基于改进型YOLOv5s 的安全帽检测
2023-12-28于秋波胡文宇
于秋波,万 擎,胡文宇,赵 宁
(1.天津津铁供电有限公司,天津 300381;2.天津津铁电子科技有限公司,天津 300381)
1 引 言
安全帽是一种使用广泛、实用性强的劳动安全防护用品,可有效避免头部遭受外界危险带来的伤害。由于施工环境的复杂多变,工人在实际施工过程中往往忽视佩戴安全帽,导致人身伤害事故发生。特别在作业面较大的施工中,监控范围较传统施工更大,监控时间也更长,加之视觉疲劳和误判等问题,传统的人工监管已不能满足安全管理的要求。据住房和城乡建设部公布的数据,全国在2012~2016 年间,建筑施工事故导致的建筑工人死亡人数约为2850 人,平均每天1.57 人死亡[1]。因此,实现对安全帽的自动化检测对于提高施工安全管理的效率和准确性具有重要意义。
2 SH-YOLO 设计
YOLOv5s(也被称为YOLOv5 Small)是YOLOv5系列中的一个变种模型,它是YOLOv5 系列中最小和最轻量级的模型。在保证检测精度的基础上,实现更小的参数量和更快的检测速度,适用于实时安全帽佩戴检测的需求。因此,本文选择在YOLOv5s 的基础上进行改进,提出了用于检测佩戴安全帽的SH-YOLO(SafetyHelmet-YOLO)。在SH-YOLO 的网络结构中引入无参数注意力机制模块SimAM[2]来增强特征提取网络的性能。同时,采用串联Maxpooling网络结构和Shortcut 融合特征的方式以SPPFCSPC[3]替换原模型的SPPCSPC,从而快速获取不同尺寸的感受野。
从网络结构方面而言,在此提出的SH-YOLO算法主要由五个部分构成,分别为:输入层(Input)、主干网络(Backbone)、颈部网络(Neck)、头部网络(Head)和预测层(Prediction)。整体网络结构如图1所示。

图1 SH-YOLO 网络结构
其中,Input 负责对数据集进行多种数据增强操作,以提高算法的鲁棒性,包括Mosaic 数据增强、自适应锚框和自适应图片缩放等处理。
Backbone 由数个CBL 模块、C5 模块、MP 模块和SimAM 共同组成。在这当中,CBL 模块由Conv层、BN 层和LeakyReLU 激活函数构成;MP 模块为Maxpooling 层。
Neck 采用SPPFCSPC 模块与特征金字塔结构融合,由各层特征检测不同类尺度的目标。结构由CBL 模块、MP 模块、SPPFCSPC 模块、C5 模块组成。SPPFCSPC 模块连接Backbone 与Neck,其由众多CBL 模块与三个相同的Maxpooling 层组成。
Head 由三个CBL 模块组成,分别输出3 个不同尺度的特征图。
Prediction 则是采用CIOU_Loss 函数计算定位信息损失,并使用NMS 保留最优预测框,去除多余预测框[4]。
3 注意力机制
SimAM 被应用在安全帽检测任务中,但因为施工场景存在大量的干扰因素和复杂的背景,可能会使模型难以识别和提取关键特征,从而影响模型的准确性。在施工场景中,如何让模型更好地关注场景中的重要区域是一个必须要解决的问题。Backbone是模型的核心组成部分,它的主要作用是对输入图像进行特征提取,因此,新设计与优化皆是针对此模型进行。对Backbone 进行优化,加强模型对重要特征的学习并抑制不必要特征的能力,从而实现模型关注场景中的重要区域。在Backbone 中引入Sim AM 注意力机制,使得主干网络更加专注于施工场景的重要特征信息[5]。SimAM 整体结构如图2 所示。

图2 SimAM 注意力机制
相比于以往提出的通道注意力机制和空间注意力,SimAM 模块有着独特的特点。SimAM 是一种结合通道维度和空间维度的三维注意力模块,它的特点在于它能够同时考虑通道、高度和宽度三个维度来计算注意力权重,从而可以定义通道维度和空间维度的三维注意力权重。它不需要额外的参数,将其加入网络也不会增加网络的复杂度。这一点从SimAM 注意力机制的实现方法中可以看出。SimAM注意力机制是源于神经科学理论,该理论表明,在神经系统中传递信息丰富的神经元通常与周围其他神经元不同,信息丰富的神经元呈现出独特的放电模式。被激活的神经元通过空间抑制机制来抑制周围神经元,这种现象在神经科学中被称为空域抑制[6]。因此,这类神经元通常具有较高的重要性,可以通过度量神经元之间的线性可分性来找到它们。
具体的实现,则是通过SimAM 中定义的能量函数et,公式为:
输入特征张量X 由目标神经元t 和其他神经元xi组成,且有X∈RCHW,其中C、H、W 分别代表特征张量的通道数、高度和宽度;i 和M 分别表示某个通道上的神经元索引和所有神经元的个数,且有M=H×W。公式中所有值为标量;通过最小化上述方程实现同一通道内目标神经元t 和其他神经元xi之间的线性可分性;是目标神经元t 和其他神经元xi线性变换得到的,其变换公式为:
式中wt代表线性变化的权重,bt为线性变化偏置。
为便于计算,引用二元标签(yt=1,y0=-1)并添加正则化项,λ 为正则化系数。转换得到能量函数:
由公式(3)解出wt和bt:
将得到的wt和bt代入转化后的能量函数,可求出最小能量
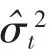
其中,X 为输入的特征张量,E 为et在所有通道和空间维度的总和,⊙为Hadamard 乘积。通过在公式中添加Sigmoid 函数可以限制能量函数E 的值不会过大,从而避免训练时出现梯度问题。添加Sigmoid 函数并不会影响每个神经元的相对重要性,因为此函数是逐元素应用的,即每个神经元的输出会单独经过Sigmoid 函数的处理[7]。
4 高效SPPFCSPC 模块
在安全帽佩戴情况的检测目标中具有不同的尺度,这会使得模型在处理这些目标时难以捕捉其细节信息,在处理不同尺度的特征图时就会增加计算量,拖慢模型的检测速度。因此,为了增强处理不同尺度目标的能力,并且减少计算量和提升检测速度,提出一种高效的SPPFCSPC 模块。SPPFCSPC 的网络结构如图3 所示。

图3 SPPFCSPC 网络结构
SPPFCSPC 网络采用特征金字塔结构来处理不同尺度的特征图,将主干网络提取到的深层次特征图分为两个分支进行处理,最后通过Shortcut 方式融合不同感受野的特征。
其一分支经过两个1×1 大小的CBL 模块和SPPF网络结构的处理。SPPF 网络结构的设计是采用串行Maxpooling 方式进行池化,将这些串行Maxpooling操作得到的池化结果拼接在一起,得到具有不同感受野的特征图,以此提高网络对多尺度目标的检测能力。
在另一分支中,将生成的特征图与主干网络提取的特征图结合,采用CBL 模块完成融合,得到一个更加丰富的特征图。CSPC 模块的特征融合操作可提取不同方向的特征,且利用不同分支信息的互相补充,提高对不同尺度大小目标的检测能力[8]。
将输入特征图传递到多个相同的Maxpooling层中进行操作,每个Maxpooling 层只需对其上一层的输出进行操作,因此计算量相对较小。Maxpooling并联操作需要对多个不同大小的特征图进行池化,会带来巨大的计算量。同时,SPPFCSPC 网络结构采用Shortcut 操作替代Concat 操作,能够有效减少模型参数的数量。该操作将某一层的输出直接与后面某一层的输入相加,能更好地保留原始输入的信息,提高网络性能。
5 实验与分析
5.1 实验平台
实验PC 端配置的实验环境如下:中央处理器采用Intel i5-9400F,该处理器拥有六个核心,适用于常规应用和轻度游戏;显卡选用GeForce RTX 3060,提供先进的图形渲染和深度学习加速能力;操作系统运行在稳定且开放的Linux 发行版Ubuntu 20.04;深度学习任务由PyTorch 1.13 框架负责,为研究员和开发者提供了丰富的工具,用于构建、训练和部署深度学习模型;编程语言方面采用Python 3.8,这是一种强大且易于学习的语言。此外,为优化深度学习性能,特别安装CUDA 11.7 和CUDNN 8.4,分别提供了GPU 并行计算能力和深度学习加速库。
5.2 实验参数
学习率、权重衰减、动量、学习周期被称为超参数,因为它们不是由网络训练得到的参数,而是人为设定好的。超参数可以在模型训练期间进行调优,为模型提供最佳结果。学习周期与模型的泛化能力有关。当发现模型的训练误差小但泛化误差大时,说明学习周期长,导致模型过拟合,此时应当降低学习周期。学习周期不足,表现为训练误差大,模型没有得到充分优化。当不想重复多次试验来确定最优学习周期时,可以使用提前终止策略,即在训练过程中,若发现泛化误差基本稳定不变,即提前终止训练。动量的作用是对那些当前梯度方向与上一次梯度方向不同的参数进行削减,即在这些方向上减慢了。权重衰减是正规化的一种形式,其作用是防止过拟合。学习率的作用是控制梯度下降的速度。具体的参数设置如表1 所示。

表1 实验参数设置
5.3 实验数据集
实验所使用的数据集SafetyHelmet Dataset 共有6000 张图片,分辨率为640×640,其中包括安全帽和行人两种类型。安全帽图片数量为4000 张,摔倒图片数量为2000 张。这些图片既有通过现场拍摄获取的,也有从网络中搜集而来的,并且也涵盖了不同的光照条件、拍摄距离、拍摄角度以及画质清晰度,保证了多样性。
为了确保数据集的可靠性和有效性,对安全帽和行人数据集进行细致的筛选和标注,并将数据集划分为5400 张训练集和600 张测试集。
在制作数据集时,首先使用LabelImg 工具进行标注,需要对图片中所有需要检测的目标进行框选,并用相应的类别标签加以命名。这些标注信息将被保存为与图片名称一致的.xml 标签文件。
当所有图片标注完成后,将原始图片存储在一个名为JPEGImages 的文件夹中,并将所有标签文件存储在另一个名为Annotations 的文件夹中,确保图片和标签信息互相对应。
然后将得到的VOC 数据集转换为YOLO 数据集格式用于训练。XML 文件中包括目标的类别、中心坐标、宽、高(class_id、x、y、w、h),按照已知参数带入转换公式进行归一化处理,得到所需的中心坐标、宽度和高度数值大小。
Safety Helmet Dataset 的格式转换由下式实现:
式中,(xmax-xmin)、(ymax-ymin)分别表示框的宽度和高度;xc、yc表示中心点坐标;Width、Heigth 为宽度和高度。
将标注数据转化为可读取的格式需要将标注数据转化为模型可读取的格式。此处将XML 格式的标签文件转换为TXT 格式标签文件,并将其保存在一个名为Labels 的文件夹中。
此外,按照ImageSets/Main 文件夹中的TXT 文件设置将安全帽和行人图片进行了数据集划分,分为训练集、验证集和测试集。最后,需要将已划分好的数据集的图片复制到一个名为Images 的文件夹下,并将它们对应的标注TXT 文件复制到一个名为Labels 的文件夹下,以便后续模型训练和评估使用。
5.4 对比实验
在实验软硬件环境、超参数设置、训练集与测试集划分比例全相同的条件下进行对比实验,从Precision、Pecall、mAP、FPS、参数量和计算量等指标来证明SH-YOLO 相对于原始算法的优越性。检测效果对比结果汇总为表2。

表2 不同模型检测效果对比
由表2 数据可见,SH-YOLO 在安全帽和行人两种类别的检测精度AP 数值方面均高于YOLOv5s 算法,分别获得了6.7% 和2.4%的提高。在检测速率方面,与YOLOv5s 算法相比,SH-YOLO的FPS 提高了2 f/s。在参数量和计算量方面,SHYOLO 都小于YOLOv5s 算法。
SH-YOLO 的实际检测效果如图4 所示,可见其在SafetyHelmet 数据集上表现优异。在复杂的施工场景中,算法能够准确检测出人员是否佩戴了安全帽。不仅如此,该算法还成功地将佩戴普通帽子的情况识别为行人,展现出较强的抗干扰能力。

图4 实际检测效果
6 结束语
SH-YOLO 基于模型融合的策略被提出,增强了原YOLOv5s 模型的检测能力。结合了SimAM 模块的特性,并将其融入到模型的Backbone 网络中,进一步提升了模型对关键特征的提取能力,改善了模型在复杂任务中的性能表现。SPPFCSPC 模块算法的引入,加快了感受野的获取过程,降低整个网络的计算量,提高网络的计算速度。SH-YOLO 很好地平衡了准确度和速度这两个在安全帽佩戴检测算法中最为重要的评估指标,为安全帽佩戴检测提供了高效准确的技术支持,为施工场景下的人员安全监控提供了有效而可靠的解决方案,对于改善工地安全管理具有重要意义。
