基于改进SimBERT的藏医药专利文本分类模型研究
2024-01-03罗丽锦陈颂斌
罗丽锦,高 屹,2,陈颂斌,樊 淼
(1.西藏民族大学,陕西 咸阳 712082;2.西藏光信息处理与可视化技术重点实验室,陕西 咸阳 712082)
0 引言
大数据技术创新的不断提升以及我国对知识产权意识的不断加强,为文本分类带来了很多便利条件,但文本分类仍然面临着以下挑战:①具有高质量核心技术的知识产权数量没有随着知识产权数量的增加而增加;②目前没有按知识产权重要程度的权重对有限的资源进行分配;③研发创新大多围绕学术研究和研究项目展开,导致知识产权容易与市场需求脱节,产业转型效率低下[1].
2023年4月26日,国家主席习近平在主题为“加强知识产权法治保障有力支持全面创新”中指出,中国始终高度重视知识产权保护,愿进一步深化同世界知识产权组织的友好合作[2].有效应对专利文本分类效率,能够保护知识产权.需求者可通过文本分类技术快速匹配到相似专利,这样既能减少需求者在大量专利数据上的检索时间,又能有效预防知识产权重复,从而达到避免侵犯知识产权的效果.
IPC是国际通用的专利管理系统,它主要对单一的技术主题进行分类,所以IPC存在无法直接反映某一技术领域的发展趋势、状况以及某些细分领域的分析不够细致等缺陷[3].引入深度学习技术能够有效提升文本分类效率,减少传统分类带来的错误率,对专利文本自动分类具有重要意义.
本文研究的核心点是基于SimBERT进行改良的文本分类模型.SimBERT是由Google提出的对BERT模型进行改进之后的模型,它主要用于提升中文文本分类和匹配任务的性能.由于SimBERT拥有Transformer的编码器结构,所以它能够充分理解文本的上下文语义.SimBERT采用预训练加微调的方式进行模型训练,增强了中文文本分类和匹配任务的效果.SimBERT模型可以通过增加层级或扩增预训练数据来进一步提高分类性能.
1 国内外研究现状
文本分类是人工智能领域重要的任务之一,它随着人工智能领域相关技术的快速发展而发展,通过融入机器学习和监督学习等新方法,来提高文本分类的创新力和效率.这些新方法也能应用在专利文本分类领域,为专利的审阅、检索和数据分析等提供技术支持.
国内的专利文本分类研究现状大致分为两种,即中国国家知识产权局在文本分类领域里的研究、国内高校和研究机构在该方面的研究.美国是专利领域的主要创新来源者,它的大多数公司和专利机构通过机器学习和自然语言处理等方法来处理专利文本分类.欧洲等国家也有大量研究人员对该领域进行了研究,并取得显著成果.
梅侠峰等提出将RoBERTa和多尺度语义协同融合在一起的专利文本分类模型,该模型在部级上的准确率达到了88.9%,在大类级别上该模型达到了82.6%的准确率[4].慎金花等人将平面模型与层次模型做对比,得出在大类层次上Rocchio模型分类效果最好,准确率为96.3%,在小类层次上,层次KNN模型的分类效果最好,准确率为95.59%;在大组层次上层次支持向量机和层次KNN模型的分类效果最好,准确率为93.8%[5].杨超宇等人对SVM进行改进,提出的TF-IDF-LDA-SVM模型的准确率为98.51%[6].刘燕提出了BERT-BIGRU中文专利文本分类模型,对8类专利文本进行分类,其准确率达到了85.44%[7].余本功等人应用两种特征通道训练WPOS-GRU模型,其准确率达到了97.4%[8].Ran Li等人结合词汇网络方法的BERT、词汇网络方法结合CNN和LSTM进行对比实验,得出词汇特征提取方法能够提升模型训练的收敛速度,其准确率为82.73%[9].Milan Miric等人应用监督的ML方法将文本数据自动分类到已定义好的类别或组中,并以ML方法在AI专利上的应用为例,将该方法与其他分类方法模型做对比,其准确率最高为96%[10].
2 相关技术
2.1 SimBERT
SimBERT是基于检索、生成于一体的预训练语言模型.采用BERT结构,并利用大规模语料库进行预训练,是为NLP任务提供更加准确和有效的文本表示.与传统的词向量(如one-hot)相比,SimBERT能够结合上下文语义信息,对文本的理解会更加准确,也能通过已知的知识来判断输入文本之间的相似性,提高了预测速度并且准确度高[11].与BERT模型相比,SimBERT在中文文本分类任务中能提供更好的性能.与ALBERT相比,SimBERT参数更少,模型更轻量化,可提供更准确的中文文本表示,也具备词汇级别的语义理解能力.
2.1.1 预训练模型的训练方式
在了解SimBERT之前,先了解一下预训练模型的三种训练方式.第一种是输入模型时随机mask一个或多个token,再通过上下文信息来预测这个被mask的token,它在做自然语言理解(NLU)任务时效果更好,但在生成式问题上效果较差.第二种是通过前面或后面出现的所有token来预测当前要预测的token,它在做生成类任务时效果更好,但该方法不能用上下文信息来做预测.第三种是通过编码解码操作将输入的句子转化成文本序列.
2.1.2 UniLM
UniLM是一种用于解决NLP任务的统一语言模型,对于上文提到的预训练模型的三种训练方式,UniLM都适用,它的目的是通过统一的语言模型来训练不同架构任务,其核心是通过特殊的注意力掩码使模型拥有序列到序列模型的能力.它通过在句子的开头添加[SOS],在句子的结尾添加[EOS]符号来得到句子的特征向量.比如输入这样一个文本“去哪个城市”,回答的句子是“咸阳”,我们称之为目标句子.UniLM把这两个句子拼接成序列“[CLS]去哪个城市[SEP]咸阳[SEP]”,它的注意力掩码为图1所示.
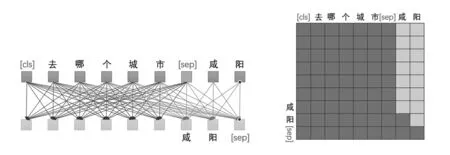
图1 UniLM注意力掩码图图2 Sep2Sep模型
输入的序列“[CLS]去哪个城市”是双向的Attention,输出的序列“咸阳[SEP]”是单向的Attention,它支持递归的预测序列“咸阳[SEP]”,因此它拥有文本生成的能力,即Seq2Seq能力,其模型如图2所示.
由于UniLM拥有特别的注意力掩码,使得“[CLS]去哪个城市[SEP]”这个序列只在彼此之间互相Attention,和序列“咸阳[SEP]”没有任何关系,即无论序列“[CLS]去哪个城市[SEP]”后面是否拼接了序列“咸阳[SEP]”都不会影响到前面7个token.总之,在向UniLM输入内容的时候会随机mask部分token,这样输入部分就可用于MLM任务,增强了NLU能力,输出部分就可以用于Seq2Seq任务,增强了NLG能力.
2.1.3 SimBERT
SimBERT运用有监督训练方法,可以通过收集到的中文相似句对做语义相似度计算任务,采用两个BERT编码器对两个句子进行编码表示,然后再运用汉明距离或余弦相似度等方法计算它们之间的相似度来得分,也能通过构建Seq2Seq模型来进行相似句生成任务.其构建方式可以分为编码器和解码器两个部分.编码器将输入句子编码为固定长度的向量表示,解码器用该向量表示来生成和输入句子相似的另一个句子.用输入的句向量来训练检索任务,如图3所示.比如“华山北峰海拔1 614米”和“华山高1 614米”是一组相似句对,在相同批次中,将“[CLS]华山北峰海拔1 614米[SEP]华山高1 614米”和“[CLS]华山高1 614米[SEP]华山北峰海拔1 614米”全部加入模型进行训练,就能生成一个相似句.从数学角度来看,就是把所有批次内输入的句向量组成句向量矩阵C.矩阵C的形状如下:(a,X,b)=(batch_size,sequence_length,hidden_size).对每个输入的句向量,在b维度上进行L2归一化,将归一化后的[CLS]向量按照batch的维度进行堆叠,得到一个a*b的句向量矩阵C.通过点乘的方式计算句向量矩阵的相似度矩阵,得到一个a*C的相似度矩阵CC^T.将相似度矩阵乘以一个缩放系数,然后对对角线进行掩码处理,将其设为一个较大的负数.最后对每一行进行softmax操作,得到一个分类任务的目标标签.在训练过程中,可以为每个样本选择一个相似的句子作为目标标签,并根据目标标签进行分类任务的训练.

图3 训练检索任务
2.2 通道注意力机制
通道注意力机制(Channel Attention Mechanism)是一种用于计算特征图通道之间相关性的注意力机制,是在一个特征图中,不同通道的响应对于不同任务会有不同的重要性.通道注意力机制通过计算每个通道的重要性,来让模型更加关注那些重要的通道.这种方法能够消除噪声,增强特征表达,并提高模型的准确率和鲁棒性.

其中,表示sigmoid的函数为W0∈RC/r×C,W1∈RC×C/r.需要注意,MLP的权重W0和W1为两个输入所共享,ReLU激活函数在W0之后.通过给每个通道都赋予不同的重要性,模型就能更加准确地对不同通道的特征进行处理,从而提高模型的性能.其结构如图4所示[12].
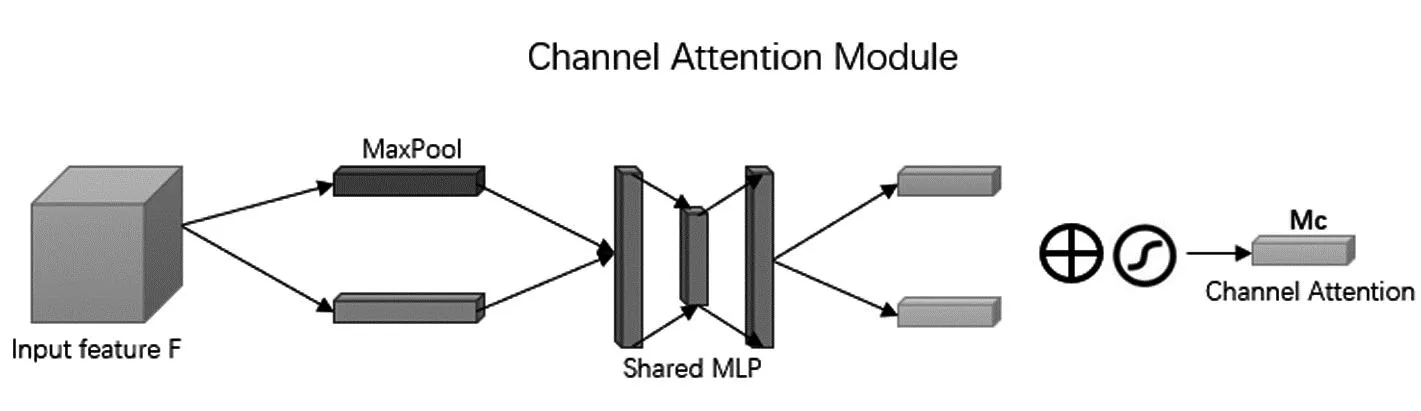
图4 通道注意力机制

图5 SimBERT-CAM-CL的模型结构图
2.3 卷积层
卷积层是深度学习中卷积神经网络的重要层类型,主要用于处理一个规则的二维或多维网格(或格子)上组织的数据,比如地理信息系统中的栅格数据以及图像数据等.卷积层的主要功能是运用一组可学习的滤波器(亦可称为卷积核),对输入的数据进行卷积操作,提取网格结构数据的局部信息[13].
2.4 SimBERT-CAM-CL的藏医药专利文本分类模型
SimBERT结合通道注意力机制和卷积神经网络层,可以在原有的模型基础上进一步增强特征表达,提升模型性能.
融入通道注意力机制可以给不同通道进行重要性加权,以提升模型对某些重要特征的关注度来达到优化输入embedding向量的效果.比如对数据集中“制剂”“五味子”等关键词,采用通道注意力机制来提高它们对模型学习文本语义的影响力.
首先,将收集到的文本数据进行数据清洗和文本预处理等操作,然后将数据集划分为测试集和训练集,将训练集数据送入SimBERT中进行编码,得到768维的embedding向量为原始embedding向量.通过融入通道注意力机制给embedding向量赋予通道权重,得到通道权重向量(先将维度从768维降低到12维,即64倍降低,然后再将维度提升回768维).把每个通道的权重相乘,再将结果与原始的embedding向量相加,得到一个加权的embedding向量.然后,再将维度提升回768维,将优化后的向量输入到32×768×1的卷积神经网络层中,利用多个卷积核提取藏医药文本数据中摘要的特征信息,得到32×512×1的向量表示(kernel_size参数值设为3).接着,将卷积神经网络层的输出结果进行Max pooling,将序列长度减少,得到一个固定维度为32×171×1的向量,然后把这个向量输入到全连接层,最后传递到Softmax函数,以IPC主分类号的“部”和“大类”为分类依据,得到最终的分类结果.
3 实验结果与分析
本实验是在Windows11系统上完成的,GPU为GTX3090,处理器为Westmere E56xx/L56xx/X56xx,使用Python3.7.13的编程环境,并在Pytorch1.7.1深度学习框架上搭建模型.更多实验环境如表1所示.

表1 实验环境
为了对参数进行更新,利用Adam优化器,定义了激活函数ReLU,用交叉熵损失函数来对模型进行训练.实验时选择合适的初始学习率是训练神经网络的重要因素之一.太小的学习率会导致模型收敛速度较慢,需要更多的迭代次数才能达到较好的性能;而太大的学习率可能导致模型在训练过程中震荡或发散.向量维度选择768维,较高的维度虽然可能导致计算变得复杂,但也能使特征表达变得更加丰富,其详细信息如表2所示.
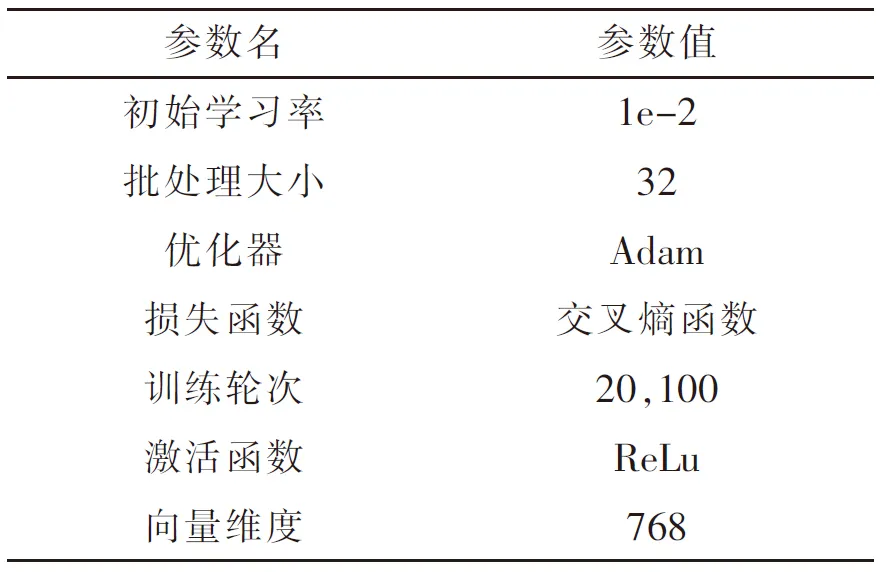
表2 参数信息
为了模型训练和评估,将预处理后的数据按照8∶2划分成训练集和测试集.这样可以确保模型在训练过程中学习到足够的信息,并且在测试集上进行评估时能够准确地反映出模型的性能.
由于藏医药专利数据集的缺失,本实验采用自建数据集,而专利数据可以通过曾在欧洲专利局和知网中公开的数据进行收集得到,通过对关键字“藏医”“藏药”等的检索进行搜集,确保了自建数据集的合理性和可靠性.通过Python爬虫技术爬取欧洲专利局中与藏医药相关的专利数据5 621条,其中包含专利号、专利名称、摘要、分类号和所属部类5列字段数据[14].
由于此数据集为自行构建,所以存在大量的数据清洗工作,如摘要的数据噪声、所属部类数据少于20条等.此处通过正则表达式、条件筛选等方法对数据进行清洗,以便提高特征提取部分的效率,将处理后的数据根据不同所属部类进行随机抽取,按照8∶2划分训练集4 389条数据和测试集1 103条数据.本实验将IPC分类法中的“部”和“大类”作为样本的分类,样本在IPC分类法中的类别分布情况如表3所示.

表3 专利数据详情

表4 Confusion Matrix
3.1 实验过程
将训练集数据输入到SimBERT预训练的语言模型中进行编码.这个过程将文本转化为向量表示,得到原始embedding向量,这些原始嵌入向量包含了文本的语义信息.
为了进一步优化这些嵌入向量,引入了通道注意力机制.这个机制为每个通道(或者说每个语义维度)赋予了权重,以反映其在分类任务中的重要性.把每个通道的权重相乘,再把结果与原始的嵌入向量相加,得到一个加权的嵌入向量.这个加权的嵌入向量在保留了原始语义信息的同时,更加关注与分类任务相关的特征.
接下来,将优化后的向量输入到卷积神经网络层中.卷积神经网络利用多个卷积核来提取藏医药文本数据中摘要的特征信息.每个卷积核都可以捕捉不同尺度和模式的特征,从而丰富了模型对文本的理解能力.
卷积神经网络层的输出结果经过Max pooling操作,将序列长度减少,得到一个固定维度的向量.这个向量包含了摘要中最重要的特征信息,为后续的分类任务提供了有用的输入.
最后,将这个向量输入到全连接层,并通过Softmax函数得到分类结果.全连接层进一步处理特征向量,把它映射到各个分类类别上,并输出对应的概率分布.Softmax函数将这些概率进行归一化,使其总和为1,从而得到最终的分类结果.
在训练模型时,选择Adam优化器来对模型的训练进行优化.Adam优化器结合了梯度的一阶矩估计和二阶矩估计,能够自适应地调整学习率,提高了模型的训练效果.为了衡量观测值和预测值之间的差异,采用交叉熵损失函数作为模型的目标函数.交叉熵损失函数在多分类问题中广泛应用,能够有效地衡量模型的预测准确度,并促使模型向更好的方向优化.
在训练过程中,采用批量梯度下降的方法进行参数更新.批量梯度下降将训练集划分为多个批次,每个批次包含多个样本.通过计算每个批次的损失函数梯度,并根据该梯度对参数进行更新,这样可以有效地优化模型并提高训练效率.
通过以上的步骤和方法,能够对藏医药专利文本进行全面的处理和分析,从而可建立一个高效准确的分类模型.
3.2 实验评价指标
在模型运行完或输出后,要用评估指标对模型的效果进行评估.分类模型中有几个常用的模型指标,分别是Recall、Precision、F1、ROC、AUC.Recall为召回率,Precision为精确率,F1为结合了召回和精确的调和平均,ROC代表整个分类模型的好坏,AUC为计算ROC下的面积.
根据表1,计算各指标的公式如下:
(2)
(3)
(4)
(5)
(6)
(7)
3.3 实验结果对比分析
为验证本文提出的SimBERT-CAM-CL模型的有效性,将此模型与其他文本分类模型进行对比,对藏医药专利的部和大类一起进行分类实验.对比模型如下:
1) BERT:由多个Transformer编码器层组成,其中Transformer是一种基于自注意力机制的神经网络架构.有12个编码器层,每个编码器层具有12个自注意力头,隐藏层有768个隐藏单元.采用WordPiece嵌入将文本标记成小的词块(subwords),然后将这些词块嵌入到768维的向量表示中[15].
2) ALBERT:采用层级参数共享和参数分解的方法,它具有12个隐藏层,隐藏层有768个隐藏单元,具有12个自注意力头.采用WordPiece嵌入将文本标记成小的词块(subwords),然后将这些词块嵌入到768维的向量表示中[16].
3) Chinese-Word-Vectors:用本文模型进行训练,分词工具使用Chinese-Word-Vectors,窗口大小设置为5的动态窗口,子采样1e-5,低频词阈值为0,迭代次数为5[17].
4) SimBERT:采用原始SimBERT模型进行训练,即BERT+UniLM+对比学习,将文本特征转化为768维向量.
将本实验处理好的数据集放入不同模型进行训练,分别得到BERT(见图6)、ALBERT(见图7)、Chinese-Word-Vectors(见图8)、SimBERT(见图9)以及SimBERT-CAM-CL(见图10)模型的准确率如表5所示.
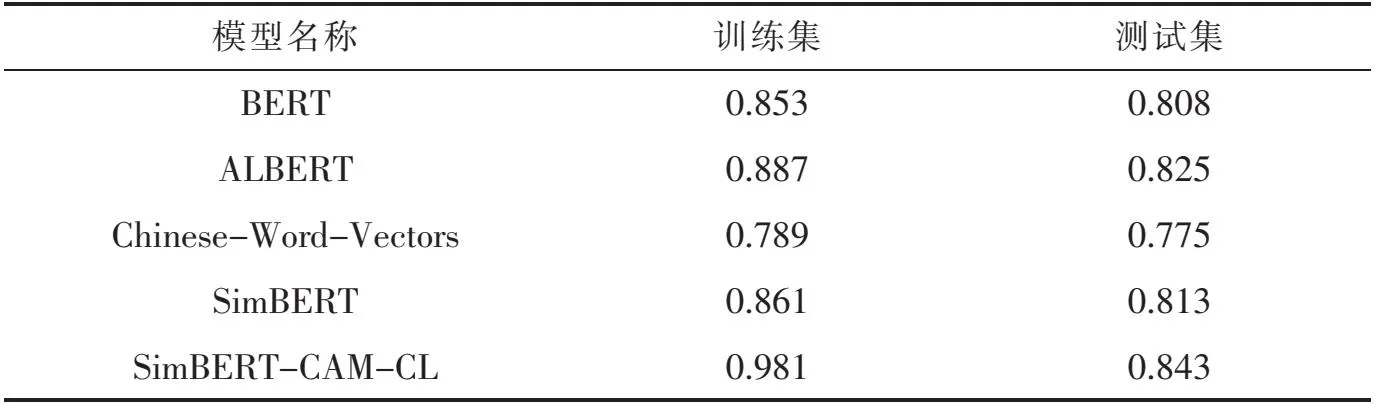
表5 各模型准确率

图6 BERT模型准确率图7 ALBERT模型准确率
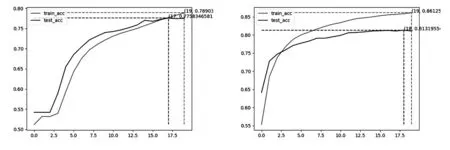
图8 Chinese-Word-Vector模型准确率图9 SimBERT模型准确率
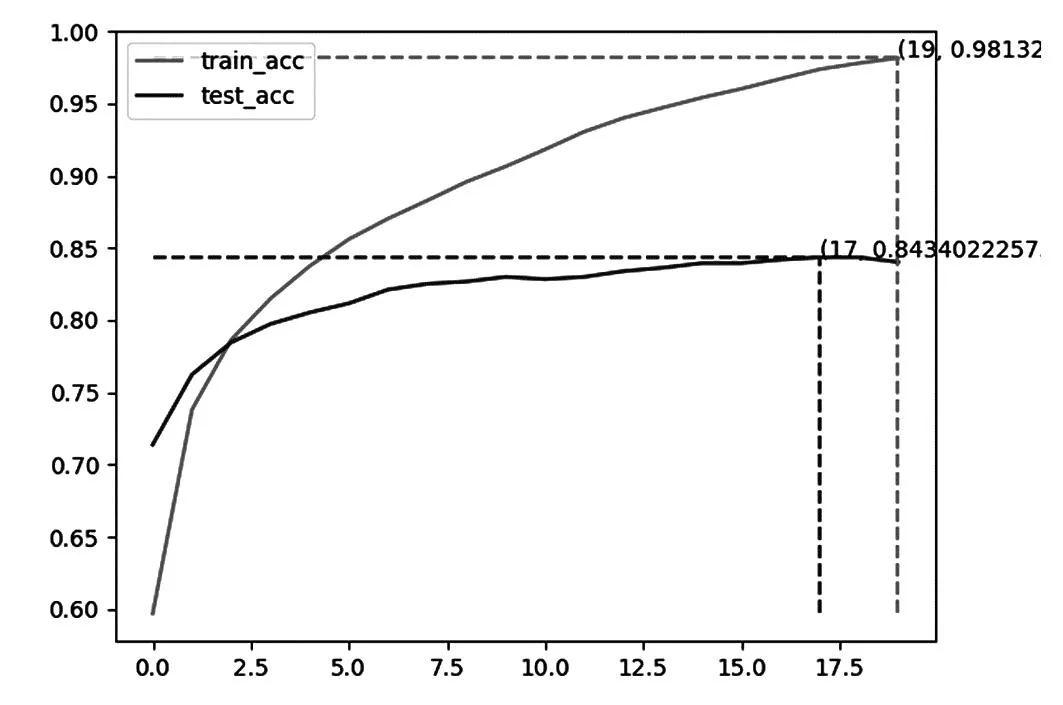
图10 SimBERT-CAM-CL模型准确率
通过上述参数对比可以看出,本文提出的SimBERT-CAM-CL模型比BERT、ALBERT、Chinese-Word-Vectors、SimBERT模型准确率在训练集和测试集上都有提升,表明本文模型是有效的.
4 结论
实验结果显示,SimBERT-CAM-CL在准确率上取得了显著提升.同时,该模型还能够通过优化模型结构和参数设置,降低模型复杂度,但是,本实验的数据集是专门针对藏医药领域的.由于这一特殊性,大部分数据集都被分类到部A中,因此实验主要集中在大类别的分类任务上,这就限制了模型的广泛适应性和泛化能力.
此外,由于藏医药专利研究相对较少,本实验只能获取到5 000多条相关数据,相较于其他研究运用的数据量可能超过上万条的情况,本实验结果可能存在一定的局限性.为了增加数据集的丰富性和实验的可靠性,未来的研究可以在学术论文、专利文件、公开数据库等平台上寻找和收集更多与藏医药相关的数据.这将有助于扩大数据的规模和多样性,提高实验结果的泛化能力.
