缺血性卒中患者院内复发风险预测模型开发与验证研究
2024-01-09陈思玎姜英玉王春娟杨昕李子孝姜勇王拥军谷鸿秋
陈思玎,姜英玉,王春娟,杨昕,李子孝,姜勇,3,王拥军,4,5,谷鸿秋,
目的 开发基于机器学习算法的缺血性卒中患者院内复发风险的预测模型,并进行外部验证,为相关研究提供借鉴。
方法 开发队列为中国卒中联盟(China Stroke Center Alliance,CSCA)研究队列,将此队列中的缺血性卒中患者按照8∶2随机划分为训练集和内部验证集。验证队列为第3次中国国家卒中登记(the third China national stroke registry,CNSR-Ⅲ)研究队列。基于指南、文献回顾,确定备选预测因子,然后采用拉索(least absolute shrinkage and selection operator,LASSO)回归进行筛选。基于logistic回归模型以及机器学习算法[随机森林模型、极端梯度提升(extreme gradient boosting,XGBoost)、轻量级梯度提升机器学习(light gradient boosting machine,LightGBM)模型]开发缺血性卒中患者院内复发风险预测模型。评价模型区分度(C统计量)和校准度(Brier得分)两方面的指标。
结果 CSCA研究队列共纳入1 587 779例缺血性卒中患者,其中院内复发99 085例(6.2%)。CNSR-Ⅲ研究队列共纳入14 146例缺血性卒中患者,其中院内复发623例(4.4%)。LASSO回归选择出年龄、性别、卒中病史、高血压、糖尿病、脂质代谢紊乱、心房颤动、心力衰竭、冠心病、周围血管病、LDL-C、空腹血糖、血清肌 以及院内抗栓治疗作为缺血性卒中院内复发的预测因子。内部验证中,各模型的区分度均在0.75左右,XGBoost模型的区分度(AUC 0.765,95%CI 0.759~0.770)略高于其他模型,各模型的Brier分数均在0.05左右。外部验证中,所有模型的预测效能均较低(AUC<0.60),各模型的Brier分数均<0.08。
结论 在预测因子数量和维度有限的情况下,logistic回归模型和机器学习算法预测缺血性卒中院内复发风险的效能均较低。未来需从预测因子和算法模型上做更多探索。
卒中是一种患病率、复发率、死亡率以及致残风险均较高的疾病。其中,缺血性卒中是最主要的类型,占卒中的80%以上[1-2]。缺血性卒中的预后相对不稳定,存在较高的复发风险,特别是在疾病早期[3-4]。利用复发风险预测模型,准确评估缺血性卒中患者早期复发的风险,实现患者的精准风险分层与精细管理,以进一步降低早期复发风险,对缺血性卒中的二级预防具有重要意义。本研究依托中国卒中联盟(China Stroke Center Alliance,CSCA)[1]和第3次中国国家卒中登记(the third china national stroke registry,CNSR-Ⅲ)研究队列[5],基于机器学习算法开发并验证缺血性卒中院内复发风险的预测模型,以期为后续更新、研发缺血性卒中二级预防精准工具提供借鉴。
1 对象与方法
1.1 研究队列及对象 开发队列为CSCA研究队列。CSCA是由中国卒中学会发起,国家卫生健康委员会神经系统疾病医疗质量控制中心指导的全国性、多中心、多方面干预、持续性的卒中医疗质量规范和改进项目[1,6]。本研究纳入分析的是CSCA项目2015年8月-2022年12月的数据。验证队列为CNSR-Ⅲ研究队列。CNSR-Ⅲ为全国范围内的前瞻性、多中心急性卒中登记研究,其数据库连续记录了2015年8月-2018年3月全国201家医院连续纳入的缺血性卒中或TIA患者资料[5]。本研究入组标准:①发病年龄≥18岁;②临床确诊为缺血性卒中;③发病7 d内就诊并住院治疗。排除院内复发结局缺失的患者。
1.2 预测因子与结局 参考国际缺血性卒中早期管理指南[7]、文献报道的相关预测模型[8],结合本研究的数据特点,确定备选预测因子,包括患者的人口学特征、卒中病史、伴随疾病、实验室检查指标、抗栓治疗5个方面共计19个变量。人口学特征包括性别、年龄;伴随疾病包括高血压、糖尿病、脂质代谢紊乱、心房颤动、心力衰竭、冠心病及周围血管病;实验室检查包括LDL-C、空腹血糖、糖化血红蛋白、INR值、Hcy、血清肌酐、血清尿素氮以及尿酸水平。本研究的结局变量是院内缺血性卒中复发事件。
1.3 缺失数据预处理 因本研究预测因子的数据缺失率均在10%以内,因此有缺失数据的连续变量均用中位数填补,分类变量用众数填补。
1.4 模型开发
1.4.1 特征选择 特征选择是在建立模型之前降低数据维度、减少输入预测因子数量并找到最重要的预测因子的过程。该步骤可以提高模型的可解释性和提高运算效率。本研究在训练集中利用拉索(least absolute shrinkage and selection operator,LASSO)回归进行特征选择,利用十折交叉验证方法选择Lambda的最优值[9]。
1.4.2 模型训练与验证 本研究将开发队列中符合入组标准的患者按照8∶2划分为训练集和内部验证集,利用logistic模型[10]、随机森林模型[11]、极端梯度提升(extreme gradient boosting,XGBoost)模型[12]、轻量级梯度提升机器学习(light gradient boosting machine,LightGBM)模型[13]在训练集中进行模型开发。将训练好的模型在内部验证集中进行验证和评估,并在独立的外部验证集(CNSR-Ⅲ)中进行外部验证。
随机森林模型:是一种集成学习模型,随机森林针对每一个决策树通过递归分裂数据,使得每个叶节点包含尽可能纯净的样本,从而形成一个深度较深的决策树。随机森林中的每个决策树都对新样本进行预测,最后通过投票(对于分类问题)或平均(对于回归问题)来确定最终的模型输出[11]。
XGBoost模型:属于集成学习的一种梯度提升算法。由梯度提升决策树模型发展而来,它不仅以提升的方式组合多个决策树,还可以进行二次泰勒展开。XGBoost引入了正则化项,包括L1和L2正则化,以控制模型的复杂性,防止过拟合[12]。
L i ghtGBM模型:是一种梯度提升框架,用于高效处理大规模数据和高维特征。LightGBM模型使用了基于直方图的学习方法,通过对连续特征进行离散化,减少了训练过程中的计算复杂度,提高了训练速度。此外,该模型采用按层生长的策略,在训练过程中可更加高效地选择最佳分裂点[13]。
1.5 统计学方法 连续变量用M(P25~P75)表示,分类变量以频数和率表示。比较不同模型对院内缺血性卒中复发的预测性能时,主要从区分度和校准度两个方面进行评价。采用ROC的AUC,即C统计量来评估区分度;采用Brier得分(0~1分)以及校准曲线图评估校准度。Brier得分越趋近0,模型的校准度越好[14]。最优模型的预测因子的重要性通过Shapley加法解释(shapley additive explanation,SHAP)值体现,通过SHAP图可视化预测因子的影响。
本研究利用Python 3.9.7软件train_test_split函数,按照8∶2的比例在开发队列中随机划分为训练集和内部验证集;利用GridSearch CV在训练集中进行十折交叉验证调参。所有统计和分析在SAS 9.4和Python 3.9.7中完成。
2 结果
2.1 一般资料 研究共纳入CSCA数据库1 601 207例缺血性卒中患者,排除院内复发结局缺失的患者13 428例,最终纳入1 587 779例缺血性卒中患者作为开发队列人群,其中院内复发99 085例(6.2%)。开发队列中位年龄67.0(58.0~75.0)岁,女性593 898例(37.4%),有卒中病史的523 364例(33.0%),伴随高血压1 188 036例(74.8%),伴随糖尿病439 563例(27.7%),伴随脂质代谢紊乱406 542例(25.6%)。外部验证队列共纳入CNSR-Ⅲ的15 166例患者,剔除1020例TIA患者,最终纳入14 146例缺血性卒中患者作为本研究的外部验证队列人群,其中院内复发623例(4.4%)。外部验证队列中位年龄63.0(54.0~70.0)岁,女性4426例(31.3%),有卒中病史的3369例(23.8%),伴随高血压10 932例(77.3%),伴随糖尿病4793例(33.9%),伴随脂质代谢紊乱6252例(44.2%)。开发队列中女性比例高于外部验证队列(37.4%vs.31.3%),卒中病史比例高于外部验证队列(33.0%vs.23.8%),院内抗栓治疗的比例低于外部验证队列(90.8%vs.97.8%)(表1)。
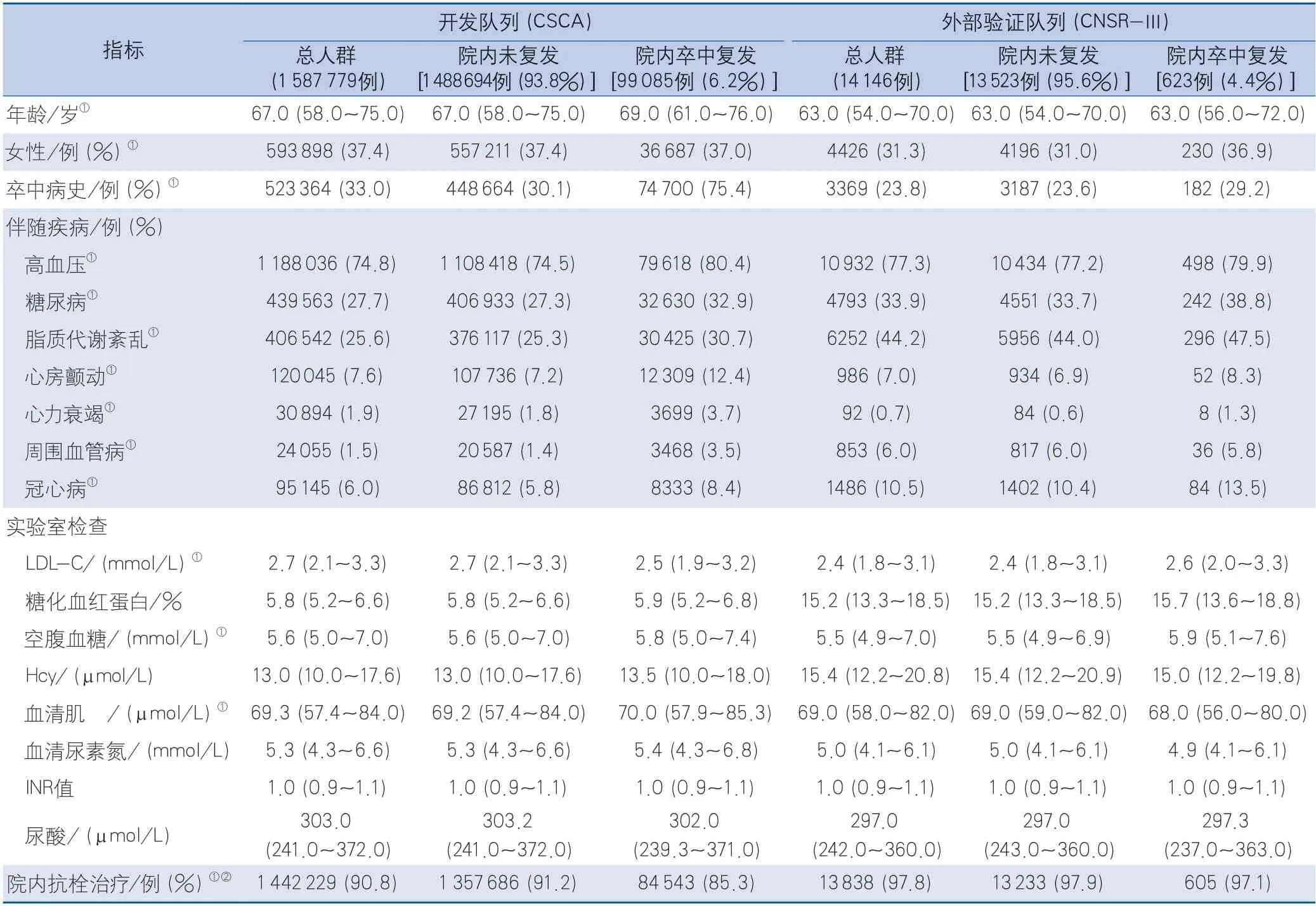
表1 开发队列与验证队列中缺血性卒中患者的基线特征Table 1 Baseline characteristics of ischemic stroke patients in the development and validation cohorts
2.2 特征选择结果及调参 在开发队列中按照80%的比例随机划分出训练集,特征选择利用十折交叉验证确定LASSO的Lambda等于0.001,在训练集中利用LASSO的方法选择了14个变量作为预测院内缺血性卒中复发的预测因子,分别是年龄、性别、卒中病史、高血压、糖尿病、脂质代谢紊乱、心房颤动、心力衰竭、冠心病、周围血管病、LDL-C、空腹血糖、血清肌酐和院内抗栓治疗。
2.3 模型建模与验证 在开发队列中的训练集中进行logistic、随机森林、XGBoost以及LightGBM模型建模,而后在测试集中进行内部验证。
在内部验证中,各模型的区分度差异较小,其中XGBoost模型的区分度略高(AUC0.765,95%CI0.759~0.770),其次是随机森林模型(AUC0.764,95%CI0.758~0.769)、LightGBM模型(AUC0.764,95%CI0.757~0.769)以及logistic模型(AUC0.749,95%CI0.741~0.758)(表2,图1)。

表2 机器学习算法和logistic模型预测缺血性卒中患者院内复发(内部验证和外部验证)Table 2 Machine learning algorithms and logistic model predictions of in-hospital recurrence in ischemic stroke patients (internal and external validation)
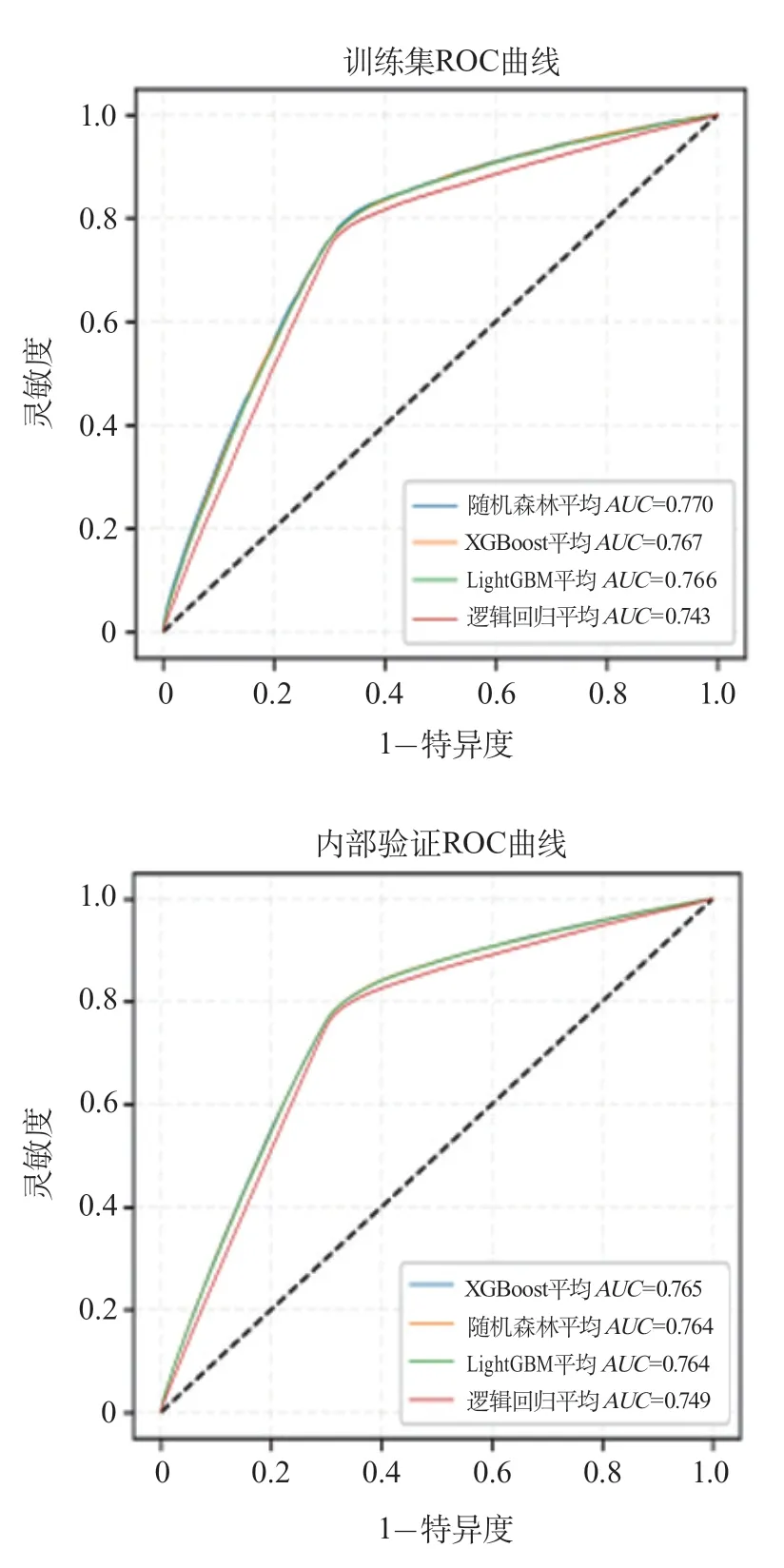
图1 机器学习算法和logistic模型在开发队列训练集和内部验证集中的ROC曲线Figure 1 ROC curves of machine learning algorithms and logistic model on the training and internal validation sets of the development cohort
在外部验证中,各模型的区分度均下降,其中随机森林模型的区分度略高(AUC0.565,95%CI0.529~0.598),其次是LightGBM模型(AUC0.551,95%CI0.484~0.617)、XGBoost模型(AUC0.546,95%CI0.477~0.607)以及logistic模型(AUC0.543,95%CI0.493~0.584)(表2)。
校准度方面,开发队列和验证队列的Brier分数都较好(0.05左右)。校准情况见图2和表2。在内部验证的XGBoost模型中,卒中病史、院内抗栓治疗、心房颤动是前3位强预测因子(图3)。
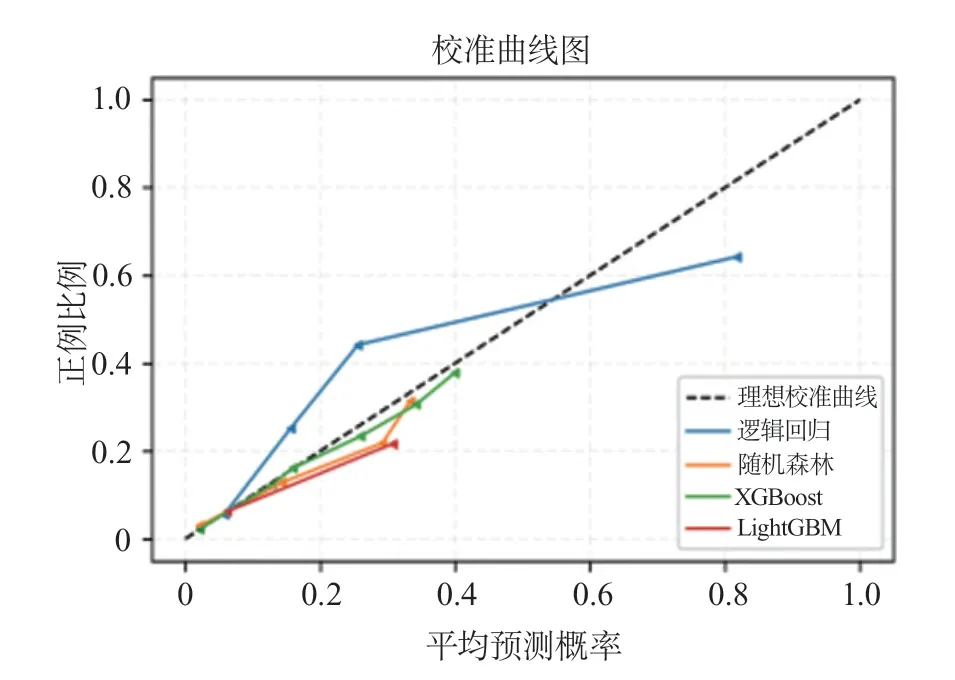
图2 机器学习算法和logistic模型在开发队列中的校准曲线图Figure 2 Calibration curves of machine learning algorithms and logistic model on the development cohort
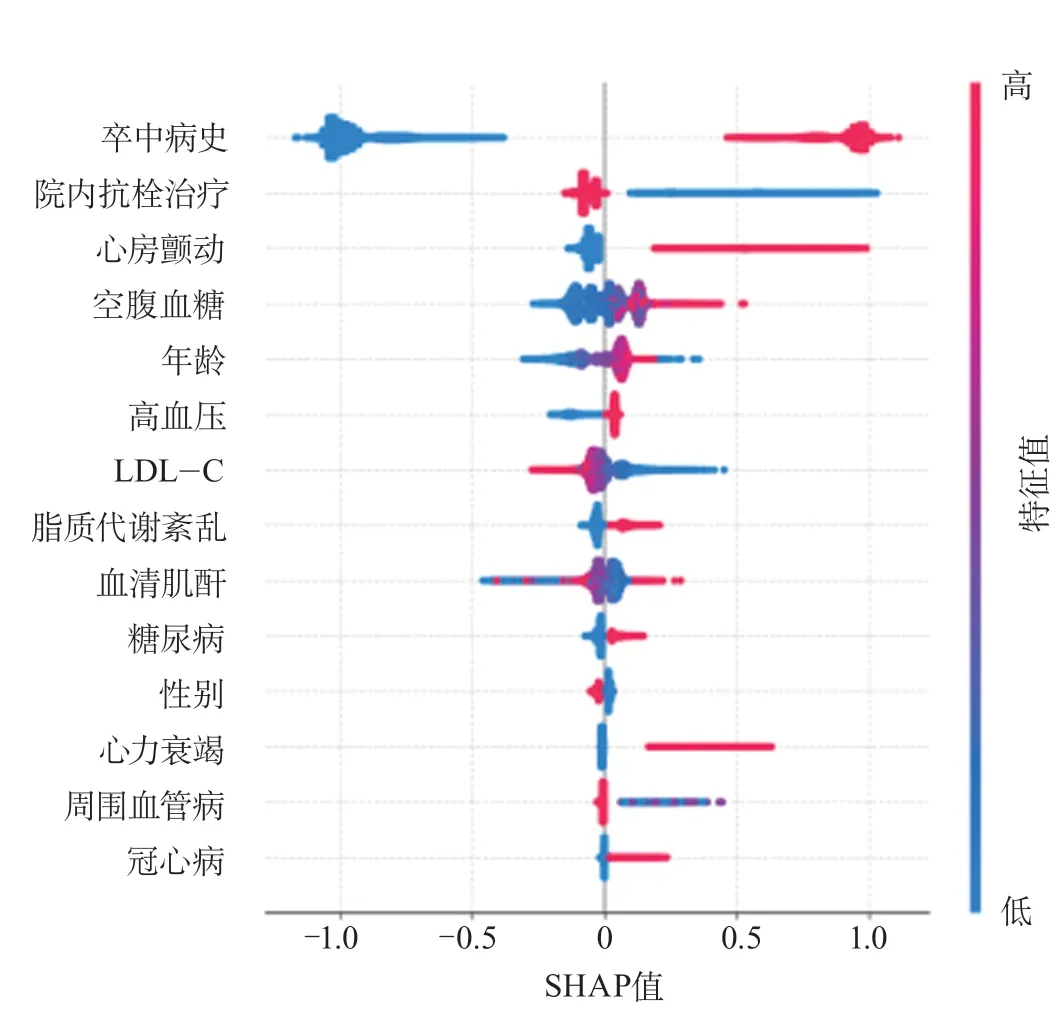
图3 XGBoost模型预测因子Shapley加法解释图Figure 3 Shapley additive explanations for predictive factors in the XGBoost model
基于logistic回归开发模型为:
其中Z是线性组合:Z=-1.390-0.184×性别+0.003×周围血管病-0.018×年龄-0.041×LDL-C-0.018×空腹血糖-0.002×血清肌酐+1.772×卒中病史-0.01×冠心病+0.117×高血压+0.256×糖尿病+0.157×脂质代谢紊乱+0.633×心房颤动+0.271×心力衰竭-0.781×院内抗栓治疗。
3 讨论
本研究基于百万卒中队列数据,利用logistic回归及机器学习算法构建了缺血性卒中患者院内复发风险的预测模型,并利用高质量的独立外部数据进行了外部验证。在特征选择方面采用知识驱动和数据驱动结合的方式进行候选因子选择,最终确定了14个预测因子,其中卒中病史、院内抗栓治疗、心房颤动是最优模型的前3位强预测因子。研究结果显示,在开发队列中,logistic模型和机器学习模型都有较好的预测性能(AUC>0.75),其中,在内部验证集中各算法差异很小,XGBoost模型表现略好于其他算法。但在外部验证中,logistic模型和各机器学习模型的预测性能均欠佳(AUC<0.6)。
本研究的开发队列CSCA和验证队列CNSR-Ⅲ数据本身存在一定的异质性。例如:开发队列的整体患者年龄、女性比例高于外部验证队列;外部验证队列的高血压、糖尿病、脂质代谢紊乱、心房颤动和心力衰竭患者比例高于开发队列。此外,CSCA和CNSR-Ⅲ纳入的均是发病7 d内的缺血性卒中患者,而卒中复发风险在第一周最高,且两个队列中患者的住院时长也有差异(中位数10 dvs.13 d);CNSR-Ⅲ中轻症患者的比例要高于CSCA,其本身的复发比例(4.4%)也低于开发队列(6.2%)。上述异质性因素均有可能影响卒中院内复发风险的预测效果,导致由开发队列训练并验证的模型在CNSR-Ⅲ外推时出现预测性能下降的情况。此外,本研究为了避免过拟合没有纳入重采样、调整权重等处理类别不平衡的技术,所以预测会存在偏向性问题[15],并没有将机器学习参数灵活的优势发挥出来,所以对比logistic模型性能提升有限。
XGBoost是陈天奇[12]等于2016年开发的机器学习算法,是兼具线性规模求解器和树学习的算法,近几年在疾病预测领域中应用广泛,如癌症患者化疗后死亡预测[16]、卒中后肺炎预测[17]、缺血性卒中患者不良预后预测[18-19]等。在本研究中,XGBoost在开发队列的内部验证集中表现略好,这可能与其对代价函数做了二阶泰勒展开,引入了一阶导数和二阶导数,同时代价函数引入正则化项,控制了模型的复杂度,有助于一定的模型稳定性有关。虽然与XGBoost一样,随机森林模型以及LightGBM模型的AUC均高于logistic模型但是改善并不多,这可能是由于机器学习的优势在于计算快、适合高维度数据以及处理非共线性等问题,本研究采用知识驱动的方式选择了19个变量,在进行了LASSO回归的降维后仅仅纳入了14个变量用来构建模型,为了避免开发队列中模型过拟合,建模也并未采用重采样等灵活调整的手段,所以并没有发挥出机器学习的优势。
与开发队列不同,外部验证中随机森林模型的AUC最高。随机森林模型相较于XGBoost模型不需要过多的超参数调整,由于随机特征选择和多个树的平均效果,随机森林模型相较于XGBoost模型天生具有一定的抗拟合能力,所以具有更好的鲁棒性。本研究的初衷是利用更少的临床变量来实现更好的预测效果,以方便外部验证和集成到临床决策支持系统中,为实际临床使用提供帮助。但预测模型的外推性一直是领域内存在的客观问题,由于开发数据和验证数据的分布不一致,模型泛化能力较差是客观存在的,如何提高预测模型在外部验证中的表现是开发预测模型时需要仔细考虑的内容,除了数据本身的一致性问题,还应注意避免过拟合的发生。使用带有正则化参数的模型,避免参数在训练集中过拟合,可以减少在开发队列中的过拟合现象。
既往文献中Vida Abedi等[20]利用机器学习算法建立预测卒中复发风险的长期预测模型,其研究结果显示1年预测AUC最高(0.79),5年预测AUC最低(0.69),与本研究开发队列的预测结果相似。此外,有研究者基于影像组学和生物标志物资料构建的COX回归预测模型来预测2年内缺血性卒中复发风险的AUC为0.8296[21],基于影响组学数据预测14 d TIA复发风险预测模型的AUC达到0.850(内部验证集)[22],其研究结果的C统计量高于本研究建立的预测模型,提示未来可进一步加入影像组学的变量来丰富数据维度,实现更精准的预测。不过,增加这些预测因子,在独立的外部队列中预测性能如何,应用性如何,还有待更进一步的研究。
开发临床预测模型,最终目的是服务于临床实践和应用。纳入更多数量和维度的预测因子,如各组学数据(基因组学、影像组学、蛋白组学、代谢组学等),采用更复杂的算法(如各种机器学习算法),能在一定程度上提升预测效果,但是如何平衡预测模型的开发、应用的成本和预测的效果及实际可应用性,是一个难题。随着数据收集、存储、分析技术的进步,成本的降低,未来从预测因子和算法模型上可以做更多探索,或许可以开发出成本可控、效应可接受、实际可应用的预测模型。
利益冲突本文所有作者均声明不存在利益冲突。
