Improving Yolo5 for Real-Time Detection of Small Targets in Side Scan Sonar Images
2023-12-21WANGJianjunWANGQiGAOGuochengQINPingandHEBo
WANG Jianjun, WANG Qi, GAO Guocheng, QIN Ping, and HE Bo
Improving Yolo5 for Real-Time Detection of Small Targets in Side Scan Sonar Images
WANG Jianjun, WANG Qi, GAO Guocheng, QIN Ping*, and HE Bo
,,266100,
Side scan sonar (SSS) is an important means to detect and locate seafloor targets. Autonomous underwater vehicles (AUVs)carrying SSS stay near the seafloor to obtain high-resolution images and provide the outline of the target for observers. The target feature information of an SSS image is similar to the background information, and a small target has less pixel information; therefore, accurately identifying and locating small targets in SSS images is challenging. We collect the SSS images of iron metal balls (with a diameter of 1m) and rocks to solve the problem of target misclassification. Thus, the dataset contains two types of targets, namely, ‘ball’ and ‘rock’. With the aim to enable AUVs to accurately and automatically identify small underwater targets in SSS images, this study designs a multisize parallel convolution module embedded in state-of-the-art Yolo5. An attention mechanism transformer and a convolutional block attention module are also introduced to compare their contributions to small target detection accuracy. The performance of the proposed method is further evaluated by taking the lightweight networks Mobilenet3 and Shufflenet2 as the backbone network of Yolo5.This study focuses on the performance of convolutional neural networks for the detection of small targets in SSS images, while another comparison experiment is carried out using traditional HOG+SVM to highlight the neural network’s ability. This study aims to improve the detection accuracy while ensuring the model efficiency to meet the real-time working requirements of AUV target detection.
side scan sonar images; autonomous underwater vehicle; multisize parallel convolution module; attention mechanism
1 Introduction
The real-time processing technology of high-resolution side scan sonar (SSS) images presents great significance in improving the intelligence of autonomous underwater vehicles (AUVs) in complex marine environments. AUVs equipped with SSS–combined with data-driven operations such as image processing, signal detection, and artificial intelligence–play an important role in the exploration and development of marine resources, underwater unknown area detection, and underwater search and rescue (Healy., 2015; Venkatesan, 2016; Geraga., 2017).
With its rapid development, deep learning has achieved excellent results in many application fields. Recent years have seen the emergence of many new neural networks, such as convolutional neural networks (CNNs), which are commonly used in the field of imaging. Thanks to the mature development of CNNs, the target detection algorithm in SSS is gradually improving in speed and accuracy. Withthe lightweight development of CNNs, the relevant applications of underwater SSS target detection move further to- ward intelligence and autonomy, assisting staff in judgment and rescue work.
Li. (2021) proposed a deep neural network for acquiring a detector using zero-shot SSS images, developed an efficient pseudo sample synthesis method and improvedit specifically for SSS images, and then validated the modelwith real SSS images. Given that the deep learning method needs massive data support, Ye. (2018) fine-tuned a CNN through pretraining based on a small SSS dataset and achieved high classification accuracy. Karimanzira. (2020) obtained a simple detector by pretraining RCNN (Girshick., 2014) and built a general underwater object detection system in sonar images. The results show sa- tisfactory accuracy but slow detection speed, taking 1.2s to process an image. Ge. (2021) took optical images as input, used the style transfer network to simulate the SSS image, generated the ‘simulated side scan sonar images’, and then used the CNN pretrained on ImageNet (Deng., 2009) for classification. Cai(2021) proposed an efficient upsampling PE method and combined U-Net (Ronneberger., 2015) and MobileNetV3-SSDLie (Liu.,2016; Howard., 2019) to improve the speed of under-water target detection and develop a high-performance mo- del. Using the earlier CNNs such as AlexNet (Krizhevsky., 2012) and GoogLeNet (Szegedy., 2015), Ngu- yen(2020) combined image enhancement techniques to detect divergent SSS images. The accuracy of the classifier (Sun., 2020) is 92.2%, achieved by proposing a seabed sediment recognition method based on a probabilistic neural network. However, the disadvantage of this me- thod is that several useful SSS image features may be lost. By improving VGG16 (Simonyan and Zisserman, 2014), Tang. (2020) achieved a recognition accuracy of the model of up to 90.58% and improved generalization perfor- mance. Zhou. (2022) used traditional methods, fuzzy C-means clustering and K-means clustering to cluster images globally, and obtained target edge information by pulse-coupled neural networks, and used Fisher discriminant criteria to improve the target detection accuracy, and used an Intel i7 8700 with a 6-core CPU to detect a 1 ping sonar image in 0.075s.
With the popularity of computer vision technology, requirements for the overall performance of target detection and accurate detection of small targets in specific scenes are also increasing. Compared with large targets, small ones have the disadvantages of fewer pixels and features that may lead to a series of low detection accuracy problems. Effectively improving the accuracy and speed of small target detection is thus of great significance for the application of specific scenes. At present, most studies explore small target detection in infrared, radar, and remote sensing images, but few focus on SSS images.
An efficient end-to-end CNN has been proposed to rea- lize infrared small target detection (Ju., 2021). The model consists of two modules, an image filter and an in- frared small target detection, to combine the image filter and target detection tasks in one network. Wang. (2021) set up a fully convolutional regression network to detect small infrared targets in the spatial domain. Zhang and Wei (2021) improved the backbone of Yolo3, and downsampling was reduced from 8 to 4 times to improve the detection accuracy of small targets in common optical images in daily life. Su(2022) proposed a channellocation attention mechanism to enhance the ability of feature extraction and designed a high-level feature enhancement module to address the loss of high-level location information for small targets. Kim. (2021) improved Yolo5 by proposing the effective channel attention pyramid Yolo to detect small targets in aerial images. Zhou. (2020) studied a super object CNN to classify urban functional zones in remote sensing images.
The abovementioned CNN-based target detection me- thods have achieved leading results. Compared with traditional target detection methods based on machine learning, CNN-based methods can integrate different tasks, such as feature extraction, feature fusion, and object classification, into one network. In addition, with end-to-end training, the network can learn the deep semantic features of the target. The target detection method based on CNN mainly includestwo- and one-stage networks. Although the two-stage network can obtain high detection accuracy, the model size is large, and the computing cost is redundant (Ren., 2015). Due to the limited computing resources of the embedded platform mounted by AUV and the high requirements on the complexity and operation times of the model, we examine the lightweight one-stage CNNs to detect the SSS image and ensure that AUV can detect small underwater targets in real time. Moreover, small underwater targets have weak echo and few effective pixel points, resulting in low contrast between the target and background and, thus, difficult feature extraction. The quality of feature extraction determines the accuracy of target recognition; therefore, the design of the CNN backbone is a major research focus. The contributions of this study can be summarized as follows:
1) Yolo5s is used as the baseline, and a built multisize parallel convolution module is embedded into its backbone to extract target features in parallel, allowing richer target feature information to be obtained after one module. We thus effectively solve the issue of low contrast between tar- get and background pixels.
2) Convolutional block attention module (CBAM) is introduced in the stage of feature extraction and fusion to improve the detection accuracy of small targets.
3) The method for calculating anchors is improved to move the prediction boxes closer to the targets.
This paper is organized as follows: Section 2 discusses several concepts involved in neural networks and explains the frameworks of Yolo5 and the proposed method; Section 3 explains the collection and enhancement methods ofdatasets; Section 4 compares the results of detection accuracy and speed among all networks and traditional method; Section 5 presents the conclusions.
2 Network Architecture
The data obtained from each neuron layer in a CNN is in 3D form, which can be understood as multiple 2D pictures stacked together into a feature map. When building one CNN, the convolution kernels of each network layer are set up in advance and then convoluted with the corresponding feature map, resulting in a feature map of the next layer. The expression of the feature map size is
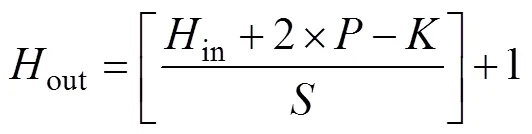
whererepresents the size of the feature map,represents the number of pixels filling each side of the feature map in the convolution operation,represents the convolution stride,represents the size of the convolution kernel, and the operator [] represents rounding up.
In the feature map of each network layer, the area size mapped on the input image by each pixel point is called the receptive field (RF). One more general explanation is that one pixel point on the feature map corresponds to the area on the input image, and the expression of RF size is
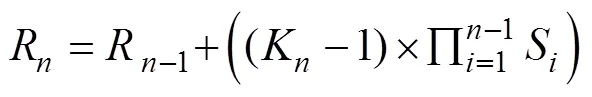
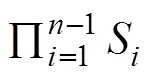
Target detection networks are either anchor-free (Tian., 2020) or anchor-based, and Yolo5 (Glenn, 2020) be- longs to the latter. For target detection tasks based on anchors, the first step is to label the dataset manually, commonly by using a rectangle box to mark the target. This box is called Ground Truth (GT), which is the correct answer given by humans to the machine. The network randomly predicts another set of rectangle boxes called anchors, which fit the GT according to the loss function. The anchor set must strictly correspond to the RF; otherwise, it will adversely affect the detection performance.
2.1 Yolo5
Yolo series networks (Redmon., 2016; Redmon and Farhadi, 2017; Redmon and Farhadi, 2018; Bochkovskiy., 2020; Glenn, 2020) are fast and compact open- sourceobject detection models. Compared with other networks, Yolo has stronger performance with the same size and better stability. Yolo1 is the first end-to-end CNN that can predict the category and GT of objects. Yolo is mainly composed of three parts, as follows: 1) The backbone is mainly used to extract features; 2) The neck fuses the multiscale features obtained from the backbone; and 3) the head completes the final positioning and classification tasks.
On June 25, 2021, Ultralytics released the first official version code of Yolo5, and thus far, many ‘yaml’ files of network models have been developed under the project. Four versions are available according to size: Yolo5s, Yolo-5m, Yolo5l, and Yolo5x. The latter three versions are deep- ened and widened on the basis of Yolo5s. The backbone of Yolo5 uses Cross Stage Partial Network (CSPNet) (Wang., 2020), which solves the problem of redundant gradient information in the optimization of CNNs, integrates the gradient changes from beginning to end into the featuremap, reduces the model parameter numbers, guarantees the inference speed, and obtains ideal accuracy in the training. To enhance the use of low-level feature information and improve information dissemination, the neck in Yolo5 uses PANet (Liu., 2018), which uses Mask RCNN (He., 2017) and FPN (Lin., 2017) for reference to add a bottom-up path. The head applies an anchor on the feature map and generates the final output vector with class probability, object score, and bounding box.
One of Yolo5’s major innovations is the focus structure, in which slicing is the key step. Similar to downsampling, the focus takes one value for every other pixel to obtain four subimages before one original image enters the back- bone. Focus centralizes the image width and height information into the channel space, and the dimension of the channel is expanded four times. That is, after slicing, the result is equivalent to changing the original RGB 3-channel mode into 12 channels. Finally, the feature information of 12 channels is convoluted to obtain the double downsampling feature map. The slicing operation and focus results are shown in Figs.1 and 2, respectively.
Intuitively, the role of focus is the same as that of down-sampling but also shows differences. Focus increases a cer- tain computational efficiency. Taking parameter number asthe evaluation standard and taking the official Yolo5s code as an example, the input image size is 640×640×3. The comparison results of the calculation are as follows:
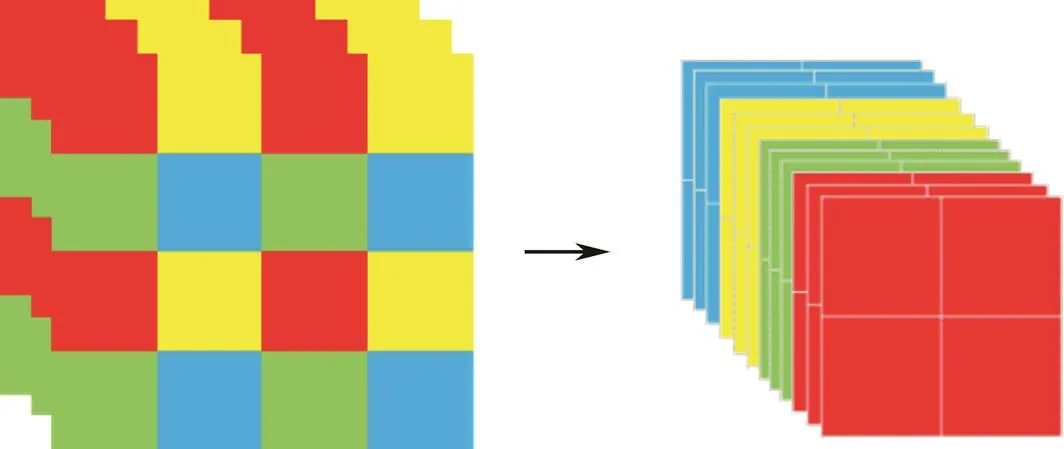
Fig.1 Slicing operation.
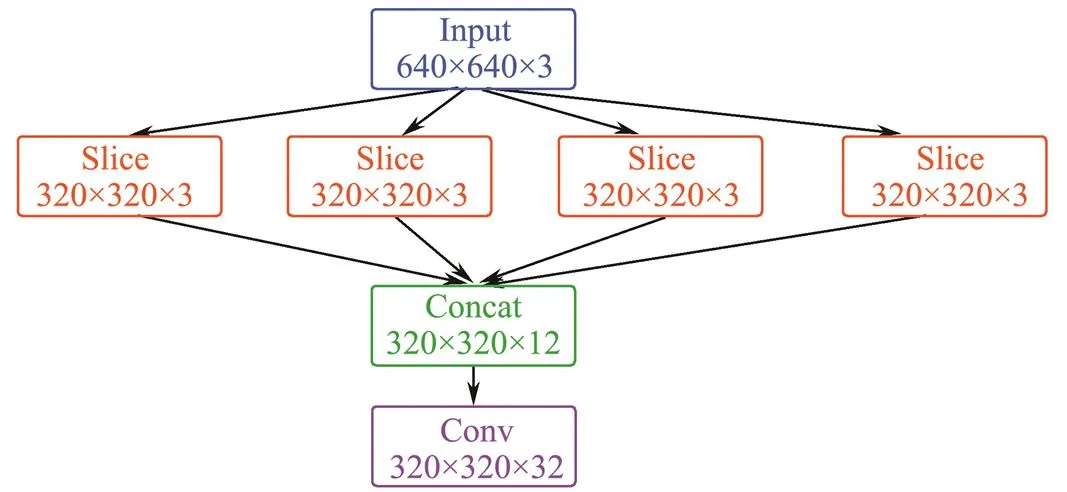
Fig.2 Structure of focus.
1) Convolution downsampling. Set the convolution kernel size as 3×3, convolution stride as 2, output channel as 32, and feature channel as 320×320×32 after downsampling, then the parameter number is

2) Focus. After slicing, the size of the feature map is 320×320×12, and after convolution with 3×kernel, the output feature map size is 320×320×32, which is calculated as
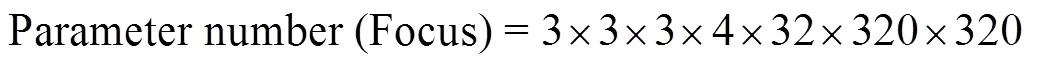
Yolo5 uses theactivation function to add nonli- near properties to the network, expressed as
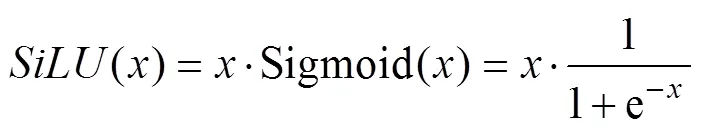
Figs.3 and 4 show the Yolo5 model and its submodules, respectively. In both figures, the ‘concat’ indicates that the feature information from the different convolution layers is concatenated along channels. In Fig.4, the ‘BN’ represents batch normalization, which means normalizing the feature information of each batch. ‘Conv2d’ denotes a ge- neral 2D convolution operation, and the convolution kernel size and stride can be set flexibly. Officially, the convo- lution kernel size is 1×1, and the convolution stride is 1.
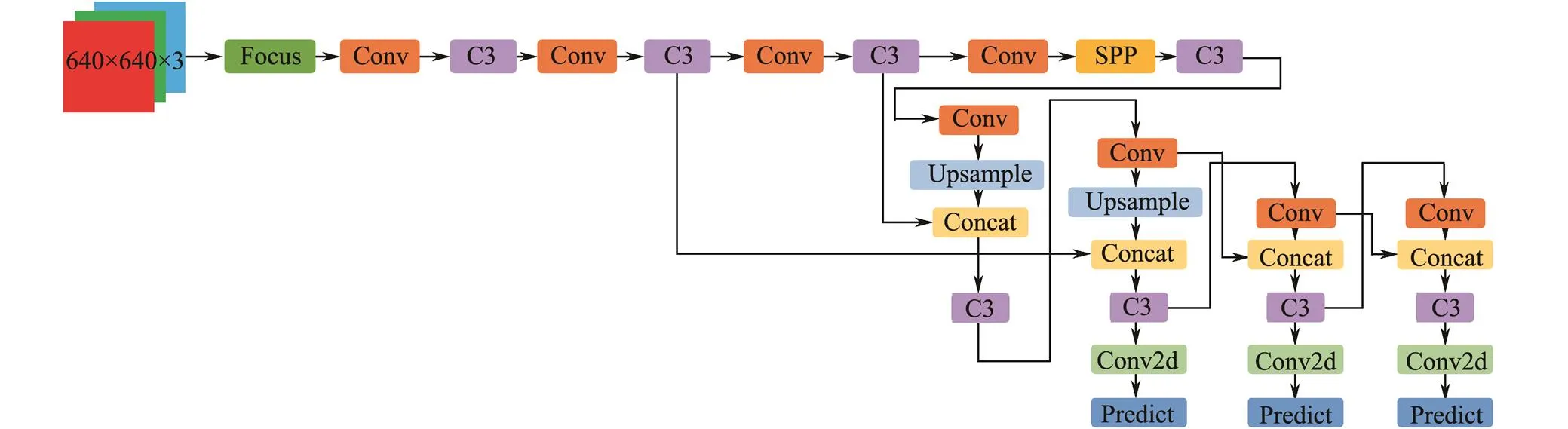
Fig.3 Architecture of Yolo5.
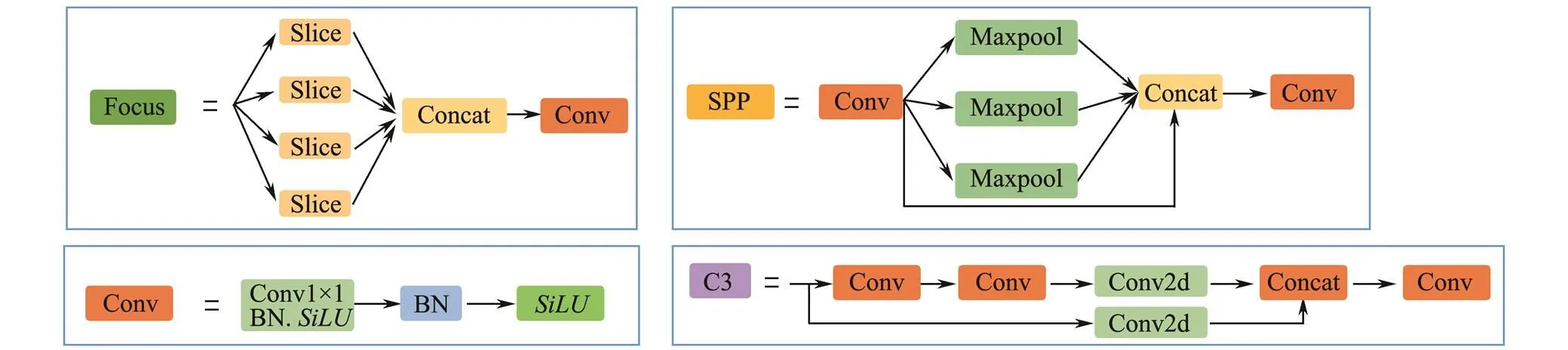
Fig.4 Submodules of Yolo5.
2.2 ProposedNetwork
2.2.1 Anchor
The K-means clustering method is used in Yolo5 to au- tomatically calculate the anchor that is suitable for the train- ing dataset. K-means is a classical and effective clustering method that calculates the distance (or similarity) between samples; those that are closer are grouped into the same cluster. Yolo5 calculates the Euclidean distance between samples (that is, the sum of squares of errors between samples). In this study, we calculate the intersection over union () of the GT and anchor using 1−Anchor GTas the dis- tance between samples. If the GT has a largewith the corresponding anchor, then the smaller 1−Anchor GT, the closer the distance between samples. Table 1 lists the anchor, fitness, and the best possible recall of all anchors obtained through Euclidean distance and 1−Anchor GT. We can observe that the anchor, fitness, and the best possible recall obtained by using 1−Anchor GT all increase.
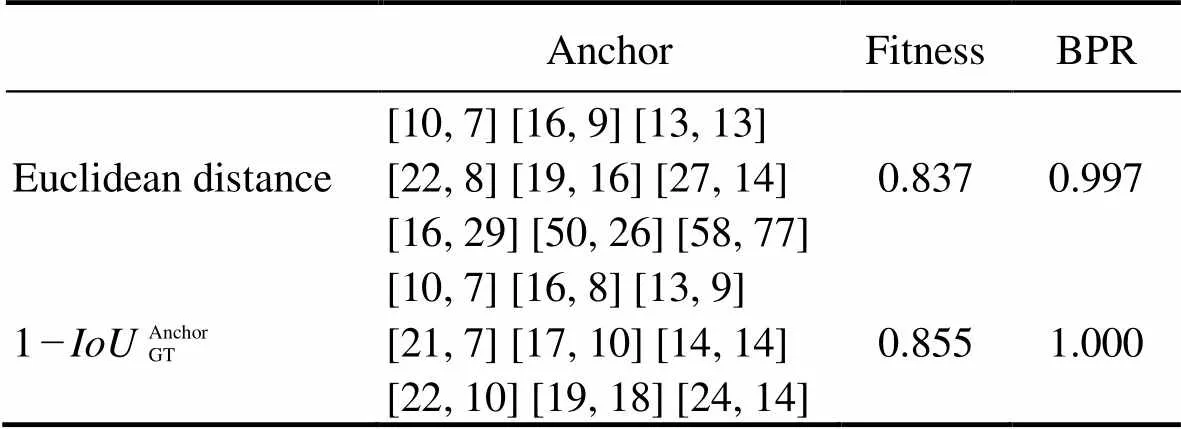
Table 1 Anchor, fitness, and the best possible recall (BPR) of all bounding boxes obtained through Euclidean distance and 1−IoUAnchor GT
2.2.2 Multisize parallel convolution module
The convolution kernel of 1×1 is essentially a transformation that linearly combines information among diffe- rent channels to increase its interaction and maintain the scale of the feature map. Given the small convolution kernel, computational efficiency is improved by reducing the number of model parameters.
In CNNs, as the convolution kernel size increases, the larger the RF that can be obtained, the more picture information can be seen, and the better the global features. How- ever, a large convolution kernel can lead to a burst of com- putation, which hinders the increase in model depth. There- fore, Inception (Lin., 2017) uses two layers with a 3 ×3 kernel and replaces one layer with a 5×5 kernel, uses two layers with a (1×)+(×1) kernel and replaces one layer with an×kernel. These replacements have the following advantages: 1) Under the condition of obtaining the same feature map, the network deepens, introduces more nonlinear operations, and improves the advantages of the neural network itself; 2) The number of parameters and computational complexity of the network decrease.
In view of the above analysis, we design the multisize parallel convolution module (MSPCM). First, the use of a 1×1 convolution kernel expands the number of channels, thereby aggregating feature information. Then, convolution kernel branches with different sizes (3×3, 5×5, and 7×7 are introduced simultaneously to obtain feature information, which increases the network adaptation to targets of different scales. Notably, instead of having one layer with a 5×5 kernel, we have two layers with a 3×3 kernel, and the number of channels in each branch decreases by half compared with the previous layer to reduce the number of parameters. Finally, the 1×1 kernel fuses the features with different scales. Fig.5 shows the MSPCM.
从中可以看出,中国观众偏爱喜剧、合家欢类型的电影,以上电影也几乎全部是大团圆结局。与中国观众相似的是,韩国观众也对于满足民族自豪感的类型片情有独钟,因此《鸣梁海战》《暗杀》等抗日题材的电影榜上有名。但与中国观众不同的是,韩国观众似乎更能接受主角的死亡、不幸等悲惨命运,哪怕是喜剧片也流露出浓郁的悲剧氛围,例如喜剧电影《七号房的礼物》,结局以无辜的男主角在无罪释放前被执行死刑而告终。
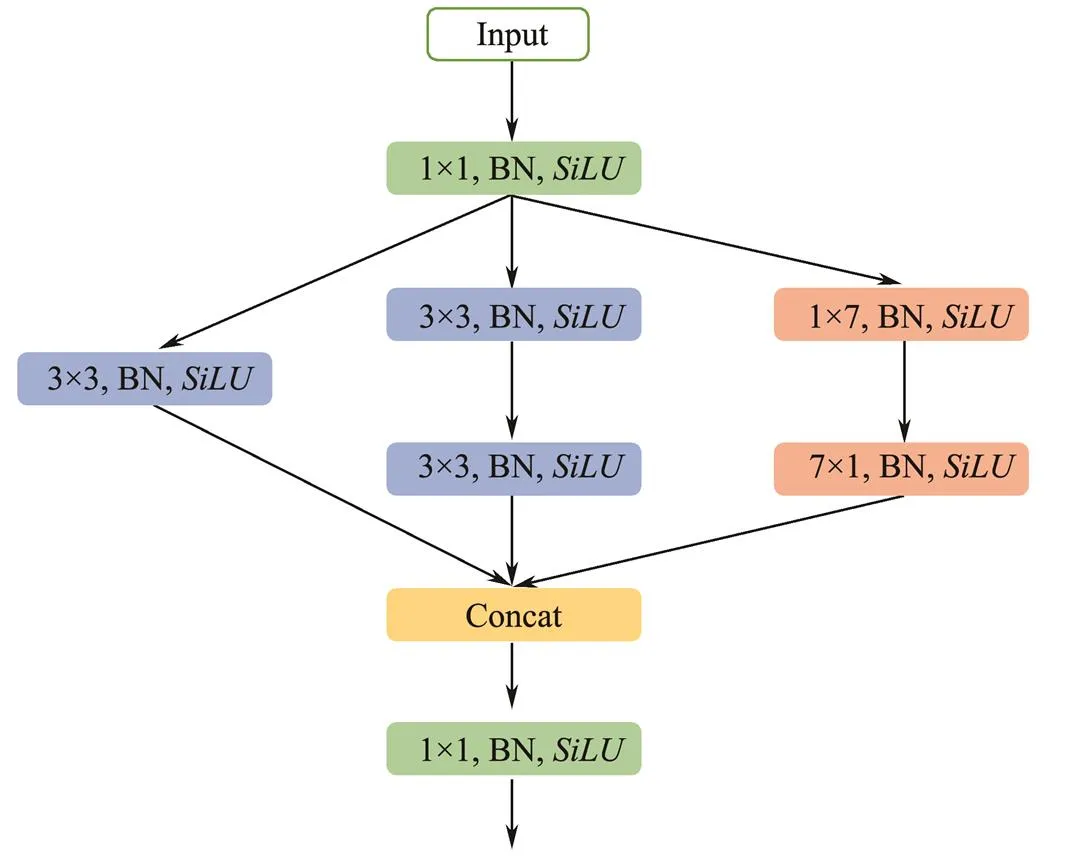
Fig.5 Multisize parallel convolution module. ‘BN’ represents batch normalization operation; one nonlinear activation is performed after each BN, and SiLU is used as the activation function.
2.2.3 Attention mechanism
The network combined with Yolo5 and Transformer (Vas- wani, 2017) is officially presented. A transformer is initially used in the field of natural language and consists of six encoders and decoders each. Yolo5 only uses the en- coding part of the Transformer, as shown in Fig.6. The encoder comprises a multihead self-attention mechanism and a fully connected feed-forward network. In each part, residual connection and layer normalization are introduced. Residual connection makes each feed-forward neural network contain not only the output of self-attention but also the original input, which further uses the shallow layer in- formation. Yolo5 removes layer normalization, and the au- thor of Yolo5 notes in the code that ‘LayerNorm layers removed for better performance’. The attention mechanism enables the network to focus on the important parts of the image and facilitates the detection of small targets (Miao, 2022). We verify this effect of the attention mechanism by carrying out a comparative experiment on the of- ficially published Yolo5s-transformer.
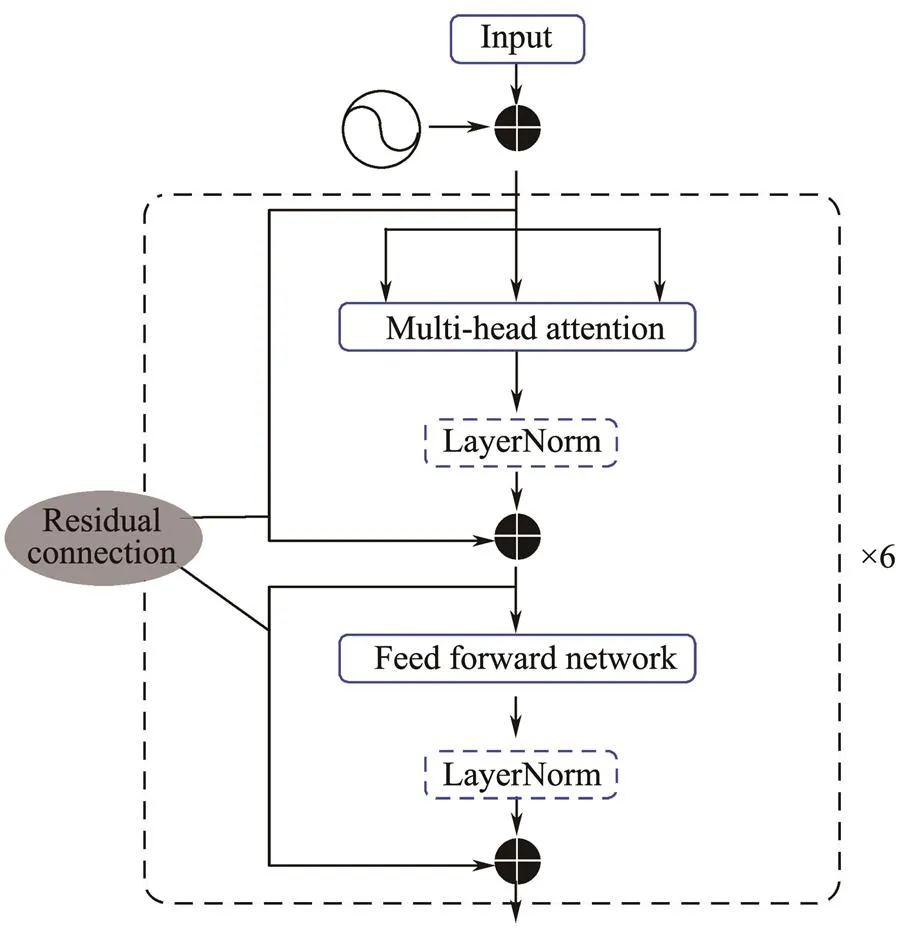
Fig.6 Encoder in Transformer without a ‘LayerNorm’ in the dotted box in Yolo5.
For comparison, we introduce the CBAM (Woo., 2018), which consists of two independent submodules, namely, channel attention and spatial attention. CBAM main- ly contains convolution, pooling, and nonlinear activation operations, where the activation function includes Sigmoid and. The expressions ofare
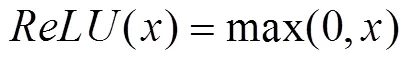
CBAM not only reduces parameters but also ensures its potential integration into existing network architectures as a plug-and-play module. We embed this module in the back- bone and neck of Yolo5s. Figs.7 and 8 show the CBAM structure and the overall proposed network models, respectively.
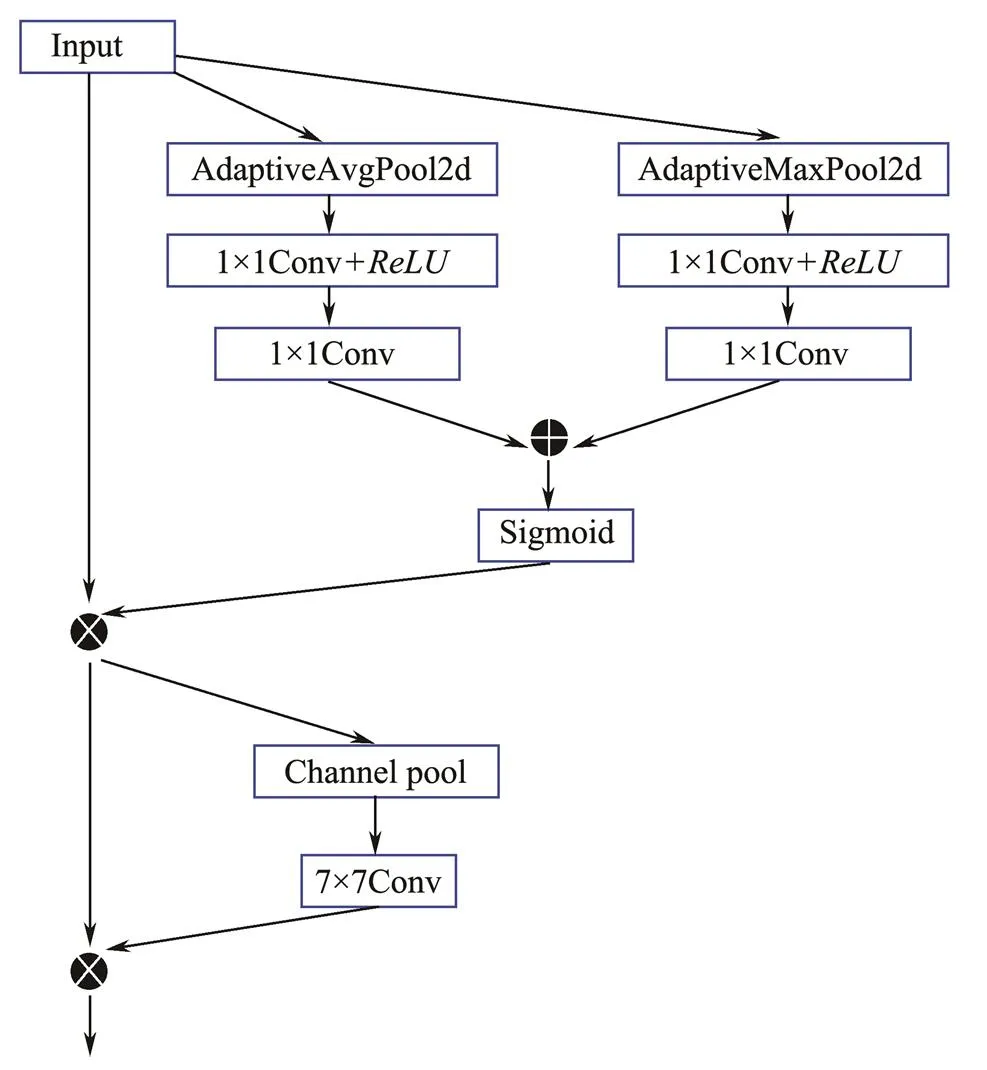
Fig.7 CBAM architecture.
Based on the calculation method of the feature map and RF size described above, Table 2 lists the convolution kernel size, convolution kernel stride, input and output of the feature map, and RF size for each network layer. We set the input image to 640 pixels×640 pixels×3 (represents the RGB channel). Given that we use the 18th/22nd/26th network layer for detection, Table 2 shows that the RF size of the 22nd/26th network layer is larger than 640, which can cover the whole image without missing any pixel informa- tion.
3 Dataset
3.1 Dataset Preparation
SSS Shark-S150D is installed on the left and right side of Sailfish-260 AUV, and data were collected at the dock of Qingdao Scientific Research Center of the State OceanicAdministration. Table 3 presents the summary of the working parameters of the SSS. Sailfish-260 is an AUV that is independently developed by the Underwater Vehicle Laboratory of the Ocean University of China, which has a load of 110kg, a length of 2.8m and a diameter of 262mm. Fig.9 depicts the overall structure of the Sailfish-260 AUV and the SSS position.
The SSS mainly comprises two transducers mounted on both sides of the AUV and electronic cabin circuits. The tilt angle of the transducer and the radio frequency rate are fixed to send an acoustic pulse to the seafloor in advance, and then the received echo signal is processed to convert the acoustic signal into pixel values to visualize the seafloor topography. The electronic cabin circuit mainly trans- mits the transducer array, receives the ultrasonic data, and transmits the processed sonar data through cables at the same time. The imaging principle of the SSS is shown in Fig.10. During AUV navigation, the transducer emits sector-shaped sound pulses to the seafloor vertically at a certain time interval. A single transmission can obtain one nar-row-band seafloor information from each of the two transducers. The information is recorded as 1-ping, and many pings are stitched together into one complete×4800×3 (indicates the number of pings) seafloor topographic SSS image using OTech software.
The initial distance between the AUV and the ball is 5 m when the ball is sunk into the seafloor during a calm sea state, but the distance ranges from 5 to 10m because of complex sea conditions. To enrich the dataset, we collect data on both calm and complex sea states. With the movement of the seawater itself, the ball does not sink vertically to the seafloor, and its final location cannot be clear, resulting in a small probability of detecting the metal ball by the AUV with SSS; therefore, the available data is li- mited.
We composed the data of 1800 pings into one complete SSS image, as shown in Fig.11. Given that an 1800×4800 image contains too much pixel information, each image isdivided into two subimages of 1800×2400 left and right for training. The packets are transmitted by the UDP pro- tocol on the SSS transmitter. UDP is fast but sacrifices a certain reliability and inevitably causes a packet loss pro- blem, which leads to the loss of certain pixel information. In addition, the image has no pixel information as black, as shown between the two black horizontal lines on the right side of Fig.11. The packet loss problem easily occurs between different pings, corresponding to the edge pixels of the image, while most of the targets are concentrated in the middle and thus does not affect the model recognition effect. In addition, the AUV and the ball move due to the ef- fect of the seawater, and thus most of the SSS images contain multiple balls.

Table 3 Working parameters of the Shark-S150D SSS
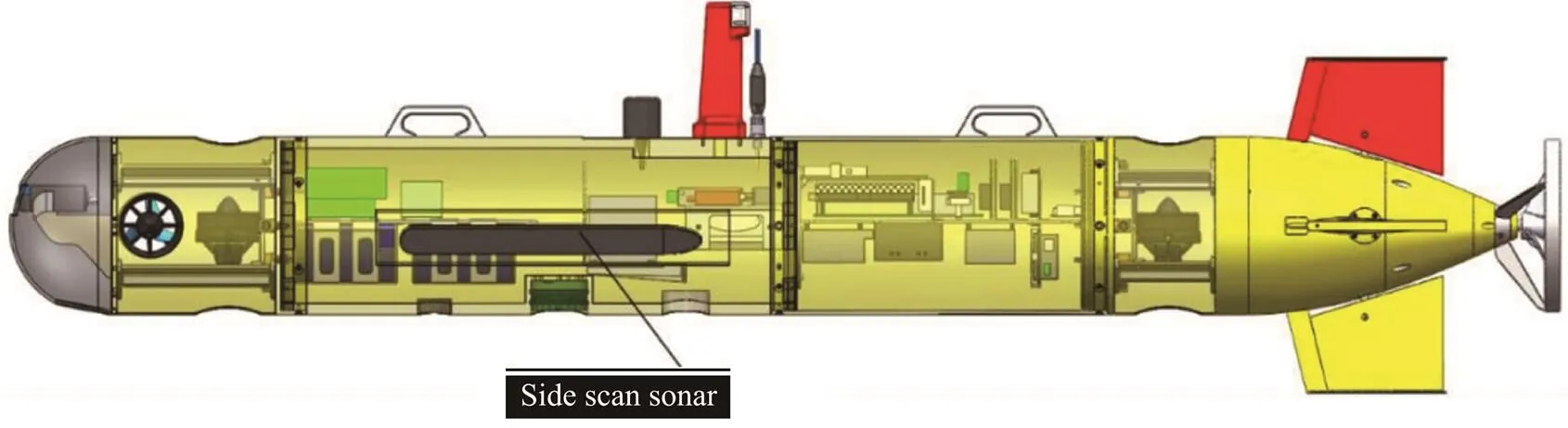
Fig.9 Overall structure of Sailfish-260 AUV and the position of the SSS.
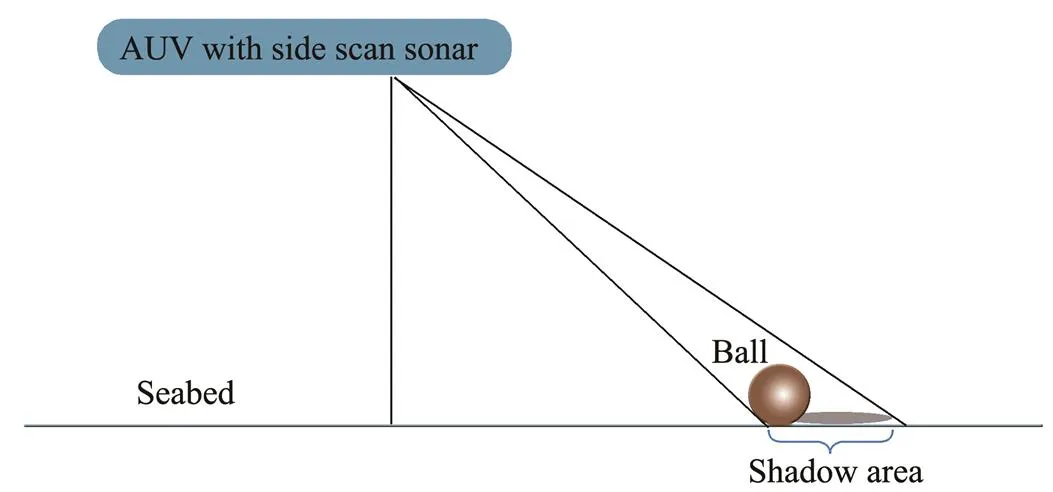
Fig.10 Schematic of SSS imaging.

Fig.11 Diagram of complete SSS. (a), Example where the red and pink boxes correspond to the GT of ‘ball’ and ‘rock’, respectively; (b), left subdiagram of (a); (c), right subdiagram of (a).
The brightness of the image reflects the seabed features. When the sound pulse hits hard objects, the echoes are alsorelatively strong, which corresponds to the highlighted tar- get area in the SSS image. In the echo signal received by the transducer, a certain area has no value return due to the target occlusion, which is reflected in the SSS image as the shadow area. As shown in the SSS imaging principle illustrated in Fig.10, the shadow of the ‘ball’ presents a regular oval shape, while the ‘rock’ presents an irregular shape, which is used as the basis for labeling. The collected data are randomly divided into training-, validation-, and test sets according to the ratio 8:1:1. The training set is used to train and fit the network in the forward propagation; the validation set is used to update the weight and error in the backpropagation, and preliminarily evaluate the detection performance of the model; and the test set is assigned to analyze the generalization performance to more objectively demonstrate the effectiveness of our method. Note that validation and test sets are not included in the network training.
Compared with imaging technology of optical photogrammetric instruments, underwater image collected by SSS is difficult for the following reasons: 1) high hardwarecost to realize real-time sonar imaging, and sonar needs mul-tichannel signal synchronous sampling; and 2) the process- ing and operation of massive signal data need the support of powerful computing units. Moreover, underwater noise is easily confused with targets, especially weak and small ones that are more likely to be submerged in the background of sonar images. Therefore, less useful data are avail- able.
3.2 Dataset Enhancement
A mosaic is proposed in Yolo4. The main idea is that four pictures are randomly clipped, flipped, zoomed, and then stitched into one image as training data. The stitched image is thus the same size as the original image. The advantages of this trick are as follows: 1) geometric distortion operations (cropping, flipping, scaling) of images can achieve dataset expansion without pixel information changes, well solving the problem of small sample size; 2) adjusting the HSV space of the image, improving the brightness, contrast and saturation of target pixels, and enriching the pixel information to further gain from attention mechanism can improve the detection accuracy of targets; and 3) the network can process four pictures at the same time, improves batch size, and calculates four pictures at the same time at BN, resulting in increased global normalization values. When the network can process more pictures at a time, the value obtained by one batch is more representative of the global image. In this study, we stitched nineimages at one time; Fig.12 depicts an example of the sti- tched training input. Notably, the process of data enhancement simultaneously improves both images and labels, which avoids relabeling the newly obtained data and saves much redundant work.
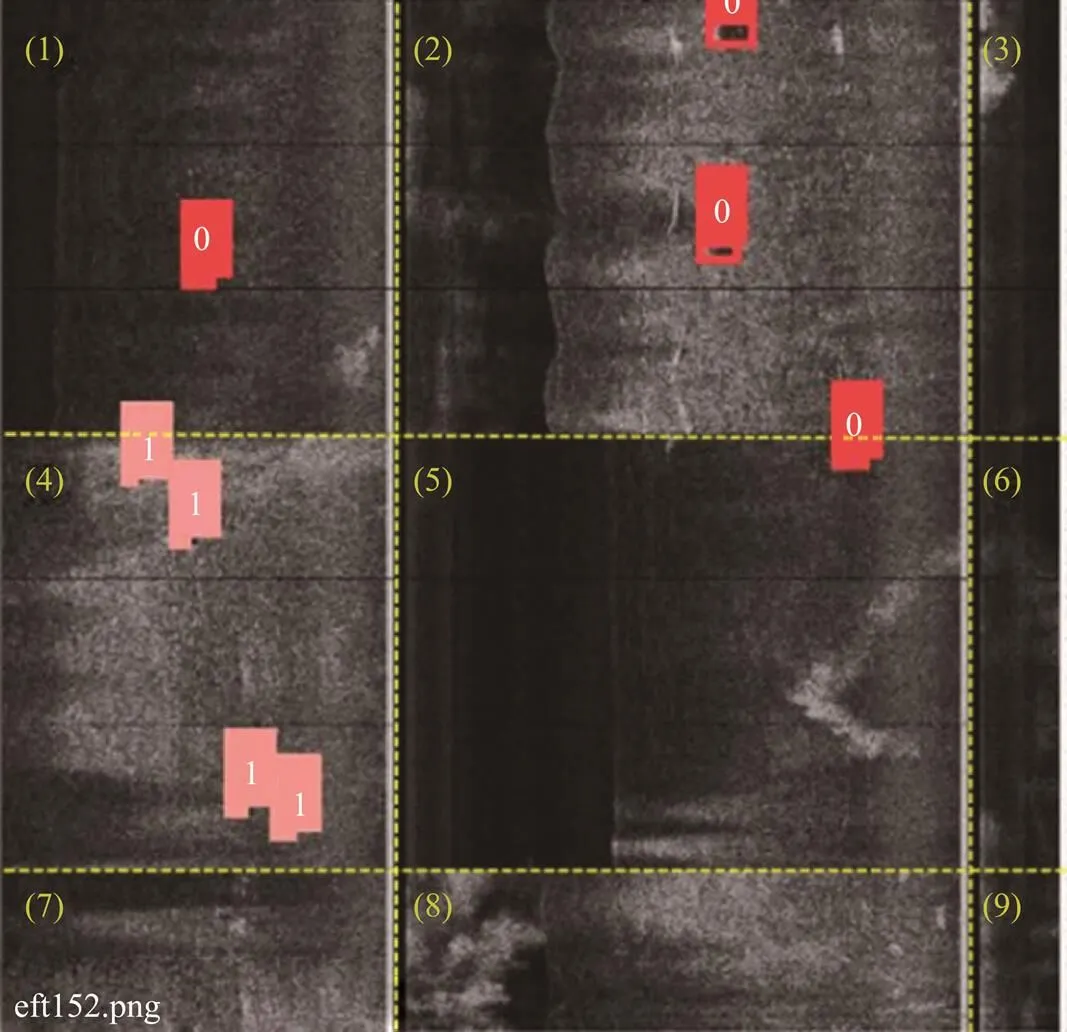
Fig.12 Sample input image for network training. Each sub-image is labeled for a clear display. The red box ‘0’ means ‘ball’, and the pink box ‘1’ means ‘rock’, corresponding to the GT of the two targets, respectively.
4 Analysis of Experimental Results
4.1 Metrics
In target detection tasks, the commonly used model metrics are recall, precision, and average precision (). Before obtaining these indicators, we first calculate true positive (TP), false positive (FP), false negative (FN), and true negative (TN), as summarized in Table 4.

Table 4 Definitions of TP, FP, FN, and TN
is the ratio of positive numbers in predicted results to all TP, that is

is the ratio of the correct positive numbers to all positive numbers in predicted results, that is
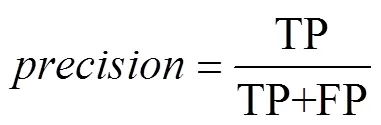
The above two formulas show thatandare mutually exclusive, and simultaneously improving them is difficult.makes a trade-off betweenand, indicating the area under thecurve. The higher thevalue, the better the performance of the classifier. When multiple categories of objectives are involved, the mean() is used to evaluate the model as a whole, computed as
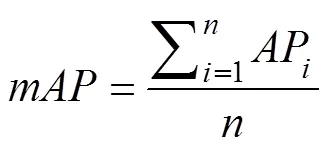
whereAPrepresents thevalue of the-th class, andrepresents the number of categories in the dataset.
4.2 Implement Details
The models were trained on a machine with an Intel (R) 2.20GHz×16-core CPU with 16GB of memory and a Ge- Force RTX3060 GPU to accelerate computing.
Given the small dataset, we use the official weight file of Yolo5s. To prevent overfitting problems and to obtain a model with good generalization performance, we use the early stop technique to stop the iteration earlier whenvalues on the validation set are no longer increasing after 55 epochs. In the first three epochs, we stabilize the mo- del at the beginning of training by using warm-up (Goyal., 2017), with momentum set to 0.8 and initial bias learning rate set to 0.1. Other hyperparameters include the initial learning rate set to 0.005, learning rate decay rate set to 0.2 (after each training epoch, learning rate=learning rate×0.005), momentum is 0.957, and momentum decay is 0.0005 (after each training epoch, momentum=momentum×(1−0.0005)).
4.3 Results Analysis
4.3.1 Detection accuracy
Table 5 shows the detection accuracy results of Yolo5s- Yolo5x. The detection accuracy cannot be effectively improved but rather can be decreased by blindly deepening one kind of network. Table 6 compares the detection results of the Yolo5s-transformer and the proposed Yolo5s-MS- PCM with and without CBAM. Each metric (except for the precision of ‘ball’) of Yolo5s-MSPCM without CBAM is higher than that of Yolo5s, which shows that the proposed MSPCM can effectively improve the accuracy of small tar- get detection. Although theof Yolo5s-MSPCM with CBAM is lower,andobtain the best results, demonstrating the validity of the proposed network. The detection results by this method under different sea conditions are shown in Fig.13.

Table 5 Detection results of Yolo5s, Yolo5m, Yolo5l, and Yolo5x (AP average is mAP@0.5)
Note: The optimal value of each metric is in bold.

Table 6 Detection results of the Yolo5s-transformer and Yolo5s-MSPCM (AP average is mAP@0.5)
Note: The optimal value of each metric is in bold.
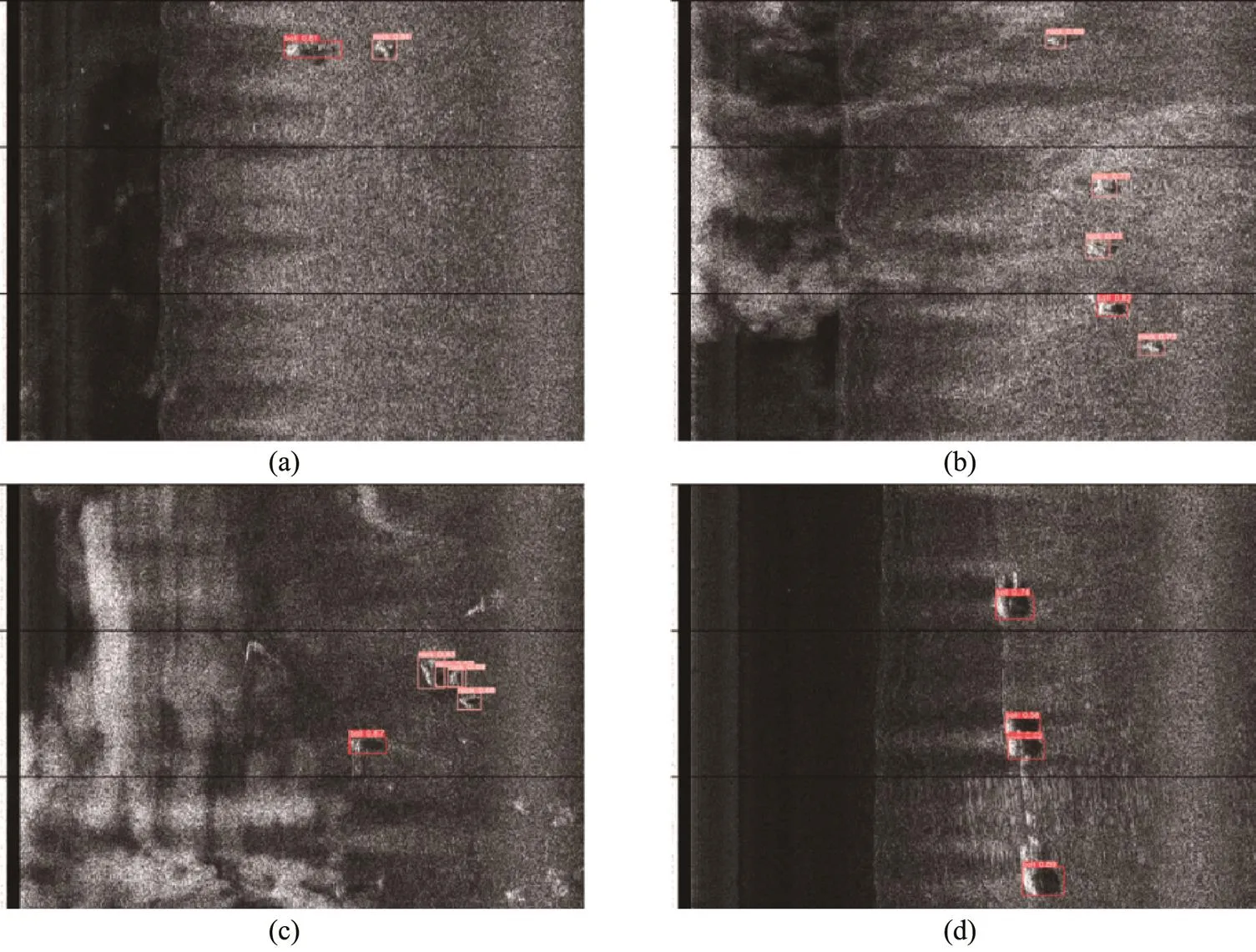
Fig.13 Example of the detection results by the proposed network. (a), Calm sea conditions, where ball and rock are identified with an accuracy of 0.8 or higher; (b), unbalanced samples, where the detector locates and classifies ball and rock well; (c), multiple rocks overlap, and the model identifies all rocks well; (d), high seawater velocity, where the ball moves faster, and its traces can be seen, proposal method could accurately identify and locate the metal ball.
For the two combined networks, Yolo5s-Mobilenet3 and Yolo5s-Shufflenet2, using Mobilenet3 as the backbone of Yolo5 can achieve better results. By contrast, Shufflenet2 is not suitable for detecting our dataset. In addition, to show the performance of CNN, we use the traditional target de- tection algorithm, HOG+SVM (Dalal and Triggs, 2005), which extracts target features by HOG and classifies them by SVM. Adding the ‘background’, the dataset has three categories in total, and thusSVM classifiers are needed. Table 7 records the detection results, which are not very sa- tisfactory. We analyze the following reasons: 1) The background feature of the seabed and the target are too similar, and HOG extracts the target gradient information that is easy to mix the background and the target into one category; 2) The pixel information of SSS image is similar to the grayscale image. The ‘ball’ and ‘rock’ are shown as highlights in SSS images without rich pixel information, and the traditional detection algorithm is not as powerful as the convolutional kernel in extracting features.

Table 7 Detection results of Yolo5s-Mobilenet3, Yolo5s-Shufflenet2, and HOG + SVM (AP average is mAP@0.5)
Using line charts, Figs.14 and 15 compare the changes ofand training loss of all CNN methods, respectively. We can see that theof the proposed method shows a stable and continuous upward trend, and the turbulence range of other models is large, especially Yolo5l. The curves of the two combined models (., Yolo5s-Mobilenet3 and Yolo5s-Shufflenet2) are at the bottom; that is, the training accuracy is the least ideal. The training loss of all methodsshows a downward trend. Although the loss of the proposed method does not decrease the fastest at the beginning, it finally converges to the lowest compared with those of other methods. For Yolo5l, the turbulence range is the largest, the loss of the two combination models ranks in the top two, and the detection performance is not ideal.
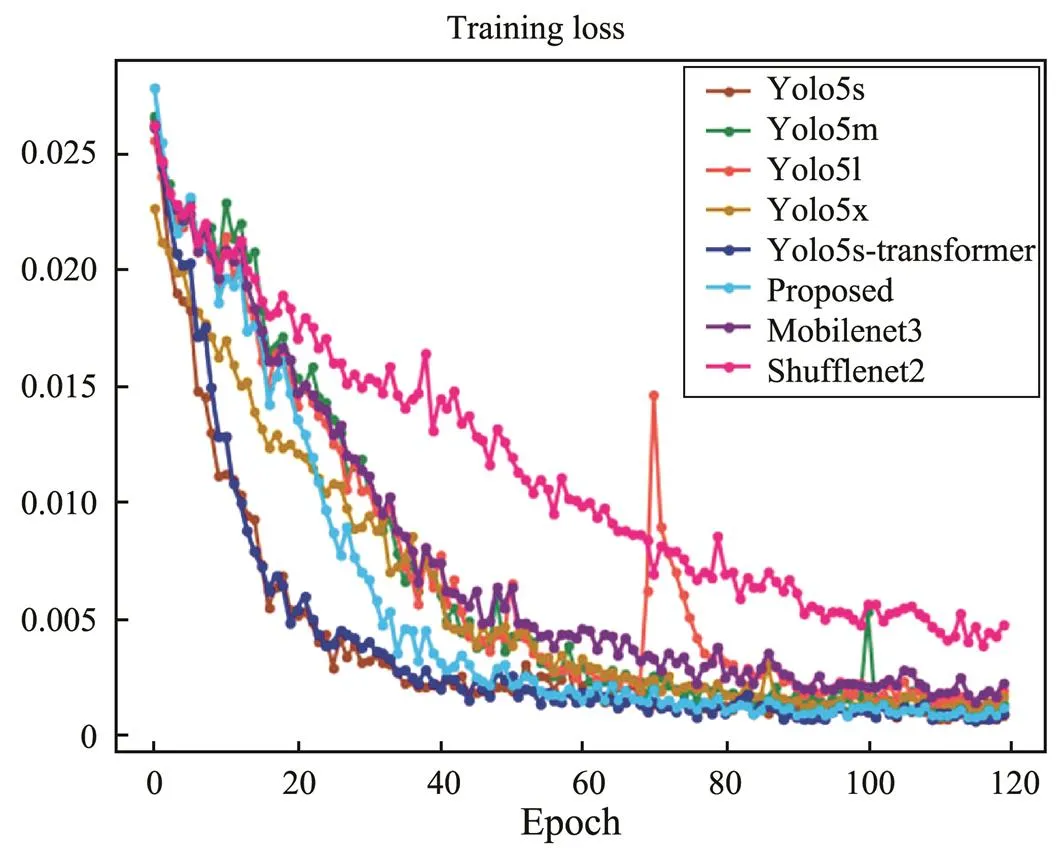
Fig.15 Training loss based on all methods.
4.3.2 Detection speed
In the experiment, we stitch 6s of sonar data into a complete SSS image. SSS sends approximately 60 pings per second; as the time to parse per second of original data is around 0.2s, then the total parsing time of one image is 1.2s, and the total time to obtain an image is 6+1.2=7.2s. Thus, the network processing and identification of one image time within 7.2s can meet the real-time requirement of AUV.
Table 8 reports the detection speed of all networks, including the times for network preprocessing, inference, and nonmaximum suppression (NMS). In addition, the results show the total time each model takes to detect one image and the number of parameters per network, which are directly proportional. Comparing the four networks of the Yolo5 series clearly shows that the larger the network size, the longer the detection time of the model. Yolo5x detects an image for more than 7.2s, which does not meet the re- quirements of AUV real-time processing. The MSPCM con- tains parallel branches and large convolution sizes, resulting in more network parameters and lower inference efficiency. Although our network does not show an optimal real-time performance, it takes about 2.4s to process one pi- cture. One SSS image can be detected before the next image arrives, and thus the network can meet the real-time pro- cessing requirements of embedded devices. The detection speeds of the two combined networks, Yolo5s-Mobilenet3 and Yolo5s-Shufflenet2, are both faster. HOG+SVM is thefastest. However, the detection accuracies of the three me- thods are not ideal.
5 Conclusions
This study proposes an MSPCM that can simultaneouslylearn rich feature information with different sizes. By combiningthe proposed module with Yolo5s and introducing the attention mechanism CBAM, several training tricks are added additionally–such as the improved calculation me- thod of anchor and the introduction of the data augmentation mechanism Mosaic–which effectively improves the small target detection accuracy in SSS images. According to the experimental results of the Yolo5 network series, deep- er networks do not necessarily have a beneficial effect on small target detection. The deeper the network, the more information is lost, especially for small targets. Therefore, when designing the backbone for extracting feature infor- mation, we must consider not only the depth but also the width of the network. Although the lightweight networks Mobilenet3, Shufflenet2, and traditional HOG+SVM can greatly improve the detection speed, too much is lost in terms of detection accuracy. The proposed method obtains the optimal detection accuracy and, despite its low real- time performance, can still meet the real-time detection requirements of AUVs.
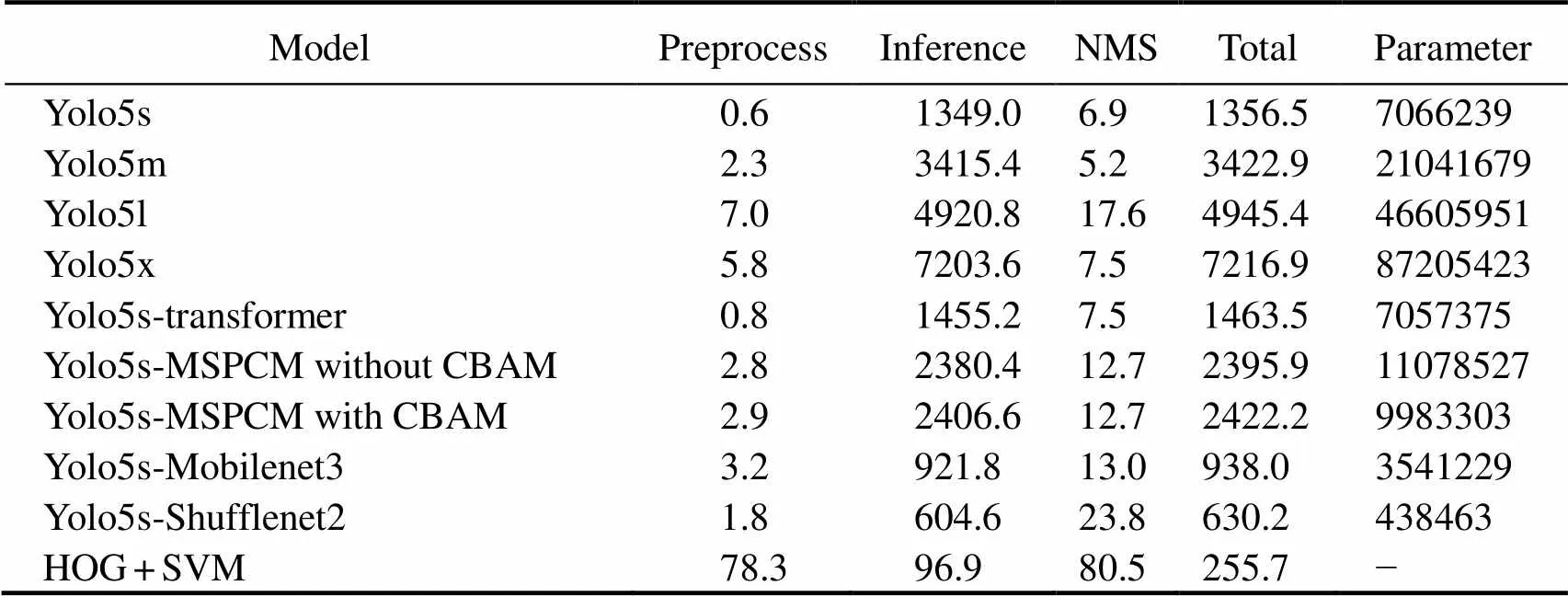
Table 8 Comparison results of detection speed (ms) of all networks
Acknowledgement
This work is supported by the National Key Research and Development Program of China (No. 2016YFC0301 400).
Bochkovskiy, A., Wang, C. Y., and Liao, H. Y. M., 2020. Yolov4: Optimal speed and accuracy of object detection.: 2004.10934.
Cai, L., Wang, C., and Xu, Y., 2021. A real-time FPGA accele- rator based on winograd algorithm for underwater object de- tection., 10: 2889.
Dalal, N., and Triggs, B., 2005. Histograms of oriented gradientsfor human detection.. San Diego, CA, USA, 886-893.
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., and Li, F. F., 2009. ImageNet: A large-scale hierarchical image database.. Miami, Florida, USA, 248-255.
Ge, Q., Ruan, F., Qiao, B., Zhang, Q., Zuo, X., and Dang, L., 2021. Side scan sonar image classification based on style trans- fer and pre-trained convolutional neural networks., 10: 1823.
Geraga, M., Papatheodorou, G., Agouridis, C., Kaberi, H., Iatrou, M., Christodoulou, D.,., 2017. Palaeoenvironmental implications of a marine geoarchaeological survey conducted in the SW Argosaronic Gulf, Greece., 12: 805-818.
Girshick, R., Donahue, J., Darrell, T., and Malik, J., 2014. Rich feature hierarchies for accurate object detection and semantic segmentation.. Columbus, OH, USA, 580- 587.
Glenn, J., 2020. Yolov5 tag2.0. https://github.com/ultralytics/ yolov5/tree/v2.0. Accessed Oct, 2023.
Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A.,., 2017. Accurate, large minibatch SGD: Train- ing imageNet in 1 hour.: 1706.02677.
He, K., Gkioxari, G., Dollár, P., and Girshick, R., 2017. Mask R-CNN.. Venice, Italy, 2961-2969.
Healy, C. A., Schultz, J. J., Parker, K., and Lowers, B., 2015. Detecting submerged bodies: Controlled research using side- scan sonar to detect submerged proxy cadavers.,60: 743-752.
Howard, A., Sandler, M., Chu, G., Chen, L. C., Chen, B., Tan, M.,., 2019. Searching for mobileNetv3.. Seoul, Korea, 1314-1324.
Ju, M., Luo, J., Liu, G., and Luo, H., 2021. ISTDet: An efficient end-to-end neural network for infrared small target detection., 114: 103659.
Karimanzira, D., Renkewitz, H., Shea, D., and Albiez, J., 2020. Object detection in sonar images., 9: 1180.
Kim, M., Jeong, J., and Kim, S., 2021. ECAP-YOLO: Efficient channel attention pyramid YOLO for small object detection in aerial image., 13: 4851.
Krizhevsky, A., Sutskever, I., and Hinton, G. E., 2012. ImageNet classification with deep convolutional neural networks.. South Lake Tahoe, NV, USA, 1097-1105.
Li, C., Ye, X., Cao, D., Hou, J., and Yang, H., 2021. Zero shot objects classification method of side scan sonar image based on synthesis of pseudo samples., 173: 107691.
Lin, T. Y., Dollár, P., Girshick, R., He, K., Hariharan, B., and Belongie, S., 2017. Feature pyramid networks for object detection.. Honolulu, HI, USA, 2117-2125.
Liu, S., Qi, L., Qin, H., Shi, J., and Jia, J., 2018. Path aggregationnetwork for instance segmentation.. Salt Lake, UT, USA, 8759-8768.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y.,., 2016. SSD: Single shot multibox detector.. Amsterdam, Netherlands, 21- 37.
Miao, L., Li, N., Zhou, M., and Zhou, H., 2022. CBAM-Yolov5: Improved Yolov5 based on attention model for infrared ship detection.,,. Harbin, China, 564- 571.
Nguyen, H. T., Lee, E. H., and Lee, S., 2020. Study on the classification performance of underwater sonar image classification based on convolutional neural networks for detecting a submerged human body., 20: 94.
Redmon, J., and Farhadi, A., 2017. Yolo9000: Better, faster, stronger.. Honolulu, HI, USA, 7263-7271.
Redmon, J., and Farhadi, A., 2018. Yolov3: An incremental im- provement.: 1804.02767.
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A., 2016. Youonly look once: Unified, real-time object detection., Las Vegas, NV, USA, 779-788.
Ren, S., He, K., Girshick, R., and Sun, J., 2015. Faster R-CNN: Towards realtime object detection with region proposal networks.Montreal, Quebec, Canada, 91-99.
Ronneberger, O., Fischer, P., and Brox, T., 2015. U-net: Convolutional networks for biomedical image segmentation.. Mu- nich, Germany, 234-241.
Simonyan, K., and Zisserman, A., 2014. Very deep convolutional networks for large-scale image recognition.: 1409.1556.
Su, N., He, J., Yan, Y., Zhao, C., and Xing, X., 2022. SII-Net: Spatial information integration network for small target detection in SAR images., 14 (3): 442.
Sun, C., Hu, Y., and Shi, P., 2020. Probabilistic neural network based seabed sediment recognition method for side-scan sonar imagery., 410: 105792.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D.,., 2015. Going deeper with convolutions.. Boston, MA, USA, 1-9.
Tang, Y. L., Jin, S. H., Xiao, F. M., Bian, G., and Zhang, Y. H., 2020. Recognition of side-scan sonar shipwreck image using convolutional neural network.. Taiyuan, China, 529-533.
Tian, Z., Shen, C., Chen, H., and He, T., 2020. FCOS: A simple and strong anchor-free object detector., 99: 1-13.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N.,., 2017. Attention is all you need.. Long Beach, CA, USA, 6000-6010
Venkatesan, S., 2016. AUV for search & rescue at sea–An innovative approach.. Tokyo, Japan, 1-9.
Wang, C. Y., Liao, H. Y. M., Wu, Y. H., Chen, P. Y., Hsieh, J. W., and Yeh, I. H., 2020. CSPNet: A new backbone that can enhance learning capability of CNN.. Seattle, WA, USA, 390-391.
Wang, H., Li, H., Zhou, H., and Chen, X., 2021. Low-altitude infrared small target detection based on fully convolutional regression network and graph matching., 115: 103738.
Woo, S., Park, J., Lee, J. Y., and Kweon, I. S., 2018. CBAM: Convolutional block attention module.. Munich, Germany, 3-19.
Ye, X., Li, C., Zhang, S., Yang, P., and Li, X., 2018. Research on side-scan sonar image target classification method based on transfer learning.. Charleston, USA, 1-6.
Zhang, G., and Wei, J., 2021. An improved small target detection method based on Yolov3.. Zheng- zhou, 220-223.
Zhou, T., Si, J., Wang, L., Xu, C., and Yu, X., 2022. Automatic detection of underwater small targets using forward-looking sonar images., 60: 1-12.
Zhou, W., Ming, D., Lv, X., Zhou, K., Bao, H., and Hong, Z., 2020. SO-CNN based urban functional zone fine division with VHR remote sensing image., 236: 111458.
(May 24, 2022;
August 25, 2022;
February 15, 2023)
© Ocean University of China, Science Press and Springer-Verlag GmbH Germany 2023
. E-mail: appletsin@ouc.edu.cn
(Edited by Chen Wenwen)
猜你喜欢
杂志排行

Journal of Ocean University of China的其它文章
- Effects of 5-Azacytidine (AZA) on the Growth, Antioxidant Activities and Germination of Pellicle Cystsof Scrippsiella acuminata (Diophyceae)
- Wave Radiation by a Floating Body in Water of Finite Depth Using an Exact DtN Boundary Condition
- Underwater Acoustic Signal Noise Reduction Based on a Fully Convolutional Encoder-Decoder Neural Network
- Revisiting the Seasonal Evolution of the Indian Ocean Dipole from the Perspective of Process-Based Decomposition
- Assessment of Storm Surge and Flood Inundation in Chittagong City of Bangladesh Based on ADCIRC and GIS
- Contraction of Heat Shock Protein 70 Genes Uncovers Heat Adaptability of Ostrea denselamellosa