基于Python的多维度、层次化的综合实验平台
2023-12-26王成喜张春飞籍风磊
梁 楠,王成喜,张春飞,徐 涛,籍风磊
(1.吉林大学 a.公共计算机教学与研究中心; b.通信工程学院,长春 130012;2.一汽大众汽车有限公司 采购部,长春 130013)
0 引 言
Python是具有很强的可移植性语言[1],提供了丰富的标准库,广泛应用于数据处理、人工智能、游戏开发等领域。由于Python功能丰富且易学易用,目前各专业都在积极探索使用Python工具实现相关科学研究的数据处理、数据分析、计算视觉和人工智能等方法。“新工科”背景下开展多学科交叉融合,科研与教学融合,是培养适应未来社会需求的复合型人才和提高教学质量的重要途径[2-3]。吴汤婷等[4]针对卫星导航定位实验教学中的手动下载数据模式操作繁琐、耗时长和易出错等问题,基于Python语言开发了数据下载软件,提升了实验教学质量。杨俊秀等[5]通过在高频电子线路实验中引入Python对数据进行处理,辅助学生和老师高速处理数据,将Python数据处理功能应用于实验教学中。张玉荣等[6]利用Python和OpenCV库处理小麦籽粒图像,将Python联合计算视觉应用于农业方面。李益兰等[7]研究了Python在税务审计中数据处理和分析的方案,表明Python在抓取税务数据、数据分析及可视化处理等方面都有积极效果。
笔者结合我校工科专业人才培养的差异化需求,设计针对不同专业的多维度、层次化的综合创新实验平台。平台投入教学,助力科教融合课程培养体系建设,培养学生的科研兴趣,提升学生就业的竞争力。
1 平台架构设计
该平台的实验项目由图像识别、机器学习及数据分析3部分组成。平台整体设计框架如图1所示。其中,图像识别实验由文字、人脸和车辆识别3个模块构成; 机器学习实验由K临近(KNN:K-Nearest Neighbor)、支持向量机(SVM:Support Vector Machine)、朴素贝叶斯(NB:Naïve Bayes)、决策树(DTC:Decision Tree Classifier)4个模块构成; 数据分析实验由工作量计算和生物信息数据处理两个模块构成。学生根据专业方向和科研项目需求,通过用户界面选择任意模块开展实验。该平台基于Python的图形用户界面(GUI:Graphical User Interface)库Tkinter模块开发的用户界面如图2所示。

图1 实验平台整体架构
图像识别模块设计遵从循序渐进原则。文字识别模块首先采用少量代码实现简单的文字识别功能以激发学生的编程兴趣,接着采用多种方式实现人脸识别,为算法移植到硬件系统打下基础; 针对交通和汽车等相关专业,设计车牌检测和识别实验。
机器学习模块采用常用机器学习算法,包括:KNN、SVM、NB、DTC。针对农学相关专业,该模块设计了机器学习识别玉米病害的实验,并比较不同算法的识别性能。
数据分析模块设计基于Python的Excel处理及分析实验。实验根据学生专业设置不同的基础数据类型。商学、管理学等专业采用教学工作量的数据进行实验,生命科学等专业采用生物信息数据进行实验。
2 平台模块设计
2.1 图像识别实验模块
2.1.1 文字识别模块
光学文字识别(OCR:Optical Character Recognition)结合光学和计算机技术检测像素的亮暗,将字符转换成图像文件,再利用识别工具将字符的图像转换成文字[8]。Tesseract是目前公认的具备精确性和灵活性的开源OCR系统[9],本实验模块利用pytesseract(Python中的Tesseract接口),采用5行代码实现图片中的文字识别,代码如下:
from PIL import Image #PIL是Python图像处理标准库
import pytesseract # pytesseract是Python Tesseract接口
image=Image.open(‘Zen of Python.png’) #读取图片
word=pytesseract.image_to_string(image) #识别图片中文字
print(word) #显示出文字
2.1.2 人脸识别模块
人脸识别模块基于开源计算机视觉库OpenCV实现,OpenCV支持先进的图像处理技术且应用范围很广,可显著提高处理效率,支持跨平台处理,降低编程成本[10-11]。人脸识别和检测相辅相成,因为在人脸识别前需要判断当前图像内是否有人脸出现,这个过程是通过人脸检测实现的。因此该模块先向学生介绍人脸检测,再进行人脸识别实验。
基于OpenCV提供的级联分类器Cascade Classifier,利用特征文件进行人脸检测。同时为增加实验趣味性,提供戴眼镜特效的例子。实验平台提供了多项OpenCV级联分类器文件,学生可根据自己的需求和兴趣,进行眼睛检测、笑容检测、车牌检测和猫脸检测等实验功能。
在人脸检测后,实验平台提供不同算法进行人脸识别实验,分别为:Eigen Faces、Fisher Faces和局部二进制模式直方图(LBPH:Local Binary Pattern Histograms)。学生可将自己感兴趣的人脸图像作为输入训练算法,并自己调整参数测试识别效果。
2.1.3 车牌识别模块
车牌识别结合车牌检测和文字识别两个步骤进行。首先基于OpenCV进行车牌区域检测,通过高斯模糊、图像灰度化、边缘检测、形态学处理和中值滤波等操作,将车牌提取后,再结合文字识别功能对车牌进行识别,也可将实验结果与OpenCV中训练好的分类器进行车牌识别的结果进行比较。通过实验使学生更好地理解图像处理中各操作实现的效果,明确图像识别过程的基本流程。并结合前面学习过的文字识别实验,可以更好地巩固已学知识。
2.2 机器学习实验模块
机器学习实验从常用算法的原理部分开始,基于Python的开源机器学习库sklearn进行代码实现。sklearn集合多种机器学习算法,可快速建立各类模型。为使学生能从更直观的角度认识到机器学习算法在实际生产生活中的应用前景,该模块实验以机器学习算法在玉米病害识别中的应用为例,展示各算法的实现过程及分析应用的效果差异。
KNN通过记忆训练过的数据集完成学习判别,根据k个临近样本信息判断测试样本信息[12]。调用方法为from sklearn.neighbors import KNeighborsClassifier。SVM通过寻找超平面区分不同类别的样本[13],具有优秀的泛化能力。sklearn支持不同的支持向量机类,如表1所示。NB是基于概率论的算法,对所有已知类别,假设属性相互独立[14]。对待分类项,通过计算先验概率和条件概率进行决策。sklearn中提供了不同的朴素贝叶斯类,如表2所示。DTC相比于其他算法,可解释性更优[15]。基于训练集的特征,DTC模型通过学习一系列问题判断样本的分类标签,从树根开始,在信息增益最大的节点上分类数据,各子节点在迭代过程重复该分裂过程,直到只剩下叶子为止。Python中调用方法为from sklearn.tree import DecisionTreeClassifier。

表1 Sklearn中的支持向量机类

表2 Sklearn中的朴素贝叶斯类
2.3 数据分析实验模块
数据分析实验从Python提高Excel数据处理效率为切入点,按照数据处理的流程设计数据读取、清洗、分析及展示等实验过程。涉及的Python功能模块包括:xlrd、xlsxwriter、pandas、numpy、matplotlib、seaborn等。
为使实验模块功能与学生日常学习工作和科研相结合,本模块实验以工作量计算和生物信息数据处理和分析为例,为学生展示日常工作及科研中用到的常见功能。在工作量计算模块中,通过数据读取和分析计算后,以指定格式的表格作为输出,并对输出结果进行统计和分析。在生物信息数据处理的实验中,通过癌症基因组图谱数据库下载实际的公开核糖核酸(RNA:Ribonucleic Acid)及临床数据等,利用Python进行分析后,生成科研常用的火山图、热图和箱线图等。
3 平台测试结果
3.1 图像识别实验模块
3.1.1 文字识别实验
以截取的Python之禅的图片为例进行文字识别,通过该实验激发学生对Python工具的兴趣,了解Python作为编程工具的便捷性,如图3所示。
3.1.2 人脸识别实验
在实验之初,以戴眼镜特效的例子激发学生兴趣。读入图片后,基于级联分类器利用特征文件进行人脸检测,调用方式为:cv2.CascadeClassifier(“haarcascade_frontalface_default.xml”)。读取眼镜图片,并根据人脸区域和尺寸调整眼镜覆盖区域和尺寸,最终生成如图4所示的效果。

图4 人脸检测后实现戴眼镜特效的图片
实验平台提供Eigen Faces、Fisher Faces、LBPH 3种方式进行人脸识别。笔者以LBPH为例展示识别效果。利用recognizer=cv2.face.LBPHFaceRecognizer_create创建特征脸识别器,读取训练图片后,利用recognizer.train()训练识别器,读取测试图片,利用label,confidence=recognizer.predict()识别图片中人脸。label为返回的标签值,confidence为返回的可信度,表示未知人脸和模型中已知人脸之间的距离,0表示完全匹配,低于5 000可认为是可靠的匹配结果。图5a即为模型输入的训练图片,图5b为测试图片及返回的模型识别可信度和标签值。
3.1.3 车牌识别实验
在本模块中,通过实验结果直观地展示在图像识别过程中常用的处理方法对图像处理效果,包括高斯模糊、灰度化、Sobel算子边缘检测、二值化、腐蚀、膨胀和中值滤波等,从而将车牌区域截取出来,如图6a所示。检测到车牌后,再对其进行灰度化、二值化和形态学处理等,从而生成便于识别的图像形式,最终采用pytesseract.image_to_string将截取的车牌图片进行识别后,显示出车牌识别结果,如图6b所示。

图6 车牌识别实验输入及输出结果
3.2 机器学习实验模块
机器学习模块以KNN算法为例展示实验结果。玉米病害数据集取自2018AIchallenger植物病害程度图片数据集中玉米病害的部分,其中分类0表示健康玉米,分类1表示玉米灰斑病,分类2表示玉米锈病,分类3表示玉米叶斑病,分类4表示玉米花叶病毒病,分类图片如图7a所示。通过sklearn.model_selection中的train_test_split将数据集中30%选为测试集,训练集图片数量为2 147张,测试集图片数量为921张。将图像读取并转换为像素直方图存储在数组中,构建分类模型,使用训练集训练模型,评估模型得分,使用数据测试并显示分类结果。图7b为从分类2数据集中抽取图片测试,模型预测结果也为分类2。

图7 玉米病害识别实验输入及输出结果
3.3 数据分析实验模块
3.3.1 工作量计算实验
该实验目的是使学生熟悉Python中xlsxwriter、pandas、numpy等模块在Excel数据处理中的使用。程序处理的原始文件为Excel表格,共分为两个Sheet。其中Sheet1为收集到的工作人员的相关工作信息,包括课程名称、学时和授课人数等信息。Sheet2中为工作人员的基本信息,处理重复值、缺失值及空格值后,依照实验要求对原始数据进行折算。运行程序后,生成工作量明细的Excel文件和工作量合计表的Excel文件。对明细中的每项数据,都是依据实验规定的参数和公式计算,并且有相应的数据折算前的来源标注在表中,依据明细计算的情况生成工作量合计表,如图8所示。
3.3.2 生物信息数据分析实验
该实验模块提供下载于癌症基因组图谱数据库的公开数据供学生实验使用。将实际科研中常用的数据用于学生的实验中,使学生能更好地将所学知识应用于后续科研工作中。本部分以差异基因的火山图为例展示实验结果。将部分RNA-Seq文件利用Python程序xlsxwriter及pandas模块合并后,对重复值、空白值进行处理后,提取差异基因,计算差异倍数(log FC)和差异的P值,在P值<0.05的前提下log FC>1标记为上调,log FC<-1的标记为下调,利用seaborn模块生成火山图,如图9所示。
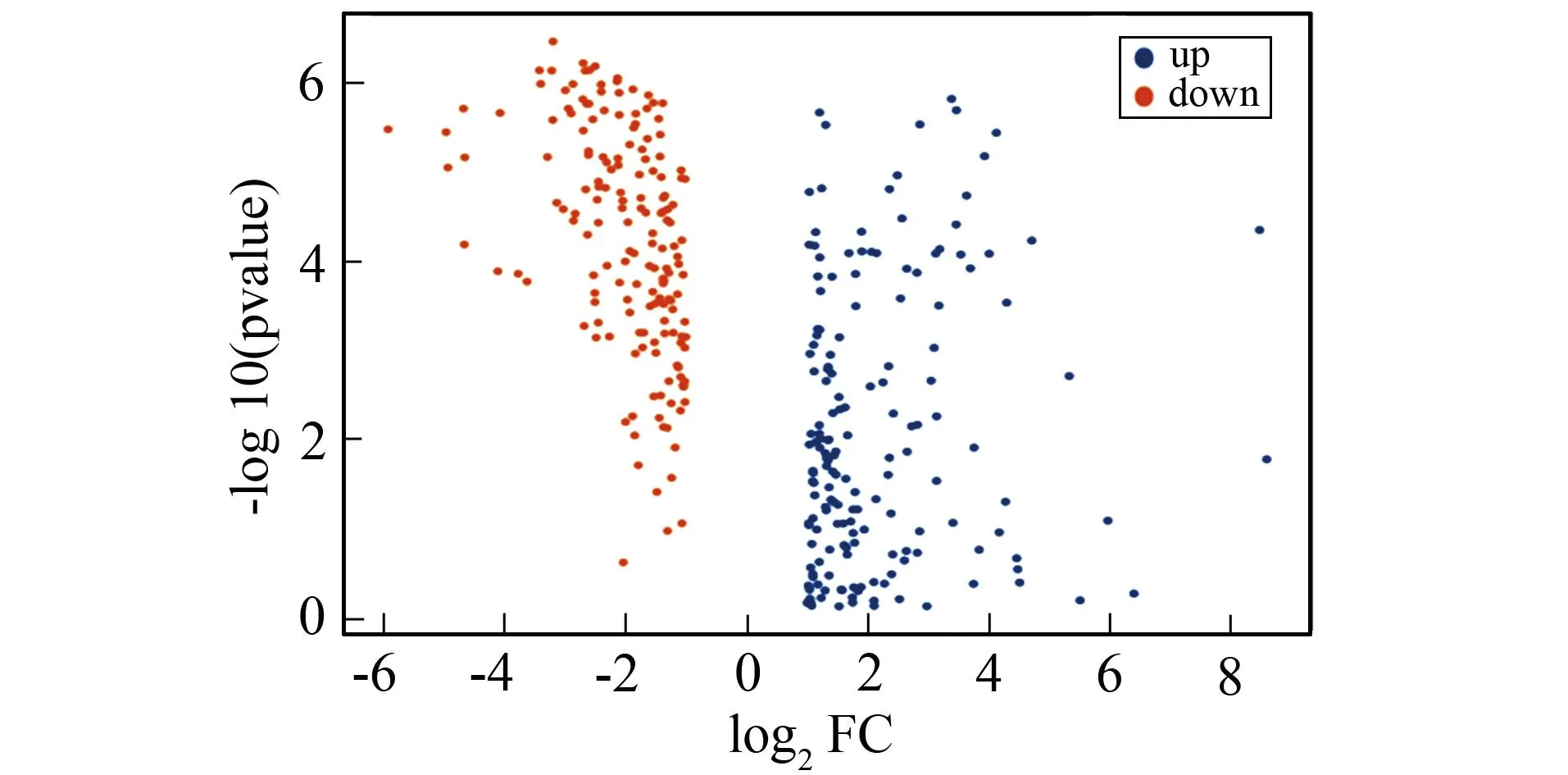
图9 差异基因火山图
4 结 语
笔者提出的基于Python的综合实验平台已在开放性创新实验中应用,面向多个专业的学生。学生通过学习本实验课程,对Python在图像识别、机器学习以及数据分析的编程实现有深入的了解和掌握。同时,根据专业方向和科研项目需求,自主选择实验模块,真正实现了差异化教学,因材施教,从而实现将科研融入教学,提高本科生教学质量的目标。
