针对目标遮挡的自适应特征匹配网络
2023-12-19苏宏阳杨大伟
毛 琳, 苏宏阳, 杨大伟
(大连民族大学 机电工程学院,辽宁 大连 116600)
1 引 言
目标跟踪是计算机视觉领域中一个重要研究方向,其任务是准确跟踪给定视频序列中的标注目标,如行人、车辆、动物等。目标跟踪应用非常广泛,如视频监控、自动驾驶、机器人视觉等,但由于目标在视频中普遍存在遮挡、消失等现象,会极大降低现有算法的准确性和鲁棒性,使算法在实际应用中可靠性降低。
目标遮挡是目标跟踪中常见挑战之一,传统目标跟踪算法往往无法应对目标遮挡带来的问题,导致跟踪效果下降。近年来,研究者们开始使用深度学习来解决遮挡问题。一类基于深度学习的目标跟踪算法利用强化学习思想,在目标遮挡的情况下,动态调整跟踪器行为,以适应目标的变化。例如,ATOM[1](Accurate Tracking Overlap Maximization)通过设计两个模块,一个模块进行训练,不断增强检测框与真实结果重叠率,另一个模块则是分类模块,用于前景背景判别,以此获得更高的跟踪精度。PrDiMP[2](Probabilistic Regression for Visual Tracking)则在ATOM 基础上,通过融合置信度回归方法,进一步优化概率回归模型,取得更加准确的回归结果。另一类基于深度学习的目标跟踪算法则采用孪生神经网络结构,以SiamRPN[3]为基础的许多目标跟踪算法将目标跟踪看作一个相似度匹配问题,通过学习模板和搜索区域的相似度来进行目标定位,配合复杂的特征后处理来应对目标遮挡、目标消失等挑战。如通过级联区域建议网络(Region Proposal Network,RPN)[4,5],来生成更多的区域建议框,以达到更准确的跟踪。此外,还有一些目标跟踪算法利用分割技术,在原有的分类和回归分支基础上,增加预测目标分割掩码的分支[6-7],通过分割算法将目标分割出来,将跟踪问题转化为一个前背景分类问题,实现跟踪和分割的互补,提高了跟踪的准确性。以上算法均取得不错成绩,但由于引入复杂的特征后处理,导致更多的计算,并且更加依赖超参的设置。总的来说,基于深度学习的目标跟踪算法已经取得了一定进展,但面对目标完全遮挡时,算法很难找到目标位置,往往需要设计繁琐的手工特征和复杂的特征后处理。
在最近,Fei Xie 等人提出EoC[8](Extract or Correlation)模块,EoC 模块中集合了自注意力和交叉注意力(Self-Attention,SA;Cross-Attention,CA),作者以EoC 模块构建骨干网络,通过在特征提取过程中不断计算相关性,获得良好的跟踪性能。而Yutao Cui 等人则在MixFormer[9]中提出了一种混合注意模块(Mixed Attention Module,MAM),可以同时进行特征提取和特征融合,获得优异的算法性能。
同时,在目标分割领域,针对时间信息利用不充分的问题,Oh Seoung Wug 等人提出了一种基于时空记忆网络的视频对象分割方法[10],通过在时间和空间维度上建立记忆单元来捕捉视频中对象的运动和形状信息。Xie Haozhe 等人提出了一种高效的区域记忆网络[11],通过学习目标区域和背景区域之间的相互关系来提高分割精度和效率。Paul Matthieu 等人提出了一种局部记忆注意力网络[12],利用局部上下文信息来提高分割效果,并加速模型推理。Wang Hao 等人提出了一种时序记忆注意力网络[13],通过在时间维度上建立记忆单元来建模视频序列的长期依赖关系,从而提高视频对象分割的精度。
综上所述,为解决目标跟踪中常见的目标遮挡问题,本文算法结合相关滤波和MixFormer 的思想,提出一种自适应特征匹配网络,该网络通过目标特征互相关计算,对目标特征进行自适应加权,提高特征匹配准确度。同时,本文借鉴分割领域中记忆网络的思想,构建一个特征记忆网络,用于缓解目标跟踪中时间信息利用不充分问题。通过利用特征记忆网络,算法能够更好地适应跟踪目标在时间序列中的运动和变化,即使在目标完全遮挡时也能自适应推断目标位置,从而提高跟踪的精度和稳定性。在数据集上的实验结果表明,本文算法在解决目标遮挡问题方面具有更好的表现,能够更准确地跟踪目标,并且在完全遮挡情况下也能保持较高的跟踪精度。
2 自适应特征匹配网络
针对目标遮挡的自适应特征匹配网络算法框架在文献[14]的基础上构建,如图1 所示,可将其分为四个部分:骨干网络、自适应特征匹配网络(Adept Feature Match Network,AFMN)、特征记忆网络(Feature Memory Network,FMN)、分类回归网络。

图1 整体网络框架Fig.1 Overall network framework
2.1 骨干网络
在运动目标的处理过程中,常常会遭遇尺度变化和遮挡等问题,这时无法获取完整的目标特征,只能获得局部特征,这就可能导致跟踪错误。因此,本文旨在研究如何有效利用局部特征。为实现这一目标,本文采用Inception V3 作为骨干网络,并进行迁移学习。Inception V3 同时使用多个尺度的卷积核来提取特征,这种设计使得模型能够适应不同尺度的图像,提高了模型的鲁棒性。此外,该模型还采用1×1 卷积核来减少模型的参数量和计算复杂度,同时增加了模型的非线性和表达能力。通过卷积层、池化层、批量归一化等操作,该模型将输入图像转换为高维特征向量,并逐渐提取越来越抽象的特征,以区分不同的目标,为后续处理和跟踪任务提供支持。
在训练过程中,使用相同的结构来构建查询帧和记忆帧的骨干网络,但不共享它们之间的权重,将其分别表示为Φq,Φm。在骨干网络提取特征完成后,分别使用自适应卷积层τq,τm对骨干网络的输出进行处理,以适应后续的特征处理操作,具体可用公式表示为:
2.2 AFMN
在目标跟踪中,大多数算法通常依赖目标区域特征来进行跟踪。然而,当目标发生遮挡时,无法获取目标完整信息,导致算法在前背景分类和检测框回归时出现偏差,使得预测位置偏离实际轨迹,就会产生跟踪漂移的问题,如图2 所示。

图2 跟踪漂移示意图Fig.2 Schematic diagram of tracking drift
针对目标遮挡产生的跟踪漂移问题,分析其产生原因,以图2 为例,由分数响应图可以看出,在分类阶段,由于目标被遮挡,目标区域得分急剧降低,又因为存在与目标相似的背景,导致算法错误的给背景赋予较高分数,而将目标分类为背景。由跟踪图可以看出,在回归阶段,受前背景分类的影响,导致回归精度大大降低。进一步,在进行下一帧跟踪时,由于受到前一帧跟踪结果的影响,算法将上一帧跟踪结果进行特征匹配,使算法误把背景作为目标进行跟踪,造成了跟踪漂移的问题。
针对上述问题,本文在实验中发现,获得骨干网络提取的特征后,其多通道的特征图中存在许多相似或重复的特征,这可能会对特征匹配造成干扰,尤其在目标遮挡时更为明显。
为解决这个问题,如图3 所示,对骨干网络的输出fq和fm,将其按通道拆分为h份,拆分过程可表示为:
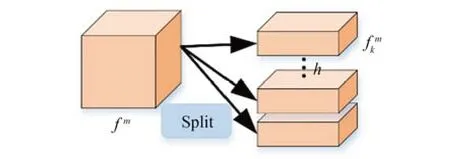
图3 特征图拆分示意图Fig.3 Schematic diagram of feature map splitting
将二者进行分头后,不仅可以解决相似和重复特征对跟踪造成的影响,还可以通过多次计算fq和fm之间的相似度,对二者的相似性关系进行多维度观察,提高特征的利用效率,并进行自适应的特征检索,为特征匹配提供更多参考,减小误判的可能。如图4 所示,在进行特征图拆分后,通过多次计算相似性关系,生成多个目标响应,为算法提供更多选择,通过训练,最终实现正确的跟踪。

图4 多响应分数图Fig.4 Multi-response fractional graph
因此,为了更准确地确定目标位置,本文将骨干网络提取的特征进行分头,提出一种基于相关滤波和注意力的方法,计算目标逐像素的相似度,通过被遮挡目标暴露部分进行局部到局部的特征匹配,从而显著提高目标定位精度。该方法将特征图转换为一维向量,并通过计算特征图向量像素间的点积相似度,判断不同特征之间的互相关程度。然后,将这些点积相似度作为权重系数组成权重矩阵,对记忆帧特征图进行加权,筛选目标特征,并与查询帧特征拼接,最终进行分类回归操作,实现自适应的特征匹配。这种方法可以更好地解决目标遮挡问题,提高跟踪算法的精度和鲁棒性。整体结构图如图5 所示。
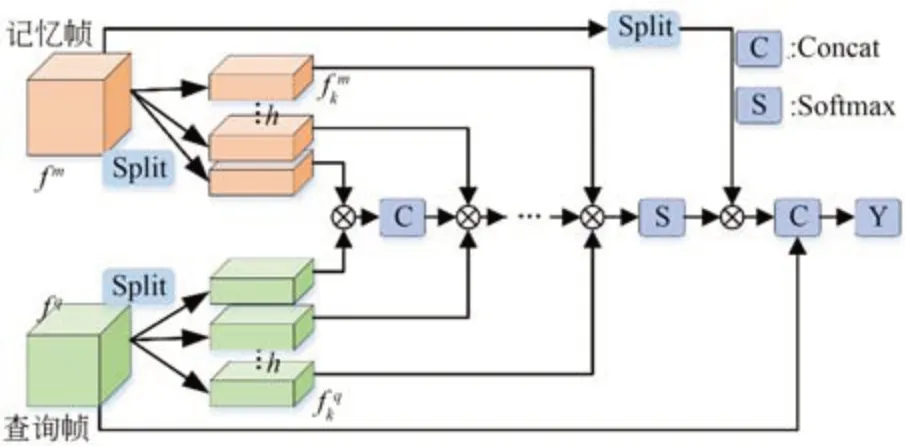
图5 AFMN 结构图Fig.5 AFMN block diagram
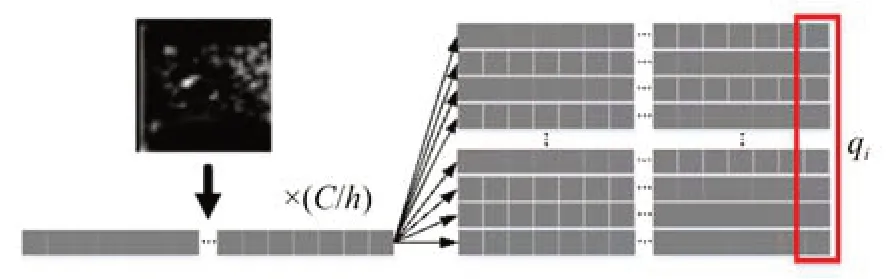
图6 特征图向量示意图Fig.6 Schematic diagram of feature map vector
随后,通过矩阵乘法计算向量qi和mj之间的点积相似度,由点积的几何意义可知,两个向量之间的点积结果越大,则代表两个向量越相似,以此获得权重矩阵wk,可表达为如式(4)所示:
式中,通过矩阵乘法的方式,实现了计算不同特征图像素之间的点积相似度为计算获得的2 维矩阵,其中每个元素代表了和特征图任意两个像素点之间的相似程度。随后,使用softmax 函数对其进行归一化处理,为权重矩阵不同元素赋予相似度分数,将其表达为式(5)的形式,式中,exp 为指数操作,作为除数防止指数操作过程中数值溢出,θ为qi和mj的相似度夹角。可以得出,wk经过softmax 函数归一化处理后,其中每一元素都根据相似程度被赋予不同的相似度分数,将其对进行特征加权,便可对中不同目标特征实现自适应的注意操作,可表达为如式(6)所示:
式中,为方便计算,将权重矩阵wk进行转置,表达为(wk)T,并与'进行矩阵乘法计算,其中,,包含了和任意两个特征图像素点的点积相似度,则包含记忆帧C h个通道的特征图像素点。使用权重矩阵wk对的每一通道、每一像素点进行自适应加权,以关注的不同区域,并获得概率矩阵Mk,并将其简化为式(7)。式中,cosθ,cosβ为向量点积之间的夹角,i,j分别为qi和mj的索引,v为mj像素点的索引。当i,v=1 时,代表特征图第1 个像素点与第1 个通道特征图的全部像素点相似度总分。当i=HW,v=C h时,代表特征图第HW个像素点与第C h个通道特征图的全部像素点相似度总分。
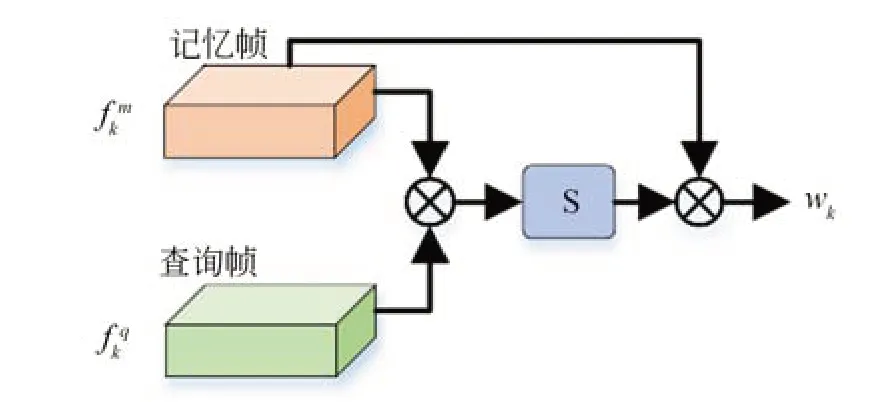
图7 点积相似度计算Fig.7 Calculation of point-product similarity
其中:h为所分头数,k为头数的索引,C,H,W分别表示矩阵的行数、列数和通道数。
通过式(8)计算得到的概率矩阵涵盖记忆帧中所有可能目标特征,即使目标被部分遮挡也能自适应检索目标的局部特征,并通过局部特征匹配来完成跟踪过程。将该概率矩阵与查询帧特征矩阵进行拼接,可得到AFMN 模型的最终输出Y。具体可表达为:
该输出能够指导后续的分类和跟踪任务。具体来说,上述方法获得的输出能够有效关注目标特征信息,在进行特征匹配时给予目标所在区域更高的评分,从而实现更精确的跟踪结果。
2.3 FMN
为有效利用历史帧提供的目标信息,本文算法将回归跟踪框后的图像帧存储在特征记忆网络中。在每次跟踪新的查询帧时,从FMN 中选择相应的记忆图像,并通过骨干网络进行特征提取。由于孪生神经网络的特性,骨干网络可以提取与查询帧目标相似的特征。将记忆特征与查询帧特征一起输入到AFMN 中,即使目标被遮挡,由于AFMN 是逐像素计算相似度,因此也可以实现局部到局部的特征匹配。本文认为初始帧包含最准确的目标特征,而与查询帧相近的记忆帧包含与查询帧最相似的特征,因此记忆帧包含第一帧和查询帧的前一帧,余下T-2 帧通过以下公式来进行选取:
其中:T为要选取的帧数,P为当前帧的索引,l为间隔系数,即隔多少帧选取一张记忆帧,idx即为最终的记忆帧索引。通过记忆帧的选取,整个算法通过对多帧目标位置进行学习,在目标被完全遮挡时,也可以自适应推测目标存在位置,并具有较高的精度。
2.4 分类回归网络
根据文献[15]阅读发现,无锚检测器在检测框的标定和回归方面表现更佳且参数更少,因此采用无锚头网络进行分类回归任务。如图8 所示,该网络包含分类分支、中心度分支和回归分支,每个分支分别使用轻量级网络γcls,γreg中的七个卷积层对AFMN 传入的数据进行处理,然后使用单个卷积层wcls,wctr,wreg将其降维以进行分类回归。分类分支用于目标背景分类,中心度分支使用FCOS的中心度公式来加强预测框回归效果,回归分支直接估计目标位置并进行检测框标定。

图8 分类回归网络Fig.8 Classification regression network
在本任务中,为解决目标遮挡问题,采用一系列损失函数。首先,分类分支采用FocalLoss损失函数,可用公式表示为:
其中:Loss表示损失函数值,N表示批次大小,H和W分别表示预测结果的高度和宽度,pij表示预测结果中位置i,j的概率,mij表示掩码,α和γ是可调节的超参数,用于表示损失的重要程度。该损失函数能够有效应对样本不均衡的情况。通过调整难易样本的权重,FocalLoss 使模型更关注难以跟踪的目标,从而提高对少数类别目标的学习能力,进一步提升跟踪准确性。
其次,中心度分支使用交叉熵损失函数,并结合特征图像素点与目标中心点的距离进行权重赋值。可用公式表示为:
其中:yi是目标中心度的标签,ŷi是预测的中心度值,N是样本的数量,λ是权重参数,用于调节损失值权重。通过交叉熵损失函数对比预测的中心度值和目标中心度的标签值,来衡量模型的中心度预测准确程度,并对背景标签进行了排除。最终计算所有样本损失的平均值,并根据权重参数进行损失调节。这种距离加权策略能够抑制远离目标中心点的像素得分,使模型更加关注目标的中心区域。
对于回归分支,采用IOU 损失函数来拟合更准确的预测框坐标。可用公式表示为:
式中,IOU代表预测框与标签的交并比。
最后,将上述损失函数作为子损失函数,采用多元交叉熵损失进行最终的损失计算,权重比例为0.2∶0.2∶0.6。这样的设置在文献[14]中得到了论证,能够综合考虑分类、中心度和回归任务,使模型更好地适应目标跟踪任务的特性,提升整体性能。
3 实验结果分析
3.1 实验设计
本文网络使用GOT-10k,COCO 和LaSOT数据集进行训练。骨干网络采用预训练的Inception V3 模型,将AFMN 的h和FMN 的T都设为3,训练过程采用SGD 优化器,整个训练过程包括20 个周期,每个周期包含38 000 个数据,初始学习率设为1×10-6,在第一个周期,采用线性学习率,使其增长至6×10-3,随后两个周期,采用余弦退火学习率,学习率从6×10-3呈余弦变化下降至1×10-6,并在后续所有周期中保持1×10-6不变。
3.2 算法对比
为了全面地验证本文算法的有效性,在多个目标跟踪数据集上进行了测试,包括OTB-2015,VOT2018,GOT-10k 和LaSOT 数据集。这些数据集具有挑战性和多样性,能够评估算法在不同场景下的鲁棒性和准确性。
在测试中,本文算法表现出良好的跟踪效果。如表1 所示,算法在OTB-2015 数据集上表现出色,跟踪精度优于大多数的跟踪器。但在VOT2018 数据集中,如表2 所示,跟踪准确度低于绝大多数跟踪器,鲁棒性却优于其他跟踪器,这是因为VOT2018 评估工具中所提供的跟踪框是旋转的,而本文算法回归的跟踪框是平行于x轴和y轴的,因此在VOT2018 数据集中的表现会受到一定影响,但这也侧面印证了本文算法具有良好的鲁棒性。此外,如表3 所示,在GOT-10k数据集上,算法也取得很好的跟踪效果,相比于STMTrack 算法,AO提高了1.8%,SR0.5提高了2.4%,SR0.75提高了1.9%,并且超过了平均性能水平。在LaSOT 数据集上,本文算法也表现出了竞争力,能够在跟踪任务中取得良好的结果。总的来说,本文算法在多个数据集上的测试结果都表现出了较好的鲁棒性和准确性。同时,针对目标遮挡、目标消失和背景干扰等情况时,具有更高的鲁棒性。面对复杂场景时的跟踪效果在可视化分析部分进行展示。
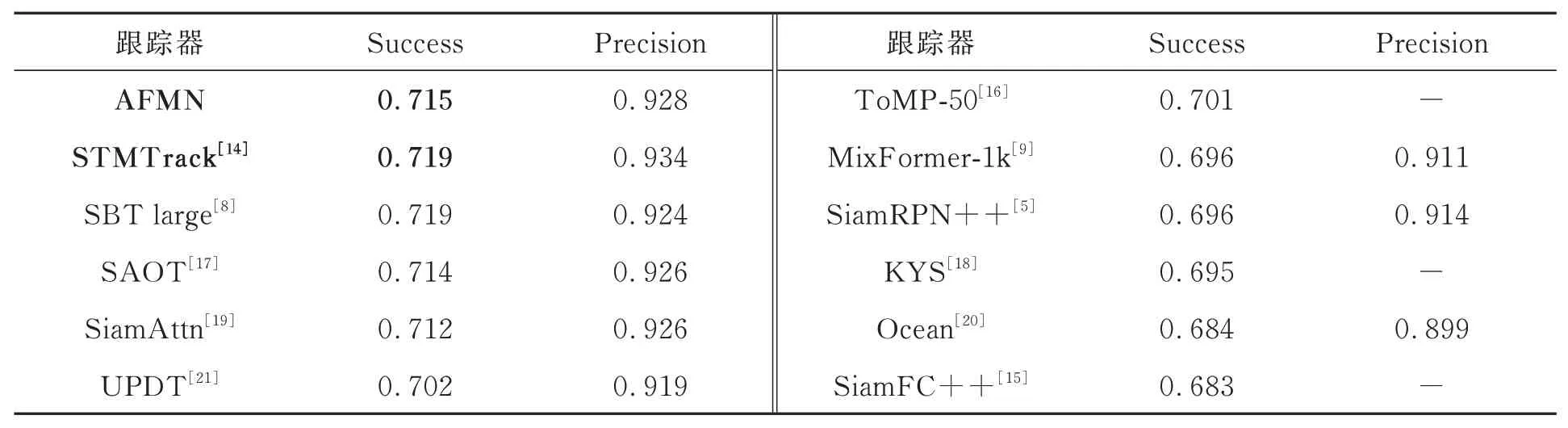
表1 在OTB-2015 数据集上,AFMN 与其他跟踪器的比较Tab.1 On the OTB-2015 dataset, AFMN compares to other trackers

表2 在VOT2018数据集上,AFMN 与其他跟踪器的比较Tab.2 AFMN compares to other trackers on VOT2018 dataset
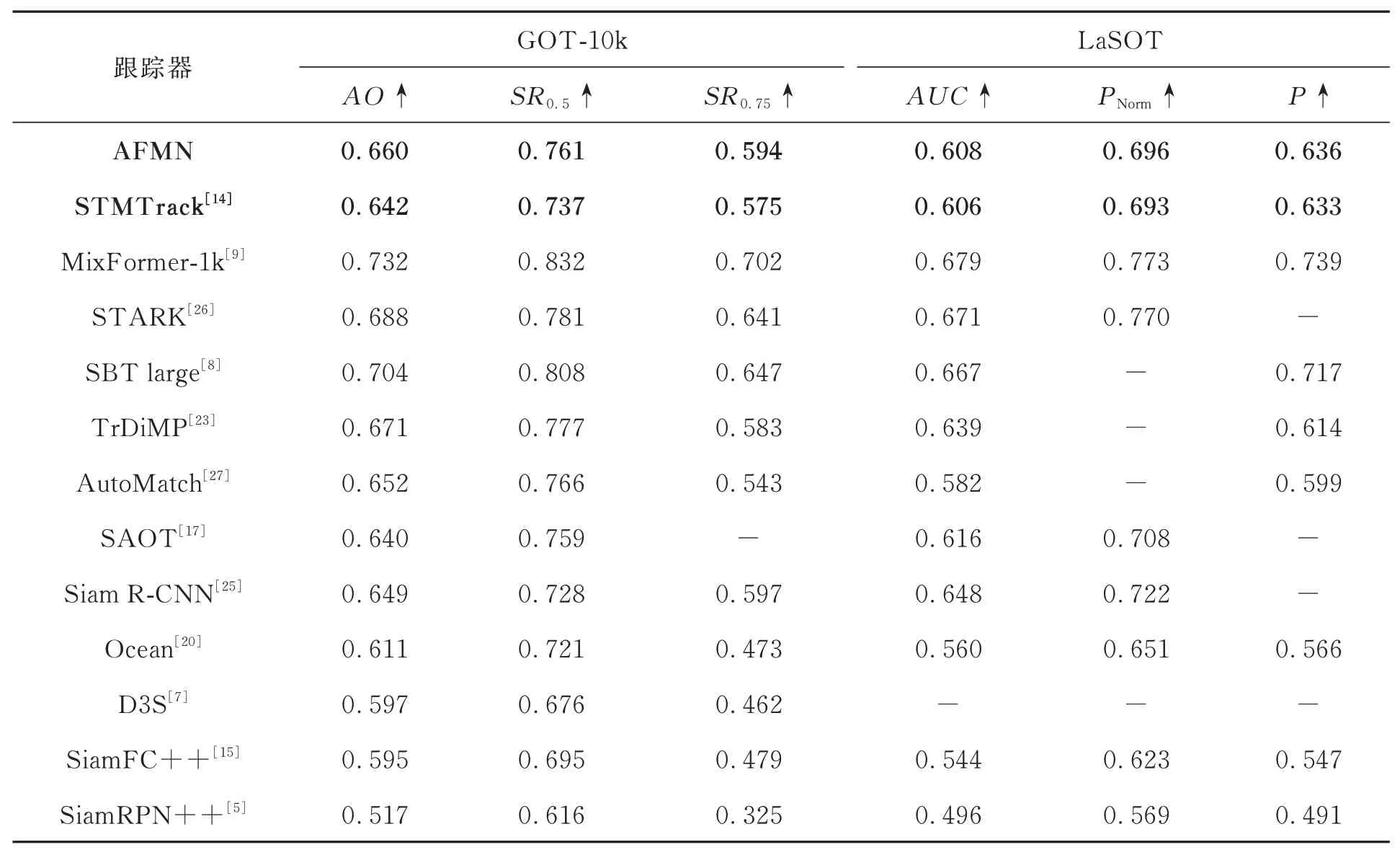
表3 在GOT-10k 和LaSOT 数据集上,AFMN 与其他跟踪器的比较Tab.3 AFMN compares to other trackers on GOT-10k and LaSOT dataset
3.3 可视化分析
为了验证本文算法在目标遮挡场景下的性能,本节使用包含遮挡目标的视频序列进行算法性能的评估和分析,将本算法与STMTrack 算法进行对比,如图9 所示,本文算法在面对目标遮挡和目标消失时,仍然可以准确对目标进行定位和跟踪,在图9(c)中,目标被完全遮挡,由于本文算法是多记忆帧计算目标相似度,网络可以隐性的学习目标运动趋势,进而对目标所在位置进行估计,所以实现了更准确的跟踪。这些结果表明,本文算法可以有效地解决遮挡问题,提高跟踪精度和鲁棒性。进一步证明了本文算法在目标遮挡状态下的有效性。

图9 可视化对比Fig.9 Visual comparison
同时,图10 展示了本文算法在目标遮挡场景下更多的跟踪效果,在图10(a),图10(c)和图10(d)中,目标被部分遮挡,均实现了准确跟踪,在图10(b)中,目标短时间内完全消失,本文算法依旧自适应推断出了目标位置。实验结果表明,本文算法在目标遮挡状态下具有良好的鲁棒性和稳定性。

图10 目标遮挡场景下的可视化结果Fig.10 Visualization results in the object occlusion scenario
3.4 消融实验
为验证AFMN 中特征图拆分份数对跟踪结果的影响,仅在GOT-10k 数据集上进行训练和测试。该数据集包含超过10 000 个视频序列,其中涵盖了大量目标遮挡场景,因此能够有效验证本文算法的有效性。实验结果如表4 所示。
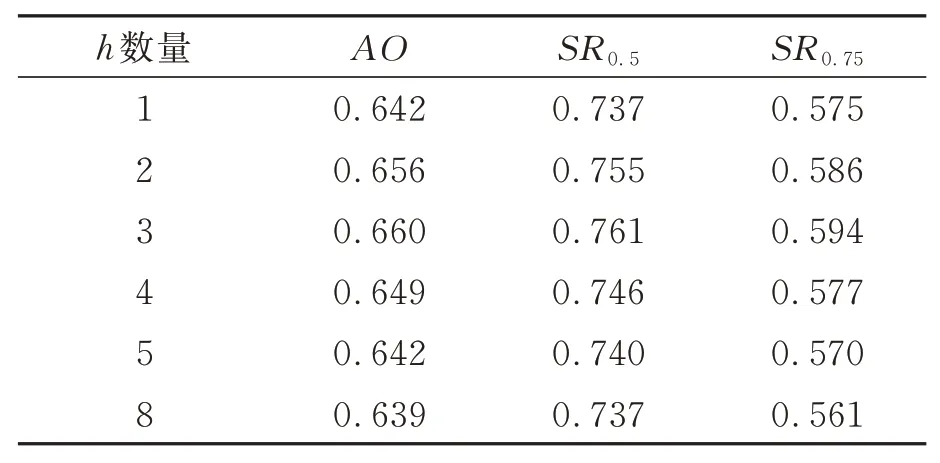
表4 h 对AO 的影响Tab.4 Influence of h on AO
根据表4 可以得出结论:当特征图被拆分为3 份时,跟踪效果最佳。这是因为特征图中存在许多重复的特征通道,将其分成多份后可以进行多个角度的相似度比较。但由于特征图通道数有限,若份数过多,则每份所包含的目标特征就不足以充分表达目标特性,会忽略部分特征,从而导致跟踪精度降低。
为验证FMN 中记忆帧数对跟踪结果的影响,同样在GOT-10k 数据集上进行训练和测试,并得到实验结果,如表5 所示。
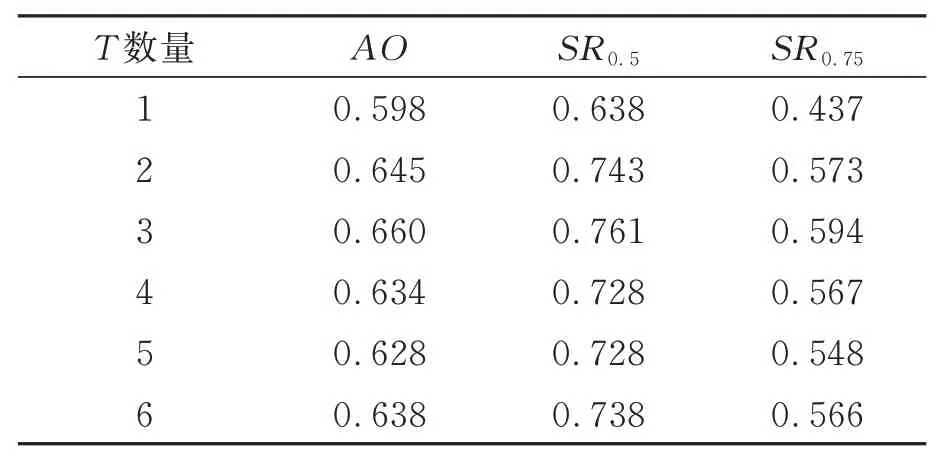
表5 T 对AO 的影响Tab.5 Influence of T on AO
根据表5 的数据,当记忆帧数为3 时,跟踪效果最佳。这是因为过少的记忆帧无法提供足够的目标表观信息,从而导致跟踪结果不佳。而当记忆帧过多时,如在目标遮挡的场景中,跟踪器会更倾向于匹配相似度最高的区域,而忽略被遮挡的目标,从而导致跟踪精度降低。因此,选择适当的记忆帧数可以提高跟踪器的性能。
4 结 论
本文针对目标遮挡问题提出了一种自适应特征匹配网络,该网络通过一个有效的模块AFMN 对骨干网络提取的特征进行处理,并将目标遮挡问题转化为背景估计和目标位置估计的联合优化问题,通过计算记忆帧与查询帧的像素级相似度,将目标和背景分别编码,进而确定某一区域属于背景或目标,以此来提高目标跟踪的精度和鲁棒性。并且,通过特征记忆网络对记忆帧进行挑选和保存,为特征匹配提供额外的表观信息,同时使网络隐性的学习目标运动趋势,进而实现更好的跟踪结果。在Got-10k 数据集上的实验结果表明,本文所提出的算法与STMTrack算法相比,AO值提升1.8%,SR0.5提升2.4%,SR0.75提升1.9%,在使用一张NVIDIA 1080Ti显卡时,运行速度可达21 FPS。并且在处理目标遮挡问题时具有良好的性能表现,与当前流行的目标跟踪算法相比具有更高的精度和更强的鲁棒性。
