基于GA-XGBoost 算法的肺癌预测研究
2023-12-18柯东晏峻峰
柯东 晏峻峰


关键词:肺癌;SMOTE过采样;特征选择;遗传算法;集成算法;XGBoost
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2023)11-131-05
0 引言
肺癌是起源于肺部支气管黏膜或腺体的恶性肿瘤,其发病率和死亡率增长很快,是对人的健康及生命威胁最大的恶性肿瘤之一[1]。由于肺栓塞常常伴有呼吸困难、咳嗽、胸痛、咯血等症状,临床症状特异性不强,通常难以鉴别,故漏诊率较高,以致延误救治时机[2]。在我国,肺癌是危害人类的生命健康的主要恶性肿瘤之一,在排名前十的恶性肿瘤中,肺癌的发病率和死亡率分别占20.03% 和26.99%[3]。若肺癌在早期阶段能被及时发现并得到恰当的治疗,患者的5 年生存率可提高到50% 甚至更高[4]。
在早些年,Ledley[5]等人第一次将医学领域的数学模型应用到计算机辅助诊断中,首次提出计算机辅助诊断。Weizeng Li 等[6]提出了将决策树和逻辑回归相结合的逻辑树,分别评估单个和多个肿瘤标志物的诊断价值;Caijoie Ren 等[7]提出一种基于临床肺癌个体化鉴别方案,采用LASSO 进行回归分析,得到了最优预测结果;Nuhic Jusua 等[8]利用机器学习算法预测模型作为一种非侵入性工具来区分恶性与良性,应用于肺癌的预测分类。Stefano Elia 等[9]使用遗传算法在五种肿瘤标志物种选择出两种指标物进行联合检测,得到了最好的肺癌预测结果。相对于单个模型而言,集成模型由多个基学习器构成,因此具有更好的分类和回归效果。例如张楚函[10]以随机森林算法建立术前诊断模型,建立了肺癌前期预诊断模型;张雨晴等[11]应用随机森林分析非吸烟女性肺癌风险因素。然而,机器学习在肺癌研究中也面临一些挑战,如样本大小、数据质量、模型的可解释性以及算法模型耗时长等方面的限制。因此,本研究致力于解决这些问题,探索临床上肺癌患者与其生活习惯之间的关系,建立基于生活习惯进行肺癌预测的分类模型。通过算法的融合、优化,确定的最终模型在肺癌数据集上进行试验,实验得到93.2% 的高准确率,同时算法模型相比强分类器SVM 具有更快的响应速度,充分证明该模型能应用到临床,辅助医生进行疑似病例的肺癌预测,结合必要的医学检查,及时对肺癌患者进行医学干预,为肺癌患者争取更多的治疗从而提高生存率。
1 研究方法
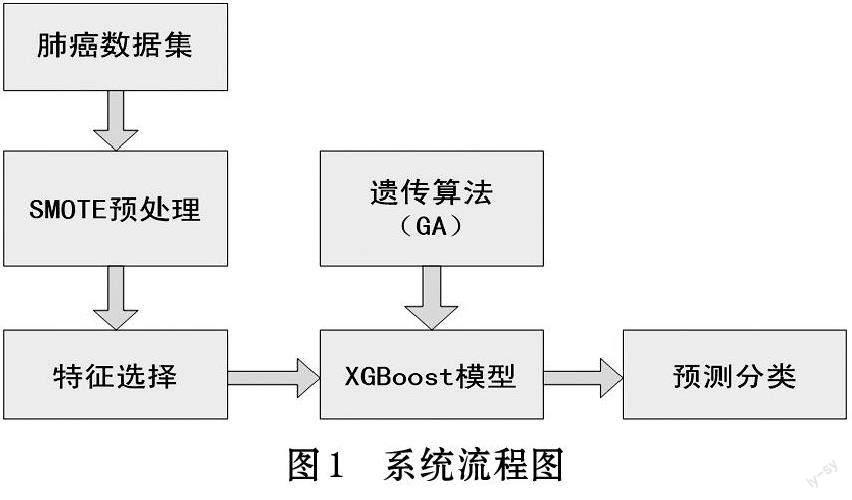
本文方法如下:不平衡数据是指数据集中某一类别的样本数量明显少于其他类别的样本数量[12],本文数据集标签比例严重失衡,标签为0 的样本29 条,标签为1 的样本280 条,即正负标签比例大约为1:9,因此引入过采样技术SMOTE 方法对数据做均衡化处理;对本实验所用到的肺癌数据集进行随机森林重要性排名,根据排名结果选择贡献较大的特征,参与模型计算,实现降低数据纬度、提高分类准确率的效果;构建GA-XGBoost 算法模型即:采用遗传算法优化梯度提升树算法XGBoost,并与其他机器学习方法如支持向量机(SVM),决策树(DT)、K 最近邻(KNN)、贝叶斯(NB)以及未调优的XGBoost 进行对比,证明模型的优越性。具体流程图如图1 所示。
1.1 构建GA-XGBoost 模型
极端梯度提升树(XGBoost)算法是由陈天奇在2014 年提出,该算法能够极大地提升模型的训练速度和预测精度[13]。它的设计是为了正确使用资源,克服以往梯度提升的局限性[14]。本文XGBoost 目标函数如下:
遗传算法(GA)是一种求解优化问题的工具[15],主要用于解决搜索和优化问题。算法过程如下:
⑴ 初始化:生成一组初始种群,其中每个个体代表一个解。
⑵ 适应度评估:对每个个体进行适应度评估,即计算其对应的目标函数值。
⑶ 选择:从种群中选择一部分个体作为下一代种群的父代。
⑷ 交叉:对父代中的个体进行交叉操作,生成新的子代。
⑸ 变异:对子代中的个体进行变异操作,引入随机因素,增加种群的多样性,防止算法陷入局部最优解。
⑹ 更新种群:将父代和子代合并,生成新的种群。
⑺ 终止条件判断:判断是否达到终止条件,如最大迭代次数、目标函数达到某个阈值等。
⑻ 输出结果:输出最优解或者最優解对应的目标函数值。
本实验构建GA-XGBoost 肺癌诊断模型如图2。
2 实验过程及结果分析
本文基于Anaconda开发环境下的jupyter-notebook编辑器。研究选用kaggle 学习库所公开的的肺癌数据集。该数据集包含疑似肺癌患者平时生活习惯和生理、行为表现等部分数据,一共有309 个样本,类别为良性肿瘤和肺癌肿瘤,数据集包含的14 个特征基于疑似患者的生活记录,分别是年龄(AGE)性别(SEX)、是否吸烟(SMOKING)、黄色手指(YELLOW)、平时是否有同辈压力(PRESSURE)、是否焦虑(ANXIETY)、是否有慢性病(CHRONIC DISEASE)、是否感到疲劳、是否哮喘、药物过敏(ALLERGY)、饮酒(ALCOHOL CONSUMING)、咳嗽(COUGHING)、呼吸急促(SHORTNESS OF BREATH)、吞咽困难、胸痛(CHEST PAIN)、是否肺癌(LUNG_CANCER)。特征中“是”为1,“否”为0;标签中患肺癌为1,没有患肺癌为0。实验以70% 的数据集作为训练集,30% 作为测试集。
2.1 评价指标
在分类指标问题上采用混淆矩阵是最直观的,混淆矩阵可以详细的展示分类性能。混淆矩阵如表1所示。
本文在混淆矩阵基础上引入准确率(Accuracy)、灵敏度(Sensitivity)、特异度(Specificity)作为算法的判断指标。其中灵敏度又叫真阳性比例,即实际发病且被准确诊断的病人所占比例;特异度又称为真阴性率,是指实际无病并能准确检测的病历所占比例:
2.2 数据均衡化处理
本文数据集标签比例严重失衡,标签为0 的样本29 条,标签为1 的样本280 条,即正负标签比例大约为1:9。采用SVM-SMOTE 过采样技术进行数据均衡化处理,原始数据和均衡化处理后的数据分布如图3、图4 所示。
2.3 特征选择
特征重要性计算结果可以用于特征选择和可视化,帮助我们理解模型的特征贡献程度,从而更好地解释和使用模型。本文通过随机森林算法得出特征重要性排序,结果如表2 所示。
排在后面四位的是YELLOW_FINGERS,GENDER,ANXIETY,FATIGUE,由于这四个特征重要性比较低,故予以剔除,保留排名结果选择排名靠前的10 个特征重新训练模型。比较SMOTE 均衡化前后、进行特征选择前后进行XGBoost 训练,结果如表3 所示。
2.4 GA-XGBoost 实验结果
和随机森林算法(Random Forest,RF)超参数空间类似[16],XGBoost 超参数众多,需要手动设定。本文选取常见的三个超参数:n_estimators(树的数量),max_depth(最大樹深度)、learning rate(学习率)进行遗传算法优化,将评估指标AUC 作为适应度函数。考虑到适应度函数上界难以确定,本文选取最大循环次数作为算法的终止条件。本文借助可视化工具—学习曲线,确定超参数的大致范围,三个超参数的学习曲线图分别如图5、图6、图7 所示。
由学习曲线可知,n_estimators 最佳取值在60左右,max_depth 最佳取值为6 左右,learning_rate 最佳范围为0.2 到0.3 之间。用遗传算法进行最优值搜索:设定n_estimators 范围为50 到75,步长为1;max_depth范围为4 到9,步长为1。Learning_rate 范围设定为0.2-0.3,步长为0.01。遗传算法结果如表4 所示。
得到XGBoost 最佳参数后,为了验证模型的优越性,同其他机器学习进行比较。不同算法的比较结果如表5 所示。
进行遗传算法优化的GA-XGBoost 模型,准确率达到0.932,灵敏度达到0.928。特异度达到0.921,准确率和灵敏度最高。虽然SVM 在分类中也表现出了不俗的性能,在特异度上较XGBoost 稍高,但作为强分类器,SVM 复杂度高,耗时长。在讲究实效性的临床医疗诊断中,基于简单学习器集成的XGBoost 算法在高分类性能的同时还能实现快速运算,与其他机器学习方法相比,进行遗传算法优化的GA-XGBoost,表现堪称完美。
3 结束语
对疑似患者进行早期的预测诊断是应对肺癌的有效手段[17]。本文提出的基于GA-XGBoost 算法的预测分类模型在准确率、灵敏度和特异度三项指标上表现优异,运行时效上优势明显。模型的最终目的是在临床上指导医生对患者的肺癌风险进行提前判断,但本文数据集是肺癌患者的日常表现、生活习惯记录,存在一定的主观性,未来可以从更多的临床电子病例出发,采用客观、标准化的数据。下一步结合大样本,高纬度的客观化数据,尝试深度学习的建模,致力于人工智能在人类的癌症事业中的更大应用。
