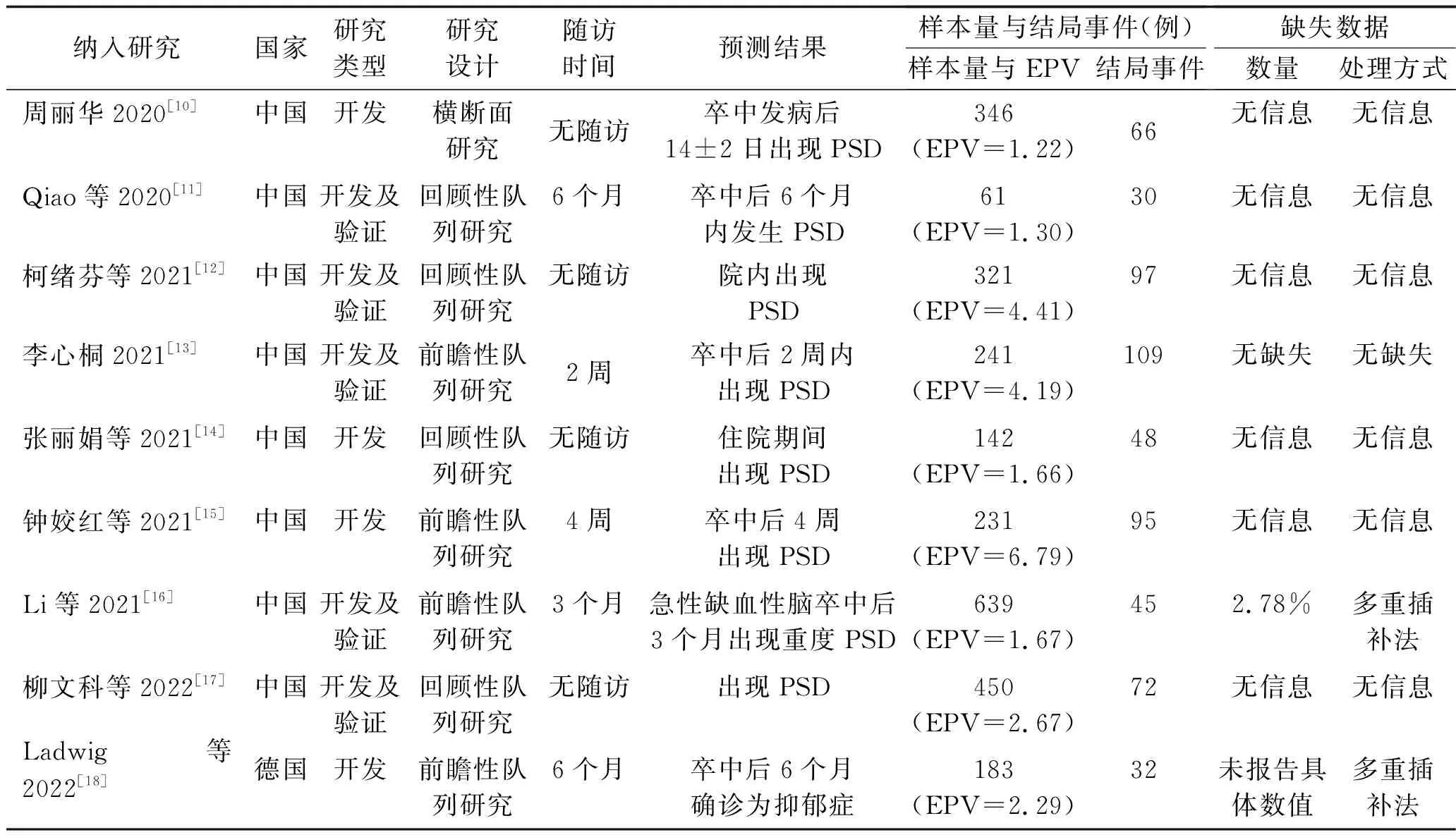
表1 纳入研究的基本特征与预测结果
2.3 模型构建情况 纳入文献中,8篇[10,12-18]采用logistic回归,1篇[11]采用了LASSO回归;3篇[10,15,18]未报告校准度,8篇[10-14,16-18]使用受试者工作特征曲线的曲线下面积(Area Under the Curve,AUC)评价模型区分度,AUC均大于0.7,表示预测模型的区分度良好。3项研究[11-12,17]进行了外部验证并表现出较好的区分度(AUC 0.793~0.885),仅1项研究[13]进行随机拆分验证。纳入文献的模型包含3~7个预测因子,其中次数出现最多的是美国国立卫生研究院卒中量表(National Institutes of Health Stroke Scale,NIHSS)评分、Barthel指数(Barthel index,BI)、年龄、高血压,均为各级医疗机构易获取、可测量的指标。3篇[13-15]以公式、6篇[10-13,16-17]以列线图作为呈现模型,仅1篇[18]进一步将模型转化为量表。纳入文献均对模型的应用进行了评价、讨论。以上内容见表2。
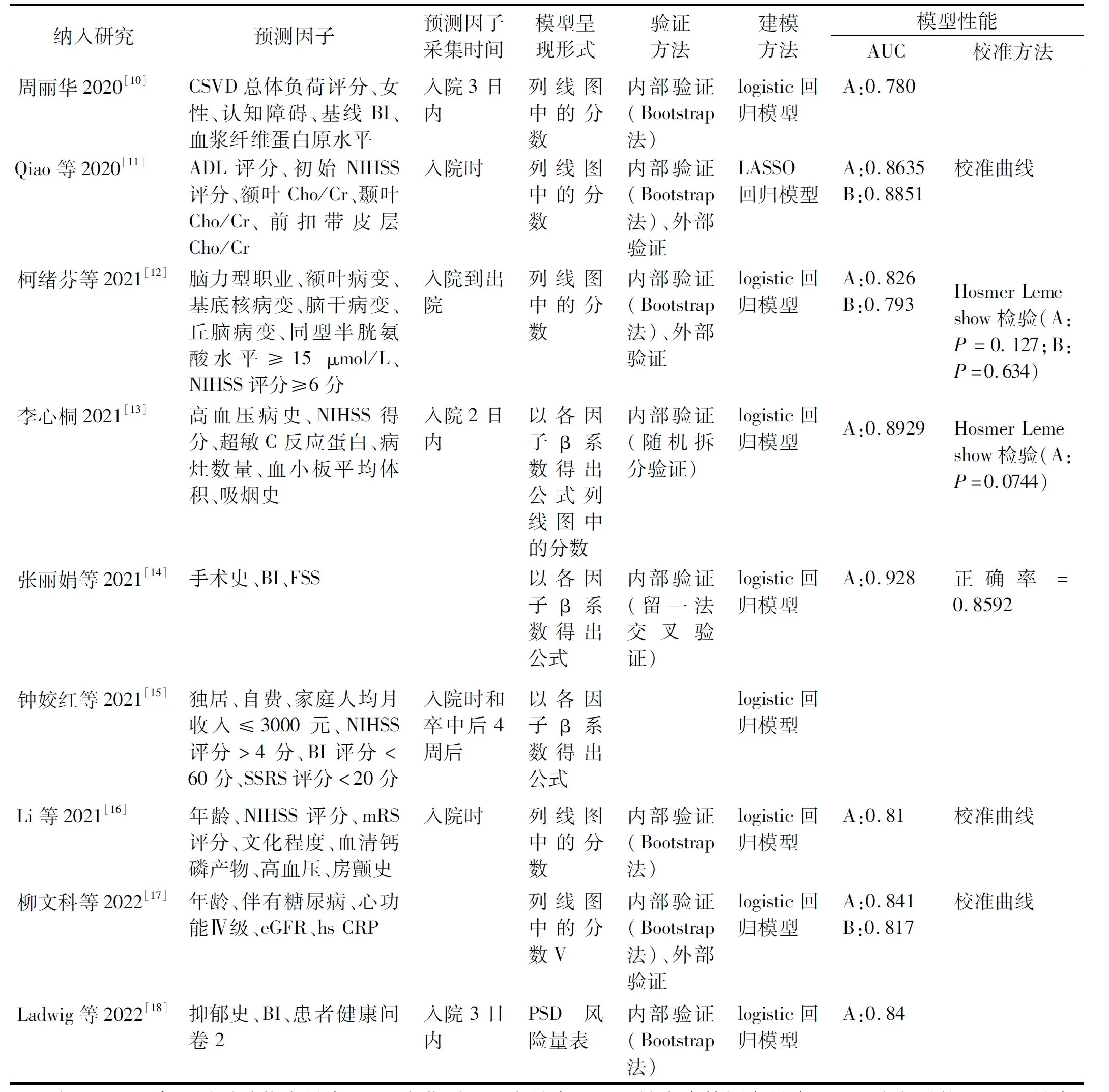
表2 模型构建情况
2.4 纳入文献的偏倚风险评价
2.4.1 与研究对象有关的偏倚 在研究对象领域,纳入的9项研究偏倚风险均低,见表3。
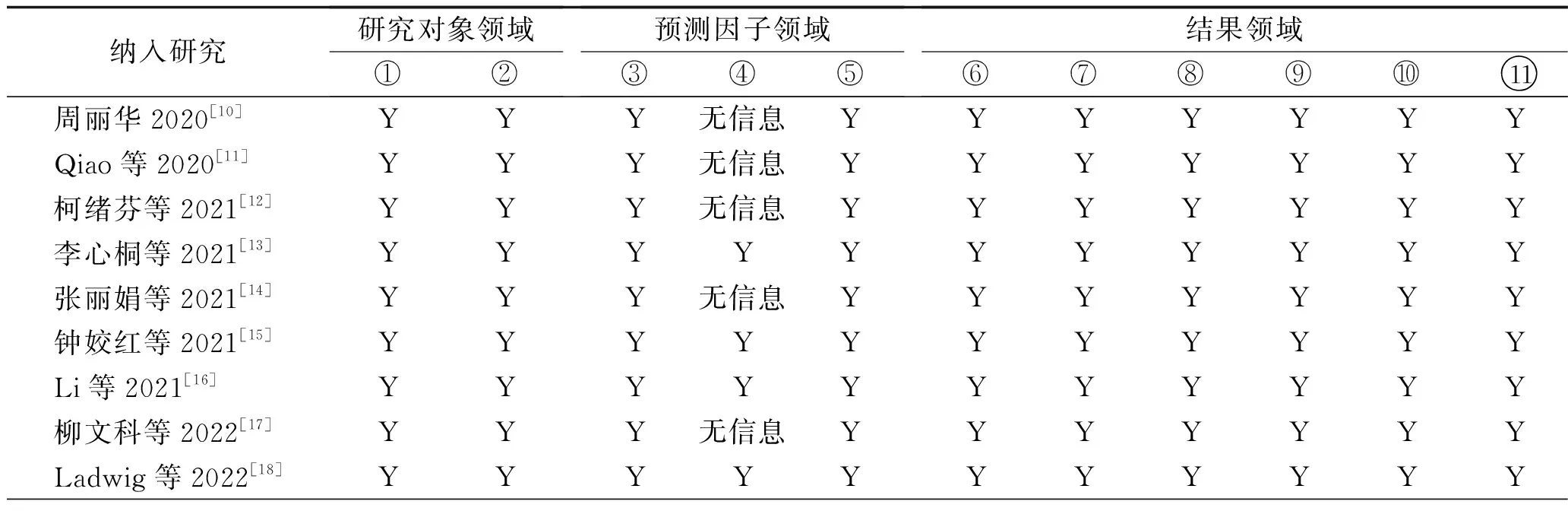
表3 纳入研究的研究对象、预测因子、结果和分析领域评价
2.4.2 与预测因子有关的偏倚 在预测因子领域,4项研究[13,15-16,18]偏倚风险低,5项研究[10-12,14,17]的偏倚风险不清楚。对预测因子评估者的施盲情况和与预测因子有关的偏倚风险的高低相关[8],对评估者施盲的研究的偏倚风险较低[9]。由因及果的前瞻性队列研究[13,15-16,18]默认对预测因子的评估者施盲,而横断面研究[10]和回顾性队列研究[11-12,14,17]对预测因子评估者的施盲情况不得而知,故偏倚风险不清楚,见表3。
2.4.3 与结果有关的偏倚 在结果领域,纳入的9项研究均为低风险偏倚,见表3。
2.4.4 与分析有关的偏倚 在分析领域,9篇文献均为高风险偏倚,见表3。在开发模型时[19],EPV<10会造成模型过拟合,EPV>20则可提高统计效能以减少混杂因素的干扰,而9篇文献的EPV均<10,说明其有效样本不足。将连续型变量转换为分类变量会丢失部分数据信息,进而影响模型准确性;3篇文献[12,15-16]将连续型变量转化为分类变量,导致其偏倚风险增高。数据是否有缺失及其缺失程度直接影响数据质量的高低[20],从而影响模型预测效能。9篇文献中,6篇[10-12,14-15,17]未报告相关信息,1篇[18]采用多重插补法但未报告缺失数量,1篇[16]报告缺失数据占比为2.78%并采用多重插补法进行填补,仅1篇[13]无数据缺失。变量筛选需以临床专业知识为最基本的考量,综合考虑样本量和自变量大小以确定统计方法、检验水准,如脱离临床则会出现较大偏差[20]。如变量较少可直接全部纳入回归模型进行分析。5项研究[10,12,14-15,17]仅采用单因素分析法筛选变量,未考虑数据的复杂性和临床特点,因此其偏倚风险较高。在性能评估方面,6项研究[11-14,16-17]同时报告了区分度和校准度。3项研究[11-12,17]进行外部验证,1项研究[15]未进行验证,其余均进行内部验证。纳入文献的偏倚风险见表4。

表4 纳入文献的偏倚风险评价
2.5 适用性评价 在适用性评价方面,9个模型在研究对象、结果领域的适用性均较高,有4个模型[10,12,14,17]在预测因子领域的适用性不清楚;4个模型[10,12,14,17]的总体适用性不清楚。纳入文献的适用性评价结果见表5。
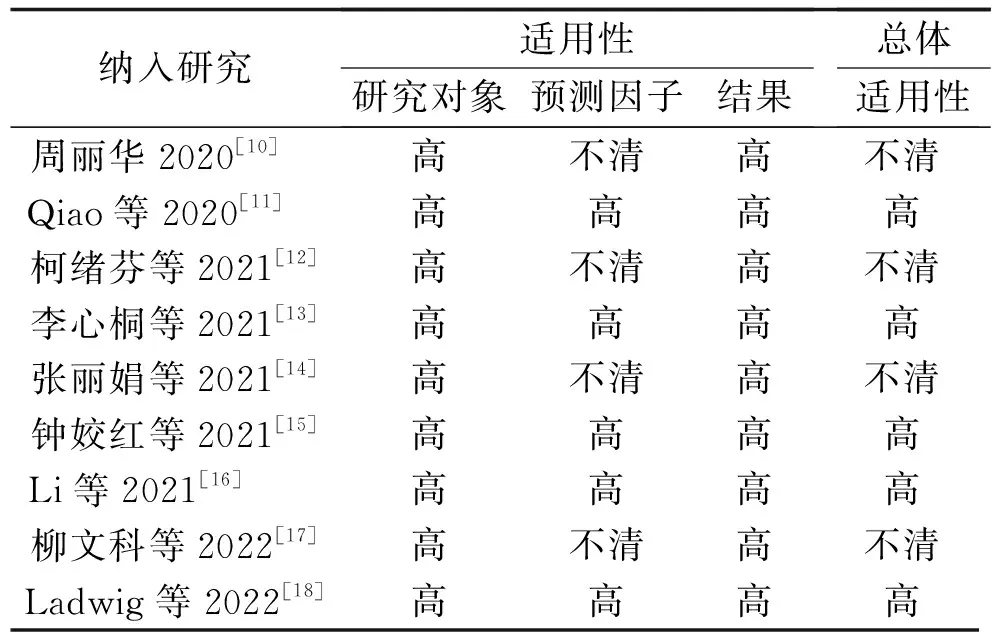
表5 纳入文献的适用性评价
3 讨 论
3.1 IS患者PSD风险预测模型仍处于发展阶段 本研究最终纳入4项模型开发研究、5项模型开发及验证研究,共计9项研究,共包含9个模型。9个模型的AUC为0.780~0.928,其中6个模型的AUC>0.8,预测性能较好。但9项研究偏倚风险均高,偏倚风险主要集中在分析领域,其原因大致包括:未报告盲法、因变量事件数不足、模型过拟合、未报告或未处理缺失数据和仅依据单因素分析筛选预测因子等。此外,9项研究关于PSD的定义和诊断标准存在异质性,而不同的诊断评估标准会影响模型的外部验证、临床实践转化和推广性。建议研究者未来选用目前广泛使用且《最佳实践建议》[21]推荐的汉密尔顿抑郁评分量表。
3.2 IS患者PSD预测模型的整体偏倚风险较高 本研究纳入的9项研究的总体偏倚风险均较高,5项研究[11,13,15-16,18]的总体适用性较高,其余4项研究[10,12,14,17]的总体适用性均不清楚。未来,需开发偏倚风险低,适用性高的预测模型。对未来护理实践和临床研究的启示如下。(1)NIHSS评分、BI、年龄、高血压是纳入的9个模型中包含的主要预测因子,应注意对上述变量的评估。(2)优化研究设计:建议在评估预测因子、结局事件时对评估人员施盲,诊断性的预测模型适合采用横断面的研究设计,预后模型可采用前瞻性队列的研究设计[20],以减少因研究设计而产生的偏倚。未来可参照PROBAST[8]进行研究设计以减少偏倚。(3)样本量应充足:依据PROBAST[8],建议模型开发研究应扩大样本量使EPV>20以获取足够的统计学效能甄别混杂因素对结局的影响[20],而模型验证研究则需使结局事件数>100以降低偏倚风险[22]。(4)科学处理缺失数据:依据缺失原因和数据形式选择适当的处理方法。6项研究未报告缺失数据相关信息[10-12,14-15,17],可看作研究者忽略了缺失数据的处理,由此产生较大偏倚。常见的处理方法有删除法、加权法、插补法[23]。(5)切忌只依赖单因素分析筛选预测因子,预测因子的筛选需综合考虑其临床重要性、客观性、适用性、易获取性和经济成本[8],而非单纯依靠统计方法。(6)选用更优的建模方法。Qiao等[11]采用LASSO回归建模。LASSO回归是一种机器学习算法,通过构造一个惩罚函数得到一个较为精炼的模型,可以处理复杂的临床数据,有效地解决过拟合和多重共线性问题[24]。从预测性能来看,Qiao等[11]LASSO回归模型在外部验证集的AUC为0.885,与其他logistic回归模型[12,17]相比,其外部验证AUC更高,预测性能更优。这提示,随着医疗数据的不断整合与结构化,以及数据挖掘技术的进步,研究者可尝试使用机器学习算法处理复杂数据并构建模型。(7)模型呈现应以临床使用便捷为原则。有2项研究[14-15]仅以公式作为呈现形式,未来可借助R语言rms包绘制列线图,或开发网络计算器[25]、评分系统,以方便临床使用。此外,未来研究者应参照个体预后或诊断的多变量预测模型透明报告(Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis,TRIPOD)[26],以规范其研究报告。
4 小 结
本研究共纳入9项研究,包括9个IS患者PSD风险预测模型,偏倚风险均较高。研究结果提示,IS患者PSD风险预测模型的研究仍处于发展阶段,未来应参照PROBAST和TRIPOD优化研究设计和研究报告,建议开展多中心、大样本量研究,结合机器学习等人工智能算法,开发准确性和简便性兼备的模型,同时对模型进行外部验证或实证研究以优化模型。
