基于文本内容分析的互联网医疗平台信息质量评价研究*
2024-01-03王亚妮
王 君 姚 唐 王亚妮
(1北京航空航天大学经济管理学院 北京 100191 2首都医科大学燕京医学院 北京 101300)
1 引言
互联网医疗作为我国健康科技创新的重要组成部分,是互联网技术在医疗行业的落地应用。互联网医疗平台是以医疗健康信息交流为主的媒介,患者与医生可以通过其进行健康咨询、经验分享和交流互动等活动,对日常健康管理和疾病控制有着重要影响[1- 2]。目前国内比较知名的互联网医疗平台有“丁香园”“春雨医生”“好大夫在线”等。平台信息质量是影响互联网医疗可持续发展的关键因素。然而互联网医疗平台在提供便捷资源的同时,面临着医疗数据庞大、信息质量参差不齐等问题[3],影响患者信息浏览和健康决策。提高互联网医疗平台信息质量,帮助患者更好地利用平台管理健康并预防疾病,使互联网医疗服务更好地满足患者需求,对互联网医疗平台的可持续发展具有重要意义。
目前学术界有关信息质量评价的研究已有一定基础[4- 5]。在互联网医疗平台方面,主要围绕平台信息服务质量[6-7]、用户使用意愿[8]及用户满意度[9]进行研究。互联网医疗信息质量评价主要借助问卷调研[10]、专家访谈[11]等定性分析方法,采用文本内容分析法对信息质量进行评价的研究还比较欠缺。因此,本文基于国内典型互联网医疗平台数据,对用户发布的文本内容信息进行自然语言处理和聚类分析,提取信息质量评价的特征指标建立逻辑回归模型并进行灰色关联度修正,构建互联网医疗平台的信息质量评价指标体系,以期帮助互联网医疗平台构建合适的信息搜索规则、提高服务质量和效率,促进互联网医疗资源最大化利用。
2 资料与方法
2.1 数据来源
本研究聚焦“丁香园”论坛肿瘤医学板块用户主页的信息及其发布的帖子信息。于2021年9—12月基于Python的selenium库编写程序爬取肿瘤医学版块的29 300篇帖子及其评论,通过对帖子进行清洗过滤,获得有效帖子22 057条,涉及发帖用户10 725名。爬取的信息主要有文本型和数值型两类,帖子信息包括标题、内容、发表时间、标签、评论、浏览量和点赞数、收藏数等;用户信息包括昵称、职业、等级、积分、既往发帖链接、粉丝数、作品总浏览量、帖子被收藏总次数等。
2.2 数据处理思路
首先对文本内容清洗和处理,借助北京大学语言计算与机器学习组提供的pkuseg多领域分词库对文本信息进行分词和词性标注;借助哈尔滨工业大学自然语言处理实验室创建的停用词表、百度停用词表和基于词频统计的人工选择停用词方法对数据进行停用词去除;然后根据词频-逆向文件频率(term frequency-inverse document frequency,TF-IDF)生成文档向量并基于k-means聚类算法进行文本聚类,结合聚类后的关键词抽取确定文本类别;最后抽取信息质量评价指标,利用Python开源库statsmodels提供的统计分析方法实现逻辑回归模型并进行灰色关联度修正,构建信息质量评价指标体系,见图1。
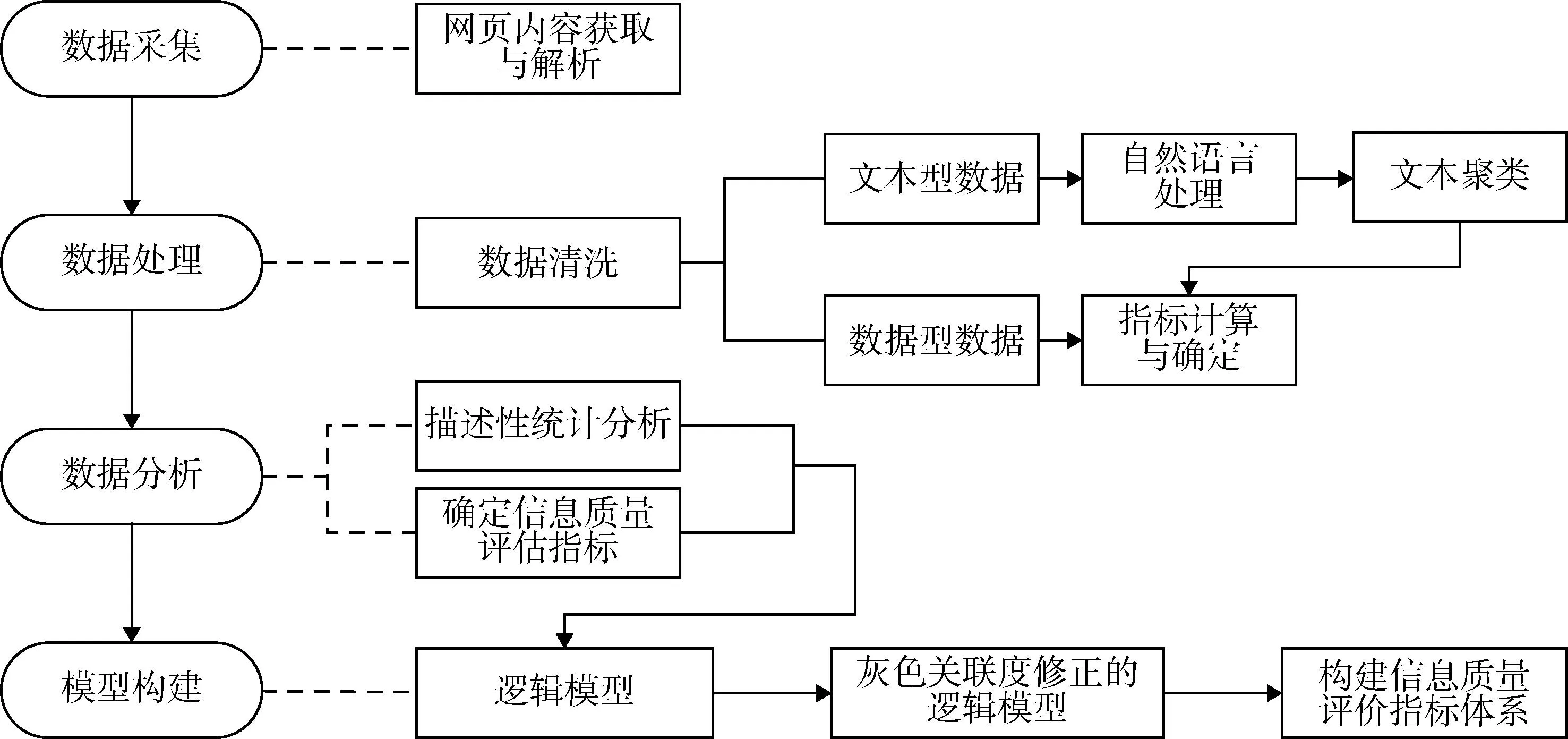
图1 数据处理过程
2.3 数据预处理
pkuseg分词工具致力于为不同领域数据提供个性化的预训练模型。用户可以根据分词文本领域特点,自由选择不同模型[11]。分词后,进行停用词去除。首先利用停用词表去除常规无用字词,接着采用词频统计方法人工选择进一步去除停用词,最后基于词汇词性标注去除介词、副词、语气词、叹词、拟声词等对于文本分析无用的字词。
2.4 聚类分析
聚类分析可以帮助分析文本信息的大致分类属性。采用向量空间模型对每一个文档都用向量dj表示:
dj=(w1,j,w1,j,…,wt,j)
(1)
文档向量的每个维度对应一个词组。通过TF-IDF方法计算文档向量各维度的取值,选取权重较大的前10 000个词组作为TF-IDF各维度对应词组,构建针对整个文档集的TF-IDF矩阵。并采用基于Python的numpy库的linalg.svd方法对TF-IDF矩阵进行奇异值分解,在尽可能保留文档信息的情况下选取r=300,得到原矩阵近似表示。TF-IDF矩阵近似表示如下:
(2)
其中,Ur矩阵是取U矩阵的前r列所得矩阵,Wr矩阵是取对角阵W前r个对角元素所得对角阵,Vr矩阵是选取V矩阵前r行所得矩阵。
利用构建的文档近似矩阵,采取基于sklearn库的聚类方法实现k-means聚类[12]。在随机选取初始聚类中心的前提下,不同k值的聚类算法运行结果对应的轮廓系数不同。k取值为6时对应的轮廓系数最大,因此k-means聚类k值设置为6。采用随机选取初始聚类中心并设定k值为6的条件将文档集聚成6类。对各类别文档进行词频统计,并根据高频词汇将各类别进行归纳。
2.5 指标提取及说明
借鉴医学信息和信息管理领域信息质量评价的相关研究,结合互联网医疗平台特征,选取一级指标和对应的二级指标,见表1。

表1 互联网医疗平台信息质量评价指标
2.6 模型构建
因变量为离散变量的计量模型称为离散被解释变量模型。在离散被解释变量模型中,逻辑回归模型因其具有简单、可并行化、可解释性强等特点而被广泛使用[13]。逻辑回归模型思想是使个体为某一类别的概率最大化,采用最大似然法进行参数估计。
灰色关联度分析是灰色系统理论中非常活跃的分支,其基本思想是根据各序列的相似程度来判断其之间联系是否紧密[14]。灰色关联度分析可以从多角度对物品质量进行评价,具有操作性强、效果好等优点。基于互联网医疗信息质量评价指标,采用逻辑回归模型和灰色关联度修正对影响信息质量评价的影响因素进行分析:
lnP=βXT
(3)
其中P为使帖子为高质量帖子的概率,β为系数向量,X为指标向量。
3 结果
3.1 数据处理结果
3.1.1 词云图展示 对文本进行分词和停用词处理后绘制词云图,见图2。词云图主要是对文本数据进行视觉表示,通过不同的字体大小和颜色展示每个词的重要性,便于读者迅速直观地了解词的重要程度和文本内容主旨。“丁香园”肿瘤医学板块的帖子及评论出现频次最高的关键词主要涉及肿瘤、资讯、发现、情况、免疫、治疗等,这些关键词都与用户的健康咨询、知识分享、病例共享等内容和服务密切相关。

图2 基于文本内容的词云图构建
3.1.2 聚类分析结果 共得到6个聚类结果。第1类高频词包含肿瘤、研究、细胞、治疗、免疫、患者、癌症、基因、临床等,称为医学研究;第2类高频词包括下载、指南、链接、翻译、临床、肿瘤等,称为知识分享;第3类高频词包括治疗、患者、肿瘤、化疗、药物、手术、转移、方案、检查等,称为治疗方案;第4类高频词有患者、癌症、治疗、食物、作用、饮食、化疗、营养等,称为患者养护;第5类高频词有肿瘤、治疗、临床、手术、医师、化疗、内科、患者、解剖等,称为医患交流;第6类包含许多无医学含义词汇,归为杂项。对聚类后各类别分布情况进行分析,治疗方案类帖子数量最多,医患交流类、知识分享类和杂项类帖子占比很小,见图3。
3.2 信息质量评价模型结果
在实证模型中,以帖子标签为被解释变量,提取到的二级指标为自变量,进行逻辑回归,见表2。其中系数指各自变量对被解释变量的影响系数。对模型的整体检验log-likelihood值为-4 032.2,说明自变量组合对被解释变量的影响具有统计学意义。在α=0.05的显著性水平下,除可读性(RE)、主题相关度(TS)及发布者粉丝数(AS_1)3项指标外,其他指标对信息质量评价的影响均具有统计学意义(P<0.05)。

表2 信息质量评价模型(一)
3.3 灰色关联度修正结果
对模型进行灰色关联度修正,见图4。灰色关联度值大于0.9表示指标间具有较强的相关性,基于逻辑回归的结果剔除完整性(CT)、可读性(RE)、信息量(AI)、主题相关度(TS)及发布者粉丝数(AS_1)变量,对数据进行第2次逻辑回归,见表3。结果显示所有变量均具有统计学意义(P<0.05),修正前后回归模型的拟合系数R2分别为0.284 6和0.278 5,均方误差相近,表明两次回归结果对样本的拟合效果相近。灰色关联度修正之后的逻辑回归模型如下:
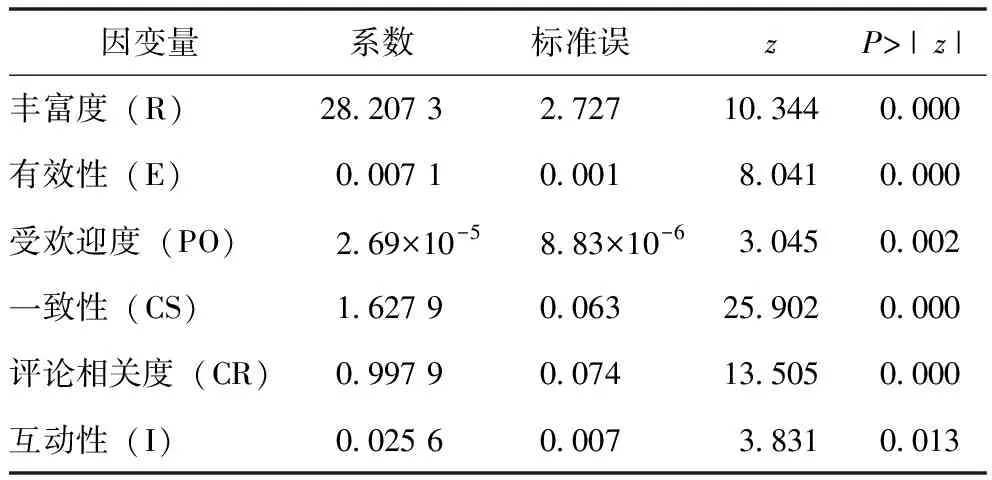
表3 信息质量评价模型(二)
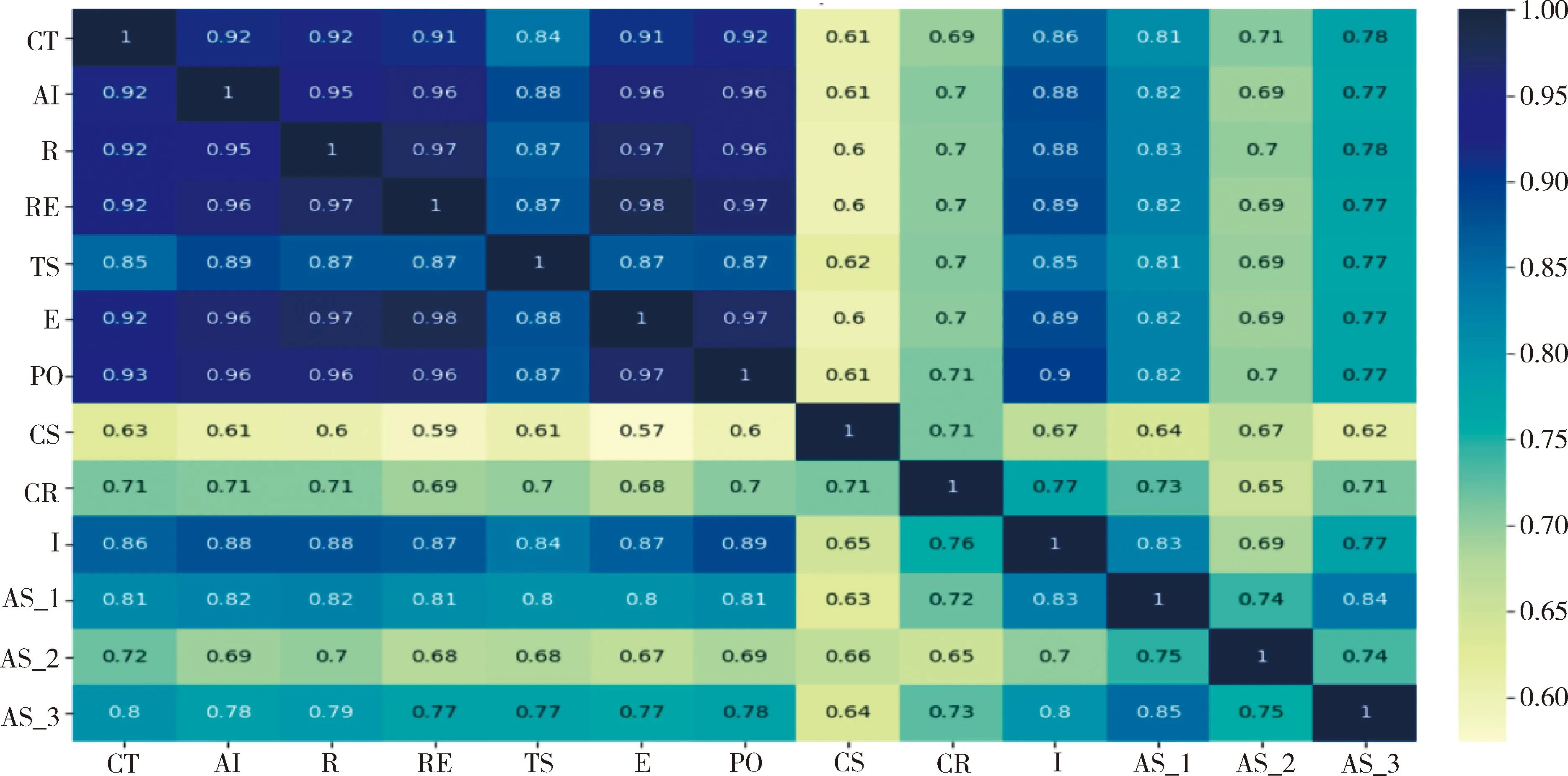
图4 灰色关联度分析结果
lnP=28.207 3×R+0.007 1×E+0.000 026 9×
PO+1.627 9×CS+0.997 9×CR+0.025 6×I+
0.121 8×AS_2-0.002 6×AS_3-2.791 4
(4)
3.4 互联网医疗平台信息质量评价指标体系
基于逻辑回归和灰色关联度修正的模型分析后的信息质量评价指标体系,见图5。

图5 互联网医疗平台信息质量评价指标体系
4 讨论
4.1 互联网医疗平台在发布信息时应注重信息呈现的丰富度
互联网医疗平台中的信息特征在其质量评价中具有至关重要的作用,且主要体现在信息的丰富度方面。信息形式是用户浏览时的直观印象,对于尝试在平台上寻求信息支持的患者来说非常重要。互联网医疗平台应当采取措施鼓励用户发布信息量大、信息丰富多样的帖子,吸引更多用户参与平台互动,信息呈现的丰富度直接决定信息被接纳的难易程度[15]。面对种类繁多的信息,互联网医疗平台发展不应局限于单一的文字信息形式,还可以发布如短视频、图片等有趣的信息吸引用户,让用户更愿意投入平台。
4.2 用户之间的交流互动有助于提升互联网医疗平台信息质量
互联网医疗平台上用户发布的信息被其他用户浏览并产生具体的互动如点赞、收藏和评论等行为时,此信息得到的正面评价会显著提升。用户之间的交流互动一方面使用户发布的信息被更多信息搜寻者知晓;另一方面,用户之间的交流互动也可以引导其他用户更精准、专业地贡献信息,平台用户作为医疗信息接收者的同时,也可作为信息提供者来分享知识,促进互联网医疗服务的发展[16]。用户的积极参与和交流互动有助于实现互联网医疗平台信息价值。
4.3 信息发布者的权威性是互联网医疗平台信息质量评价的重要因素
发布者的权威性是指发布者对该领域知识的掌握及专业程度,身份权威发布者的帖子更具有说服力,对于其他用户来说更有价值[17]。互联网医疗平台应注意采取适当措施控制用户积分的发放,因为当用户获得较高积分时,反而不利于其提供高质量信息。在信息过载时代,只有在源头保证信息质量,即确保信息发布者的权威性,平台中发布的信息才会有参考和借鉴意义。平台可以让浏览信息的用户对发布信息进行打分,再结合发布者的特征如年龄、受教育程度、患病时长等加权得到该发布者的总体权威性得分。
5 结语
本研究以国内典型互联网医疗平台为研究对象,借助Python网络爬虫获取数据,采用自然语言处理和文本内容分析对用户发布的帖子进行聚类分析和特征提取,并设计了基于逻辑回归模型和灰色关联度修正实验的互联网医疗平台信息质量评价指标体系,有助于用户发布高质量信息并快速识别有价值的信息,也将有助于互联网医疗平台构建合适的信息搜索规则,以及提高信息服务质量和效率。
