国家储量规范约束下的储量研究新模式
2023-12-18侯东梅郭敬民黄建廷王飞腾
侯东梅 郭敬民 黄建廷 王飞腾
摘 要:海上油田储量复核算工作具有时间紧、任务重、人员少、标准高的特点,传统方式消耗大量的时间与人力。本次研究遵照国家评审依据,创新性构建地质逻辑、数据与计算机语言的空间拓扑关系,完善从数据层到处理层再到数据转换层各个环节的关联,挖掘出1200条逻辑关系,转化为21,000条计算机代码,实现储量参数自动化处理、计算单元自动化匹配、数据多维度自动化对比。工期缩短80%以上,折算节约人力成本近500万元,传统工作模式實现优化转型,为打造渤海数字化油田奠定研究基础。
关键词:海上油田,储量估算规范,拓扑关系,自动化处理
0 引 言
油气储量是指导油田勘探开发、确定投资规模的重要依据,也是编制油气开发方案的重要依据,通过合理选择储量计算单元、计算方法,准确求取储能参数和储量参数,进而探讨储量增减的影响因素,进行储量评价[1]。DZ/T 0252 2020《海上石油天然气储量估算规范》要求,首次向国家申报储量后开发生产井完钻后3年内要进行储量复算,储量复算后开发生产过程中要进行储量核算,油气田废弃前的储量与产量要进行清算[1]。因此,储量计算工作贯穿了海上油气田勘探开发过程的各个阶段。
储量计算工作包含了对油田数据的统计、分类、计算、制表、检查等工作,是将井上零散的数据变为各个储量单元的数据,涉及有效厚度、有效面积、孔隙度、含烃饱和度、体积系数等参数的求取与对比分析。该工作耗时长、工作量大,但目前大部分油田还处于人工计算加计算机辅助的阶段[2]。
海上油田储量复核算的特点为人员少、任务重、工作时间紧,同时储量研究工作又具有专业性强、数据量大、数据间关联复杂、研究质量要求标准高。经常会有大量反复和重复性工作,报告编写(文字、附图、附表、插表)均需手工反复修改、调整完成,质控难度较大,标准化的核查需要实现自动化。
随着中海石油总公司“七年行动计划”的整体部署,渤海油田2025年上产4000万吨的开发形势下,开发速度加快导致油田资料成倍增加、地质油藏认识改变,需要创新储量研究思路,快速开展储量估算,高质量高效率缩短储量研究工期,形成基于精细油藏描述需求的、适时更新的数据库、研究平台及研究成果库,实现储量研究与精细油藏描述一体化技术研究平台,使得渤海油田储量研究工作向标准化、流程化、软件化迈进,为渤海油田高效开发提供技术支撑。
1 总体研究思路
1.1 平台架构设计
根据当前储量研究与精细油藏描述一体化研究的需求,建立储量复核算数据自动化处理平台,解决学科广、软件多、数据杂的数据管理问题;调研储量研究与各研究软件的文件交换格式,建立数据接口,方便导入本项目研究需要的各类数据。在地质参数统计的基础上按相关标准规范形成附图、附表、研究报告等相关内容。
如何将储量复核算研究的思维及执行的各项标准规范表达成计算机语言是地质工程师面临的难点。
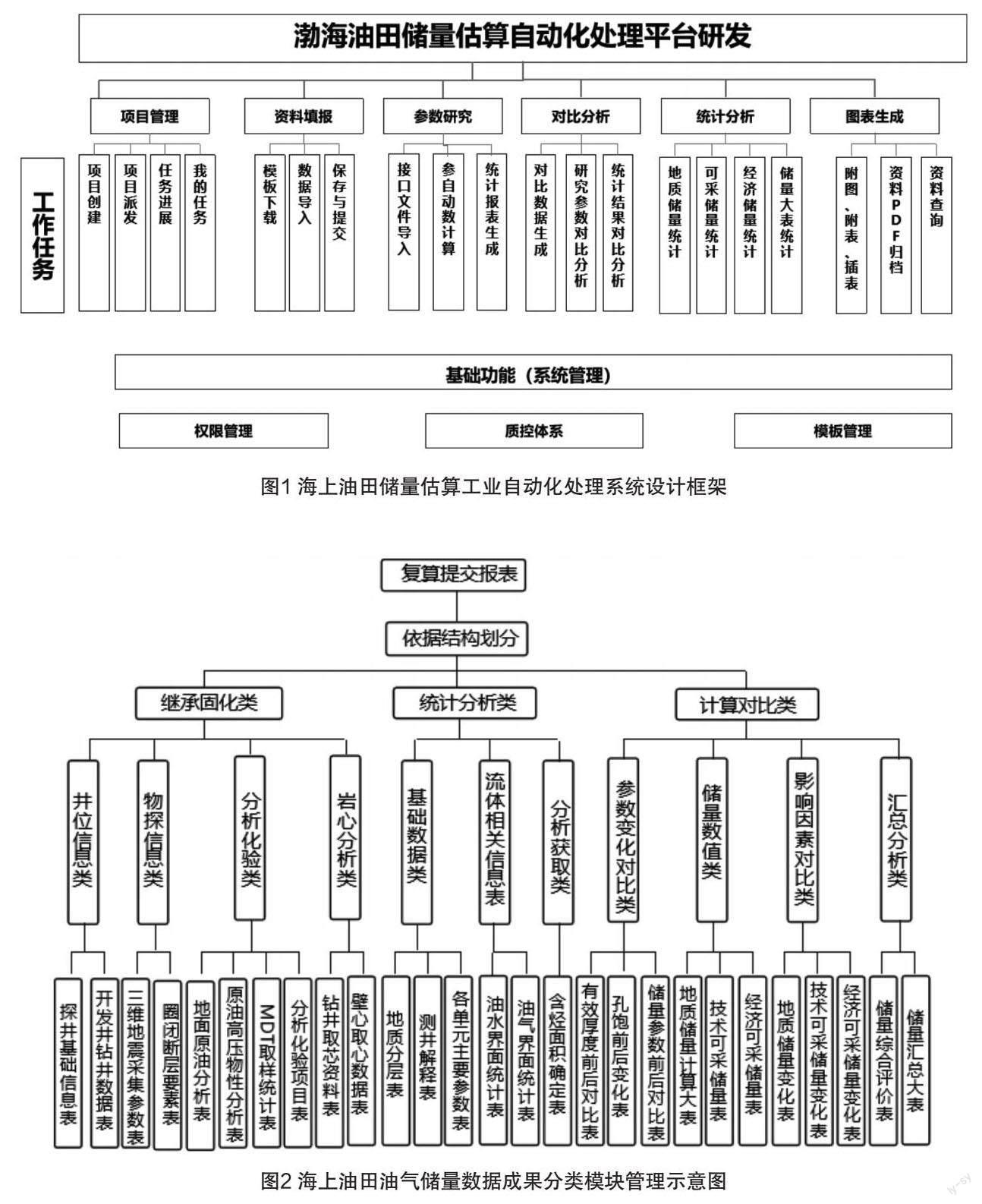
针对该问题,本项目着眼于渤海油田48个油气田储量估算报告成果,以DZ/T 0217-2020《石油天然气储量估算规范》 、DZ/T 0252-2020《海上石油天然气储量估算规范》、DZ/T 30334-2020《石油天然气探明储量报告编写规范》 为依据,按照国家储量估算研究思路,创新性构建各种地质逻辑、数据与计算机语言的空间拓扑关系,将储量估算各项工作进行梳理,完善从数据层到处理层再到数据转换层各个环节的关联分析,共挖掘出1200条逻辑关系,并将其进一步转化为21,000条计算机代码,以此为核心,搭建起了“海上油田储量估算工业自动化处理系统”(如图1所示)。
1.2 模板管理
计算机程序的最大特点是能够快速准确地处理海量数据工作,将具有规律的工作模块化完成,而储量计算工作的过程恰好符合这一特点(如图2所示)。本次研究的研究思路以问题为导向,从最初的需求分析来看,整个软件平台的核心内容应为数据的处理及规范制表[3]。采用模板的方式,适应标准规范的要求,以及不同项目、不同时期模板差异,保障系统未来的扩展性。把附表、插表等通过表格样式、数据来源绑定、计算关系处理、格式控制等方面固化内容。
1.3 质控体系
数据处理的难点在于油气田庞大的数据量。
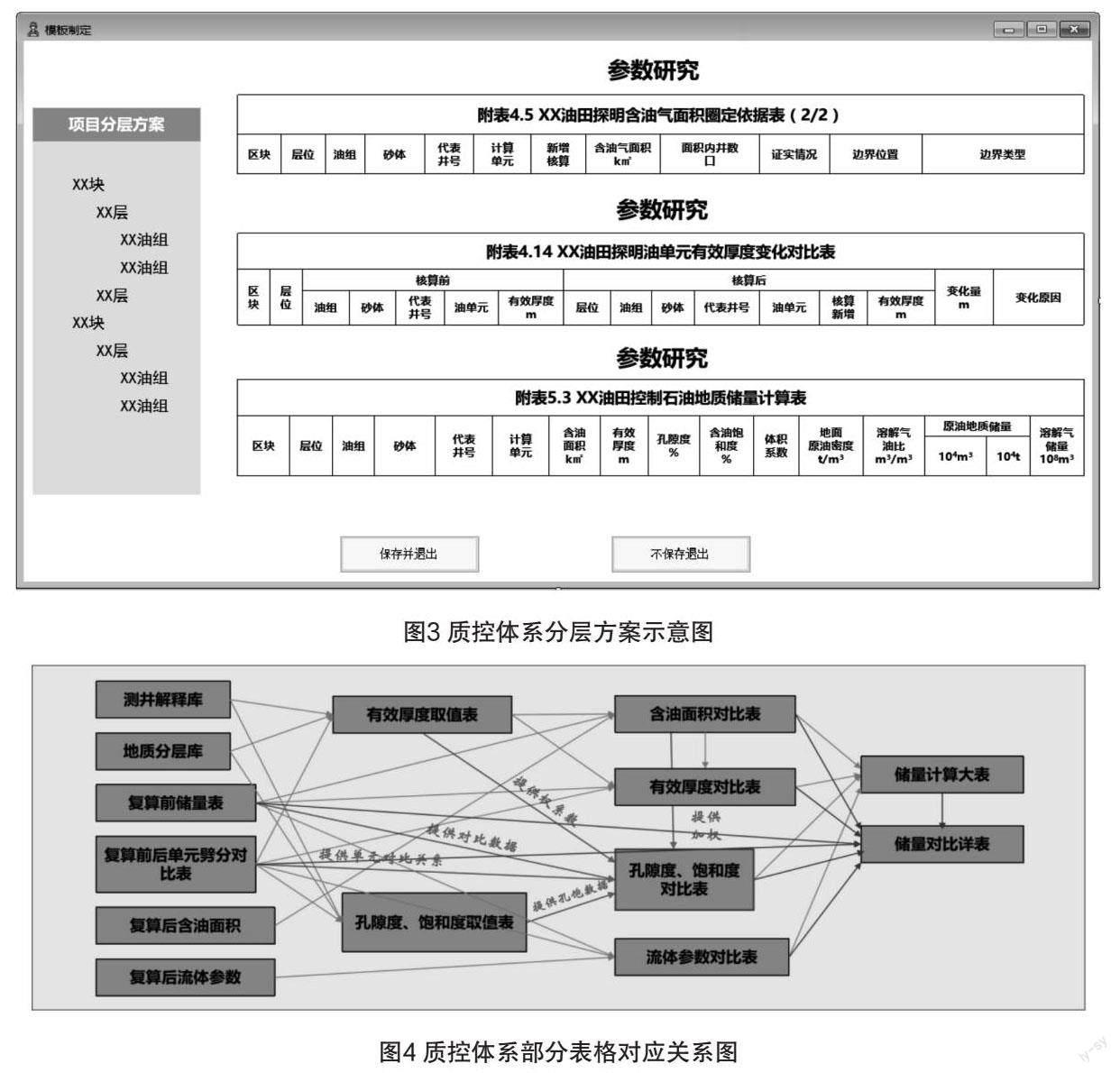
每口井、每百米大概有20个数据点,单个数据点的信息主要有:所属层段、砂体厚度、有效厚度、夹层厚度、孔隙度、含烃饱和度、渗透率及流体参数等,数据处理是对井上数据的分类、提取、运算、比较等过程。规范制表的难点在于表格格式的确定。储量计算工作的最终数据结果主要体现在附表文档中,附表中表格类型多、格式多,包括:表头的格式、数据的位数、单位的写法、文字的字体、符号的规范等等,由于附表中表格多、数据量大,制表过程中易产生三基错误。本次项目将全部表格格式依照规范进行编制,制表过程不需要人工参照规范反复修改,所有表格按照标准格式批量输出。质控体系通过项目分层方案、内置计算方法、错误预警3个方面保障数据的正确性。
(1)项目分层方案:参数研究、对比分析、统计分析中大量的数据都涉及区块、层位、油组,为保障这些数据的统一,系统提供了项目分层方案的功能。以此控制数据在“框架”层面的正确性(如图3所示)。
(2)计算方法内置:参数研究、对比分析、统计分析中大量的数据都存在现有的计算关系,系统内置了大量计算逻辑,保障了数据的前后闭合。
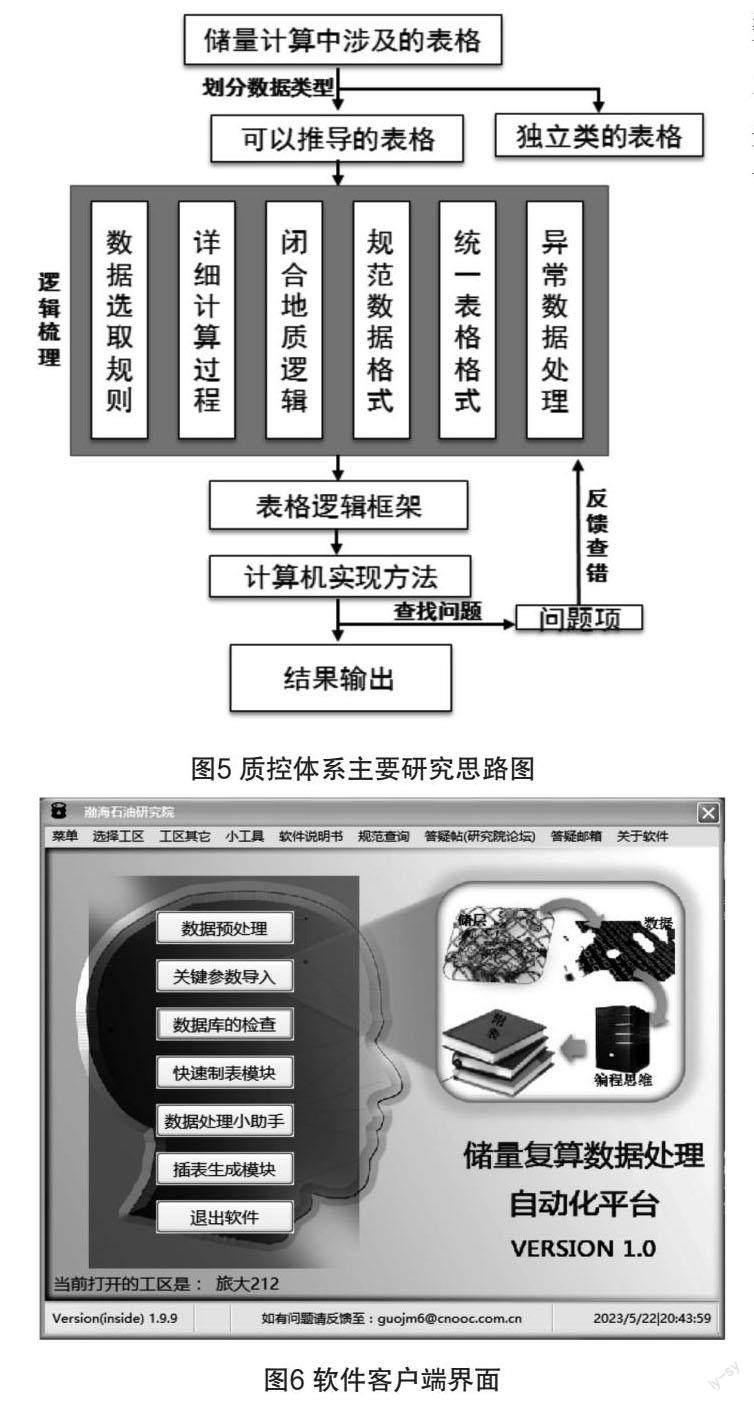
为实现储量计算结果输出的自动化、半自动化,整体思路以各个数据库及参数表之间的数据关联为主线。储量计算过程中,生成任一张表格都需要5~10个其他数据的支持,以“探明原油计算单元核算前后孔隙度、含油饱和度变化对比表”为例,生成该表需要核算后孔隙度、饱和度取值确定表提供数值,需要核算后有效厚度、含烃面积的相关表格提供数据进行加权,需要复算前储量计算表提供对比数据,需要核算前后单元劈分对比表提供复算前后单元对比关系等等(如图4所示)。
(3)错误检查:数据导入中,对重点的数据错误进行检查,保障数据入库质量。
对于数据表之间的复杂关系,软件在编写过程中,对要生成的每一张表进行提前设计,理清与其他表的关系,明确如何对接、使用每个数据源,依此,逐个完成每个表的编写(如图5所示)。
2 数据自动化处理实现
项目的关键功能是实现多个库的数据读取和统一调配,使所有数据成为一个庞大的数据集,并提供规范的数据输出格式。基于Microsoft VisualBasic 6.0在Windows系统上界面可视及操作灵活的特点,结合电子表格控件工具对数据强大的梳理能力,编制“储量复算数据处理自动化平台”,对储量计算数据进行快速处理(如图6所示)。
2.1 大批量数据处理
油气田资料中最主要的两个数据库是:地质分层数据库及测井解释成果数据库,地质分层数据库是根据井震结合、连井对比的方法得到的地层横向对比关系,通过平剖结合分析将井与井之间建立起层段对应关系;测井解释成果数据库包含了以井为单位纵向分布的数据,包含了大量储量计算所需要的参数。
平台模块二主要针对这两个数据库的处理,通过地质分层数据库提供井与井之间的层位对应关系,软件快速遍历测井解释成果数据库内几十万个数据,重新进行整理、劈分,建立起以储量计算单元为单位的全新数据库,自动将测井解释成果库中的单井数据分段提取至新库中每个储量计算单元的条目下,完成了对各个储量计算单元资料的统计汇总。
2.2 必要性文件输入
在储量计算工作时,除了地质分层数据库与测井解释成果数据库,还需要一些其他数据,包括油气各自的流体参数、上一版储量计算结果及相关参数、储量单元劈分变化情况、各个砂体的含烃面积以及每口井的补心海拔数据等。软件设计了模块三“必要文件的输入”,以及各类资料的格式说明文件,方便数据的一次性导入(如图7所示)。
2.3 成果工业化制表
在软件中,完成前面的预处理、统计及输入等工作,便可正式开始进入成果输出模块,按照表与表之间数据的关联性,所有表格需要按照顺序完成,完成一个阶段的输出才可进行下一阶段的输出,输出表格分为探明、控制、预测3套表格,每一套又根据油、气划分为两类,共计6套表格,单独一套表格包括了:有效厚度取值确定表、孔隙度饱和度取值确定表、有效厚度变化对比表、含烃面积变化对比表、孔隙度饱和度变化对比表、流体参数变化对比表、储量计算表、储量变化对比详表等。6套表格外还包括:流体界面取值确定表、油组划分表、砂岩百分含量表等独立的表格。储量规范要求的36类附表、29类插表均可实现自动化(如图8所示)。
输出模块包括全自动与半自动两种输出类型,全自动型是指表格全部数据均可通过其他表格获取,制表过程完全由软件完成,科研人员只需完成备注的说明部分;半自动是指制表过程中部分数据无法由现有数据进行推导得到,例如:叠合含烃面积、碾平厚度等,软件生成的表格中预留位置,方便人工填入这类数据,后续计算会自动引用人工填写的数据来计算后续的结果(如图9所示)。
3 自动化功能及应用
3.1 数据统计
统计类工作可细分为梳理、划分、提取3个方面,主要是将油田内单井上零散的数据按照层位划分结果划分为各个砂体或小层的数据[4]。储量计算工作中常规统计方法是通过人工在井上逐个值读取、记录,例如:统计某油田的流体界面数据,若有100口井、30个砂体,需要统计的数据个数一般在4000~7000个,人工完成需要一周以上的时间,且容易出现差错。
而该项目只需要导入测井解释成果数据库及地质分层数据库,程序会根据各井的储层对比结果,对单井的数据进行梳理、划分,自动建立一页表格,并以储量计算单元为单位对每个表格进行命名,再将测井解释成果数据库的数据自动提取至每个储量计算单元对应的表格当中,同时完成制表。人工完成类似的统计类工作需要2~3周的时间,该平台可使数量在10万以下的数据在半小时内统计完成,经矿场使用提质增效效果明显。
3.2 数据计算及对比
软件可快速完成各类储量计算参数从样本到井上、从井上到储量计算单元的逐个层次的各类算术平均、加权平均计算,计算过程中所有参数可自动从数据库中提取,无需人为操作。除此之外,软件还可自动完成砂地比计算、TVD与TVDSS深度转换、各单元储量的计算等。
对复算前、后储量变化对比的分析中,各个储量计算参数对储量变化的影响的计算较为繁琐,而简单地将各储量参数变量引起的储量增量平均化,不能客观反映各储量参数的变化对储量变化值的影响,根据调研,软件在储量参数与储量无量纲化基础上,采用储量参数敏感性分析及储量不确定性分析的思路,使用基于参数增量的增量劈分,保证更加准确地反映出储量变化的真实情况[5,6],全部计算过程内置于软件中,可一键完成。
3.2.1 制表编排规范化
参照DZ/T 0334-2020《石油天然气探明储量报告编写规范》,设计输出表格编制、排版的规则,涉及每张表的表行、表头、表元。对制表过程中的各类细节增加控制,包括数据字体、小数位数、表格边框、行距列距等等,并根据不同类型的表格加以区分。
数据表格生成过程为:首先,根据需要自动生成表头,依次逐行设置储量计算单元,处理数据并将数据填入相应行列位置;其次,对表格添加边框并调节间距,规范表头格式,依次完成每一类数据的格式,包括小数位数等;最后,统一字体格式,将需要合并的网格进行合并,完成最终表格并保存(如图10所示)。
3.2.2 数据自查功能
地质静态数据中,地質分层数据库与测井解释成果数据库是最大的两个库,两个库之间主要依靠井位、深度来匹配数据,而在匹配过程中,由于地质分层是由地质与地震专业相结合确定的,部分分层位置与测井解释中的砂体边界不一致,需要校正分层深度,以保证储量计算单元的顶底都为砂体边界。由于数据量巨大,人工检查需要大量的时间与精力,软件的预处理模块可提供检查功能,运行后自动在有问题的分层位置标上颜色及参照值,用数值正负区分分层位置是过高或是“切砂”,软件查错速度相比较人工检查更快捷、更准确,减少遗漏(如图11所示)。
4 结 语
该平台实现了储量计算参数自动提取、自动加权、自动选值、储量结果自动计算、多参数自动对比等功能,并能自动生成规范要求的36类附表、29类插表的标准化的储量数据表,用以代替人工操作计算机进行数据分析的复杂过程,避免人为过失导致数据失准问题的发生,研究工期缩短80%以上,折算节约人力成本近500万元,大幅提升了油田传统储量估算工作的效率,实现了对传统工作模式的优化转型,开创了海上油田储量估算研究新模式,使渤海油田储量复核算工作向统一标准和规范的工作流、数据流、软件流迈进,为打造渤海数字化油田奠定了一定的研究基础。
参考文献
中国海洋石油总公司.QHS2081-2014海上油气田开发图集编制规范[Z].1991-06-05.
陈元千,周翠.中国《页岩气资源/储量计算与评价技术规范》计算方法存在的问题与建议[J].油气地质与采收率, 2015, 22(1): 1-4.
郭林,周东红,沈东义,等. TB级海量地震数据三维显示系统的设计与实现[J]. 中国海上油气, 2012 (S1): 50-55.
吴胜和.储层表征与建模[M]. 北京: 石油工业出版社,2010.3.
孙立春,蒋百召,何娟,等. 基于参数增量的地质储量增量近似劈分方法[J].中国海上油气, 2015, 27(2): 48-52.
胡允栋,关涛.储量参数误差对储量精度的影响[J].石油勘探与开发, 1998, 25(6): 70-74.
