基于特征融合和注意力机制的遥感目标检测
2024-01-05刘树东任慧娟张众维
刘树东,任慧娟,张众维
(天津城建大学 计算机与信息工程学院,天津 300384)
0 引言
遥感图像能进行多视角、大规模的监测,在军事调查、城市规划、自然灾害评估与灾后救援等领域有着重要的应用价值[1]。但遥感图像分辨率高、背景复杂,图像中目标尺度变化大、长宽比变化极端等特点,均为遥感目标检测带来了挑战。
随着深度学习技术的发展,姚群力等[2]提出基于多尺度卷积神经网络的遥感目标检测框架,通过引入膨胀瓶颈结构,构造深度特征金字塔,增强对多尺度目标特征的表征能力;李竺强等[3]提出一种针对机场目标的检测网络,在特征提取阶段利用深度残差块卷积神经网络对特征图进行提取;Xu等[4]在YOLOv3中引入密集连接网络来增强特征提取的能力;杨志钢等[5]提出了多重特征金字塔网络,通过添加跨层连接来提高特征的传播和重用率。上述算法在一定程度上提高了对多尺度目标的检测能力,但是对于长宽比变化极端的目标检测性能较低。一般来说,浅层特征感受野小,适合检测小目标,而长宽比较大的目标则需要更大的感受野。为此,本文引入了基于膨胀编码的多尺度特征融合模块以增大感受野,提高对长宽比变化极端目标的检测性能。
近年来,注意力机制因为打破了卷积神经网络短距离建模的局限性而备受关注。Hua等[6]提出了一种强化目标的自注意预筛选全卷积网络,引入自注意力模块并通过结合卷积长短期记忆网络构建深度特征金字塔来优化注意力特征图;Ran等[7]提出了多尺度上下文和增强通道注意模型,增强特征图像通道注意力并将上下文信息与多尺度检测方法融合,以提高卷积神经网络的表征能力;Liu等[8]提出了一种中心-边界双重注意模块,利用双重注意机制提取目标的中心和边界区域的注意特征。由于注意力机制可以获得长距离建模的优势,能够在全局范围内根据赋予的权重来快速、准确地关注到权重较大的目标区域,达到提升网络性能和效率的目的。因此,为了解决遥感图像中极大目标检测困难的问题,本文算法采用注意力机制,通过建模捕获长距离依赖性和自适应性,提高检测准确率。针对上述问题,本文提出了一种基于多尺度特征融合和全局-局部注意力的遥感图像目标检测模型,主要工作如下。
1)设计多尺度特征融合模块(multiscale feature fusion,MSFF),通过堆叠不同膨胀率的残差空洞卷积块,生成具有多个感受野的输出特征,强化感受野的多尺度性,增强对深层特征信息的提取;添加残差连接,保留浅层信息以提取小目标特征,二者结合有利于提取多尺度目标特征,保证小目标检测的同时提升对长宽比变化极端目标检测的性能。
2)采用全局-局部注意力模块(global-local attention,GLA),将大卷积核分解为空间卷积和通道卷积,分别捕获空间和通道维度的长期依赖性和适应性,实现动态地提取丰富的全局上下文信息;利用卷积神经网络(convolutional neural network,CNN)短距离建模的空间局部性和平移不变性来提取局部上下文信息。结合以上两部分,能够在近乎不增加参数量的同时提高全局和局部信息的建模能力,提高对大尺寸目标的检测精度。
3)通过消融实验验证了本文算法的有效性,在航空遥感DOTA数据集上与当前主流算法进行了客观对比,并与YOLOv5m模型检测结果进行了主观对比,均证实了本文算法的优越性。
1 遥感图像目标检测算法
YOLOv5对中、小目标具有较高的检测准确率,然而,遥感图像中还存在着大量尺寸相对较大且长宽比变化极端的目标。因此,为了在保证小目标检测性能的基础上提升对其他类型目标的检测精度,同时对比了YOLOv5在s、m、l和x模型上的性能,综合考虑设备能力和效率、精度之间的平衡,本文选择以YOLOv5m中6.0版本模型为基础进行改进。改进后的整体网络结构如图1所示,主要由特征提取模块、特征融合模块和检测头构成,具体改进如红框所标注。
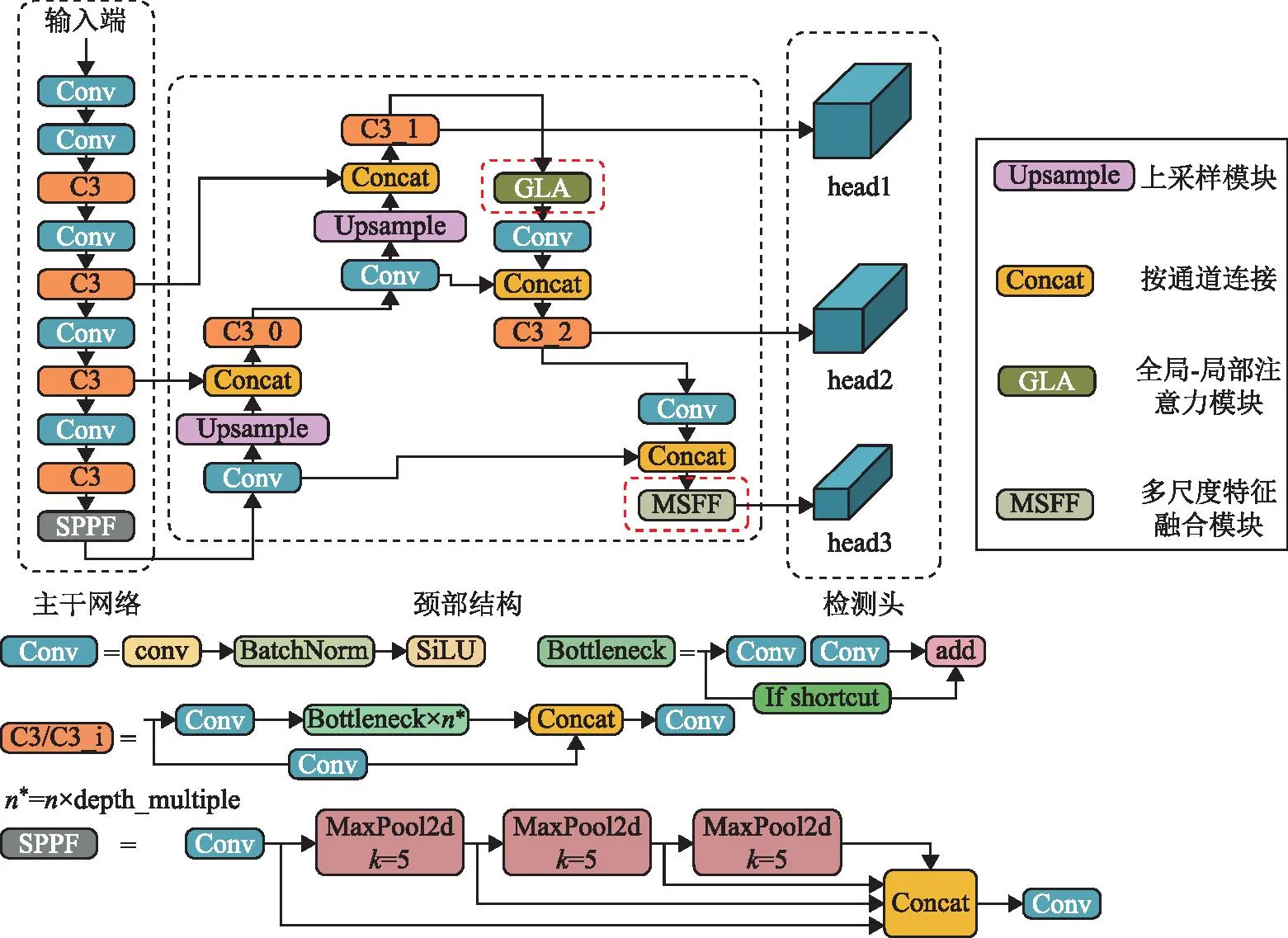
图1 基于多尺度特征融合和全局-局部注意力的遥感图像目标检测网络结构
1.1 特征提取模块
特征提取模块即主干网络部分,该模型将原有Focus模块替换为6×6大小的卷积,使得模型更加高效。然后经过Conv模块和C3模块交替连接,实现网络的加深和下采样操作。其中Conv模块包括一般的卷积操作(conv)、批量归一化操作(batch normalization,BN)和SiLU激活函数。C3模块输入输出通道数相同,其中,n为目标种类数,主干网络中的Bottleneck默认shortcut为True,颈部结构中没有shortcut。利用SPPF替换了原始版本中的SPP模块以减少模型的计算量。
1.2 特征融合模块
特征融合模块即颈部结构,是特征提取模块的输出特征图通过自下而上和自上而下的操作,再与中间层特征进行融合来构成的。为进一步提高模型对多尺度目标的检测性能和对全局信息的提取能力,本文在C3_1(与head1相连的C3模块)后添加全局-局部注意力模块,将与head3检测头连接的C3_3模块替换为多尺度特征融合模块。
1)多尺度特征融合模块。为解决遥感图像中部分目标尺寸大及长宽比变化极端的问题,本文提出了一种基于膨胀编码块(dilated encode block,DEB)[9]的多尺度特征融合模块,其结构如图2所示。
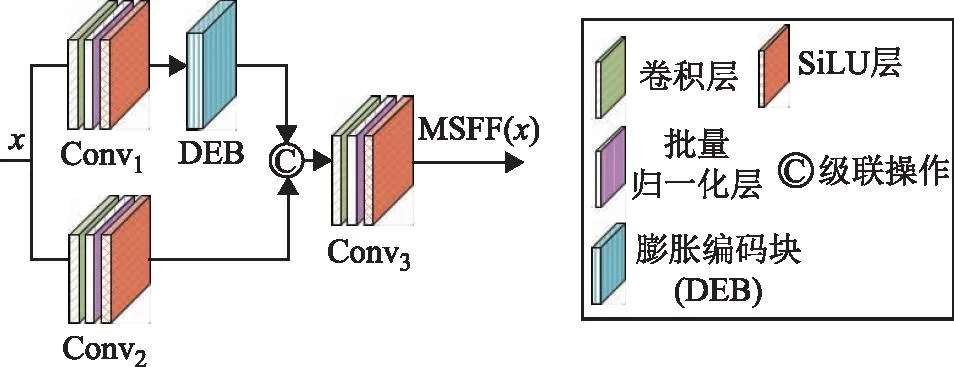
图2 多尺度特征融合模块
该模块上分支的输入特征x通过Conv1中的1×1卷积降维后连接DEB模块来提取多尺度特征。下分支的x经过Conv2形成了一个残差连接,充分保留了原始的特征信息,且其中的1×1卷积能降低通道维度和计算复杂度,减少参数量。Concat充分融合上述特征,并利用Conv3得到相同的输入输出通道。多尺度特征融合模块MSFF(x)表示为式(1)。
MSFF(x)=Conv3(Concat(Conv2(x),DEB(Conv1(x))))
(1)
式中:x表示输入特征;MSFF(x)表示提取多尺度特征操作。每个卷积块(Convi,i=1,2,3)都包含卷积层、批量归一化层和激活层。其中,卷积层中卷积核大小为1×1,步长为1,填充为0。
膨胀编码块包含两个主要的组件:投影层和膨胀残差组,其结构如图3所示。
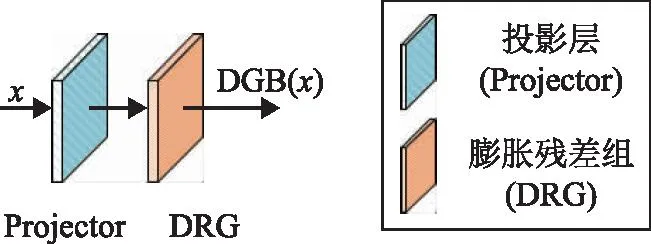
图3 膨胀编码块结构图
膨胀编码块DEB(x)可以表示为式(2)。
DEB(x)=DRG(Projector(x))
(2)
式中:x表示输入特征;DRG(·)表示提取的不同感受野特征的融合操作;Projector(·)表示提取上下文信息操作。
投影层结构如图4所示。输入特征x首先通过Conv4中1×1的卷积降低通道维度,然后通过Conv5中3×3的卷积进行局部特征提取和细化,使得语义信息更明显,最后增加残差连接,将细化后的特征与原始特征进行相加,得到更加丰富的特征信息。每个卷积块中的卷积层后都有一个BN层,目的是加快网络训练和收敛的速度。投影层Projector(x)可以表示为式(3)。

图4 投影层结构图
Projector(x)=Conv5(Conv4(x))+x
(3)
式中:x表示输入特征;Conv4(·)表示提取降低通道维度后的特征操作;Conv5(·)表示细化语义信息操作。
膨胀残差组结构如图5所示,4个不同膨胀率的膨胀残差块(dilated residual block,DRB)通过堆叠的方式获得不同大小的感受野以提取多尺度特征。单个膨胀残差块的结构如图6所示,3个卷积块中卷积核大小分别为1×1,3×3和1×1,且所有卷积层后都有1个BN层和1个ReLU层。其中第一个1×1卷积可以降低通道维度,3×3膨胀卷积可扩大感受野,尽量保证长宽比大的目标特征。最后,利用1×1卷积恢复通道维度。此外,残差连接也保证了小尺度目标的特征。膨胀残差组DRG(x)表示为式(4)。
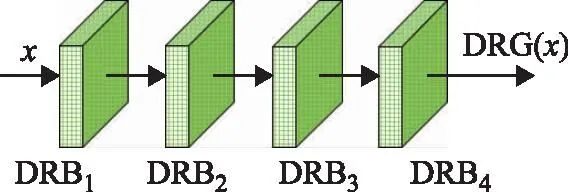
图5 膨胀残差组结构图
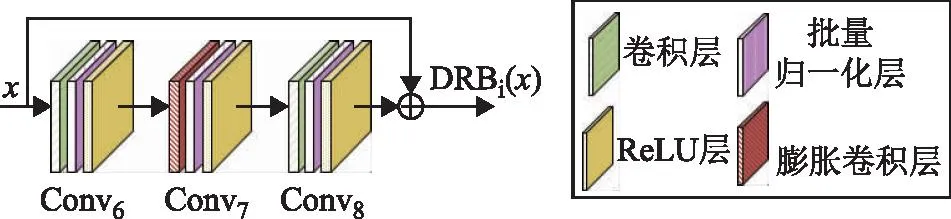
图6 膨胀残差块结构图
DRG(x)=DRB4(DRB3(DRB2(DRB1(x))))
(4)
式中:x表示输入特征;DRG(·)表示提取具有多个感受野的特征操作;DRBi(x),i=1,2,3,4是4个不同膨胀率的膨胀残差块,可以表示为式(5)。
DRBi(x)=Conv8(Conv7i(Conv6(x)))+x,
i=1,2,3,4
(5)
式中:Conv7i(·)表示第i个膨胀残差块中的膨胀卷积操作,其膨胀卷积的卷积核ki的大小可表示为式(6)。
(6)
式中:i表示膨胀残差块的位置;ri表示第i个残差块中膨胀卷积的膨胀率。
2)全局-局部注意力模块。在卷积神经网络中,卷积核的大小限制了网络提取深层特征的能力,自注意力机制[10]可以通过长距离建模实现空间维度的长期依赖性和适应性,但却忽略了通道维度的适应性。为了解决这些问题,本文引入了全局-局部注意力模块,充分利用了自注意力具有适应性和长期依赖性的优点和卷积获取局部上下文信息的特点。
全局-局部注意力模块结构如图7所示[11]。其中每个卷积层的卷积核大小为1×1,步长为1。全局-局部注意力模块可以表示为式(7)。

图7 全局-局部注意力模块
GLA(x)=BN(Conv(LKA(GeLU(Conv(x)))))+x
(7)
式中:x表示输入特征;GLA(x)表示该模块提取的到的融合特征;GeLU(·)表示激活函数;LKA(·)表示大核注意力模块(large kernel attention,LKA);BN(·)表示进行批量归一化。

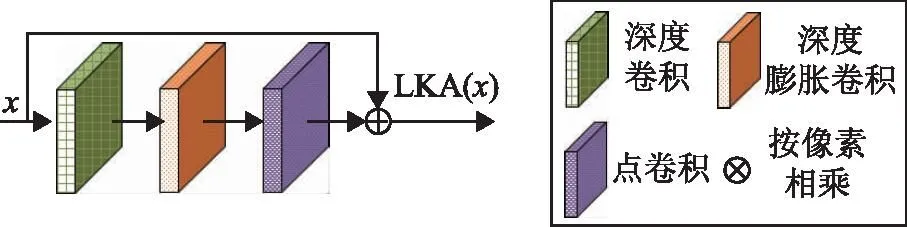
图8 LKA模块
(8)
式中:x∈RC×H×W表示输入特征;DW-Conv类似CNN中的卷积,用来提取局部上下文信息,因此又称为空间局部卷积;DW-D-Conv为加入膨胀率的DW-Conv,称为空间远程卷积,能够通过扩大感受野来建立内部空间特征信息间的长期依赖关系,提取全局上下文信息;Conv1×1又叫通道卷积,能在通道维度建立长期依赖性并提取特征信息,加强在通道维度上的适应性,使得适应性和长期依赖性相关;Attention∈RC×H×W表示生成的注意图,图中的值表示每个特征的重要性,⊗表示按像素相乘。
2 实验与结果分析
为了验证多尺度特征融合模块和全局-局部注意力的有效性,在Ubuntu系统上基于DOTA数据集进行消融实验,将结果上传DOTA官方网站后,根据官方反馈的mAP评价指标的客观数据来分析网络的性能。
2.1 数据集与实验设置
1)数据集。DOTA-v1.0是2017年由武汉大学公开发布的用于遥感图像目标检测的大型数据集。该数据集共有2 806张图像,其中训练集、验证集和测试集的占比分别为1/2、1/6和1/3。DOTA数据集包含15个常见类别:飞机、棒球场、桥梁、田径场、小型车辆、大型车辆、船舶、网球场、篮球场、储罐、足球场、环岛、港口、游泳池和直升机。
为了更有效地进行训练,将DOTA数据集裁剪并调整成尺寸为1 024像素×1 024像素的子图像,重叠部分为200像素,分别获得15 749和5 297张子图像用于训练和验证和测试,并通过拼接各子图像的检测结果得到最终完整的检测结果。
综上所述,与现有的遥感图像公开数据集相比,DOTA-v1.0数据集的数据量较为庞大,足够完成训练和测试任务,且该数据集中包含15类不同大小、不同形状的目标,也有诸如飞机或直升机、小型汽车或大型汽车等容易混淆的目标,在提高检测难度的同时更有利于验证算法的有效性。后续实验均在该数据集上进行训练、验证和测试,并将测试结果上传到DOTA官网,得到每一类目标的AP值和3种COCO类型的评价指标。
2)实验设置。模型训练时的硬件平台CPU为Intel(R) Core(TM) i7-7700 CPU @ 3.60 GHz,内存为16 GB,GPU为NVIDIA GeForce GTX 1 080,8 GB。软件平台为Ubuntu18.04操作系统、Pytorch深度学习框架和Python编程语言。
2.2 实验结果及分析
本文采用平均精度(average precision,AP)和均值平均精度(mean average precision,mAP)对实验进行评估。
1)消融实验。为了验证本文所提MSFF模块和GLA模块对长宽比变化极端目标和大尺寸目标的检测性能的提升,进行消融实验。具体指标如表1所示。

表1 本文消融实验在DOTA测试集上的定量比较
由表1可知,第一,与改进前的YOLOv5m模型相比,添加MSFF后的新模型中,桥梁、船舶和港口的AP值分别提高了6.91%、4.12%和4.34%,充分说明了MSFF模块对长宽比变化极端类目标的有效性。除此之外,部分小目标如大型车辆、储罐等和大目标如环岛等目标的AP值均有小幅度的提升,也说明了该模块能够有效提高多尺度目标检测的性能。第二,与改进前的YOLOv5m模型相比,添加GLA后的新模型中,田径场、足球场和环岛的AP值分别提高了0.83%、0.72%和2.68%,充分验证了GLA模块对大尺寸目标的有效性。此外,部分其他目标如棒球场、桥梁、直升飞机等不同目标的AP值也均有不等的提升,也充分说明了GLA通过长距离建模有效获取全局上下文信息,对大多类目标均能够有较好的检测效果。第三,仅添加MSFF的模型和仅添加GLA的模型比初始模型的mAP50分别提升了1.03%和1.17%,这表明所加模块在该模型中起到加强作用。此外,mAP75、mAP50:95均有一定提升,充分证明这两个模块的有效性。同时添加2个模块的模型(即本文算法)比前面3个模型的mAP50分别提升了1.66%、0.63%和0.49%,表明这两个模块之间不存在排斥作用,相互兼容性较强,可以联合使用以提高模型的性能。
综上所述,消融实验充分验证了本文提出的遥感图像目标检测算法中多尺度特征融合模块和全局-局部注意力模块的实际有效性。
除了客观的评价指标外,模型的参数量和计算量也是分析模型性能的重要指标。消融实验中模型的性能指标如表2所示。
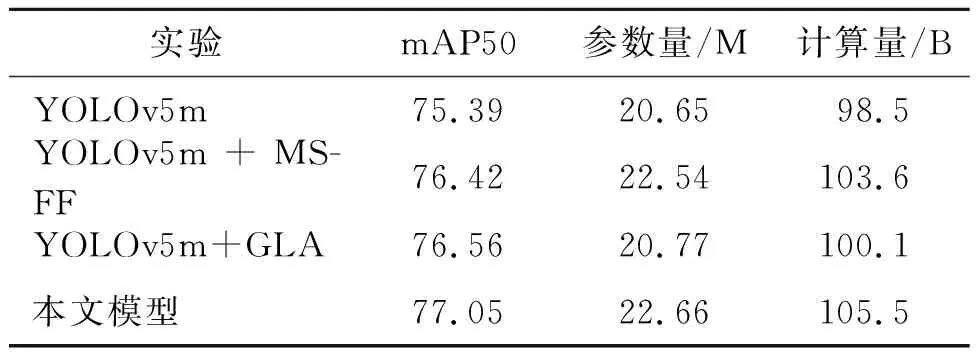
表2 DOTA数据集上不同模型的性能比较
从表2可以看出,首先,本文模型与YOLOv5m相比,mAP值提高了1.77%,参数量增加了2 M,计算量增加了7 B,这是由于模型越大,网络越复杂,但复杂度增幅较小。其次,添加GLA的模型较原模型的参数量和计算量相差不大,但mAP50增长了1.17%,充分验证了GLA在达到较好检测效果的同时并没有造成繁重的计算开销和参数。
2)对比实验结果分析。为了验证本文算法的有效性和优越性,将其与目前主流的RRPN[12]、P-RSDet[13]、R3Det[14]、SCRDet++[15]、PolarDet[16]、S2A-Net[17]、OPLD[18]等遥感图像目标检测算法进行定量比较。实验选择mAP50(以下简称mAP)作为评估指标,mAP值越高表示检测效果越好。定量对比结果如表3所示。

表3 本文算法与其他算法在DOTA测试集上的定量比较
由表3可知,当前主流算法中S2A-Net和OPLD的mAP较高,达到76%以上,而本文算法的mAP值比上述算法分别高出0.94%和0.62%,整体检测性能最优。从单个类别的AP值来看,首先,YOLOv5m自身对小目标的检测性能较高,而本文改进后的算法在近乎不影响小目标检测性能的基础上,对大尺寸目标(如田径场、足球场、环岛等)和长宽比变化极端的目标(如桥梁、船舰、港口等)的AP值分别提高了2%~4%和4%~6%,整体的mAP值提高了1.66%,充分证明了本文所提算法对大尺寸目标和长宽比变化极端目标的有效性。其次,针对长宽比变化极端的目标(如桥梁、港口等)和大尺寸目标(如田径场、足球场、环岛等),PolarDet、S2A-Net和OPLD算法更具有优势,与之相比,本文对相应目标的检测性能略有差距,但仍优于多数方法,同时上述算法在小目标(如大小车辆、船舰、篮球场、储罐、游泳池等)上的检测性能表现不足,且总的mAP次于本文算法。可以看出,本文算法对于多种尺度类型的目标检测的整体效果更佳。
3)实验可视化结果分析。为了进一步证明本文算法对YOLOv5算法的提升,在DOTA测试集结果中选取7张典型图片,包括8个场景及多个不同类型的目标。对YOLOv5m与本文算法的检测结果进行主观评价,如图9所示。
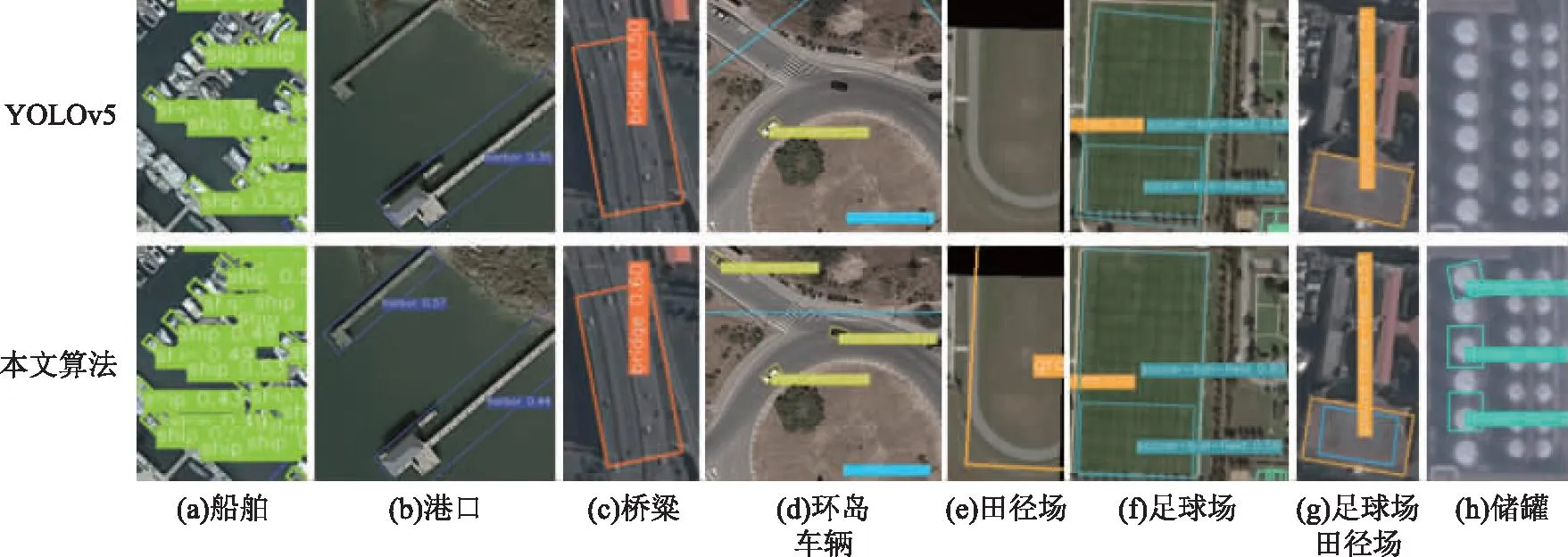
图9 YOLOv5与本文算法在DOTA数据集上的可视化结果对比图
图9(a)~图9(c)分别展示了船舶、港口和桥梁等长宽比变化极端的目标的检测结果;图9(d)~图9(f)分别展示了环岛、田径场和足球场等大尺寸目标的检测结果;图9(d)、图9(h)分别展示了车辆、储罐等小目标的检测结果。从图中可以看出,本文算法较好地改善了YOLOv5m对以上类别目标的漏检情况,且对相同目标的检测精度也更高(如图9(c)中的桥梁),从视觉效果上充分验证了本文所提算法的有效性。
3 结束语
针对遥感图像中部分目标尺寸大且长宽比变化极端等问题,本文提出了一种基于多尺度特征融合和全局-局部注意力改进的YOLOv5算法,用于遥感图像目标检测。利用多尺度特征融合模块可以获得多个不同感受野的输出,有效地提取和融合网络中不同尺度的特征信息;采用全局-局部注意力机制,在建立长期依赖关系的同时,保证了空间维度和通道维度的适应性,使得网络在多方面共同关注感兴趣目标区域,抑制无用信息,加强了网络在全局范围内对特征的提取。本文所提算法提高了遥感图像目标检测的性能,在与当前主流算法对比中取得了最优的总体评价指标,既保留了YOLOv5网络在小目标检测方面的优势,又提高了大目标以及长宽比大的目标的检测性能。本文算法可应用到航空建筑物检测、车辆检测等相关领域,为智能检测、城市规划等领域提供理论和技术支持。
