迈向可信学习分析:报告解析、结构模型与未来生态
——2023年学习分析与知识国际会议评述
2023-12-27吴永和郭胜男许秋璇
吴永和,钱 雨,郭胜男,许秋璇
(1.华东师范大学,上海 200062;2.上海熙育信息科技有限公司,上海 200062)
一、引言
2023年3月13日至17日,学习分析研究协会(Society for Learning Analytics Research, 简称SoLAR)在美国德克萨斯州举办了第十三届学习分析与知识国际会议(The Thirteenth International Conference on Learning Analytics &Knowledge,简称LAK23),该会议以线上和线下相结合方式举行,邀请了来自学习分析、教育数据挖掘、学习科学、教育技术和其他相关学科领域的297名研究专家,共同探讨学习分析领域的前沿研究。此次会议的主题为“迈向可信学习分析” (Toward Trustworthy Learning Analytics),从学习分析的设计、实施和评估等多个阶段讨论偏见、隐私、道德、透明度和问责制等问题,旨在保护学习者的隐私、尊重学习者的自主性和多样性发展等。
学习分析旨在通过挖掘和分析教育数据提高教育质量和优化教育决策,是推动教育数字化转型的核心力量。然而,随着学习分析在教育中的成熟度增加,收集和使用学生数据表现出极大的安全隐患,甚至被控诉为一种监控和潜在的隐私侵犯,其在主要应用场景中的伦理风险逐渐暴露。《2022地平线报告:教与学版》也对学习分析有效性提出了质疑,并指出了学习分析中的伦理、算法偏差、不公平等问题[1]。由此可见,当前学习分析的可信度较低,严重影响了其在实践应用中的持续推进与采纳,也难以避免地给教育数字化转型造成负面效果。因此,本文通过系统梳理和分析LAK23会议的主要报告和研讨内容,洞悉学习分析技术的研究动态和未来趋向,深入探索并构建可信学习分析的框架和实践生态系统,以促进学习分析技术的高效、健康发展,为教育数字化转型提供可持续的新动能。
二、主题报告
本次大会包含两场精彩的主题报告,主讲人分别是伦敦大学学院的伊瓦·罗杰斯(Yvonne Rogers)教授和卡内基梅隆大学的肯恩·科丁格(Ken Koedinger)教授。
(一)主题报告1《以人为本的学习工具:赋权还是分析学生?》(Human-Centred Learning Tools: Empowering vs Analysing Students?)
当前,新一代大型语言模型(Large Language Models,简称LLMs)蓬勃发展,比如ChatGPT(由OpenAI开发)就引发了业界和学界的热烈讨论。许多学者对这种新型人工智能的教育应用表示担忧[2],而Rogers教授认为,不应担心ChatGPT会把学生变成欺骗者,而应该学会接受和利用这种技术,教学研究者需要重新思考课后作业内容和评价反馈方式。在报告中,Rogers教授从“提供反馈是学习的核心”入手,分析和比较了数字便利贴(Digital post-It notes)、实体聊天盒(SmallTalk)、数据可视化(Data Visualizations)等提供反馈的技术工具,研究表明,这些工具都能有效促进学生的思考与反思,但数字反馈能够更好地帮助教师跟踪和了解学生的学习路径。基于此,进一步提出了在软件应用程序中嵌入探究式聊天机器人,以此作为一种学习支架,为学生提供及时的评估和反馈。最后,Rogers教授讨论了生成式人工智能工具在教育中的未来,她认为这种新一代的人工智能可以帮助学生更好地思考,将为学生和教师的学习和分析带来各种新的可能性。另外,她还强调需要研发与可信学习分析相关的课程,并辅以一种迎合学生喜好和兴趣的方式来开展人工智能伦理教育。
(二)主题报告2《实现更好、更公平的学习分析》(Learning Analytics Toward Better, More Equitable Learning)
针对本次大会的主题“迈向可信学习分析”,Koedinger教授认为,其中一个关键点是测试学习分析能否为改善学生学习的课程改革提供可靠见解。他将该测试称为闭环实验,因为其具体过程是一个从使用课程数据来构建更好的预测模型,到将预测模型实践于该课程中改进学习的循环。他强调,更好的预测必须完成这个循环,即必须要证明该预测和改善学习有明显的因果关系。在报告中,Koedinger教授介绍了两个闭环实验:第一个是2016年的“实干者效应”预测研究,基于四门不同课程中12500多名学生的数据,该研究进行了因果推断分析,结果表明,积极的实践比被动的阅读或观看的学习效果更好,并且通过混合效应回归发现课程单元内实践比单元前实践或单元后实践的学习效果更好。第二个研究是基于K-12学生和大学生在人工智能导师、在线课程、教育游戏中产生的主动学习数据,对学生的学习曲线进行建模,结果发现,在精心设计的在线实践环境中,各个学生的学习曲线具有极大的相似性。最后,Koedinger教授提出,这些闭环实验的结果可以为产生更好、更公平的学习提供普适性的启示。
综上,Rogers教授从技术发展的角度,提出了以ChatGPT等生成式人工智能工具推动学习分析的发展,并针对其伦理问题提出要研发与可信学习分析相关的课程;而Koedinger教授则基于学习分析本质的视角上,提出以完整的闭环实验支持可信学习分析的发展。两位教授的报告内容均为可信学习分析的研究与实践提供了重要思路。
三、 主要内容
本次会议共收录论文72篇,其中长篇论文49篇,短篇论文23篇。通过对这些论文进行关键词提取与可视化分析得到词云图(如图1所示),由此可见,“机器学习”“协作学习”“多模态”“隐私”等是本次会议聚焦的热点话题。
通过研究剖析会议收录论文并结合2022版《学习分析手册》要义[3],以及基于中国古代哲学“道法术器”思想的视角[4],本文将会议的研究主题归类为四个方面: 学习分析技术、学习分析方法、学习分析应用和可信学习分析(如图2所示)。其中,学习分析技术是“术”的层面,指支持各个研究阶段的具体干预或分析手段;学习分析方法是“法”的层面,指研究学习环境中数据与各个主体之间的关系的方法或策略;学习分析应用是“术”和“法”的落地实现,是检验技术与方法有效性的反馈和优化;最后,可信学习分析是“道”的层面,是学习分析的指导思想和方向,引导和约束学习分析技术、学习分析方法和学习分析应用的发展。
(一)学习分析技术
1.网络分析技术
网络分析技术主要包括社会网络分析(Social Network Analysis,简称SNA)和认知网络分析(Epistemic Network Analysis, 简称ENA),构成网络的要素主要有节点和关系。其中,社会网络分析是一种利用网络和图论来研究社会结构的技术[5]。认知网络分析是基于认知框架,通过分析话语数据和文本数据创建可视化模型来探索各个认知要素间的关系特征[6]。Lixiang Yan等提出了一种社会-认知网络分析(SeNA)方法,通过将社会网络分析与认知网络分析相结合,在社会空间分析中加入时间的度量来分析同质性[7]。该研究基于开放学习空间中98名学生的多模态数据进行同质性分析,结果发现,与单独的社会网络分析相比,社会-认知网络分析可以更好地揭示不同学习设计的对照组之间在同质性方面的显著行为差异。Nicole等利用认知网络分析来评估专家和新手教师在模拟使用仪表盘时的时间话语模式,以此了解专家和新手教师的认知网络差异,为基于仪表盘的课程计划定制提供启示[8]。

图1 LAK23会议关键词词云图
2.自然语言处理
自然语言处理(Natural Language Processing, 简称NLP)是一种利用计算机技术对人类语言进行自动化分析的技术[9],旨在实现人与计算机之间的有效通信。Nazaretsky等收集了模拟教室中教师与模拟学生互动讨论的转录数据,然后采用自然语言处理技术对其进行自动分析,结果表明,该方法可以对教师的表现作出较准确的评估[10]。Byeongjo等利用自然语言处理技术分析大规模开放在线课程(MOOCs)中学生解决问题的办法,研究发现,有18种常见的解决问题方法,如使用纸笔、同伴学习、试错等,并发现学生在解决编程问题时严重依赖 “工具”[11]。Wesley等使用Transformer语言模型对MOOCs中同行提供的论文分数的可靠性和有效性进行验证,通过对BERT大型语言模型进行微调来自动对论文质量进行评分,并以此作为验证的衡量标准,该方法可以提高MOOCs中同行评分的可靠性,增加系统的可信度[12]。
3.多模态学习分析
多模态学习分析是指通过对视频、日志、音频、手势、生物传感器等多种数据进行采集、编码和分析,来深度分析和诠释学习者的学习心理和学习行为变化等,旨在理解学习过程、挖掘学习规律以及优化学习效果[13]。基于典型的多模态学习分析管道开发的协作质量模型,Pankaj等探索了不同配置的管道建模,以提高模型的泛化性,结果发现,经常被忽视的上下文数据特征可以提高协作质量模型的泛化性[14]。Fahmid等提出利用多模态来识别和检测学生在基于游戏的协作学习环境中的脱离行为,研究表明,单模态模型的预测精度严重依赖于基础真值的模态,而多模态模型以其丰富的模态数据得到了更高的准确性,超越了单模态模型[15]。Armanda等基于多模态学习分析视角探索了一种交互式的、低障碍的学习分析过程,称为“教师在循环”。通过该过程,教师参与设计用于评估小组工作的探索性数据,利用可视化工具挖掘数据隐含的教学意义,并使用这种多模态信息迭代改进课程[16]。
4.时序性学习分析
时序性学习分析是指在学习分析中加入时间的概念,主要包括时间推移分析和时间序列分析,其中时间推移分析认为时间是一个连续的事件流,而时间序列分析认为时间是多个事件的相对排列[17]。Nazeri等探讨了自我调节学习的时间性,基于自我调节学习的相变和周期性特征来描述四种自我调节学习阶段:确定任务、计划、实施和适应,这四种阶段对应了自我调节学习的多种迭代行为,研究发现,自我调节学习阶段与作业成绩之间存在显著相关性,另外,该研究还发现,两天是进行阶段干预的合适时间[18]。为了评估团队合作的有效性,Zhao等提出了多模态具身团队签名(Multimodal Embodied Teamwork Signature,简称METS),这是一种结合空间和时间数据对团队对话内容建模以生成具身团队签名的方法,研究证明了该方法可以识别高绩效团队和低绩效团队在不同的学习阶段的关键差异[19]。
5.学习分析仪表盘
学习分析仪表盘是一种可视化学习轨迹的技术,帮助教师、学习者和其他利益相关者深入探索和理解学习过程,为实施干预、优化学习提供了可靠证据[20]。Blaženka等分别于2017年(N=222)和2022年(N=196)对二年级信息通信技术专业的学生进行了调查,旨在深入了解学生们认为最能支持学习的仪表盘功能,最后通过因子分析产生了一个包含五个潜在因素的仪表板模型:比较、计划、预测、课外活动和教师[21]。为了改进学生同行评审,辅助教师提供写作反馈,Amber等设计了一个接受学生评论并用机器学习模型标记评论的仪表盘,该仪表盘将有效利用学生同行提供的信息、识别学生写作中的常见问题,并且可以对学生同行评审的质量进行评估[22]。Stanislav等探索了具有不同可视化素养(Visualisation Literacy, 简称VL)技能的教师如何使用带有数据讲故事元素的学习分析仪表板,结果表明,高可视化素养的教师往往采用复杂的探索策略,对设计中的细微矛盾更敏感,而低可视化素养的教师从更明确的数据讲故事指导中获益最多[23]。Kimia等运用韦纳(Weiner)归因理论,探索仪表盘信息内容对学习者的影响,旨在研究学生对设计的仪表盘的理解以及社会比较对学生学习判断的影响[24]。
(二)学习分析方法
1.预测模型
预测模型是基于已知数据对未来事件进行推理的一组技术或方法,包括线性回归、逻辑回归、决策树、贝叶斯网络和支持向量机等[25],既可用于预测教学试题质量,也可用于预测学生学习成功或失败的个性化因素和机制等。Marinho等基于神经语言模型提出了一个新的神经网络文本回归优化目标:项目特征曲线,旨在预测多选题中的项目反应理论参数,并将其应用到巴西国家高中考试(ENEM),结果表明所采用的结构可以较好地预测2020和2021年项目的难度参数b[26]。Boxuan等从学习者的遗忘行为和语言特点出发,建立了一个预测学生单词回忆概率的模型,该模型利用注意机制整合了与遗忘、问题格式和词间语义相似度相关的关键信息,结果表明,该模型具有较好的预测性能,并发现将多种遗忘信息类型和项目格式相结合可以提高学习成绩[27]。Husni等利用学生在智能数学辅导系统MATHia的活动表现数据建立了一个预测模型,旨在预测中学生的阅读能力,并发现MATHia跟踪的某些特定知识或技能可能会推动学生学习数学时阅读能力的自适应发展[28]。为了预测学生阅读过程中的分心,Daniel等提出了一种仅依赖于滚动数据分类的早期脱离检测方法,并基于565名大学生的阅读数据集进行评估,研究得出该方法预测准确率达70%[29]。Louis-Vincent等基于Moodle 学习管理系统数据,结合行为参与的概念,采用聚类技术和训练机器学习算法预测加拿大的一所法语大学本科课程的辍学率,以指导教师对“有风险”学生进行干预[30]。
2.解释模型
解释模型是利用所有可观察的证据对结果进行解释以确定它们之间的因果关系,是一种典型的事后检验[31]。解释模型与预测模型的主要区别在于前者不对未来作出任何声明或判断。Jionghao Lin等利用一个综合的以学习者为中心的反馈框架来分析作业反馈内容,旨在确定不同成绩的学生群体的反馈内容特征,研究使用可解释模型SHAP (SHapley Additive exPlanations)对学生学习结果的预测结果进行解释,并发现SHAP可以透明地解释特征对预测的重要性[32]。Vinitra Swamy等检查并比较了LIME(Local Interpretable Model-agnostic Explanations)和SHAP两种基于实例的可解释性方法,将其用于九门不同课程的学生成功预测模型,并对其可信度进行定量分析和半结构化专家访谈研究。定量结果表明,两个解释模型在任何单个课程的重要特征都不一致;定性结果表明,教育工作者不喜欢任何一种解释模型,甚至经常选择一种混淆性的解释[33]。Hilário Oliveira等比较了十种机器学习和深度学习模型对葡萄牙语和英语文章连贯性评分的预测性能,并利用可解释的人工智能方法来检查和解释表现最好的模型中的重要特征。结果表明,基于传统机器学习模型的自动连贯性评估的解释性比基于深度学习模型更好,在特征方面发现,衡量词汇多样性和词汇发生率的特征(如形容词和状语短语)、代表心理过程的特征可以较好地预测两种语言类型文章的连贯性[34]。
(三)学习分析应用
1.自我调节学习分析
自我调节学习(Self-Regulated Learning,简称SRL)是指学习者积极地探索与调节自身学习过程中的情感、认知和行为变化以实现其目标,而自我调节学习分析旨在表征SRL各要素的状态特征以及基于数据改善SRL各阶段的学习效果[35]。Jeremy等探索了学习管理系统日志中反映学生SRL行为的频率和顺序模式以及它们与学习成绩之间的关系,结果显示,成绩好的学生比成绩差的学生更频繁地表现出一些SRL行为(例如制定个人计划、评估),但总体上,两组学生表现出相似的SRL行为序列[36]。Oleksandra等通过对学习成绩、学生自我调节学习的测量报告以及基于学习行为序列聚类生成的档案进行调查,描述了学生学习行为的不稳定性和变化,并提出了一种通过聚焦学生行为变化来分析自我调节学习中时间性的新方法[37]。
2.协作学习分析
协作学习分析关注学习者协作过程中的交互和真实环境,旨在用数据分析促进协作。Andrew Zamecnik等根据四种反馈类型(任务型、流程型、监管型和自我水平型)比较了客户和导师两种类型行业主管的反馈对团队协作的帮助效果,并调查了临时反馈的质量,结果表明,导师的反馈比客户的反馈更有帮助、更有利于协作学习[38]。Robin Jephthah Rajarathinam等利用语音活动检测(Voice Activity Detection, 简称VAD)算法,从本科工程讨论部分录制的单个音频流数据中提取小组工作的话语转换信息,然后通过手动编码分析学生的协作行为和师生互动,结果表明,高质量的个人音频数据可以有效地描述课堂上发生的协作过程,为未来使用音频数据概念化团队协作提供了启示[39]。
3.教育话语和写作学习分析
教育话语和写作学习分析聚焦于语言和人工制品,通过自然语言处理等技术来分析与提供反馈,从而改进学习。Yukyeong Song等基于学生和教师之间的在线数学讨论话语,对语言同步性和学生的数学素养进行建模,结果表明,数学素养高的学生更有可能与教师做分享,而数学素养较低的学生倾向于重复教师的话语,该研究促进了对教师数学讨论的理解,并可以指导教师有效开展数学讨论[40]。Sehrish Iqbal等通过比较传统的机器学习分类器和预先训练的语言模型BERT来研究基于布鲁姆分类法的修辞类别分类的自动化程度,并探索了修辞类别与写作表现之间的关联,结果表明,BERT模型的准确率比传统的基于机器学习的分类器高18%,另外,在低成绩组、中成绩组和高成绩组中,修辞类别之间存在统计学差异,这表明修辞类别可以预测写作表现[41]。Watts等基于自动反馈设计框架、自我调节学习理论和有效协作学习教学法开发了一个自动反馈的工具,为学生“有机化学”课程的写作作业提供形成性反馈[42]。
4.情感学习分析
情感学习分析将数据驱动的学习分析、教育数据挖掘技术与情感科学和学习科学的理论相结合,目前关注的研究话题包括辍学情感分析、论坛讨论情感分析、课堂情感分析、教师情感分析等。Andrew Zamecnik等设计了一个压力分析仪表盘,该仪表盘将学生的生理数据编码为真实团队模拟的不同阶段的压力水平,旨在可视化学生的生理数据,并调查了教师对该仪表盘的理解程度、使用效果和信任度。除了压力外,走神也是学生课堂常见的情感状态[43]。Megan Caruso等进一步探索了走神与学习结果之间的关系,通过分析学生阅读长篇文章的自我走神报告和不同时间的学习评估,研究发现,走神对事实性的、基于文本的明确信息和跨文本多个部分的信息整合有负向预测作用,而对单个句子的局部推理没有作用。此外,走神只能预测阅读期间的理解能力,但无法预测延迟一周后的情况[44]。
5.社会性学习分析
社会性学习分析用于量化、表征和改善社会环境中的非正式学习,包括社交媒体学习、社区学习、博物馆学习等,利用网络分析等理解人与人以及人与物之间的关系,关注节点的特征以及节点之间的关系本质。Nguyen利用社交媒体平台TikTok上年轻人创作的视频来研究和理解气候变化教育,他对与气候变化相关的标签进行语义网络分析,揭示了多层次、相互交织的话语,包括气候变化危害、呼吁人们采取行动减少人类对自然系统的影响以及倡导环保行动等,并进一步探索了年轻人对气候变化的讨论和观点[45]。由于学习目标和学习模式的分散,互动式博物馆的学习效果很难衡量,Matthew Berland等针对该问题提出了一个新的度量标准——共同选择时间(Joint Choice Time,简称 JCT),旨在衡量游客如何以及何时围绕交互式博物馆展览进行合作,并使用辛普森多样性指数来衡量博物馆展览游戏结果的创造性[46]。
(四)可信学习分析
学习分析高度依赖于教育数据,在收集、分析和使用个人数据的过程中隐藏着重要的伦理问题,严重限制了学习分析的采纳与实践推广,可见,研究可信学习分析成为当务之急,是数字化转型时代的重要议题。Max van Haastrecht等强调了可信是学习分析验证的一个重要标准,通过系统回顾学习分析验证研究,发现目前的研究过度依赖实证效度标准,而忽略了可信和真实性等解释性标准,认为学习分析需要通过整合“深描”教育经验的整体验证策略来推进,并提出基于论证的验证是一种“前途无量”的方法,可以产生可信的和真实的结果[47]。
学习者是学习分析的关键主体,因此,学习者隐私素养等是可信研究的关键方向之一。Andrea Franco等扩展了SpeakUp社交媒体课堂交互应用程序,基于学生个人的实际社交媒体痕迹设计了一个技术增强的主动学习场景,旨在提高青少年对互联网数字痕迹的认知,提升青少年的隐私素养[48]。为了研究学生对学习分析隐私担忧的性别差异,René F Kizilcec等对德国、美国等五个国家的762位高等教育学生进行了调查并基于多元回归等分析发现,国家背景、学位课程和年龄是学生对学习分析隐私担忧的性别差异的重要调节因素[49]。
隐私保护是伦理问题的首要维度,旨在保护学习者和其他教育利益相关者的数据权益和隐私,亦是可信学习分析的重要考虑。为保护学习分析在线讨论中的学习者身份,Elaine Farrow等开发了一种半自动化的方法,基于正则表达式识别论坛消息中的人名并用一致的假名替换,结果发现,这种为在线讨论量身定制的方法在精确性和召回率上都优于使用深度神经网络的通用假名化工具[50]。Xinyu Li等提出了一种计算机视觉定位(CVPE)方法,旨在收集复杂学习环境中的社会空间数据,该方法兼顾可扩展性和实用性且重点考虑了学生隐私保护,具有屏蔽个人面部身份、处理后自动删除记录等功能[51]。
一些学者亦聚焦于学习分析中的算法偏见、公平等以支持其可信。Fan Zhang等针对多群体的偏见问题,提出了一个组合方案——将预测学生成绩的机器学习模型与保持高度的模型公平性的强化学习模型相结合,结果表明该模型有效地降低了多群体的算法偏差,并且实现有竞争力的预测精度[52]。Lin Li等针对学习分析中的预测偏差问题,对49篇最新发表的同行评议实证论文进行系统综述,从保护性属性、公平性指标及其在各种教育任务中的应用、增强预测公平的策略三方面探讨当前的局限性,并提炼出相关建议以指导未来学习分析中预测偏差的研究[53]。
(五)研究述评
随着人工智能技术的迭代更新,学习分析也在发展过程中日趋成熟,呈现出以下研究趋势:(1)在学习分析技术方面,通过将不同技术结合或加入不同变量,丰富数据分析功能和数据可视化结果,比如将社会-认知网络分析相结合,并加入时间维度以分析同质性;(2)在学习分析方法方面,通过对机器学习算法和深度学习神经网络等进行批判性对比或优化改进,研究出一种更适合自己研究目的的算法,对未来事件进行更精确地预测或对因果关系进行更准确地解释;(3)在学习分析应用方面,将智能化的数据挖掘技术和分析算法应用于自主学习、协作学习、语言学习和社会学习等各种学习场景,为改进学习效果提供有效启示。然而,当前的学习分析普遍缺乏对数据的明确规范和有效管理,数据隐私和伦理成为新的挑战。确保学习分析技术合理应用的关键是要落实隐私保护,充分激发和增强数据主体的信任,实现可信学习分析。此外,未来研究需关注交叉学科与学习分析领域的融合。例如,将脑科学、学习科学理论引入学习分析的学业预测和自我调节学习层面,促进发现学习规律。
四、可信学习分析的结构模型
LAK会议是学习分析领域最具权威性的顶级学术会议之一,汇聚了学习分析领域的学术前沿与热点研究。LAK23的主题为“迈向可信学习分析”,这与当前学习分析发展的社会需求相呼应。随着人工智能技术在教育实践中的应用范围不断扩大,《2022地平线报告:教与学版》提出了基于人工智能的学习分析这一概念,即在学习分析的过程中使用人工智能技术来收集、分析和理解数据,帮助教育利益相关者进行决策与规划[1]。与此同时,该技术的应用也引发了更多的道德与公平问题,比如师生群体对该技术的有效性存在质疑、对数据的不严谨使用会引发隐私泄漏、不完善的算法会导致学生受到不公正待遇等,这些问题亟需社会各界的关注与解决。因此,进一步深入剖析LAK23的主题“迈向可信学习分析”,对可信学习分析进行具体的概念阐释、发展梳理与框架研究,旨在为我国学习分析领域的创新和进步提供启示。
(一)可信学习分析的概念阐释
“信任”的本质是社会成员在面对社会不确定性和复杂性增加时,对置信对象的一种依赖方式[54],较为典型的有情感型信任、规范型信任与理性型信任,这三种类型都是以信任者为中心,聚焦于信任者的情感态度或行为选择[55]。而“可信”是指置信对象通过展现自身的特质,使个体或组织对其产生信任[56]。
随着智能时代的发展,“信任”不仅局限于人际关系,也扩展至人机交互。最早出现的是“可信机器学习”[57],综合不同学者的观点,其特质包括透明性、隐私性、公平性、可解释性和鲁棒性等[58-59]。Michael Lewis等曾提出系统的可信任性与其可靠性、可预测性、智能水平和透明度、自主程度紧密相关[60]。Khalid等认为,当机器人具有人性化、透明度高、沟通顺畅和反馈有效等特性时更容易被信任[61]。众多国际组织和学术团体也对其重点关注,2019年4月,欧盟发布《可信人工智能的伦理指南》(Ethics guidelines for trustworthy AI),提出了可信人工智能的七项关键条件[62],包括“人类能动性和监管”“技术稳健性与安全性”“隐私与数据治理”“透明性”“多样性、非歧视性和公平性”“社会与环境福祉”“问责制度”。2019年6月,美国国家科学技术委员会更新了《国家人工智能研究与发展战略规划》(The national artificial intelligence research and development strategic plan),强调机器学习算法的合法性、道德性和鲁棒性[63]。2022年4月,京东探索研究院发布了《可信人工智能白皮书》,从“可靠可控”“透明可释”“数据保护”“明确责任”“多元包容”五个维度构建了可信人工智能框架[64]。
基于“可信人工智能”的发展,一些学者也在学习分析领域提出了“信任”的概念。Corrin等强调在学习分析中负责任地使用数据,提出从数据所有权和管理、知情同意、隐私和安全、信任和问责制等解决学习分析中的公平和公正问题[65]。Brown等认为,执行不当的伦理和数据隐私框架会对学习分析的结果以及研究的可重复性产生负面影响,并从长远来看会破坏对该学科的信任[66]。随着学习者行为数据的挖掘和积累、数据分析技术的提升,自2016年起,LAK会议也开始关注学习分析中的“可信”问题(如图3所示),通过提炼LAK16—LAK23历年论文关键词发现,学者们对学习分析的隐私、公平、信任等问题的关注度越来越高,LAK23更是直接以“可信学习分析”为会议主题,旨在全面审查使用教育数据和算法的意外后果,包括潜在的误用和误解、道德规范、隐私、透明度和问责制等,切实解决在设计和实施学习分析的过程中引发的社会和教育问题。综上,众多学者对于“可信学习分析”都强调了隐私安全、技术信任、社会正义等方面。因此,本研究认为,可信学习分析(Trustworthy Learning Analytics,简称TLA)是指具有安全性、稳健性和公正性的学习分析,即在数据收集、数据处理和数据分析的过程中充分保障数据主体的安全和权益,以获取数据主体的信任。
(二)可信学习分析的结构模型
如今,学习分析中的数据关注范围不断扩大,不仅可以访问更多的数据,而且还可以访问不同种类和粒度的数据[67],导致数据隐私等担忧日益增加。当前可信人工智能是热点议题,尤其是关注“以人为中心”的设计理念[68],但鲜有研究聚焦于可信学习分析。因此,本研究立足于“以人为中心”的视角,基于可信人工智能伦理准则,结合学习分析自身的特征和过程,从安全性、稳健性和公正性三个层面提出了可信学习分析结构模型(如图4所示)。
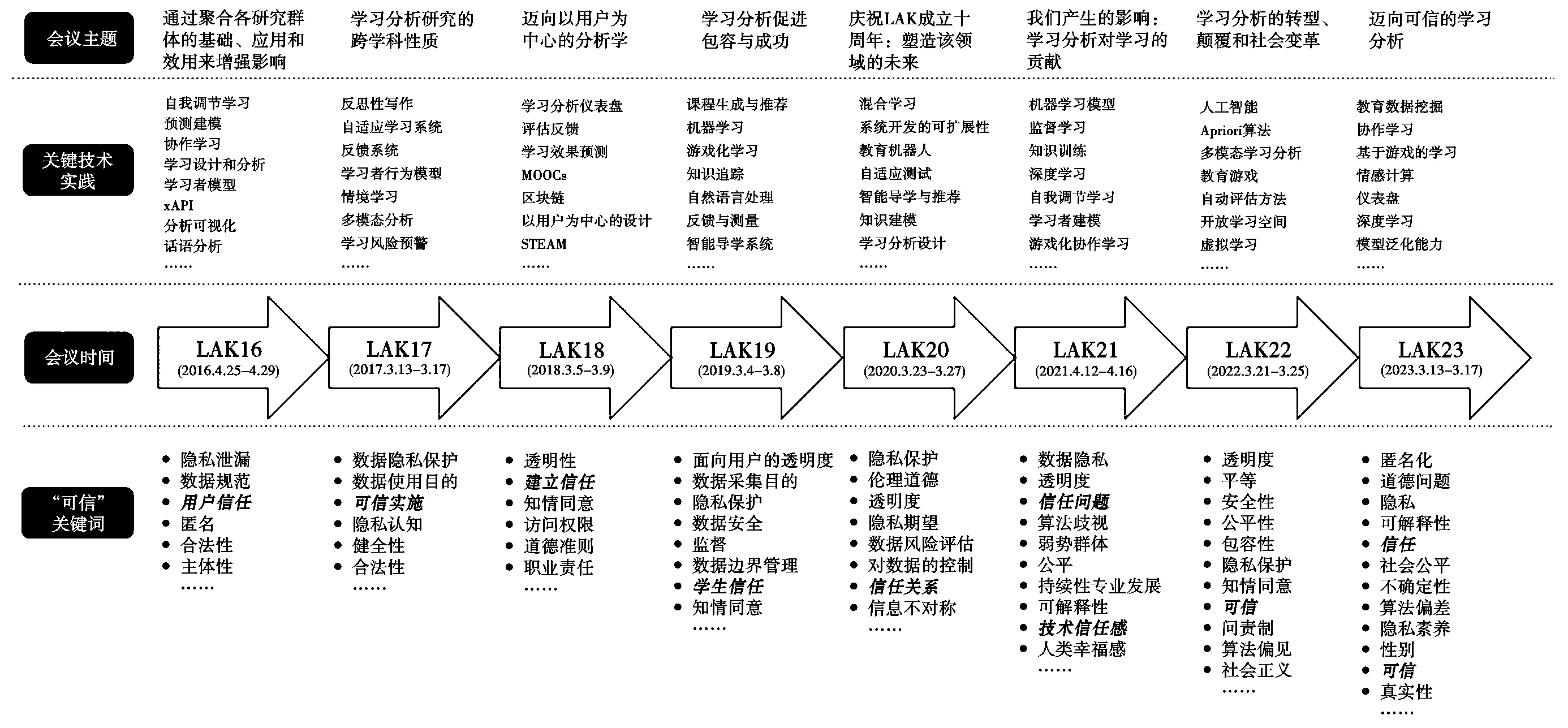
图3 LAK16—LAK23的“可信”关键词
首先,可信学习分析要保障数据主体的安全性。学习分析的所有利益相关者可分为数据主体和数据客体,其中学生既是数据主体,也是数据客体,而教师、研究者和机构等都是数据客体[69]。在学习分析的过程中,数据主体的个人隐私面临各种风险,保障其安全的关键在于控制和限制,其中,控制是指个人对自身信息流动的影响能力,限制是指防止他人访问自身数据的可能性[70]。为达到较好的控制和限制效果,第一,需要培养数据主体个人的数据意识和隐私素养。第二,需要增强各个利益相关者的道德感和责任感,制定个人道德准则,比如避免任何损害学生及其受教育机会的行为、确保利益相关者理解所使用的学习分析技术、保证分析教学和实践中的科学性、准确性和真实性等。
其次,可信学习分析要确保数据收集技术、数据处理技术和数据分析技术的稳健性,具体包括精准分析和预防伤害两个层面。在数据收集方面,需要利用语音识别、脑电感应、眼动追踪等技术和相应的设备捕捉全面的多模态数据,包括行为、心理、生理和基本信息等类型的数据[71],并结合研究目的完成数据的分类、回归与特征选择,以保障学习分析的精准性;此外,数据收集要充分尊重数据主体的自主性,尤其是在使用摄像头、眼动追踪眼镜和位置传感器等设备进行监视时,需要进行严格的数据管理,还可以利用去身份化数据来保护个人隐私[72]。在数据处理方面,选择合适的算法和技术是至关重要的,比如线性回归、逻辑回归、决策树、朴素贝叶斯分类器、支持向量机和神经网络等,根据研究问题建立适切的模型并对模型进行不断验证和优化,最终选择最佳方案,该方案决定了学习分析的精准性;另外,在整个数据处理过程中都需要保证算法、模型等的透明化、可解释性,并采取有效措施防止学习者隐私泄露和多平台间的数据鸿沟等问题。在数据分析方面,以可视化的方式呈现学习分析结果,比如交互式仪表盘、热点图、统计数字和图表以及自动报告等有意义的形式,可以突出分析重点、提高实施干预的精准性;还可根据反馈结果进行迭代以检验分析结果的有效性,防止因数据缺失、算法偏见等问题导致学习者的学习、性格、兴趣、能力等出现发展偏差。
最后,可信学习分析要维护社会的公正性。学习分析是教育数字化转型的核心助推剂,要与社会发展保持一致,通过人类监督和制度规范实现学习分析非歧视性、多样性和公平性。第一,需要防范分析技术的偏见风险。特征工程是学习分析中生成预测分析的常用数据挖掘技术,其中人口统计学特征极易引发偏差,比如性别刻板印象等。此外,使用无监督机器学习技术(如聚类)也可能会引发歧视[73],如为学生标记“有风险”或“表现不佳”等标签,可能会对学生的自尊和教师的期望产生负面影响。第二,需要结合人类的解释性。在学习分析过程中应始终坚持“以人为中心”的基本原则,尊重学生的多样性和异质性算法驱动的学习分析技术只是一种工具,还应该整合人类教育经验的验证、解释和评价,通过人工编码等实现学习分析的多样性和全面性。第三,需要建立适切的问责制。问责制是一系列规范学习分析场景中各个方面的原则,具体是指学习分析的每个部分都必须由一个人、一个机构或一个部门精准负责,保障相关内容符合伦理并正常运作。通过确定责任实体和责任领域可以评审整个分析过程,推动学习分析的稳健发展,实现学习分析问责的公平性。
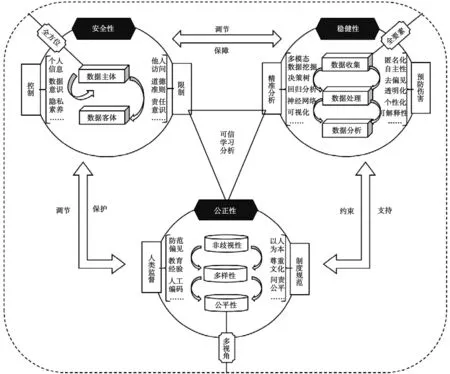
图4 可信学习分析结构模型
五、可信学习分析的未来生态
通过阐释可信学习分析框架发现,可信学习分析的实践需要个人、企业和社会等共同支持。2022年3月,中共中央办公厅、国务院办公厅印发的《关于加强科技伦理治理的意见》中也进一步明确了开放合作以建立多方协同合作机制的治理要求[74]。因此,基于人-机-环境系统理论构建了可信学习分析生态系统(如图5所示),为可信学习分析的研究和实践提供未来方向和建议。
人-机-环境系统理论从整体观念出发,将人、机、环境看作是一个相互作用、相互依赖的系统,并运用系统科学和系统工程的方法合理地安排系统中每一个布局,以获得系统的整体最优化[75]。从该视角看,可信学习分析也是一个由人、机、环境(侧重于社会环境)构成的系统,其中,“人”指所有参与系统的教育利益相关者,“机”指各种学习分析软件和硬件设施,“环境”指人、机共同和谐存在的社会条件。因此,可信学习分析生态系统具体包含三个层面:主体可信、技术可信和制度可信,通过提升个人的隐私素养和数据素养、监督企业科技“向善发展”、鼓励政府设立“底线责任”、探索基于新型人工智能的学习分析技术、构建可信的“学习分析学”等途径,在拓展学习分析的研究方法和应用领域的同时,充分保障学习分析的发展潜力。
(一)立足“以人为本”,提升教育利益相关者的隐私素养和数据素养
学习分析的核心主体始终都是教育中的“人”,即学习者,其他利益相关者在学习分析实践过程中需要充分考虑和保护其权益,以实现主体可信。首先,为了防止学习分析计划与实施的不平等,要保证所有教育利益相关者参与学习分析决策和实践的全过程,并整合记录参与人特征、参与时间和决策发言等内容,以全面了解利益相关者的需求并制定相应策略。其次,可以通过举办讲座或工作坊等形式培养数据主体的隐私素养,包括数据意识、安全意识和保护意识等,增强对数据的感受力、判断力和洞察力,提高对自我数据信息的控制能力以及对他人使用自我数据的限制能力。最后,可开设学习分析技术的相关培训课程以发展数据客体的数据素养,包含数据技术素养、数据理论素养和数据价值素养三方面[76]。其中,数据技术素养是指使用学习分析技术的能力;数据理论素养是指具有数据分析原理、数据分析伦理、教育学原理等理论知识;数据价值素养是指正确的数据价值观,对数据本体、数据价值产生和数据价值挖掘等有准确深刻的理解。

图5 可信学习分析生态系统
(二)坚守“科技向善”,建立数据管理机制和技术安全标准
高新企业是学习分析的关键技术支撑,提供了重要的学习分析平台和工具,是保障技术可信的核心力量。一方面,数据是学习分析的基础,因此,建立数据管理机制是保证学习分析技术安全、可靠的重要基石。企业要在专家团队的理论指导下对学习分析数据的“采集、存储、传输、使用和删除”全周期的安全进行管理规划,提供透明化、可控化和可追溯的数据安全解决方案,奠定数据安全可信的发展根基。另一方面,要联合其他企业建立学习分析技术安全标准和行为规范等,将可信学习分析原则融入学习分析平台和工具开发应用各个环节,保证安全合规。具体来说,对内需要制定技术安全行动指南和内部监管审查制度,加强伦理教育和培训;对外需要促进相关企业间的互信合作,实现平台互认的同时相互监督,构建良性的竞争合作关系。
(三)设立“底线责任”,制定可信学习分析治理规范和问责制度
新兴科技的进步推动学习分析朝着更智能、更开放的方向发展,但是技术本身具有较强的不确定性、复杂性和模糊性等特征,需要国家对其进行约束以塑造可信学习分析的制度环境。当前教育数据治理存在着许多问题,比如治理主体的数据治理能力较低、数据采集及共享商业化现象严重、数据应用及监管标准缺乏一致性等,极大地影响了学习分析的可信发展,因此需要政府制定可信学习分析治理规范,具体包含学习分析需求评估体系、数据运行与审查机制、学习分析风险预警与防范机制等,以统筹学习分析发展与治理之间的关系。另外,要制定精准的问责制度,进一步明确学习分析每一个环节伦理监管和可信保障的组织机构和职能权限,兼顾处于不同发展阶段、应用场景的各个责任主体的利益需求,完善各个组织机构的管理职能,以实现形成动态敏捷的风险防控和监督管理。
(四)探索基于新型人工智能的学习分析技术,赋能教育数字化转型
随着大语言模型(如BERT、DALL-E、GPT-4等)的兴起,人工智能技术开启“模型通用化”的范式转变[76],即训练的模型不再只针对某一特殊领域,而是适用于大范围甚至所有领域,该模型也被称为基础模型或大模型[77]。在教育领域,丰富的学习场域和革新的多模态技术生成了海量的教育数据,但针对不同学生年龄、不同学习科目、不同教学过程的数据则需要训练不同的学习分析模型,导致现有的学习分析工具适用领域较窄,限制于某一学段或某一学科。因此,在新型人工智能技术的支持下,学习分析专家需要探索并构建基于通用大模型的学习分析模型,降低其对教学环境的敏感度,拓展学习分析的适用范围。此外,人工智能技术也可以助力研发相关学习分析工具,如学习分析仪表盘、自动反馈等,使其更加智能与个性化,帮助使用者更简便、更高效、更可靠地分析结果、理解学习与优化学习,加强教育利益相关者对学习分析的信任,以优质数据和智能技术共同赋能教育数字化转型。
(五)构建可信的“学习分析学”,发展数字教育新范式
作为教育技术学的重要学科分支,学习分析已发展出较为成熟的理论基础和实践应用,比如数据科学、分析技术、教育信息化实践等,具备成为独立学科的能力。学习分析学的根本理念是“以人为本”,旨在通过数据科学和分析技术全面、系统地追踪学习、理解学习和优化学习,其可信的关键在于充分保障教育利益相关者的权益,尤其是教育主体的安全,这与祝智庭教授所提出的教育第四范式的理念相一致[78]。该范式是数字时代的教育新范式,围绕数据挖掘和智能分析,强调“以学生为中心”“适性发展”“精准、定制、个性化”“需求驱动”,旨在以机制灵活、开放创新、适需服务的未来数字化教育颠覆传统教育体系和教育组织形式。可信的学习分析学是从个人、技术、社会等多个角度综合考虑学习分析的安全性、稳健性和公正性,基于“可信”的意义,对数字教育新范式的理念进行继承与发展。在未来,学习分析学需要不断扎实学科理论与迭代优化教学实践,构建出更安全、更可靠的学科生态体系,担负起其对于教育的责任,传达“以人为本”的人性关怀,不断深化数字教育新范式,推动教育改革朝着更加公平、高效和优质的方向发展。
