基于大语言模型和知识图谱的数字孪生流域知识平台设计
2024-01-08李树元
李 巍,李树元
(1.水利部海河水利委员会,天津 300170;2.天津市龙网科技发展有限公司,天津 300170)
1 背景与意义
近年来,随着ChatGPT 在人工智能领域率先取得突破性的进展,基于大规模文本训练的生成式预训练(Generative Pre-Trained,GPT)模型在文本生成任务上表现出了强大的泛化能力,大语言模型(Large Language Model,LLM)已经成为人工智能领域的研究热点。目前,大语言模型已在文本生成、文本理解等多个领域取得了显著成就,在语音识别、图像描述生成等跨模态任务中也展现出强大的潜力,已在情感分析、问答系统、文本分类、智能客服、机器翻译等方面得到了广泛应用。GPT模型在专业领域也取得了进展,医疗、金融、电力等行业相继研发了领域大语言模型[1-3],但在水利行业尚未见比较成熟的应用案例。
数字孪生流域作为智慧水利发展的重要方向,近年来备受关注。建设数字孪生流域是提升国家水安全保障能力的重要支撑,水利部明确了提升流域设施数字化、网络化、智能化水平的目标,提出加快建设数字孪生流域,构建智慧水利体系,推动新阶段水利高质量发展[4-6]。水利部发布了数字孪生流域技术导则,部署了一系列先行先试项目。数字孪生永定河系统是水利部部署的先行先试任务之一,是数字孪生海河的重要组成部分,系统建设内容包括感知体系、数据底板、模型平台、知识平台、水利业务应用等。知识平台作为数字孪生流域的重要组成部分,在推进数字孪生流域建设中发挥着关键作用。
知识平台的通用构建技术路线是基于知识图谱,通过梳理水利业务对象及其相互关系,搭建知识图谱库,并用于具体的水利业务应用。如何将新一代人工智能技术应用于水利行业,基于大语言模型搭建水利知识平台,在数字孪生流域建设中发挥支撑作用,是一个比较前沿的研究方向。本文以数字孪生永定河系统为基础,基于海量的业务数据、图书文献、期刊论文和行业资料,构建数字孪生永定河知识库。以知识库为基础,训练大语言模型,创建水利对象、预报方案、调度预案、历史场景等知识图谱。基于大语言模型、知识图谱和向量数据库,实现知识检索和智能问答,以及水利对象信息智能检索、历史场景复演、防洪预案和生态调度方案智能匹配等水利业务智能应用。
2 系统设计
2.1 总体架构
数字孪生永定河系统知识平台基于数字孪生流域总体技术架构,汇聚关系型数据库、方案预案、标准规范、科研文献、图书档案、项目资料等结构化、半结构化和非结构化数据,通过知识抽取、知识融合、文本分割、知识向量化、知识存储等环节,构建知识库;基于语料库训练大语言模型,构建规则引擎和知识图谱计算引擎,共同组成知识引擎;在知识库和知识引擎基础上,开发知识应用程序,包括文档搜索、智能问答、图谱检索、知识统计等基础知识应用,以及水利对象关联、业务规则匹配、历史场景复演、实时调度方案编制等专题知识应用。知识平台总体架构,如图1所示。

图1 知识平台架构
2.2 知识库建设
知识库是数字孪生永定河流域知识平台的核心组成部分。知识库存储了关于流域的各类信息和知识,包括但不限于流域的自然地理、水文气象、水资源开发利用、预报调度预案方案等信息。知识库不仅可以提供知识检索,同时可为大语言模型和知识图谱提供丰富的语料库和实体关系提取素材,为知识应用提供全面和准确的知识支撑。
知识库的构建步骤包括数据收集、筛选、整合与分割、结构化数据格式转换、数据清洗和标准化等预处理、文本预处理、数据标注、知识抽取、知识建模、知识融合、知识向量化与存储、知识质量评估、知识验证与完善、知识更新与维护等。通过知识抽取和格式转换,构建基础知识库和主题知识库,基础知识库由文档库、语料库、向量数据库和知识图谱库组成;在此基础上,根据业务场景可构建主题知识库,包括水利对象关系知识库、预案知识库、历史场景知识库、专家经验知识库、专题图谱知识库等。
2.3 知识引擎构建
数字孪生永定河流域知识引擎由大语言模型、规则引擎和知识图谱计算引擎构成。
大语言模型提供了自然语言解析引擎和知识推理引擎,其训练包括模型预训练、Tokenizer 训练、指令微调、奖励模型和强化学习等环节。本项目基于中文分词器,采用开源的互联网新闻数据集、百科类数据集、社区问答数据集、翻译语料库,以及通过图书文献等资料自主构建的水利行业基础数据集和永定河专题数据集等,作为文本预训练数据集和指令数据集,对模型进行预训练和精调。
规则引擎实现将业务规则和应用程序代码的分离,将业务规则集中管理,实现动态修改业务规则快速响应需求变化,提高了系统的灵活性和可维护性。本系统采用Drools 作为规则引擎,提供规则编辑器、规则执行引擎等一系列工具,构建水利业务规则库。
知识图谱计算引擎用于处理大规模的知识图谱数据,并提供分析和应用服务,其主要功能包括知识图谱的构建、存储、查询、推理和更新。本系统采用基于Neo4j 图数据库和图查询语言Cypher、图算法库构建知识图谱计算引擎。
2.4 智能业务应用
在通用的文档搜索、智能问答、图谱检索、知识统计的基础上,设计开发丰富的水利业务专题应用,将丰富的知识运用到防汛预报调度、水资源管理、水环境保护等业务场景中。
(1)智能问答。基于大语言模型和知识图谱的深度融合,采用知识向量化检索召回模式,研发数字孪生永定河智能问答机器人。该智能问答机器人既能回答关于永定河流域的基础性知识,如官厅水库基本情况介绍、官厅水库的总库容等,也能回答官厅水库的预计来水量之类的预测类的问题。智能问答系统界面,如图2所示。
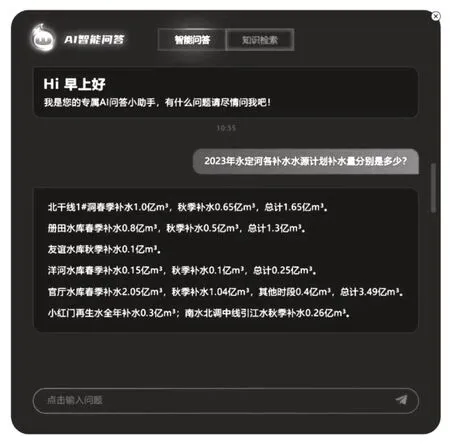
图2 智能问答系统界面
(2)水利对象关联查询。实体对象包括江河湖泊、水利工程以及水利对象的治理管理活动等,通过对这些水利实体和概念的关联关系进行查询检索,可为水利知识的融合提供基础。用户可以方便地查询到各种水利对象之间的关联关系,以及与之相关的属性、特征等信息。例如,查询官厅水库关联的河流、行政区、水文站、视频监控点、电站等。
(3)业务规则智能匹配。业务规则包括防洪工程调度规则、生态水量调度规则和工程运行管理规则等,提取流域内的水利工程、来水边界、控制对象等节点,分析各节点的来水情况、控制对象、启用条件、运行方式等要素,将调度规则方案逻辑化、知识化、关联化。例如,在知识平台中可查询永定河生态补水的调度目标、各个补水水源之间的关系和各自的输水计划以及详细的数据,也可查询图谱中各节点对应的具体数据。
(4)历史场景复演。收集整理永定河历史上发生的Ⅰ级洪水、Ⅱ级洪水和一般洪水资料,如1737、1780、1801、1819……1956、1963、2012、2023 年等。对历年的典型洪水进行复盘推演并提取知识图谱,包括历史洪水场景的核心过程、暴雨洪水特征和主要应对措施等。基于历史场景知识库,可为同类暴雨洪水事件的预报调度提供决策参考。
(5)实时调度方案编制。基于知识库、水利专业模型算法引擎、规则引擎以及大语言模型,让计算机学习永定河流域内的防洪调度预案、动态洪水风险图、流域水工程联合调度方案等预案方案知识,分析和总结历史调度方案和调度结果与成效,推荐水工程联合实时调度最优方案,将推荐的调度方案同步在三维可视化平台进行实时复演呈现。同时,可自动生成调度令,调用办公自动化流程辅助下达调度令。
3 核心技术分析
3.1 大语言模型预训练与精调
永定河数字孪生大语言模型有别于ChatGPT 这类通用大语言模型,是典型的领域专业大语言模型。当前主流的大语言模型均选择基于Transformer 架构的深度神经网络模型作为主体结构,有别于传统的RNN 之类的神经网络模型,Transformer 具有多头自注意力机制和高效并行计算能力,并能有效捕获不同维度词之间的关联程度,能够高效处理大规模文本数据。
数字孪生永定河大语言模型采用“无监督预训练”+“有监督下游任务精调”模式,首先基于大规模文本数据训练一个具备通用语义表达能力的大语言模型,然后使用高精度的水利行业和永定河流域的标注数据进行精细微调优化,以适配水利业务应用的精准需求。训练过程中采用数据并行和模型并行等分布式训练技术,将模型训练任务分散到多个GPU计算节点上并行执行,从而显著提升训练效率。
3.2 知识图谱与大语言模型深度融合
知识图谱是一种结构化的语义知识库,能够准确表达实体及其相互关系。但知识图谱的构建过程耗时费力,语言理解和文本生成是知识图谱应用中的技术难点。而大语言模型在语义理解和文本生成方面表现优异,但模型训练和推理成本较高,同时存在幻觉、解释性差、无法实时更新等问题。将两者深度融合则可实现优势互补,大语言模型补足了知识图谱的语义理解能力,知识图谱补足了大语言模型的知识准确度。两者的深度结合可提供精准、可控、可靠的知识处理方案,可胜任更加复杂和准确度要求更高的任务。
本系统基于知识图谱与大语言模型深度融合,通过调用大语言模型的接口服务,实现知识图谱从创建到应用以及更新全生命周期各环节的效率和质量提升。在知识图谱构建和更新环节,通过大语言模型从文本中提取实体及关系;在知识应用阶段,通过大语言模型来表达知识图谱中的知识。同时,通过知识图谱增强大语言模型的训练和应用环节,利用知识图谱作为评估数据集,优化模型预训练和微调。在推理阶段,将知识图谱接入大语言模型,为大语言模型提供准确的知识源,提升大语言模型的推理结果的可靠性。
3.3 知识向量化与知识检索增强生成
知识向量化是一种将知识转化为高维向量的技术体系,其核心技术包括词向量表示、知识图谱嵌入和文档向量表示等,可实现将词、知识图谱以及文档转换为高维向量。为了进一步提升知识检索和问答的准确性,本系统基于大语言模型(LLM)+知识召回(Knowledge Retrieval)的知识检索增强生成(Retrieval-Augmented Generation,RAG)模式,将永定河流域文档资料和知识图谱进行切片和向量化处理,基于向量检索实现知识召回,将召回的知识作为上下文提供给大语言模型进行归纳总结,然后以对话形式与用户交互,从而提升生成结果的可解释性、可控性和可更新性。具体技术路线,如图3所示。
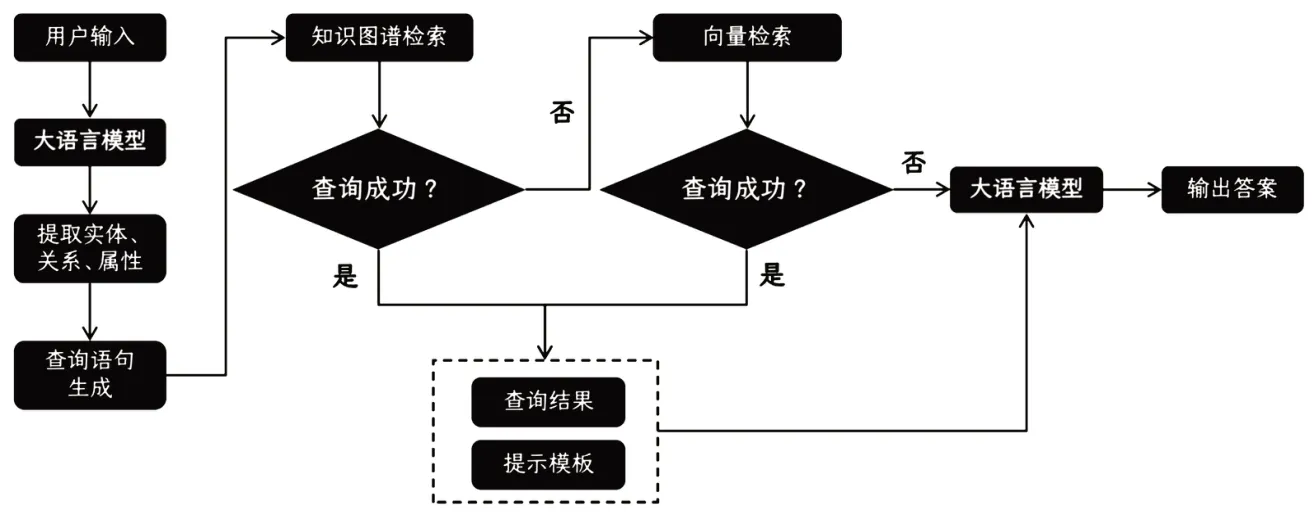
图3 知识检索增强生成技术路线
4 总结与展望
本文以数字孪生永定河系统已有数据为基础,设计了数字孪生永定河流域知识平台,主要建设内容包括知识库、知识图谱、大语言模型、智能业务应用等。其中,知识库的建设是基础,知识库的规模和质量决定了知识图谱和大语言模型的能力以及知识应用的成效;知识引擎是核心,其中大语言模型提供了强大的自然语言解析、语义理解和知识推理能力,知识图谱和业务规则引擎提供精准的知识查询检索和规则匹配能力,两者的深度融合即基于大语言模型和知识图谱的知识检索增强生成技术是提升知识应用质量的基石;知识应用是关键,只有将知识应用于具体的业务场景中,才能对业务起到支撑作用。
大语言模型的训练、知识图谱的构建以及智能问答的算法实现是知识平台建设的技术难点,大语言模型的训练算法正在快速更新迭代演化,可不断更新训练算法,训练出高度匹配永定河流域管理业务的大语言模型。基于大语言模型和知识图谱的知识检索增强生成技术的智能问答应用也能实现更加精准的信息匹配和更高质量的结果生成。
