神经网络对Z 地区石油产能进行预测
2023-12-25杨雨希谭成仟潘景宇郑晓梅付雨萱
杨雨希,谭成仟,李 航,侯 斌,潘景宇,郑晓梅,付雨萱
(1.西安石油大学地球科学与工程学院,陕西西安 710065;2.陕西省油气成藏地质学重点实验室,陕西西安 710065;3.中国石油长庆油田分公司第八采油厂,陕西西安 710016)
致密油已成为全球石油地质领域研究的一大热点,然而致密油聚集条件和聚集机理与常规油藏明显不同,加上地质、开发、工程等诸多因素影响[1-2],使得致密油水平井开发存在产量递减快、单井产能差、采出程度低等问题。对致密油水平井产能预测成为非常规油气田开发规划与部署的重要依据。通过机器学习对油井产能预测的研究已成为领域研究趋势[3-7],但是对于油井初期产能预测的研究贡献较少[8],本文将研究神经网络对初期产能的预测。通过对致密油水平井相关资料分析出哪些因素会影响初期产能。使用DNN 模型进行预测。实例证明,该方法可以对致密油水平井的初期产能进行很好的预测。
1 深层神经网络
深层神经网络已经成为机器学习社区开发的主流策略。深层神经网络作为多层无监督神经网络,具有多个非线性映射的特征变换,可以对高度复杂的函数进行拟合。
函数f(x) 初始公式采用以下形式:
式中:w-随机初始化权重;b-偏置。
模型隐藏层的激活函数采用sigmoid:
初始化线性函数之后模型开始前向传播(图1):

图1 深层神经网络模型
通过进行前向传播,模型可以获得预测值。为了衡量预测值和真实值之间的差异,以W 和b 作为变量构建损失函数。本研究选择均方误差(MSE)方法作为模型的损失函数:
2 数据集
2.1 数据来源
本文的资料为Z 地区Z183 油藏长7 段,位于鄂尔多斯盆地的南部,主要为致密油藏。整体是以深湖-半深湖沉积为主的沉积环境,平均孔隙度仅为6.68%,主要集中在2%~10%,渗透率集中在0.05~0.20 mD。储层多以岩屑长石砂岩、长石岩屑砂岩为主,总体上Z地区具有高石英、低长石的特点[9]。自2013 年开始建产至今,已开发水平井数量97 口,累计产油57.8 t,形成了以压裂水平井为主体的致密油藏开发技术[10]。
2.2 数据分析
实验选用Z183 油藏25 口井相关资料,整理得出13 个影响因素。通过分析将这13 个因素分为3 大类。其中地质因素包括视储能系数、渗透率、脆性指数;开发因素包括井距、水平段长、裂缝密度、返排率、返排时间、生产压差;工程因素包括用液强度、加砂强度、砂比、总排量;影响致密油水平井初期产能因素数量众多。为了避免某些因素对产能预测产生负相关影响,导致模型的准确率降低。通过热力图分析每个因素对水平井初期产能相关系数的强弱,筛选出影响初期产能具有正相关性的影响因素,为模型建立最优解(图2)。
由图2 可以看出,有8 个特征和初产水平有紧密的关系,那么数值筛选可以筛选出这8 个因素作为模型的输入。
3 建立预测模型
3.1 模型建立
通过上节的数据分析,其中地质因素包括视储能系数、脆性指数;开发因素包括井距、水平段长、裂缝密度;工程因素包括用液强度、加砂强度、总排量。提取8个相关因素。实验将20 口井共160 个数据用于训练,5口井共40 个数据用于测试。输入神经元设为8 个影响产能的因素,隐藏层设为5 层,通过DNN 模型来进行训练(公式1,公式3~6)。激活函数采用sigmoid(公式2),损失函数采用MSE(公式7)。
由于筛选过后的模型参数数量依然很多,因此,在训练过程中加入dropout,用来减少模型对主要参数的依赖而忽视其他参数对数据的影响(下节会对dropout 的设置进行说明)。为了自适应调整学习率来改进梯度下降,优化器使用Adam 算法。
3.2 优化模型
将训练次数设置为1 000,每次训练数量为5,dropout 设为0.3。测试了深层神经网络和浅层神经网络对训练误差的影响,结果见图3、表1。

表1 不同隐藏层深层神经网络的训练误差表
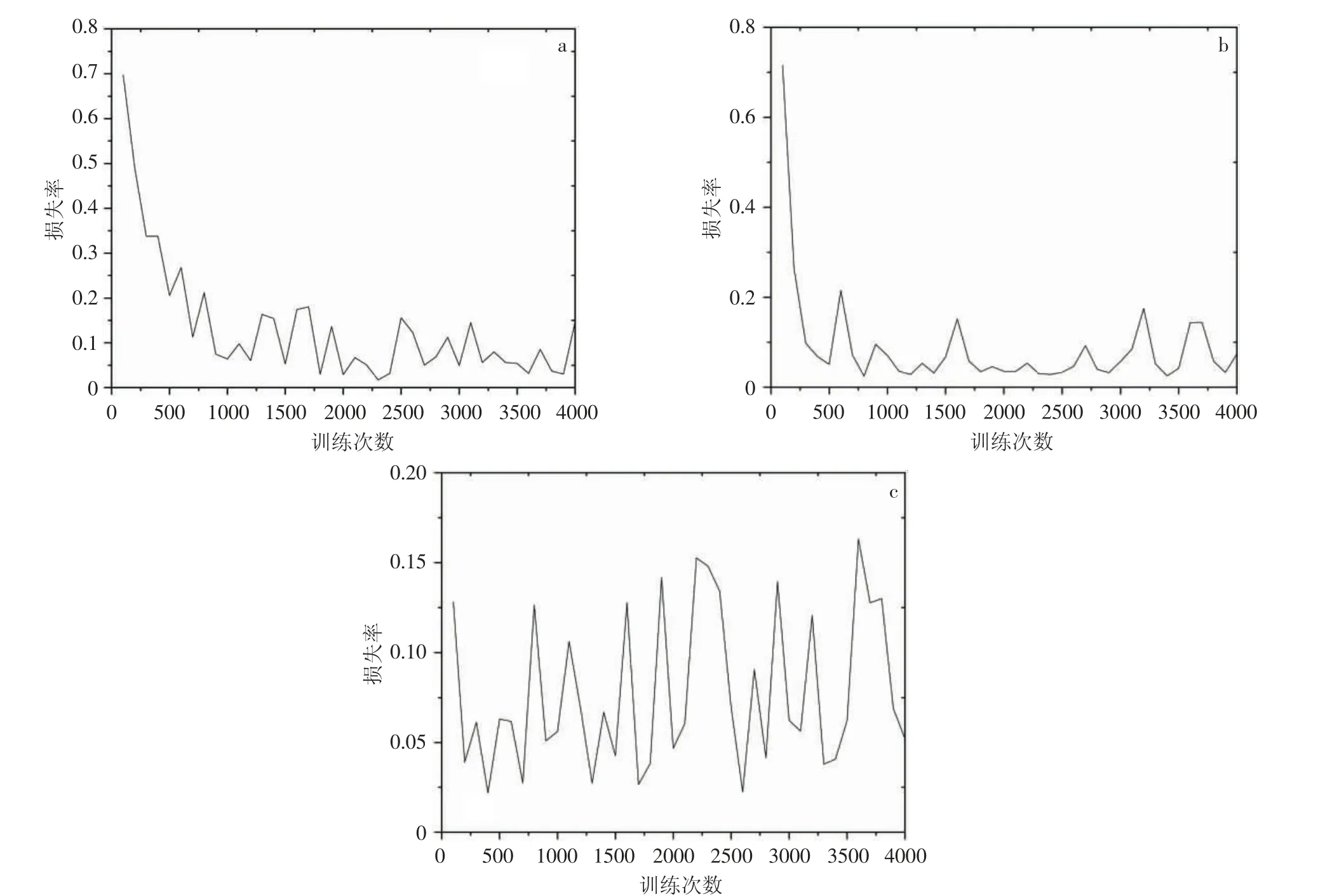
图3 不同隐藏层深层神经网络的训练误差:a.隐藏层为1;b.隐藏层为5;c.隐藏层为7
通过图3a、图3b 和表1 可以看出,深层神经网络的训练误差能控制在5.000%以下而浅层神经网络的训练误差变化幅度很大,基本上在5.000%以上,至于迭代4 000 次出现的异常会在下部分说明。
通过图3b 和图3c 展示了深层神经网络的隐藏层为5 层和7 层的训练误差。可以看出隐藏层数量的增加会增加训练的速度,在隐藏层为7 层时,训练误差的下降速度比5 层快4 倍,但是迭代次数继续增加,7 层的训练误差波动很明显,5 层虽也有波动但整体呈下降趋势。不能更好的说明隐藏层数增加训练效果好。
由图4 可以看出,dropout 的设置对训练误差的影响,当dropout 设置为0 时,训练误差为14.000%。设置为0.1 时,训练误差达到最大16.300%。随后逐渐降低达到训练误差的最小值7.410%。之后训练误差逐步增加。说明dropout 为0.3 时,模型的效果最好。

图4 dropout 的设置对训练误差的影响
通过调整超参数来提高神经网络性能,当学习率为0.01 时深层神经网络和浅层神经网络的测试误差不再减少。
隐藏层为5 层时,测试误差达到最小值为9.734%(图5),模型的准确率为90.266%,模型为浅层神经网络的测试误差为10.260%,隐藏层为7 层时,测试误差为10.340%。5 层的准确率相对浅层和隐藏层为7 层的模型高出20.000%。层数的增加并没有使得准确率变高。对比5 层模型的训练误差和测试误差,没有出现较大的方差和偏差,说明5 层神经网络模型没有出现过拟合和欠拟合的现象,模型效果很好。

图5 隐藏层为5 层时的测试误差
实验数据与开发模型的预测见图6 中。在图6 中,绘制了预测数据和实验数据与总数据点的数据索引。从该图中可以明显看出,所开发模型的结果精确地遵循实验数据的趋势,这从目标数据和模型结果之间的惊人覆盖显而易见。因此,该模型用于预测Z 地区致密油水平井初产水平具有很高的可靠性。
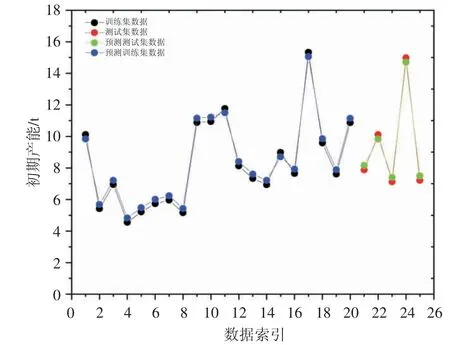
图6 初期产能训练和测试数据集索引图
3.3 讨论
深层神经网络对致密油水平井的初期产能预测具有出色的鲁棒性。特别是加入dropout 以后,模型性能极大改善,对模型不依赖影响力大的参数的适应性提高。使测试集的损失达到了90.266%。
致密油水平井初期产能影响因素按照重要程度为水平段长、加砂强度、裂缝密度、脆性指数、用液强度、总排量、井距、视储能系数。预示着影响致密油水平井初期产能的影响因素主要在开发和工程方面,其次是地质因素。说明同一地区在地质因素相近的情况下,开发和工程因素是影响致密油水平井初期产能的重要因素。基于此效果,可以通过这些因素指导Z 地区致密油水平井的开发,获取更高的产能。
通过上述实验可以发现,通过开发因素、工程因素、地质因素是可以预测出水平井的初产水平,相对于其他人通过油井动态生产数据预测产能,该方法更加便捷,需要的数据少,更重要的是可以对刚开发的新井进行预测。对于模型在训练迭代次数达到4 000 次时所产生的异常值,是因为数据集的数量少,导致模型的训练误差产生波动。
虽然这个模型对于致密油水平井初期产能的预测有着不错的效果,但是通过热力图显示的13 个影响因素对初产水平的预测仍然偏低,还需要更全面的影响因素数据参与到模型训练中来,而且误差的效果一般,这是因为数据集的数量少,训练曲线波动依然很大。因此,可以通过增加数据达到更好的效果。
4 总结
在这项研究中,设计了深层神经网络来预测致密油水平井初期产能。该方法先将开发、工程、地质13 个影响因素作为参数,通过前期的数据分析得出影响Z地区致密油水平井初期产能的主要因素是工程因素和开发因素,筛选出8 个相关数值特征作为模型输入参数。在训练和测试过程中使用了200 个数据点,通过开发模型的统计和图形评估表明该模型具有鲁棒性,可以非常准确的预测致密油水平井初期产能。此外通过对比隐藏层数量来确定最佳模型。结果表明当隐藏层数量为5 层时,模型预测致密油水平井初期产能最准确,达到了90.266%。而其他数量的隐藏层模型的准确率在90.000%以下。总之,通过深层神经网络来预测致密油水平井初期产能达到了很好的效果,在预测产能数据方面也表现出合理的误差,证明了该模型不逊色于其他传统方法。
