信息熵原理探讨及其在二元系统的应用
2023-12-29张丽琴徐士涛
张丽琴,徐士涛
淮北师范大学 物理与电子信息学院,安徽 淮北 235000
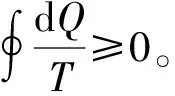
1948年,克劳德·香农[2]首次定义了信息熵的概念,将其定义为一个离散随机变量的所有可能取值所包含的平均信息量,并将统计熵作为信息论的核心概念,用来描述系统的不确定性。信息熵会随着系统有序程度的增加而减少,而随着无序程度的增加而增加。信息熵衡量了随机变量出现的期望值,当一个变量的信息熵较大时,它可能出现的各种情况就更多,即包含的信息更丰富[3-5]。因此,我们需要更多的表达来描述它,即需要更多的信息来确定这个变量。一条信息的信息量与其不确定性直接相关。例如,对于非常不确定或完全未知的事情,我们需要获取大量信息才能理解。相反地,如果我们对某件事已经有了较多了解,就不需要太多信息就能理解清楚。因此,信息量的度量可以视为不确定性的度量。
信息熵是用来研究不同种类随机事件的数学工具,它的价值在于减少事件发生的不确定性,使得信息变得确定和有序。与我们熟知的熵相比,信息是有秩序的,而熵则是无序且复杂的。本文通过探讨信息熵与随机事件之间的联系,引出背后的统计模型,深化对信息熵的认识和理解。通过考虑二元系统,定量描述信息熵的演化过程,进一步强调了在非平衡系统中引入信息熵的概念的必要性和重要性。
1 信息熵原理
信息熵是用于衡量随机事件不确定性的重要概念,它提供了一种量化度量,用于描述在给定一系列可能性时,对于实际结果的预测或预期程度[5]。信息熵的计算基于事件发生的概率分布,通过对所有可能事件的概率加权求和来衡量系统的不确定性。用公式表示为:

2 二元系统
针对不同物理系统,二元系统的研究具有广泛的适用性。例如,许多物理系统可以被抽象为二元系统,这种抽象能够帮助我们更好地理解系统的基本行为。铁磁矿、合金等实际系统可以通过二元系统的分析来获得系统的相关行为[7-10]。此外,生活中的相变现象,如液体加热时的相变,也可以通过理解二元系统的概念得到解释。通过研究模型,我们可以更好地理解随机性如何影响系统的不确定性和混乱程度。这种理解有助于强调信息熵的广泛应用性,而不是仅限于确定性系统。在处理量子系统时,结合统计力学和量子力学的原则,应用信息熵的最大值原理,以更好地理解和描述量子效应。量子力学中的波函数振幅平方反映了在不同状态中找到系统的概率。通过最大信息熵原理,可以理解系统趋向于进入最不确定的状态,这与量子态的性质相一致。信息熵的最大值原理在量子力学用来衡量量子态的不确定性和信息分布,系统趋向于达到具有最大熵的状态,即系统在不受约束条件限制的情况下,会倾向于进入最不确定的状态。在量子系统中,这可以解释为系统趋向于进入最平均分布的状态,这与量子态的特性相符合[11-13]。
综上所述,信息熵是一个贯穿不同领域的普适概念,有助于我们深入理解随机性和不确定性对系统行为的影响。通过探索经典的二元系统到随机性的模型,可以更好地把握信息熵的本质,并将其应用于多样的物理体系中。
3 信息熵原理在二元系统中的应用
在研究物理系统时,我们经常需要计算状态数,以便更好地理解系统的性质。对于一个特定的二元系统,考虑其状态数,粒子固定在N个位置上,且每个位置上的小磁铁只保留自旋向上或向下两种运行方式,对应磁矩为±m。系统的状态数可以通过一个生成函数来表示,其中每个位点上的自旋方向决定了系统的状态。这个生成函数是一系列项的和,每一项表示系统的一个可能状态,通过N个独立磁矩的乘积来构建。若假设每个位置可以被占用(自旋向上↑)或空置(自旋向下↓),如表1所示。同一种元素可以表示为两种状态的位点,即已占用或未占用。表1中的1、2或3表示位点的编号。不同编号的位点在物理空间中应当不会重叠。

表1 某特定二元系统状态数的位点序号
无论研究对象性质如何,都可以用竖直向上或竖直向下的箭头来指定这两种状态。如果磁体自旋向上,磁矩是+m;如果磁体自旋向下,磁矩为-m,这样的模型通常被称为伊辛模型。现在考虑N个位点,每个位点上都有一个磁矩(假设其值为±m)。每个磁矩只可能有两个方向,并且不考虑磁矩之间的相互作用。N个磁矩组态总数为2×2×2…=2N。系统的状态是通过给出每个位点上的磁矩方向来指定的,有2N种状态。不难理解,系统的每个不同状态都包含在N个因子的符号乘积中(如图1所示)。图1是2N个项之和,其中的每一项都是系统允许的可能状态,每一项都是N个单独磁矩的乘积(即生成“函数”,用来表征系统可能出现的状态)。这样的求和不是一个状态,而是列出系统所有的可能状态。

图1 N个小磁体组成的伊辛模型的所有可能状态的生成“函数”
对于N个磁矩的二元系统,它的总磁矩M可以取不同的值,从而得到不同的状态。如果我们从所有磁矩自旋向上的状态开始,然后每次翻转一个磁矩,可以得到M的所有可能取值。系统的状态数与总磁矩M的可能取值数相等,但是实际上,系统的状态数远远多于总磁矩的可能取值个数,因为不同状态可能具有相同的总磁矩M。M可以取以下值:
M=Nm,(N-2)m,(N-4)m,…,-Nm。 (2)
若从所有小磁体自旋向上的状态(M=N·m)开始,每次翻转一个磁体就可以得到M的可能取值集合。我们可以翻转N个磁体,得到所有自旋向下的最终状态(M=-N·m)。总磁矩M有N+1个取值,系统有2N个可能状态。当N≫1时,我们有2N≫N+1,即系统的可能状态数远远多于总磁矩的可能取值个数,此时系统的许多不同状态可能具有相同的总磁矩M。为了更好地理解系统的状态数,引入了自旋过剩的概念,它表示自旋向上和自旋向下的差值。通过这个概念,进一步计算系统的状态数,并引入了生成函数的概念,通过对生成函数进行展开,得到系统的状态数和各个自旋过剩值的分布。若定义自旋过剩:
N↑-N↓≡2s, (3)
其中N↑+N↓=N。当我们只关心在一个状态中有多少小磁体的自旋向上,有多少小磁体的自旋向下(而不是哪个特定位点的磁体自旋状态)时,去掉图1的下角标。由此发现展开系数便是我们的目标函数g。如表2中所示,显示的是磁矩个数与生成函数之间的产生与一一对应关系。从表2中可以清晰的看出,生产函数增加的数量是磁矩个数的N次幂。
把表2中的生成函数关系带入公式(3),为了计算简便,此处,↑用z表示,↓用1表示,把公式(3)进行泰勒级数展开,得到:
其中G(N,z)是生成函数。
若(N,n)→(N,s);n≡N↑=N/2+s,
得到
当N为偶数,gmax=g(N,0),g(N,N/2)=g(N,-N/2)=1 。
为了进一步计算(↑+↓)N,利用
令t≡N/2-s,由此我们得到:
这也验证了前面(6)式,g(N,s)是具有相同s值的状态个数,同时也是具有相同能量的状态个数。如果对一个自旋系统施加均匀外磁场,不同s值的各个状态其能量也不相同。当N为奇数时,s为半整数,N/2+s和N/2-s也都是整数,所以不用担心阶乘运算中出现半整数。
由(10)式得
假设每个磁矩不会彼此影响,故系统有2N种不同的状态。
我们注意到N↓=N/2-s,并且对(9)式取对数:
lng(N,s)=lnN!-lnN↑!-lnN↓!, (12)
当N很大时,我们用斯特林近似
进一步有
最后我们得到伊辛模型的熵为:
此时g(N,s)在N很大时的结果为:
其中
如图2所示,从图中我们发现N=100,g(s)可以被看成离散的“高斯函数”,即g(s)上的每一点几乎都在高斯函数曲线上。实际上g(s)的理论值和近似值在N小于100时差距较大,但是随着N越来越大,理论值所呈现的图像越来越趋近连续的高斯函数曲线。同时,从图中还可以非常轻易的看出,当s取0时,对用的g(N,s)值都是1。进一步,我们考虑了当N很大时的情况。在这种情况下,我们使用了斯特林近似来估计组合数,从而得到了系统的熵。熵的计算显示,随着N的增大,系统的状态数呈指数增长。

图2 二项式系数g(N,s)在线性尺度上的高斯近似
如果假设每个小磁体自旋向上和自旋向下出现的几率都相等,即N个小磁体自旋向上和自旋向下出现的几率为P=1/2N,那么就会得到当N很大时系统出现具有状态(s)的几率为
由此我们发现,当N趋于无穷大时,s=0出现的几率趋于0,除此之外的几率似乎比0还小,但是所有情况的几率求和应该为1。但是当N很大却不是趋于无穷时,可以把g(N,s)准确地理解成高斯分布[14]。从图3中可以看出,随着N的取值范围从1 000变化到9 000,N越来越大,概率分布函数P(s)却越来越“平坦”,因此对于任意s,概率都几乎相同。若N趋于无穷大时,概率P(s)则趋近于一条直线。说明并不存在这样一个P(s),使其既要保证与s轴围成的面积恒等于1,又要保证函数每一点的函数值趋于常数。

图3 N取不同时的P(s)的函数“曲线”
若考虑N固定且很大,有:

通过计算,我们发现随着N的增大,极化率的概率分布函数逐渐变得“尖锐”,这意味着在极大系统中,极化率的值更有可能集中在某些特定值附近[15-16],而其他值的几率逐渐减小。我们重新考虑物理量极化率:

则极化率的概率分布函数为:
即
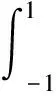
则公式(29)可以进一步简化为:
利用公式(31),得到图4。从图4的极化率分布函数可以看出,随着N数目的增加,极化率函数的峰值越来越尖锐,若N趋于无穷大时,极化率P(ρ(s))则趋近于一条直线。说明并不存在这样一个P(ρ(s)),使其既要保证与s轴围成的面积恒等于1,又要保证函数每一点的函数值趋于常数。极化率的概率分布函数逐渐变得“尖锐”,这意味着在极大系统中,极化率的值更有可能集中在某些特定值附近,而其他值的几率逐渐减小。即极化率的概率分布呈现一定的秩序性,这正是信息熵函数的特征体现。

图4 极化率的概率分布函数
4 总 结
通过探讨信息熵原理及其在二元系统和伊辛模型中的应用,阐述了信息熵在衡量随机变量不确定性方面的重要性。介绍了信息熵的演化过程和其有序性的基本原理,并详细讨论了在二元系统和伊辛模型中计算信息熵的方法。最后强调了信息熵在理解随机性和不确定性对系统行为的影响以及其在实际应用中的多样性方面的重要性,发现随着N的增大,概率分布函数或者是极化率的概率分布逐渐变得“尖锐”,这意味着在极大系统中,概率值更有可能集中在某些特定值附近,而其他值的几率逐渐减小。本文的研究对于深入理解信息熵的本质和应用于多样的物理体系中具有一定的参考价值。
