基于随机森林模型的城市非法营运车辆识别
2024-01-09黄子璇李桥兴
黄子璇,李桥兴,2
(1.贵州大学 管理学院,贵州 贵阳 550025;2.喀斯特地区发展战略研究中心,贵州 贵阳 550025)
非法营运车辆指未依法取得营运权却实施了营运行为的车辆,即未按规定领取有关主管部门核发的营运证件和超越核定范围进行经营的车辆。人流、物流和车流的增量与区域交通出行需求不匹配,在一定程度上给非法营运车辆的出现提供了市场契机[1]。非法营运车辆不交纳任何运营费用且多数为低端和维修保养不到位的车辆,具有较大的安全隐患[2]。乘客对道路运输相关法律法规缺乏了解,选择乘坐非法营运车辆并与司机严密串词为道路交通执法增加了难度[3]。高速公路电子不停车收费系统(ETC)能够根据车辆的行驶特征反映非法营运车辆的时空变化规律,可有效查处高速公路非法营运车辆从而优化高速公路的运行秩序并提升管理水平。
数据挖掘是信息处理领域的重要课题,由人工智能、数据库和机器学习等多领域的理论和技术融合而成,分类则是数据挖掘的重要功能之一。研究人员对分类算法进行了大量研究,具有代表性的算法包括随机森林包括模型[4]、决策树算法[5]和逻辑回归模型[6]等。随机森林模型主要用于回归和分类,在生物信息、金融经济和新能源等的多维数据分析中具有广泛的应用[7]。决策树算法用于为各类方案的效益值而做出决策,在临床试验[8]和文本索引[9]等方面应用广泛。逻辑回归模型是一种广义的线性回归分析模型,被主要应用于地形探测[10]、经济预测[11]和文本识别[12]等领域。国内研究人员针对网约车的非法营运[13]以及其司机与平台间的演化博弈[14]、非法营运车辆的识别与安全监管以及长效治理机制[15-17]等进行了研究。国外研究人员研究了运输情况[18]、车票价格[19]及汽车类型对产能影响[20]等。另外,国内研究人员多采用自组织映射神经网络(Self Organizing Maps,SOM)[21]、卷积神经网络[22]和K-Mediods及其改进算法[23]等数据挖掘方法构建非法营运车辆识别算法。由于仅凭法律手段无法完全解决非法营运车辆在道路交通执法中的识别和查处问题,因此本文基于城市高速公路有效指标的ETC数据,采用随机森林算法建立非法营运车辆的识别模型,并加入决策树算法和逻辑回归模型进行比较。最后,根据西南某市高速公路车辆的流水指标数据进行实证分析,验证了本文所提出的随机森林模型更适用于非法营运车辆识别。
1 研究方法
1.1 研究方法
随机森林(Random Forest,RF)算法基于自助法(Boot Strap)重采样技术对原始训练集M中有放回地重复随机抽取N(N≤M)个样本生成新的训练样本集合,然后根据自助样本集生成N个分类树组成随机森林。其实质是改进的决策树算法将多个决策树合并在一起,在Bag-ging基础上对每棵决策树进行随机特征选择,然后对测试集进行回归预测,最后整合预测结果并投票得出结果。
CART分类树算法是一种应用广泛的决策树学习方法,由特征选择、树的生成以及剪枝组成。CART分类树算法是在给定输入随机变量X条件下输出随机变量Y的条件概率分布的学习方法,其实质是基于基尼系数最小化准则进行特征选择的二分递归算法,可以避免数据过分拟合并有效提高预测精度。
逻辑回归(Logistics Regression,LR)算法是一种针对被解释变量为二分类的概率型非线性回归统计方法,其优点是对数据的方差性和正态性不做具体要求。二元逻辑回归是逻辑回归的最简形式,其实质是基于Sigmoid函数的有监督二分类模型。
1.2 指标构建
高速公路电子不停车收费系统主要包括车辆进出公路的收费站点名称、时间、车型、交易类型、交易耗时、通行速度和车牌等。与普通车辆相比,非法营运车辆在工作日或周末行驶长途与短途的次数和天数不同、通行时间段与正常通勤车不同。因此,根据非法营运车辆行驶特点,本文构建了累计通行天数、累计通行次数、单次平均通行时间、是否同城、是否周末通行和通行时间段等6个特征指标来识别非法营运车辆,6个特征指标的具体含义如表1所示。

表1 特征指标
1.3 分类模型评价指标
为了解机器学习模型的泛化能力,本文使用常用的分类模型评价指标来衡量模型的性能,包括准确率(Accuracy)、精准率(Precison)、召回率(Recall)和F1分数。本文采用随机森林预测模型的因变量即车辆是否为非法营运车辆,并当车辆为非法营运车辆时赋值为1,否则赋值为0,从而建立混淆矩阵,如图1所示。当车辆实际为非法营运车辆时,通过随机森林预测模型将其分类为非法营运车辆的样本数,设为TI,分类为合法营运车辆的样本数,设为FL。当车辆实际为合法营运车辆时,通过随机森林预测模型将其分类为非法营运车辆的样本数,设为FI,分类为合法营运车辆的样本数,设为TL。本文的模型评价指标如下所示:
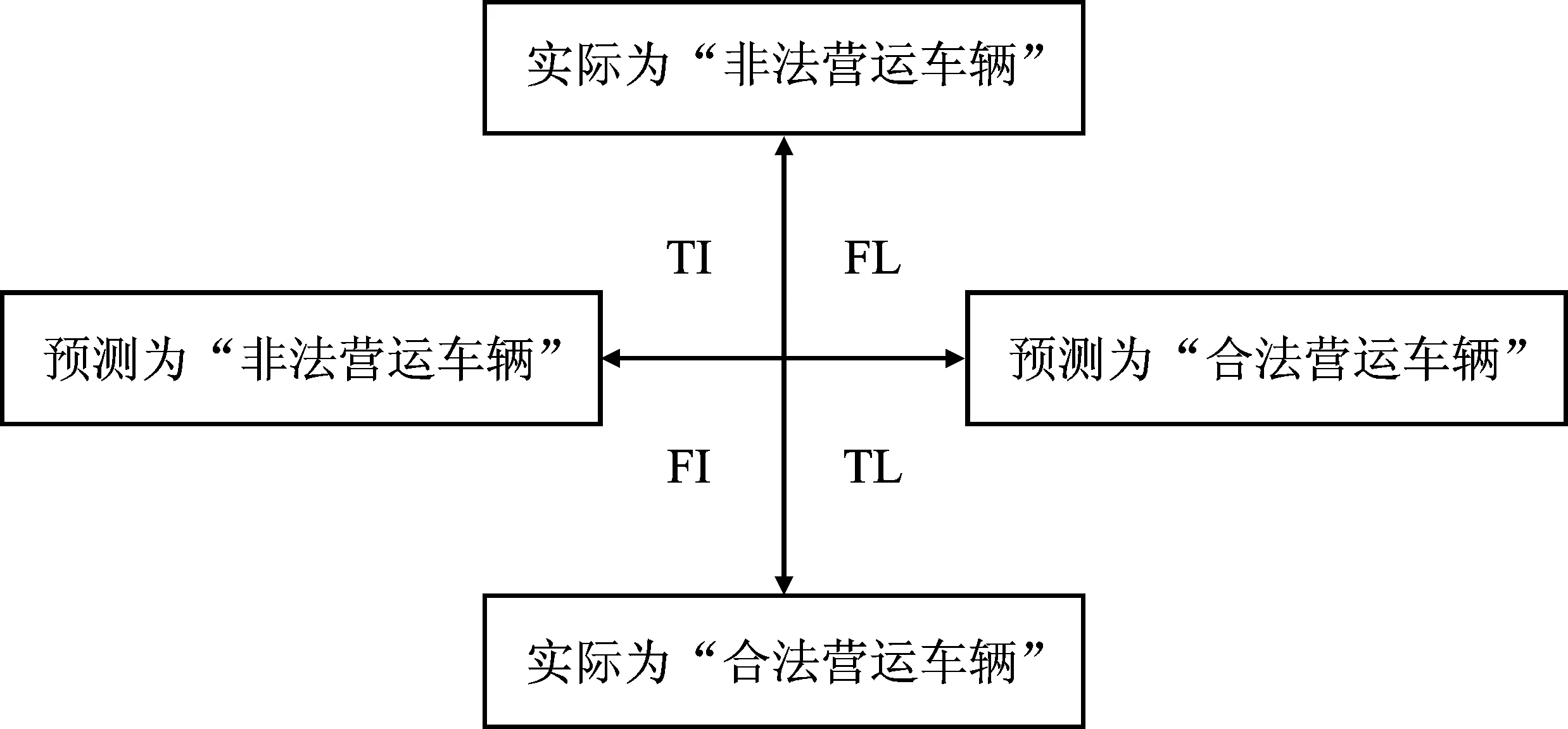
图1 混淆矩阵Figure 1. Confusion matrix
准确率表示预测正确的样本数占总样本数的百分比。
(1)
精准率表示在预测为非法营运车辆的样本中预测正确的比率。
(2)
召回率表示在实际为非法营运车辆的样本中预测正确的比例。
(3)
F1分数综合考虑了精准率和召回率,在两者同时达到较高水平时取其平衡值。
(4)
2 实验与分析
2.1 数据处理
本文使用数据为2022年2月6日~2022年3月8日西南某市409万余条高速公路电子不停车收费系统(ETC)出口数据,其中ETC收费系统共含93个字段。本文根据识别非法营运车辆的目的剔除无用字段, 筛选共10项有用字段,如表2所示。如图2所示,本文在清除交易失败(TRADE_RESULT)、特殊车辆(VEHIC LE_USER_TYPE)和非客车(VEHICLE_CLASS)的冗余通行数据后,得到100万条行车数据和70 575辆车的车牌数据,其中非法营运车辆52辆。
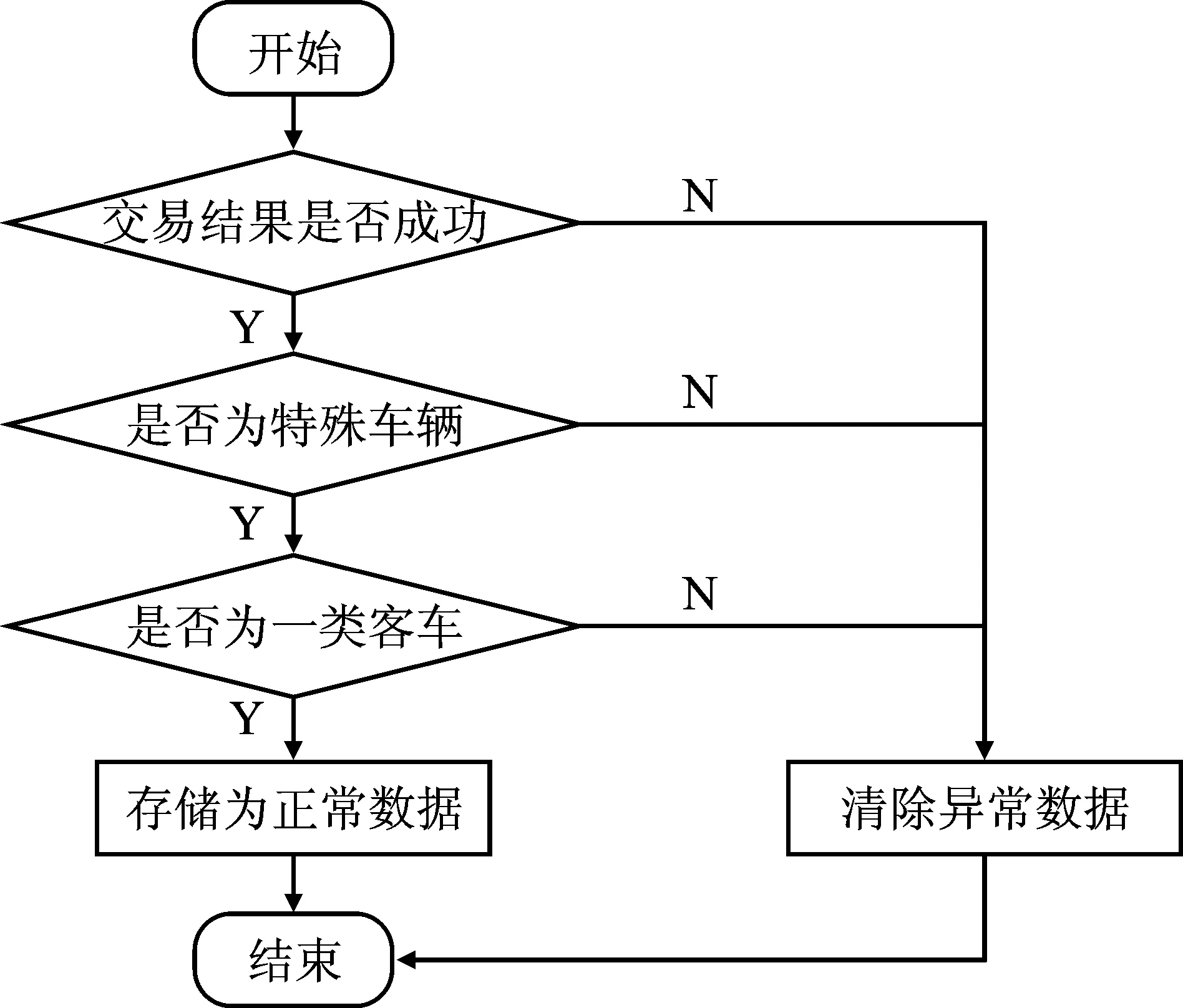
图2 清除冗余数据流程Figure 2. Flow of clearing redundant data

表2 ETC数据有效字段
2.2 相关性检验
图3表明天数(days)和次数(frequency)的相关系数为0.88。由于司机的出行天数与其出行频率呈正比,故相关性较高。但出行天数和次数都可分别设置阈值判断嫌疑车辆,因此不可去除这两个指标的任意一个。是否同城(same time)、是否周末出行(weekend)、出行时间段(time period)、单次平均通行时间(mean time)与是否为非法营运车辆(label)这5个指标之间的相关性较低。是否同城(same time)、是否周末出行(weekend)、出行时间段(time period)、单次平均通行时间(mean time)、天数(days)和次数(frequency)分别与是否为非法营运车辆(label)未存在线性重叠。因此,这6个因变量指标可以被用于随机森林算法计算。
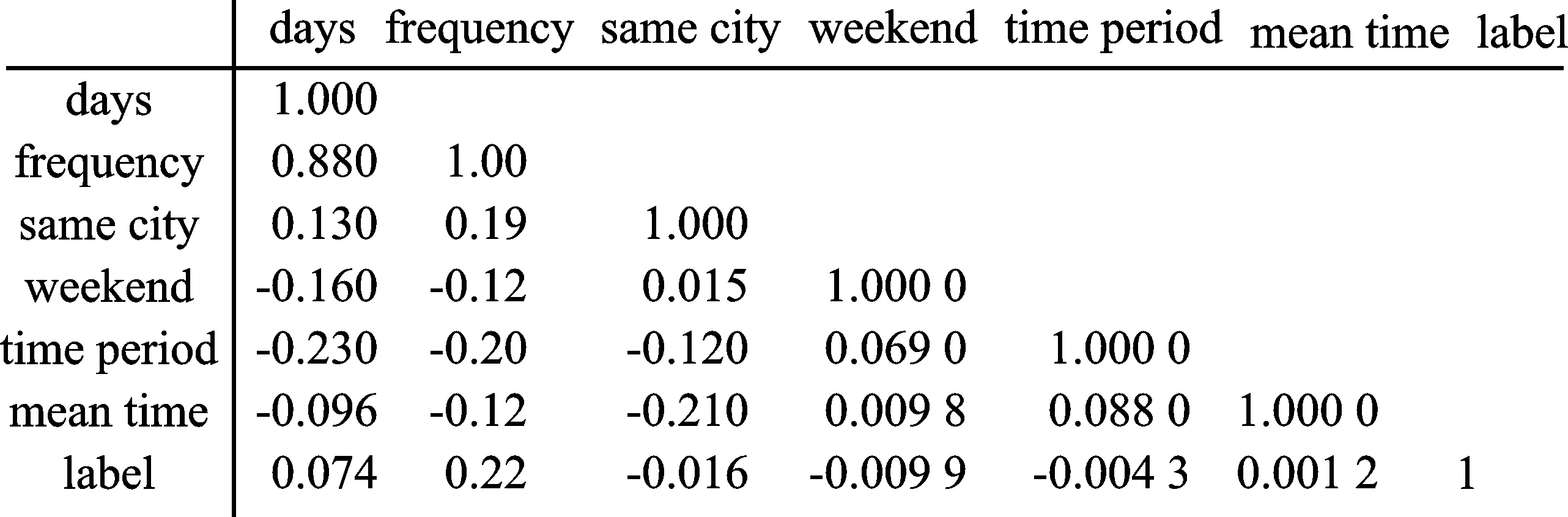
图3 相关系数Figure 3. Correlation coefficient
2.3 实验过程
由于数据集为不平衡数据集,即检测合法营运车辆样本量远大于非法营运车辆样本量,因此对于各类别样本数量不一致数据,决策树算法本身的信息增益偏向于具有更多数值的特征,即预测变量类不平衡较易影响决策树模型,故需要对数据集检测结果特征进行数据平衡操作。常用的数据平衡方式有欠采样(对多数类)、过采样(对稀有类)。其中,使用较多的过采样方法有自助法、SMOTE(Synthetic Minority Oversampling Technique)算法(创建与稀有类相似的合成数据)。由于对多数类做欠采样存在丢弃有用信息的风险,本文采用SMOTE算法对训练集稀有类进行过采样,即对非法营运车辆样本集进行过采样。利用SMOTE算法找出与过采样记录相似的记录,对原始记录及其相邻的记录随机加权后取平均,生成合成记录。本文共有52条非法营运车辆样本,随机筛选100条合法营运车辆样本数据,经过SMOTE算法采样后组成1∶1比例的样本子集各100条数据,并且设置80%的训练集和20%的测试集。
2.4 实验结果
实验使用Jupyter Notebook编辑器建立随机森林模型、CART分类树模型和二元逻辑回归模型,在经过SMOTE算法将样本均衡化后,每次随机选出100个合法营运车辆样本和100个非法营运车辆样本进行训练,经过10次训练得到最后的分类器(Random Forest Classifier,RFC)。随机森林模型、CART分类树模型和二元逻辑回归模型分类器评价指标及其结果如图4~图6所示。其中,模型分类器准确率由高到低依次为随机森林模型RFC、二元逻辑回归RFC和CART分类树模型RFC,准确率分别为0.987 5、0.985 0和0.982 5。CART分类树模型RFC的合法营运车辆召回率和非法营运车辆精确率与随机森林算法RFC的合法营运车辆召回率和非法营运车辆精确率相同,但其余模型的精准率、召回率和F1分数均比随机森林模型RFC的精准率、召回率和F1分数低,且准确率也低于随机森林模型RFC准确率。虽然二元逻辑回归RFC的合法营运车辆召回率和非法营运车辆精确率比随机森林模型RFC的合法营运车辆召回率和非法营运车辆精确率高,但其余指标均低于随机森林模型RFC,且其准确率为0.985 0,低于随机森林模型RFC准确率。

图4 随机森林模型分类器评价指标及结果Figure 4. Evaluation indicators and results of random forest model classifier
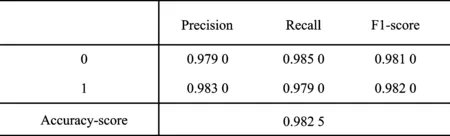
图5 CART分类树模型分类器评价指标及结果Figure 5. Evaluation indicators and results of CART classification tree model classifier
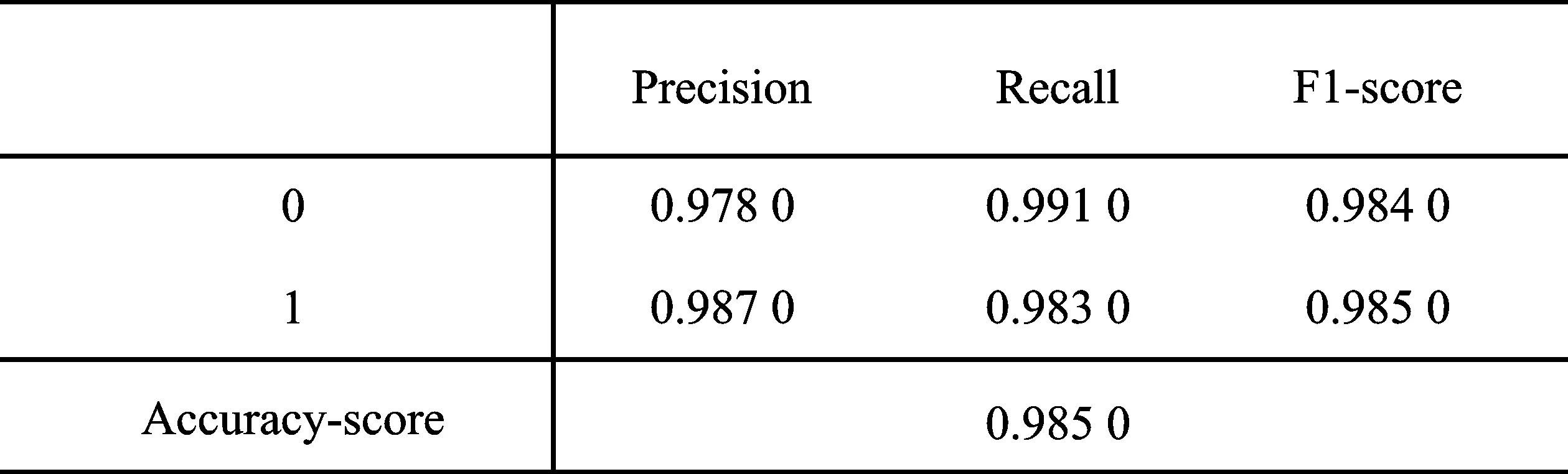
图6 二元逻辑回归分类器评价指标及结果Figure 6. Evaluation indicators and results of binary logic regression classifier
3 结束语
为了优化高速公路运行秩序,提升高速公路管理水平,有效稽查高速公路非法营运车辆,本文根据高速公路车辆流水数据建立识别非法营运车辆指标,并基于随机森林模型、CART分类树模型和二元逻辑回归模型建立识别非法营运车辆训练器。通过对西南某市2022年2月6日~2022年3月8日100万条高速公路ETC出口数据和7万余辆嫌疑车辆数据进行处理,提取有效字段和指标投入算法进行验证,所得分类器准确率由高到低依次为随机森林模型RFC、二元逻辑回归RFC和CART分类树模型RFC,准确率分别为98.75%、98.50%和98.25%。结果证明随机森林模型训练出的分类器可以较好地预测出非法营运车辆,其准确率最高。
