计算人文下的古籍引书研究及全文本知识库的构建
2024-01-03刘浏齐月刘雏菲李文祺王东波
刘浏,齐月,刘雏菲,李文祺,王东波
(南京农业大学信息管理学院,南京 210095)
0 引 言
中华典籍是中华传统文化的重要载体,加强文物和古籍保护研究利用是“推动中华优秀传统文化创造性转化、创新性发展”的主要途径。在数据科学和人工智能迅猛发展的当下,面向古籍文本的知识挖掘与知识库构建,以及古籍知识内容的数据分析与可视化视角展开的计算人文探索,已逐渐成为古籍保护和研究利用的重要主题[1],既是传承弘扬中华优秀传统文化的现代诠释,也是“让书写在古籍里的文字都活起来”的鲜活实践。
古籍引书是古籍计算人文研究的重要内容。古籍引书中凝结着先贤智慧的结晶,“引据大义,正之经典”,古人著书立言往往“旁征博引”以示学识之渊博,“咏古抒怀”以明立意之深远,“辨章学术,考镜源流”以求治学之严谨。卷帙浩繁的古籍以引书的形式彼此关联,源远流长的文化则在引书里留下传承印记。古籍引书研究作为对“引经据典”的追本溯源,有助于发现古籍中记录的思想发展源流,并从浩如烟海的古籍中梳理中华传统文化传承脉络。从文献学的角度看,古籍引书研究既可以通过考本源、辨支流的方法来厘清古代学术流派渊源,从而把握思想文化发展内涵,也可以提供广博的训诂、音韵、校勘内容,从而更准确地解释和理解经典文献著作;从史学的角度看,古籍引书研究可以充分搜集和利用旁证来解析相互矛盾之说,从而还原历史的真相;从图书情报的角度来看,古籍引书研究可以通过对大规模古籍文献资源的知识挖掘,实现古籍关联的数据分析和影响力的客观评价。古籍引书研究是传统文化传承研究的绝佳切入点,具备了较大的研究潜力和价值,将是弘扬中华优秀传统文化的有效助力。
计算人文时代的古籍研究以大规模数字化文本作为研究对象,以此为基础的古籍引书研究则借文本知识挖掘和引文分析方法呈现新的发展潜力[2-4]。从研究内容来看,不论是从结构化知识出发的量化统计分析,还是宏观视角的大规模网络关系发现,抑或是基于客观数据的古籍影响力衡量与评价,均需要更大规模的古籍语料、更智能的知识挖掘技术以及更高效的知识表示框架,古籍引书全文本知识库的重要性由此可见一斑。计算人文视角的古籍引书研究及全文本知识库资源构建,符合新文科尤其是图情学科当下发展的新趋势,契合“让中华文化展现出永久魅力和时代风采”。
1 计算人文下古籍引书研究的内涵和价值
古籍引书是古籍中“引经据典”的现象,也可以将其视为“古籍文本中的被引文献”,与文献计量学中的引文现象类似[3]。参考“引文分析”的定义[5],古籍引书包含了施引和被引的双向引用行为和现象,也可特指被引用的古籍,含义视上下文而定,因此,古籍引书研究同时关注引用现象和被引古籍。
例1.史記正義 虞喜志林云.南公者.道士.識廢興之數.知亡秦者必於楚.漢書藝文志云.南公十三篇.六國時人.在陰陽家流.
如例1所示,《史记正义》“虞喜志林云……”一句中,出现《志林》《汉书·艺文志》两部古籍之处,均可以看作引书现象。其中《史记正义》为施引古籍,《志林》《汉书·艺文志》为被引古籍,“虞喜”为被引古籍作者,“南公者.道士.识废兴之数.知亡秦者必于楚”“南公十三篇.六国时人.在阴阳家流”则为引书内容。从该定义出发开展的古籍引书计量研究[2-3],充分利用了文献计量学的数据解释力,相较于传统文献学擅长的列举和分析、考证和勘误,能得到更加宏观的分析和解释视角。这恰恰体现出计算人文[6]的特点,通过引书知识的自动获取、大规模计量分析和可视化数据结果呈现,为古籍引书研究提供了新的思路,也带来了大量亟待解决的技术问题。
计算人文视角的古籍引书研究以知识的获取和表示为基础,通过对古籍引书研究对象和技术框架的重点阐释,本文首先力图厘清计算人文下古籍引书研究的理论和技术内涵。古籍引书从现象上可分为明引和暗引,其中,明引可分为目录学典籍所引古籍题录和经学注疏文献所引古籍观点内容,暗引可分为史学典籍所引古籍事实观点和诗词歌赋所引典故,不同类型的古籍引书目的风格存在较大差异。厘清各类型古籍引书特点异同,是引书知识的表示、标注和知识库构建的基础,也是计算人文下古籍引书研究的前提。
1.1 古籍引书的类型
目录典籍引书可用于览全貌、考版本、辨源流,自西汉刘向《别录》、刘歆《七略》以来,后世历代目录编纂为概览当时的图书全貌提供了绝佳的对象,典型如《二十四史》中多部史籍的《艺文志》《经籍志》,宋代《太平御览》、明代《永乐大典》、清代《四库全书》《古今图书集成》等,其数字化的工作也早已得到了广泛的关注。从古籍引书研究视角看,目录典籍所引古籍包含了书目题录、版本卷册等知识,《四库全书总目》等还包含关于古籍主题内容、关联传承的简介摘要。书目题录等是知识表示和知识库构建的基础,也可作为古籍引书自动标注的外部知识,以提升深度学习等模型的性能。
经学注疏引书以解经义,并逐渐形成了引书规范,顾炎武《日知录》述为“凡引前人之言,必用原文”[7],清末陈澧进一步阐释为“说经之文与时文不同者,时文不能引书,说经之文,则必须有引书”,并总结出“引书法”规范十条,与现代学术引文规范异曲同工[8]。经学注疏的规范性使其成为古籍引书研究的绝佳对象,引据不仅包含出处、作者和原文,还兼顾观点评价、二次文献、共引评价等,以《十三经注疏》为代表的系列注疏文献还包含了注解疏解多层级的引用体系,也为计算人文下古籍引书的多视角对比研究提供了天然的知识来源。
史书引书以求史实,无引书不成史书,史籍中所含引书知识丰富程度不亚于经学引书,然而其所引形式多为化用暗引,一般难以通过格式化手段自动获得引书知识,借助自然语言处理前沿技术自动发现暗引内容并补全引书知识,可以成为史学引书研究的重要技术手段。进一步来说,史籍暗引研究与经籍明引研究相对应,在内容上可互为参照,在方法上可互为补充,如《史记》三家注、《三国志》裴松之注等重要史籍注疏文献,将是对两者进行对照考察的重要对象。另外,通史引书与断代史引书在研究对象方法上也存在明显差异,通史引书研究可关注史籍成书前各时代典籍动态关联或变化,而断代史引书研究则可更多考察某一时代典籍的静态面貌情况。
诗词歌赋引典以寓言、咏志和抒怀,引典虽然不是对古籍内容的直接引用,但从引用行为和引用效果来看,与引书十分相似,引典与引书均体现了古人“无一字无来历”的写作追求,可以将引典看作一类特殊的古籍引用现象。从古至今,诗词歌赋引典之丰富让人目不暇接,屈原、庄子的神话寓言,三曹与七子的建安风骨,引典以成诗文的同时,更成为后世所引之典,凝练在“庄生晓梦迷蝴蝶”“蓬莱文章建安骨”等传世佳句中。引典的传承造就了“中国盒子”式的艺术美感和文化内涵,更是中华民族文化绵延千年的灵魂,王勃引六百年前马援典故以抒“老当益壮,宁移白首之心?穷且益坚,不坠青云之志”,而一千三百年后的今人仍能感受其气魄,由此可见一斑。计算人文视角的诗词歌赋引典研究,视典故为所引对象,由于所引形式多为文学性的化用,少有固定的格式,因而标注难度较大。一方面,可以借用史书暗引自动发现相关技术;另一方面,也可以将其看作词汇语义知识,并使用古文信息处理中常见的词汇语义标注方法。值得注意的是,知识表示中的引典知识与引书知识存在较高的相似性,因此可将其视为古籍引书知识库的有效补充。
1.2 古籍引书研究与全文本知识库构建思考
古籍引书研究的重要性早已为经学、史学、目录、文献等学科所发掘,但由于技术方法的限制,多精于单部经典的释义考证,较少关注系列古籍间的交织关联,难以梳理出古籍引书源流的客观全貌,而这却是计算人文的优势所在。相较于传统的古籍引书研究,计算人文的视角包含了从获取到分析的一系列技术方法和应用探索,包括但不限于引书知识的表示和标注,引书知识的获取与引书知识库构建,基于文献计量和社会网络的引书分析和评价,以及基于全文本内容的引书情感分析、主题分析等。其中,全文本知识库的构建具有承上启下的作用,是古籍引书研究的核心内容。借由引文分析视角探索古籍经学引书的研究思路已得到初步尝试,立足学术全文本分析挖掘目录典籍引书、史书引书和诗词歌赋引典的研究设想也具备了成熟的技术基础。
古籍引书全文本知识库之于古籍引书计算人文研究,就像引文数据库之于引文分析研究,其构建过程还体现出对古籍引书内涵的深刻辨析和对前沿古籍文本挖掘技术的全面应用。知识库的构建需要对引书条目知识进行标注和表示,即文本中明确出现的书名、作者等,若以人工方法标注,则将耗费大量时间和人力成本;若以计算机自动标注,则对文本的格式化程度有较高要求。从古籍引书格式来看,目录典籍和经学引书相对规范,一般会在引用上下文中明确提及被引书名、作者和原文等,可称为古籍明引。史书引书较为隐蔽,如《史记》虽也有对《诗经》《论语》等经典原文的直接引用,但更多的是在著述过程中化用史料,并辅以增补和删减,较难在原文中直接找到明确规范的引书条目。诗词歌赋引典则更为灵活,一般以词语或短语形式化用被引内容,且文学性体裁更重修辞,难以直接借助格式自动获取。以上两者可称为古籍暗引。
古籍引书格式化程度的不同,面向明引和暗引的古籍引书知识库构建遵循的思路方法和技术难度也不同。对于前者,通过小规模人工标注,结合命名实体识别方法,构建机器学习模型,以实现计算机自动标注,这一思路可行性已得到前期研究的验证;后者则对古籍文本智能处理技术提出了较高的要求。值得欣喜的是,预训练框架下的深度学习为文本知识挖掘带来了技术飞跃,颇具影响力的Si‐kuBERT等古汉语预训练模型展现出良好性能的同时,进一步降低了技术门槛。面向隐藏在古籍字里行间的暗引,深度学习预训练模型分布式的文本语义表示能力,有助于实现更加准确的词汇级和句子级引书知识自动发现,使得面向暗引的古籍引书知识库构建不再是空谈。
古籍引书知识库不仅限于文本中引书知识的标注,还包含了引书知识的完善。对于所有的引书条目来说,除了引书上下文中标注的知识外,还应补充引书上下文之外的相关知识,这对于更深入的古籍引书研究来说必不可少。具体来说,与书名相关的有卷名、篇章名、注疏关系等,与作者相关的有朝代、师承、学派等。引书知识的补充可以参考多种来源的知识,如目录典籍引书中的“互著别裁”,经学引书中的“互参”,也可以利用引书知识标注文本进行自动补全。对于一些文本内容之外的知识,还可以通过人工方式参考专业文献、书籍或辞典来完成。全文本知识库也是对古籍引书相关全文本内容的涵盖,不仅包含了引书上下文,还包括了施引和被引古籍的全文本内容,以及引书上下文和全文本内容的对应位置关系和链接。此外,知识库还包含对全文本内容的词汇语义知识标注,以及后续待考察的情感评价、主题风格等,知识库的构建本身应体现出古籍引书研究的内容,并结合研究成果实现知识库的不断更新。
计算人文下的古籍引书研究同时也是全文本知识库应用的最佳方案。面向古籍引书知识库的统计计量和数据分析等计算人文研究,借助古籍文本知识挖掘技术,通过对古籍文本内容和关联知识进行结构化组织、数据化阐释和可视化呈现,有助于从新的视角认识和推动优秀传统文化的传承和发展,有利于降低专业研究成果的理解门槛,可助传统文化的教育、普及和推广。新视角下的古籍挖掘、应用与探索,是提升中华文化影响力的内在要求,是第二个百年奋斗目标下,增强文化自信力并推动中华文化获取世界话语权,让世界了解中华文明的精神魅力,并让世界理解和认可中国特色社会主义文化内涵的必然选择。
2 古籍引书知识库的技术前瞻
古籍引书全文本知识库的提出并不是空中楼阁,而是现有多个领域成熟技术和探索经验的有效结合。其中,以深度学习为前沿的古文智能处理技术保证了古籍文本的信息处理和大规模知识自动挖掘,以关联数据为代表的知识表示方法与知识库构建技术保证了古籍引书多维度关联知识的有效表示和存储,而古典文献学、史学、文献计量学以及人文计算等传统和现代的研究领域共同培育了古籍引书计算人文研究的应用土壤,使其成为一项具有独特潜力的研究领域,并逐渐得到学者的关注和探索[3-4]。
2.1 古文智能处理
古文智能处理是古籍引书全文本知识自动获取和组织的技术前提。作为一个颇具中国特色的交叉研究领域,古文智能处理是从古籍中挖掘中华传统文化知识的钥匙。古文智能处理可以看作自然语言处理和中文信息处理相关技术和方法在古籍文本中的应用和迁移,其根据古汉语词汇和语法等特点进行领域化的调整和改进,并以知识挖掘和提取为主要目的[9]。近年来,随着深度学习在自然语言处理中的逐渐成熟,古文智能处理的诸多研究问题开始全面转向深度学习的技术和方法,研究重心也逐渐从基础的自动分词、词性标注和命名实体识别等研究,延伸至知识库建设等更复杂的领域[10]。随着深度学习在预训练模型下引领自然语言处理进入新的发展阶段,古文智能处理领域也跟进了较有影响力的SikuBERT预训练模型[11],有望成为古文智能处理的新标杆。
较之前期的机器学习方法,深度学习下的表示学习能够从文本语料中自动学习得到词语的分布式表示特征,不再需要额外的特征工程,古文智能处理在当下也越发关注更大规模的古籍对象以及更复杂的知识挖掘任务。古籍引书全文本知识挖掘是对现有古文智能处理前沿技术的全面应用以及对技术边界的拓展,目前以深度学习预训练模型为前沿的古文智能处理技术集中于序列标注任务,尚未在古籍文本主题分类、词义分析、情感分析、内容生成等任务中得到较多尝试和验证,而这恰是古籍引书全文本知识挖掘的基础,值得深入探索和解决。
2.2 知识表示及知识库构建
知识表示是古籍引书全文本知识库构建的主要内容,其关注以何种形式表示古籍引书知识和相关属性以及知识之间的关联。目前,最成熟的知识表示框架源于Berners-Lee等提出的语义网[12]及后续的关联数据[13],并在谷歌提出知识图谱[14]后得到了广泛的认可。源于语义网的知识表示框架以RDF(re‐source description framework)为基础,其自提出至今不断更新和修改,形成了围绕三元组资源表示的语言规范[15]。作为语义网的发起和维护组织,W3C(world wide web consortium)面向逐渐复杂的知识表示需求,在RDF基础上制定了包括知识建模词表RDFS(resource description framework schema)[16]、序列化的表示语言Turtle[17]、关联数据表示方法JSON-LD(JavaScript object notation for linked da‐ta)[18]等,同一框架下的OWL(web ontology lan‐guage)语言[19]和后续更新的OWL2语言[20]则成为专门的知识本体表示规范。国内外重要的知识库,如DBPedia、Schema.org、OpenKG和CN-DBPeidia等,均以语义网作为知识表示框架,随着知识检索、知识问答等人工智能应用的不断探索,知识库越发重要的资源价值也得到了更多领域和学科研究者的重视[21-23]。
语义网框架在本体构建、知识表示等多方面为古籍引书知识表示提供了较为完整的语言描述方案。对于古籍引书相关的古汉语研究、中国古代史研究、古代目录文献研究、古籍计算人文研究等领域来说,基于《十三经注疏》《二十四史》等经学、史学系列古籍构建的古籍引书全文本知识库,可作为数据资源供相关研究者参考和使用。该知识库以古籍引书本体为知识表示基础,以RDF、OWL及Schema语言为框架,能够与主流知识图谱资源相对接,且以关联数据形式构建结构化古籍引书知识,包含作者、书名、朝代、内容、主题等多方面的属性,也包含各属性之间的引用、相似、继承、反对等多维关联,并能够支持知识检索和知识问答,能够提高古籍目录研究、古籍版本研究、古籍散轶内容整理等大量相关研究的资源利用效率。
2.3 计算人文研究简述
古籍计算人文[6],也可称为“人文计算”或“数字人文”,是当下令人瞩目的研究热点,相关研究发展历程和趋势对本文的古籍引书知识库的应用研究具有重要的参考意义。大致起步于20世纪80年代的国内计算人文以陈炳藻[24]关于《红楼梦》作者的讨论为代表[25-26],其研究和发展方向以计算机和信息技术为主要导向,并以面向古籍的历史GIS(geographic information system)[27]和典籍数字化[28]研究最为鲜明。随着自然语言处理技术的推进,计算人文得以将焦点从文本数字化逐渐转向文本内容。数字人文这一表述的火热激发了学者们对这一领域更深层的思考和讨论[29],在人文与技术交叉现象的背景下,人文对象、人文问题乃至人文学科的重要性越发得到了重视[30],以中华传统文化探寻为线索的古籍计算人文研究也迎来了新的发展契机。一方面,基于古文智能处理技术的古籍文本内容和知识挖掘如火如荼,词法分析[31]、实体识别[32]、自动句读[33]等领域和问题均取得了显著的进步,而知识组织和知识库建设也逐渐成为领域内持续性研究的前提,典型代表有支撑唐宋时期历史人物探索的中国历代人物传记资料库(China Biographical Data‐base,CBDB)[34-35],以词法分析和实体标注为主要内容的《资治通鉴·周秦汉纪》知识库[36],面向历史事件结构化检索的《史记·列传》知识库[37],面向农史的方志物产知识库[38]等。
古籍计算人文研究以文本知识挖掘和知识库构建为桥梁,可助跨越古籍文本所固有的语言知识和字符技术门槛,其成为近年来的研究热点是得益于知识库构建技术的蓬勃发展。古籍计算人文研究对于知识库的应用集中于知识的统计分析和可视化呈现,因而对知识库的结构化程度要求较高,而基于语义网框架的知识库构建恰好能够满足这方面的应用需求;另一方面,古籍引书的计算人文视角能够以更加直观、朴素的方式切入传统文化,通过数据分析技术获得更加客观、简洁的研究结论,并以数据可视化的形式呈现出来,从而更契合研究成果的教育普及和大众推广,将传承弘扬中华优秀文化落到实处。
2.4 古籍引书研究回顾
古籍引书是中国传统文献学的重要研究对象,其主要通过对引书内容的校勘考证,“正本清源”以帮助人们更好地理解古籍经典。从对象来看,古籍引书研究主要关注对古籍经典尤其是“四书五经”的引用,相关研究可以按古籍引书类别进行简单划分。面向古籍辞书的引书研究以《尔雅》《说文解字》等最为常见,一般通过校勘和考证理解古籍经书中的字词句义。儒家经典也是古籍引书的重要研究对象,《诗经》被引最为常见,相关研究多以《诗经》背后蕴含的文化传承价值为主要内容[39],其他先秦儒家经典,如《尚书》[40]、《礼记》[41]、《论语》[42]的被引现象均得到了充分的关注,《春秋》引书研究则更多是对相关注疏所引其他古籍的考察[43]。还有研究专门以系列经书如“五经”或者“十三经”为对象,以求考察引书现象的全貌[44]。值得注意的是,虽然发现和整理的难度较大,但古籍暗引的现象仍然得到了一定的探索[45]。可以看出,传统的古籍引书研究主要通过人工文献查阅检索,凭借个人主观理解来解读和评价引书内容,也有少数研究直接关注引书背后的文化传承现象,而基于大规模知识库的数据分析和计算人文研究尚未得到太多关注。
古籍引书研究对经典的考察日臻全面、深刻,研究对象也逐渐延伸至特殊体裁的文献以及相对冷僻的古籍。古籍引书研究方法对引书现象及其背后思想价值和文化内涵的把握和剖析较为深刻,然而大规模古籍引书之间的复杂关联是传统研究方法所难以企及的,其背后隐藏的文化传承线索仍值得深入探究和挖掘。计算人文引入了数据计量与统计分析的视角,并以客观、细实的研究结论充实现有古籍引书研究。总的来说,该研究以古籍引书知识库为基础,结合引文分析等方法,静态地判断和评价古籍引书的影响力,动态地描绘古籍引书的生命周期,观察系列古籍引书间的关联全貌,发现少量古籍引书间的相互关系,从全文本分析视角下挖掘古籍引书文本内容,对古籍引书主题和情感进行探索,发掘潜藏在古籍引书字里行间的文化矿脉。
3 古籍引书全文本知识库构建框架
知识库在古籍引书计算人文研究中的重要地位已毋庸置疑,然而其具体技术框架仍需充分考虑古汉语典籍文本以及古籍引书研究的各种特殊之处,这也是保证计算人文研究深度和广度的重要前提。古籍引书全文本知识库的构建以引书知识的本体构建和知识表示为基础,以引书知识的人工标注和自动发现为主要过程,以全文本标注语料库、关联数据库、深度学习模型库为主要内容。本节围绕上述环境阐述古籍引书全文本知识库构建的主要框架。
3.1 古籍引书知识表示
古籍引书全文本知识库以W3C知识表示体系作为技术基础,使用RDF与OWL知识表示本体作为出发点。古籍引书本体关注古籍引用行为,面向史书引书和经学注疏引书两类古籍引书对象,明引和暗引两类古籍引书行为,围绕古籍的著录知识、引书内容等属性,引用关系、著录关系、人物关系等关系,并补充古籍引书全文本分析和数字人文研究所关注的引书计量分析数据和影响力评价指标等。具体来说,该本体将设计包括但不限于书籍、作者和引用条目三大类实体,题名、成书朝代、四部类别、思想学派、语言风格等属性,篇章包含、直接引用、间接引用、暗引、情感评价、作者师承、内容关联性等关系。这阶段力求准确、完整地将古籍引书相关的对象、行为、属性、关系、计量评价、主题内容等知识表示在同一个本体中,为后续相关的知识标注、知识库构建以及计算人文研究提供可靠的知识来源。
基于OWL本体表示框架,使用protégé工具[46]设计古籍引书本体,图1展示了古籍引书本体基本框架。具体来说,该本体设计了古籍引书对象、古籍引书作者和古籍引书条目三大类实体,并围绕实体构建了七大类关系用于表示引用关系和著录关系,描述了六种属性用于补充古籍引书相关的其他知识,如朝代、被引频次、引书内容等。古籍引书本体的设计和构建先于知识标注和知识发现,但应在此过程中逐渐完善,并在知识库构建和后续应用研究中得到完整体现。
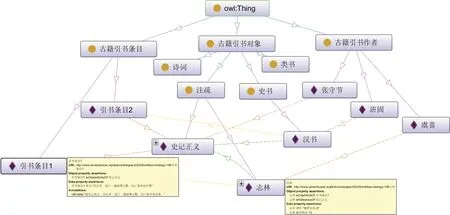
图1 古籍引书本体示例(基于protégé)
RDF和OWL语言的优势在于可以将本体知识表示为XML格式的文本序列化格式,如图2所示。这样可以与序列化标注的文本对接,高效地利用人工和自动标注得到的古籍引书知识,并快速、准确地构建超大规模的古籍引书本体和知识图谱。以RDF和OWL语言为基础,可以进一步扩展更新至W3C体系下的JSON-LD或Schema知识表示框架,从而与现有的主流知识图谱和知识库资源对接,使古籍引书本体得到更广泛的推广和应用,并有助于该领域得到更多的关注。除此之外,古籍引书本体还支持SPARQL查询语言,可以兼容知识查询和推理等进一步的应用探索。

图2 古籍引书本体的RDF/OWL序列化表示示例
3.2 古籍引书知识标注
构建古籍引书全文本知识库需要面向古籍文本进行标注,以得到本体描述框架中的古籍引书相关实体、属性和关系等。古籍引书知识标注须以人工标注工作为基础,辅之以机器学习模型,从而实现超大规模语料库的知识标注。人工标注一般需制定标注规范以保证标注的一致性,且该规范应与古籍引书本体相对应,以保证面向文本的标注结果可以自动转换为序列化的RDF和OWL语言。基于上文的古籍引书知识本体,可以初步设计一个包含六类实体、十六类关系的知识标注规范,其中实体包括引书名称、引书内容、引用作者等,部分关系如表1所示。
2.PD1抑制剂:程序性细胞死亡蛋白-1(PD1)/CD279是一个CD28家族的共抑制分子。它主要在活化的CD4+和CD8+T细胞及Tregs细胞表面表达,也可以在活化的B细胞、NK细胞、单核细胞和特定的树突状细胞表面表达。PD1可以与其配体PD-L1和PD-L2相结合,参与调节外周T细胞的耐受性,导致T细胞增殖降低,使其失活并凋亡,形成免疫抑制的微环境。PD1抑制剂的代表性药物是Nivolumab和Pembrolizumab,目前已经在恶性黑色素瘤、肾细胞癌、肺癌等肿瘤的研究中有阳性结果。

表1 古籍引书标注规范示例
在标注规范的基础上,可借助BRAT[47]标注平台实现古籍引书知识的人工标注。BRAT是一个开源的可视化标注平台,可以搭建在服务器上通过客服端访问,实现多线程同步标注,极大地提高标注效率。BRAT支持自定义标注规范,并支持程序设计以实现在自动标注基础上的人工校对,同时标注结果可保存为序列化形式,以便于与语义网RDF和OWL语言的自动转换。图3展示了本文引言中例1所含引书知识的标注结果,该结果包含了实体和关系两类,格式如表2和表3所示。
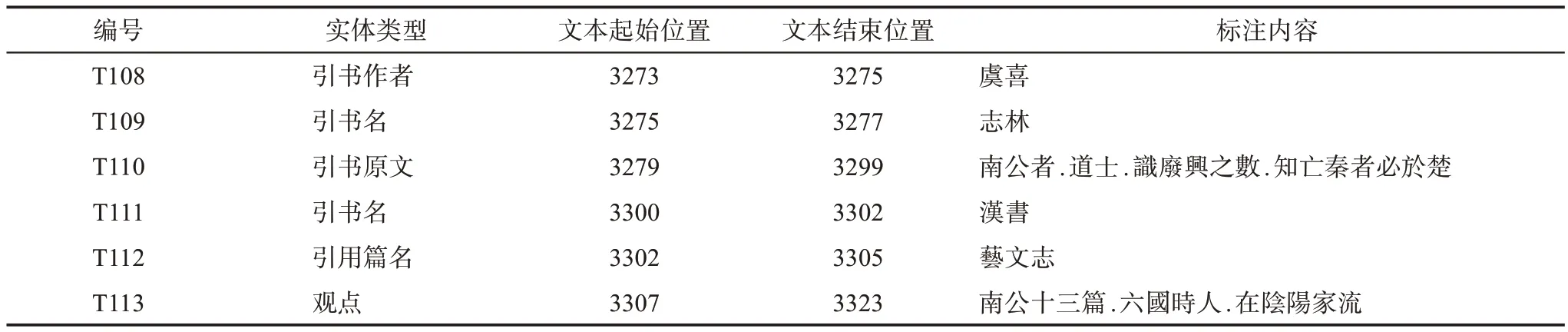
表2 古籍引书知识标注格式(实体部分)

表3 古籍引书知识标注格式(关系部分)

图3 BRAT下古籍引书知识人工标注示例
同时,序列化表示的人工标注结果易于转换为机器学习序列化标注模型所需要的训练语料,因此,各类引书知识可以通过命名实体识别、实体链接、文本分类等任务来实现大规模自动标注。仍以本文引言中例1为例,“虞喜志林云.南公者.道士……”一句在序列化标注模型中的表示形式如表4所示,在这一模型中,可以将引书作者、引书名、引书内容视为不同类型的命名实体,并使用Siku‐BERT和SikuRoBERTa等古文预训练模型构建深度学习下的命名实体识别任务,以实现多类别古籍引书知识的自动标注。而对于“南公者……”“南公十三篇……”两处引书内容,则可借助文本分类模型将其自动区分为引书原文和观点。图4展示了深度学习下使用句子分类任务的模型框架,其核心是通过神经网络模型自动学习得到引书内容的向量表示,再结合句子分类模型来判断引书内容的具体类型。

表4 序列化标注模型中的古籍引书知识表示

图4 深度学习下的引书内容自动分类模型框架
值得注意的是,深度学习模型还可用于暗引内容的自动发现。图5展示了深度学习下的古籍暗引知识发现技术框架,基于孪生网络模型这一神经网络耦合架构,可以同时获取两个句子的向量表示,并在高维空间中比较两个句子向量的相似程度。由此可以判断某一句子是否为古籍暗引的内容,实现古籍暗引内容的自动发现。
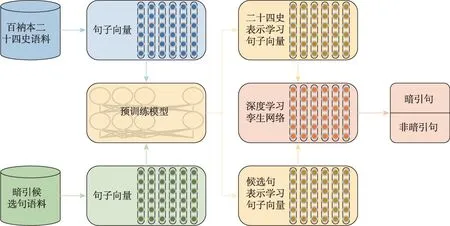
图5 基于孪生网络模型的古籍暗引知识发现技术框架
3.3 古籍引书知识补全与消歧
对古籍引书知识进行人工和自动标注后,即可将其自动转换为本体知识表示所需的各类序列化文本格式,但若要以此为基础实现完整的古籍引书知识库构建,还需对标注内容做进一步的补全和消歧,以保证知识的完整和准确。在例1中,“虞喜志林云……”一句可标注为一例引书实例,其中“虞喜”标注为引书作者,“志林”标注为引书对象,“南公者……”标注为引书内容,“汉书艺文志云……”一句可标注为另一例引书实例,其中“汉书艺文志”标注为引书对象,“南公十三篇……”标注为引书内容。此外,文本中引书知识之间的关系也已标注。不难发现,由于标注知识直接源于古籍文本内容,因此,仍有部分知识需要额外补充,如古籍《志林》的类型,虞喜所处朝代,《汉书》与《艺文志》之间篇章关系,《汉书》作者知识及所处朝代等。这部分引书知识的补全可以借助上下文标注知识相互补充,如此处“虞喜志林云”标注出《志林》的作者为虞喜,上下文中若单独出现《志林》,则可以据此补充其作者“虞喜”。此外,也可以借助《汉语大词典》等外部知识以人工方式补全。
同时,标注得到的引书知识之间可能存在指称歧义,主要是古籍书名的同书异名和同名异书歧义[48],如《诗经》和《诗三百》。此外,还有数量繁杂的缩略名、别名现象,如《左传》与《春秋左传》《春秋左氏传》《春秋左氏》《左氏传》等。古籍引书知识库构建之前,需对引书对象即古籍书名进行有效的歧义消解,以保证知识库中实体指称的唯一性。引书名的歧义可以借助上下文和外部知识进行人工消解,也可以利用自然语言处理中的实体链接等方法进行自动消解。
4 古籍引书全文本知识库构建初探
本节从经学引书、史书引书、文献目录学引书和诗词歌赋引典四个方面,结合研究实例进一步描述古籍引书全文本知识库构建的具体流程,古籍引书知识表示本体、知识标注技术以及知识补全和消歧方法已在上文详细说明,因此,本节不在额外赘述具体过程,只在必要时做出补充,并具体阐释各知识库构建时的特点和难点。此外,本文在第5节进一步讨论知识库的应用前景,并在后续研究中对各类知识库的构建和应用进行拓展。
4.1 经学引书全文本知识库的构建——以《论语注疏》为例
《论语注疏》作为《十三经注疏》之一,是注疏典籍中的经典,也是经学引书研究的代表对象。《论语注疏》成书于北宋时期,以魏晋何晏注和北宋邢昺疏为主体,引据典籍自先秦至隋唐,类型丰富,是儒家学说思想传承脉络的重要载体。
《论语注疏》引书时,大量使用作者的姓氏来指代其《论语》相关著作,如其序所言,“今謂何晏時.諸家謂孔安國.包咸.周氏.馬融.鄭玄.陳羣.王肅.周生烈也.集此諸家所說善者而存之.示無勦說.故各記其姓名.注言包曰馬曰之類是也”。
该书所引上述诸家著作形式一般为“郑注云……”,其中“郑注”即郑玄所著《论语注》。其他经典文献,如杜预《春秋释例》、王弼《老子注》等,也使用作者名指代。对于这类引书条目,标注了引书作者和引书内容后,可以补全作者名、引书名等知识。而对于同一作者的不同著作,《论语注疏》引书时会有明确区分,如用形容“郑注尚书……”明确区分于郑玄《论语注》,避免了歧义。
《论语注疏》引书中还有一类重要的引书现象,形如“丧服四制引书云……”,即以《丧服四制》引用《尚书》的内容作为引书内容,类似于科学引文分析中的二次引用,是儒家经典传承脉络的直接体现,对于散轶古籍的自动整理和还原也大有裨益。对于此类引书条目,标注引书名的同时,需进一步标注其引用关系,以供引书知识的完整表示和知识库的构建。此外,《论语注疏》中同一处引书条目下会出现多次引用现象,此时除首次出现的引书名,其余均会被省略引,如“晋灼曰……又曰……”,该例中前后两处引书内容均出自晋灼《汉书集注》,后一处引书内容虽无法标注出引书或引书作者,但可以通过引书关系表示这类多次引用现象。
本文结合《论语注疏》的上述引书特点,利用古籍引书知识表示本体和古籍引书标注工具,通过人工标注和补全、消歧完成了《论语注疏》引书知识库的构建。该知识库包含引书条目1680条,如表5所示。

表5 《论语注疏》引书知识库示例
4.2 史书引书全文本知识库的构建——以《史记三家注》为例
《史记三家注》是《百衲本二十四史》所采用的《史记》版本,作为我国第一部纪传体通史,历代为之作注者众多,然而现在大多都已亡佚,唯有南朝宋裴骃的《史记集解》、唐司马贞的《史记索隐》和张守节的《史记正义》被保存了下来,合称《史记三家注》。三者的成书时间不同,在注释的侧重点和完善程度上也有所差别,其中包含的引书知识十分丰富宝贵,对于古籍引书研究以及古代历史研究都具有重要的价值。
《史记三家注》中,《史记集解》成书时间较早,因此《史记索隐》有时还会直接对《史记集解》的引书进行注解,从而形成更为复杂的引书现象,例如:
【集解】皇覽曰.蚩尤冢在東平郡壽張縣闞鄉城中.高七丈.民常十月祀之.有赤氣出.如匹絳帛.民名為蚩尤旗.肩髀冢在山陽郡鉅野縣重聚.大小與闞冢等.傳言黃帝與蚩尤戰於涿鹿之野.黃帝殺之.身體異處.故別葬之
【索隐】按.皇甫謐云.黃帝使應龍殺蚩尤于凶黎之谷.或曰黃帝斬蚩尤于中冀.因名其地曰絕轡之野.皇覽.書名也.記先代冢墓之處.宜皇王之省覽.故曰皇覽.是魏人王象.繆襲等所撰也
其中,《史记索隐》对《史记集解》所引《皇览》的由来进行了解释。从古籍引书视角来看,可以认为上述两处引书条目都引用了《皇览》,而《史记索隐》对《史记集解》所引《皇览》还存在二次引用的关系,而这一现象可以通过文本格式自动抽取得到。
《史记三家注》引书内容极为丰富,存在大量散轶、难考的古籍,同时异名现象十分丰富,本文为此参考了《史记三家注引书索引》《史记索隐引书考实》等研究专著予以补充和完善。由于引用书目种类繁多,在完成引书知识补全和消歧后,本文以“书名首字拼音的大写字母和书名顺序的数字编号”为规则,为每部引书制定了唯一的编号,并以此为基础构建了引书知识库,如表6所示。

表6 《史记三家注》引书知识库示例
4.3 文献目录学引书全文本知识库的构建——以《四库全书总目提要》为例
《四库全书总目提要》(以下简称《总目》)是清代纪昀等为《四库全书》编纂的目录,包含了丰富的古籍目录、传承、版本相关知识,在规模、体制、编制能力等各方面均为历代之最。本文不仅关注《总目》的目录知识,还从古籍引书的视角进一步表示出其正文中出现的所有书目知识。以此为线索构建知识库可以完整地表示《总目》的核心内容,并为引书计量等后续研究提供可靠的资源。
《总目》引书以别称和缩略最为常见,因此,书名的同名异指和异名同指现象较为丰富,需要进行充分的消歧处理。异名同指即同一对象具有多个别称,常见于注疏文献,与经学引书中所见歧义相似,如《毛诗正义》又称《诗正义》《毛诗》或《毛传》。同名异指即多个对象具有同一个名称,这在本文经学引书中并不常见,或源于《十三经注疏》的编写体例和规范。但《总目》引书对象时间跨度大、类型范围广,因此存在较多同名异指,如《易传》一名可指“十翼”,也可指《程子易传》《朱子易传》《东坡易传》等共8部典籍。因此,《总目》引书知识标注中需要对两类歧义进行重点消解。
此外,《总目》在书目的提要内容中大量引用了典籍篇章名称用于解释书目源流。例如,在《周礼注疏》条目下有“故建都之制不與召誥洛誥合.封國之制不與武成孟子合.設官之制不與周官合.九畿之制不與禹貢合云云”。其中,《召诰》《洛诰》《武成》《周官》《禹贡》皆为《尚书》篇名。因此,知识标注和知识库构建时需将篇章从属关系表示完整。
本文标注《总目》全文共得到64766处引书实例,消歧后共24185种引书实体,除了通用的作者、朝代知识,还包含《总目》特有的收录形式、部类、版本、卷数等知识,具体如表7所示。

表7 《四库全书总目提要》引书知识库示例
4.4 诗词歌赋引典全文本知识库的构建——以《唐诗三百首》为例
《唐诗三百首》是唐诗研究的重要对象,唐诗引典也是古诗词研究尤其是诗词翻译研究的重要领域,因此,适合作为知识库构建的对象。一方面,诗词引典从用法和目的上均与古籍引书存在一定区别,引用对象十分灵活,既可以是人物生平、历史事件,也可以是其他古籍、诗词或成语。虽然知识标注仍可以沿用实体标注技术和工具,但知识补全需要进一步做分类处理。另一方面,诗词较之一般古籍内容结构较为特殊,一部典籍所收每首诗虽可看作篇章或者段落,但从引典的角度来看,将其作为单独的作品对待更好,这样才能对不同诗词的引典现象进行对比分析和研究。因此,诗词文章引典的全文本内容无需像古籍引书那样构建倒排索引库,可以直接作为引书条目对待。具体的知识库构建如表8所示。

表8 《唐诗三百首》引典知识库示例
5 古籍引书全文本知识库的应用浅析
作为计算人文下古籍引书研究的技术和资源基础,古籍引书全文本知识库具有诸多应用领域和前景。
5.1 古籍引书计量分析和影响力评价
一方面,以古籍引书知识库为基础,利用引文分析和评价的思路和方法,可以对古籍引书进行计量分析和影响力评价,这也是计算人文下古籍引书研究的主要内容。具体来说,围绕古籍引书计量数据,从成书朝代、古籍类型、思想学派等多个维度进行古籍引书计量以获取高影响力古籍;利用G指数等作者评价指标,可以对古籍作者,如史学家、经学家进行影响力评价;参考半衰期等计量指标,可以考察先秦古籍尤其是儒家经典的持续影响力及影响力年代分布,还能从篇章角度进行对比分析,发现其中暗藏的思想和文化传承线索;参考布拉德福定律,划分古籍引书的核心区,考察高影响力引书的群体分布特点以及其背后的引书传承规律。古籍引书计量和影响力评价在于从计量数据的全貌出发,获取古籍的客观影响力数据,以提供古籍引书研究的新角度和新数据。
另一方面,以古籍引书知识库中引书关系为主要内容,基于引书知识之间的施引被引、耦合和同被引关系等引书关系,结合作者、朝代、类型等属性关系,实现古籍引书关系网络的构建,并以引书知识计量数据来确定网络结点之间关系的权重。参考引文网络分析方法,可以使用PageRank等算法得到引书网络和作者网络中引书和作者的排名,并使用这一排名进一步衡量引书和作者的影响力;根据引书网络和作者网络中的关系权重计算点度中心度,发现引用关系中频繁出现的引书和作者,从而衡量其重要性和影响力;计算中介中心度发现引书网络和作者网络中的重要“中间人”,从而发现具有桥梁作用的古籍和作者;使用凝聚子群方法来发现引书网络中和作者网络中关系密切的小团体,探究古籍引用中的文化流派和学术团体。基于文献耦合关系和同被引关系的计量数据,分别使用文献耦合分析和同被引分析方法探究引书之间的相关性和主题相似性,并依此自动聚类以构建具有相同主题的引书集合,从引书主题关系的角度进行引书影响力评价。
5.2 古籍引书内容的主题分析和情感评价
基于古籍引书的全文本内容,可以分析探究引书内容,与学术文献引用内容分析类似,该研究不关注引书的计量数据,而是关注具体的古籍引书内容,可以从情感和主题等角度进行古籍内容的理解和评价。这类研究主要使用自然语言处理中的文本分类和主题挖掘技术,如机器学习中LDA(latent Dirichlet allocation)主题模型,深度学习中句子向量表示模型等。借助这类文本内容挖掘方法,可以获取古籍引书全文本内容中的主题、风格、思想等文化知识,以及历史事件、人物关系、事实评价等历史知识;可以对古籍影响力评价结果进行补充,以获得更全面的评价结果,并结合情感分析、文本相似度分析等全文本分析思路,进一步考察古籍引书的观点引用、数据引用、负面引用等特殊的引用现象。
引书内容的情感分类即引书作者对被引古籍的态度和评价,情感类别包括赞同、中立和反对三种。参考文本情感内容分析方法,可以使用机器学习中的SVM(support vector machine)模型和深度学习中的预训练模型进行引书内容的文本分类。对于情感分类的结果,可以根据引书内容的不同类型即引书原文和观点,进行更深入的计量分析;也可以计算引用情感类别与引书影响力、作者影响力的相关性,从而发现在古籍引书和传统文化传承过程中,古籍引书内容的情感态度能够产生多大程度的影响,产生的影响是正向的还是逆向的。
引书内容的主题分析分为面向施引注疏文献和面向被引古籍两个方面。对于施引文献来说,引用内容主题反映注疏文献引用古籍时所关注和使用的主题内容,首先,基于引书知识库中的引用内容,可以构建引书内容词表并计算相应词频,结合TFIDF(term frequency-inverse document frequency)等特征词抽取方法得到引书内容主题词语;其次,根据引书内容语句,结合LDA主题模型求解古籍引书内容的主题分布和每个主题的词语分布;最后,综合两种方法分别获取表征古籍引用内容的主题词语,并构建主题词共现网络,借助社会网络分析方法挖掘分析引用内容中主题词语的关联,并藉此发掘主题词语网络中表现的传统文化内涵。对于被引古籍来说,引用内容主题与被引古籍本身的主题并不一定相同,被引古籍引用内容主题的分析方法与施引古籍相关研究方法相同,通过构建被引古籍的引用内容主题词语网络,可以进一步计算引书影响力在不同引用内容主题下的表现,发现不同主题对引书影响力的贡献程度,从而更深入地发现在古籍引用过程中、传统文化传承过程中,不同文化主题的地位及其发挥的影响力。
5.3 古籍引书与文化传承
基于古籍引书知识库及古籍引书影响力评价数据,古籍引书的计算人文研究还可以文化传承为线索开展。具体来说,以古籍尤其是先秦古籍和儒家经典为对象,以《二十四史》《资治通鉴》等史书为朝代线索,以古籍引书知识为佐证材料,考察古籍中的观点、思想和文化内涵在朝代变化中的发展和传承特点。以儒家经典《论语》为例,从篇目、文本内容、主题、情感评价等角度,综合考察其在不同被引用的分布情况,并结合影响力等评价指标进行量化视角的数据分析,最终以可视化形式呈现分析结果,相关结果对接至公开的知识检索和问答系统,以助知识普及和文化推广。此外,还可以利用上述主题挖掘知识开展传统文化传承内容和脉络的探究和梳理,藉由影响力知识、聚类知识和相关性知识等,进行主题内容分析,将引书网络扩展为主题网络。从主题网络出发,探索主题之间关联、传承和影响,发现其中的演变规律,并以传统文化为线索,对引书主题进一步整合,从中凝练出传统文化的传承和发展规律,比如,《春秋》所蕴含的儒家文化主题及其相关引书所体现的儒家文化传承发展规律。文化传承研究的重心在于对古籍引书知识库和古籍引书计量和影响力评价结果的数据分析和可视化呈现,为文化传承研究提供基于数据的客观解读和量化结论。
5.4 古籍引书全文本内容与散轶古籍整理
基于古籍引书知识库的全文本特点,可以面向散轶古籍整理进行辅助性的探索。实际上,目录典籍引书和经学注疏引书中保留了大量散轶古籍的线索,这些线索也是传统文献学研究散轶古籍的重要参考依据。许多散轶古籍以古籍引书内容的形式分散留存在各类古籍中,人工获取和整理的方式耗时、耗力。通过古籍引书全文本知识库的助力,从计算人文视角探索大规模、系统化、自动化的散轶古籍内容整理,对于古籍整理和保护来说具有较大的探索潜力和价值。而自动整理得到的散轶古籍内容知识库虽然不一定能完全还原散轶古籍本身,但对于古籍传承脉络探索和经学发展等传统文献研究来说,仍然具有值得参考的资源价值。
6 总结与展望
古籍计算人文如今已成为古籍研究的重要领域,也为文献学的重要对象——古籍引书研究赋予了新技术和方法的视角。本文从四种较为典型古籍引书类型出发,关注其在引书现象中的共性和特点,并以知识库的构建为落脚点,探讨古籍引书研究在计算人文视角下的概念内涵和技术框架。本文详细描述了古籍引书全文本知识库中的主要方法,包括知识表示、知识标注、知识补全和消歧,以四类古籍引书为例,介绍了本研究团队在知识库构建中的现状和进展,并分析和展望了知识库在古籍引书计算人文研究中的应用。
在未来的研究中,将以知识库构建为核心,面向《十三经注疏》《二十四史》等语料资源,进一步扩展和完善已有的古籍引书全文本知识库。一方面,围绕知识库构建的技术框架,进一步探索引书知识的自动抽取和标注,引书内容的自动分类和暗引内容发现等任务;另一方面,以引书知识的计量分析、主题挖掘等研究为切入点,从大规模数据视角,考察和描述各类古籍的引书现象,发掘古籍引书计算人文研究的潜在价值。
