云模型和集成分类结合的故障数据不平衡学习∗
2024-01-05马森财赵荣珍吴耀春
马森财, 赵荣珍, 吴耀春
(兰州理工大学机电工程学院 兰州,730050)
引 言
大数据时代的来临为旋转机械故障数据的处理、存储和利用带来了新的机遇和挑战[1]。一直以来,分类问题是故障诊断甚至是机器学习研究领域的重要组成部分[2-4]。然而,在采集的旋转机械状态数据中,某些类别的数据数量远少于其他一些类别的数据数量,但这些样本数量较少的类别往往又十分重要,不可忽略。此现象造成了不平衡数据集的产生,传统分类器在这种类间分布不平衡的数据集上训练时常常会出现分类面偏移,导致故障误分类,使模型辨识精度降低。因此,对不平衡数据分析技术进行深入研究,是工业大数据挖掘的重要前提之一,对旋转机械智能故障诊断技术的发展具有积极的促进作用。
针对不平衡数据的学习,相关研究主要从数据层面、分类算法层面来找寻和探讨其解决方法。文献[5]提出了一种不平衡分类与深度学习相结合的疾病自动检测方法,首先使用Borderline-SMOTE算法对训练集做了平衡处理,然后设计了一种一维深度卷积神经网络,并利用平衡处理后的训练集进行训练,有效避免了由于多数类样本较多而造成的过拟合。文献[6]提出了基于密度聚类与多工序制造特征的质检数据过采样方法,在少数类簇中进行了数据生成,使用多数类簇剔除了无效数据,解决了汽车零部件质检数据存在的合格与不合格产品数量不平衡问题,提高了汽车零部件的检测效率。文献[7]提出了一种混合方法来解决不平衡数据学习问题,利用聚类方法指导了新的样本生成,并构建了集成模型以进一步提升算法的性能。上述研究成果都有效解决了不平衡数据带来的困扰,且经归纳后发现,结合集成学习的不平衡学习算法在解决类别分布不平衡的问题上卓有成效。大量研究表明[8-11],在数据层面和分类算法层面共同处理数据不平衡问题将成为主要趋势。
笔者基于上述分析,首先,通过实验分析不同程度的类别不平衡数据作为训练集时对传统分类器的影响;其次,提出一种基于云模型的样本再生技术,并将其和集成ELM 分类模型结合,在样本层面和分类器层面上解决训练样本类别不平衡对故障模式辨识精度的影响;最后,将该方法运用在滚动轴承故障数据集中,通过实验验证了方法的可行性。
1 相关理论简介
1.1 云模型
假设U={x}为一个精确数值组成的论域,C为与U对应的定性概念,U中的元素xi对于定性概念C的确定度为yi,是一个在稳定范围内的随机数,则x在论域U上的分布称为云,每一个xi称为云滴。云模型用期望Ex、熵En和超熵He这3 个特征来描述云滴群的整体特性。
云模型是一种能实现定性定量转换的双向认知模型,其依靠云发生器来实现,云发生器主要分为正向云发生器和逆向云发生器2 种。正向云发生器根据云的3 个数字特征(Ex,En,He)产生若干含有确定度yi的云滴(xi,yi),实现了定性到定量的映射。其中:定量值xi为论域U上的一次随机实现,服从以Ex为期望、En′2为方差的高斯分布。同时,E′2n又是服从以En为期望、He2为方差的高斯分布的一次随机实现。因此,xi对U的确定度yi满足
逆向云发生器可以将云滴群(x,y)转换为以数字特征(Ex,En,He)表示的云模型,实现从定量值到定性概念的转换。云发生器模型如图1 所示,然而在实际工作中表示云滴确定度的y值很难获得,因此图1(b)所示的逆向云发生器实用性并不高。针对此问题,文献[12]提到了一种无需确定度y的逆向云发生器算法,根据此改进算法,可以在实际样本的基础上计算滚动轴承各状态下特征的高斯云分布模型指标,即期望Ex、熵En和超熵He。具体计算公式如下
其中:为样本均值;S2为样本方差。
1.2 装袋式集成学习算法
装袋式(Bagging)集成学习是并行式集成学习方法的代表,在学习过程中要构造多个学习器。若构造的学习器是同一类,则称为同质集成,反之则称之为异质集成[13]。其在学习时,先从包含n个样本的原始训练集中随机选择一个样本,将其复制到训练子集中,此时该样本仍存在于初始训练集中,在下次采样时仍有被选中的可能。这样,经过n次随机采样,可得到一个内含n个样本的训练子集(该训练子集中可含有重复的样本)。照此方法,重复t轮可得到t个训练子集,然后基于每个训练子集训练出一个子学习器。Bagging 集成学习的子学习器也被称作弱学习器,常用的弱学习器包括人工神经网络和决策树等,这些学习器在m类问题上的识别准确率一般不低于1/m。
Bagging 集成学习结果通过综合t个子学习器的学习结果得到。对于回归预测问题,通常将子学习器的结果经过简单平均后得到集成学习结果;对于分类问题,最终结果常用投票法得到。
综上所述,集成学习综合多个分类器给出了最终的预测结果,但多个分类器参与学习会消耗大量时间。为弥补这一缺陷,需要选用效率较高、泛化性相对较好的子分类器。ELM 与其他分类器相比,恰好具有计算复杂度低、泛化性强等特点[14]。
1.3 定义的样本类别不平衡程度度量公式
在类别不平衡问题中,将样本数较多的一类称为多数类,反之被称为少数类。设多数类样本数为kmuch,少数类样本数为kleast,则样本不平衡比率(imbalance ratio,简称IR)的计算公式为
根据IR 值,类别不平衡可划分为轻度不平衡和重度不平衡问题。前者的IR 值较小,对传统分类器的分类影响不大;后者会在极端条件下令分类器完全失效。
2 基于云模型的样本生成模型和基于装袋法的集成ELM 模型
2.1 滚动轴承状态信号采集和信号特征提取
本研究以无锡市厚德自动化仪表有限公司的一套双跨双转子综合故障模拟平台(图2)来模拟滚动轴承故障。故障轴承安装端如图3 所示,信号的采样通道共5 个,其中:通道1~3 连接1 个三向加速度传感器,采集故障轴承的2 个径向和1 个轴向方向的振动加速度信号;通道4 和5 各自连接1 个电涡流传感器,采集轴的径向振动信号(故障轴承直接安装在该轴上)。图4 为具体的故障轴承,其中:1 为内圈故障轴承;2 为外圈故障轴承;3 为滚动体故障轴承;4 为保持架故障轴承。 实验测得滚动轴承NSK6308 在4 种故障和正常共5 种状态下的振动信号5×80=400 组,选择5×20 组作为测试样本。采样转速分别为2 600,2 800,3 000 和3 200 r/min,采样频率为8 kHz。

图2 双跨双转子综合故障模拟平台Fig.2 Double-span double-rotor comprehensive fault simulation platform

图3 故障轴承安装端Fig.3 Fault bearing mounting end

图4 故障轴承Fig.4 Fault bearing
转速为3 000 r/min 时轴承部分故障的振动信号如图5 所示。将振动信号用一维小波进行消噪后,构建出5×11=55 维的多域多通道特征数据集,为i通道构造的原始特征集如表1 所示。为后续实验及分类考虑,将特征数据归一化至[-1,1]的区间上。
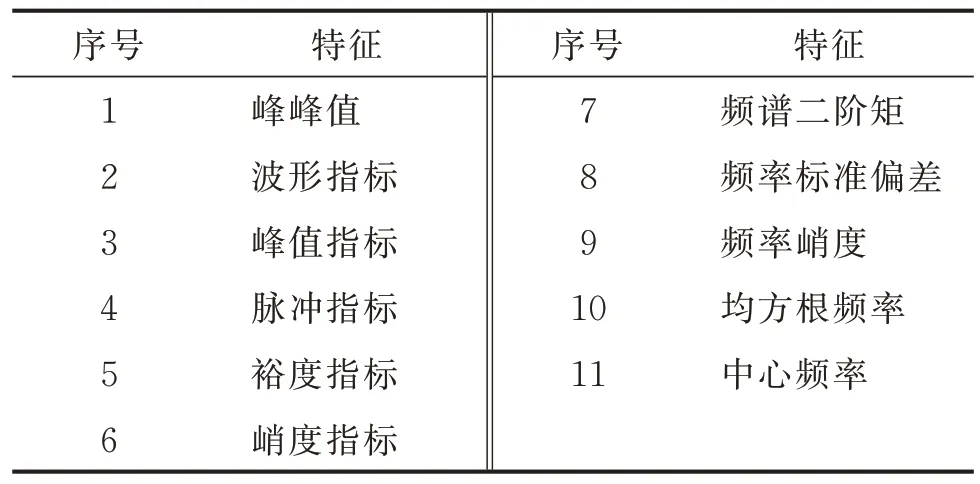
表1 为i 通道构造的原始特征集(i=1~5)Tab.1 The original feature set for the channel i(i=1~5)
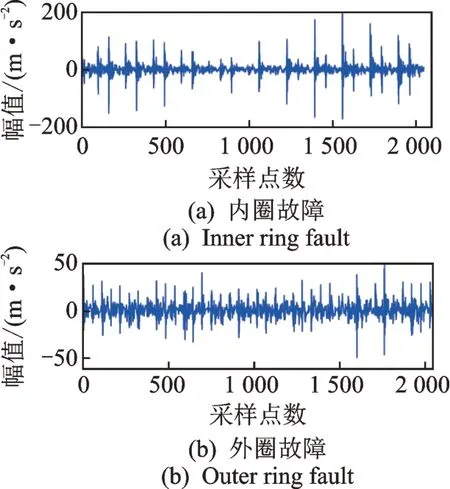
图5 3 000 r/min 时轴承部分故障的振动信号Fig.5 Vibration signal of partial failure when rolling bearing speed is 3 000 r/min
2.2 基于云模型的滚动轴承特征样本再生成技术
设滚动轴承的状态序号m=(1,2,3,4,5),分别表示滚动体故障、保持架故障、内圈故障、外圈故障和正常状态;特征序号为j=(1,2,…,55)。首先,以滚动轴承在状态m下第j个特征的特征值为输入,利用1.1 节所提的改进逆向云算法计算出云模型指标(Exm,j,Enm,j,Hem,j);其次,将该指标作为正向云发生器的输入,可以获得带有确定度的云滴(xi,yi),设云滴个数i=1 000。高斯云由这些云滴汇聚而成,云滴的xi值即可视为状态m下第j个特征的再生样本。
设样本数为60 的特征值期望为标准值,以实际样本数为自变量、实际样本数目下的特征期望与标准期望的比值为因变量来绘图,不同数目实际样本的期望与标准期望的关系如图6 所示。由图可知,当实际样本的数量极少时(最少为1),特征云模型会发生期望Ex偏移的现象,其中外圈故障特征偏移较为明显,但总体上样本特征的期望值趋于相对稳定,这说明基于云模型的样本再生技术在该故障数据集上具有可行性。

图6 不同数目实际样本的期望与标准期望的关系Fig.6 Relationship between expectations of different numbers of true samples and standard expectations
以转速为3 000 r/min 时滚动体故障和轴承外圈故障情况下通道1 信号的频谱二阶矩为例来说明样本的再生成过程。设少数类的实际样本数仅为8个,2 种故障情况下通道1 振动信号的频谱二阶矩云模型如图7 所示,其横、纵坐标均为无量纲量。实际样本原本无对应的确定度值,故无法进行基于云模型的可视化表达。每个特征属于对应概念的程度,即确定度可按式(6)进行计算
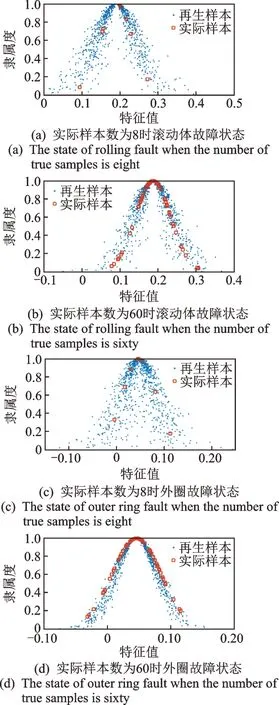
图7 2 种故障情况下通道1 振动信号的频谱二阶矩云模型Fig.7 Spectrum second-order momen cloud model of the vibration signal of channel 1 under two fault conditions
其 中:ym,j为 状 态m下 第k个 实 际 样 本Nm,k的 第j个特征与对应特征云的确定度;Fkm,j为实际样本Nm,k的第j个特征值;Exm,j为状态m中第j个特征的期望值;En′m,j为状态m中 第j个 特 征 的等效方 差,是 以特征的En为期望、He为标准差生成的一个正态随机数。
由图7(b,d)还可看出,特征值符合高斯分布,且大多数样本分布在高斯云的峰顶,从顶至尾逐渐减少。因此,在借助云模型进行样本生成时要进行分层抽样,本研究将确定度范围[0,1]等分为5 个区间,分别按照5∶4∶3∶2∶1 的比例来进行抽样,以获得不同确定度区间内的再生特征样本。虚拟样本的采样分布如图8 所示。
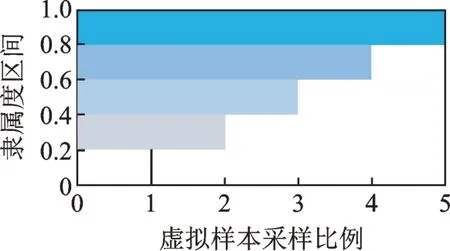
图8 虚拟样本的采样分布Fig.8 Sampling distribution of virtual samples
云模型是根据现存的实际样本构造而出,同样,再生样本也必须根据已有的样本来衍生。通过基于固有样本的高斯云模型,可以衍生出滚动轴承在不同状态下各个特征的再生样本。
2.3 基于装袋法的集成极限学习机
在隐含层节点相同的情况下,相较于极限学习机,集成极限学习机具有更好的分类精度。本研究将ELM 的隐含层节点数设定为10 个,在确定了隐含层节点的情况下,以分类误差不小于95%为原则,确定参与集成学习的子分类器数目(即ELM 的数目)。经验证,子分类器ELM 的数目不小于30 时满足实验要求,至此完成了集成极限学习机的2 个超参设置。E-ELM 学习流程如图9 所示,其中输入至子分类器ELMi的训练子集Ti由训练集通过自助采样得到,测试样本U的最终结果借助了相对多数投票法,综合考虑了各子分类器的结果。
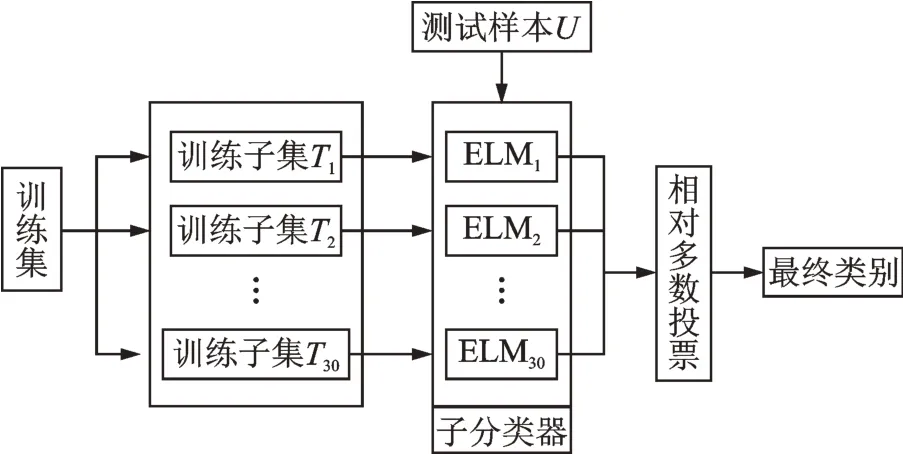
图9 E-ELM 学习流程Fig.9 Learning process of E-ELM
2.4 总体流程
设计的方法流程如下:
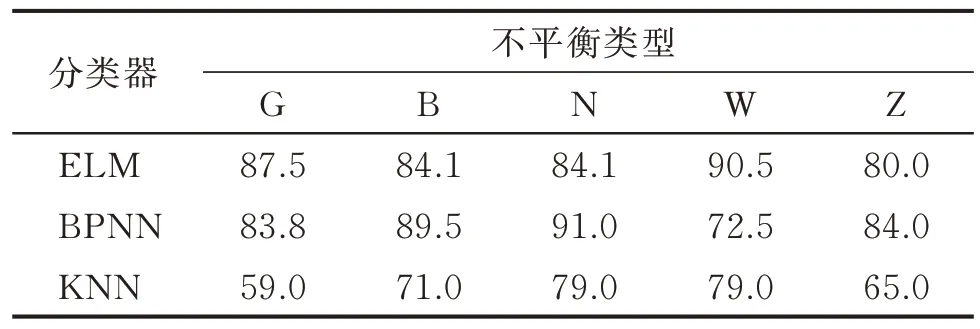
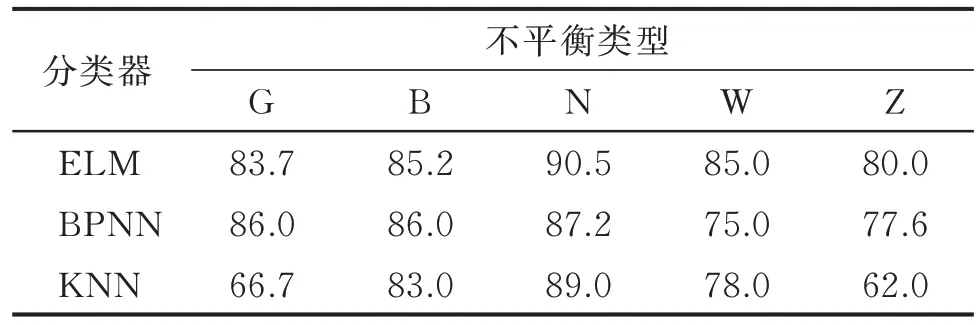
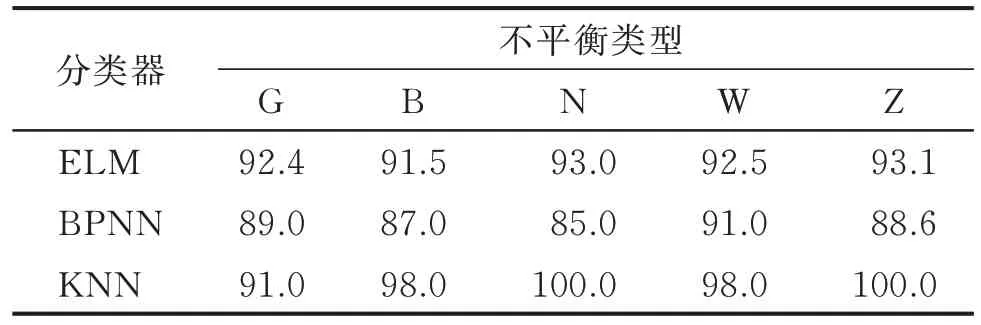
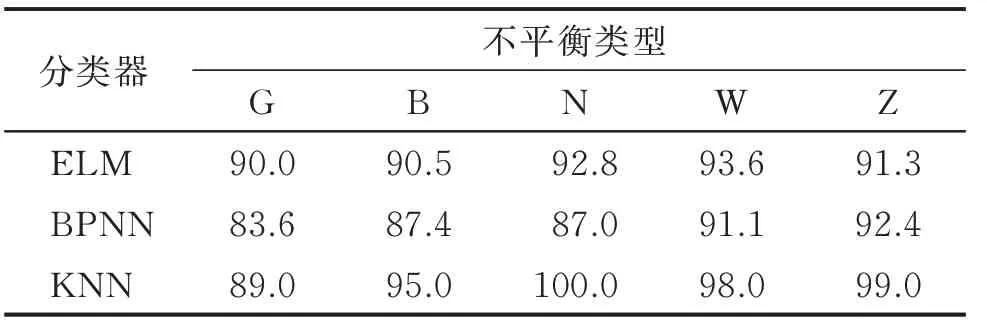
1) 计算训练集中各类的样本数km(m=1,2,…,5),kmuch=max(km),若50 2) 按式(1)计算各类样本的IR 值,将IR>1.4的类视为少数类,需要进行样本生成,将该类的样本数扩充至60;若IR<0.857,则该类样本过多,需要进行欠采样,使样本数目至60; 3) 将平衡样本集输入至E-ELM 中进行训练; 4) 利用测试集验证分类效果。 本研究中各类训练样本最大数量为60,故无需进行欠采样操作。图10 为不平衡数据学习流程图。 图10 不平衡数据的学习流程Fig.10 The learning process of imbalanced data 实验时,少数类样本数目统一设为5,即IR=60/5=12,此时训练样本类别分布极度不平衡。分别用“G”,“B”,“N”,“W”和“Z”表示训练集中滚动体故障样本较少、保持架故障样本较少、内圈故障样本较少、外圈故障样本较少以及正常状态样本较少,将其定义为一类不平衡情况;“GB”,“GN”,“GW”,“BN”和“BW”表示对应的两类样本数据量较少,将其定义为二类不平衡情况。 本节验证了滚动轴承故障训练数据存在一类和二类不平衡时,传统分类器ELM、误差反向传播网络(back propagation neural networks,简称BPNN)和K 近邻(K-nearest neighbor,简称KNN)分类器的识别精度。在实验时,ELM 和E-ELM 的隐层神经元数目均为10;BPNN 的隐含层为1 层,隐层神经元数目设为12,训练最小误差为0.1,训练次数为1 000次;KNN 的近邻样本数目设置为6。 在2 600 和3 000 r/min 2 种转速下,一类不平衡训练样本分类器的分类精度分别如表2,3 所示;二类不平衡训练样本分类器的分类精度分别如表4,5所示。按照组合C25=10,即两类不平衡的情况有10 种,表中只取5 种二类不平衡情况进行实验。 表2 2 600 r/min时一类不平衡训练样本分类器的分类精度Tab.2 Classification accuracy of classifiers with a kind of imbalanced training samples at 2 600 r/min % 表3 3 000 r/min时一类不平衡训练样本分类器的分类精度Tab.3 Classification accuracy of classifiers with a kind of imbalanced training samples at 3 000 r/min % 表4 2 600 r/min时二类不平衡训练样本分类器的分类精度Tab.4 Classification accuracy of classifiers with two kinds of imbalanced training samples at 2 600 r/min % 由表2~5 可知:训练样本不平衡对KNN 分类器影响最大;训练集二类不平衡对分类器的影响比一类不平衡要大;BPNN 和KNN 对轴承外圈故障样本不平衡的训练集比较敏感;在样本极度不平衡时,ELM 的辨识精度总体上要高于BPNN 和KNN。 采用本研究的样本再生技术将类别分布不平衡的训练集补充完整后训练分类器,并验证其分类精度。在3 000 和3 200 r/min 转速下,训练集经再生技术补充后训练的分类器学习能力分别如表6,7所示。 表6 3 000 r/min 时训练样本经再生技术补充后训练的分类器学习能力Tab.6 The learning ability of classifiers trained after training samples supplemented by regeneration technology at 3 000 r/min % 表7 3 200 r/min 时训练样本经再生技术补充后训练的分类器学习能力Tab.7 The learning ability of classifiers trained after training samples supplemented by regeneration technology at 3 200 r/min % 对比表3 和表6 发现,经再生样本补充的训练集训练的分类器在分类精度上有较好的提升。对比同转速下不同分类器的分类精度发现,ELM 的分类精度较好,且ELM 的训练时间(0.021 s)低于BP 神经网络的训练时间(0.27 s),这说明ELM 比BPNN 更适合作为Bagging 集成学习模型的子分类器。 为获得更好的学习效果,不平衡训练集用基于云模型的再生样本补充平衡后训练出了E-ELM 模型,拟在算法层面提高数据的最终学习效果。结合方法对不同工况下一类不平衡数据和二类不平衡数据的学习情况分别如表8,9 所示。 表8 结合方法对不同工况下一类不平衡数据的学习情况Tab.8 The combined method on the learning situation of the one type of unbalanced data under different working conditions % 表8 表明,基于云模型的样本再生技术和E-ELM 结合后,能大幅度改善一类不平衡数据的学习效果。对比表9 和表4、表5 后发现,本研究方法对于二类不平衡数据同样具有较强的学习能力。 表9 结合方法对不同工况下二类不平衡数据的学习情况Tab.9 The combined method on the learning situation of the two types of unbalanced data under different working conditions % 首先,验证了不平衡数据对传统分类器的影响;其次,用所提的样本再生技术平衡了数据,并用传统分类器验证了本方法在不平衡问题上的作用;最后,证明了E-ELM 作为本方法体系的分类器时,对不平衡学习的促进作用。实验表明,本研究设计的方法能较好地消除训练样本类别不平衡对滚动轴承故障辨识精度的影响,解决了因个别类训练样本较少引起的数据不平衡问题。 1) 基于云模型的样本再生技术本质上是依靠特征自身的分布趋势来构造虚拟样本,可视化效果强,可以直观地了解样本的分布。 2) 采用分层抽样技术从众多再生样本中获取部分用于填充不平衡训练集,在兼顾泛化性的同时尽量使得大部分再生样本靠近期望值。 3) 在分类阶段引入了集成的思想,以消耗一定时间为代价换取了分类精度的大幅提高。 4) 正态分布并不是所有故障数据的分布形式。有时同一类故障聚类时,类内会聚成若干个小簇。基于云模型的样本再生成技术在处理这种类型的数据时是否有较好的效果,还需进一步探讨。
3 实验分析及探讨
3.1 训练样本类别不平衡对传统分类器的影响

3.2 本研究所提样本再生技术的有效性验证
3.3 本研究的样本再生技术和E-ELM 结合后对不平衡数据集的学习效果验证


3.4 实验小结
4 结 论
