基于改进XLNet算法的震后舆情分析研究
2024-01-01郑通彦王尅丰黄猛张淞周文涛游巧刘帅

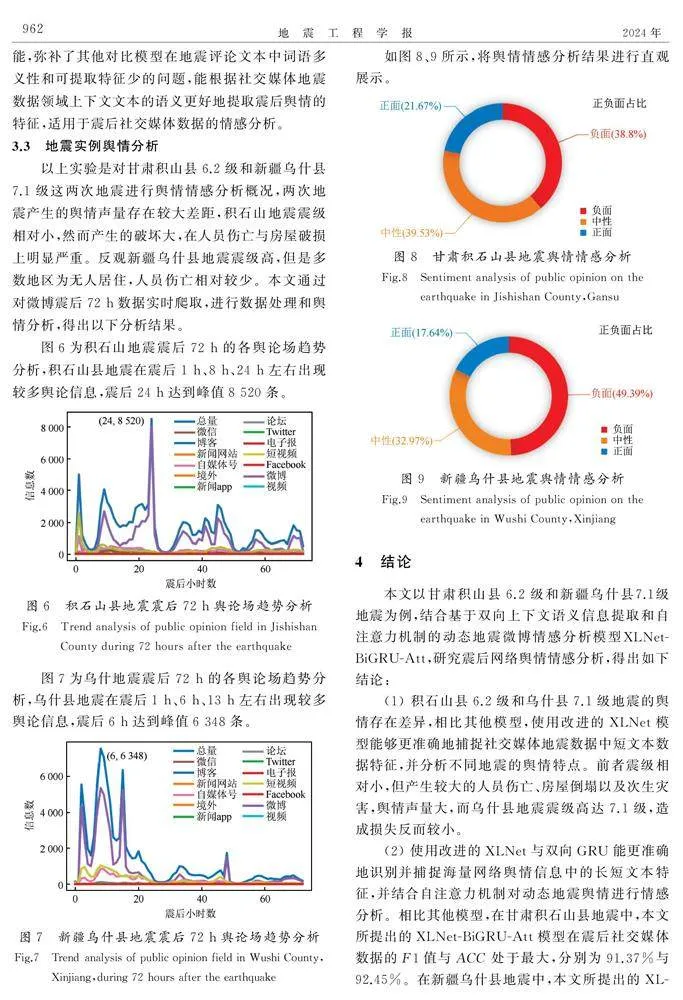







摘要:震后对网络舆情信息的监控与分析,对于相关部门开展震灾应急救援、掌握救灾动态、稳定民众情绪具有重要意义。为解决震后舆情信息数据量大、语言多义性等问题,文章使用自回归模型(XLNet)作为文本向量化表示层,将社交媒体地震数据文本转化为包含上下文语义信息的媒体数据词向量,同时,使用双向门控循环单元(BiGRU)网络作为特征提取层,把词向量序列输入到BiGRU层,提取社交媒体地震数据的文本特征;将初步提取特征的文本输入到注意力机制层(Attention),进一步提取更为重要的情感类别特征,并对重要特征进行权重强化,构建基于网络地震应急处置信息改进的XLNet-BiGRU-Att地震舆情情感分析模型;最终,获得社交媒体地震数据的舆情态势。相比传统的XLNet模型,文章模型在甘肃积石山县6.2级与新疆乌什县7.1级地震的舆情情感分析中能够准确,快速捕捉长短文本数据特征,分析舆情态势,情感分析准确率分别提升到92.45%和93.42%。
关键词:舆情分析; XLNet; BiGRU; 甘肃积石山; 新疆乌什
中图分类号: P315.9文献标志码:A文章编号: 1000-0844(2024)04-0955-10
DOI:10.20000/j.1000-0844.20240228002
Post-earthquake public opinion analysis based on improved XLNet
algorithm: a case study of the Jishishan, Gansu M6.2,
and Wushi, Xinjiang M7.1 earthquakesZHENG Tongyan WANG Kefeng HUANG Meng ZHANG Song
ZHOU Wentao YOU Qiao LIU Shuai
(1.China Earthquake Networks Center, Beijing 100045, China;
2.Institute of Disaster Prevention, Sanhe 065201, Hebei, China)Abstract:
The monitoring and analysis of public opinions on online platforms after earthquake aid is highly significant in emergency rescues, understanding disaster relief dynamics, and stabilizing public emotions. However, it is difficult to quickly gather and categorize these opinions given the large volume of post-earthquake public opinion data and polysemy of language. To address these problems, we employed the autoregressive model (XLNet) as a text vectorization layer, which converted the text of earthquake-related data on social media platforms into word vectors containing contextual semantic information. The bidirectional gated recurrent unit (BiGRU) network was used as the feature extraction layer, and the word vector sequence was input into the BiGRU layer to extract text features from these data. These texts were then input into the attention mechanism layer to extract features that are categorized based on sentiments that are highly important. The weights of important features were enhanced to construct an improved XLNet-BiGRU-Att sentiment analysis model based on the information gathered from online earthquake emergency responses. Finally, the public opinion situation of these data was obtained using the model. Compared with the traditional XLNet model, the proposed model yields higher accuracy and can more quickly capture the characteristics of both short and long text data gathered from the public opinion sentiment analysis of the Jishishan and Wushi earthquakes. We successfully increased the sentiment analysis accuracy to 92.45% and 93.42% for the Jishishan and Wushi earthquakes, respectively.
Keywords:public opinion analysis; XLNet; BiGRU; Jishishan in Gansu; Wushi in Xinjiang
0引言
地震灾害具有突发性和不可预测性,严重威胁人类生命财产安全和经济社会稳定[1-2]。地震发生后,通常会产生很多地震相关舆情,例如震感强弱、伤亡情况、余震情况和救援情况等[3]。将民众对地震灾害的认知、感知和响应、适应进行研究,是减轻灾害损失与影响的重要途径[4-5]。因此,震后社会舆情信息的监控、分析、处置和引导对相关部门开展震灾应急救援和稳定社会情绪具有重要意义。
近年来,伴随移动互联网技术的迅速发展,蕴含海量数据的社交媒体平台为开展地震舆情监测与分析提供了丰富的数据源[6]。社交媒体平台具有实时性、互动性、强扩散及空间分布广泛等特点,如微博评论已成为地震灾害舆情分析的主要数据源[7]。国内外学者基于社交媒体数据,对不同地震事件开展了地震舆情时空变化分析及情感分析等方面的研究。薄涛等[1]以微博为数据源,通过机器学习中的人工神经网络模型,建立了基于社交媒体数据的地震烈度快速评估方法。 Kryvasheyeu等[8]以2012年美国桑迪飓风为例,利用Twitter数据进行了飓风灾害损失评估,发现灾害损失越大,Twitter用户活跃程度越高。徐敬海等[9]提出基于位置的微博地震灾情提取流程,并以云南永善地震为例进行应用,取得较好效果。杨天青等[10]提出一种基于公众速报灾情信息的地震灾情过滤与推理方法,并以芦山地震为案例进行了方法验证。曹彦波等[11-12]以2014年景谷6.6级地震为例,基于微博舆情信息进行震后有感范围快速判定研究,并采用情感词典和规则相结合的方法,以2013年四川芦山7.0级和2017年九寨沟7.0级地震为例,基于震后24 h微博数据分析了地震灾区民众情绪反应特点。齐珉等[7]以2017年四川九寨沟7.0级地震为例,基于微博数据分析了社会民众对此次地震事件的情感倾向,并研究了影响网民情感波动的主要因素。郑嵘等[13]以2017年九寨沟地震和林芝地震为例,提出灾害微博的实时处理框架,并验证了原型系统的可用性。Qu等[14]对2010年玉树地震的新浪微博数据进行分类统计,并分析了民众对地震事件的情感。李亚芳等[3]分析了新疆伽师6.4级地震后48 h新浪微博相关的博文和评论,并将其可视化。陈昱杉等[15]以新浪微博关于“九寨沟地震”事件为例,提取响应时间、响应强度、传播强度、主题分布等舆情扩散特征的指标,研究了地理空间距离对网络舆情信息扩散的影响。
从社交媒体数据舆情持续时间与文本特点角度进行分析的研究还比较少。针对震后社交媒体数据集文本特点,本文结合震后72 h持续舆情变化,克服震后社交媒体数据集与通用数据集情感处理不同的困难,准确把握震后舆情传播趋势。通过分析研判舆情动向,强化网络舆情监测,提出舆情的引导建议,为震后环境下的应急机制提供参考依据。
具体来说,本文以2023年12月18日甘肃积山县6.2级和2024年1月23日新疆乌什县7.1级地震为例,采集了两次震后72 h内网络信息数据近20万条,其中包含震感信息、救援信息、人员伤亡信息等地震信息。为解决震后舆情信息数据量大和语言多义性等问题,拟采用XLNet模型作为预训练模型来捕捉短文本的数据特征,并结合双向GRU和注意力机制模型,分别捕捉网络剩余长序列文本和重要信息特征,构建一个基于双向上下文语义信息提取和自注意力机制的动态地震微博情感分析模型XLNet-BiGRU-Att,进一步提高地震案例分析的速度和准确率,以期为科学有效的地震应急管理提供辅助参考。
1研究对象与数据处理
1.1甘肃积石山县6.2级地震
2023年12月18日23时59分,在甘肃临夏州积石山县(35.7°N,102.79°E)发生6.2级地震,震源深度10 km,兰州、定西、临夏等地震感强烈。甘肃积石山6.2级地震最大烈度为Ⅷ度,Ⅵ度区及以上面积8 364 km2。震后泥石流、滑坡、崩塌等次生灾害随之发生,地震还造成多处交通中断。
1.2新疆乌什县7.1级地震
2024年1月23日2时9分,在新疆维吾尔自治区阿克苏地区乌什县(41.26°N,78.63°E)发生7.1级地震,震源深度22 km。截至当日8时统计显示,全县范围内房屋共倒塌房屋47间、受损78间。截至2024年1月26日8时,共记录到余震4 216次,其中,3.0级以下4 067次,3.0级及以上149次:3.0~3.9级121次,4.0~4.9级21次,5.0~5.9级7次。最大余震5.7级,距主震震中约22 km。地震最大烈度为Ⅸ度,Ⅵ度区及以上面积27 926 km2。
1.3数据采集
地震应急数据包括地震行业官网数据、主流新闻媒体网站数据、微博数据、论坛以及贴吧数据等,如图1、2所示。本文从数据挖掘和机器学习的角度出发,采用基于Python的Selenium自动化技术,结合高级调度器模块多时段分布式任务调度[16],从央视网、人民网、新浪新闻、网易新闻、搜狐新闻、新浪微博、抖音、快手等主流媒体网站中分别获取了震后72 h内甘肃积石山县6.2级地震和新疆乌什县7.1级地震应急处置信息相关数据113 000条和91 800条,构建地震应急事件相关的舆情分析数据集,为模型实验提供了数据支持。社交媒体地震评论有其自身的数据特点,如表1所列。
从社交媒体与新闻网站上采集到海量的震后相关舆情信息后,对数据进行预处理:首先,对海量的数据进行清洗与去重操作,例如在数据中会包含“@XXX”、“#XX”等字符,对这类文本进行正则化,去除文本中的特殊字符、空格以及非中文字符;然后,处理地震社交媒体数据文本中的停用词,提高文本处理的效率和准确性,同时由于多数舆情评论文本中存在emoji表情,采用emoji-switch库将emoji表情转换为相应的中文文本,与文本信息一起构成数据集;最终,形成初步清洗后的地震网络信息数据集,包含150 083条震后社交媒体数据。
之后,对清洗过的地震网络信息数据集进行情感标注,以大连理工大学林鸿飞团队整理的中文情感词汇本体库作为模型的情感标注来源,将“乐”“好”等定义为正向情感[积极],将“怒”“哀”“惧”“惊”等定义为负向情感[消极],其余为[中性];对这些数据进行情感三分类的标注后,最终得到了经过清洗、标注、增强预处理的120 567条地震社交媒体数据。
2研究方法
2.1预训练语言模型
与基于自回归语言建模的预训练处理方法相比,基于自编码的预训练处理方法具有较强的双向上下文建模能力,例如双向编码器表征法(Bidirectional Encoder Representations from Transformers,BERT)。然而,BERT模型使用掩码破坏输入的方式,更容易忽略掩码位置之间的依赖性,会导致预训练-微调(pretrain-finetune)的差异。在2019年,谷歌提出了一种新的自然语言处理(Natural Language Processing,NLP)预训练模型XLNet,这是一种广义的自回归预训练模型方法。它实现了双向的上下文学习,通过最大化因子分解顺序中所有排列的预期期望可能性进行学习。XLNet通过自回归公式克服了BERT依赖掩码位置的局限性,并将Transformer-XL的思想结合到预训练模型中,在文本表示语言任务中表现出色。自回归语言模型(AutoRegressive Language Modeling,AR)方法只能学习单词之间的依赖关系,自编码语言模型(AutoEncoding Language Modeling,AE)方法只能学习深度双向语义信息,这两种模型单独使用时都有各自的优点和劣势问题。而XLNet正是将AR和AE方法的优势结合起来,基于AR模型融入双向语言模型,提出一种随机排序语言模型(Permutation Language Modeling,PLM),避免了原始的自回归模型不能结合上下文信息,以及自编码语言模型由于mask导致的独立性和数据分布一致性等缺点。
XLNet的核心思想是以排列组合的方式重构输入的社交媒体地震数据文本,引入PLM的训练目标并对全排序的序列进行采样优化,在自回归语言模型上实现了双向预测,并通过对上下文进行语义特征双向表示,可以解决在社交媒体地震数据文本中的词语在不同语境下存在的多义性问题。
接着使用XLNet模型中的Attention掩码机制,其原理是在Transformer内部遮盖不需要的部分,使这部分在预测时不起作用。但从模型外部看,文本顺序与输入时一致,都为从左向右的单向输入。图3所示为XLNet掩码机制实现方式举例。图中原始输入句子为地震社交媒体数据文本[楼,蹦,迪,一,样,吓,死],假设随机生成序列为[楼,蹦,迪,一,样,吓,死],但输入到XLNet中的句子仍然是[楼,蹦,迪,一,样,吓,死],那么在XLNet内部是以图中掩码矩阵实现的。对于排列后的“楼”字来说,由于在首位无参考信息,因此第一行无阴影,假设当排列后的“迪”字位于最后一个位置,可以参考的信息有[楼,蹦,一,样,吓,死]。以此类推,因此序列的真实的输入顺序并没有改变,只是通过掩码的操作展示出随机排序的效果。
XLNet模型中PLM与Attention掩码机制结合可以解决AR方法中不能看到上下文语义的问题,具体是通过上下文双向语义的特征表示,更加全面了解词语在语境中的意思。但是在PLM模型中,全排序语序随机打乱也带来了原Transformer无法解决的问题:例如输入序列为[楼,蹦,迪,一,样,吓,死],给定一种排列方式为[死,样,楼,迪,一,蹦,吓],当要预测第三个位置时,即“楼”,其概率为P(楼|死,样),如果此时给定另一种排列为[死,样,蹦,一,楼,吓,迪],当要预测第三个位置,即“蹦”,其概率为P(蹦|死,样),此时预测“楼” 和“蹦”的概率相等,但实际是表示了不同的词义。这是由于原AR方法是按顺序基于上文进行预测,不需要考虑位置信息,但PLM为全排列方式,当位置打乱后就无法辨别出原始位置,即在PLM模型中不能将位置信息与要预测的内容信息分离开来进行预测。
XLNet模型中的双流自注意力模型可以解决这个问题:双流可以分为ContentStream和QueryStream,ContentStream用于表示每个token的内容信息,QueryStream表示每个token在原始输入句子中的位置信息。双流自注意力模型的工作原理为:在ContentStream中,对于图3,若要预测“楼”,需要编码上下文的位置和内容信息,以及“楼”本身的位置和内容信息;在QueryStream中,若要预测“楼”,需要编码其上下文信息以及“楼”本身的位置信息。图4为XLNet模型的双流模型图。
式中:m为网络层的数量;Q、K和V为注意力机制的Query、Key和Value,Query用于指定要关注的内容或属性,Key包含与查询相关的信息,主要用于与查询进行比较,Value为包含实际的信息或属性,我们希望从注意力机制中获取这些值。一般情况下,内容隐藏状态会被初始化为e(x),表示随机初始化的词向量,查询隐藏状态会被初始化为一个变量w。XLNet预训练语言模型以Transformer-XL框架为核心,引入循环机制和相对位置编码,充分利用了上下文语义信息,用模型学到的知识计算出文本的向量表达,以解决社交媒体地震数据文本中出现的词语在不同语境信息下语义不同的问题。在XLNet-BiGRU-Att模型中,XLNet层将输入序列转化为可被BiGRU层接收的词向量序列,进行特征提取。
2.2注意力机制
注意力机制主要来源于人类视觉的处理过程,通过浏览信息获取人类视觉的注意力焦点,提取出文本所想表达的当前任务中的关键信息。人类的视觉生理就是一种Attention机制,将有限的注意力放在重要信息上,节省资源,以便快速获得最有效的信息。注意力机制的本质为许多Query、Key、Value所组成的函数,通过关注输入权重的分配,使模型可以得到更准确的语义信息,以式(3)为注意力机制的目标函数:
注意力机制应用于不同社交媒体地震数据进行情感分析任务时,将经过XLNet模型向量化和BiGRU网络提取后的地震评论文本特征输入到其中,对地震评论文本序列中重要特征增加权重值,使模型更加注重于重要特征中的内容,以此提升BiGRU网络的特征提取能力。之后通过Softmax归一化对加权后的向量进行处理,得到句子的情感倾向值,至此模型的训练任务完成。
2.3情感分析方法
本文主要对震后舆情评论进行情感分析,情感分析为倾向性分析和意见挖掘,是对带有情感色彩的主观性文本进行自动解释和分类情感(通常是积极、消极或中立)的分析过程。目前地震灾情获取方法基本形成了基于遥感的方法、基于地震台网方法和基于社会网络(如短消息等)的方法等[16-18]。地震发生后,大量网友在新浪微博发布与地震相关的博文和评论,信息中包含民众的各种情感色彩和情感倾向性的表达,如高兴、生气、悲伤、赞扬、谴责等。通过分析这些信息的主观色彩,可以把握民众舆论对于地震事件的看法和情感倾向。本文主要采用改进的XLNet-BiGRU-Att地震舆情情感分析模型,对经过预处理与标注的数据进行分析,针对舆情文本信息进行情感评价,即情感极性判定。其中,消极情绪主要是指民众对地震表现出害怕、恐慌、悲观等负面情绪;积极情绪主要是指民众表现出乐观、祝福、鼓励等正面情绪;中性情绪是指其表达的正面和负面情绪相抵消,或未表现出主观情绪。通过舆情情感分析结果,可视化表达民众当前的情感状况。
3实验与模型评估
3.1XLNet-BiGRU-Att模型地震舆情情感分析
针对社交媒体地震数据的多义性和特征提取困难等问题,为更好地捕捉震后社交媒体数据的文本特征,使用XLNet模型作为文本向量化表示层,将媒体数据文本转化为包含上下文语义信息的媒体数据词向量,使用BiGRU 网络作为特征提取层,并把词向量序列输入到BiGRU层提取媒体数据的文本特征,再将初步提取特征的文本输入到注意力机制层,进一步提取情感类别特征,对重要特征进行权重强化,最终获得媒体数据的情感倾向结果值。本文提出的XLNet-BiGRU-Att模型充分利用上下文的语境信息和与地震舆情相关的情感信息,在一定程度上解决了XLNet模型在媒体数据情感分析方面可提取特征少、未考虑单词间句法依存导致的词语多义性等问题。其中XLNet-BiGRU-Att模型的体系结构如图5所示,主要由以下6个部分组成:文本输入层、XLNet层、BiGRU层、注意力机制层、Softmax层和输出层。实验过程如下:
(1) 数据预处理。对震后网络舆情信息进行情感动向分析的第一步,即将数据文本去重、去除特殊符号、空格等;去除文本信息中的停用词以及将emoji表情转为相应的中文字符;最后对震后舆情评论进行情感词性标注。
(2) 文本输入。将数据预处理后的地震微博文本输入到XLNet中,对输入的地震社交媒体数据文本进行序列化表示。输入文本的长度为n,文本序列为X=(X1,X2,…,Xn),Xn表示文本数据的第n个字。
(3) 社交媒体地震数据文本向量化表示。针对XLNet模型中输入的序列化媒体数据文本数据,在查找字典后将每个词转化为对应的字典编号,得到序列化媒体数据文本数据E,利用Transformer-XL自回归编码器进行训练,将媒体数据文本数据进行动态表示,得到媒体数据文本词向量表示g。在使用Transformer-XL自回归编码器时,计算当前媒体数据文本中每个词与其他词之间的相对位置关系,利用相对位置信息去调整每个词的权重,从而获得媒体数据文本句子中每个词对应的词向量。通过这种方法学习到的词向量g,充分利用了媒体数据文本中词的上下文关系,使得媒体数据文本中每个词在不同上下文语境中具有更好的表达。
(4) 提取社交媒体地震数据语义特征。将从XLNet层中学习到的媒体数据文本对应的词向量传给BiGRU层,利用前向GRU层和后向GRU层:前向GRU顺序提取深层的语义特征,后向GRU逆序提取,经过多个GRU隐藏单元的训练,最终得到两个文本向量的上下文语义特征,分别记作媒体数据文本向量F1和F2。
(5) 文本特征拼接及权重赋值。拼接正向语义特征社交媒体地震数据文本向量F1和反向语义特征社交媒体地震数据文本向量F2,并通过Attention层对媒体数据的特征向量进行权重赋值,使模型对媒体数据文本向量中的重要特征提高注意力,最后通过softmax激活函数输出对应媒体数据文本的情感分类。
3.2模型评估
实验选取卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN)、BERT、FastTest、BERT+BiLSTM、XLNet等模型为6个对照实验组,与本文提出的基于XLNet算法的震后网络舆情分析模型(XLNet-BiGRU-Att)通过社交媒体地震数据集进行对比训练,并对甘肃积山县6.2级和新疆乌什县7.1级地震震后社交媒体数据进行模型测试评估。
由于在积石山县与乌什县地震中含有较多地震相关特殊情况,如积石山县地震震级相对较小,但伤亡严重,乌什县地震震级大,但损失较小。因此,震后舆情评价的结果可以对比实验得出最适合地震领域的情感分析模型。本文的评价指标为情感分类模型性能常用指标,包括F1值(F1-score)、准确率(Accuracy,ACC)。震后微博舆情数据实验的测试结果如表2、3所列。
通过表2、3中准确率ACC值和F1值的实验结果可以看出,在甘肃积石山县地震中,本文所提出的XLNet-BiGRU-Att模型的F1值与ACC最大,分别为91.37%与92.45%;在新疆乌什县地震中,本文所提出的XLNet-BiGRU-Att模型的F1值与ACC最大,分别为93.52%与93.52%。其中BERT模型和XLNet模型是基于Transformer构建的,在结合社交媒体地震数据上下文语义消除词语多义性方面,优于FastText、CNN模型的训练效果。XLNet模型在地震媒体数据领域文本的准确率和F1值上更优于BERT模型,尤其在地震特点明显的震后社交媒体数据文本数据集中的实验结果更加突出。
实验表明,虽然XLNet方法的实验结果比较理想,但本文所提出的XLNet-BiGRU-Att模型在社交媒体地震数据文本中相较于基础模型XLNet,准确率及F1值都有一定程度的提升,表明在地震舆情分析领域,XLNet-BiGRU-Att模型具有良好的性能,弥补了其他对比模型在地震评论文本中词语多义性和可提取特征少的问题,能根据社交媒体地震数据领域上下文文本的语义更好地提取震后舆情的特征,适用于震后社交媒体数据的情感分析。
3.3地震实例舆情分析
以上实验是对甘肃积山县6.2级和新疆乌什县7.1级这两次地震进行舆情情感分析概况,两次地震产生的舆情声量存在较大差距,积石山地震震级相对小,然而产生的破坏大,在人员伤亡与房屋破损上明显严重。反观新疆乌什县地震震级高,但是多数地区为无人居住,人员伤亡相对较少。本文通过对微博震后72 h数据实时爬取,进行数据处理和舆情分析,得出以下分析结果。
图6为积石山地震震后72 h的各舆论场趋势分析,积石山县地震在震后1 h、8 h、24 h左右出现较多舆论信息,震后24 h达到峰值8 520条。
4结论
本文以甘肃积山县6.2级和新疆乌什县7.1级地震为例,结合基于双向上下文语义信息提取和自注意力机制的动态地震微博情感分析模型XLNet-BiGRU-Att,研究震后网络舆情情感分析,得出如下结论:
(1) 积石山县6.2级和乌什县7.1级地震的舆情存在差异,相比其他模型,使用改进的XLNet模型能够更准确地捕捉社交媒体地震数据中短文本数据特征,并分析不同地震的舆情特点。前者震级相对小,但产生较大的人员伤亡、房屋倒塌以及次生灾害,舆情声量大,而乌什县地震震级高达7.1级,造成损失反而较小。
(2) 使用改进的XLNet与双向GRU能更准确地识别并捕捉海量网络舆情信息中的长短文本特征,并结合自注意力机制对动态地震舆情进行情感分析。相比其他模型,在甘肃积石山县地震中,本文所提出的XLNet-BiGRU-Att模型在震后社交媒体数据的F1值与ACC处于最大,分别为91.37%与92.45%。在新疆乌什县地震中,本文所提出的XLNet-BiGRU-Att模型在震后社交媒体数据的F1值与ACC处于最大,分别为93.52%与93.52%。表明在地震舆情领域,XLNet-BiGRU-Att模型能够更准确地提取震后舆情特征,弥补了其余对比模型在社交媒体地震数据文本中词语多义性和可提取特征少的问题。
(3) 通过舆情分析获取到两次地震的灾情相关信息。可以看到,以网络舆情信息为基础的AI提取分析模型虽然在舆情情感分析上取得了较好的结果,但是文本可能在震后舆情信息中覆盖面过大,提取时会去除较多有用的信息。因此,特征提取模型在真实震例中应不断修正和积累,在之后的地震应用中,不断完善自主学习与更新修正过程。
参考文献(References)
[1]薄涛,李小军,陈苏,等.基于社交媒体数据的地震烈度快速评估方法[J].地震工程与工程振动,2018,38(5):206-215.BO Tao,LI Xiaojun,CHEN Su,et al.Research of seismic intensity rapid assessment based on social media data[J].Earthquake Engineering and Engineering Dynamics,2018,38(5):206-215.
[2]刘磊,赵东升,朱瑜,等.1993—2017年我国大陆地震灾害损失的时空特征[J].自然灾害学报,2021,30(3):14-23.LIU Lei,ZHAO Dongsheng,ZHU Yu,et al.Spatiotemporal characteristics of earthquake hazard losses in China's mainland during 1993-2017[J].Journal of Natural Disasters,2021,30(3):14-23.
[3]李亚芳,王新刚,梁庆云.基于新浪微博大数据的新疆伽师6.4级地震舆情分析及可视化研究[J].内陆地震,2020,34(1):103-110.LI Yafang,WANG Xingang,LIANG Qingyun.Public opinion analysis and visualization of Xinjiang Jiashi MS6.4 earthquake based on Sina Weibo big data[J].Inland Earthquake,2020,34(1):103-110.
[4]苏桂武,马宗晋,王若嘉,等.汶川地震灾区民众认知与响应地震灾害的特点及其减灾宣教意义:以四川省德阳市为例[J].地震地质,2008,30(4):877-894.SU Guiwu,MA Zongjin,WANG Ruojia,et al.General features and their disaster-reduction education implications of the earthquake disaster cognition and responses of the social public in MS8.0 Wenchuan earthquake-hit area:a case study from Deyang prefecture-level city,Sichuan Province[J].Seismology and Geology,2008,30(4):877-894.
[5]王若嘉,苏桂武,张书维,等.云南普洱地区中学生认知与响应地震灾害特点的初步研究:以2007宁洱6.4级地震灾害为例[J].灾害学,2009,24(1):133-138.WANG Ruojia,SU Guiwu,ZHANG Shuwei,et al.A preliminary study on the characteristics of cognition on and response to earthquake disaster of the middle school students in Puer area,Yunnan Province,China:a case study on the 2007 ninger earthquake with MS6.4[J].Journal of Catastrophology,2009,24(1):133-138.
[6]杨腾飞,解吉波,闫东川,等.基于深度学习的社交媒体情感信息抽取及其在灾情分析中的应用研究[J].地理与地理信息科学,2020,36(2):62-68.YANG Tengfei,XIE Jibo,YAN Dongchuan,et al.Extracting sentiment information from social media based on deep learning and the research on disaster reduction[J].Geography and Geo-Information Science,2020,36(2):62-68.
[7]齐珉,齐文华,苏桂武.基于新浪微博的2017年四川九寨沟7.0级地震舆情情感分析[J].华北地震科学,2020,38(1):57-63.QI Min,QI Wenhua,SU Guiwu.2017 Sichuan Jiuzhaigou M7.0 earthquake sentiment analysis based on Sina Weibo[J].North China Earthquake Sciences,2020,38(1):57-63.
[8]KRYVASHEYEU Y,CHEN H H,OBRADOVICH N,et al.Rapid assessment of disaster damage using social media activity[J].Science Advances,2016,2(3):e1500779.
[9]徐敬海,褚俊秀,聂高众,等.基于位置微博的地震灾情提取[J].自然灾害学报,2015,24(5):12-18.XU Jinghai,CHU Junxiu,NIE Gaozhong,et al.Earthquake disaster information extraction based on location microblog[J].Journal of Natural Disasters,2015,24(5):12-18.
[10]杨天青,姜立新,席楠.地震速报灾情信息过滤与推漫方法研究:以芦山7.0级地震为例[J].自然灾害学报,2015,24(1):96-103.YANG Tianqing,JIANG Lixin,XI Nan.Filtering and deduction method of rapidly-report earthquake disaster information:taking Lushan 7.0 magnitude earthquake as an example[J].Journal of Natural Disasters,2015,24(1):96-103.
[11]曹彦波,吴艳梅,许瑞杰,等.基于微博舆情数据的震后有感范围提取研究[J].地震研究,2017,40(2):303-310.CAO Yanbo,WU Yanmei,XU Ruijie,et al.Research about the perceptible area extracted after the earthquake based on the microblog public opinion[J].Journal of Seismological Research,2017,40(2):303-310.
[12]曹彦波.基于社交媒体的地震灾区民众情绪反应分析[J].地震研究,2019,42(2):245-256.CAO Yanbo.Analysis of People's emotional response in earthquake-stricken areas based on the social media[J].Journal of Seismological Research,2019,42(2):245-256.
[13]郑嵘,张晨晓,乐鹏,等.基于微博的灾害信息快速提取方法研究[J].测绘地理信息,2020,45(5):133-137.ZHENG Rong,ZHANG Chenxiao,LE Peng et al.Disaster information extraction from microblog[J].Journal of Geomatics,2020,45(5):133-137.
[14]QU Y,HUANG C,ZHANG P Y,et al.Microblogging after a major disaster in China:a case study of the 2010 Yushu earthquake[C]//Proceedings of the ACM 2011 Conference on Computer Supported Cooperative Work.Hangzhou China:ACM,2011:25-34.
[15]陈昱杉,李凤全,王天阳,等.网络舆情信息扩散中距离的影响:以新浪微博“九寨沟地震” 事件为例[J].浙江师范大学学报(自然科学版),2020,43(1):77-84.CHEN Yushan,LI Fengquan,WANG Tianyang,et al.The role of distance in Internet public opinion diffusion:taking Sina microblog “Jiuzhaigou earthquake” as an example[J].Journal of Zhejiang Normal University (Natural Sciences),2020,43(1):77-84.
[16]赵福军,蔡山,陈曦.遥感震害快速评估技术在汶川地震中的应用[J].自然灾害学报,2010,19(1):1-7.ZHAO Fujun,CAI Shan,CHEN Xi.Application of rapid seismic damage assessment based on remote sensing to Wenchuan earthquake [J].Journal of natural disasters,2010,19(1):1-7.
[17]帅向华,郑向.防震减灾公益服务短信技术平台设计与实现[J].自然灾害学报,2011,20(6):40-44.SHUAI Xianghua,ZHENG Xiang.Design and realization of SMS technology platform for earthquake disaster mitigation public service[J].Journal of Natural Disasters,2011,20(6):40-44.
[18]AMIRI G G,KHORASANI M,MIRZA H R,et al.Ground motion prediction equations of spectral ordinates and arias intensity for Iran [J].Journal of Earthquake Engineering,2009,14(1):1-29.
(本文编辑:贾源源)
