四次样条插值的改进Fast-ICA算法
2024-01-08郭松林丘斯帆
郭松林, 丘斯帆
(黑龙江科技大学 电气与控制工程学院, 哈尔滨 150022)
0 引 言
现有的信号处理技术有很多,Fast-ICA是其中一种常用的信号处理技术,用于从混合信号中分离出独立成分[1]。独立成分是指在统计上相互独立的信号,这些信号可以描述原始信号中的特征,如声音信号和图像信号等,其在分离非高斯信号方面具有很好的性能[2]。Fast-ICA算法在信号处理、图像处理、生物医学、金融等领域中有广泛的应用[3],是当前独立成分分析领域的研究热点之一。然而,Fast-ICA算法中存在一些问题,如收敛速度慢、分离精度不高等[4],这些问题限制了该算法在实际应用中的表现。
为此,笔者改进Fast-ICA算法,在原算法的基础上,通过在Fast-ICA算法与原函数之间的误差进行四次样条插值,提高算法的精度,通过理论分析和实验验证,将探讨改进算法的性能和优越性,为实际应用提供了更为可靠的解决方案。
1 盲源分离算法
1.1 盲源分离的基本原理
现有三个不同物理源发出的信号s1(t)、s2(t)、s3(t),分布在不同位置的三个传感器所测得的信号为x1(t)、x2(t)、x3(t),每个传感器所获得的信号应是每个源信号的加权和,即
x1(t)=a11s1(t)+a12s2(t)+a13s3(t),
x2(t)=a21s1(t)+a22s2(t)+a23s3(t),
x3(t)=a31s1(t)+a32s2(t)+a33s3(t)。
盲源分离模型[5]可以描述为
x(t)=As(t),
式中:x(t)=[x1(t),x2(t),…,xm(t)]T——m维观察列向量;
s(t)=[s1(t),s2(t),…,sn(t)]T——n维源信号;
A——一个随机且未知的混合矩阵。
盲源分离的一般过程[6]如图1所示。
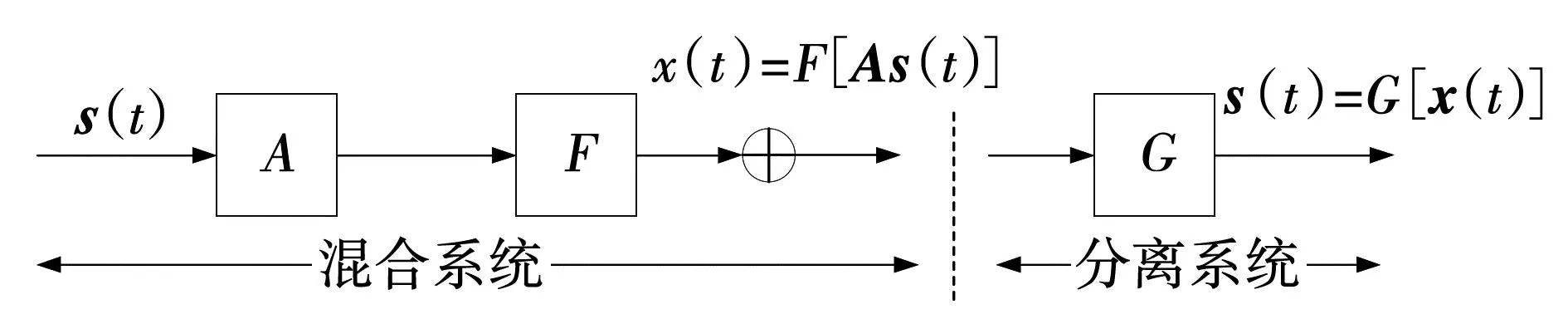
图1 盲源分离过程
从图1可以看出,盲源分离首先通过混合矩阵A得到观测信号x(t),接着寻求非线性映射G,以此达到将源信号分离的效果。
1.2 Fast-ICA算法
Fast-ICA算法也称为固定点算法,其中最常见的形式有采用四阶累积量和基于负熵的固定点算法,由于负熵作为Gauss性度量更能发挥其优越性,因此,应用负熵的Fast-ICA算法覆盖面更广[7]。
当负熵是判据时,
J(yi)∝{E[F(yi)]-E[F(v)]}2,
将J(yi)对ui求导,
式中:F(yi)——目标函数的非线性函数;
f(yi)——其一阶导数。
当稳态时,Δui=0,因此可以得Fast-ICA算法的两步算式为
(1)
经过多次实验分析,该算法在收敛性上存在一定缺陷,采用牛顿迭代算法,将式(1)的第一个式子等效为
(2)
求式(2)的根,应用牛顿迭代法求解得:
则
经过代数简化后可以得:
2 改进Fast-ICA算法
2.1 四阶牛顿迭代法
常见的求解方程f(x)=0方法有牛顿迭代法[8],其迭代公式为
文献[9]提出了一种四阶牛顿迭代法,形式为
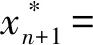
则可推得,Fast-ICA算法公式为
文献[9]对上述算法进行了详细的收敛性证明,算法的误差方程为
2.2 四次样条插值
常见的插值方法有牛顿插值、拉格朗日插值及样条插值[10],文中基于三次样条插值,构造出四次样条插值函数。
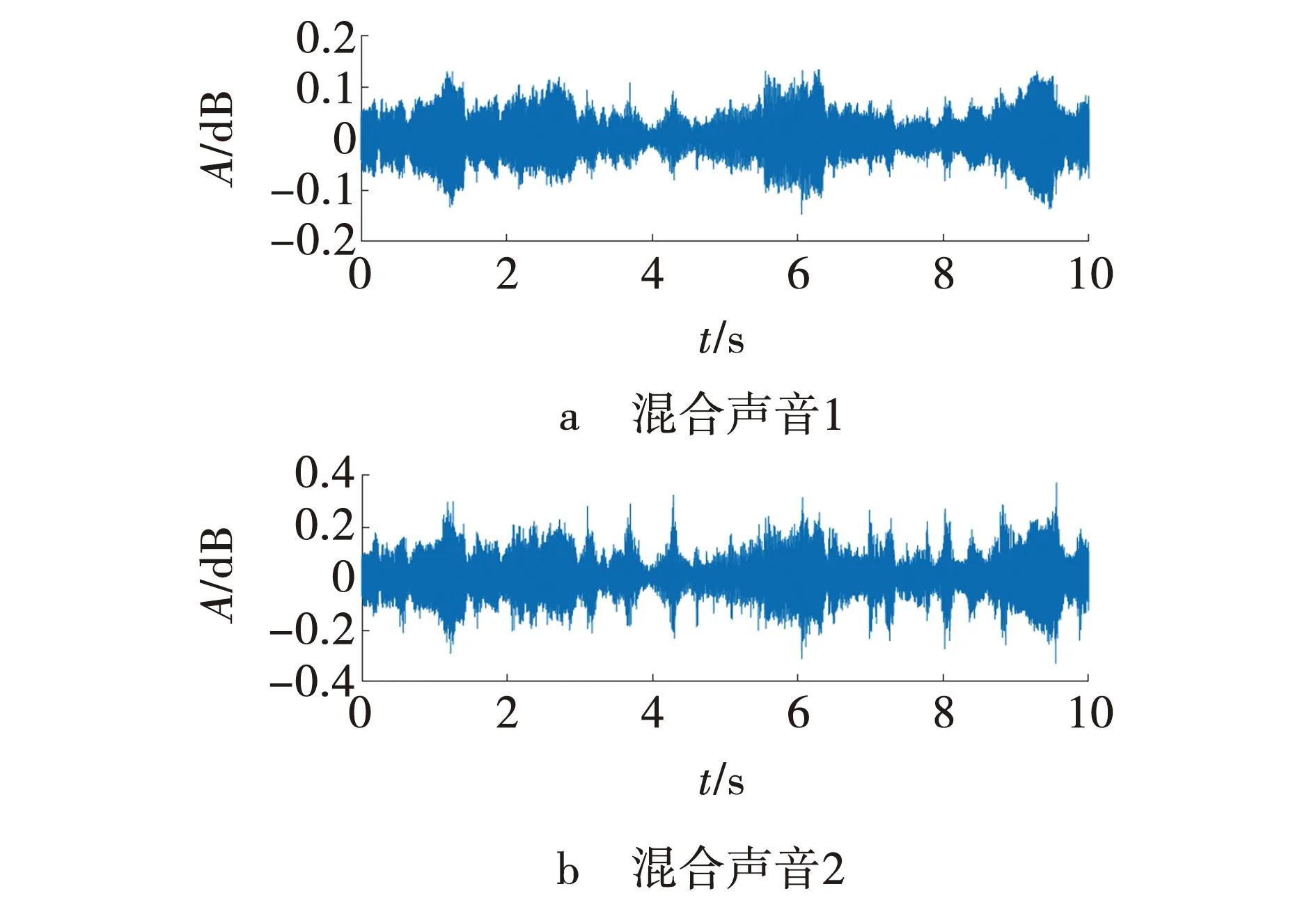
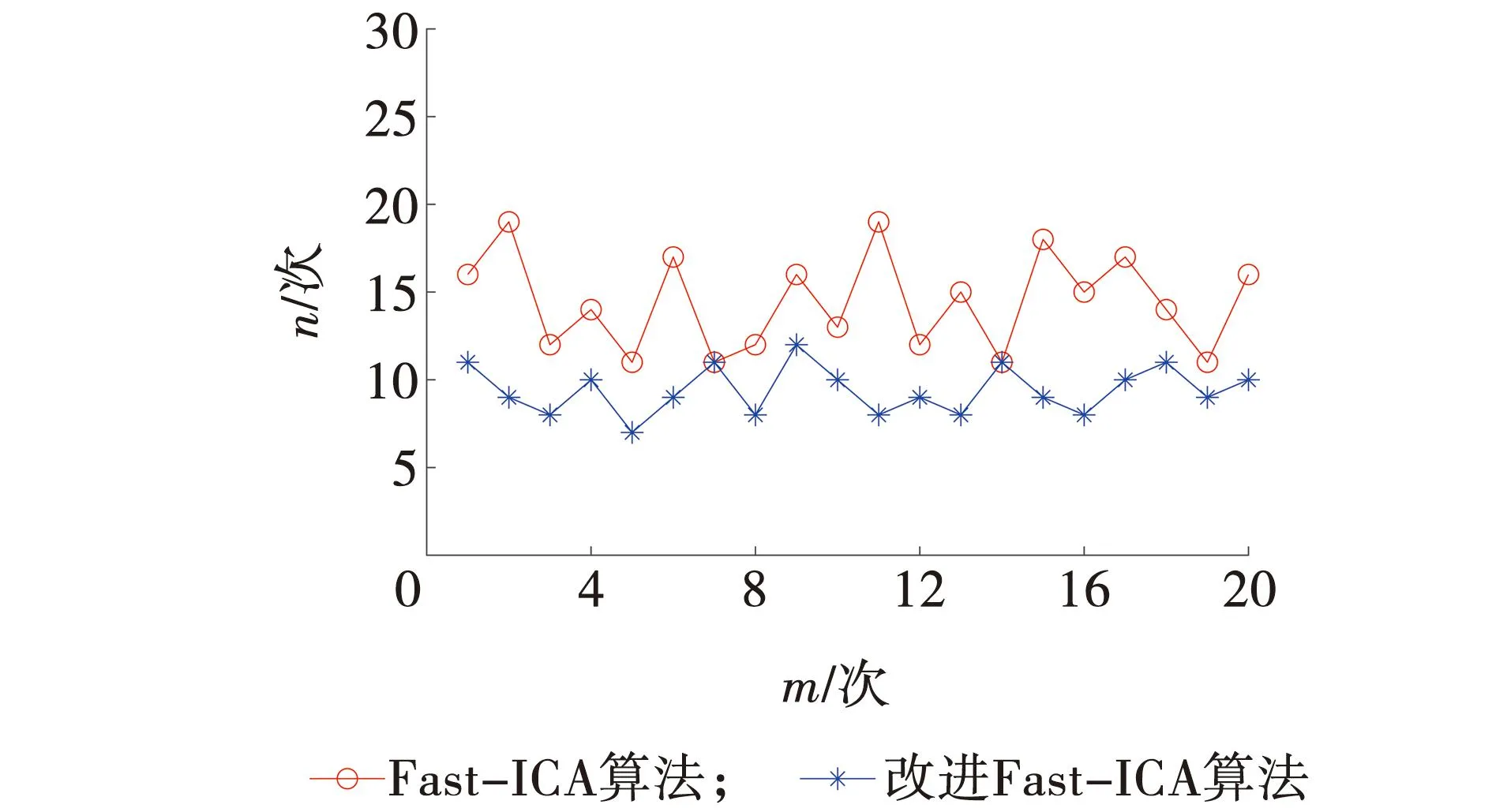
设a=x0 s(x)=ai+bit+cit2+dit3+eit4, 式中,x=xi+th,0≤t≤1。 由s(xi)、s′(xi)、s″(xi)、s‴(xi)、s″(xi+1)的值,可以得: 进而可以得,s(x)的表达式为 则有: 再由文献[11]中引理2.2.1可以得: 2s(xi)+s(xi-1)]。 记Dis(x)=s(i)(x),则有: 最终得出四次样条函数为 分析构造的四次样条函数的误差,对一个给定的步长h和无限可微的y(x),定义为 Ehy(x)=y(x+h),Dy(x)=y′(x), 此外,有: 式中,Eh=ehD。 因此,定义: Eh1Eh2y(x)=y(x+h1+h2), 可以得,Eh1Eh2=e(h1+h2)D。 令i=0,1,…,n-1;0≤k≤n-1-i,可以得 接着,根据定理2.3.1[12],得: 将区间[a,b]划分为n个均匀的子区间,令h=(b-a)/n,很容易得: 据此,证明了四次样条插值函数是具有四阶收敛的,从而提高了插值曲线的精度。 设f(x)=cos8x,x∈[-2,2],利用上述四次样条插值函数对其插值,得到原函数与插值后的函数图像,如图2所示。由图2可以看出,经过四次样条插值后的函数与原函数是非常接近的,故用四次样条插值逼近原函数是非常好地选择。 图2 原函数与插值后的函数 根据上面的讨论,给出改进Fast-ICA算法的步骤如下: (1)将数据进行中心化使其均值为0。 (2)对数据进行白化处理,得到z。 (3)选择一个初始化向量w。 (4)使用改进后的迭代公式来重新计算w。 (5)标准化w,w←w/‖w‖。 (6)判断收敛与否,若不收敛则返回(4)。 (7)对分离结果进行四次样条插值。 利用Matlab进行仿真实验,分别用传统Fast-ICA算法与文中改进的算法对两组语音数据进行仿真,对比改进前后的仿真结果。 信号源为两组不同的语音信号,分别是男声和音乐声,如图3所示。接着利用Matlab生成一个随机混合矩阵,将两组语音信号混合,如图4所示。 图3 原始语音信号 图4 混合语音信号 得到混合语音信号后,首先用传统的Fast-ICA算法对其分离,如图5所示。可以看出,传统算法分离性能优秀,很好地分离出了原始语音信号。接着,用文中改进的Fast-ICA算法对其分离,结果如图6所示。由图6可见,改进后的算法依旧能够很好地分离出原始语音信号,尽管与传统算法分离的排列顺序不一致,但这是由于算法分离的无序性导致的,并不影响结果,具体的分离性能还需根据算法PI值来分析。 图5 Fast-ICA解混信号 图6 改进的Fast-ICA解混信号 为了进一步证明改进算法对比原算法有更快的收敛速度,文中随机选取了20个初始分离矩阵,分别对两种算法运行了20次,记录每一次的迭代次数,结果如图7所示。 图7 算法收敛速度 同时本文还比较了两种算法的分离性能,常用的有通过算法PI值来衡量,其公式为 式中:m——源信号的个数; cij——C=WA的元素; W——经过样条插值后,再进行一遍算法分离得到的分离矩阵。 其结果PI值越小,则证明算法具有更好的分离性能。同样对两种算法进行20次仿真,记录PI值。将平均迭代次数N与平均PI值记录如表1所示。 表1 算法PI均值、N与MSE 在评价与分析分离信号与原始信号的一致性时,常采用均方误差作为判断依据,同样本文比较了改进算法与传统算法的均方误差,其公式为 si——原始信号。 其结果MSE越小,则说明算法分离精度越高,结果如表1所示。 从图7可以看出,原算法对初始向量比较敏感,每次迭代的次数波动较大,而改进的算法则波动较小。从表1可以看出,改进算法的PI均值较原算法有29%的提升,平均迭代次数则有35%的提升,而改进算法的精度较原算法有24%的提升。证明改进算法收敛速度与精确性都优于原算法。 (1)基于Fast-ICA算法提出的四阶牛顿迭代法,通过四次样条插值,使算法的收敛速度与精度进一步提升,给出平均迭代次数与算法PI均值的证明。 (2)通过仿真实验对比了两组算法分离语音信号的性能,仿真结果显示,改进后的Fast-ICA算法收敛速度更快,较原算法有35%的提升;精度较原算法有24%的提升,分离出的信号更接近于源信号。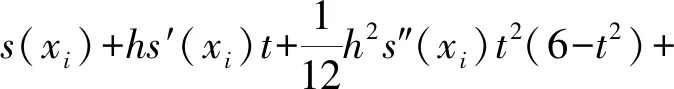

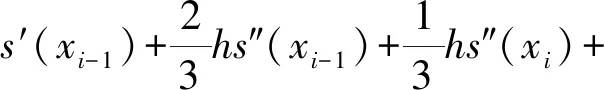
2.3 误差分析
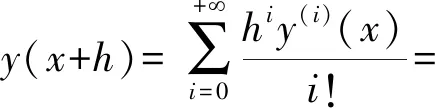
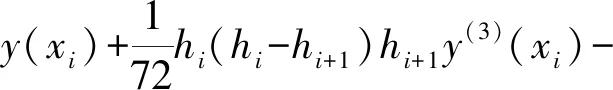
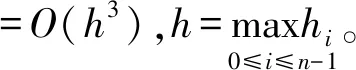

3 仿真实验与结果分析





4 结 论
