基于自适应自编码器假人力学响应降维和重构方法
2024-01-01侯志平朱海涛刘灿灿等


关键词: 汽车安全;汽车碰撞试验;假人力学响应;降维方法;自编码器
中图分类号: U 467 文献标识码: A DOI: 10.3969/j.issn.1674-8484.2024.03.006
假人力学响应是评价车辆碰撞安全性能的重要参数之一。假人内部设置的50~70 个传感器经过标定后可用于采集车辆碰撞过程中假人所受的力、力矩、位移、加速度等数据。利用上述数据可以计算出假人的损伤值,进而对车辆碰撞安全性能进行评价。因此,在碰撞安全和假人开发等领域,众多研究者对假人力学响应曲线进行数据挖掘研究工作,为汽车碰撞安全装置的开发[1-2] 和假人研发、传感器标定[3-4] 等提供依据。
然而,通过碰撞试验获得的假人力学响应,都是时序性的曲线形式,样本数据量少且有效信息和冗余信息杂糅,无法直接用于统计分析,曲线也无法与离散参数构建函数关系。因此,需要对假人力学响应曲线的有效信息进行提取和降维。
传统的降维方法可以分为特征选择和特征提取。
特征选择法是将原数据集按照某种算法抽样组成新的数据集代替原数据集,该过程不产生新数据[5-6]。
通过为假人响应曲线附加不同的权重,可以对曲线进行不同密度的抽样,再通过优化算法调整权重值,实现优化降维的目的。尽管特征选择法可以通过优化算法提取到曲线的某一段关键特征,但是仍然无法与离散的设计参数建立函数。同时,优化算法的训练容易陷入局部最优解,所以需要研究更复杂的优化算法来弥补这一缺陷,却又会导致降维算法更加复杂[7]。
特征提取法通过提取原高维数据中的有效信息融合生成低维数据,该方法会产生新的数据集。应用该方法时,先将响应曲线分割为离散的高维数据点,再利用降维方法将高维数据点降至低维数据点。对于常用的特征提取法可以分为线性和非线性2类,其中研究者常用的线性特征提取降维方法是主成分分析法(principal component analysis,PCA)。
W. Sun 使用PCA 法提取尸体碰撞试验获取的力学响应数据的有效信息,并用于构建与体型信息相关的函数表达式[8]。通过PCA 降维得到的低维数据独立性强,用于构建函数时拟合精度高。然而PCA 法获取的低维数据无法保留原数据的全部有效信息,而且该方法只能用于样本数据量大于高维数据维度的情况,对于假人力学响应这类小样本降维问题不适用。
为解决假人力学响应数据降维问题,弥补现有降维方法的不足,本文提出了自适应自编码器方法。基于标准自编码器的原理和假人力学响应数据的特征构建限制条件对其进行改进;利用假人力学响应数据对标准自编码器和自适应自编码器的线性和非线性降维能力和重构能力进行验证;对仿真结果进行分析总结。
1 自适应自编码器方法构建
1.1 标准自编码器算法
标准自编码器方法被广泛应用于图像降维降噪[9-10]、特征提取[11-12] 等领域。标准自编码器通过改变可训练参数的值,使得输出层的高维数据尽可能地接近输入层的高维数据,实现网络自适应训练的目的[13]。如图1所示。该网络左右2 部分中每一层的神经元个数关于中间层对称,左半部分为降维网络,右半部分为升维网络。输入层、输出层的神经元个数与力学响应高维数据的维度相同。降维网络和升维网络的层与层间都设置权值和偏置作为可训练参数。
文中标准自编码器的采用s-p-s的网络结构,其中:s为输入层和输出层神经元的个数,p为中间层神经元的个数。选择均方误差作为损失函数,选择适应性矩估计算法(adaptive moment estimation algorithm,Adam) 作为优化器函数。激活函数Φ可以是线性或非线性的,相应地标准自编码器即为线性或者非线性标准自编码器降维方法。
1.2 自适应自编码器算法
在标准自编码器网络中添加权值正交、无关性特征和单位化3 种限制条件[14],构建自适应自编码器算法,以增强低维数据的独立性。
1) 权值正交。该限制使得被“编码”的低维数据相互独立的[15-16]。可以避免信息的冗余,使得网络有更小的规模。由于该限制的存在,权值矩阵中仅是有价值的权值( 对角线上的) 是非零的,可确保在利用反向传播算法更新参数时,有足够的信息从非零的权值上传播,避免梯度消失的问题[12, 16]。
2) 无关性特征。该限制对编码器输出数据的协方差矩阵的非对角线的数据进行限制,使其接近0。该限制同权值正交限制相结合,去除低维数据间的相关性。
3) 单位化。该限制可以防止随着矩阵范数的增大,低维数据的方差增大,无法求得一个合适的解,导致计算出现问题。
利用自适应自编码器生成的低维数据,具备独立性强的优点,可以自由地选择中间层神经元的个数来匹配设计参数的个数;可以通过选择激活函数来实现线性和非线性降维;特殊的网络结构对小样本情况也可实现高效降维。
2 降维方法分析与验证
为验证自适应自编码器算法的线性和非线性降维能力,设计了如图2 所示的验证过程。
重构均方误差:是指降维得到低维数据重构回高维数据后与原高维数据的均方误差值。重构均方误差值越小,表明重构的高维数据精度就越高,进而说明低维数据融合高维数据的有效信息越多。
互相关系数:是表示变量间相关程度的量。计算方法如公式(1) 所示。本文通过计算低维数据间的协方差值用于评价低维数据间的相关程度。低维数据间的互相关系数越接近0,其相关性越弱,独立性越强。当与车辆或假人设计参数构建函数关系时,低维数据间的相互影响就越小,构建的函数精度就越高[7]。
2.1 样本数据集生成
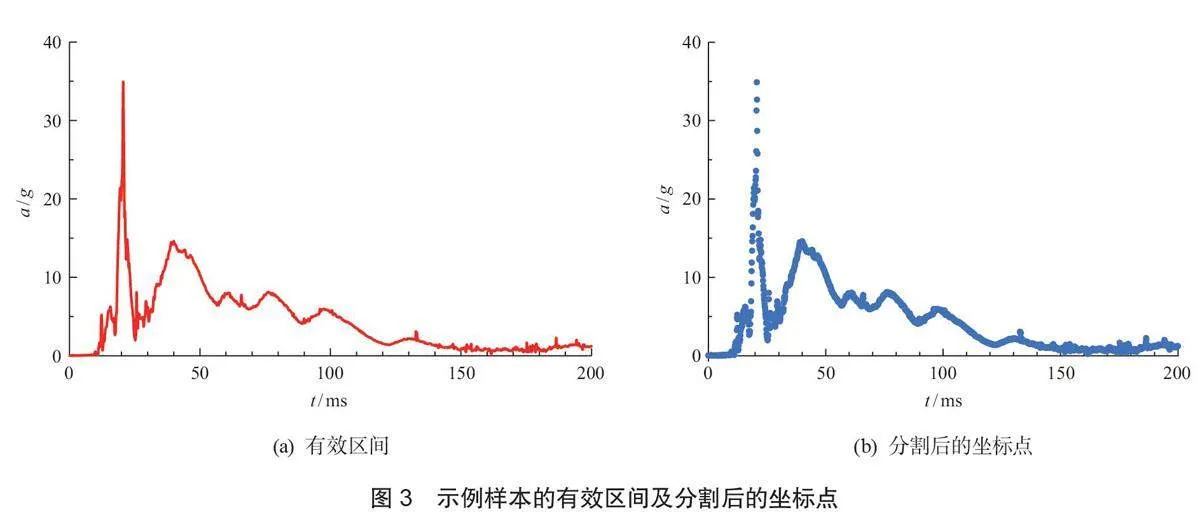
选择67个汽车侧面碰撞试验中,EuroSID-II假人的头部重心合成加速度曲线数据作为样本数据。如图3a 所示为其中某一个示例样本的有效区间。将样本数据分割为离散坐标点组成高维数据集[8]。本文选择分割间隔为0.1ms 的均匀取样方法,利用EVA® 软件,对每一条曲线在有效区间内进行取样,所取的坐标点数为2001个,样本数据集维度为67×2001。图3b为示例样本的分割后的坐标点。
2.2 线性降维方法
2.2.1 标准自编码器线性降维
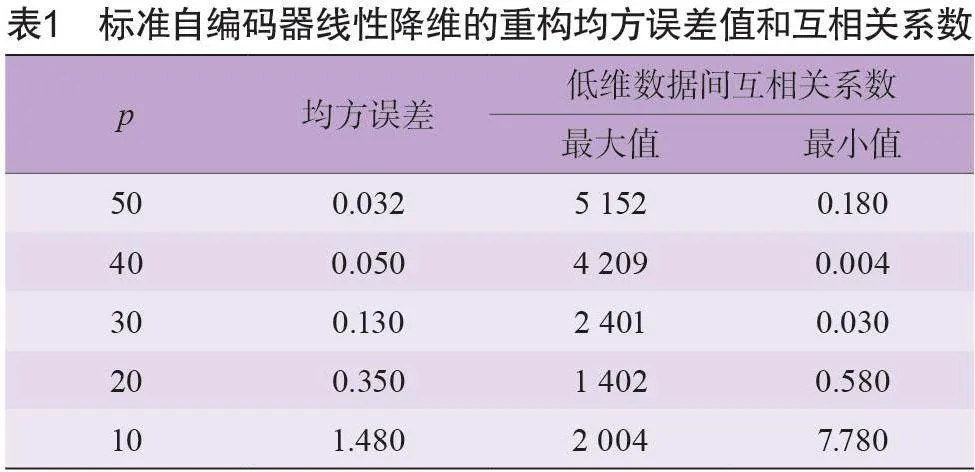
应用不同网络结构的线性标准自编码器对样本数据进行降维。激活函数为线性激活函数。由于67 组样本中每一组的样本维度都为2001,所以线性标准自编码器网络的输入层和输出层神经元的个数s=2 001个,即网络结构为2001-p-2001。p为中间层神经元的个数,同样也是低维数据的维度。待损失值稳定后保存网络。如表1所示为不同网络结构的标准自编码器对样本线性降维的重构均方误差值和低维数据间互相关系数( 互相关系数为低维数据协方差的绝对值)。
从表 1可以看出,当中间层神经元个数为50 时,均方误差值最小,为0.032。得到的低维数据间互相关系数的绝对值的最大值都是远大于0的,例如:p=50时,最大值为5 152。说明线性标准自编码器得到低维数据间有很强的相关性。
2.2.2 自适应自编码器线性降维
使用不同网络结构的线性自适应自编码器对样本数据进行线性降维。激活函数为线性激活函数。待损失值稳定后保存网络。如表2所示表示不同网络结构的自适应自编码器对样本数据线性降维的重构均方误差值和低维数据间互相关系数( 互相关系数为低维数据协方差的绝对值)。
从表 2 可以看出,当中间层神经元个数p=50时,均方误差值最小,为0.026。得到的低维数据间的互相关系数都是非常接近于0 的。例如: p=50时,最大值为0.035。说明线性自适应自编码器得到的低维数据间不具有相关性。从表2 可以看出:当p = 10~40时,自适应自编码器学习能力因受到限制条件的影响而导致均方误差值大于标准自编码器的相应网络结构的均方误差值。
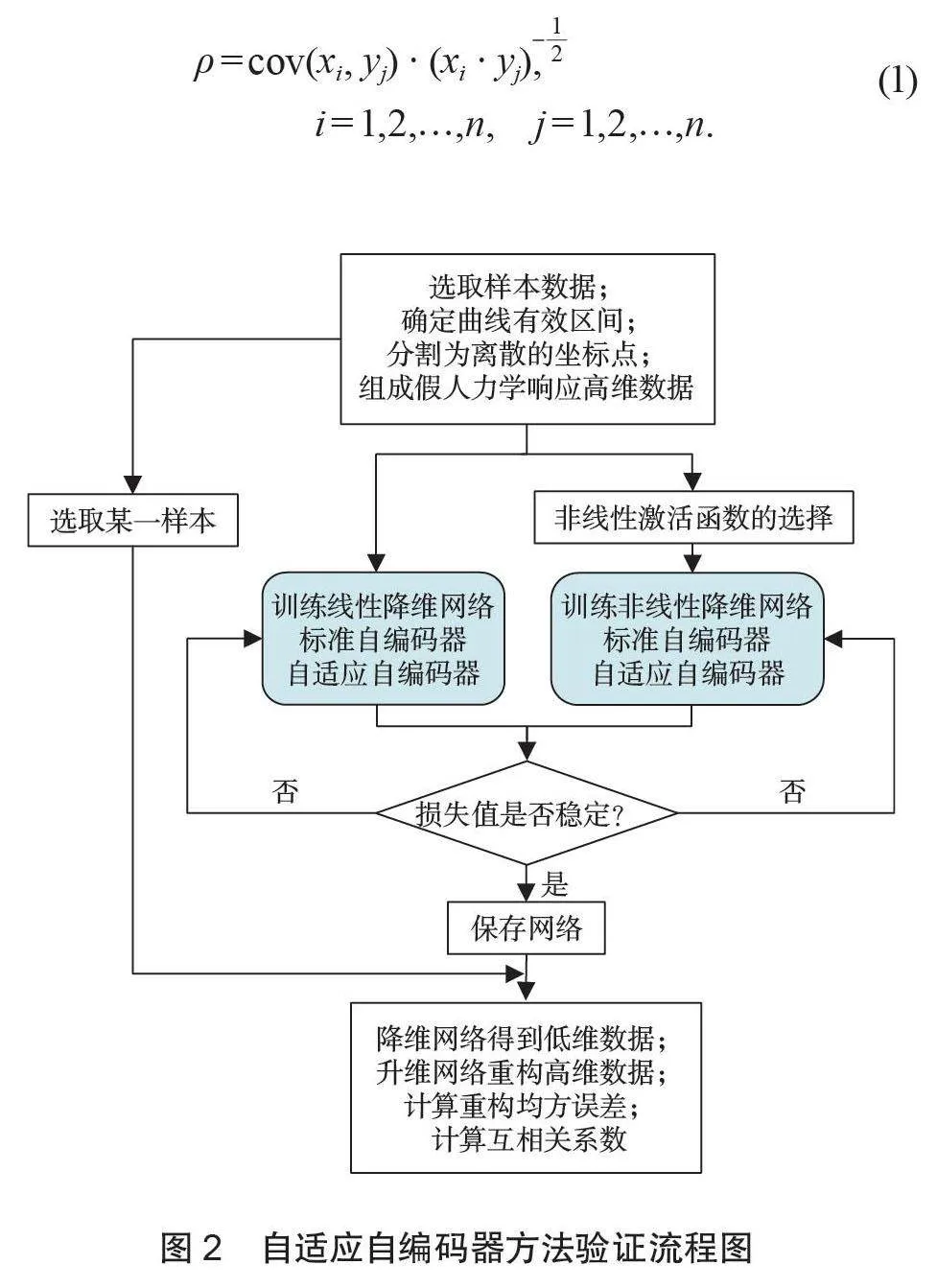
为比较不同均方误差值情况下,重构曲线对原曲线的拟合程度,绘制均方误差相差较大的p = 10、p = 50,这2 种网络结构下的重构曲线。随机选取某一样本描绘成力学响应曲线如图 4 所示。当p = 10、均方误差为1.75 时,重构的高维数据曲线与原数据曲线相比,30 ms 之后整体趋势大致相近,但与原数据曲线的最大幅值完全不符;当p = 50、均方误差为0.026 时,重构的高维数据曲线与原数据曲线相比,整体趋势已经非常接近,大部分位置的幅值也十分相符,2 条曲线近似重合。
结果表明:线性降维时,自适应自编码器和标准自编码器的均方误差值随着中间层神经元个数的增加而减小。在中间层神经元个数相同的情况下,自适应自编码器的部分重构均方误差略大于标准自编码器的重构均方误差,表 1 与表 2 中数据表明自适应自编码器所添加的限制条件对网络训练过程中的可训练参数取值加以影响,限制了网络的学习能力。故表2 中p= 10、20、30、40情况下的均方误差值都比表1 中相应网络结构的均方误差值稍大一些,随着中间层神经元个数的增加,可训练参数的个数也相应增加,网络的学习能力也被弥补。当p= 50,经过一段时间的训练后,自适应自编码器的均方误差值也相应减小。比较两者的低维数据间互相关系数,自适应自编码器得到的低维数据互相关系数更接近于0,独立性更强。
2.3 非线性降维方法
2.3.1 非线性激活函数选择
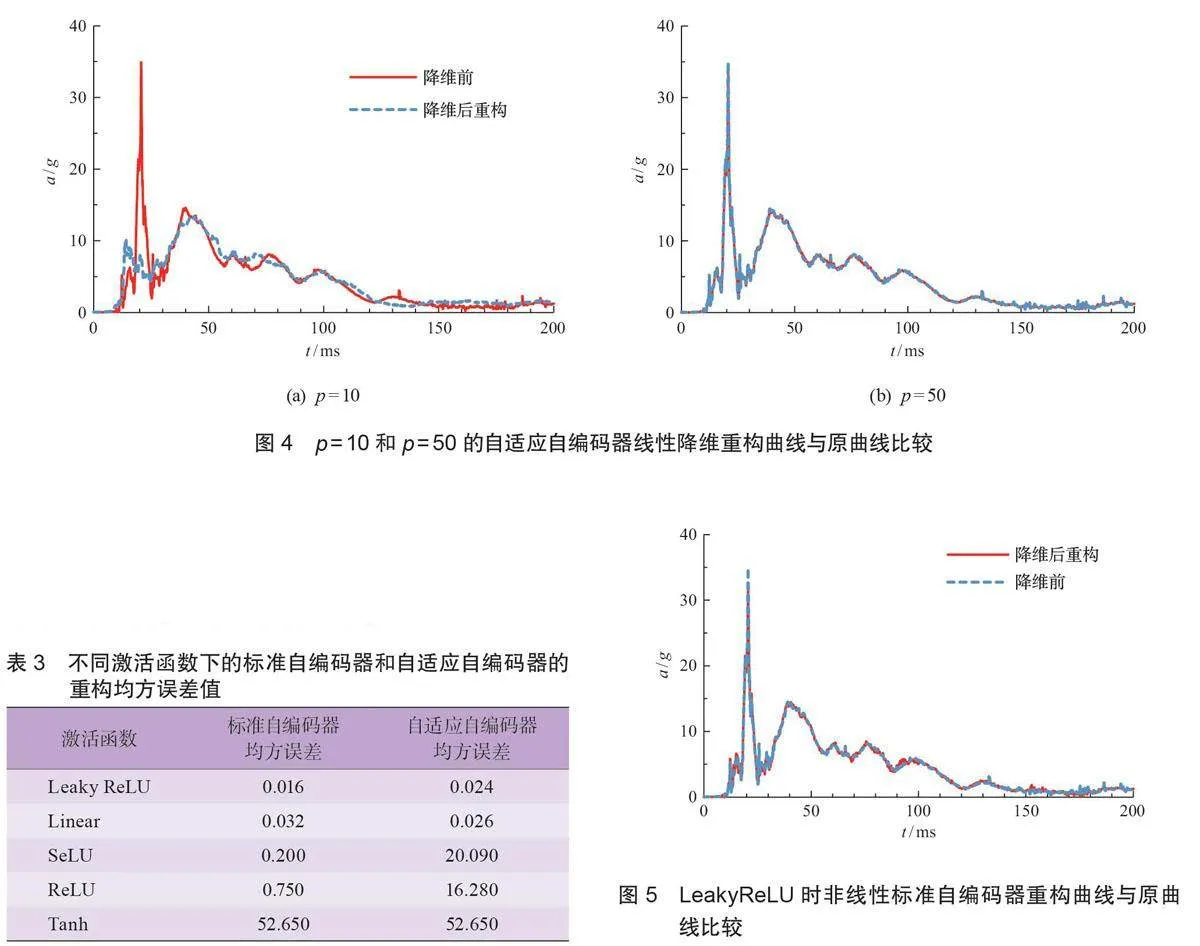
实现非线性的降维的关键在于非线性激活函数的选择。非线性激活函数是向神经网络中引入非线性的特性。目前广泛使用的非线性激活函数有修正线性单元函数(rectified linear unit,Relu)、LR 修正线性单元函数(leaky rectified linear unit,Leaky Relu)、双曲正切函数(Tanh) 和比例指数线性单元函数(scaledexponential linear unit,Selu) 函数。基于3.2节可知,中间层神经元个数为50时,均方误差值最小,因此采用的网络结构为2001-50-2001。待损失值稳定后保存网络。表3 为不同激活函数的标准自编码器和自适应自编码器对样本降维的重构均方误差值。
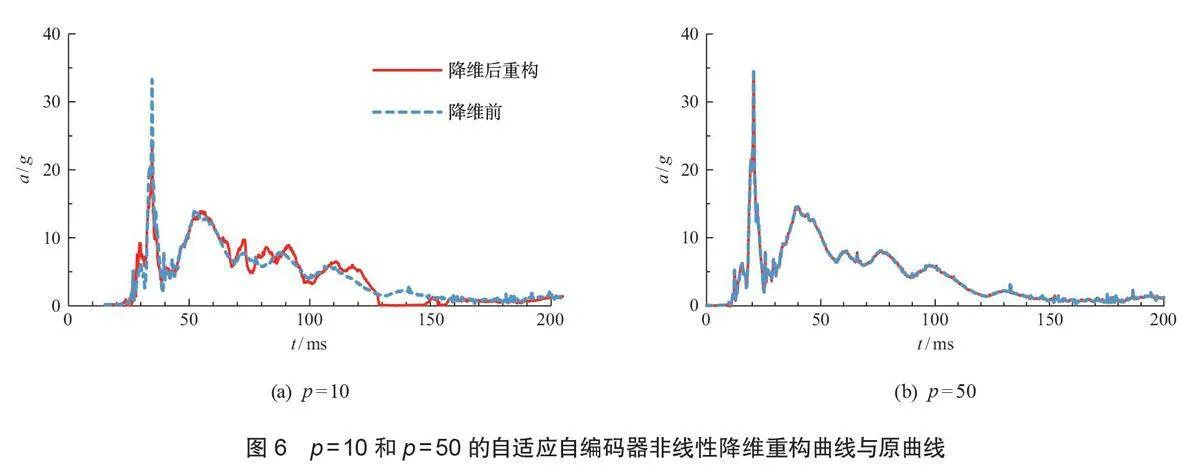
从表3可以看出:当激活函数为LeakyReLU 时,2种自编码器的均方误差值最小,分别为0.016和0.024,且均小于各自的线性降维的均方误差值。当激活函数为SeLU、ReLU时,同种自编码器内的均方误差值比较接近,均大于线性降维的均方误差值。不同种自编码器间,自适应远大于标准自编码器,说明限制条件的增加对SeLU、ReLU激活函数都有较大影响。而当激活函数为Tanh 时,2种自编码器的均方误差值最大,均为52.65,远大于线性降维的均方误差值。将激活函数为LeakyReLU的非线性标准自编码器和非线性自适应自编码器所得到的低维数据重构回高维数据,并描绘成力学响应曲线如图5和图6(b) 所示。图中降维前与降维后重构的整体趋势已经非常接近,大部分位置的幅值也十分相符。因此,本文在研究非线性降维问题时选择LeakyReLU 作为激活函数。
2.3.2 标准自编码器和自适应自编码器非线性降维
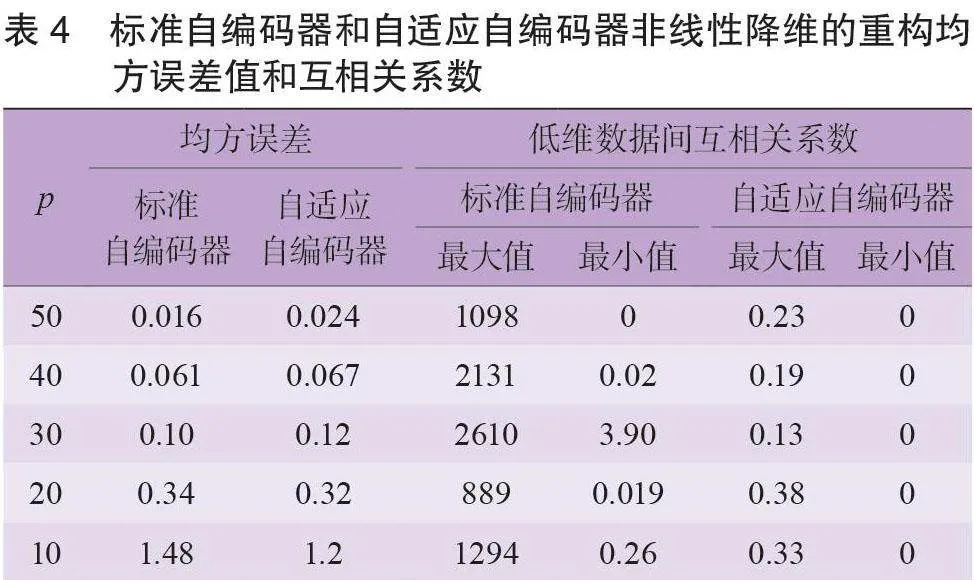
应用标准自编码器和自适应自编码器对样本数据进行非线性降维。激活函数为LeakyReLU 函数。待损失值稳定后保存网络。如表4 所示为不同网络结构的标准自编码器和自适应自编码器对样本数据非线性降维的重构均方误差值和低维数据间互相关系数。
从表4 可以看出:当中间层神经元个数为50 时,两者均方误差值最小,分别为0.016 和0.024。然而,标准自编码器得到的低维数据间的互相关系数都是远大于0的。例如:p=50时,最大值为1098。而后者的互相关系数都是非常接近于0的。例如:p=50时,最大值为0.23。
表1 与表4 说明:非线性标准自编码器得到低维数据间有较强的相关性。但相比于标准自编码器线性降维来说,非线性降维的相关性稍弱一些。非线性自适应自编码器得到的低维数据间不具有相关性。选取某一样本,描绘成力学响应曲线如图6 所示。
结果表明:非线性降维时,在中间层神经元个数、非激活函数相同的情况下,自适应自编码器的重构均方误差接近于标准自编码器的重构均方误差(表4)。比较两者的低维数据间互相关系数,自适应自编码器得到的低维数据互相关系数更接近于0,说明其低维数据的独立性更强。
通过标准自编码器对不同激活函数的验证,当激活函数为LeakyReLU时,均方误差值为0.016,图5和图6b直观地反映LeakyReLU函数下的重构曲线非常接近原曲线。当 p=50时,2种降维方法非线性降维均方误差值都略小于线性降维均方误差值。
3 结论
本文提出了自适应自编码器方法,并利用碰撞试验假人力学响应数据进行验证,结果表明对于合成加速度类型的响应曲线,该方法在保证低维数据重构均方误差值低、维度可调的同时,实现线性和非线性的降维,所得到的低维数据互相关系数小、独立性强,能有效地解决假人响应数据与各类设计参数构建函数关系时存在维度过高问题。
主要研究结论如下:
1) 相比于标准自编码器,自适应自编码器得到的低维数据间互相关系数更小,独立性更强,更有利于函数的拟合。
2) 自适应自编码器能够实现线性和非线性降维,能够将低维数据重构回高维数据。
3) 自适应自编码器实现非线性降维的关键在于非线性激活函数的选择,通过相同网络结构下不同激活函数的对比验证,选择LeakyReLU函数适用于本文的样本数据降维。
