一种基于联邦优化算法的传染病风险评估模型的构建
2024-01-09拜亚萌刘云朋孟军霞
拜亚萌,刘云朋,孟军霞
(焦作大学信息工程学院,河南 焦作 454000)
传染病风险评估的基本原理是通过多时空节点触发与多学科渠道监测暴发流行情况、病因、风险、过程及驱动因素的多源数据构建运行敏感特异、分期度量的评估预警模型,从监测数据中发现、识别异常情况,预测大规模传染病爆发的概率[1],实现对突发性传染病的监测、预警及响应为一体的创新技术体系。
对传染病风险预警关键在于对系统性风险的综合评估,而系统性风险则是多维度数据的风险之和,如果系统性风险过高,超过设定的预警值,则自动触发报警机制,并辅助专业机构做出高效管理及精准研判[2]。本研究构建的传染病风险评估模型以共享数据平台获取的多源信息为基础,制定数据-资源-应用相融合的风险研判及决策模式,为智能化决策提供重要支撑。
1 基于复杂网络的风险评估模型的构建
为解决传染病疫情风险的动态性及不确定性,动态捕捉网络中的异常情况,以医疗类、社会类、病原类等三类信息为节点,以三者之间的相似性为边,设计了一种基于复杂网络的传染病风险评估预警模型,网络模型结构如图1所示。通过衡量多元数据之间的相关性,计算各节点和边的权重,构建基于复杂网络建模的风险评估算法,完成对突发公共事件系统性风险的评估预警。与传统的时空评估模型相比,复杂网络评估模型可从网络视角对确诊病例之间构建联系,从而对新发传染病传播进行精确预警。
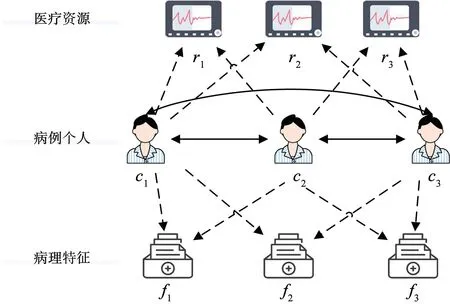
图1 传染病风险网络Fig.1 Infectious disease risk network
节点信息表示。医疗资源信息是指与医疗机构、医护人员等相关的资源信息,包括医院数量、床位数、医护人员数量等。在传染病疫情中,医疗资源信息的可用性及充足性是至关重要的,因此将医疗资源信息作为风险评估网络的第一个节点。病例个人信息是指与患者相关的个人身份信息,通过对病例个人信息(如职业、年龄、性别、所在地等)的收集及分析,了解疫情的传播范围及趋势,为制定应急预案提供依据,因此将病例个人信息作为风险评估网络的第二个节点。病理特征信息是指与疾病相关的生物学特征,包括病原体类型、病毒传播途径、患者感染程度等,通过对病理特征信息的收集及分析,了解疾病的严重程度及发展趋势,为制定应急预案提供依据,因此将病理特征信息作为风险评估网络的第三个节点。
边的表示。相似边分为实线和虚线两种类型,其中病例之间产生的相关联系用实线表示,病例与医疗资源、病例与病理特征之间产生的相关联系用虚线表示。其中,实线的相似边主要包括个人特征之间、病例与医疗资源、病例与病理特征的相似度,虚线的相似边主要包括不同患者的病理特征与历史传染病所体现的病理特征之间的风险系数相似度,其中患者病理特征主要包括所使用的医疗资源、所在地区等相关信息。以图1的网络为例,病例个人信息表示为c1、c2、c3,病例个人所表现出的病理特征分别为f1、f2、f3,共同使用的医疗资源分别为r1、r2、r3。
节点权重计算。定义医疗资源集合R={r1,r2,…,rn}、病例集合C={c1,c2,…,cn}、病例特征集合F={f1,f2,…,fn}。设定病例患者ci具有f1、f3两个病理特征,则定义其病理特征集合为Fci={1,0,1,0,…,0},其与历史数据中传染病病理特征之间的相似性为ωfi。设定病例患者ci在治疗过程中使用了r1、r2两种医疗资源,则定义其医疗资源集合为Rci={1,1,0,0,…,0},权重为其与传染病的相关度及占据率的乘积ωri。通过上述定义得到病例患者ci的节点权重Dci=ρ·RciωR·FciωF,该节点权重为病例个体所使用的医疗资源风险和具有的病理特征系统风险,其中ρ为病例个体归一化处理后的风险系数。
边的权重计算。边的权重表示不同病例患者之间个人特征之间的相似度,定义为Cij,由此可知,病例ci与病理特征fi之间的相似度定义为Fci·iωfi,病例ci与医疗资源ri之间的相似度定义为Rci·iriωri。
相似性计算。在构建风险评估网络后,需对每个节点之间的相似性进行计算。使用皮尔逊相关系数方法来计算不同节点之间的相似性指数,根据相似性指数的大小确定每个节点之间的关联程度,并将其作为边的权重。系统整体相似度定义为Sij,即Sij=ρ·Cij·RciωR·FciωR。

在实际应用中,可将以上3个节点的信息输入到风险评估网络中,通过计算相似性指数和优化网络结构来预测传染病疫情的风险等级级传播路径。例如,如果某个地区的医疗资源信息与其他地区相比存在较大差异,该地区可能成为疫情爆发的重点区域;如果某个地区的病例个人信息与其他地区相比存在较大的共性,该地区可能成为疫情扩散的主要方向。通过这种方式可提前预测疫情的发展趋势及影响范围,及时采取相应的防控措施。
2 基于声誉区块链的联邦学习训练框架
2.1 训练框架
为保护患者数据的所有权和隐私权,降低数据泄露风险,采用分布式联邦学习框架(Federated Learning,以下简称FL)技术完成风险评估模型训练。FL是一种分布式机器学习框架,主要特点是确保用户隐私,在不共享原始数据的前提下通过参数交互完成协同训练,生成全局模型,可有效保护数据隐私[3]。基于FL的学习框架在无需交换原始隐私数据的前提下聚合训练数据,实现了全局模型训练,因此设计了一个基于区块链信誉值评估的联邦学习框架来训练风险评估模型,该训练框架包括基础设施层与区块链应用层,风险预警模型联邦学习训练框架。
2.1.1 基础设施层
基础设施层采用环状与星状混合的具有以太网拓扑结构的移动网络,该网络包括数据训练管理中心、数据使用者及多个医疗机构组成。其中,数据使用者包括医疗机构、政府机构、疾控中心、保险机构等相关实体部门,该移动网络包括了各类移动网络设备(如通信基站、路由器、无线AP点等)。
移动网络设备利用本地数据训练本地数据模型,通过在本地进行数据训练,充分利用本地资源,实现实时、高效的模型训练及推理。本地数据训练具有一定的隐私保护优势,因为敏感数据可在本地设备上进行处理,不必传输到云端或其他地方。本地训练还可降低网络延迟及数据传输量,节省通信资源及能耗。
端节点主要指处于移动网络边缘的各类基础通信设备,存储海量的患者数据,包括个人隐私数据,这类数据会上传至中心服务器,不仅降低了患者隐私数据的泄露风险,也实现了海量医疗数据的分布式存储,有效降低了中心式存储压力。充分利用FL计算框架的特点,端节点仅需为本地风险评估模型提供训练数据及测试数据,通过下载、计算、迭代、上传全局参数,即可完成对风险评估模型的学习优化。
边节点主要完成端节点与数据训练管理中心之间的数据传输及访问控制,边节点网络设备具有较强的计算能力及通信能力,可实现分布训练任务、传输模型参数等功能,还要针对不同的任务需求完成符合条件的端节点筛选及训练监督功能。在本训练框架中,边节点被设计用于完成上述任务,在联邦学习任务中,首要任务是完成通信中继,为端节点和管理中心提供稳定的传输信道,训练管理中心充当中央聚合器,聚合本地模型以形成全局模型,与参与节点相互传输模型参数,以更新全局评估模型。边节点负责端节点筛选,接收管理中心发布的任务,利用其内置智能合约机制选择满足条件的端节点,接收端节点训练后的模型参数,通过聚合计算后更新全局模型,通知端节点下载更新优化后的模型参数。
2.1.2 区块链应用层
通过计算各个训练节点声誉值的方式完成对区块链各参与节点的选择、奖励、评估。由于区块链本身具有公开透明的天然技术特性,该层将节点的声誉值存储在声誉区块链的数据块中,即使发生纠纷或恶意破坏,存储在数据区块中的声誉值仍是永久且公开的证据。构建的区块链存储参与节点的综合声誉值包括数据请求者对于参与医院的直接声誉意见和其他数据请求者的间接声誉意见之和,通过区块链账本交易及综合声誉值评估实现了对积极贡献的参与节点进行激励。通过区块链技术,声誉值可被安全地存储及验证,能充分奖励那些积极参与联邦学习的医院,从而构建一个可信、公正的基于区块链声誉值评估的联邦学习生态系统。
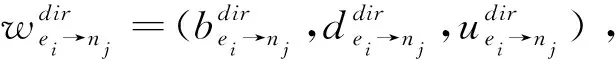
(1)
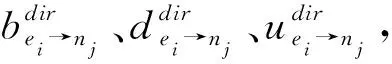
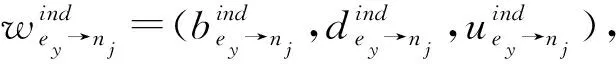
(2)
其中,E是其他数据请求者的集合,ky表示其他数据请求者间接声誉值的权重因子,权重因子计算公式如式(3)所示:
(3)
综合声誉值。为保证训练网络的公平性,防止恶意数据请求者的破坏,将为数据请求者提供最终的声誉值,综合声誉值计算公式如式(4)所示:
(4)
边缘节点ei对医院nj的最终声誉综合值计算如式(5)所示:
(5)
对候选医院的综合声誉值进行计算比较,边缘节点ei可选择声誉值较高的候选医院作为模型训练的矿工节点,将计算后的综合声誉值上传到区块链,为其他边缘节点或其他数据使用者选择使用。
2.2 具体步骤
设计的基于区块链信誉值评估的联邦学习框架在不交换各自隐私数据的前提下通过链下聚合学习方式共享数据模型,不同参与节点计算本地风险评估模型后上传到区块链,共同训练得到统一共享的风险评估全局模型,通过数据管理中心统一调度,对训练模型全局参数实现迭代,从而完成风险评估预警模型的优化学习。基于声誉区块链的联邦学习过程步骤如下:
步骤1:任务发布和合约创建。各类数据使用者利用智能合约机制创建合约条款,内容包括数据大小、数据类型、最低声誉值要求、任务截止时间、奖励情况等。利用合约内置cycles机制,将请求任务上传至指定范围内的边缘节点。边缘节点接收到任务发布请求后,解析合约内容,并将满足条件的矿工节点发布合约内容。矿工节点接收到计算任务后,通过本地模型进行计算任务,将是否参与任务情况进行反馈。
步骤2:核对声誉值和上传核对结果。边缘节点收到参与反馈后,对参与任务的候选矿工节点进行监督,使用双重主观逻辑模型对矿工节点的计算能力进行评估,结合已交互边缘节点的意见,对参与节点的间接声誉值进行评估,若其值与区块中存储的声誉值一致,则将完成任务后的奖励上传至联盟链区块,更新参与节点的综合声誉值,为下一次评估参与节点的间接声誉意见提供参考。
步骤3:选择候选医院并执行联邦学习任务。数据使用者接收到边缘节点返回的计算任务后,结合合约要求及资源信息,选择合适的医院子集来执行联邦学习算法,并对本次任务的参与节点进行质量评估,为边缘节点后续选择候选矿工节点提供意见,确保局部数据模型的评估精确度及数据质量。
3 实验分析
仿真实验采用TensorFlow 1.10.0软件完成对基于声誉区块链的联邦学习框架的性能评估,对比方案分别是基于Fedavg算法的联邦学习方案[4]、基于FedProx算法的联邦学习方案[5]。选用MNIST数字分类数据集,其中选取5000个训练实例作为训练集,选取1000个测试实例作为测试集。
采用基于声誉值的联邦学习方案,图2描述了不同的医院声誉值评分机制变化情况,分别对3种不同的声誉评分方案进行比较,即本研究提出的声誉值方案,基于提供服务节点不确定性的声誉值方案1,基于任务发布者相似性的声誉值方案2。从图2可知,前6次训练迭代过程中,所有参与节点表现良好,参与医院均获得较高的声誉值,无法甄别出恶意节点。在后续的8次训练过程中,由于恶意节点的不当行为,所有方案的声誉值均出现下降趋势,本研究所提方案下降趋势最为明显。在最后的6次训练过程中,3种方案的整体声誉值又随之增加,但包含有恶意节点的方案1和方案2增加幅度要明显高于本方案,表明本方案可提供更为稳定的声誉变化机制。从最后6次交互训练中可知,虽然恶意节点参与训练,但对本方案的声誉值评分影响不明显,但方案1和方案2的平均声誉值仍处于较高值,无法在短时间内检测出恶意节点的存在,由此可知本研究所提模型方案在风险评估性能上相对更好。

图2 不同声誉值评分机制的比较Fig.2 Comparison of different reputation scoring mechanisms
4 结论
以复杂网络理论为基础,从网络视角对确诊病例之间构建联系,设计了基于复杂网络的传染病风险评估模型,对新发传染病疫情进行风险监测预警。设计了基于声誉区块链的联邦学习框架,在确保隐私数据不泄露的情况下提高联邦学习算法的效率及信息计算的时效性,进一步提高了风险评估模型的精确度。提出的风险评估模型通过复杂网络建模及智能合约机制,脱离依赖静态历史数据或经验案例的被动预案方式,达到了降低强中心化管理带来的责任风险,完善了传染病预测理论体系,有效提升了预警管理效率。
