人眼视觉特性与视频编码压缩技术探讨
2023-12-31曾伟民
曾伟民
(星宸科技股份有限公司,福建厦门 361000)
作为视频编码使用频率相对较高的视频监控领域,对于视频编码压缩技术的应用具有非常高的标准,需要在各种场景中实时拍摄千变万化的图像,包括各种运动和非运动的人和物体等。其中视频背景是固定的最为常见,例如风景、建筑物,在较长时间内并不会发生变化,或者只发生非常轻微的变化。本人在查阅大量相关资料后认为针对此场景,可以从人眼视觉特征角度,对现有的视频监控领域的视频编码压缩技术做定向改进和优化,可以获得更优的视频编码压缩效果。
1 针对视频监控领域的视频编码压缩技术相关研究
在监控视频中,存在较长时间不发生变化的背景,会生成背景冗余问题,可以通过模拟人眼视觉,锁定运动物体,忽略静置物体的特性,将等待处理的视频图像划分为静止图层与运动图层2 个图层,合理控制作为背景的静止区域在视频编码压缩过程中的压缩率。
如果采用视频帧序列背景去除算法,可以通过随机背景更新方式,提升监控视频的模型工作效率,却也存在一定的目标不完整问题,以及因光线变化产生的“鬼影”问题。如果空间平面存在2 个黑点,在两者间距达到一定程度后,此时距离黑点有一定距离的人是无法区分黑点的数量,这个观察景物细节的极限数值即为分辨率。如果在观察的目标运动速度加快时,此时人眼的分辨率会出现明显下降。
本文对视频帧序列背景去除算法做详细分析后发现,可以通过从监控视频本体出发,根据人眼视觉的分辨率特性,将更多资源应用到运动物体的运动图层中,合理控制视频编码压缩的侧重点。
2 基于人眼视觉特性的视频编码压缩技术
2.1 视频编码技术整体框架
从人眼视觉特征角度分析视频编码技术的框架系统,需要先明确监控视频的固定背景+运动对象的特点,再确认观察运动对象的实际需求。明确这2 项内容后,通过运动目标检测技术,对监控视频划分为需要关注的监控观察部分,以及拥有人眼视觉冗余的视频背景部分。在提取运动目标、背景图层的重要数据信息后,对2 项内容分别做编码处理。
视频编码技术的框架系统可以划分为以下几个环节:第一,输入视频;第二,检测运动目标、构建背景图层;第三,编码背景图层,同时提取运动目标,并为运动目标进行编码;第四,形成压缩文件;第五,解码背景图层与运动目标;第六,图像整合;第七,输出视频。
2.2 背景模型构建
在实际应用中,视频帧序列背景去除算法不仅存在鬼影问题,也会出现背景更新速度偏慢的问题。
为合理解决这2 项问题,本文在设计视频编码压缩技术算法时,针对背景模型的初始化内容额外增加预处理环节,以时间轴的方式对监控视频做分段处理,以分段后的监控视频构建相应的背景模型。再根据每个像素的像素值,以及相邻像素点的像素值,构建足够规格的样本集。在产生新的像素值后,会在最短时间内与已有的样本集做可靠比较。如果样本集内拥有新的像素点,证明此时不需要对背景模型做任何程度的处理;如果新的像素点不在样本集内,则要立即展开对背景模型的更新工作。
同时,在视频帧序列背景去除算法的基础上,将灰度图像自适应阈值分割算法与其进行整合,可以对运动的目标进行更准确的检测作业,以此形成详细且完整的监控视频背景图像。又因为在监控视频中,绝大多数的视频背景并不会产生太大的变化,这也意味着背景图的序列不会产生大幅度的变化[1]。
2.3 视频编码与解码
现阶段应用的视频编码标准有以下2 种,分别为ITU.T(ITU-T for ITU Telecommunication Standardiza tion Sector,国际电信联盟电信标准分局)制定的H.26X系列标准,以及ISO(International Organization for Standardization,国际标准化组织)制定的MPEG 系列标准。其中,H.26X 系列标准的H.264,是以H.263 为基础,对MPEG 部分使用优点进行吸收、借鉴,有效提升视频编码压缩性能。本文在分析各类视频编码标准后,选择以H.264 为基础,进行监控视频运动目标与静止背景的编码工作,静止的背景帧作为参考帧使用[2]。
2.3.1 视频编码
对于视频编码,可以细分为背景编码、目标提取、目标编码3 个部分。
第一部分为背景编码,即对视频帧序列背景去除算法进行优化,提取运动目标,并构建监控视频的背景。其中,静止背景存在大量多帧视频共同使用的数据信息,在实际应用中并不需要对每帧视频进行编码。可以先设置一个编码间隔,同一间隔内的视频帧使用相同的背景图,作为共同的图像背景使用,以此提升背景编码效率。
对于静止背景的图像编码一帧图像,可以采用以下几个步骤完成,如图1 所示(以下步骤要形成流程图)。

图1 静止背景的图像编码一帧图像流程图
第一步,对静止背景的图像进行检测,判断其是否是这个监控视频的第一张静止背景图像。如果是,则执行第二步内容。如果不是,则执行第三步内容。
第二步,针对监控视频输入的整帧图像,通过帧内预测编码进行处理。这个过程与传统编码器的编码过程相同,即使用给定帧的相邻宏块的空间相关性,对现有的宏块进行预测,并根据预测情况选择合适的预测模式,完成预测误差的变换处理,并对误差结果做相应的量化,最后对量化后的误差结果做熵编码。
第三步,针对输入整帧图像,既使用帧内预测编码,也使用帧间预测编码处理,以编码的时间成本进行比较,最后选择时间代价最低的编码方式。对于帧间预测编码,其是通过分析连续的静止背景图像拥有的时间冗余,完成整个监控视频的运动估计与运动补偿处理[3]。
第二部分为目标提取,即对于监控视频中的运动目标可以抽象成具有形状可变特性,而且变化无规则的区域性质图像。对于运动目标在监控视频中的区域,是将当前帧与静止背景图像做相减处理,拥有超过阈值的前景图像数据。
为提升运动目标的编码效率,可以将运动目标放置在由若干矩形块组合排列形成的不同形状目标块。在本文设计中,目标块的最小单位将被设计为16×16规格。具体做法是将整帧图像划分成多个16×16 规格的宏块,在对运动目标做编码处理时,锁定运动目标的目标块,并对其做编码处理即可。
第三部分为目标编码,即在监控视频中对运动目标进行提取,可以确认每帧图像都存在若干个16×16的目标块。在每帧图像中,运动目标的目标块数量、位置具有动态变化的特性,所以在对每帧图像的运动目标进行编码处理时,需要拆分成运动目标块位置信息、运动目标块图像数据2 项内容,并对两者分开进行编码处理。
本文将运动目标的编码一帧图像算法整理为如下流程,如图2 所示(以下步骤要形成流程图)。
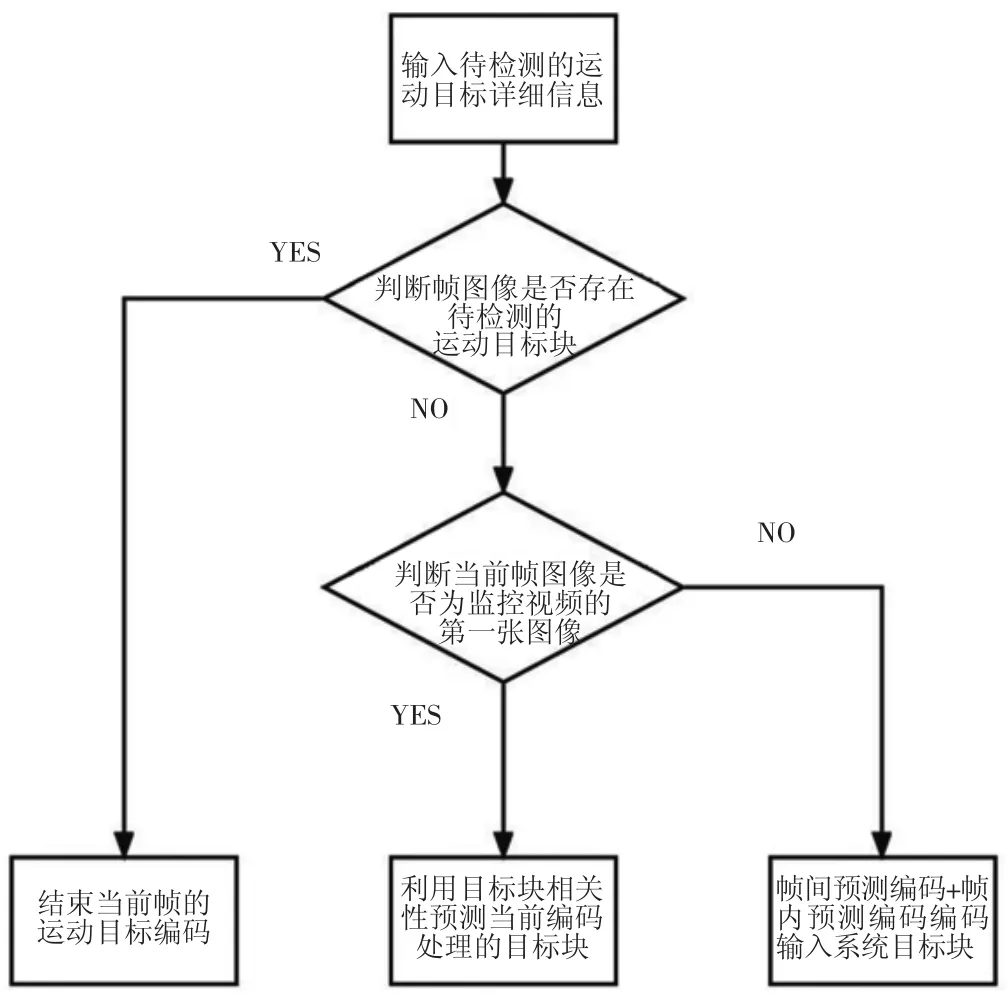
图2 运动目标的编码一帧图像算法
第一步,在视频编码压缩系统中,输入待检测的运动目标详细信息,再对监控视频的当前帧图像是否存在待检测的运动目标块进行判断,确认是否需要跳过本次编码作业。如果确认跳过编码程序,当前帧的运动目标编码工作结束。如果不跳过编码程序,则执行第二步内容。
第二步,对当前帧图像是否为监控视频的第一张图像进行判断。如果判断为是,则执行第三步内容。如果判断为不是,则执行第四步内容。
第三步,通过帧内预测编码,完成输入系统中的目标块的编码处理。考虑到在编码过程中,目标块是被抽象处理后的运动目标,并不是完整图像,可以通过本帧监控图像的其他未编码处理的目标块,利用目标块之间的相关性,对当前编码处理的目标块进行预测。
第四步,通过帧间预测编码+帧内预测编码组合的方式,对输入系统中的目标块做编码处理。对于运动目标中的帧间预测编码,则是通过监控视频的连续帧运动目标块拥有的时间冗余,完成运动估计与运动补偿作业[4]。
2.3.2 视频解码
对静止背景与运动目标做解码处理后,需要根据H.264 视频编码标准,对两者进行整合,形成最后的视频图像。可以理解为如果在监控视频中拥有待监控的运动目标时,则将其作为运动目标的像素值进行分析。如果监控视频中不存在运动目标,则要将静止背景像素值作为分析对象。而分析大量的实验数据后,发现将静止背景与运动目标进行合成,获得的视频图像,与没有处理的监控视频相比较,在人眼观察中,并没有太大的质量差异[5]。
3 实验结果分析
本文将选择6 段视频序列,以多个维度对本文提出的视频编码压缩技术进行综合测试分析。对于编码间隔,本文预先设定为200 帧。汽车监控视频分辨率为320×240,旅馆大厅监控视频分辨率为352×240,仅有烛光的房间监控视频分辨率为352×288,实验室监控视频分辨率为768×576,图书馆监控视频分辨率为160×128,地铁监控视频分辨率为720×576。
3.1 背景模型构建质量
选择汽车、旅馆大厅、烛光房间3 个监控视频,作为背景模型构建质量的测试序列,将本文设计的视频编码压缩技术与H.264 编码方法进行比较,并将码率设置为横坐标,将峰值信噪比设置为纵坐标,即可获得相应的散点图。通过对比三者的散点图,可以发现在相同的视频序列中,如果QP(Quantization Parameter,量化参数)数值较小,比较的2 种方法在运动目标所在的监控视频区域内,峰值信噪比并没有明显的差别,但是会根据视频编码压缩处理的对象,出现一定程度的变化;如果QP 数值较大,比较的2 种方法的峰值信噪比与视频编码压缩效率也没有过于明显的差别。
3.2 压缩效率对比
以实验室、地铁、图书馆3 个监控视频作为压缩效率对比的测试序列,并将QP 数值固定为27,选择10、20、50、100、150 和200 帧的监控视频,分析其压缩文件的压缩效率。通过对比大量数据,可以发现本文设计的视频编码压缩技术相较于H.264 方法,在视频编码压缩效率方面有较大幅度的提升,见表1。
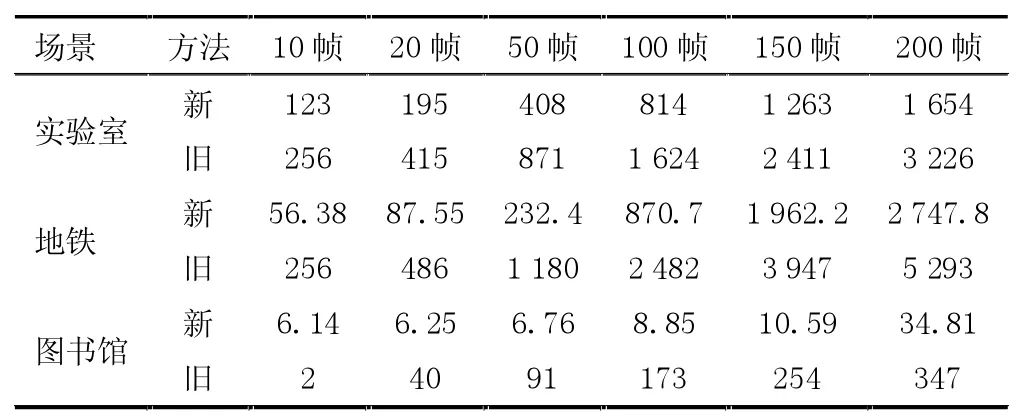
表1 压缩效率对比
对本文压缩的视频文件经解码后重建图像,并与原始H.264 编解码后的图像进行对比,可以发现,本文设计的视频编码压缩技术在总体方面,要比H.264 方法拥有更高的压缩效率,但是不同的视频序列存在一定的差异。相对而言,在图书馆的视频序列压缩率中,本文设计的方法相比于H.264 方法在压缩率方面拥有90.9%的提升幅度。其原因是这个视频序列选择的场景是在整个图书馆人流量较少的角落,在大多数时间中,并不会出现过多的待监控运动目标。对于地铁的视频序列中,本文设计的方法相比于H.264 方法在压缩率方面拥有48.1%的压缩率,其原因是这个视频序列选择地铁站,在正常工作时间内会出现较多的运动目标,在监控视频中占据较大比例。而在实验室的视频序列中,压缩率则是在地铁视频序列与图书馆视频序列之间。通过以上信息可以分析,本文设计的视频编码压缩技术,如果在监控视频中运动目标出现频率相对较低,在整个监控视频中所占比例较小,在视频编码压缩处理中,要比H.264 方法拥有更大的应用优势[6]。
4 结束语
在设计视频编码压缩技术时,建议先对人眼视觉特性相关研究内容进行深入研究,结合技术应用需求与本文理论内容,设计一套可以有效解决当前工作需求的视频编码压缩技术应用方案。在方案执行过程中,需要根据各项数据的波动情况,对原方案的细节内容做合理优化,以便获得更好的视频编码压缩效果。希望更多视频处理相关单位可以对人眼视觉特性及其相关内容做更深入的分析,推动监控、图像等领域的健康发展。
