深度学习中文命名实体识别研究进展
2023-12-27奚雪峰盛胜利崔志明徐家保
李 莉,奚雪峰,3,盛胜利,崔志明,3,徐家保
1.苏州科技大学 电子与信息工程学院,江苏 苏州 215000
2.苏州市虚拟现实智能交互应用技术重点实验室,江苏 苏州 215000
3.苏州科技大学 智慧城市研究院,江苏 苏州 215000
4.德州理工大学,美国德克萨斯州 拉伯克市 79401
命名实体识别(named entity recognition,NER)是一项基本的信息提取任务,在自然语言处理(nature language processing,NLP)应用,例如信息检索[1]、自动文本摘要[2]、智能问答[3]、机器翻译[4]、知识图谱[5]中起着至关重要的作用。NER的目标是从句子中提取一些预定义的特定实体,并识别其正确的类型,例如人物、位置、组织。
早期的NER 方法可以分为两种:基于规则的方法和基于统计的方法。基于规则的方法是根据任务手动设计特定字段的大量规则来匹配命名实体,并将其泛化和限制在其他字段上。因此,基于规则方法很费时费力[6]。基于统计的方法将NER 任务转换为序列标记任务,并使用人工标记的语料库进行训练。由于基于统计的方法的标注成本远低于设计规则的成本,因此在深度学习爆发之前成为主流方法,比如隐马尔可夫模型(hidden Markov models,HMM)[7]或条件随机场(conditional random fields,CRF)[8]。据统计,在CoNLL-2003 大会中,参加比赛的16个NER系统全部采用统计方法[9]。
本文调研了中文NER发展史上有代表性的综述论文,赵山等人[10]调研了在不同神经网络架构下最具代表性的晶格结构的中文NER 模型。王颖洁等人[11]从字词特征融合角度介绍中文NER方法。Liu等人[12]从三层体系结构(字符表示、上下文编码器、上下文编码器和标签译码器)总结中文NER的工作。康怡琳等人[13]从深度学习的角度单独地对中文NER输入嵌入表示进行了详细的总结和分析。以上综述都是集中在扁平中文NER方法的总结和分析上,没有包含中文嵌套命名实体识别,虽然张汝佳等人[14]介绍了中文嵌套NER,但是没有详细地包含中文嵌套NER 的方法,且以上综述并未对中文小样本的NER方法进行总结。
本文首先回顾了命名实体识别的发展进程,同时给出了中文NER 的特殊性;其次从中文命名实体识别的特殊性和任务分类出发。分别从扁平实体边界问题、中文嵌套命名实体识别和中文小样本问题,这三个方面对目前中文NER 研究工作进行系统性梳理,归纳总结了每一个方面的主流方法和具有代表性的模型以及部分内容的优缺点。再次整合了中文NER中广泛且常用的数据集和评价标准;最后概述了该领域未来的发展方向。
1 研究现状
命名实体识别经历了三大发展阶段,基于规则的识别方法,基于统计的机器学习方法和基于深度的学习方法。在命名实体识别中,BiLSTM-CRF的出现拉开了命名实体识别在深度学习的序幕。它的出现使得模型更加简洁、鲁棒,成为解决NER问题的深度学习基准。如图1 所示展示了基于深度学习的中文命名实体识别的通用架构分为输入分布式表示层、文本编码层和标签解码层。表示层以字符信息为基础,在字符信息的基础上添加部首、字形、词性、读音、词典等信息;文本编码可利用神经网络获取上下文依赖关系。标签解码层对输入序列进行预测并标注。这些模型处理实体时有各自的优缺点,比如CNN可对数据进行并行化处理,因此计算速度较快,但是存在上下文信息记忆缺失的问题。LSTM是RNN的变体,可以有效地学习长距离依赖的信息,不过仍然存在梯度问题。而GNN凭借不断挖掘图数据的模型,可以更高效地挖掘实体之间的关系,但是模型结构过于庞大,因此灵活性和拓展性差。Transformer是常常与BERT组合进行预训练,从而生成深层次的语言特征,但是需要消耗大量算力资源。因此在选择模型上要根据具体情况分析。
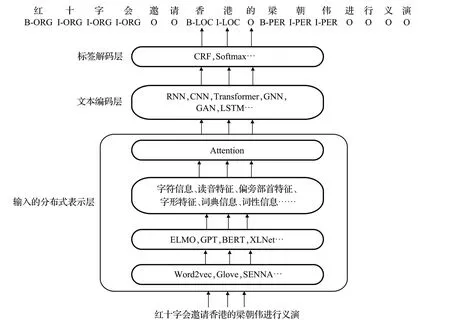
图1 基于深度学习的中文命名实体识别的通用架构Fig.1 Common architecture for Chinese named entity recognition based on deep learning
字符表征是CNER研究的重点。简单的外部特征,如词性、部首和笔画,包含的信息量较少,在信息量不足的情况下是有效的,在BERT 预训练模型提出之前,这些特征表现良好。然而,随着BERT等预训练语言模型的发展,预训练字符表示可以抓住汉字的大部分语义信息,因此在使用这些预训练语言模型时,CNER 模型很难从简单的外部特征中受益。除此以外,借鉴现有的英文NER方法对于解决中文NER问题是非常必要且有价值的。
1.1 预训练模型
在NER 的深度学习模型中,词嵌入是一种常用的数据预处理方法,可以学习到单词向量表示并捕捉句子相应的语义和句法信息。
Qiu 等人[15]对NLP 的预训练语言模型(pre-trained language model)进行了全面的综述,并将PTM 分为预训练的词嵌入和预训练的上下文编码器。在分类的基础上,将预训练的字符嵌入分为静态嵌入和动态上下文嵌入。静态嵌入被训练为查找表,每个字符的嵌入固定在表中,如NNLM、Word2vec、FastText、Glove 等。但由于静态嵌入的训练结果是一个固定的词向量矩阵,不能被动态修改,因此无法解决一词多义现象和实现真正的文本语义理解。
动态上下文嵌入也被称为预训练语言模型,这些模型生成的表示会根据上下文而变化,如ELMo、BERT、ERNIE、ALBERT、NEZHA 等,其中BERT 是最常用的。对于给定的字符,BERT将其字符位置嵌入、句子位置嵌入和字符嵌入作为输入,然后使用掩码语言模型(MLM)对输入的句子进行深度双向表征的预训练,获得鲁棒的上下文字符嵌入。由于BERT出色的表现,一些学者开始探索如何在减少训练资源的情况下获得相似的效果。因此,基于BERT模型改进的RoBERTa、SpanBERT等模型相继提出。此类模型限制输入序列的长度,因而在文本自动摘要等生成式任务上表现不佳。为解决此类问题,XLNet通过应用Transformer-XL 来提取长文本特征。此外,百度提出的ERNIE 模型也更专注于中文领域的词向量训练。
1.2 中英文NER之间的关联性
近年来,深度学习在NLP 领域的优越特性,即可直接从数据中学习特征表示,为该领域带来了显著的突破。在英文命名实体识别方面,深度学习模型也已大幅提升了其性能。与此同时,相对于中文命名实体识别技术,英文文本的NER技术由于英语特有的分词规则,即词与词之间存在天然的空格屏障,研究难度更小,起步更早,已经达到相对成熟的阶段。因此,近年来,国内外学者开始将英文NER 技术应用到中文命名实体识别中,因为中英文文本都具有明显的语法和词汇特征;其次,中文和英文都是上下文重要的语言,实体的上下文信息对实体识别具有重要影响。此外,中文NER 和英文NER 面临的问题具有相似性,例如,未登录词的问题。随着各领域和大数据时代的发展,会出现大量新实体,但这些新实体在词典中缺乏统一的命名规范规则。所以,命名实体识别(NER)需要具备强大的上下文推理能力,能够识别中英文中的嵌套实体,包括外层实体和内层实体。这是当前NER 研究中的热点之一。同时,中英文NER 都存在文本歧义问题,同一文本在不同位置所代表的实体类型可能不同,因此需要在进行NER之前进行实体消歧的处理。
综上所述,由于中文语言的特殊性,加上中文NER起步又晚,所以当其中一些的深度学习的方法直接用在中文命名实体识别任务上时并不能取得在英文命名实体识别上一样的良好的效果。因此中文命名实体识别较为困难。而中文NER的特殊性和难点体现在如下几点:
(1)中文词语边界模糊。和英文文本不同的是,中文文本不具有显示的分隔符(比如空格)和明显的词性变换特征(例如,英文中的地名和人名会首字母大写)作为边界标志。因此难以确定分词边界。
(2)嵌套实体。实体包含其他实体或被其他实体包含,要同时识别出内部实体和外部实体,是当前的研究热点之一。
(3)实体歧义。在实体识别的结果中,存有同一个实体可能会有不同的指代,或者存在一词多义的情况,这会导致实体识别的结果不够准确且存在歧义。因此,在获取准确、无歧义的信息之前,需要对实体识别结果进行消歧处理。
(4)低资源的NER。目前对有限的领域和有限的实体类型而言,命名实体识别可以在这些地方取得良好的识别效果,无法迁移到其他特定领域中。
2 基于深度学习的中文命名实体识别
自引入深度学习后,虽然一些深度学习模型在英文命名实体识别任务上取得了较好的性能提升,但是中文NER的处理有一些独特的困难,例如,汉语句子中的每个汉字之间没有明显的分割边界、实体存在嵌套问题和中文低资源领域的问题。从处理中文命名实体识别的角度出发,将这些深度学习的方法分为扁平实体边界问题、中文嵌套命名实体识别和中文小样本问题。图2为基于深度学习的中文NER 方法分类图,也体现了本文的写作思路和文章结构。

图2 基于深度学习的中文NER方法分类Fig.2 Chinese NER classification based on deep learning
2.1 扁平实体边界问题
命名实体识别过程通常包括两个部分:(1)实体边界识别;(2)确定实体类别(人名、地名、机构名或其他)。因此确定实体边界对于命名实体识别来说有着举足轻重的作用。ENER 实体通常可以通过一些明显的形式标志来识别,比如地点或人名实体的单词首字母大写。因此,在英文中,实体的边界识别相对来说比较容易。但是,与英文相比,中文命名实体识别任务更为复杂。这是因为中文中的实体往往没有明显的形式标志,而且实体的构成也更加复杂。与实体类别标注子任务相比,实体边界的识别在中文NER 任务中更加困难。因此,在中文NER任务中,需要采用更加复杂和精细的算法来进行实体识别和边界识别,以达到更高的准确率和召回率。先前有研究者用基于字符的方式解决CNER,虽然取得了较好的性能,但不能利用词边界和词序信息确定实体边界。近年来,随着深度学习的引入,CNER的研究主要是针对中文词之间没有明确的边界这一特点进行展开,在研究的过程中发现,对于没有完全基于词的中文命名实体识别模型而言,外部资源的引入,可以为词汇提供边界信息,从而提升模型性能,这被视为提升模型性能的其中一种辅助工具。因此在确定实体边界方法上大致可以总结为分词和中文字词特征融合两个角度。
2.1.1 分词
在中文NER中,分词是一个必要的前置任务,因为中文是以字符为基本单位的,而不像英文等语言有空格作为单词的分隔符。因此,分词的质量会对NER 任务的性能产生很大的影响。在分词方面,有两种主要的方法:管道分词和联合训练。下面将详细介绍管道分词方法和联合训练方法。
(1)管道分词
管道分词是指将分词和NER分为两个独立的阶段进行处理,即先对输入文本进行分词,然后再进行NER标注,如图3所示。

图3 分词流水线模型示例Fig.3 Example of participle pipeline model
给定句子“上海市长江医院医生王刚”经过中文分词(CWS)系统后划分了相应的单词分为“上海市,长江,医院,医生,王刚”然后在输入到基于单词的NER模型[16]中进行实体识别。但是不同的分词系统或工具[17-18]会有不同的分词结果,比如会分成“上海,市长……”等情况。管道分词的方法简单有效,易于扩展,但无法处理错误分割造成的误差传播问题,同时忽略NER 对分词的辅助标注问题[19]。目前常见的分词工具如表1 所示。列出了常用的比较成熟的中文NER分词工具。此外,图4列出了不同分词工具在不同语料库上的分词结果准确性。

表1 常用的中文NER分词工具Table 1 Commonly used Chinese NER segmentation tools

图4 不同的分词工具在WEIBO和MSRA数据集上的准确度结果Fig.4 Accuracy of different word segmentation tools on WEIBO and MSRA datasets
(2)联合训练
联合训练是将分词和实体识别任务视为一个整体任务,通过共享底层的神经网络来完成。图5给出了联合训练的架构图,这种方法可以利用分词和实体识别任务之间的相关性,提高整体模型的准确性和泛化能力。
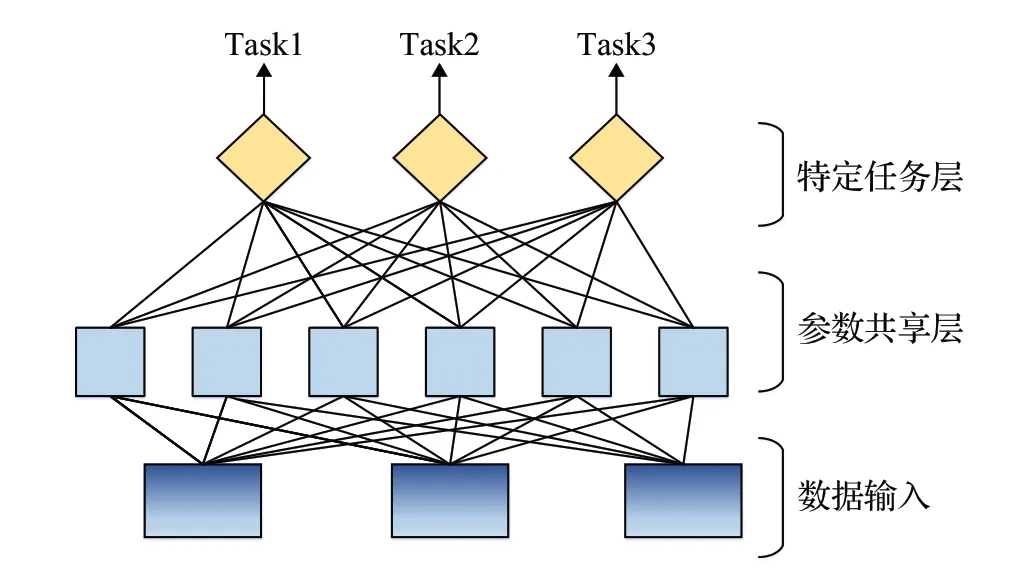
图5 联合训练的架构图Fig.5 Architecture of multitasking training
Peng 等人[20]率先提出联合训练中文NER 和中文分词(CWS)模型,一方面采用单向的LSTM网络用于分词模块,另一方面使用基于特征的对数双线性链CRF作为NER 的特征提取器;具有线性链特性的CRF 既可以用于NER 的特征提取又可以访问LSTM 模块产生的分词特征,它将嵌入和LSTM 的隐藏向量作为变量,因此可以将梯度传播回LSTM 中以调整参数。最终分词和神经网络训练共享LSTM的所有参数,实现参数共享获得5%的性能提升。
为了获取局部字特征,Wu等人[21]利用CNN捕捉本地上下文,同时联合训练了中文NER和CWS模型以提升CNER模型预测实体边界的能力。但是,文献[20-21]提出的模型只关注中文NER和CWS之间共享的信息,却忽略每个任务的特定信息带来的噪音。为此,Cao等人[22]提出整合共享任务词边界信息的对抗性迁移学习框架,利用对抗训练确保中文NER 任务仅使用共享的词边界信息,由此可以过滤特定信息产生的噪音。此外,Tang等人[23]构建了一个多任务BERT-BiLSTM-AM-CRF智能处理模型,利用BERT提取结合上下文信息的动态词向量,通过BiLSTM 模块进一步训练后将结果输入CRF层进行解码。经过注意机制网络后,该模型可以在两个中文数据集上共同学习,最后通过CRF对观测注释序列进行分类提取,得到最终的结果。在MSRA数据集中的F1得分显著提高0.55%。
Zhu等人[24]利用多种任务中学习实体共享的边界信息的方式,将词边界信息和语义信息结合起来。通过对抗学习方法,从中文分词(CWS)、词性标注(POS)和实体识别学习特定任务的单词语义信息,并将所学到的边界信息与语义信息结合起来。在Resume数据集上达到了95.70%的效果。由于现有的基于Transformer的CNER模型常常忽略Transformer底层捕获的信息以及Transformer每个头投影的子空间的重要性,于是Wang 等人[25]提出了多任务标签智能Transformer(MTLWT),从全局的角度,将实体边界预测(EBP)和实体类型预测(ETP)任务分配给前两层,并为每个注意力机制头提供一个特定的焦点,使得头部投射成为一个重要的子空间。实验表明MTLWT在MSRA数据集上的性能优于其他框架。
综上所述,联合分词和中文NER 共同训练的模型虽然可以共享分词和NER 任务中相同的语义信息,但是联合模型必须依赖于CWS 和NER 任务标注的数据集,同时还需要在不同的切分标准下进行注释。这显然增加了模型的复杂度和训练时间。在本文,对管道训练和联合训练两种方法进行了比较分析,如表2所示。

表2 管道训练和联合训练方法比较Table 2 Comparison of pipeline training and combined training methods
2.1.2 中文字词特征融合
中文NER 通常采用基于字符级别的模型,因为中文需要分词,分词不准确会影响基于词的模型的性能。但是,是否充分利用词汇信息有助于基于字符的NER模型更好地确定实体边界。因此,如何在字符级别的模型中引入词汇信息成为中文NER领域的研究重点。
融合字词特征方法是一种利用自动构建的词典的技术,该词典是对大规模自动分段文本进行预训练得到的。这种方法通过使用词典中单词的边界信息和预训练的单词嵌入的语义信息来提高中文NER 模型的性能。相较于联合方法,融合方法更易于获取且不需要其他标注好的分词数据集。根据融合模型架构是否具有可移植性进行分类,可以大致分为自适应基础架构、基于图结构模型和自适应嵌入三大类。其中,自适应基础架构和基于图结构模型属于动态结构的范畴,即需要设计合适的模型结构来整合词汇信息。
(1)自适应的基础架构
自适应的基础架构也可以称为序列建模层。它利用现有的神经网络模型对输入序列进行建模。主要的神经网络模型有基于RNN及其变体的网络模型LSTM[26],基于CNN 的模型[27-28]和基于Transformer 的模型。在序列建模层中自适应的融合词汇信息。
Zhang等人[29]率先将词典信息融合到中文命名实体识别中,设计了Lattice LSTM 模型,其结构如图6 所示。该模型将输入的字符序列与自动构建的词典中的所有潜在词组成一个Lattice(有向无环图),相邻字符之间的边连接起来,同时潜在词的首尾字符也进行连接,以充分利用单词边界信息和语义信息,从而避免了分词带来的误差传播。然而,Lattice LSTM 也存在一些缺点,因为它只能考虑以每个字符为结尾的潜在词,会出现潜在词冲突和引入噪声的问题;例如图3中的“市长”和“长江”就是典型的潜在词冲突,需要全局语义才能解决。此外,Lattice LSTM 本质上仍然是一个LSTM 结构,因此存在难以并行化,缺乏可迁移性,并且运行速度较慢的缺点。

图6 Lattice LSTM模型结构Fig.6 Lattice LSTM model structure
为了解决Lattice 结构中的潜在词冲突问题,Gui 等人[27]提出了LR-CNN 模型。该模型采用CNN 进行特征提取,每层引入Attention机制来融合对应字数的词汇信息;同时,采用Rethinking机制解决词汇冲突问题,将高层特征作为输入,并通过注意力调整每一层的词汇特征。LR-CNN 使用并行化方法进行特征提取,相较于Lattice LSTM模型加速了3倍左右。同样,WC-LSTM[28]也对Lattice LSTM进行了改进,采用四种不同的策略将单词信息编码为固定大小的向量,以便可以分批训练。
为了更好地利用Lattice结构中有效的词信息,Xue等人[30]提出了基于自注意力机制的PLTE模型。该模型将相对位置关系编码和每两个非相邻令牌共享的枢纽融入到Lattice 结构中,以增强自我注意力机制,从而大大提高了运算效率,并在MSRA等数据集上取得了良好的实验结果。
Li 等人[31]提出了一种基于Transformer 的FLAT 模型,如图7 所示,用于处理序列中长距离依赖关系。该模型使用完全连接的自注意力机制,并改进了原始Transformer的绝对位置编码,设计新的相对位置编码表达Lattice 结构。模型为每个字符和词汇分配了两个位置索引:头部位置和尾部位置,通过这两个位置索引,可以从一组标记中重构原有的Lattice结构,并实现字符与所有匹配词汇信息间的交互。FLAT 模型运行效率很高,在性能上优于其他结合字典的模型,其中,使用BERT在大型数据集的性能改进尤其明显。

图7 FLAT模型结构Fig.7 FLAT model structure
相比于FLAT 模型使用词嵌入和设计新的Transformer 层,Zhu 等人[32]提出了Lex-BERT,它直接将词典信息整合到中文BERT中,用于命名实体识别任务。在Ontonotes4.0和ZhCrossNER上的实验表明,Lex-BERT的模型远远优于FLAT模型。Yan等人[33]提出了基于自适应Transformer的TENER模型。在TENER中,Transformer编码器不仅用于提取单词级别的上下文信息,还用于对单词中字符级别的信息进行编码。并且TENER模型的实验表明,TENER的性能优于当前基于BiLSTM的模型。
但FLAT 和TENER 模型需要在确定实体边界时学习词汇中单词的其他嵌入。这就带来一个缺点,即如果词典得到更新,那么模型必须重新训练,同时词典还会引入过多的匹配噪声。为了克服这些缺点,Wang等人[34]提出了DyLex,这是一种用于基于BERT 的序列标记任务的插件词典合并方法。与传统方法不同,DyLex采用了一种有效的监督词汇的方法来消除匹配噪声。在WEIBO 数据集上的实验表明,即使使用非常大规模的词典,DyLex框架也实现了SOTA水平。Liu等人[35]则是在词典信息中引入了词的字符位置,以更好地理解字符的含义。为了融合字符、字和字位置信息,他们对键值存储网络进行了改进,提出了一种TFM 模块。这个模块不仅可以简单地串联使用,还可以与一般的序列标记模型兼容。
(2)基于图结构模型
近年来,图神经网络在处理图数据时具有许多优势,比如可以忽略节点的输入顺序、不受邻居节点的影响等。这些特性使得图神经网络成为了当前研究的热点。常见的图神经网络包括图卷积神经网络[36]、图注意力网络[37]以及门控图神经网络[38]等。这些网络模型可以用于实体边界的识别等任务。同时,一些学者也将图结构和词典信息结合起来,以解决实体边界识别等问题,取得了不错的效果。
Sui 等人[39]在中文NER 任务中首次引入了GAT 网络和自动构造的语义图,如图8 所示,并提出了CGN 网络(collaborate graph network)。该网络通过构造三种不同的图结构来获取词语的多角度、全方位信息,并在融合层进行合并。相较于传统的方法,该模型不仅提高了中文NER 任务的准确率,而且极大地降低了计算时间成本。该研究成果为中文NER任务的深度学习方法提供了一种新思路,并对后续研究产生了积极的推动作用。然而,该模型没有区分不同的词边缘,容易混淆字符和单词之间的信息流。于是,Zhao等人[40]提出了一个多通道图注意网络MCGAT,它由三个词修改的图注意网络组成。该网络利用字符与单词之间的相对位置关系,并结合词频统计信息和逐点互信息,以进一步提高模型的性能。此外,Gui 等人[41]引入一个具有全局语义的基于词典的图神经网络LGN。该网络使用GNN构造构成字与词之间的关系,打破了基于RNN 的链式结构。LGN通过不断地递归聚合实现节点与连接边的信息更新,从而提升了模型性能。为了更好地捕获对长距离依赖性能,Tang 等人[42]提出了一种新颖的词字符级图卷积网络WC-GCN(word-character graph convolution network)。该网络通过引入全局注意GCN 块来学习以全局上下文为条件的节点表示。
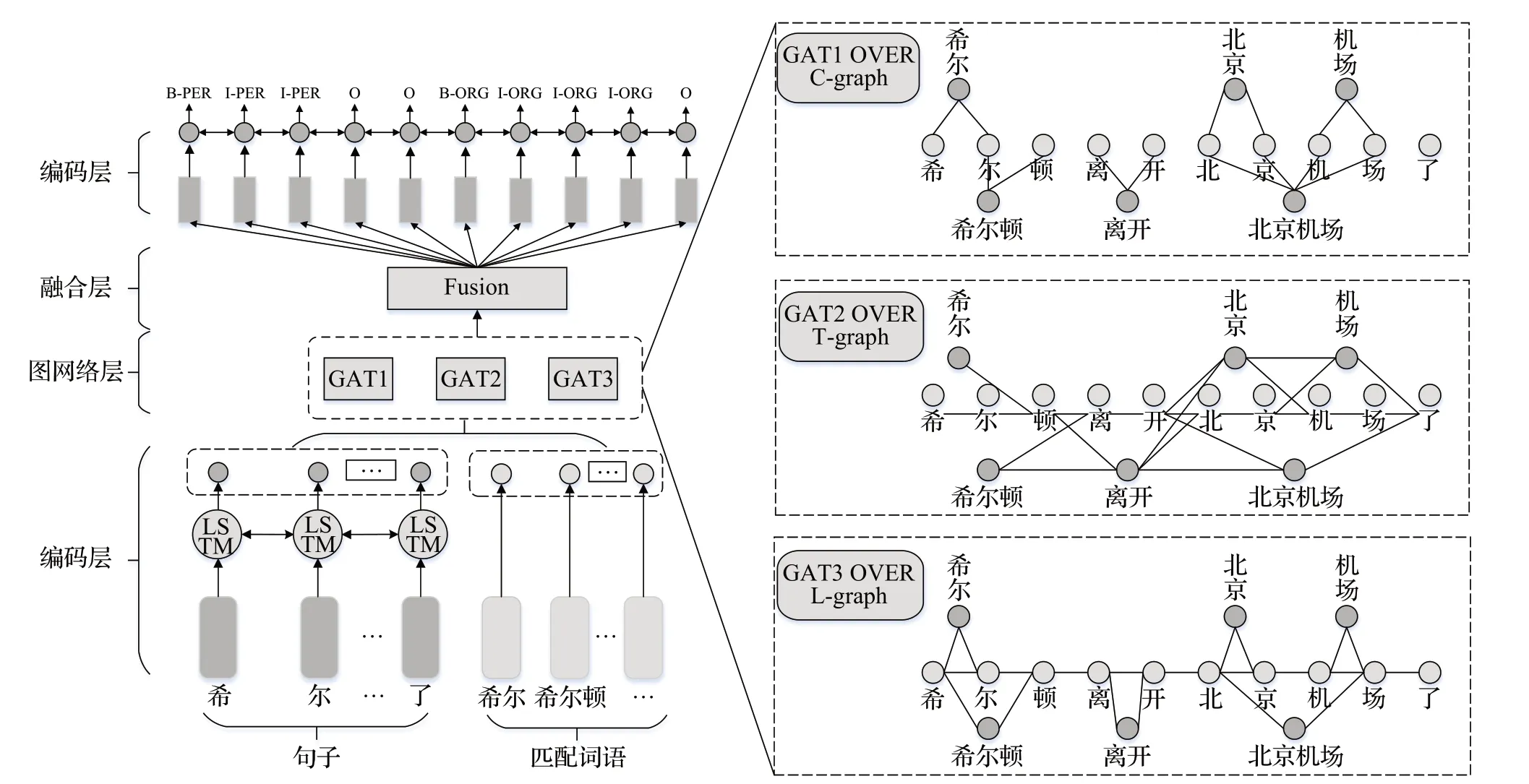
图8 CGN网络架构图Fig.8 CGN network architecture diagram
由于分词之间的依赖关系可以帮助确定实体边界,因此利用与句法依赖关系相关的信息来提高NER性能也是一个新思路。一些研究者采用了图神经网络来学习句法依赖图的信息,并将学习到的信息合并到经典的双向长短期记忆(BiLSTM)条件随机场(CRF)NER方案中,这种方法取得了不错的效果。例如,Zhu 等人[43]和Zhang等人[44]都利用了图注意网络来建立具有句法依存信息的单词之间的依赖关系。Zhang等人[44]提出了一种名为MCSN(multi-graph collaborative semantic network)的方法,该方法利用汉语单词的依赖关系,不仅克服了词典的不足,而且更好地捕获了汉语单词的语义信息。
Wang等人[45]提出了一种多态图注意力网络(PGAT),旨在捕捉字符与匹配词之间的动态相关性。该模型将每个字符映射到四个位置,即B(开始)、M(中间)、E(结束)和S(单个词)。通过使用基于图注意力网络(GAT)的语义融合单元,可以动态地调节每个位置上匹配词和字符之间的注意力,从而可以显式地捕捉每个位置上字符和匹配词之间的细粒度相关性。在医学领域,中文NER 也是一个重要的课题。Xiong 等人[46]利用多源知识,将词典与中国临床NER(CNER)的边界结合在一起,提出了一种基于关系图卷积网络(RGCN)的新方法。对于任何句子,都会构建基于每个知识源中的单词或概念的关系图。其中将出现在句子中的词典单词或知识图概念进行标记,该标记具有词典单词或知识图概念的边界信息,这种方法有效地确定医学文本中的实体边界。
(3)自适应嵌入
自适应嵌入是一种将词典匹配信息直接添加到字符表示中的方法。与传统的嵌入方法不同的是,自适应嵌入不涉及编码层,而仅仅对嵌入层的表示进行修改。这种方法可以提高嵌入层的效率,并且可以更好地适应特定任务的需求。
为了引入字典信息,Lattice LSTM在输入序列中非相邻字符之间增加了多条附加边,这大大降低了训练和推理的速度。为了解决这些问题,Ma 等人[47]提出了SoftLexicon模型,一种更简单的方法来实现Lattice LSTM的思想。该模型在不修改上下文编码器的情况下,为具有固定长度向量的字符表示添加了词典信息。SoftLexicon将句子与字典相匹配,并对于每个字符找到包含它的所有单词。然后,将这些单词分为四个类别(BMES),并将它们映射到四个类别的向量中。最后将这四个向量与字符表示相连接,使边界信息和词义信息同时添加到输入表示层中。该方法避免了设计复杂的序列建模体系结构,可以快速适应任意合适的神经网络NER模型,并具有可迁移性。
为了捕获融合字词信息空间中的细粒度相关性,Zhao 等人[48]提出了DCSAN。DCSAN 是一个动态的交叉和Self-Lattice 注意网络,将Cross-Lattice 注意模块和Self-Lattice注意模块与门限词-字符语义融合单元相结合。Cross-Lattice注意模块和Self-Lattice注意模块分别用于捕获输入特征空间之间的相关性和动态融合单词特征。这些模块能够有效地解决中文NER中存在的多义性和嵌套实体的问题。此外,DCSAN 能够建立任意两个字符之间的直接联系,因此即使字符之间的距离很远,也能够识别出它们是否属于同一个实体。该研究为中文NER 任务的深度学习方法提供了一种新思路,并在实验中取得了良好的效果。这两者结合可以有效地显式捕获不同空间之间的细粒度关系。Huang等人[49]也利用Lattice结构来引入词典信息,但是在此基础上使用外部无标签数据对词频进行计数,并利用改进的交互信息来表示单词的权重。此外,该方法为词典信息的每个部分动态分配权重,注意力机制也针对词典信息进行了处理。在这种方法中,字符和词典信息的融合在输入层之前进行处理,使其具有更快的训练速度和更好的通用性。
BERT模型[50]通过掩词模型和相邻句预测两个方法完成文本字词特征的预训练。掩码语言模型和相邻句预测是常用的自监督学习方法,可以通过大量无标签数据进行预训练,然后在有标签数据上进行微调,从而提高中文命名实体识别的性能。这些方法不需要对模型进行太多修改,因此受到了该领域的广泛关注。掩码语言模型通过将单词掩盖并学习其上下文内容特征来预测被掩盖的单词,相邻句预测则通过学习句子间关系特征来预测两个句子的位置是否相邻。为了更好地发挥词典信息和预训练模型BERT各自的优势,更深层次的将词典信息集成到BERT底层中,有很多研究者聚焦在词典适配器上,利用自匹配的词典特征完成字词融合。Liu 等人[51]提出了用于中文序列标记的词典增强BERT(LEBERT),如图9所示,该模型通过词典适配器层将外部词典知识直接集成到BERT层中,并且在中文数据集取得了较好的结果。Sun等人[52]在BERT结构中加入词典适配器将词典信息引入,有效地获取了实体边界和单词信息。值得一提的是Guo 等人[53]同时引入了指针网络的序列对,将序列标记任务转化为序列生成任务从而获取全局语义特征。

图9 LEBERT架构图Fig.9 LEBERT schematic diagram
此外,由于汉字的复杂和特殊性,在引入词信息过程中同时会融合汉字字形、拼音、部首和笔画等特征。比如,如图10 所示,Wu 等人[54]在中文命名实体识别中引入了汉字的结构信息,并提出了一种新型的交叉Transformer模型,名为MECT。该模型通过将汉字特征和部首级嵌入集成在一起,能够更好地捕获汉字的语义信息。与其他模型相比,MECT 能够有效地提高中文NER的准确性。在Wu等人[54]的基础上,Zhang等人[55]额外引入汉字拼音特征,提出Visphone模型。该模型使用两个相同的交叉转换器编码器,将输入字符的部首和语音特征与文本嵌入相融合。并使用一个选择性融合模块被用来得到最终的特征。在OntoNotes4.0、MSRA、Resume和WEIBO上进行了实验,F1值比MECT模型分别提高了0.79%、0.32%、0.39%和3.47%。Mai 等人[56]通过加入汉字语音特征,解决了实体边界潜在词歧义问题。笔画信息是汉字书写的最基本单位。

图10 MECT架构图Fig.10 MECT architecture diagram
尽管单个笔画本身没有特定含义,但是在字符书写的过程中,笔画的顺序和组合会包含一定的语义信息。Luo等人[57]在研究中提出了一种基于笔画和ELMO[58]的中文电子病历实体识别方法。实验结果表明,通过对语言模型进行预训练,笔画ELMO能够学习到大量汉字的内部结构信息,并取得了比随机字符ELMO更好的效果。
汉字的字形信息源于甲骨文模仿实物形状的方式而来,且通常使用卷积网络来对汉字的图像进行信息和语义提取。Xuan 等人[59]提出了一种结合了滑动窗口和注意机制的方法,来将每个字符的BERT表征和字形表征融合起来。实验证明,这种方法可以获得汉字上下文和字形之间潜在的交互知识。还有一些中文命名实体识别模型引入了多粒度嵌入的方法。比如,Zhang 等人[60]结合了中文笔画、汉字部首和汉字特征,使用卷积网络提取汉字笔画信息,并将其与字词信息相结合,有效地丰富了语义信息和实体边界信息。Huang等人[61]提出了三种关系,包括字符之间的相邻关系、潜在单词之间的字符共现关系和令牌之间的依赖关系,并设计了一种掩盖的自我注意机制来合并潜在单词本地上下文信息。为了避免词典和依赖关系等外部知识引入噪声,他们提出了一种门控信息控制器来解决这个问题。实验证明,这种方法是有效的。
2.1.3 模型总结
表3列举了近年来,基于深度学习方法解决扁平实体边界问题的模型在四个常见的中文数据集上的F1-score结果对比。并且直观地列出模型采用的字符嵌入的方式和引入何种外部资源。从表格中不难发现加入预训练模型BERT 之后的性能都显著提高,尤其是LRCNN 在WEIBO 上的F1-score 值显著提升了7 个百分点,虽然使用BERT可以提高识别的准确率,但是BERT需要大型数据集,并且BERT 内部参数过多,在训练时会导致内存不足和训练时间过长等缺点;并且还会发现确定实体边界的主体的方法依然是BiLSTM+CRF,使用Transformer 方法的性能,往往要受到是否引入预训练模型BERT的影响;此外还可以看出加入词典和额外的外部资源后对于性能提升是有效的,但是在实际应用中,构建词典是费时费力的,而且还会伴随着由错误数据的影响。

表3 扁平实体边界模型的F1-score结果分析Table 3 F1-score analysis of flat entity boundary model
联合训练的方法模型,比如ZH-NER 和MTLWT等,挖掘共享底层网络信息,从共享分词和NER任务中语义信息,提取更多的字符和词特征,有效地提高分词和实体识别任务之间的相关性。但是联合模型必须依赖于CWS和NER任务标注的数据集,这显然增加了模型的复杂度和训练时间。
自适应的基础框架模型,如CNN 堆叠编码结构的LR-CNN、WC-LSTM和具有晶格结构的Lattice,以及具有Transformer结构的PLTE、FLAT等。这些自适应的基础架构都是从模型输入层的角度优化中文命名实体识别性能;这类模型通过设计相应的结构以融合词汇信息。但是模型不具有移植性的特点。晶格结构有效地解决了因为分词带来的误差传播了的影响,并且有效地融入词典信息。CNN堆叠编码模型则解决了词汇冲突的问题,在数据集上达到了不错的效果。但是这两者无法有效地捕获长距离依赖的问题,存在一定程度上的信息损失。基于Transformer 的深度学习网络模型,如DyLex等,克服了文本长距离依赖问题以及减少了捕获句子中单词之间关系的计算成本,从而提升了模型的性能,但是在实际的应用场景中,Transformer 模型所需的模型参数往往较多,网络结构复杂,所以还是一定程度上影响了模型性能。
基于图结构模型,如MCGAT、LGN、SDI、PGAT等,将NER 任务转化为node 分类任务;一方面挖掘文本内部的图结构信息,另一方面在图结构中融入词典信息,从而提取更多的局部特征。比如PGAT[46]同时在MSRA、WEIBO、OntoNotes4.0 三个数据集上的表现效果极佳,在OntoNotes4.0 上实现了81.87%的结果,超出了基于Transformer 模型的SOTA 结果。此外,SDI 则引入句法依存图结构有效提升文本上下文语义信息,但是仍然面临图数据带来的模型结构复杂的问题。
自适应嵌入模型中,如LEBERT、MECT、Visphone、PDMD等通过只修改表示层的操作,引入预训练模型和外部资源特征比如具有部首、读音、笔画、词频等增强汉字语义特征,实现了可移植的效果。比如,Mai 等人将读音与词边界信息融合,得到了更好的嵌入表示,有效地解决了边界歧义问题,在OntoNotes4.0中文数据集上达到了83.14%的极佳效果;同样Huang 将词频加入到表示层嵌入中,利用常用的BILSTM+CRF 编码器,在Resume上达到了96.73%的最好效果。
总的来说,在确定实体边界的问题上,可以从引入外部资源、模型结构、输入层的表征三个方面进行优化。即引入词典获取更丰富的语义信息和汉字的相关特征,在输入层引入预训练好的语言模型,同时结合多个深度学习网络,取长补短地获取适合相应任务的模型。而这种思路逐渐成为确定实体边界提升CNER 任务的主要思路。
2.2 中文嵌套命名实体识别
在许多实际应用中,命名实体是具有嵌套结构。具体来说,一个实体可以包含其他实体或成为其他实体的一部分,如图11“南京市红十字会”是一个ORG 类型的实体,它包含两个内部实体,即“[南京市]LOC”,“[红十字会]ORG”。由于一般模型的序列标注特性和单标签分类特性,往往只能识别一个大实体“南京市红十字会”或者两个小实体“红十字会”和“南京”。难以将这三个实体同时全部识别出来。嵌套命名实体需要丰富的实体及其之间的关系,因此,对嵌套命名实体的识别已成为重要的研究方向。

图11 中文嵌套命名实体识别示例Fig.11 Example of nested named entity recognition in Chinese
对于嵌套NER 的研究,研究者大多集中在英文嵌套命名实体识别(English nested named entity recognition,ENNER)任务上,从模型体系结构的角度来看,目前基于深度学习解决ENNER的方法可以分为以下几种主流:基于分层的、基于过渡、基于区域的、基于超图的方法和其他模型方法[62]。然而,由于中文文本的复杂性,针对中文嵌套命名实体识别需要在上述几种主流的方法的基础上进行改进。下文将详细介绍这几种主流方法在中文嵌套实体识别上的应用。
2.2.1 基于分层的方法
基于分层的方法通常将嵌套的NER任务视为多个扁平命名实体识别(flat name entity recognition)任务。该方法先提取内部实体,然后将其送到下一层提取外部实体,同时遵循级联结构,对层模块进行串联连接。然而,该模型存在明显的层与层之间的误差传播问题。
图12展示了基于分层的两种具有代表性的一般体系结构;图12(a)的分层结构包括编码器-解码器模块,其中每一层包含一个编码器层和一个解码器层,较高层的编码器可以从较低层的编码器获取实体信息。例如Ju 等人[63]首次提出了一种以内向外的方式动态地堆叠平面NER层的模型,即Layered-BiLSTM-CRF模型。该模型将编码器的输出合并到当前的平面NER 层中,以构建检测到的实体的新表示,并随后将新表示馈送到下一个平面NER层。这种策略允许模型通过利用其对应的内部实体的知识来识别外部实体,其中堆叠层的数量取决于输入序列中的实体嵌套级别。此外,张汝佳等人[64]在文献[63]的基础上添加了分割注意力模块和边界生成模块,进行边界增强,有效地捕获潜在的分词信息和相邻字符之间的语义关系。

图12 基于分层的两种具有代表性的一般体系结构Fig.12 Two representative general architectures based on layering
图12(b)仅包含解码器模块,在这个体系结构中只有一个共享的编码器层和多个解码器层来捕获来自不同层的实体。比如,Wang 等人[65]提出了一种新型的嵌套命名实体识别分层模型,即金字塔模型。该模型采用由内而外的方式处理嵌套的NER 任务。具体而言,金字塔模型由一系列相互连接的层组成,每一层都预测一定长度的文本区域是否为实体。此外,还设计了一个反金字塔,以允许相邻层之间的双向相互作用。这样,该模型将根据命名实体的长度来识别,避免了层迷失和错误传播的问题,实现了更加精准的命名实体识别。相比之下,Shibuya等人[66]提出了一种基于CRF的解码方法,可以从外到内的方式迭代识别实体,避免结构歧义。首先,使用BiLSTM 模型对输入语句进行编码,并利用最后一个隐藏层的输出来表示语句中的令牌。然后,对于每个命名实体类别,构造一个CRF进行解码,提取最外层实体和内部实体,而无需重新编码。对于每个实体类别,对应的CRF解码整个句子的标签序列,以提取最外层的实体。然后,该模型在先前提取的实体的基础上进一步递归地提取内部实体,直到每个区域都没有检测到多令牌实体。同样,金彦亮等人[67]也采用分层机制,但是在每一层之间加入一个自注意力机制模块联合多层序列标记模型,更有效将较低层实体中的隐藏语义送到更高层的实体中。在人民日报的数据集上良好的结果证明了加入自注意力机制的有效性。
2.2.2 基于区域方法
基于区域的方法一般将嵌套命名实体识别任务视为多类分类问题,并采用各种策略在分类之前获取潜在区域(即子序列)的表示。根据进展策略的不同,现有的基于区域的方法可以分为两类,分别为基于枚举的策略和基于边界的策略。具体来说,基于枚举的策略是指从输入句子中学习所有枚举区域的表示,并将它们归入相应的实体类别。而基于边界的策略则是通过利用边界信息建立候选区域(可能是实体)的表示,然后完成实体分类。两种策略的体系结构如图13和图14所示。

图13 基于枚举策略Fig.13 Enumeration based policy

图14 基于边界策略Fig.14 boundary based policy
在基于枚举的策略中,Sun 等人[68]提出了一种端到端的基于区域的TCSF模型,该模型能够同时学习句子中的令牌上下文信息和区域特征。为了实现任务,模型通过从上下文标记级序列中枚举所有可能的区域表示来进行训练。在Transformer 的启发下,模型进一步设计了一个区域关系网络,对句子中的所有可能的区域表示进行建模,以产生每个区域的关系表示。这种方法使得模型能够更好地捕捉上下文信息,从而在中文嵌套命名实体识别任务中取得了很好的效果。Long 等人[69]提出了一种分层区域学习框架,能够自动生成候选区域的树状层次结构,并将结构信息纳入区域表示,以帮助更好地分类。此外,还引入了基于词的相干测度来进行层次区域生成,测度值越高表示相邻词之间的相干程度越高。
相较于枚举策略,基于边界策略的最大优势是不需要再对一个句子中的所有区域进行枚举。虽然文献[68-69]具有处理嵌套命名实体识别的能力,但也同时面临着计算代价过大、忽略了边界细节、不充分利用与实体部分匹配的大跨度和多体识别难度过高等问题。为处理这种情况,Shen等人[70]给出了一种二层次的实体标识符模型。这种模型首先利用了对种子跨度的滤波和边界回归得到了长度建议,并确定了实体,进而把经过边界调整后的长度建议标识成了具体的类别。该方法在训练过程中,合理地使用了实体的边界信息以及部分匹配的跨度。同时利用了边界回归,在理论上能够覆盖任何长的实体,从而增强了对长实体的辨识能力。而且,在第一阶段过滤掉了许多低质量种子跨度,从而减少了推理的时间复杂性。在嵌套的命名实体识别数据集上的实验表明,提出的方法在ACE2005 的数据集上达到了86.67%的F1 值。但是,这两个阶段的方法仍然存在忽略跨度边界、长实体识别困难和误差传播的问题。于是,Huang 等人[71]提出了一种新的NER 框架,称为Extract-Select。该框架采用了一种跨度选择策略,让提取器能够准确地提取嵌套实体,有效避免以往的两阶段方法中的错误传播。在推理阶段,训练好的提取器会选择特定实体类别的最终结果。此外,该模型还使用了一种混合选择策略,结合了跨度边界和内容,提高了对长实体的识别能力。为了评估抽取结果,该模型还设计了一个判别器,并使用生成对抗训练方法对提取器和判别器进行训练。该方法显著减轻了数据集大小的压力,并在ACE2005数据集上实现了87.76%的F1值,表明该方法的有效性。为了学习更好的跨度表示和提高分类性能,Yuan 等人[72]提出了一种三仿射机制(triaffine mechanism)。该机制在跨度结构中集成了内部标记、边界和标签等一些异构因素。三仿射注意力使用边界和标签作为查询,并使用内部标记和相关的跨度作为跨度表示的键和值;而三仿射评分则与分类的边界和跨度表征相互作用。实验表明,该机制在KBP2017 数据集上取得了最先进的F1成绩。为了解决嵌套数据中存在大量重叠的问题,Wan等人[73]提出了一种在跨度层中基于图相似度的全局构建实体-实体图和跨度-实体图的方法。他们将相似邻居实体的信息集成到Span 表示中,从而连接跨层和训练数据中的实体关系。这样,可以更好地处理实体之间的关联信息,提高嵌套实体识别的准确性和效率。Chen等人[74]在BA(boundary assembling)模型的基础上进行改造,使模型能够通过在外部资源中预先训练的词嵌入来捕捉句子的语义信息,有效解决由于特征稀疏而导致识别性能差的问题。
总的来说,跨度模型通常是解决嵌套问题的常用模型,但是该模型在划分实体区域时,常常由于没有充分考虑整体上下文信息而存在负样本过多、在边界检测中未能充分利用实体部分匹配的跨度以及时空复杂度较高等问题。
2.2.3 基于过渡方法
基于过渡的嵌套NER方法主要受基于过渡的解析器的启发,这种方法从左到右解析一个句子,基于一次贪婪地解码一个动作来构建一棵树。但当实体嵌套层数很高时,状态转移的规则变得非常复杂,导致模型的性能下降。Wang等人[75]提出了一个可扩展的基于过渡的模型。如图15 所示,该模型将句子映射到一个森林结构中,其中每个实体对应于森林的一个组成部分。然后模型学习了通过一个动作序列,以自下而上的方式构建森林结构的方法。这种方法可以有效地处理嵌套实体,提高嵌套实体识别的准确性和可扩展性。在生物医学领域,Dai 等人[76]提出了一种基于端到端过渡的模型。该模型使用了通用的神经网络进行编码,并采用特定的动作和注意力机制,以确定跨度是否是不连续提及的一部分。在三个生物医学数据集上测试,证明该模型可以有效地识别不连续提及,而不会失去连续提及的准确性。
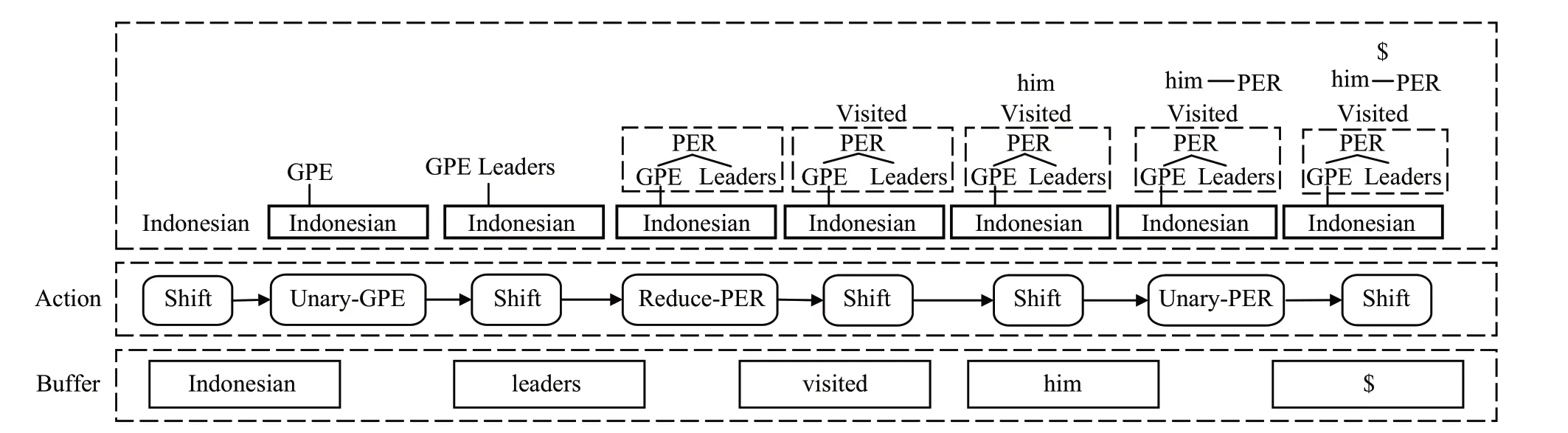
图15 基于过渡方法示例Fig.15 Example of transition based method
2.2.4 基于超图方法
基于超图的方法利用超图来表示句子中实体的嵌套结构,同时利用基于图的全局优化策略来完成边界检测和类别预测,并能利用超图中的hyperarc在属于不同命名实体的一个句子中精确标记令牌。Wang等人[77]提出了一种无结构歧义的超图表示。该模型使用分段超图来表示句子中潜在重叠提及的情况。通过重新设计节点,使得模型更好地探索不连续命名实体的各种跨度组合,从而提取局部特征。同时,使用一种广义的内外式消息传递算法,将子节点的特征有效地总结到父节点上,实现对超图结构上的推理。同样,Luo等人[78]也针对图结构歧义的问题,提出捕捉超图层之间的双向信息交互结构,有效地从Graph模块中学习更丰富的含有内部实体依赖关系的表示形式,从而提升最外部实体的预测性能。Yu 等人[79]则提出了一种利用图的依赖思想的方法。他们使用biaffine模型对句子中的开始和结束标记对进行评分,并通过探索所有跨度来精确预测命名实体。这种方法为模型提供了对输入的全局视图,从而提高了命名嵌套实体识别的准确性。总的来说基于超图的模型需要消耗大量的人力资源来设计超图;并且在训练和推理期间时间复杂度高,并且容易出现图结构歧义问题。
2.2.5 其他模型
由于嵌套实体也是属于命名实体识别中的一部分,因此,人们对依托基于机器阅读理解的解决方法,用统一模型同时解决扁平NER 和嵌套NER 越来越感兴趣。Li 等人[80]提出了一种将嵌套命名实体识别转换为机器阅读理解(MRC)任务的方法。该方法以BERT为基础,并针对需要识别的实体构造了一系列问题,从而转换带注释的命名实体识别数据集为一组{问题,答案,上下文}元组。最后,利用两个二进制分类器,一个用于预测每个令牌是否是实体的开始,另一个用于预测每个令牌是否是实体的结束,来完成嵌套命名实体识别任务。然而,这项工作在很大程度上依赖于训练数据的大小且容易忽略了内容信息。Li等人[81]提出了一种名为W2NER的模型,将NER 问题统一建模为词-词关系分类问题。该架构通过有效地建模具有Next-Neighboring-Word 和Tail-Head-Word关系的实体词之间的相邻关系来解决统一NER的核心瓶颈。此外,Zhang等人[82]用生成模型的方式统一解决Flat NER、Nested NER 和Discontinuous NER 问题,并且实验证明了生成模型有助于提升NER性能。
目前常见的中文嵌套NER的数据集有《人民日报》、ACE2004[83]、ACE2005中文[84]、IEER-99新闻[85]、MET2测试[86]等。这些都是公开数据集,同时还有一些在特定领域的隐私数据集。比如Xu 等人[87]的中医药数据集,他们在自己建立的中国传统的医学记录数据集上利用两层序列标注,对多个扁平命名实体模型进行堆叠,每一层分别识别不同粒度大小的实体,最终达到85.91%的召回率。以及电子病历数据集[88]。
综上所述,以上几种嵌套NER方法各有所长,也各有所短。研究者充分利用各种算法的优势,进一步提升实体识别的性能。上述几种方法的相关比较如表4所示。

表4 基于分层、区域、过渡和超图方法的嵌套NER比较Table 4 Nested NER comparisons based on hierarchical,region,transition,and hypergraph methods
2.2.6 模型总结
表5 给出了中文嵌套命名实体识别利用深度学习的网络在常用数据集ACE2005 中文、ACE2004 和人民日报上F1-score值的对比分析结果。从表5中不难发现中文嵌套命名实体识别的分数普遍不高,在基于分层模型中金字塔模型在Layered-BiLSTM-CRF 模型的基础上引入边界和注意力模块机制后,在ACE2005上的性能提高了7.17个百分点;Highway-Multihead和Multi-layer+Self-Attention+CRF 在每一层都采用序列标注的方式,虽然在人民日报的数据集上分别达到了91.41%和92.9%的好结果,但是序列标注会带来无法并行训练的和存在层与层之间的错误传播。而基于区域的模型可以避免层层误差传播问题,从表5 中可以看出,区域模型的整体效果比分层模型要好。其中Locate-Label、Extract-Select 和Triaffine+AlBERT 的表现尤为明显,这三个方法大都采用两阶段的方式,在区域方法中设置,相应的边界检索模块,有效地识别到嵌套实体。此外统一扁平和嵌套NER 模型效果也相对较好,比如BERT-MRC 达到了86.88%的F1值。

表5 嵌套模型的F1-score值对比Table 5 Comparison of F1-score values for nested models
基于分层的方法,如Pyramid、BERT+FLAIR 和Highway 等,因为其不考虑层与层之间的相关性,并且当前层的输出结果可能与前层的一部分结果无关,从而在使用先前层结果的输入来引入噪声,从而导致分类器的结果较差。
基于区域的方法,如基于枚举策略的TCSF、Hierarchical等和基于边界策略的Extract-Select、Triaffine 等。基于枚举策略的区域方法通过确定命名实体的起始和结束位置来识别实体,枚举所有可能的嵌套实体来确定嵌套层次,因此能够在一定程度上提高识别的准确性。但是枚举策略需要事先定义好所有的实体类型,因此对于未知的实体类型,则存在负样本多的缺点。对于边界策略的区域方法,充分挖掘区域最优子结构性质,考虑上下文信息,逐步确定实体边界从而确定嵌套层次。因此识别效率相对较高。但是对于边界标注要求较高,如果标注不准确则会影响识别结果的准确性。
基于超图的方法,如BiFlaG、Biaffine 等,因为其通过学习超图结构的性质捕捉是实体类型的共性和差异性,因此在一定程度上可以处理未知实体的问题。但是超图方法需要将所有实体与实体之间的嵌套关系表示为超图,并通过图解算法求最优嵌套关系,因此计算复杂度较高。
其他方法,如BERT-MRC、W2NER 等,基于机器阅读理解的方法通过预训练模型自动学习特征,不需要手动设计特征工程,提高了模型的泛化能力。但是也因此需要大量的训练数据和计算资源,并且该模型通常采用黑盒模式,因此其可解释性较差。
总的来说,现如今利用区域模型的方法和基于机器阅读理解的方式统一地解决扁平和嵌套的中文命名实体识别任务的主要思路。
2.3 中文NER小样本问题处理
由于基于深度学习的NER模型通常需要大规模的标记数据来更好地训练模型。当标签数据不足时,基于深度学习的中文NER模型不能充分发现数据的隐藏特征,从而大大降低了基于深度学习的中文NER 模型的性能。同时,中文NER 的任务主要用于信息专业化的领域,各领域之间的相关性不大,可移植性不高。因此,很难将现有的标签数据和深度学习模型移植到资源贫乏的领域。
针对中文命名实体识别中的小样本问题,可以采取一些方法来缓解针对上述问题,目前主要有以下几种方法:基于迁移学习的方法、基于半监督学习的方法、基于知识蒸馏的方法和基于提示学习的方法。
2.3.1 基于迁移学习的方法
基于迁移学习的方法是通过将已有的大规模数据集中的知识迁移到低资源数据集中,一方面迁移学习根据其对数据和标签依赖性小的优点,放松独立和相同的分布约束使其成为解决资源贫乏的NER 的主要选择。另一方面基于转移学习的NER方法在源域中使用大量的标签数据和预训练模型,能够提高目标域的学习性能,更重要的是它能够将源域模型的部分参数或特征表示迁移到目标域模型,而不需要额外的对齐信息,实现跨域中文NER迁移任务。目前基于深度迁移学习解决低资源的中文命名实体识别的方法可以分为三类:数据迁移的方法、基于模型迁移的方法和基于对抗网络迁移方式。如图16所示展示了迁移学习的原理图。

图16 迁移学习的原理图Fig.16 Schematic diagram of transfer learning
数据迁移的基本思路是将高资源的标注数据通过一些对齐信息(文本翻译和标签映射等)手段转换成低资源的标注数据,然后基于这些数据进行训练CNER模型[89-90]。Akbik 等人[91]提出了一种结合字向量和词向量的迁移学习模型。该模型对称地将低资源数据转换为高资源数据,以提高低注释深度学习模型的性能。Peng等人[92]提出了一种结合有限标记数据迁移学习技术的深度学习模型(TL-NER),可以应用于少量的标签数据和大量的未标记文本数据,完成中文NER的任务。Sheng等人[93]为了提高深度学习方法在实体识别任务中缺乏实体标注标记数据时的性能,减少跨域分词和标签映射中的错误率,提出了结合字符为单词的迁移学习方案。在BiLSTM网络的域中执行特征传递和参数共享任务,实现零资源标注。
模型迁移不需要学习高资源信息的特征,直接在源语言的标注数据上训练CNER,将源模型的部分参数或者特征表示迁移到目标模型上。Yao等人[94]提出了一种基于对称轻量级深度多网络协作(ALBERT-AttBiLSTMCRF)和主动学习的模型迁移(MTAL)的方法,使用主动学习优化迁移模型效果,解决了标记域数据稀缺的问题,比迁移前的效果高出3.55%的改进。多语言BERT(multilingual BERT,mBERT)是一种在大型多语言语料库上进行预训练的语言模型,在zero-shot和跨语言模型传输方面表现上最为出色,Chen等人[95]提出了一种基于注意机制的特征聚合模块,并融于mBERT 中以获取不同层次的信息。在四个zero-shot 跨语言传递数据集上证明了有效性。但是模型迁移可能会出现领域差异过大的问题,微调过程需要重新训练一部分模型,需要大量的计算资源。
对抗网络迁移是受到生成对抗网络(GAN)的启发,学习目标域与源域无关的特征,实现源域知识到目标域的迁移,有效缓解非对抗网络迁移方法带来的负迁移的问题。近年来,随着生成对抗网络(GAN)的兴起,将GAN 引入迁移学习已成为大多数NER 研究者的追求。对于具有少量注释数据的中文NER 任务,可以利用中文分词任务完成注释任务。然而,中文分词既没有保留词的特定信息,也没有利用词的边界信息。针对这一问题,Wen等人[96]提出了一种基于跨域对抗学习(CDAL)的中文命名实体识别方法,构建一个基本预训练的框架单元并对大量未标记数据的迁移学习进行预训练,有效地预测了目标域中的结果提出了一种基于跨域对抗学习(CDAL)的中文命名实体识别方法,构建一个基本预训练的框架单元并对大量未标记数据的迁移学习进行预训练,有效地预测了目标域中的结果。同时该框架可以利用汉语NER和汉语分词中两个任务共享的词边界特征,防止特定信息的丢失。在电子病历领域,Dong等人[97]将多任务BiLSTM模型与迁移学习相结合,提出了一种新的迁移学习模型。该模型从一般领域的汉语语料库中获取潜在知识,并将其应用于NER 中医学术语挖掘任务中。对实际数据集的实验评估结果表明,该方法可以作为一种在有限数据下提高NER性能的解决方案。
Hu等人[98]同时利用来自多个领域(微博和新闻)和多个任务(NER和CWS)的信息构建了一个双重对抗网络。通过不同任务、不同领域的联合训练,学习领域共享信息和任务共享信息。最后,利用共享的信息来提高网络环境在特定领域特定任务中的效果。
2.3.2 基于半监督深度学习的方法
基于半监督深度学习的中文命名实体小样本方法主要通过利用未标记数据和标记数据之间的关系,来提高在小样本情况下的CNER 性能。该方法通过在已有的标记数据上进行训练,学习一个初始模型,然后使用未标记数据进行半监督训练,进一步优化模型。
He 等人[99]提出一个包含跨域学习和半监督学习的统一模型,既可以用跨域学习函数学习域外语料库,又可以通过半监督自我训练学习域内未注释文本,有效地提高了中文社交媒体NER的性能。Chen等人[100]提出了一个鲁棒的半监督NER方法ROSE-NER来解决医学领域噪声数据对CNER 模型的稳健性产生负面影响。作者引入两步半监督模型,用大量预测的伪标记数据扩展少量的标记数据。在医学数据集上的实验表明,该方法减少了对大量标记数据的依赖,实验证明该方法优于其他方法。
为了在半监督环境下有效地融合多模态命名实体识别(MNER)的文本和图像特征,Zhou 等人[101]在半监督设置下利用未标记数据的有用信息,提出了一种新的基于跨度的多模态变分自动编码器(SMVAE)模型。该方法利用特定模态的VAE对文本和图像的潜在特征进行建模,并利用专家产品获取多模态特征。有效地解决了在社交媒体上对命名实体进行注释需要付出大量的人力的问题。Hao 等人[102]将半监督的深度学习于跨领域的迁移学习相结合,提出了一个半监督的框架可转移的NER,其中解除领域不变的潜在变量和领域特定的潜在变量。在所提出的框架中,通过使用领域预测器将领域特定的信息与领域特定的潜变量集成。使用三个互信息正则化项将领域特定和领域不变潜变量进行分离,即最大化领域特定潜变量与原始嵌入之间的互信息,最大化领域不变潜变量与原始嵌入之间的互信息,以及最小化领域特定和领域不变潜变量之间的互信息。
2.3.3 基于知识蒸馏的方法
基于知识蒸馏的小样本学习方法旨在通过使用大型预训练模型(教师模型)的知识来指导小型模型(学生模型)的学习,以提高其在小样本情况下的性能。具体来说,该方法首先使用大量的未标注数据对教师模型进行预训练,然后将教师模型的输出用作学生模型的辅助目标。其常采用的方式包括软标签蒸馏和特征蒸馏。Zhou等人[103]借鉴了知识蒸馏(knowledge distillation,KD)的软标签蒸馏,利用k-best 维特比算法建立替代标签,从教师模式中提取知识。此外为了最大程度地让学生模式吸收知识,提出了一个多粒度精馏方案,该方案综合了条件随机域和模糊学习中的交叉熵。在MSRA、WEIBO、OntoNotes4.0 上分别达到了92.99%、71.62%、76.05%的好成绩。
Wang等人[104]提出了一种提取方法(Distil-AER),将大规模标记的全标准地址数据集中的知识转移到口语对话情景下的细粒度地址实体识别任务中。利用特征蒸馏,将教师模型的隐藏层表示用作学生模型的辅助目标,进而能够更好地捕捉输入的关键特征。
在中文零资源语言中由于源语言和目标语言在特征分布上的差异,教师网络无法有效地学习跨语言共享的独立于语言的知识。学生网络在教师网络获取所有知识的过程中忽略了目标语言特定知识的学习。为了解决以上问题,Ge 等人[105]出了一种无监督原型知识蒸馏网络(ProKD)模型。ProKD 采用基于对比学习的原型对齐方法,通过调整源语言和目标语言中原型之间的距离,提高教师网络获取与语言无关知识的能力,实现类特征对齐。此外,ProKD还引入了一种原型自训练方法,通过利用样本与原型的距离信息重新训练学生网络对目标数据进行学习,从而提高学生网络获取特定语言知识的能力。在生物医学领域内,由于BioBERT[106]规模太大,速度太慢,为此Hu等人[107]提出一种基于知识蒸馏的快速生物医学实体识别模型FastBioNER,FastBioNER使用动态知识精馏对BioBERT模型进行压缩。采用动态权重函数模拟真实的学习行为,调整训练过程中各部分损失函数的重要性。从而将动态知识提取将训练好的BioBERT压缩成一个小的学生模型。
基于知识蒸馏的小样本学习方法相较于半监督学习,不需要额外的未标注数据,可以使用现有的标注数据和预训练模型来进行训练;相较于迁移学习,知识蒸馏可以在不同的任务和数据集上重复使用预训练模型的知识,实现知识的迁移。但是知识蒸馏的性能受到教师模型的影响,如果教师模型质量不好,学生模型的性能也会受到影响,并且如果教师模型的任务和数据集与当前任务和数据集不匹配,可能无法实现良好的迁移。更重要的是知识蒸馏的训练过程比传统的训练过程要复杂,需要调整很多参数,需要花费更多的时间和精力。
2.3.4 基于提示学习的方法
提示学习是一种不需要改变预训练语言模型结构和参数,通过改造下游任务、增加提示信息和专家知识,使任务输入和输出适合原始语言模型的一种方式,从而在零样本或少样本的场景中获得良好的任务效果。近年来有很多学者利用提示学习的新思路去解决英文小样本NER 的问题,比如在2021 年Cui 等人[108]提出了一种基于模板的NER模型,使用BART模板枚举文本跨度并考虑每个文本的生成概率,在手动制作的模板中输入。该方法证明了提示学习可以有效解决英文小样本NER 的问题。基于模板提示的方法需要枚举所有可能的候选实体,存在较高的计算复杂度问题,因此,Ma 等人[109]提出一种在小样本场景下无模板构建的提示方法,该方法采用预训练任务中的单词预测范式,将NER 任务转化成将实体位置的词预测为标签词的任务。该方法能减少预训练和微调之间的差距并且解码速度比基线方法快1 930.12倍。
在中文少镜头(Few-shot)或零镜头(Zero-shot)数据集上实现良好的性能一直是CNER面临的挑战。为此,Lai 等人[110]提出基于提示学习的父母和孩子的BERT(PCBERT),在中文的小样本NER 中取得的优异的效果。该方法在源数据集上训练注释模型,在低资源数据集上搜索隐式标签。同时设计标签扩展策略来实现高资源数据集的标签传输。在微博等中文数据集上证明了提示学习在中文少镜头学习中的有效性。Huang 等人[111]结合距离度量学习测量对象语义相似度方法和提示学习的模板,提出了对比学习与提示指导的少镜头NER(COPNER)。该方法引入提示组成的类别特定的词COPNER 作为监督信号进行对比学习,以优化实体令牌表示。Kan 等人[112]为了提高数据稀缺场景中事件抽取的泛化能力,提出了新的可组合的基于提示的生成框架。该框架将信息抽取任务转化为确定提示语语义一致性的任务,并重新制定在预先设计的特定类型提示中填充空格的形式。实验证明了,在数据丰富和数据稀缺的情况下,该方法优于中午数据集上的比较基线。此外,Huang等人[113]提出了基于提示性的自我训练两阶段的框架。该框架在第一阶段,引入了一种自我训练的方法,通过提示信息调整来提高模型的性能,以减轻噪声伪标签的错误传播。在第二阶段,针对高置信度伪标签和原始标签对BERT 模型进行了微调。在五个标签的OntoNotes5.0数据集上达到了73.46%成绩。总的来说,提示学习在低资源场景的CNER 任务上得到了初步尝试,未来会有更多复杂的方法来增强提示,并应用于低资源场景下的许多任务中。
在小样本问题上,基于迁移学习方法、基于半监督深度学习、基于知识蒸馏的方法和基于提示学习的方法这四种方法进行了比较分析,具体如表6所示。

表6 CNER小样本问题处理方法比较Table 6 Comparison of CNER small sample problem processing methods
3 数据集与评估标准
本章将介绍在中文命名实体识别中常用的数据集,以及评估标准。
3.1 数据集
数据集在模型性能评估环节中举足轻重的地位,尤其是经过高质量标注的数据集。
表7 列举了8 个CNER 中常用的数据集,并从其类型、实体类型、文本来源等进行说明。这些数据集的来源广泛,有常用的学术基准公开数据集,例如MSRA、WEIBO、RESUME、OntoNotes;有私有数据集适用于特定领域,比如公司提供的BosonNLP中文语料库和电子商务领域的E-commerce NER。此外还有用于竞赛的数据,但是竞赛数据是不对外公开的,需要报名参赛才能获取,比如常用于医疗竞赛的数据CCKS2020和CHIP2020。

表7 常见中文命名实体识别数据集列表Table 7 LIST of common Chinese named entity recognition datasets
MSRA[114]:微软注的新闻领域的实体识别数据集。包含5万多条中文实体识别标注数据,实体类别分为人名(Person)、位置(Location)和组织(Organization)三类实体。
WEIBO[115]:根据新浪微博2013 年11 月至2014 年12 月间历史数据筛选过滤生成。包含1 890 条微博消息,实体类别分为人名(Person)、位置(Location)、组织(Organization)和地区名(GPE)四类实体。
RESUME:根据新浪财经网上市公司的高级经理人的简历摘要数据筛选过滤和人工标注生成的。该数据集包含1 027份简历摘要,实体类别分为人名(Person)、国籍(Country)、位置(Location)、种族(Race)、专业(Profession)、学位(Education)、机构(Organization)、职称(Title)8个类别。
OntoNotes Release 5.0[116]:根据大型手工注释语料库得来。有五个版本从1.0~5.0,包含实体类别分别为人名(Person)、位置(Location)和组织(Organization)等18个实体类型。
CLUENER2020[117]:根据清华大学开源的文本分类数据集THUCNEWS筛选过滤、实体标注生成。该数据集包含实体类别分别为组织(Organization)、人名(Person)、地址(Address)、公司(Company)、政府(Government)、书籍(Book)、游戏(Game)、电影(Movie)、职位(Position)、景点(Scene)10个实体类别,且实体类别分布较为均衡,并且有望在未来成为通用的CNER数据集。
E-commerce NER[118]:人工标注的电商领域数据集。包括品牌(Brand)和产品(Product)两种类型实体。数据集规模较小,数据质量较低。
BosonNLP:根据公司提供得数据标注而来。包含组织(Organization)、人名(Person)、位置(Location)、公司(Company)、产品(Product)、时间(Time)六类实体。
People’s Daily:根据人民日报、新闻稿筛选标注而来。包含组织(Organization)、人名(Person)、政治(Geo-political)、日期(Date)四类实体。
有许多不同的注释模式可以用于不同的数据集。一般来说,常用的注释方法有BIO、BIOES、BMEWO等。目前,BIOES是最常用的命名实体注释模式。在一些实体密集的地区,选择BIOES模式可以更好地识别这些实体。注释系统越复杂,精度越高,但相应的训练时间增加。因此,应该根据实际情况选择适当的注释系统。
3.2 评估标准
在CNER 任务中 常用精确匹配的模式进行评估,只有同时识别到正确的实体边界和类型,实体才能被判定是被正确识别。同时该任务通常采用F1 值来评估模型性能计算公式如(1)~(3),TP(true positives)、FP(false positives)以及FN(false negatives),用这三个参数来计算Precision、Recall和F1-score。Precision精确率指模型识别实体中被正确识别的实体的百分比;Recall召回率,指所有标注实体中被模型正确识别的实体的概率。
4 未来展望
基于深度学习的方法被广泛地应用在命名实体识别中,但是由于中文语言的特殊性,比如语义歧义、词边界不明确、语义结构复杂等,使得建模技术仍需进一步提高。除此之外,中文语言的复杂性使得其语料库较大,同时存在各式语言表达方式,比如词语的缩写、同音词等,因此如何将这些多样化信息进行数据表示是CNER的重要挑战。为此,该领域的未来发展方向在以下几个方向。
(1)数据表示
根据具体任务使用不同的字符表征,在字符表征中引入更多的外部特征。对于有规则实体的任务,可以引入基于规则的词汇信息和词性信息;对于有许多新实体的任务,可以引入基于字符特征的信息,如字形信息、笔画信息、拼音信息和部首信息等。
引入跨语言信息从而加强数据表示。如将汉语翻译成英语,然后识别英语中的实体,最后将这些实体重新翻译成汉语。例如,Wu 等人[119]提出了一种师生学习方法,其中源语言中的NER模型被用作教师,在目标语言中的未标记数据上训练学生模型。该方法解决了现有跨语言NER方法在源语言中的标记数据不可用或与目标语言中的未标记数据不对应时不适用的局限性。这样,公共知识就可以从一种语言转移到另一种语言,而不需要成对语料库。
引入高质量的数据集,高质量的数据集对于模型学习和评估是必不可少的。与ENER数据集的相比,CNER数据集在质量和数量上仍显不足。开展嵌套CNER、细粒度CNER或命名实体消歧的研究,首先要解决这些任务缺乏高质量数据集的问题。Ding提出的Night-Nerd,这是一个大规模的人工注释的少镜头NER 数据集,具有8 个粗粒度和66 个细粒度实体类型的层次结构。弱监督和无监督学习由于语料库标注的人力成本较高,因此开发弱监督和无监督算法来实现基于少标注或无标注语料库的CNER具有重要意义。
(2)建模技术
建立更有效的模型,虽然最近的工作引入了大量的外部信息,取得了很好的效果,但在现有的模型框架下,CNER的性能遇到了瓶颈。通过设计更有效的模型,可以更好地利用外部信息。比如,引入多模态网络架构,通过多模态CNER 网络融合文本信息和视觉信息和语音信息,利用关联图像更好地识别文本中包含的具有多义词的命名实体。利用语音发音信息可以将具有歧义的信息规避掉,比如“长江(chang)”和“市长(zhang)”。此外,Li等人为NER提出了统一的MRC框架。该模型把NER看作一个序列标记问题,而是把它描述成一个机器阅读理解(MRC)任务,并用SOTA 模型获得了竞争结果。该方法是对更好模型的有效尝试。
(3)分类器
标记解码器使用编码的上下文信息来预测令牌的标记,是NER 模型的最后阶段。目前有两种主要的实现形式分别是将序列标注任务将转换为多类分类任务的MLP+Softmax和对标记序列内部依赖关系进行建模的CRF。此外,可针对标注方案中存在的数据稀疏和错误传播问题,采用多任务学习范式的多标注学习方法[120]。该方法分别标注实体及其对应的实体类型的分割信息,对原有的PLE模型进行了改进,将不同的标注序列作为不同的任务来缓解这些问题。该方法是对更好的分类效果的有效尝试。
5 结束语
本文从中文命名实体识别的难点和分类角度出发,回顾了中文命名实体识别的研究背景、传统方式和近几年来的研究成果。本文整合了常见的中文命名实体识别数据集和评估标准。其次进行分类别的介绍在解决中文命名实体识别难点的详细方法,并做出了性能比较分析。目前的中文命名实体识别在解决嵌套实体和低资源的实体识别效果不佳。未来研究可以针对数据集的自动标注、细粒度的识别、提升模型鲁棒性和轻量级等方向进行探究。
