容忍缺陷的木材多区段编号及识别算法研究
2023-12-20吴连旭徐哲壮
吴连旭,徐哲壮,林 烨
(福州大学 电气工程与自动化学院,福建 福州 350108)
0 引 言
在木制品加工行业,木制品通常由大量木材配件拼接而成[1]。未经加工的木材原料往往存在虫洞、死结、裂缝等缺陷,会影响产品的美观和功能[2]。因此需要借助机器视觉等方式对于木材缺陷进行检测,进而在后续工艺中切除。为了在缺陷检测和截锯等环节对木材原料进行精准匹配,木材的编号与识别算法设计成为了重要的研究课题。
目前已有对于编号识别的研究。Wang 等人[3]总结了针对车牌字符倾斜、模糊等识别的算法,并比较了不同车牌识别系统在数据集、工作站、准确率和时间上的差异;Fan 等人[4]提出了一个全卷积序列识别网络(FCSRN),用于快速准确地读取水表号码,FCSRN 能够捕获上下文信息,同时只需更少的参数和更少的计算;Xiang 等人[5]提出了一种基于多向照明图像融合增强技术的金属冲压字符识别算法,可有效消除油污、锈蚀、氧化、喷丸坑、不同背景颜色等因素的干扰,增强MSCs 与背景的对比度。上述方法针对字符在不同场景下的特征提出了不同的识别算法,但由于木种和缺陷等因素的影响,木材原料表面具有较大的差异,这使得现有研究成果难以在木材表面的编号识别上达到良好的识别精度。
针对上述问题,本文首先分析了木材原料的缺陷特征,通过现场采集数据分析缺陷分布情况。基于分析结果,本文提出了容忍缺陷的木材多区段编号及识别算法。该算法的基本思想是将木材原料的前段划分为多个区段,在多个区段上打印相同的编号,以避免单一编号被木材缺陷影响而难以识别。并采用YOLOv5[6]对多个区段的编号进行检测,紧接着将检测结果进行组合判断,最终得出木材的编号。实验结果表明,本文所提出的算法能够有效容忍木材缺陷对编号识别造成的影响。
1 问题分析
1.1 系统概述
系统由喷码机、工业相机、计算机终端设备以及截锯机床组成。由喷码机对木材原料进行编号打印,再由工业相机采集木材编号图像,并将采集的图像传输到计算机终端,通过计算机终端对采集的图像进行处理并识别,获取木材编号,并反馈至截锯机床。
如图1 所示,当编号打印在虫洞、腐蚀、死结、裂缝等缺陷上时,编号特征会消失,无法被正确识别。因此,如何消除缺陷对木材编号识别造成的影响成为本文主要研究的内容。
1.2 缺陷分布分析
在实际木材加工生产过程中,木材原料沿着长度方向在传送带上输送。为了第一时间获取木材编号,选取长度为29 cm 的木材原料的前段作为编号打印区域。
通过相机对750 根木材原料的前段(如图2 所示)进行采集,并对所采集的前段原料进行缺陷统计。结果见表1 所列,有缺陷的木材原料共有256 根,占比为34.13%。由此可知,编号有可能被打印在缺陷上,进而导致其无法被正确识别。

表1 带有缺陷木材原料的数量

图2 木材原料的前段
为了分析缺陷在木材原料前段的分布情况,将前段划分为多个区段,并统计各个区段的缺陷情况。如图3(a)所示,将木材原料前段的长度方向记为y轴,宽度方向记为x轴,建立直角坐标系。分别把木材原料的前段以y轴为方向平均划分为2 个区段与3 个区段。划分为2 个区段时,最上面的区段记为区段A,最下面的区段记为区段B(如图3(b)所示)。划分为3 个区段时,最上面的区段记为区段A,中间的区段记为区段B,最下面的区段记为区段C(如图3(c)所示)。

图3 木材原料前段的多区段划分
当木材原料的前段被划分为2 个区段时,对256 根带有缺陷的木材原料分区段进行缺陷分布统计分析,结果见表2所列。

表2 2 个区段的缺陷分布情况
根据表2 可以看出,缺陷分布在区段A 的木材原料有84 根,分布在区段B 的木材原料有93 根,既分布在区段A又分布在区段B 的木材原料有79 根。由于存在缺陷分布在区段A 又分布在区段B 的情况,因此将编号打印在木材原料的区段A 与区段B 时,并不能消除缺陷对编号识别的影响。
当木材原料的前段被划分为3 个区段时,进行相同的分区段缺陷分布统计分析,结果见表3 所列。

表3 3 个区段的缺陷分布情况
根据表3 可以看出,缺陷分布在区段A 的木材原料有53 根,分布在区段B 的木材原料有43 根,分布在区段C 的木材原料有48 根,既分布在区段A 又分布在区段B 的木材原料有40 根,既分布在区段B 又分布在区段C 的木材原料有59 根,既分布在区段A 又分布在区段C 的木材原料有13 根,不存在缺陷同时分布在区段A、区段B、区段C 的情况。因此,将编号分别打印在木材原料的区段A、区段B、区段C 时,可有效保证字符特征在某个区段内完整呈现。
2 编号打印与识别
为实现木材编号的识别,根据上述统计结果,通过打印机在木材原料多区段上打印,之后根据不同区段的检测结果确定木材编号。
在对编号进行打印时,调整喷码机[7-9]的打印延时,将编号打印在木材原料的不同区段。获取木材原料图像后,将木材原料图像沿长度方向等分,接着分别对各部分图像进行识别,以识别出最多次数的编号作为木材编号。
2.1 编号打印
在进行编号打印时,需要考虑木材原料划分区段个数对后续编号识别处理带来的影响。当划分的个数越多,所需要识别的图像数量也随之增加,从而导致识别木材编号的时间增长,进而影响木材原料截锯加工的效率。因此,在保证木材编号准确识别的前提下,应采用最少的区段划分对木材原料进行编号打印。
木材编号打印的具体过程:当木材原料进入编号待打印位置时,通过传感器触发喷码机进行编号打印,此时根据木材原料被划分的区段个数n,木材原料前段的长度l以及传送带的运行速度v,喷码机的打印时间间隔t应设定为t=l/(n×v),打印过程如图4 所示。

图4 木材编号打印过程
2.2 编号识别
目前用于字符编号识别的方法主要分为两大类,分别为传统图像处理与深度学习。传统图像处理方法一般由图像预处理、字符定位、字符分割以及字符识别等部分组成[10]。在进行特征提取时,主要依赖人工设计的特征提取器,针对某种特定应用,泛化性及鲁棒性较差。由于木材原料表面存在纹理、缺陷、染色等因素,因此,在进行图像预处理、字符定位时,并不能达到精准定位的效果,因而不能确保木材编号的准确识别。而深度学习方法主要基于数据驱动进行特征提取,根据大量样本的学习得到深层的、特定的特征表示,所提取的抽象特征鲁棒性更强、泛化能力更好。
目标检测(Object Detection)[11-12]是深度学习的三大基础任务之一,它具有快速定位目标、分类精准等优点。YOLO(You Only Look Once)[13-14]网络是一种one-stage 目标检测算法,其中YOLO 的第5 代,即YOLOv5 相对其它目标检测的网络结构,具有快速识别和自适应锚框等优点[6]。因此,本文采用YOLOv5 作为木材编号识别的方法。
木材编号识别的具体过程:把提取的木材原料图像切分为n张,再分别对n张切分后的区段图像进行识别,并判断每张区段图像识别出的编号字符个数与打印时设定个数是否相同,把个数相同的结果进行组合形成集合,记为{id1,id2, ..., idt},其中t≤n。统计各不同编号出现的次数,如式(1)所示,ID={id1, id2, ..., ids}表示各不同编号的集合,k表示相同编号次数,f表示分别统计不同编号出现的次数。最后,将最大统计次数km所对应的编号idm取出,作为木材的编号,如式(2)所示。
如图5 所示,以木材原料的前段被划分为3 个区段为例:

图5 木材编号识别流程
(1)将提取到的木材原料图像以3 个区段进行切分。
(2)把3 张切分好的图像放入YOLOv5 网络进行编号识别,区段B,区段C 分别识别出的结果为6A,由于木材缺陷的影响,区段A 识别出的结果为6B。
(3)将区段A,区段B,区段C 识别出的结果进行组合判断,得到木材的编号为6A。
3 实验结果与分析
3.1 实验平台
如图6 所示,实验平台主要由工业相机、喷码机、流水线系统组成,同时,还包含一台服务器进行深度学习模型训练以及实时木材编号检测。服务器的配置为:AMD Ryzen 5 5600G with Radeon Graphics 的CPU,NVIDIA GeForce GTX 1660 SUPER 的GPU 和16G 内存,搭载Windows 10 系统。通过此系统,对木材编号的打印策略以及识别方法进行实验对比分析,以此验证本文提出算法的有效性。
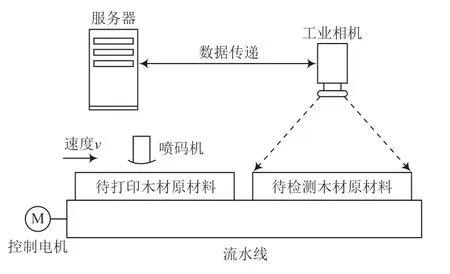
图6 实验平台
3.2 实验指标
实验通过准确率(Accuracy)、查准率(Precision)、召回率(Recall)以及木材编号检出率,即正确识别木材编号的木材原料数量来衡量本文方法的有效性。
准确率(Accuracy)、查准率(Precision)以及召回率(Recall)的公式如下[15]:
式中:TP、TN、FP、FN 分别表示检测中真正例、真反例、假正例、假反例的数量。
3.3 实验结果分析
分别对1 000 根木材原料的前段划分为2 个区段,3 个区段,4 个区段,然后进行编号打印,并与1 个区段的打印方式进行木材编号识别对比分析,实验结果见表4 所列。由实验结果可知,把木材原料的前段划分为3 个区段时,已经能达到接近100%的检出率,而在划分为4 个区段时,检出率并未得到提升。因此,为保证木材原料截锯加工的加工效率,应采用划分为3 个区段的木材编号打印方式。
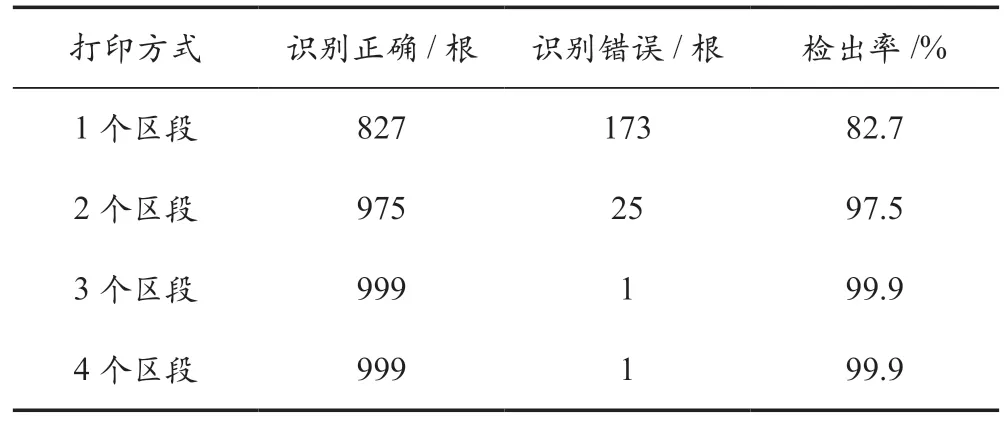
表4 木材编号的检出率
YOLOv5[6]算法根据网络宽度与深度分为4 种模型,依次为YOLOv5s、YOLOv5m、YOLOv5x 和YOLOv5l, 精度逐渐提高,但检测速度逐渐降低。本文对1 000 张编号没有打印在缺陷上的木材原料图像分别使用YOLOv5s、YOLOv5m 编号识别的方式(这里以IOU>0.5 作为YOLOv5识别正确的阈值)与颜色特征+CNN 编号识别的方式进行木材编号识别的对比分析。其中,颜色特征+CNN 是通过对字符颜色进行提取,找到字符区域,并对找到的字符区域进行分割,放入CNN 卷积神经网络进行分类识别,并将识别结果进行组合形成木材编号的方式。实验结果见表5所列。其中,YOLOv5s 与YOLOv5m 的参数量、浮点运算数、模型规模、推理速度见表6 所列。

表5 不同方法的识别精度

表6 模型性能对比
根据表5 可以看出,当使用YOLOv5 编号识别的方式相比颜色特征+CNN 编号识别的方式在准确率上有显著提升。因此,采用YOLOv5 可以有效、准确地识别木材编号。
根据表6 可以看出,使用YOLOv5m 与使用YOLOv5s 的识别准确率一致,但模型的参数量增大了197.0%,在CPU和GPU 上的推理速度增加了65.7% 和114.3%。因此,在保证精度的前提下,应使用YOLOv5s 作为木材编号识别的算法。
4 结 语
本文针对缺陷对木材编号识别产生的影响提出了一种容忍缺陷的木材多区段编号及识别算法。通过对木材原料前段缺陷情况的分析,将木材原料的前段划分为多个区段,并分别对各区段进行编号识别,将识别次数最多的编号作为木材编号。通过实验讨论了不同区段划分的木材编号检出率,以及不同识别算法的木材编号识别精度。实验结果证明,把木材原料的前段划分为3 个区段的编号打印方式相对于不进行区段划分的打印方式,木材编号检出率提高了17.2%。同时,使用YOLOv5 编号识别的方式相比颜色特征+CNN 编号识别的方式,识别精度提高了28.7%。因此,采用本文所提出的算法能够有效容忍木材缺陷对编号识别的影响,提升木制品工业的生产效率。
注:本文通讯作者为徐哲壮。
