基于变权重大坝预测模型的组合告警方法研究
2024-01-05李文博,丁勇,李登华
李 文 博,丁 勇,李 登 华
(1.南京理工大学 理学院,江苏 南京 210094; 2.南京水利科学研究院,江苏 南京 210029; 3.水利部水库大坝安全重点实验室,江苏 南京 210029)
0 引 言
中国是世界上拥有水库最多的国家,目前所拥有的大坝超过10万座,但其中95%以上都是服役40 a以上的老坝,为国民经济带来诸多保障的同时也带来了诸多安全隐患,因此对大坝服役的健康状态展开监测显得尤为重要。
如何通过对大坝监测数据进行分析处理来建立合理可靠的预测模型并实现准确告警,是大坝安全监测领域中亟待解决的技术难题[1-4]。随着高新技术的发展,机器学习算法也逐渐应用到了大坝测点的预测模型中[5],如XgBoost[6]、支持向量机[7-8]、神经网络[9-11]等。但是,单一的预测模型往往不能满足大坝多种类测点的精准预测和准确告警,因此对多个预测模型进行组合是目前研究的主要方向。
多模型组合的研究,实质上是合理对多个单一模型权重进行分配的研究。赵明华等[12]采用最优权系数法对支持向量机和多元线回归模型进行权重分配,得到了更高的预测精度;王博林等[13]以最小对数误差平方和为目标函数求解最优加权系数,对Logisti和Gompertz预测模型进行组合;高彩云等[14]建立了次优权值、最优权值、灰色综合关联度权值、熵权值和神经网络5种变形模型并行组合预测;袁维等[15]提出了一种数据“融合-预测-预警”的三步式预警方法。上述学者的研究重点在于如何得到更加精准的预测结果从而降低误告警频次,但是缺少了对实际工程中预测效果对告警影响的研究,而告警效果的好坏往往更能体现模型在各个测点上的适用情况,即便是过去表现良好的模型,随着大坝性态的变化,后续表现也会有所波动。
针对上述问题,本文提出基于变权重预测模型的组合告警算法,针对不同预测模型的预测值进行残差修正处理,并通过计算评价指标和划分组合告警区间来评价多个模型的预测精度和告警成功率,为测点在每个预测模型动态赋予权重提供理论支撑,使得测点告警情况更符合实际情况。
1 预测模型的多指标评价及优选
1.1 预测模型的多指标评价
当对多个预测模型进行组合时,预测模型数量并不是越多越好。因此,在模型组合之前,应该对单一模型进行评估和优选。其中,评价指标体系的有效建立和评价指标权重的合理分配是模型评价的关键。
本文在一些基础评价指标的基础上,针对大坝测点的数据特征,建立一种新的大坝预测模型评价指标体系。通过数值计算确定指标的主观权重和客观权重,将两者结合后对模型进行综合评价,从而优选出参与组合的模型。
1.1.1数据评价指标
影响预测模型预测效果的因素有很多,考虑到大坝测点间具有时空属性,指标选取应尽量遵循全面性、科学性和客观性的原则。本文考虑了预测误差的极值、均值、离散程度以及预测值与实测值的相关程度等,使用常见评价指标MAE、r、MAX,为避免分母为0,使用改进的MAPE指标nMAPE,并且提出一个适用于大坝测点数据的评价指标——较大绝对误差数量(LAEN),由此来构建大坝的预测模型评价指标体系。
(1) 归一化平均绝对百分比误差nMAPE。
A′(t)=A(t)/|A(t)|max
(1)
F′(t)=F(t)/|A(t)|max
(2)
(3)
(2) 较大绝对误差数量LAEN比较的是各个预测模型预测出现较大绝对误差的次数。本文规定所有预测模型在一定周期内的预测值其绝对误差的合集Z中,15%的绝对误差定义为较大绝对误差。较大绝对误差出现频次越少,说明该模型出现较大误差概率越小,预测越稳定,效果越好。
(4)
(5)
式中:A(t)为实测值,F(t)为预测值,A′(t) 为归一化后的实测值,F′(t)为归一化后的预测值,|A(t)|max为实测值中绝对值的最大值,Z15为绝对误差合集中降序15分位,B(t)为较大误差个数。
1.1.2评价指标权重的确定
使用评价指标对各单个预测模型进行评价时,每个指标对预测模型的区分程度和重要程度各有不同,因此分别采用主观赋权法和客观赋权法对每个评价指标进行权重分配。主观赋权方法选用改进的层次分析法(AHP)[16],客观赋权法选用改进的CRITIC法[17]。
各指标的综合权重的计算公式为
(6)

1.2 模型优选
在对多种预测模型进行优选时,由于不同指标评价模型预测能力的表现方式不同,如r越接近于1说明预测模型效果越好,MAE越接近于0说明预测模型效果越好,因此在评价之前,应对评价指标进行归一化,首先建立原始数据矩阵:
(7)
式中:m,n分别为数据库中样本总数和变量总数;xij为第i个样本的第j个变量的原始值。
然后根据指标特性进行正向和反向归一化:
(8)
(9)

(10)
2 变权重组合进化模型
2.1 告警方法的确定
传统的告警方法将单个预测模型的残差作为告警对象[19],若残差落在两倍标准差区间以内,表明发生此事件的概率值为95.45%,认为大坝测点性态正常;若残差超出两倍标准差区间,大坝测点为告警状态。在多模型组合告警时,提出一种为每个预测模型设置告警数值的告警方式,每个预测模型根据其状态设置相应告警数值num(本文设定告警num=1,不告警num=0)。参与组合的5个优选模型的权重u与其告警数值num的乘积之和为该测点当日最终告警数值T(0≤T≤1),具体表达式如下:
(11)
(12)
将最终告警数值平均划分为5个区间,每个区间表示不同的告警等级,最终告警数值与告警等级对应结果如表1所列。

表1 告警等级Tab.1 Alarm level
2.2 预测模型的残差修正
当采用模型残差作为告警对象时,通常假设单模型残差服从均值为0的正态分布,但实际上多个预测模型的残差结果并不符合以0为均值的正态分布,对残差进行一定修正才能取得更好的预测效果。因此在使用该告警方法时应先对残差均值进行修正。在一定周期内的预测模型残差修正方法为
(13)
(14)
式中:Δi为一个周期T内修正前的残差值,Δxi为一个周期T内修正后的残差值,Fxi为一个周期T内修正后的预测值,Δt为一个周期T内t时刻残差值。修正过后,一个周期T内的残差集可认为服从以0为中心的正态分布。
2.3 动态数据评价指标调整模型权重
大坝测点时间序列为非平稳时间序列,兼具日变化、季节及长期变化特征,考虑到邻近的时间序列对下一时刻的未来数据影响更大,对建模数据进行滑动时间窗口操作。
由于数据评价指标会影响到指标权重和模型权重,因此结合滑动时间窗口实时更新数据评价指标,对模型告警准确率会有所提升。大坝测点数据大多以年为周期,因此动态评价指标时间窗口可选为告警当天最近1 a时间区间。
2.4 告警反馈调整权重
通常情况下,多种预测模型组合得到的预测值都以预测的精度为目标,对预测结果在实际中告警应用少有考虑。告警反馈是根据各个预测模型在测点上的历史告警情况,动态调整预测模型权重,提升测点的告警准确率。当以残差作为告警对象时,在较长的时间周期内会出现每个模型告警情况相似的情况,因此需要选取较短的时间区间作为告警期(本文选取告警区间为1个月),实时调整各模型权重,得到动态模型权重u。
每个模型根据当日之前一段周期内的数据评价指标得到动态权重值,再乘以告警反馈系数记为Q,该告警反馈系数与告警成功率有关。多次试验表明,大多模型告警成功率都在80%以上,设定一个告警成功率最低限值min(本文取0.7),告警成功率低于最低限制则给相应模型分配0权重,单个模型最高权重不高于0.5。
告警反馈系数Q计算公式如下:
p误=d误/d总
(15)
Q=max(1-min-p误,0)
(16)
根据告警成功率得到的最终模型权重vj为
(17)
vj=uj×Q
(18)
式中:p误为误告警率,d误为在一个周期内告警次数,d总为周期,uj为告警反馈前模型权重,vj为告警反馈调整后的最终权重,Q为告警反馈系数。
2.5 模型告警流程
结合上述内容,基于变权重的大坝测点预测组合模型告警流程如图1所示。
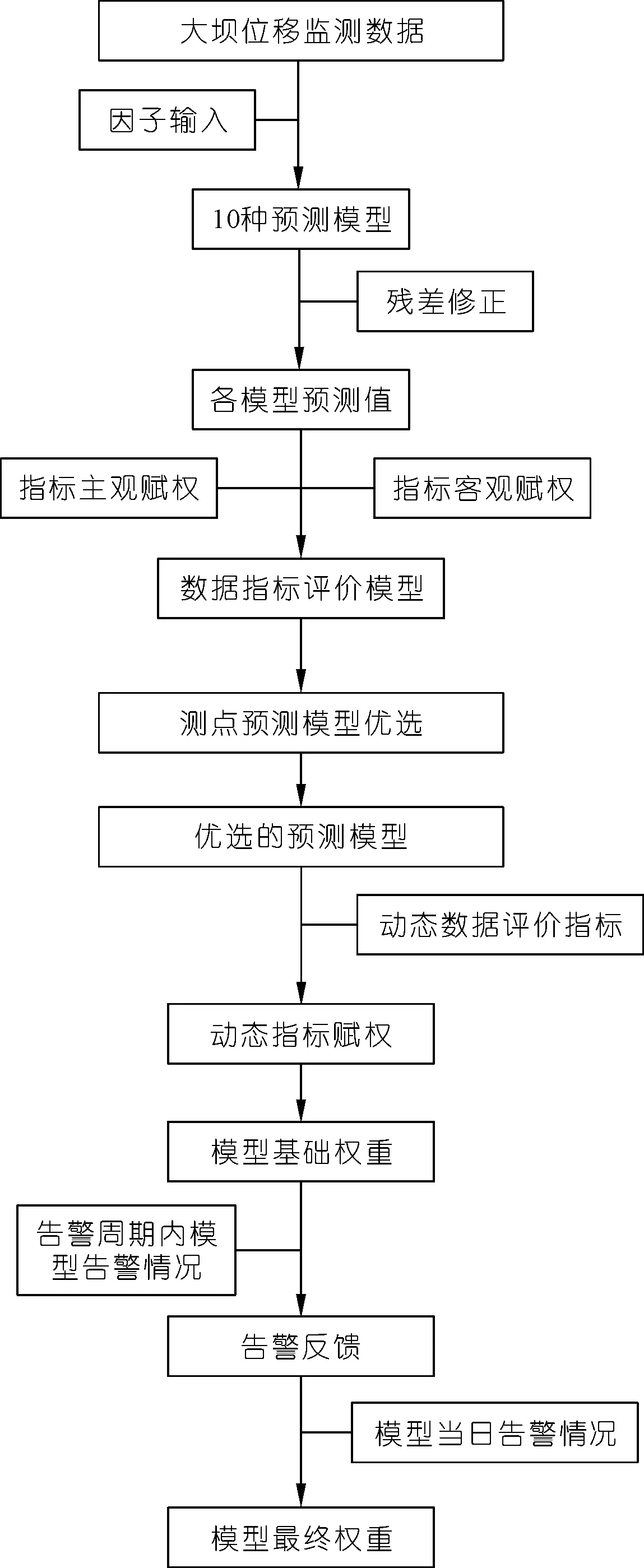
图1 总体流程Fig.1 Overall flow
3 实例验证
3.1 项目测点及模型选取
本文各类大坝监测实测数据来源于新疆察汗乌苏水电站大坝,该大坝场景具有一定特殊性,年降水量少于180 mm,降水量因子影响可以忽略。由于具有发电功能,该坝库水位长期在1 620~1 650 m内波动(见图2),处于高效率发电水位,且具有明显趋势性与周期性。该坝坝顶高程110 m(覆盖层深46 m),布置了较为完善的监测系统。本文选取坝左0+150.00断面中两条引张线(EX3、EX4)上的测点,测点实测值曲线如图3所示,具体实验步骤本文以测点EX3-7(测点1)和EX4-4(测点2)为例进行说明。

图2 库水位时间序列Fig.2 Time series of reservoir water level
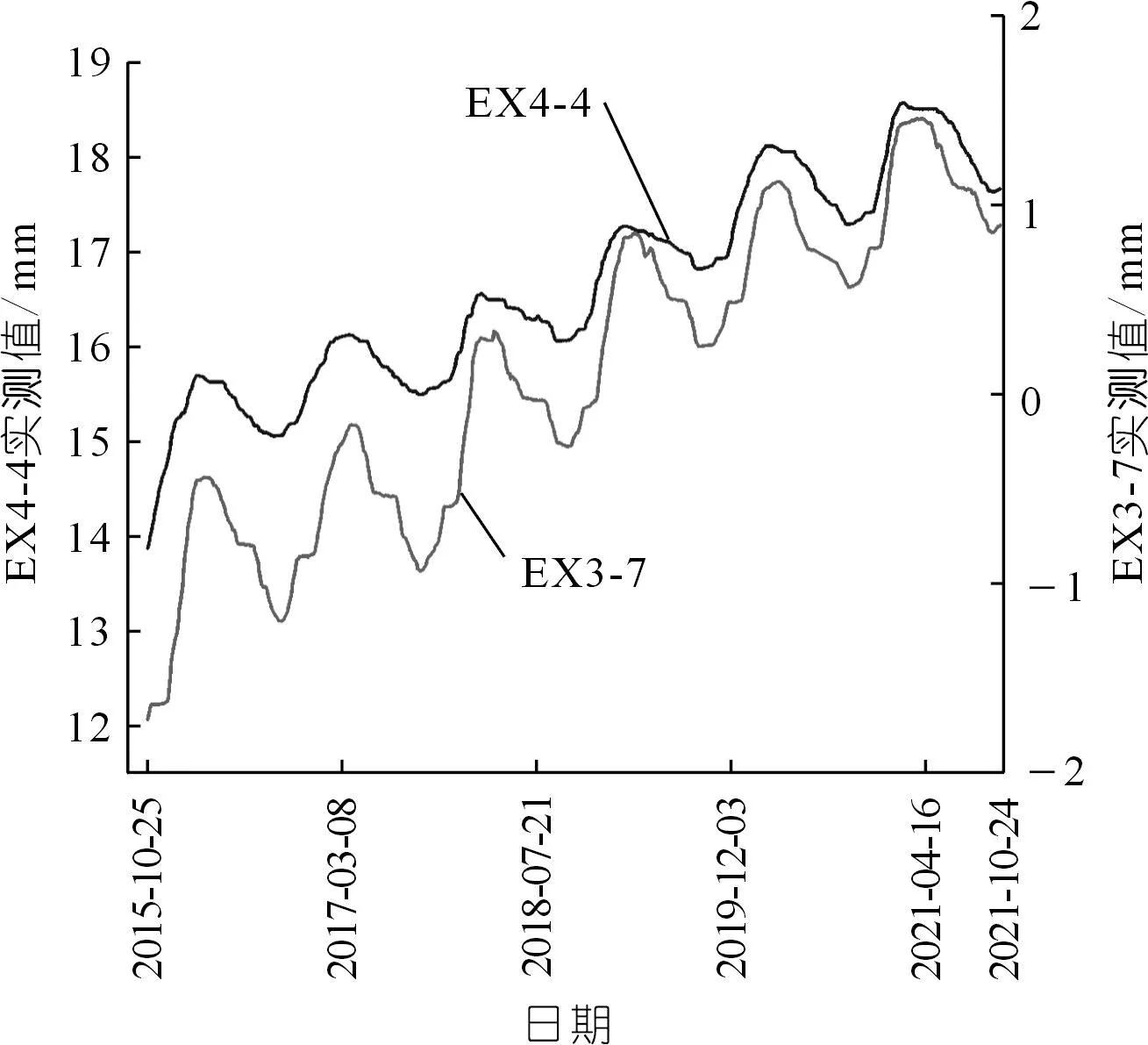
图3 测点位移时间序列Fig.3 Time series of measurement points displacereat
选用多种原理的预测模型应用于大坝预测,既包含需要影响因子的HST模型,也包含ARIMA等自回归模型,其中HST模型还分为线性模型、非线性模型及集成算法模型等,多种模型适配不同测点。本文选用常见的10种单一预测模型,分别为多元线性回归M1(Linear)、BP神经网络M2、支持向量机-高斯核M3(SVM-rbf)、差分自回归移动平均模型M4(ARIMA)、灰色理论M5、Lasso回归算法M6、岭回归M7(Ridge)、LightGBM模型M8、Xgboost模型M9和梯度提升树模型M10(GBDT)。
所用测点监测数据取自2015年10月25日至2021年10月24日,将其划分建模期、残差期、告警期和告警反馈期。其中2015年10月25日至2018年10月24日为建模期,2018年10月25日至2019年10月24日为残差期,得到1 a的预测结果,用于计算各模型的评价指标进而优选模型,以及得出各模型残差用于后面的告警。2019年10月25日至2019年11月24日得到这一个月以来各模型告警情况,2019年11月25日至2020年11月24日根据模型的告警情况,通过告警反馈调整算法权重。再结合滑动窗口模型,保持上述窗口大小不变,按步长为1向后平移近1 a,得到告警反馈期间内2020年11月25日至2021年10月24日的测点告警情况。
3.2 测点残差修正和模型优选
3.2.1模型残差修正
每个模型的残差值不会完全等于0,部分模型可能存在较大出入,故原始残差不能直接作为告警依据。在对模型预测结果进行数据指标评价之前,先对残差集内的预测值进行残差修正,使其残差大体上满足以0为均值的正态分布。通过计算出各个模型在此周期内的残差均值来确定模型的残差修正值。其中测点1的M1~M10各个模型的残差修正值分别为:-0.009,-0.004,0.052,0.036,0.091,0.118,0.100,0.026,0.060,0.027;测点2的分别为:-0.008,-0.011,-0.106,0.084,-0.021,-0.342,-0.029,-0.047,-0.114,-0.053。通过式(13)和(14)可以得到修正好的残差及预测值。以测点1为例展示并分析残差,残差期各模型的残差过程线修正前后对比如图4所示。
由图4可知,M3,M5,M6,M7,M9模型残差均值偏离0均值0.5以上,若直接使用残差落入两倍标准差外即进行告警,则会出现大量告警现象。以M3模型为例,在残差修正前,一半以上数据都处在两倍标准差以外区间,而残差修正后只有少数偏离较大的残差处在两倍标准差以外区间,如图5所示。经查阅预测期内大坝的运营管理和巡查日志,发现大坝性态均处于正常状态,因此残差期和告警期内的告警都为误告警,残差修正后的结果大大降低了误告警率,更加符合大坝坝体日常未告警性态。
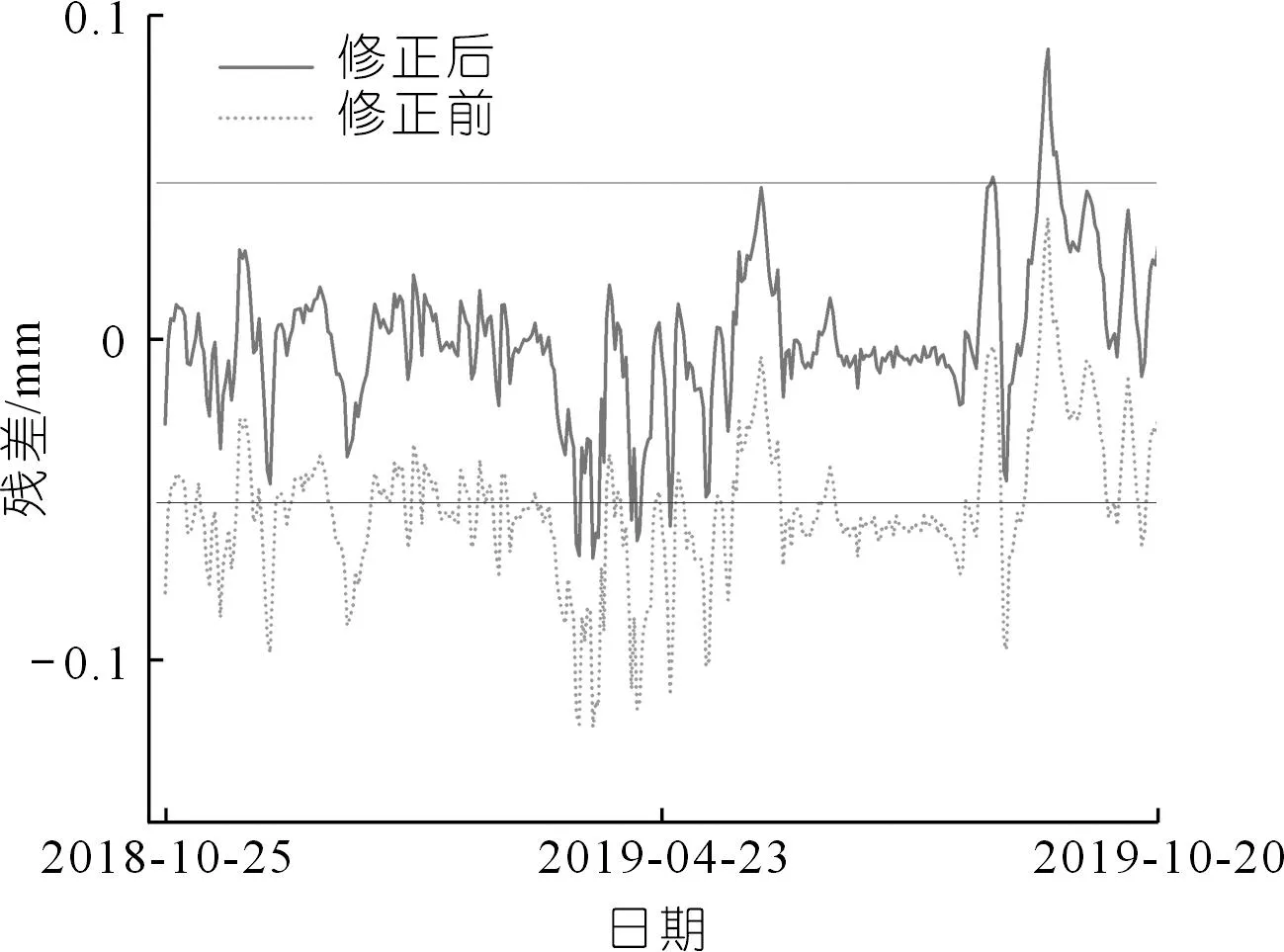
图5 M3模型残差过程线Fig.5 Residual process line of M3 model
出现上述现象主要有以下原因:① 数据分布和模型拟合的问题。部分线性回归模型是一种非参数回归方法,其中线性部分的系数是确定的,但非线性部分的形式并不是事先确定,而是从数据中学习。这种模型的主要缺点是比较久远的历史数据趋势可能会对新数据的预测产生错误的影响。② 残差周期选择的问题。选择时会出现模型在一个更大的周期上满足残差均值为0的情况,如果选择的周期太小,可能会导致残差呈现一定随机性。③ 影响因子的准确性。大坝是一个复杂的结构体,找到精准的位移影响因子仍是一个值得研究的问题。如果实测值的相关程度在该时段内有波动,则可能会导致模型预测误差过大。
针对残差修正后仍会出现告警现象的情况,进行进一步分析,图4显示告警主要分布在3月、9月和11月,分析主要有以下两点原因:① 环境量的剧烈变化。库水位有明显的上升和下降,主要原因是春季降雨、融雪和秋季降雨、河流水量的增加等,部分模型对环境因子变化的响应不够灵敏,以及位移达到新的极值出现的模型拟合问题导致的误告警。② 在11月份,位移基本保持平整,由于部分线性回归模型曲线呈整体上升或下降趋势,相对较大的位移变化速率导致模型出现较大偏差。
3.2.2模型优选
残差修正后,可以得到各模型修正后的预测值,两测点修正后的预测值在指标体系下的评价值如表2和表3所列。

表2 测点1各种模型的指标评价结果Tab.2 Evaluation results for each indicator of different models at measurement point No.1

表3 测点2各种模型的指标评价结果Tab.3 Evaluation results for each indicator of different models at measurement point No.2

取经验因子α=0.5,根据式(6)得到两测点各指标综合权重测点1的wj={0.13,0.15,0.15,0.30,0.27},测点2的wj={0.12,0.14,0.16,0.30,0.28}。根据式(10)得到10个预测模型的综合评价得分S,10个预测模型的多指标综合评价得分及排序如表4所列。
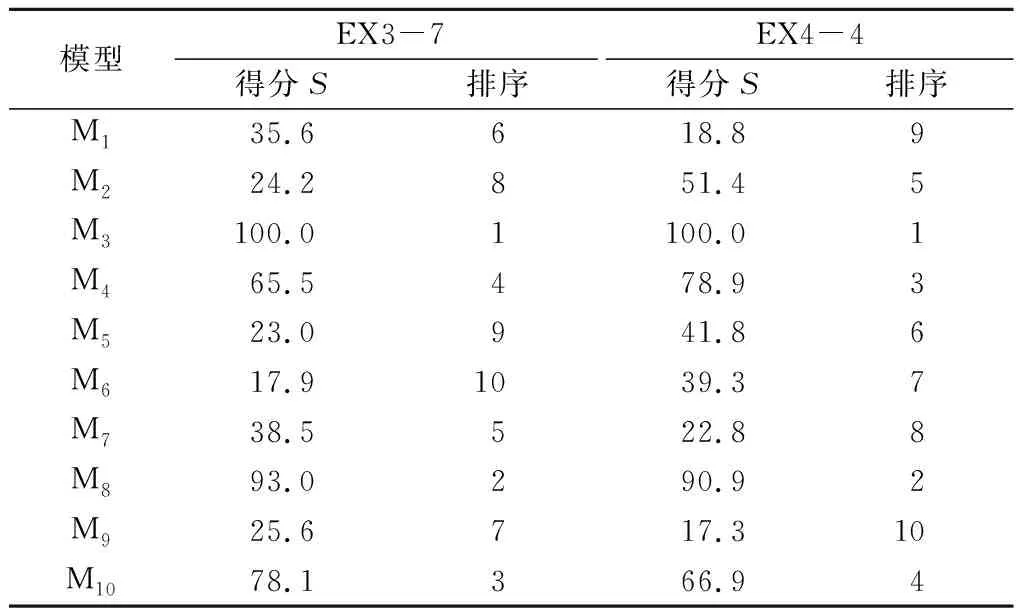
表4 告警状态与对应告警数值结果Tab.4 Alarm status and corvesponding alarm value
根据表3排序可以得到两测点排名前5位的优选模型分别为M3,M4,M7,M8,M10和M2,M3,M4,M8,M10。对优选出的5个模型按上述步骤重新进行权重分配,得到5个优选模型的初始权重值为{0.34,0.13,0.04,0.29,0.20}和{0.07,0.34,0.23,0.24,0.12}。
3.3 方案对比
根据是否考虑残差修正、动态评价指标调整权重和告警反馈调整权重,共提出5种对比分析方案,如表5所列。

表5 对比方案Tab.5 Comparison schemes
根据滑动窗口模型,再结合式(15)~(18),可以得到2019年11月25日至2020年11月24日内365个数据的告警数值分布情况。得到5种方案的告警数值区间分布及平均告警数值如图6~7所示。
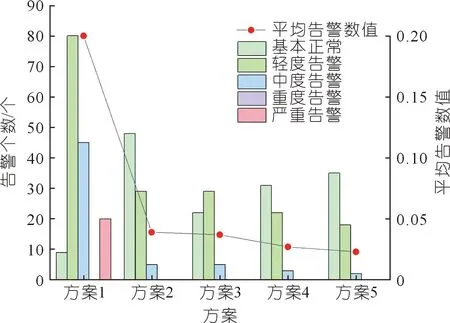
图6 测点1的5种方案告警情况Fig.6 Alarms of five schemes for measurement point No.1
使用告警数值区间法进行告警,是通过对各模型权重的调整,使得经常误告警的模型在综合告警时拥有较低的权重,以减少误告警模型对最终告警结果的影响,最终得到更符合实际情况的告警状态。
根据图6和图7综合分析可知:

图7 测点2的5种方案告警情况Fig.7 Alarms of five schemes for measurement point No.2
(1) 方案1未进行残差修正前,模型出现大量严重告警状态,与大坝真实性态不符。对于方案2的残差修正方法,方案2的告警率及告警等级明显降低,测点1中轻度告警级别及以上从145个减到34个,其中重度告警以上状态减至为0,平均告警数值由0.200减至0.039,表明考虑残差修正能够有效降低误告警频次。
(2) 在残差修正的基础上,仅考虑新的评价指标对模型赋予初始权重(方案3)或者告警反馈修改模型权重(方案4)两个中的单一因素时,与未考点这两种因素的方案2相比,两种方案基本正常个数明显降低,其中考虑告警反馈方案的轻度告警和中度告警个数也有明显降低,说明考虑新的评价指标对模型赋予初始权重或者告警反馈修改模型权重对测点告警情况的影响是有必要的。
(3) 同时考虑新的评价指标对模型赋予初始权重或者告警反馈修改模型权重,与考虑单一因素相比,在轻度告警和重度告警个数上均有明显降低,测点1的平均告警数值由0.037和0.027降至0.023,表明同时考虑两种因素对告警情况的影响优于考虑单一因素对告警情况的影响,说明同时考虑两种因素对预测是必要的。
(4) 对比不带告警反馈的方案2和方案3,考虑到告警反馈的方案4和方案5在轻度告警和重度告警中的个数上都有明显降低,基本正常占比略有上升,表明告警反馈系统能够有效地将部分虚假告警降至基本正常。随着考虑因素的增多,平均告警数值也呈整体下降趋势,测点整体异常率有明显降低,证明了方案的有效性。
4 结 论
(1) 根据大坝数据特征建立了一套适用于大坝测点的数据评价指标体系。除了常见的MAE等指标外,提出较大绝对误差数量(LAEN)评价指标,从多角度评价了大坝多个预测模型的表现情况,更加全面有效。
(2) 由于各种测点数据之间存在一定时空特性、各模型所适用数据的特征不同等原因,提出了通过残差修正和动态数据评价指标实时更改模型权重的方法。当单模型残差不符合以0为均值的正态分布时,进行残差修正使得告警更具有合理性和准确性;将滑动时间窗口模型与数据评价指标结合,实时反馈模型权重,使得在测点中表现更优的模型实时获得更高权重,模型告警更具合理性和准确性。
(3) 本文提出的告警反馈算法,不仅考虑到了模型的预测精度对告警结果的影响,而且考虑到了模型告警准确率的影响,并根据模型告警成功率实时调整模型权重。经试验证明,该告警反馈算法可以有效降低误告警率和告警级别。
