PCIe 总线DMA 高速传输系统的设计与实现
2023-12-25刘佳宁刘金鹏
刘佳宁,单 伟,刘金鹏
(中国电子科技集团公司第五十八研究所,江苏 无锡 214035)
0 引言
随着信息技术的不断发展,通信系统对数据传输带宽的要求也越来越高。作为系统内部数据交互的桥梁,IO 总线是决定整个系统传输带宽和处理性能的关键[1]。
传统的第二代IO 总线以PCI 和PCI-X 总线为代表,其特点是时钟频率较低,数据总线并行传输,在传输速度和硬件成本等方面制约了PCI 总线的整体带宽[2],且由于总线共享,单一外设无法长时间占用总线,进一步限制了总的传输速率[3]。新兴的第三代IO 总线PCI Express(PCIe)总线解决了上述问题。PCIe 总线采用点到点串行差分结构,所有外设设备通过独立通道实现互联[4],因此所有外设单独使用总线通道的所有带宽,且各设备间可以并发传输互不影响[5],因此系统的整体性能得到有效提升,解决了高速数据传输的吞吐量问题。在现代通信领域,PCIe 总线的使用前景十分广阔。
本文设计了一种基于PCIe 总线架构的高速数据传输系统,考虑到PCIe 协议的复杂性,可以使用协议芯片简化设计[6],本文则使用Xilinx 官方提供的软核作为PHY 模块实现PCIe 链路层协议,同时利用FPGA 丰富的逻辑资源和缓存资源设计顶层应用模块,完成PCIe 协议包的收发,实现 PCIe 板卡的完整协议。最后联合上层软件控制程序和底层驱动构成完整的闭环传输测试系统,为同类型数据传输系统的工程应用提供了设计参考。
1 总体方案
1.1 系统总体设计
基于PCIe 总线架构的高速数据传输系统由上位机的PCIe 根控制器(Root Complex,RC)和底层PCIe 终端设备(Endpoint,EP)构成最小闭环系统,实现PCIe 总线的接口通信和数据交互。系统总体设计如图1 所示。
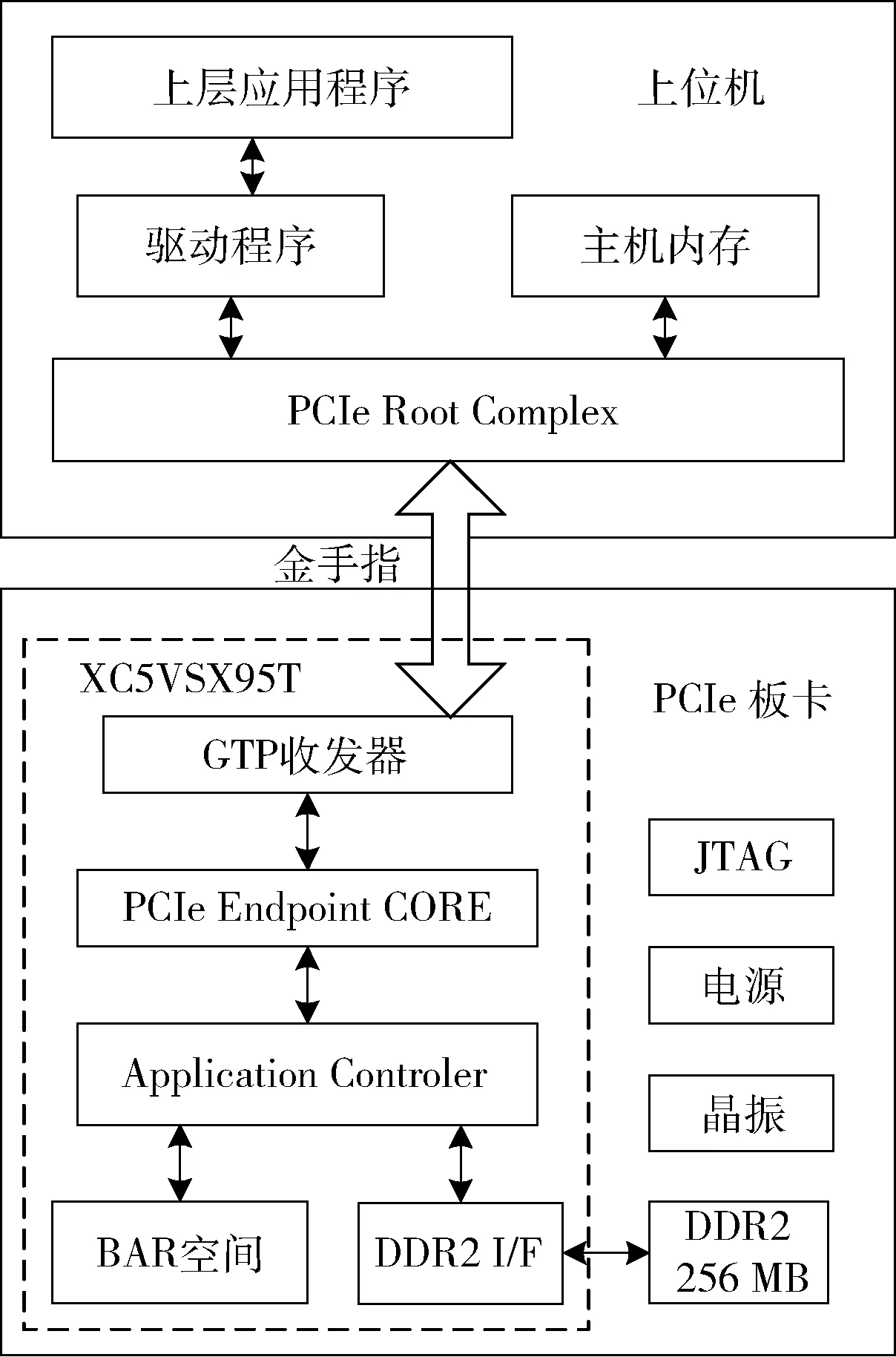
图1 系统总体示意图
1.2 系统硬件设计
系统硬件由上位机和底层PCIe 板卡两部分组成。上位机是数据传输系统的主设备,负责指令发送、状态监测和负载数据的传输。其中,根控制器是上位机PCIe总线的核心控制设备,负责支持外围所有PCIe 总线终端设备、交换设备和桥接设备的路由。通过开发相应的驱动程序可以实现上层应用与终端设备的数据交互[7]。本文对此部分不做详细描述。
底层PCIe 板卡作为终端设备EP,是本文的工作重点和设计关键。根据PCIe 协议规范,PCIe 总线采用点对点的串行通信方式,因此数据的传输是基于协议分层机制,PCIe 协议分层如图2 所示,各协议层根据规范封装数据后发送,接收则解析数据[8]。

图2 PCIe 协议分层示意图
PCIe 终端设备以FPGA 为控制核心,FPGA 选用Xilinx 公司的XC5VSX95T,使用FPGA 内部集成的RocketIO GTP 高速收发器实现PCIe 总线物理层协议,调用Endpoint Block Core 实现数据链路层协议[9],使用可编程逻辑资源实现传输层协议,同时外部设计256 MB DDR2 满足其高速缓存需求,完成终端设备PCIe 接口的所有功能需求。
1.3 总体逻辑设计
终端设备的逻辑设计主要包括PCIe 传输层协议的实现和与之匹配的DDR2 接口应用。根据传输数据量的不同,传输层有PIO(Programmed Input/Output)操作和DMA(Direct Memory Access)操作两种模式。PIO 是一种传统的数据传输方式,其特点是每次传输都需要CPU 直接参与IO 端口指令控制,且传输量一般为一个或两个DW(Double Word),一般适用于寄存器读写。DMA 是一种外部设备与内存直接进行数据交互的接口技术,不需要CPU 参与控制,因此不占用CPU 资源,适用于大容量数据传输,缺点是实时性能较差,CPU 只能通过中断方式参与控制。
本文采用PIO 与DMA 组合的复合控制模式实现传输层协议,PIO 控制逻辑负责基于BAR 空间的上位机指令字的接收和状态字的发送,DMA 控制器负责大容量数据负载的DMA 传输、DDR 接口通信和PCIe 事务维护。这种复合控制模式既能满足传输系统数据吞吐量的要求,也可以实时响应上位机的控制指令和状态更新,相比于纯DMA 控制的PCIe 传输模式,本设计更加灵活高效。总体逻辑设计如图3 所示。

图3 总体逻辑设计框图
PCIe 协议规范中规定了多种类型的传输事务,为了简化设计,本文只使用三类最基本的存储器事务实现数据传送的设计目的:存储器写(MWr),存储器读(MRd)和回应包(Cpld)。根据数据传输方向的不同实现基于BAR 空间读写的PIO 操作和基于DDR2 存储器读写的DMA 操作。总线事务类型描述及分配情况如表1 所示。

表1 总线事务类型分配表
2 指令控制模块设计
PCIe 板卡作为Endpoint 终端设备,需要实时准确接收上位机的控制指令并执行相应的操作。因此,指令控制模块的设计首先要考虑通信的准确性和实时性要求。
基于BAR 空间读写的PIO 总线操作模式需要CPU的全程参与,且请求长度为1,因此其实时性可以得到保证,此外,对关键指令采用单地址和字节指令组合判断的方式保证终端设备指令的可靠识别,提升系统的稳定性和可靠性。
PCIe 板卡的指令控制流程如图4 所示,首先指令空间在固定地址接收上位机的DMA 操作参数,包括源端地址、末端地址和操作长度,然后接收DMA 启动指令“0XF00F”,执行模块完成本次DMA 传输任务后,启动中断模块,上位机收到中断后,执行中断处理程序,清除指令空间中的中断完成标志,完成一次完整的DMA 读写流程[10]。应用程序可根据需求重复执行,或在中断处理程序中增加状态监测指令,监测本次DMA 的传输速度或者错误情况,直到完成上位机与PCIe 板卡的所有数据交互任务。
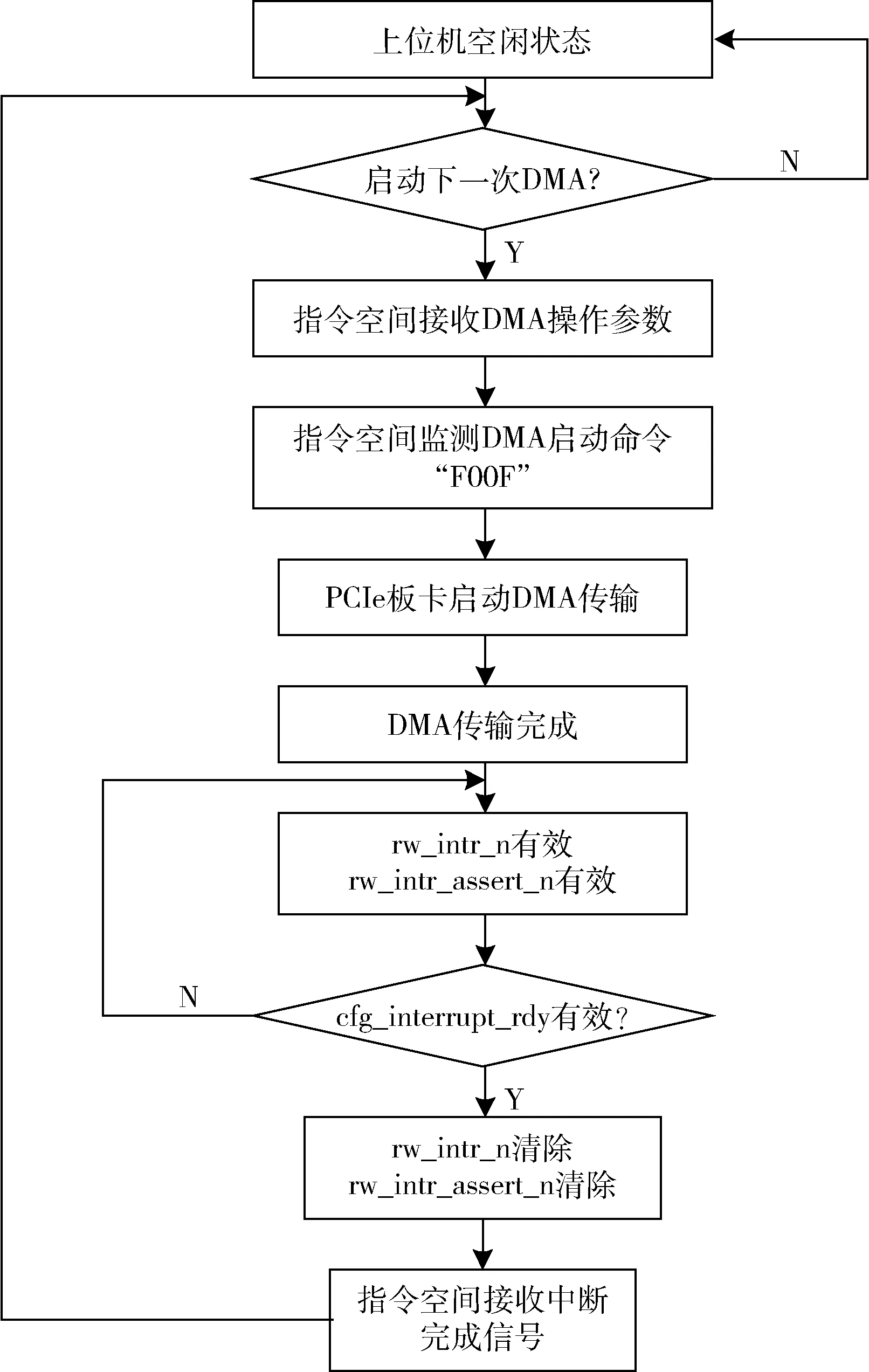
图4 指令控制流程图
3 数据传输模块设计
大容量数据负载的DMA 传输是本文的设计重点,主要完成Endpoint 的传输层协议,包括TLP 传输包的组包和解包,传输长度管理和应答超时检测等功能。
3.1 DMA 控制模块
DMA 控制模块是实现Bus Master DMA 功能的核心模块,在发起DMA 传输事务前,需要配置DMA 传输的各项参数以保证DMA 事务的合法,其中一项重要内容就是传输长度的管理[11]。
根据PCIe 协议规范,数据的传输长度不超过4 KB,根据上位机的最大负载长度MPS(Max_Payload_Size)和最大请求长度MRRS(Max_Read_Request_Size)两个参数的限制,本设计中最大负载长度确定为128 B。另外,由于上位机操作系统是基于页(page)的内存管理,为方便内存的管理和存储,DMA 的读写操作要避免内存地址溢出4 KB 地址边界。
本文设计了一种两段式切片的长度裁剪机制实现以上规则。第一段为粗切,第二段为细切,粗切旨在针对超过4 KB 的长度请求,每次提取4 KB 的最大长度启动DMA 传输,如果剩余长度小于4 KB,则依次裁剪为2 KB、1 KB、512 B,256 B 和128 B。细切则是对每一次的DMA 传输请求,继续裁剪为不超过128 B 的请求长度,保证每个TLP 的长度合法,且需要保证每次请求不能溢出上位机内存的4 KB 边界,如果溢出,则需要对此次请求继续裁剪,将128 B 的请求长度分两次发送。这种两次裁剪的设计思想,逻辑设计简单且易于维护,工程实用性强。设计流程如图5 所示。
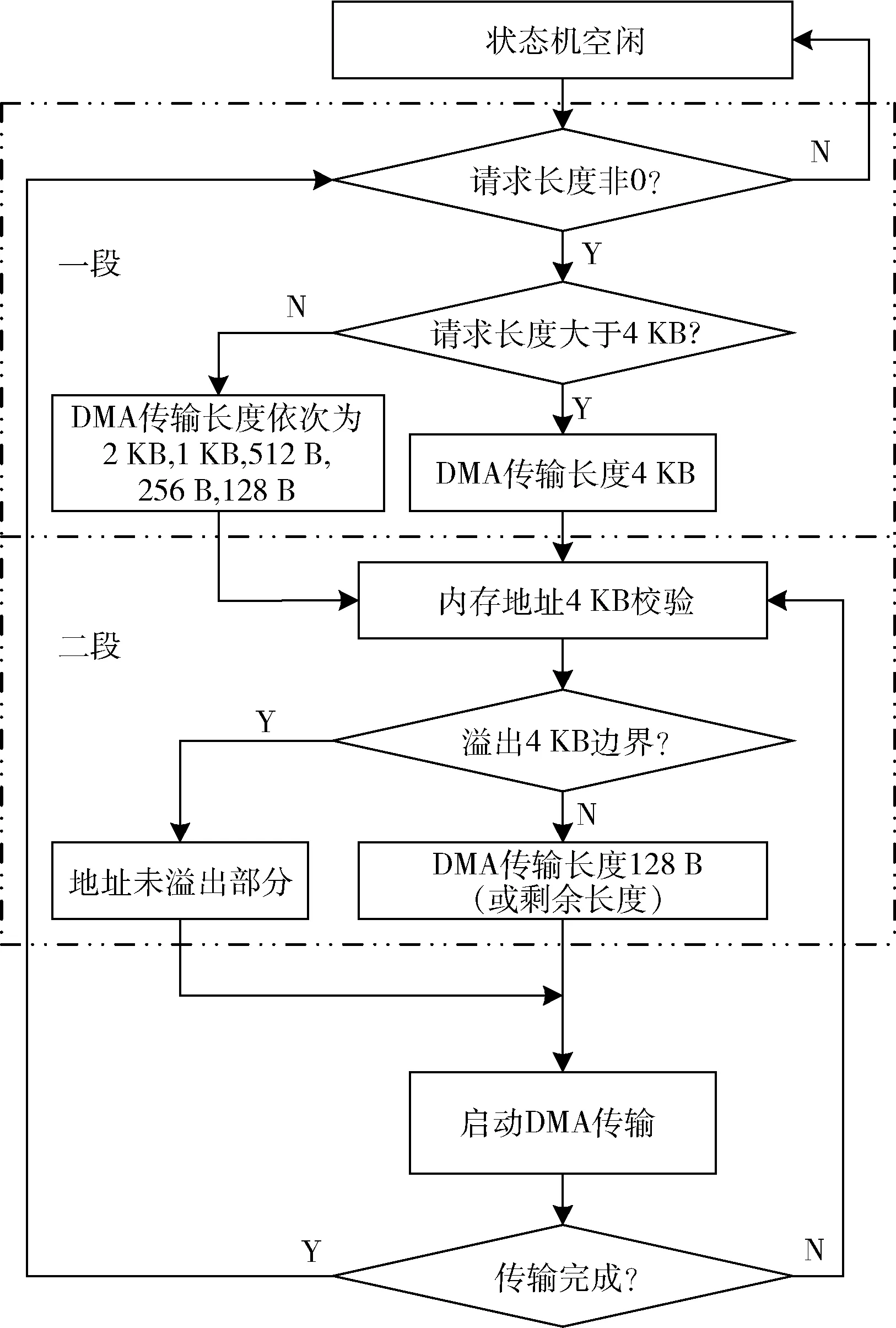
图5 两段式长度切片流程图
3.2 数据发送模块
由于PCIe 支持全双工通信和多事务并发传输,数据发送模块除了负责各TLP 事务的组包任务外,还需要仲裁各TLP 事务的发送优先级。本文使用FIFO 分别缓存各TLP 事务的包头数据,以FIFO 的空信号(empty)确定发送请求,根据仲裁结果启动发送进程,发送模块状态转移图如图6 所示。
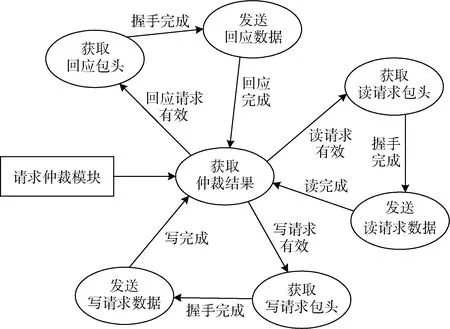
图6 发送状态转移图
请求仲裁模块根据使用背景确定仲裁机制,各事务包头FIFO 非空表示请求有效,进入仲裁队列,输出的仲裁结果随即启动发送状态机[12]。本文中,回应事务的优先级最高,读写请求优先级次之,读写请求轮询优先级。
各TLP 事务在发送包头时,需要完成两次握手协议,PCIe 核的握手保证TLP 数据进入链路层后没有溢出,DDR 的握手保证TLP 写请求在组包期间DDR 数据流不会中断[13]。
3.3 数据接收模块
数据接收模块主要对上位机的控制指令和DMA 回应负载进行解包解析,并实时更新指令空间。由于PCIe协议的多事务并发特性,负载数据的接收要解决PCIe 回应乱序问题,以及RC 设备回应数据时引入的RCB 边界分包的问题。
传统的解决方案是设计一种回应数据重新排序方法,以传输层事务的TAG 为标号,本地划分固定大小的数据缓存空间,接收到的回应数据根据TAG 信息确定对应的存储空间,实现数据重新排序[14]。这种方式会占用大量的RAM 空间,且降低了数据的传输效率。
本文设计了一种实时管理请求回应的方法,每次发送读请求事务时,在读请求RAM 表中以TAG 标号为地址,存储该读请求的长度和地址信息。接收回应数据并解包后,根据TAG 获取当前回应数据的存储地址后发起DDR 写操作,并实时计算更新RAM 空间,保证RCB 边界分包的顺序存储。同时,每个读请求对应唯一的TAG标号,TAG 长度决定了并发读请求的数量,如果所有TAG 标号的读请求均未完成,则无法发起新的读请求。这种伴随回应数据的接收实时更新回应请求、实时发起DDR 写操作的数据接收方式不仅有效解决了RCB 边界分包和PCIe 乱序问题,而且占用RAM 资源极少,保证了数据传输效率。
4 结果验证与分析
本文采用时钟计数的方法统计了全双工模式下X1通道在不同DMA 传输长度下的读写速率,并使用Chip-Scope 工具对DMA 读写的关键时序信号进行采样,分析影响读写速率的原因。
根据协议规范,传输带宽的理论极限为256 MB/s,有效带宽约为80%,实际测试的读写速度与理论值有一定差异,根据表2 的测试结果,1 MB 长度下写操作有效带宽达到75%,读操作达到60%。

表2 DMA 读写速率测试结果
对于DMA 写操作,EP 设备将负载数据从DDR 中读出,经发送模块送入IP 核,因此限制带宽的因素主要是DDR 数据的读取延迟、信号传输延时和PCIe 链路层流控buffer 的credits 握手延迟,当EP 端耗尽credits 后,流控机制会取消传输层使能信号rdy。根据实际测试结果,对于小于1 KB 长度的传输请求,由于没有credits 约束,DMA写速度甚至能超过理论极限的256 MB/s。对于DMA 读操作,EP 端设备需要发送读请求后接收RC 设备的回应数据,包括数据在RC 设备内存的读取和传输,因此主要的带宽限制因素为请求往返的系统传输延迟[15]。
以4 KB 长度为例,DMA 写操作时序如图7 所示。T1 区间有大约400 ns 的启动时间,其中DDR 数据的读延迟约200 ns,62.5 MHz 低速时钟导致的信号传输延迟200 ns,后续DDR 读取速度远超PCIe 的链路速度,因此这个启动延迟仅出现在第一拍。T2 区间由于传输层缓存buffer 中credits 较大,吞吐速度达到最大,credits 耗尽后进入T3 区间,流控机制介入并插入等待状态完成剩余数据的传输。DMA 读操作时序如图8 所示,T1 区间在请求发送时产生大约2 000 ns 的请求往返系统传输延迟,T2 区间回应数据的接收受RC 端数据处理能力制约。
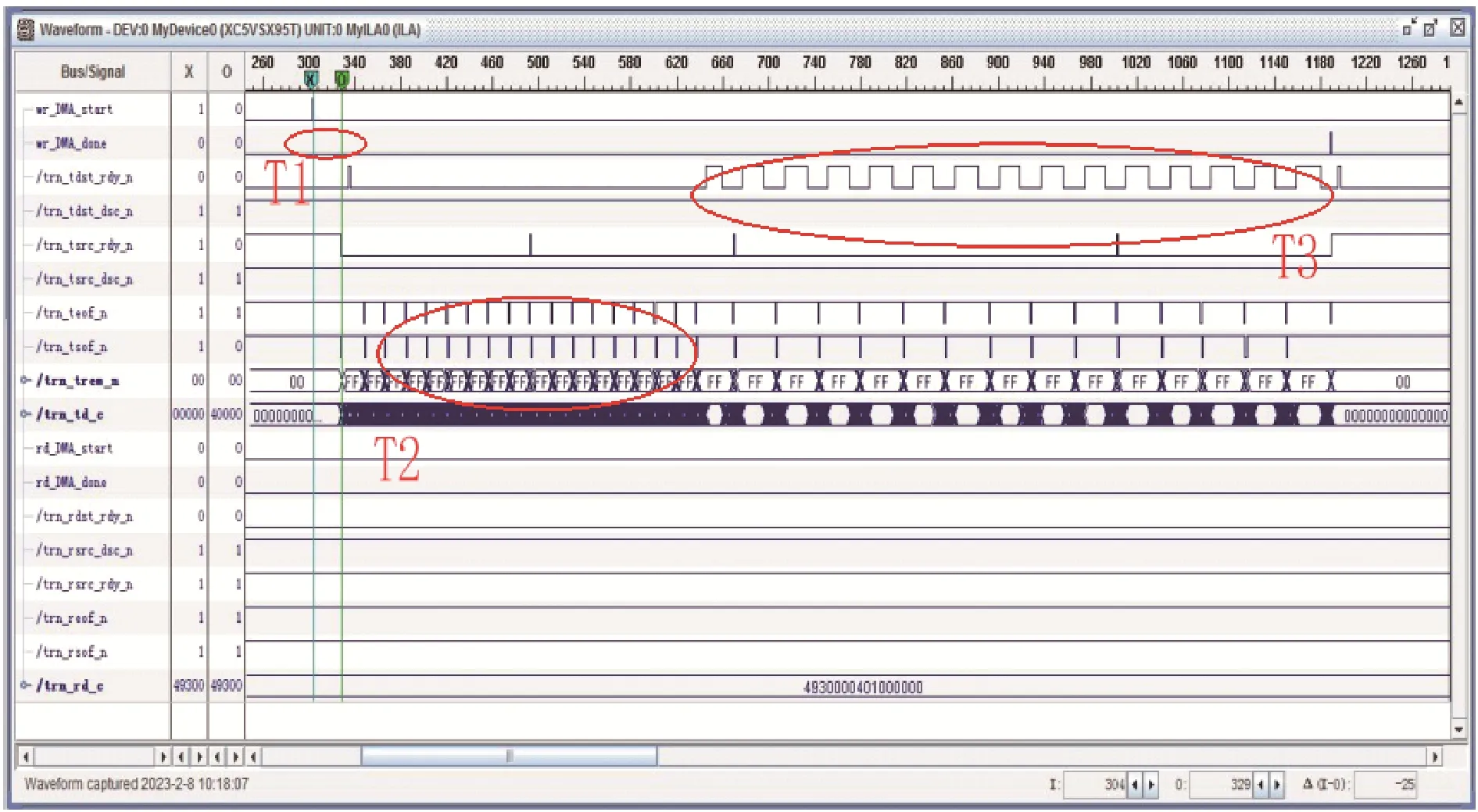
图7 4 KB 长度DMA 写操作时序示意图

图8 4 KB 长度DMA 读操作时序示意图
5 结论
本文针对总线带宽受限的问题,设计了一种PCIe 总线的DMA 数据传输系统,并进行了闭环测试。以FPGA为控制核心,采用PIO 与DMA 组合的复合控制方法实现传输层协议,设计了DMA 控制模块和收发模块实现数据的DMA 全双工传输通道。验证阶段,通过时钟计数的方法对DMA 读写速度进行了测试,最后分析了影响读写速度的因素,为DMA 传输系统的设计改进提供了思路。
