基于图卷积神经网络的主题模型文本分类探究
2023-12-31王治学
王治学
(宁夏师范学院数学与计算机科学学院,宁夏固原 756000)
文本分类主要是基于现代信息算法将文本内容根据标准进行分类标注,其多用于各个媒体平台中智能化新闻分类、广告过滤、内容审核和垃圾评论自动屏蔽等功能布设,而运用图卷积神经网络模型及算法,可通过对数据虚拟建模进行智能信息获取,进而提升有效信息处理效率,实现自动化文本分类。
1 基于图卷积神经网络的主题模型文本分类概述
随着科技的不断发展,文本数据的数量与日俱增。如何有效地管理和利用这些文本数据成为了当前迫切需要解决的问题。传统的文本分类方法主要是使用深度学习模型进行文本分类,该方法取得了较好的效果,但是随着文本数据量的增加,这些方法出现了诸如计算复杂度高、对大量低质量数据敏感等问题。在主题模型领域最流行的是BERT,该方法通过学习单词之间的上下文关系预测句子中单词的主题。本文采用BERT 的一种变体——GPT-2,其使用预训练的词向量与嵌入向量相结合进行分类。还有一种基于图卷积神经网络的文本分类方法——Grid-SVR,该方法结合了GCN 和SVR 模型。为了解决上述问题,本文提出了一种基于图卷积神经网络(GCN)的主题模型,具体如图1 所示。该模型使用GCN 作为输入层,将文本看作一个节点,利用卷积和池化操作对文本进行特征提取,再用Softmax 将文本的特征映射到空间中的不同位置。同时,考虑到文本之间的关系,本文提出了注意力机制以更好地理解文本之间的关系。使用Grid-SVR 进行实验,该模型在主题建模过程中利用了图卷积神经网络(GCN),其基本思想是利用图卷积神经网络的卷积操作从输入的文本图中提取特征,并使用图卷积神经网络来建模文本之间的关系,最终输出为一个主题表示。另外,Grid-SVR 模型采用了一种新的注意力机制,该注意力机制能够在计算上加速主题建模的过程,从而使得模型在时间上有更好的性能。实验采用来自Google 新闻网站的英文新闻数据集,该数据集包含超过1 万篇文章,其中包含大量主题相关的文本内容,以便于更好地理解文本之间的关系。一种基于GCN 的主题模型文本分类算法,该方法将文本表示为节点嵌入向量形式,并利用图卷积神经网络(GCN)提取特征,对文本进行表示,进而使用注意力机制来建模文本之间的关系。

图1 基于图卷积神经网络的主题模型构建流程
2 融合主题模型的卷积神经网络分类模型
2.1 卷积神经网络框架
2.1.1 基础框架结构
基于卷积神经网络所构建的主题文件分类模型,主要通过分类器和编码器功能来完成,具体包括以下2 点。第一,首先可运用神经网络中的池化层及卷积层对上下文信息进行编辑处理,进而获取准确的高层卷积文本语义特征,而主题信息则通过主题模型中ProdLDA 获得,再全面融合主题与上下文信息,进而获取真实的文本特征。第二,采用分类器网络全连接层实施分类结果信息输出,即可完成分类过程。具体网络框架,如图2 所示[1]。
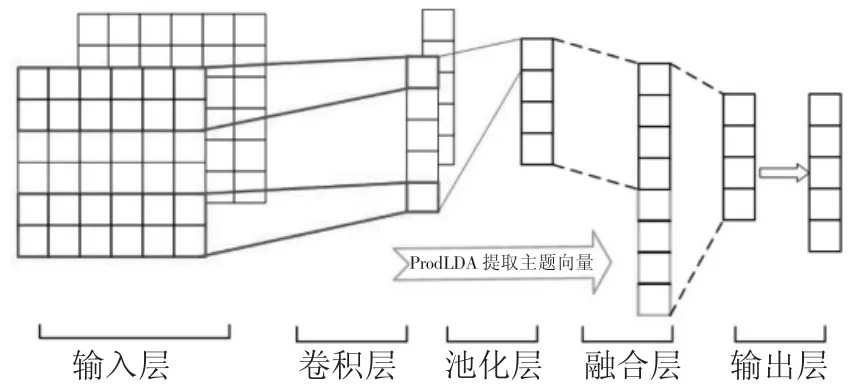
图2 卷积神经网络基础框架图
2.1.2 功能层介绍
通过上述基础框架得知,文本分类通过输入层、输出层、卷积层、融合层与池化层共同完成处理过程,具体如下。第一,输入层。其主要是将预处理后的文件信息,以CBOW 模型实施词嵌训练,并获取初始单词向量进行输入处理。该层主要负责将单词文档转化为初始向量的全过程,将文档表现成为一个规则性向量矩阵。本次实验将主要利用Clove 作为英文文本作为嵌入表示,并利用Word+Ngram 和SogouNews 作为中文文本嵌入词表示,进而提升整体模型结构训练效果,其中中文矩阵表现形式如公式(1)所示
式中:m∈[1,M],nm表示第m个文件文档中的单词总数,而M则表示数据集中全部文档数量。第二,卷积层。该层主要负责对网络模型各种数据的特征进行提取,其通常使用卷积核尺寸来提取不同长度的文本,相比单一化文本提取而言,该层的信息提取范围更广。如将卷积核尺寸设定为3 时,便可每次同时提取3 个不同单词特征。而在本次研究当中,总共布设了尺寸为3的512 个卷积核来获取不同的上下文信息,进而保障整体数据提取精度。第三,池化层。为避免卷积层在应用过程中所造成的文件冗余而影响到整体数据分类精度,必须通过池化层进行池化处理。该层主要负责对文件矩阵进行缩减,并池化处理各种上下文特征,在精简训练参数的基础上加快训练速度,进而在避免产生拟合作用的前提下解决卷积后所产生的文件冗余问题。第四,融合层。在经过池化层的池化处理后,便可通过融合层将网络模型提取到的主题特征与上下文特征融合,得到全新的文件特征向量,如公式(2)所示
式中:Vm代表通过卷积神经网络功能所得到的上下文文本语义基本特征,θm代表主题模型或获取的文档信息在K个内部潜在主题上的向量分布概率,Nm代表经过系统组合后得到的融合特征,该文本向量特征同时兼具潜在主题与上下文语义2 种不同特征。而融合层则是将不同矩阵特征基于数据序列的方式实施数据拼接与融合,进而全面解决文本数据冗余与稀疏问题。第五,输出层。经过系统融合后的潜在主题信息与上下文信息模型,主要基于Softmax 组成函数及全连接层计算各种文档数据的分布概率,进而获取准确的数据输出数值。
2.2 新闻文本分类算法流程
本次研究主要通过将ProdLDA 主题模型引入卷积神经网络当中,构建卷积神经网络融合ProdLDA 主题模型厚度的文本算法,详细算法过程如图3 所示,具体如下。第一,在对文本数据集实施预处理后,可将CBOW 模型数据集文档转为词嵌入模式,并将基本主题模型参数实施初始化处理,进而确定最佳主题数量。第二,在对模型的不断迭代训练过程中,可将词嵌入引入其中并构建特有的特征数据矩阵,进而准确评估模型性能。第三,通过训练主题模型信息,获取主题特征矩阵并准确提取全部文件上下信息,进而形成特征矩阵。第四,构建内部融合层,将文本向量拼接完成后传输至相应的分类层,适当调整权值和参数,最终构建完整的CNN 文本分类及ProdLDA 主题模型。第五,通过一系列文件信息处理,使得系统输入层与输出层均具备了部分潜在主题和上下文语义信息,最后,由Softmax 组成函数输出层来准确判断文档数据分布概率[2]。

图3 卷积神经网络融合ProdLDA 主题模型厚度的文本算法构建流程
2.3 实验结果与分析
2.3.1 初步测试
在短文本分类研究实验中,本文主要基于今日头条平台来构建2 个不同的数据集,共分为拥有20 万条信息数据的9 个类别数据集和拥有38 万条信息数据的15 个类别数据集2 种。而在长文文本分类研究实验中,则主要采用了拥有20 种不同分布状态的新闻媒体类型的英文数据集,其可用于2 万条不同的长文本集合处理。
考虑到整体训练过程中的数据处理量较大,且需要频繁更改设计主题参数才能使主题模型达到最佳数据处理效果。因此,本次研究实验主要基于评价规范中的数据准确率作为衡量标准,对主题特征进行深入分析,并以20 为一个测试梯度,通过相关搜索引擎进行数据收集、对比,最终得知50 个主题数量下的数据处理准确率达到了0.912%,故而可将其作为最佳主题数量设计参数。而词嵌入维度同样会在一定程度上影响到词语特征提取效果,因此,本次研究实验以头条数据集作为词嵌入研究平台进行数据收集、对比,最后发现,当词嵌入为150 维度时,其准确率可达0.907%,完全可以将其作为最佳嵌入词设计参数。此外,为进一步提升文件分类处理精度,实验人员再次以今日头条作为研究平台,对同样基于数据准确率评价指标,对模型训练系统迭代次数实施了分析与探索,最终得知当迭代次数为35 时,其整体文件分类效率、分类速度及分类精度最佳。
2.3.2 结果分析
在经过一系列实验测试后,最终测算出1 号数据集(20 万条数据、9 个类别)中的不同模型中数据集各项测试结果如下。在ProdLDA-CNN 模型中,F1 测试比率为0.915 0%、召回率为0.913 1%、准确率为0.917 8%。在TMN 模型中,F1 测试比率为0.914 3%、召回率为0.914 2%、准确率为0.914 9%。在Word2vec-CNN 模型中,F1 测试比率为0.904 1%、召回率为0.904 0%、准确率为0.903 8%,其整体数据测试精度均在合理范围内。而在将数据集基础类别量从9 个提升至15 个时,语料噪音和交叉信息量也会不断增加[3]。
由于语料噪音数据与数据集类别增多时,CNN 单一模型数据处理准确率大大降低,而TMN 与本次研究实验模型则依旧保持较高的数据处理准确率。为进一步证明该模型的操作可行性,工作人员还针对基于20 NG 的英文长文本数据集方面进行了一系列对比分析,结果显示,在基于20 NG 长文本数据的情况下,ProdLDA-CNN 系统模型整体分类精度相较于Word2vec-CNN 单一模型处理精度明显较高,其根本原因在于单一化CNN 模型更加侧重于对局部卷积语义的提取,而无法准确获取长文本中的各类数据信息,而本次研究实验中的主题模型则可基于文档主题特征来提取文件信息,故而其整体文件分类精度较高[4]。
3 文本分类系统设计实践
3.1 功能需求及功能模块设计
本次文本分类案例系统主要基于现代数字编程技术构建,整体采用Flask 作为基础框架,而后端文本分类系统则主要采用Python 来实施。用户可先上传需要处理的各种数据,并利用内部预处理功能模块进行数据去停、分词等基础操作,最后点击模型训练指令,再由程序处理后将最终结果返回操作界面,进而完成整体数据分类过程,详细模块功能如下。登录注册功能模块主要负责对用户信息进行验证处理,保障整体系统信息安全。数据标注功能模块主要基于内部程序规则关键词,对待处理数据实施辅助标注。预处理数据功能模块主要负责对数据叠词、去停用词及数据分词等方面的清洗工作。模型训练功能模块主要对模型进行自动调整,完善各项数据处理性能。模型评价功能模块主要负责模型评估,判断模型数据处理结果的准确性。模型预测功能模块主要负责封装训练后的各个数据模型,并通过待预测信息中封装好的后台数据实施有效预测。而批处理信息预测功能模块,则主要负责对不同数据信息进行预测处理,并提供全面的数据下载功能。通过不同功能模块之间的配合工作,大大降低了系统处理的耦合性,进而提高模型系统文件分类效率。
3.2 数据库存储模块设计
本次案例系统,主要由数据库存储、注册登录、数据标注及模型训练等几个关键模块构成。其中数据库存储模块主要负责编制与管理,如预测接口表、规则配置表及用户信息表等内部表格,进而增加整体数据分类管理的合理性,如在用户信息表设计过程中,必须包括字段名称、数据类型、是否允许为空及具体作用等几项,具体如下。将表内id 字段数据类型设计为int,允许为空设定为否,功能为操作主键。将表内userid 字段数据类型设计为varchaer(255),允许为空设定为否,功能为用户名。将表内owner 字段数据类型设计为int,允许为空设定为否,功能为管理权限(参数0 为普通用户、参数1 为管理员,默认值为0)。将表内loginip 字段数据类型设计为varchaer(255),允许为空设定为否,功能为对各种登录IP 地址进行记录。将表内loginCouunt字段数据类型设计为num,允许为空设定为否,功能为记录用户登录次数。将表内loginTime 字段数据类型设计为datetime,允许为空设定为否,功能为记录详细的用户登录时间。
3.3 注册登录模块设计
注册登录模块主要是为了保障整体系统信息的安全性,避免无关人员窃取内部信息。因分类系统对操作人员的专业性要求较高,其内部信息量极大且涉及范围较广。因此,本次案例系统主要采用token 方式来验证系统管理员信息,进而各种网络不法分子恶意入侵和攻击,详细操作过程如下。用户登录操作时将密码与账号录入,系统会将相应信息与MySQL 数据中的存储信息进行对比验证,并返回一个独有的token 签名,最后验证token 数据是否准确无误。此外,用户在本地实施token 存储时,系统会在指令发出时予以验证[5]。
具体验证流程依次为系统开启、用户登录信息录入、token 信息识别、发送主页请求和验证token 请求的准确性,如信息准确则会自动跳入主页界面,若信息有误则会在本页面发出错误提示。
3.4 其他功能模块设计
为提升数据标注工作效率,系统会在内部通过数据标注功能模块来标注规则关键词,并基于具体关键词的权重判断数据标签,最后使用分词工具进行提取,从而获取最终数据标签。而模型训练模块则主要基于训练脚本,将整体训练结构展示到页面上,其无须通过任何程序编写即可完成功能训练。用户只需点击相应的操作按钮,便可实施如分词、消除停用词等基本需求。此外,工作人员还通过操作界面设计及系统测试等方式,不断完善系统功能、提升文件分类操作精度,进而在降低人工工作量的前提下,大幅提升了整体文件分类工作效率。
4 结论
综上所述,将主体模型结合卷积神经网络技术充分融入到文本分类当中,并基于用户实际需求来构建一套完整的信息处理系统,从而真正实现智能化数据信息分类处理,使用户通过系统界面即可获取全部信息处理结果,进而真正对文本信息进行智能化分类。
