基于专家混合与领域特征的网络谣言识别模型*
2023-12-18安全徐国天中国刑事警察学院
安全 徐国天 中国刑事警察学院

引言
随着互联网的快速发展和广泛应用,以微博为代表的社交媒体平台已成为人们获取政治、金融和健康等信息的重要渠道。然而,社交媒体平台在方便人们分享信息的同时,也为网络谣言传播提供了新渠道。2023年7月21日,公安部召开新闻发布会,自开展为期100天的网络谣言打击整治专项行动以来,全国公安机关共侦办案件2300余起,整治互联网平台企业近8000家,依法关停违法违规账号2.1万余个,清理网络谣言信息70.5万余条[1]。谣言发布者利用热点新闻的热度散布虚假信息,混淆视听,给社会带来实际威胁的同时,也会削弱公众对政府和媒体的信任。
为了打击网络谣言,学者们曾采用机器学习算法,将谣言检测视为二分类问题,从文本内容和用户个人资料等信息中提取各种类型特征[2]。这些特征可以包括词频、词向量和句法结构等,之后对提取的特征进行学习,从而建立分类检测模型。传统的机器学习方法侧重于人工提取特征来对谣言进行检测。例如,2011年,Castillo等人[3]利用文本、主题和传播特征来研究Twitter新闻的可信度,并构建决策树分类模型;2015年,Ma等人[4]提出动态时间序列结构模型,该模型能够抓取多种社会语境特征随时间的变化,在网络谣言传播早期阶段展现出强大的识别能力;2016年,曾子明等人[5]定义了用户可信度和微博影响力特征,并提出融合LDA和随机森林的谣言识别模型。
机器学习算法在特征提取与选择过程中,不仅耗费大量的人力、物力与时间,且获取特征的鲁棒性也不足。随着网络谣言规模和复杂性增加,深度学习方法应运而生。2016年,Ma等人[6]将谣言文本内容输入到循环神经网络中,利用隐层向量表示文本信息并输入到分类器中,得到分类结果;2017年,Feng等人[7]对新闻内容进行建模,将向量拼接成一个矩阵并用卷积神经网络提取文本特征,最终将嵌入向量输入到分类器中进行检测;2019年,Ma等人[8]利用对抗学习方法训练生成器和判别器,扩展训练数据。将生成内容和原始内容输入到分类器中进行检测,提升模型的鲁棒性和分类准确率;2021年,南琼等人[9]构建了中文多领域虚假新闻数据集Weibo21,并提出多领域虚假新闻检测模型MDFEND,该模型利用注意力机制提取新闻的内容和领域特征,通过门控网络对特征表示进行聚合,从而进行多领域虚假新闻检测工作;2022年,耿唯佳等人[10]融合TextCNN和TextRNN模型,挖掘文本语义和时序特征,对两种特征进行加权融合,实现对网络谣言的识别;2023年,吴越等人[11]提出了基于并行图注意力网络的谣言检测方法ParallelGAT,该模型分别使用BiCAT和MIGAT模块获取谣言的传播和知识特征,最终通过聚合模块生成的特征向量进行谣言检测。
早期,由于网络谣言数据量少,研究者们将不同数据混合用于检测工作[12]。然而,这种方式忽略了不同领域间谣言的差异,例如,健康类谣言的高频关键词有“新冠”“医院”和“病毒”等;事故类谣言的高频关键词有“地震”“火灾”和“车祸”等。随着数据量的增加,研究者们开始根据谣言所属领域进行检测工作[13]。在疫情期间,“喝白酒,能够预防新冠病毒感染”等无根据言论在社交媒体平台上层出不穷。研究者们利用深度学习模型开展有关新冠病毒网络谣言的检测工作,并取得显著进展[14]。以ELECTRA模型为例,在COVID-19FakeNews数据集上训练后准确率可达94.8%[15]。然而,将这类模型应用于其它领域谣言时,检测效果则会大打折扣。
现有的网络谣言检测方法多是利用单一领域的大量数据来训练模型。这些模型在相应领域的性能较高,但在实际生活中面对多个领域数据,此类模型泛用性不足,实用价值也随之降低。为了进一步研究和开发适用于多样化情境下的网络谣言检测模型,提高检测的精度和覆盖率,本文提出一种基于专家混合和领域特征的谣言识别模型WMTC。模型采用WoBERT预训练模型,将谣言的文本内容转化为向量表示,选择改进的多尺度TextCNN模型作为“专家模型”进行特征提取,之后根据谣言所属领域对特征进行加权融合并输入分类器中进行检测。实验结果表明,该模型的性能要优于其它混合、单领域和跨领域谣言检测模型。
一、网络谣言检测模型
(一)预训练模型WoBERT
BERT是GoogleAI研究院[16]于2018年发布的一种预训练模型。传统BERT模型采用WordPiece分词操作,会将文本分割成较小的子词来加快训练速度。但对于中文来说,BERT会将每一个汉字都切分开,训练的结果就是孤零零的汉字向量。在现代汉语中,以字为单位建模无法表达词语或者短语中包含的丰富语义信息,这也造成BERT在很多中文任务上的表现并不理想。2020年,有研究人员发布了基于词颗粒度的中文语言预训练模型WoBERT[17]。该模型会使用结巴分词对输入的内容进行“预分词”操作,如果词汇在分词表中则保留,否则将其切分为字。最后,将词序列拼接起来,作为最后的分词结果。实验结果表明,WoBERT在中文文本分类等任务上的性能要优于Google发布的中文BERT。因此,本文选用WoBERT作为预训练模型。
(二)改进的多尺度TextCNN模型
相较于传统的卷积神经网络,TextCNN网络结构简单,仅包含一个卷积层和一个池化层,使用Softmax来进行分类。模型的参数数目少,训练速度快,对文本数据的浅层特征提取能力很强。但在长文本领域,TextCNN受限于卷积核大小,较长文本可能会被截断或忽略部分信息,并且该模型是基于局部窗口进行卷积和池化操作,因此无法充分捕捉到全局语义和上下文信息。
2014年,Google公司发布的GoogLeNet[18]采用Inception模块来优化卷积神经网络,即分别使用池化和卷积操作来缩小特征图尺寸,再将两者得出的特征图组合起来,这种做法既增加了网络的宽度和深度,又减少了模型的参数量,降低了过拟合风险。本文借鉴Inception模块的思想,对TextCNN进行改进:在原有卷积层前添加池化核和卷积核,增加通道数并对文本信息的浅层特征进行提取。然后,并行使用多个不同尺寸的卷积核对特征进行进一步提取,并使用零填充保持维度不变。最后,将卷积层输出的特征叠加后进行最大池化,得到特征向量。改进的多尺度TextCNN模型,如图1所示。
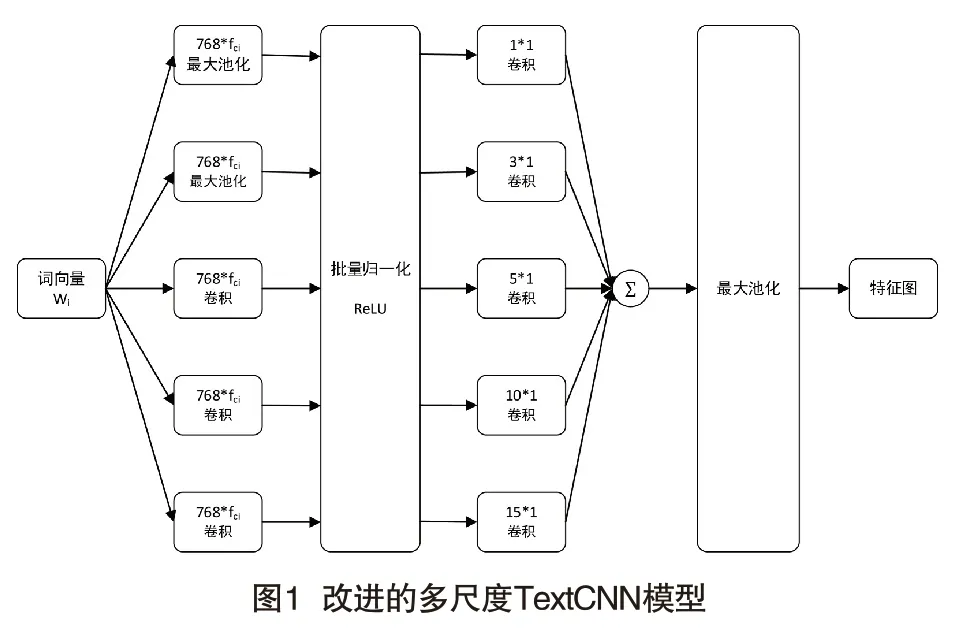
(三)混合专家模型
混合专家模型的核心思想是将多个专家模型组合成一个大型集成模型。从结构角度来说,混合专家模型可以分为两个部分,分别是专家模型和门控网络,专家模型是多个独立子模型组成的集合,每一个子模型被称为一个专家模型。专家模型之间相互独立,学习相同或不同的特征,本文选用多尺度TextCNN作为专家模型;门控网络通过学习参数决定哪些专家模型应该对特定输入数据或任务负责,从而将多个专家模型的预测结果进行加权组合,得到最终的输出结果。使用混合专家模型可以显著提高模型在处理复杂任务时的性能,但是却存在着负载不平衡的问题:在最初的几个样本上表现较好的专家模型会被门控网络分配更高的权重,并得到更充分的优化,而其余专家模型无法被充分训练。2021年,Simiao等人[19]提出负载不平衡本质上是由门控网络造成的,该问题源自于门控网络的初始化或优化过程,因此使用随机门控网络可以从根本上解决负载不平衡问题。
(四)基于专家混合和领域特征的谣言识别模型WMTC
本文在WoBERT和多尺度TextCNN的基础之上,结合混合专家模型提出一种基于专家混合和领域特征的谣言识别模型WMTC,整体框架如图2所示。
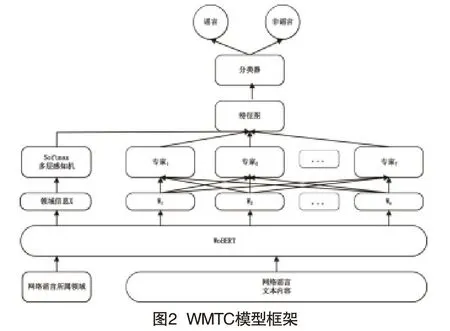
模型的工作流程如下:
对数据进行预处理,将网络谣言文本内容作为WoBERT的输入,编码后得到一组词向量W={W1,…,WN},N为编码后词向量序列的长度。选用多尺度TextCNN作为专家模型,一个专家模型提取的特征只能包含部分信息,无法覆盖谣言内容的全部特征。为了获取各个领域中谣言内容的高质量表示,模型利用专家混合的优势,同时使用多个专家模型(T=5)对谣言内容进行特征提取。每个专家模型可以表示为公式(1):
其中,W是输入每个专家模型的词向量,βi是模型参数,T是专家模型数量,则每个专家网络提取的特征可表示为公式(2):
将网络谣言的领域标签作为WoBERT的输入,编码后得到一组领域向量X={X1,…,Xd},然后,将领域向量输入多层感知机生成专家模型的权重向量。最后,与均匀分布生成的随机矩阵A相乘,使权重向量α具有一定的随机性并进行Softmax归一化。权重向量α可以表示为公式(3):
使用权重向量α={α1,α2,…αi}(1≤i≤T)来对不同专家模型获取的特征表示进行聚合,各维度代表不同专家模型在不同领域所占权重。最终获得谣言内容的特征向量可表示为公式(4):
使用有Softmax输出层的MLP作为分类器,交叉熵作为损失函数,y为预测值,yi为真实值,则有公式(5)和公式(6):
本文模型将WoBERT和多尺度TextCNN相结合,充分利用了它们各自的特点:WoBERT作为一种强大的预训练语言模型,能够充分理解文本内容的上下文信息,并捕捉词汇、句法和语义的丰富信息。WoBERT丰富的词向量表示,可以帮助TextCNN模型更好地理解和刻画文本的语义和上下文关系。混合专家模型可以根据网络谣言所属的领域生成不同的权重来调整不同专家模型的贡献,从而显著地提高了模型的泛用性和准确率。
二、实验设置
(一)数据集
本文使用中科院计算技术研究所,数字内容合成与伪造检测实验室的Weibo21数据集进行网络谣言检测实验。该数据集是中文文本数据,包含2014年12月至2021年3月,微博社区管理中心官方帐户认定的网络谣言,以及同时期经睿鉴识谣平台鉴定的真实新闻。每条数据包含网络谣言的文本内容、评论和时间戳等多个维度的信息,共有4488条网络谣言和4640条真实新闻,涵盖科技、军事、教育、灾害、政治、健康、金融、娱乐、社会共9个领域。

在数据预处理阶段,首先,对数据进行筛选,仅保留文本内容、所属领域和标签3个特征;然后,使用正则表达式对文本内容中的特殊符号、乱码文字和emoji表情进行去除;最后,对数据集进行随机化,将得到随机数据集按照6:2:2划分为训练集、验证集和测试集。
(二)实验环境及参数设置
本文实验环境为一台运行内存为32GB,硬盘空间为1TB,搭载2.30GHz的12th Gen Intel CoreTMi7-12700H处理器,GPU为NVIDA GeForce RTX 3060(显存6GB),安装Windows11操作系统的电脑。编程语言和平台版本为Python3.7.13,集成开发环境采用PyCharm Community Edition 2022.2,主要使用的深度学习库为pytorch1.12、transformers4.27.3、numpy1.19.5。
本文模型可分为WoBERT、多尺度TextCNN和分类器三部分。在WoBERT模型部分,选用的预训练模型为WoBERT Plus,嵌入维度设置为768。在处理文本数据时,限制文本序列的最大长度为170个标记;在TextCNN部分,模型第一层池化层的池化核尺寸为768*5,第1层卷积核尺寸为768*5,第二层卷积核尺寸分别为1*1、3*1、5*1、10*1和15*1。在两层之间进行批量归一化并使用ReLU作为激活函数,最终输出维度为256;在分类器部分,包含线性层、BatchNorm和Dropout层,其中Dropout概率设置为0.2,选用ReLU作为激活函数;整个训练过程中,用于数据加载器中的工作线程数指定为4。经过实验和模型调优后,本文在模型使用Adam优化器来自动调整学习率和权重衰退,其参数初值分别选定为0.0001和5e-6。在综合考虑计算资源、内存限制和模型复杂度后,本文选定批量大小为64。通过观察模型的收敛情况,本文选定模型训练的epoch为20。
(三)模型评价标准
在使用深度学习模型进行分类任务时,通常使用精确率(Precision)、召回率(Recall)和F1分值(F1 Score)来评判模型性能的好坏。根据三种指标构成的混淆矩阵结构见表2。

其中,TP表示被模型检测为网络谣言,并且检测正确的样本数量;FP表示被模型检测为网络谣言,但是检测错误的样本数量;FN表示被模型检测为真实新闻,但是检测错误的样本数量;TN表示被模型检测为真实新闻,并且检测正确的样本数量;N则表示TP、FP、FN、TN的总和,代表测试数据集中所有样本的数量。
在本文中,以上三种指标的具体评价方式如下:
(1)精确率表示所有被预测为网络谣言的样本中,预测正确的样本数量所占比例,如公式(7)所示。
(2)召回率表示所有网络谣言样本中,预测正确的样本数量所占比例,如公式(8)所示。
(3)F1分值是精确率和召回率的加权平均值,如公式(9)所示。

精确率体现了模型对真实新闻的区分能力,精确率越高,模型对真实新闻的区分能力越强;召回率体现了模型对网络谣言的识别能力,召回率越高,模型对网络谣言的识别能力越强;F1分值是两者的综合,F1分值越高,模型越稳健。
三、实验结果及分析
(一)基准模型
为了评估本文提出的WMTC模型在谣言检测任务中的实际效果,在实验中使用经过上述预处理后的数据集,与其它基准模型的检测效果进行比较。为了确保基准模型结果的公正性,本文在进行单领域基准模型的实验时,每次使用1个领域的数据对模型进行训练并进行试验;在进行混合基准模型实验时,使用所有领域的数据对模型进行训练,并分别对每个领域进行试验。本文实验采用的基准模型有:
(1)BERT:使用相同的预训练模型WoBERT Plus,并将模型参数设置为冻结状态;
(2)TextCNN:使用多尺度TextCNN模型进行试验,模型与专家模型结构保持一致;
(3)MMoE[20]:多任务学习模型,MMoE在MoE的基础上进行改进,对每个子任务都引入一个门控网络,以此来捕获不同子任务之间的差异性。使用该模型进行试验时,将不同领域网络谣言内容视为不同子任务进行建模;
(4)EDDFN[21]:该模型引入一种无监督技术,选择一组未标记的信息新闻记录进行人工标签,可以联合保存新闻记录中的特定领域和跨领域知识,以检测来自不同领域的网络谣言;
(5)MDFEND:该模型使用TextCNN作为专家模型,将谣言内容作为门控网络的输入,并通过注意力机制来提取谣言的领域特征为专家模型分配权重。
(二)实验结果对比
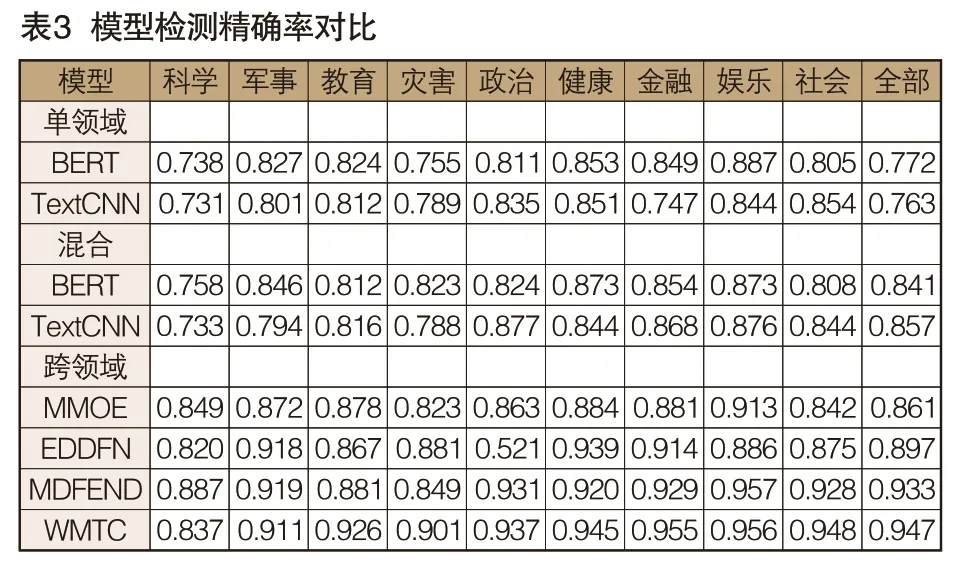
WMTC模型与其它基准模型在Weibo21数据集上的实验结果见表3至表5。
(三)实验结果分析
通过比较WMTC模型与其它基准模型的实验结果,可以得出如下结论:
(1)比较单领域和混合检测模型的结果,可以发现,混合检测模型的3项性能均高于单领域检测模型。说明收集多个领域的网络谣言对模型进行训练,有助于提高模型的性能和鲁棒性;
(2)比较混合和跨领域检测模型的结果,可以发现,跨领域检测模型的3项性能均高于混合检测模型,说明了网络谣言的领域特征对模型训练的重要性;
(3)比较WMTC和MMOE模型的结果,可以发现,不同领域的网络谣言之间存在着一定的联系,可以利用其它领域的数据来提高特定领域的检测效果;
(4)比较WMTC和MDFEND模型的结果,可以发现,使用随机矩阵可以缓解混合专家模型的复杂不平衡问题,从而提高模型性能;
(5)比较模型的召回率和精确率,可以发现,选用的模型除MMOE模型外,均对网络谣言的区分能力比较强;
(6)WMTC模型在对网络谣言内容进行特征提取的同时,按照谣言所属领域对特征进行聚合,有效对谣言内容和领域之间的关系进行建模。因此,在Weibo21数据集上,WMTC模型综合性能优于其他模型,证明了该模型的有效性和优越性。
四、结语
本文针对现有的网络谣言检测模型在多样化情景下性能低的问题,提出了一种基于专家混合和领域特征的谣言识别模型WMTC。模型使用WoBERT和多尺度TextCNN对谣言文本内容进行高质量的提取,之后结合领域信息生成权重,对专家模型提取的特征进行聚合。实验结果表明,WMTC模型在Weibo21数据集上的综合表现优于现有的单领域、混合以及跨领域谣言检测模型。但模型仍存在一些不足之处,需要进一步研究和改进,现实中社交网络平台上,往往充斥着各种类型的网络谣言,本模型仅能对网络谣言的文字内容进行识别,无法识别图片和视频信息。因此,针对网络谣言检测引入图像信息处理技术是未来需要进一步研究和改进的方向。
