基于星载被动微波的中国东北森林雪深反演
2023-12-26李王波范昕桐顾玲嘉
李王波,范昕桐,顾玲嘉
(吉林大学 电子科学与工程学院,长春 130012)
0 引 言
由于积雪在冬季森林生态系统水分循环和能量流动过程中占有重要地位[1],因此对森林地区积雪特性及其动态变化的监测非常重要。而传统人工观测和站点自动化定点观测数据难以满足较大区域尺度的积雪参数研究需求,所以卫星遥感技术成为监测积雪及其时空变化的有效方法。其中,被动微波遥感是目前反演积雪参数的最有效技术手段[2]。目前国际上发射的星载被动微波传感器主要包括美国SMMR(Scanning Multichannel Microwave Radiometer)和SSM/I(Special Sensor Microwave Radiometer)数据、日本AMSR-E(The Advanced Microwave Scanning Radiometer for EOS)和AMSR-2(The Advanced Microwave Scanning Radiometer 2)数据、中国FY-3B卫星MWRI(Microwave Radiation Image)数据[3-4]等。笔者使用MWRI被动微波数据。
在被动微波雪深反演领域,目前已有相应的物理模型和半经验算法。物理模型以辐射传输理论为基础,考虑了雪层内粒子的微观结构对辐射的影响,描述了积雪微波辐射的物理特性[2]。然而在其应用过程中,需要较多的输入参数且有些很难通过观测实验获得,因此限制了其使用范围。相比物理模型,半经验算法不仅操作简便,而且在算法运用过程中也不需要输入较多参数,因此基于半经验算法的雪深反演算法是目前被动微波雪深反演领域最常用方法。1987年Chang等[5]发现被动微波19 GHz和37 GHz两个波段水平极化数据的亮温差值和地表雪深之间存在较强的关系,以此为基础建立了经典的半经验雪深反演Chang算法。该算法是基于SMMR数据建立的,因此使用其他卫星传感器的数据时会产生一定的误差。基于Chang算法,学者们开展了基于被动微波亮温差的半经验雪深反演算法的研究,如美国国家冰雪数据中心的全球积雪时间序列数据集就是以Chang算法为基础制作的。针对Chang算法在森林地区雪深反演结果精度较低的问题,1997年Foster[6]在Chang算法的基础上加入了森林覆盖度参数,并对Chang算法中的半经验系数进行了拟合修正,建立了Foster雪深反演算法。由于国外学者建立的半经验雪深反演算法所用数据均采用国外实验实测数据,因此在国内适用性较低,雪深反演结果具有很大误差。考虑到中国地区积雪分布及特性,2008年Che[7]根据中国实际的积雪地面调查数据,对Foster算法进行了参数本地化处理,提出了Che雪深反演算法,并制作了中国雪深长时间序列数据集,填补了国内相关领域的空白。2019年,Jiang等[8]在Che雪深反演算法的基础上,结合中国东北地区的积雪环境特性和实测雪深数据,进一步修正了Che雪深反演算法的半经验雪深反演系数,建立了适用于中国东北地区雪深反演的Yang雪深反演算法。笔者在中国东北森林地区气象站观测数据的基础上,综合考虑影响森林雪深反演精度的森林覆盖度、气温等关键因素,提出了一种适用于中国东北森林地区的半经验雪深反演算法。实验结果表明,与其他半经验雪深反演算法和经典的机器学习方法相比,笔者提出的雪深反演算法在东北森林地区具有更好的适用性和更高的准确度。
1 研究区域和数据
1.1 研究区域
笔者研究地区为中国东北地区,经纬度范围从北纬38°43′延伸到北纬53°33′,从东经115°44′延伸到东经135°05′。东北地区横跨中温带与寒温带,冬季寒冷漫长,是我国典型季节性积雪区之一。此外,东北地区地形地势复杂,区域内北部为小兴安岭地区,南部为广袤的东北平原,西部为大兴安岭地区,东部为长白山山地,中部以平原为主。东北森林地区集中分布在吉林省和黑龙江省,如图1所示。

图1 东北地区地表覆盖分类图
东北地区地形地势复杂,以平原、丘陵和山地为主,植被茂密,地物复杂。区域内北部为小兴安岭地区,南部为广袤的东北平原,西部为大兴安岭地区,东部为长白山山地。东北地区临近蒙古高原,由于冬季蒙古高原高纬度、高海拔和高气压等因素的影响,每年东北地区都会受到来自这里冷空气的影响,因此在一定程度上影响了东北地区的冬季气候,使冬季气温低、风速快、风级大。东北森林主要集中分布在吉林省和黑龙江省,有多种类型的阔叶林和针叶林,且林区冠层郁闭度极高,茂密的植被和较高的森林覆盖率延长了冰雪消融时间。
1.2 研究数据
1) 风云三号卫星微波辐射计数据。风云3号B卫星发射于2010年11月5日,其上搭载有多个传感器,包括可见光红外扫描辐射计(VIRR:Visible and Infrared Radiometer),MERSI(Middle Resolution Imaging Spectrometer),MWRI(微波辐射计)等。FY-3B微波辐射计(MWRI)有5个频率(10.65 GHz、18.7 GHz、23.8 GHz、36.5 GHz和89 GHz)和10个波段,每个波段有水平和垂直极化模式,可提供10 km空间分辨率的亮温数据,主要用于探测土壤湿度、海水温度、冰雪覆盖等信息,MWRI传感器的参数如表1所示。风云卫星数据可由风云卫星遥感数据服务网(http:∥satellite.nsmc.org.cn/portalsite/default.aspx)下载。

表1 FY-3B MWRI传感器参数
2) 中分辨率成像光谱仪数据。森林覆盖度数据由中分辨率成像光谱仪的三级数据MCD12Q1地表覆盖类型产品计算得到,空间分辨率为500 m。MODIS相关数据和产品均可由美国国家航空航天网站(https:∥ladsweb.modaps.eosdis.nasa.gov/)下载。该产品共提供5种不同分类方案,笔者所用分类方案为IGBP(International Geosphere-Biosphere Proqramme)全球植被分类方案[9]。按照IGBP分类方案分别制作了东北地区地物分类图(见图1,空间分辨率500 m)和森林覆盖度分布图(见图2,空间分辨率10 km)。

图2 东北地区森林覆盖度分布图
3) 森林气象站数据。笔者所用地面观测数据为2013年-2018年(每年11月-次年3月)东北地区5个森林气象站(新林、图里河、伊春、漠河、塔河)数据,其空间分布如图1所示。数据包括观测站名称、时间、地理位置(经纬度)、海拔高度、雪深、雪密度、雪温和雪温等,共有2 500余组数据。气象站观测资料可由中国气象数据网(http:∥data.cma.cn/)下载。
2 研究方法
2.1 半经验雪深反演算法
积雪微波辐射特性受多种因素影响,包括雪的温度、密度、粒径和下垫面类型等。积雪特征参数精准测量的难度较高且难以在大范围上获取,从而限制了物理模型在雪深反演中的应用。半经验雪深反演算法操作简便且在算法运用过程中也不需要输入较多难以获取的参数,是目前被动微波雪深反演领域最常用方法。
1) Chang算法。该算法利用19 GHz和37 GHz的水平极化亮温差和雪深成正比关系、建立了代表性半经验雪深反演Chang算法,所用数据为美国雨云7号卫星的SMMR,但该算法仅适用于雪深不超过1 m的情况。当雪深超过1 m后会出现亮温饱和; 当雪深低于2.5 cm时将定义为无雪情况。
Schang=1.59(T19h-T37h),
(1)
其中Schang表示雪深;T19h表示19 Ghz水平极化数据;T37h表示37 Ghz水平极化数据; 经验系数1.59是在雪粒径为0.3 mm,雪密度为0.3 g/cm3的情况下拟合得到的。
2) Foster算法。在Chang算法的基础上,Foster[6]结合森林参数的影响,加入了森林覆盖度参数对Chang算法进行了优化。
SFoster=0.78(T19h-T37h)/(1-fforest),
(2)
其中SFoster表示雪深;fforest表示森林覆盖度。0.78为该算法针对欧亚大陆所拟合的经验系数值。但当某个地区森林覆盖度过高时,Foster算法就会由于分母1-fforest趋于0而导致算法失效。
3) Che算法。由于Chang算法和Foster算法建立所需的地面实测数据均不在中国大陆,且Foster算法在森林覆盖度过高时算法会失效。针对该情况,Che[7]基于大量中国野外积雪测试数据,对Foster算法中参数进行了修正和优化,主要调整了亮温差的经验系数和森林覆盖度系数,如下:
SChe=0.72(T19h-T37h)/(1-0.5fforest),
(3)
其中Che算法中亮温差经验系数调整为0.72,森林覆盖度fforest系数调整为0.5。相比Chang算法和Foster算法,Che算法更适用于中国地区的雪深反演,对森林地区的雪深反演也有较好反演结果。
4) Yang算法。该算法利用东北地区野外实测数据对Foster算法进行了本地化处理,是一种更适用于东北区域的半经验雪深反演算法[8]。如下:
SYang=0.38(T19h-T37h)/(1-0.7fforest),
(4)
其中Yang算法对经验系数和森林参数fforest系数进行了修正和优化,亮温差经验系数调整为0.38,森林覆盖度fforest系数调整为0.7。
2.2 机器学习算法
在森林地区,影响被动微波反演结果的有多种因素,如森林覆盖度,森林植被透过率,植被材积量,风速和温度等。这些复杂的因素都会影响雪深反演结果,因此被动微波的亮温数据和森林积雪深度数据之间并不是单纯的线性关系。近年来,机器学习方法被用于描述积雪深度与被动微波数据、其他地表参数的非线性函数关系。
1) 决策树与随机森林。决策树是一种基本的机器学习工具,是树形图的形式,由一些分支和节点组成。决策树通过自上而下的方式,根据不同分类规则对数据样本划分的逻辑方式进行计算,由于这种划分方式的图形形状很像一棵树的枝干,因此该算法被称为决策树[10]。决策树算法具有数据准备流程简单,耗费资源量小,易于学习,便于使用等优点。随机森林就是由多个决策树组成的分类器[11]。因此决策树算法所具有的优点同样可以在随机森林中体现,在保证学习速度的基础上,随机森林还可以处理更多的数据,获得更准确的分类结果。如Yang[12]等利用随机森林算法构建了考虑多因素影响的雪深反演算法并取得了精度较高的反演结果。
2) 遗传算法[13]。是一种通过模拟达尔文生物进化论的自然进化搜索最优解算法,该算法采用概率化的寻优方法,不需要确定的规则就可以自适应地调整搜索方向。并且可在处理复杂的优化问题中获得很好的结果,并且在机器学习、模型建立优化等方面得到了很大的应用[14]。针对森林地区雪深反演中存在的参数多、关系复杂的问题,有人使用遗传算法进行了雪深反演并且得到了较好的反演结果[15]。
3) 梯度提升回归树[16]。是一种boosting集成学习算法,该算法由多棵决策树组成。GBRT是连续进行造树,同时每棵树之间提升的梯度较小,这就让梯度提升回归树算法在进行预测时占用更少的内存且具备更快的速度。梯度提升回归树算法是最强大的监督学习算法之一,也是最为常用的机器学习算法之一,该算法可以防止过拟合,且算法适用于任何场景。凭借这些优势,梯度提升回归树算法在积雪信息提取领域尤其是雪深反演方面得到了相关应用[17]。
2.3 东北森林地区半经验雪深反演优化算法
基于目前代表性的半经验雪深反演算法(Foster算法,Che算法 和Yang算法),森林地区的半经验雪深反演公式如下:
S=A(T19h-T37h)/(1-Bfforest),
(5)
其中A表示模型半经验系数,B表示森林覆盖半经验系数; 基于东北森林地区气象站点数据(2013年-2018年共2 500余组数据),笔者选用2/3气象站点数据对A和B两个半经验系数进行了优化和拟合,从而得到东北森林地区的半经验雪深反演优化算法,另外1/3气象站点数据则用于验证雪深反演结果。
1) 森林覆盖度半经验系数B的选取:由于国内外众多学者在该参数的选择上均在0.5~0.7的范围,因此本研究计算了当B从0.5~0.7变化时,雪深反演结果和气象站点观测数据的相关性。相关性用相关系数R表示,R值越大则相关性越高。笔者分别针对A和B两个半经验系数进行了优化和拟合,从而得到新的适用于东北森林地区的反演算法。
① 森林覆盖度系数B的选取:研究随机计算了从0.5~0.7变化范围内算法反演结果和实测雪深数据的相关性。R计算如下:
(6)
其中yi表示反演雪深,xi表示实测雪深,m表示数据个数。由图3可见在东北森林地区,当森林覆盖度系数B=0.5时,反演雪深和实测雪深的相关性最高,随着系数B逐渐增大,两者的相关性逐渐降低。因此在笔者算法中选择了和Che算法相同的森林覆盖度系数,即B的值为0.5。
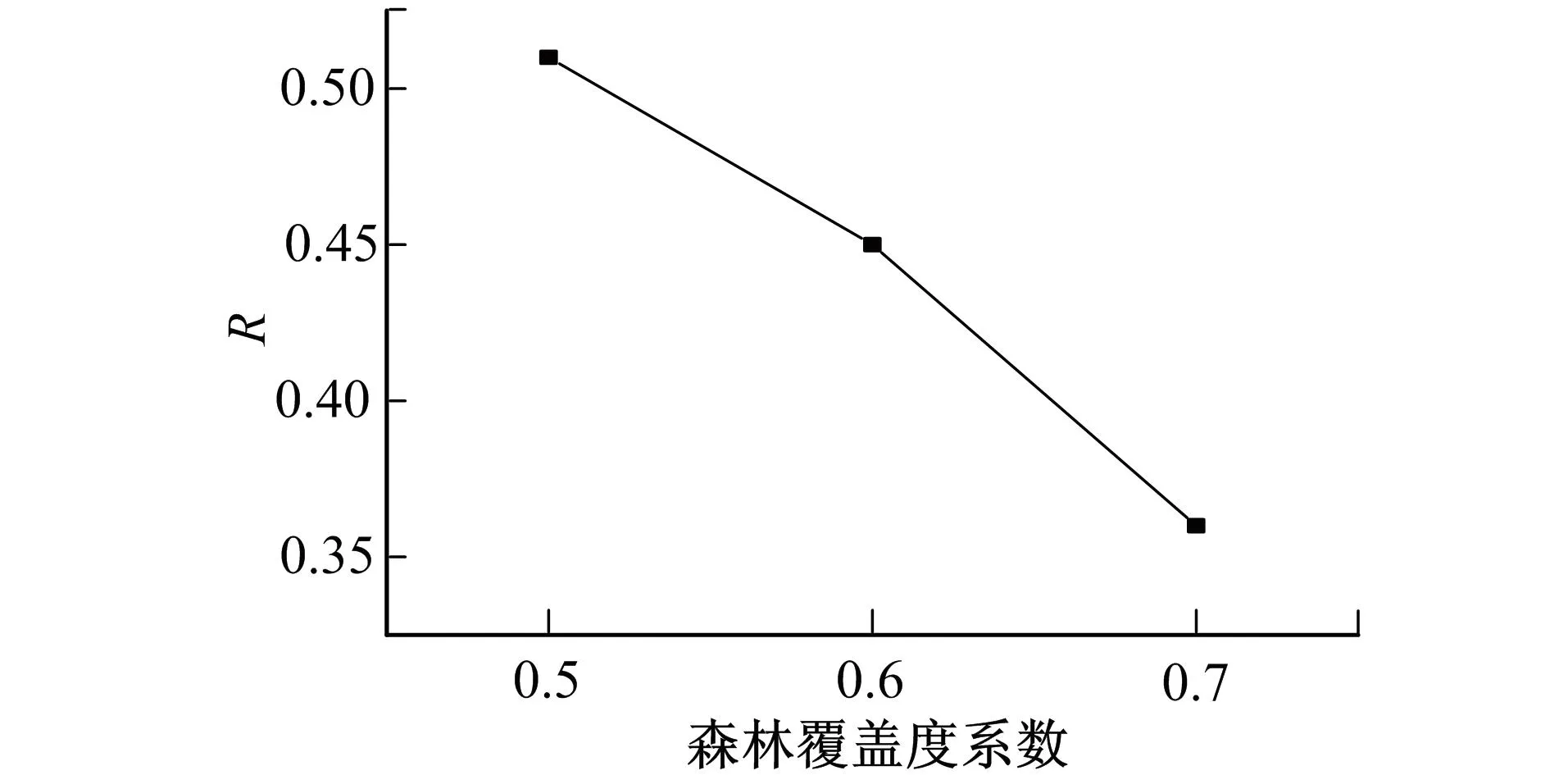
图3 森林覆盖度系数B与雪深相关性分析
② 亮温差半经验系数A的选取。目前雪深反演算法对亮温差半经验系数A都选用固定值。通常,气温会对积雪的冻融状态产生影响,而积雪的冻融状态会使积雪的电介质特性发生变化,从而影响到积雪的辐射特性。同时,气温还会对森林中的植被产生影响,随着气温的降低,植被内结合水和自由水的比例随之升高,从而影响到森林植被的辐射特性[18]。因此,笔者将森林气象站观测气温数据引入亮温差半经验系数A拟合中。东北森林地区半经验雪深反演优化算法如下:
S=(0.234Tair(T19h-T37h))/(1-0.5fforest),
(7)
其中Tair表示气温数据(10-2·K); 0.234是东北森林地区气象站观测数据拟合得到的半经验参数。
2.4 评价指标
评价雪深反演误差和精度的评价指标包括均方根误差RRMSE、相关系数R、偏差BBias3种指标。相关系数R如式(6)所示,另两种指标如下:
(8)
(9)
其中m表示数据个数,yi表示反演雪深,xi表示实测雪深。用笔者提出的算法分别和代表性半经验雪深反演算法、机器学习雪深反演算法进行对比和分析。
3 结果分析
3.1 半经验雪深反演算法结果对比
将笔者提出的算法与其他代表性半经验雪深反演算法在东北森林地区的雪深反演结果进行比较,并使用森林气象站点地面观测雪深数据进行误差分析,分析结果如图4所示。由于研究所选取的实验区域为东北茂密森林地区,森林覆盖度普遍比较高,从而造成Foster算法反演结果误差过大,因此没有将算法反演结果和Foster算法进行比较。从图4可看出,4种半经验雪深反演算法中,笔者提出的优化算法RMSE和Bias最小,相关性R最高。Yang算法雪深反演误差是其他3种算法中最小的,和笔者算法相比RMSE平均高1.3 cm,Bias平均高1.8 cm,R平均低0.06。Che算法和笔者提出算法相比,RMSE平均高2.1 cm,Bias平均高3.4 cm,R平均低0.07。Chang算法的精度最低,和笔者提出算法相比RMSE平均要高4.8 cm,Bias平均高7.7 cm,R平均低0.12。研究结果表明,在东北森林地区,笔者提出的半经验雪深反演优化算法的适用性更强,反演结果更准确,同时也表明了气温变化对于森林地区雪深反演精度有重要影响。

图4 半经验反演算法误差分析
3.2 半经验雪深反演优化算法与机器学习算法结果对比
将笔者提出的半经验雪深反演优化算法和2.2节中的机器学习算法进行了雪深反演对比,计算Bias、RMSE和相关系数R等评价参数。在使用机器学习算法进行雪深反演时,研究将所有气象站点观测数据3等分,其中2/3数据作为训练数据,剩余的1/3数据作为验证数据。最终得到的精度分析结果如图5所示。由图5可见,笔者所建立算法的RMSE和Bias最小,相关性最高。机器学习算法中,误差最小的是随机森林算法,和笔者算法相比RMSE高了1.7 cm,Bias高了1.5 cm,R低了0.13; 误差最大的是梯度提升回归树算法,和笔者算法相比RMSE高了2.8 cm,Bias高了1.9 cm,R低了0.32。
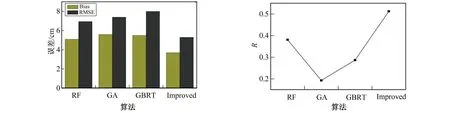
图5 机器学习算法误差分析
3.3 东北地区雪深反演结果
笔者选择2014年1月11日冬季被动微波遥感数据作为实验数据,采用笔者算法和其他算法对该日期的研究地区雪深进行反演,各方法雪深反演结果如图6所示。图6a是MODIS卫星的MOD09A1光学数据无云产品(空间分辨率500 m),白色区域为积雪覆盖区域。由于光学遥感影像无法观测到森林下的积雪情况,研究地区东部和北部的森林地区光学影像为深色。由图6b可见,Chang算法雪深反演结果中雪深最大值可达到77 cm,明显高于正常雪深值。图6c是Foster算法雪深反演结果,当森林覆盖度过高时,根据式(2)Foster算法反演的分母会趋近于0,这就会导致得到该方法雪深反演结果很高,也反映出了Foster算法不适用于东北森林地区。为方便观察,将图6c中雪深最大值设置为50 cm,雪深超过50 cm的区域按50 cm展示,雪深较深的地区基本为东部和北部地区。由图6d~图6f可见,笔者提出算法在积雪覆盖区域和雪深与Yang算法和Che算法结果都比较相近,且雪深反演范围在Yang和Che之间。
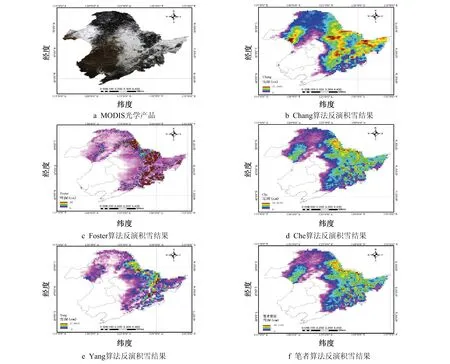
图6 雪深反演结果
4 结 语
笔者在代表性半经验雪深反演算法的基础上,考虑了森林植被介电常数随气温变化的特性,结合森林气象站点观测数据建立了适用于东北森林地区的半经验雪深反演优化算法。实验结果表明与其他代表性半经验算法相比,笔者算法的RMSE平均减小了2.3 cm,Bias平均减小了3.7 cm,R平均提升了0.11。笔者还将所建立算法与常用的机器学习雪深反演算法进行对比,结果表明笔者算法的RMSE平均减小了2.17 cm,Bias平均减小了1.67 cm,R平均提升了0.22。研究结果表明,在东北森林地区,笔者提出的半经验雪深反演优化算法的适用性更强,反演结果更准确,同时也表明了气温变化对于森林地区雪深反演精度有重要影响。
