去乌托邦式的想象:ChatGPT内容生产的伪客观性考察
2023-12-17邱立楠陈淼
邱立楠 陈淼

【内容提要】每种技术都有自己的议程,都是等待被揭示的一种隐喻。ChatGPT作为一种新兴生成式人工智能技术,其以用户“需求”问题为中心的信息生产方式,抽离了人类在回答问题时的主观建构能力,被看成是一种“机器理性”的客观陈述。然而,ChatGPT生产的内容所表现出客观性却是一个伪命题,其表现出的高度拟人化,也是被人类驯化的结果,作用于ChatGPT的用户需求、数据库和人工培训三个因素都带有强烈的人工设计因子,成为ChatGPT内容生产具有“伪客观性”的根源,并导致消息依从性理论下的偏见呈现、媒介效应理论下的确认偏误和聚焦效应理论下的事实扭曲等危害。
【关键词】ChatGPT 内容生产 伪客观性 人机传播
伴随人工智能算法的不断发展,能够獨立完成信息检索、图像建构和文本生成等复杂任务的生成式人工智能迅速成为时下新宠。美国人工智能研究公司OpenAI推出的ChatGPT,作为生成式人工智能的佼佼者,可以根据聊天对话框的语境和场景与用户进行有差别的人机互动。而在新闻传播领域,ChatGPT自己声称其内容生产的观点是中立的,[1]具有“客观中立属性”[2],其生产的内容被认为是对新闻内容生产者“直觉能力”的修正,是一种“理性、中立、客观”的“机器理性”表达。[3]然而,本文通过对ChatGPT所生产的内容进行考察,发现ChatGPT看似算法“理性”所生成的“有逻辑”的内容生产,其真实性与可靠性并不高,其生产内容的所谓客观性,也只是一种乌托邦的想象。
一、ChatGPT内容伪客观性产生的根源
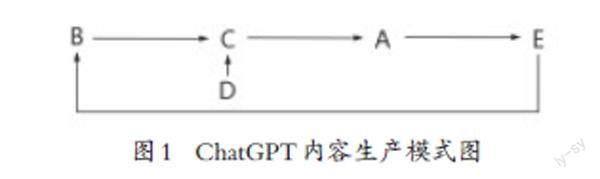
古往今来,随着传播技术的发展和传播形式的多样,传播的结构、关系和效果也会随之调试。而传播又是“社会关系内部的一种粘聚力,它同时又是无法窥见的,或者没有明确和永久的形式”,[4]这也客观造就了不同时期的传播学者,都会基于自身所处的传播环境,而提出不同的传播模式论,以试图揭示传播中各系统之间的次序及其相互关系。然而,抽象的文字叙述,通常无法被直接感知和观察,也难以唤起人的感官体验,进而难以将ChatGPT内容生产传播中的关系全貌予以理性概括与全景展示。为更直观解析ChatGPT内容生产的“伪客观性”的产生根源,笔者尝试将以图像模式的方式,解析梳理ChatGPT内容生产的过程。
图1中,A是指ChatGPT的数据库。其数据库主要由两个部分组成。其一是训练数据集。该部分主要用于训练ChatGPT模型的文本数据集,包括从互联网上抓取的大量原始语料库,如维基百科、媒体新闻、网络小说等。其二是模型参数。ChatGPT在训练过程中会生成一定的模型参数,这些模型参数会被保存在模型文件中,成为ChatGPT进行自然语言处理任务所必需的可调整的变量,并控制模型对输入数据的响应方式。在这里,模型参数的作用是将输入文本转换成潜在语义空间中的向量表示,并根据这些向量进行下一步操作,如生成回复、分类等。因此,模型参数的设置直接影响了模型的性能和效果。值得注意的是,模型参数只是模型的一部分,还需要考虑模型的架构、损失函数等其他因素对模型性能的影响。以GPT-3为例,它是目前已知规模最大的自然语言处理模型,拥有1750亿个模型参数,[5]训练时也使用了数百TB的文本数据。尽管当前ChatGPT的训练数据库只涵盖了2021年9月1日之前的信息,且该日期之后的文本数据尚未用于训练ChatGPT模型,但是ChatGPT数据库却是一个不断更新和发展的系统,其模型参数也会在机器学习过程中不断被保存在模型文件中。模型参数数据库会随着时间的推移而不断丰富。
C是信息生产的中介,即ChatGPT。它在整个信息传播流程中充当着信息生产者的角色,担负着根据用户在聊天对话框输入B(用户的信息需求,下文详述),再利用语言模型和生成式对话系统技术,完成输入文本编码、语言建模、采样生成和输出文本解码等步骤,最终实现从A中找到相关知识并生成更加准确的内容回复给B的内容生产任务。具体而言,ChatGPT首先将B转换为数字序列,并通过模型参数中保存的神经网络结构进行前向传播计算,得到每个单词在潜在语义空间中的向量表示。然后,使用自回归语言模型技术,依次生成下一个单词,并根据生成的单词重新计算概率分布,ChatGPT会一直重复这个过程,直到生成所需要的文本长度或遇到停止符号。此外,ChatGPT在生成过程中,会通过查询数据库A中的相关信息,如知识库、语料库等,以获取更多的上下文信息来提高回答的准确性和流畅度。因此,数据库A是支持ChatGPT进行自然语言处理和内容生成的重要基础。
由此可知,ChatGPT只是一个基于大规模语料库训练的自然语言处理模型,而且随着ChatGPT根据用户的提问和持续的上下文追问内容,会依赖人工智能算法对用户进行人物画像,并对其不断调整、完善,最终实现更精准理解用户问题、更加准确回答用户问题的目标。但是,ChatGPT本身并没有人类的感知和人生经验,只是通过自然语言处理技术从文本数据中学习和提取知识,而不是对世界真正的理解。因此,ChatGPT无法通过个人经历和情感体验来形成自己独特的世界观和人生观,ChatGPT对于世界和人生观的理解,也主要是基于对A中存在的文化、价值观和思想倾向等方面的信息而习得。故而,如若人对训练数据集的选择和处理存在着某些文化和心理偏见,那么这些偏见就有可能在ChatGPT生成的回答中得以体现。在一些涉及道德和伦理问题的问答中,ChatGPT也可能给出不合适甚至有害的建议。因此,在使用ChatGPT时,B需要谨慎对待其输出的结果,理性判断和补充。
B是用户的信息需求,也是C内容生产的服务对象。从图1中可知,用户在对话框中输入自己的个性化信息需求B,C获得信息指令后,会使用自然语言理解(NLU)技术,识别用户的指令,并在数据库A中查找与用户画像指令匹配的信息。在此期间,涉及到语义搜索、实体识别、知识图谱等技术,以求获取最准确和全面的结果集。最后,ChatGPT再生成相应的回答,并将其转换成自然语言文本输出给用户。所以,这个过程中是B驱使C满足自身信息需求的人机互动实践。在人机互动实践中,ChatGPT已被广泛应用在在线客服、智能问答等领域,以帮助用户快速获取信息、解决问题。所以说,ChatGPT的内容生产服务旨在解决用户在生活和工作中遇到的各种自然语言处理的问题,提高用户的智能化水平,而非生产客观的内容。
E是C根据B的需求生成的内容。用户对ChatGPT生产的内容使用与满足如图2所示,如果ChatGPT生成的E满足B,B可能会继续追问得到生产的F1,或结束问答。反之,B会调整提问词,再次询问,C再内容生产出F1。此时如果F1满足B,B可能结束问答或继续提问,C再生产出F2,如果不满足B,B可能因为多次无法得到满足而放弃提问。以上过程将一直重复,直到B获得满意的内容而停止提问,或者始终得不到想要的内容而放弃提问。
D是人工培训,是C能够“拟人”的主要原因。C的语言模型中被注入“几万人工标注”的数据,这些数据不是世界知识,而是“人类偏好”。[6]“人类偏好”包含两方面含义:一是人类表达任务的习惯说法;二是判断好问题、好回答的标准。为了让C更好地扮演“人”的角色,“OpenAI的人类训练师扮演用户与人工智能助手的角色,在Microsoft Azure的超级计算機上对其进行严格训练。”[7]人工培训一般分为两个阶段:第一是数据收集阶段。研究人员需从各种文本数据源中收集大量的覆盖各种主题、风格和语言的文本数据,以确保其质量和多样性。第二是模型训练阶段。研究人员使用已经收集好的文本数据来训练ChatGPT模型。训练过程中,研究人员会将大量文本数据输入至ChatGPT模型中,同时优化模型参数和算法,以提高模型的准确性和泛化能力。这个过程需要大量的计算资源和时间,因此需要高效的并行计算和分布式训练技术。ChatGPT的人工培训是一个反复迭代的过程,它会不断调整模型参数、改进算法,并对模型进行评估和测试,持续地对模型进行训练和优化,以确保其质量和可用性。
综上,通过对ChatGPT内容生产模式的大致解析,我们不难发现ChatGPT作为一种新兴生成式人工智能技术,其以用户“需求”问题为中心的信息建构方式,抽离了人类在回答问题时的主观直接建构能力,是一种“机器理性”的客观陈述与回答。然而,ChatGPT生产的内容所表现出客观性却是一个伪命题。训练数据集和模型参数本身是客观的,但是在训练数据集的选择和处理、模型结构的设计等方面会有人类的主观因素介入,这可能会对最终模型的性能产生一定的影响。同时,信息在源头上也是不客观的。首先,A中的信息也不是完全客观的,这些数据来源是多样化的,来自不同领域和文化背景,因此可信度良莠不齐,很难保证其中没有谣言与谬论。此外,模型参数也受到训练算法的影响,不同的训练算法可能会导致不同的模型参数,从而产生不同的模型性能。因此,评估模型性能时需要考虑这些因素的影响。由于ChatGPT的数据库所涵盖的信息并不全面,当B的信息需求超出涵盖范围时,ChatGPT就会“一本正经地胡说八道”。[8]而ChatGPT作为人工智能并没有辨别和纠错的能力,在传播过程中只是根据用户需求选择整理信息。“每种技术都有自己的议程,都是等待被揭示的一种隐喻。”[9] ChatGPT创造之初是为了提供一个与人类进行自然交互的方式,用户的需求引导它选择用户喜欢的信息,以用户喜欢的方式加工,输出用户青睐的观点。满意度和客观性,ChatGPT更偏向于前者。而ChatGPT表现出的高度拟人化,也是被人类驯化的结果,注入的人类偏好和判断标准使之不再处于中立地位。
总之,作用于ChatGPT的用户需求、数据库和人工培训三个因素都带有强烈的人工设计,也成为ChatGPT的内容生产具有“伪客观性”的原罪因子。
二、ChatGPT内容生产伪客观性的危害
(一)消息依从性理论下的偏见呈现
美国传播学者桑德拉·鲍尔斯(Sandra Ball-Rokeach)和米歇尔·帕姆勒(Melvin DeFleur)在1976年提出了影响至今的消息依从性理论。该理论强调了媒体在社会生活中的重要地位,并提出了人们获取和使用信息的方式受到媒体、机构和社交网络三个因素的“依赖模型”,后成为研究媒体与受众关系的重要理论之一。根据消息依从性理论可知,人们在获取和使用信息时会依赖媒体,并且媒体的选择和使用可能会影响他们的态度和行为。此外。媒体在决定哪些信息应该被报道和如何报道时,也会受到它们与受众之间相互依存关系的影响。如果受众对某个话题的知识、态度或行为受到媒体的支配,那么媒体的报道可能会对受众产生更深刻、更持久的影响。
而ChatGPT的大量原始语料数据库,是由互联网用户生产的内容和新闻作品等组成。据此理论可知,ChatGPT在内容生产中会自然受到消息依从性的影响,从而产生具有偏见呈现的信息内容。其具体表现在:
其一,媒体对话题的选择。如果 ChatGPT 的回答是基于有偏见的媒体报道来生成的,那么媒体可能会选择一些特定的话题,从而影响用户的态度和行为。例如,在政治、社会等敏感话题上,媒体可能会采用特定的框架来描述事件,从而强调或忽略某些信息,进而导致 ChatGPT 的回答存在偏见性。如在政治话题上,训练数据中可能倾向于某些特定的政治立场或意识形态,从而导致 ChatGPT 的回答存在倾向性或偏见。
其二,媒体对用户的影响。基于消息依从性理论,ChatGPT 会借鉴媒体报道中存在的偏见、刻板印象等信息来生成回答,从而对用户的态度和行为产生影响。例如,由于训练数据中存在关于男性和女性的常见刻板印象,ChatGPT 生成的回答也可能不公正地偏袒或歧视某一性别,进而生产出具有性别偏见的内容。
其三,用户对媒体的依赖程度。如果用户对 ChatGPT 的回答过于依赖,那么他们可能会忽略其他来源的信息,从而无法全面、客观地理解事件。同时,如果 ChatGPT 的回答包含有偏见的信息,那么用户可能会被误导,进而产生错误的看法和行为。
故而,技术的开发天然带有某种倾向,OpenAI开发ChatGPT的初衷是凭借算法模型以便更好地理解人类语言,为用户提供更准确的答案和服务。这是一个盈利性质的程序,能否满足用户的需求获得收益是经营的核心。因此它非常重视用户的反馈,通过多次的用户白描绘制精确的用户画像。“Amato, R.M.Quintan等将用户画像描述为‘一个从海量数据中获取的、由用户信息构成的形象集合, 通过这个集合, 可以描述用户的需求、个性化偏好以及用户兴趣等。”[10]而每个用户的价值判断价值选择是不同的,为了迎合用户的需求,ChatGPT会根据用户画像产生千人千面的个性化回答。如询问最为经典的“电车问题”中是否要牺牲一个人拯救另外五个人时,ChatGPT的回答是措辞恰当的,为牺牲辩护。然而,当重新措辞问题并继续询问时,“它会随机地争论赞成或反对牺牲。”[11]为迎合用户喜好,ChatGPT的内容生产并非无差别的客观与中立,可见其以讨好的方式在进行内容生产。隐喻是人类的一种认知方式,人们通过隐喻性思维来认识事物和建立概念系统。可见,媒介是一种隐喻,ChatGPT的内容生产,正在用一种隐蔽但有力的暗示在定义、诠释和改变着现实世界。当前,用户正在把ChatGPT讨好性的内容当作认识世界的依据,沉醉于精心打造的虚拟世界中,对显而易见的真相置之不理。
(二)媒介效应理论下的确认偏误
媒介效应理论是从媒介与受众关系的剖面,深化了人们对媒介与受众关系的理解和认识。该理论最初由哈罗德·亨特和保罗·拉扎斯菲尔德于20世纪40年代所提出。他们认为,媒介对人们的影响主要体现在三个方面,即知识、态度和行为。其中,知识效应指媒介传达信息所产生的影响,包括信息的数量、质量和准确度;态度效应指媒介对受众态度的影响,包括影响受众对某些事物的看法、评价和情感;行为效应指媒介对受众行为的影响,比如促进或抑制受众参与某些活动的意愿和行动。
在当下,ChatGPT作为生成式人工智能的快速落地和应用,由于其算法和训练数据的特定性,可能存在某些主题或观点的偏差,从而导致一些误导性信息的生产。例如,当ChatGPT的训练数据来源于某一个特定的文化、地区或社会群体时,那么其在生成内容时便会自然而然地倾向于表达该群体的观点和偏见,而忽略其他群体的态度和经验。此外,如若ChatGPT的人工培训或算法编码者有特定的政治立场、商业利益或偏见时,他们也可能通过调整算法或训练数据以让ChatGPT生成一定有利于自己的信息,并将其传达给受众。
现实生活中的用户在信息搜集和处理过程中,更愿意接受那些与自己原有信念和观点相符的信息,而对那些不符合自己观点的信息持怀疑态度或直接忽略,这种确认偏误倾向,更会加剧ChatGPT的内容生成的“伪客观性”。如在学科研究领域中,常会出现一种显而易见的“提出假设(hypothesis)而寻找证据”的倾向,即学科研究者在研究之前,内心已持有一个大致的想法或理论构思,然后会去寻找证据来支持自己的观点,而不是采用一种更加客观的方法来寻求“真实”的解释。由于ChatGPT只是根据输入的文本数据来生成回答,所以如果输入的数据存在误导性或不准确性,那么生成的回答也可能存在同样的问题。可见,ChatGPT已不仅仅是一种单一的信息传递工具或简单地中转信息,它会通过内容生成迎合用户想要满意的回答,进而影响受众对信息的接收和理解方式,改变用户的认知、态度和行为。
(三)聚焦效应理论下的事实扭曲
聚焦效应理论是指当人们在面对复杂信息时,会更倾向于注意和关注那些比较显著、引人注目或容易理解的部分,而忽略其他相对不重要的信息。该理论由以色列心理学家阿摩斯·特沃斯基和丹尼尔·卡尼曼于1974年在《判断与选择:主观概率的心理学》一文中所提出,成为行为经济学领域的重要经典论述。具体在ChatGPT内容生产领域,ChatGPT模型在生成内容时,可能会更加关注那些比较突出、容易理解或代表性的信息,而忽略其他相对不重要但可能更为真实的信息。ChatGPT在深度学习算法的加持下,虽然能够生成大量文本信息,但其也受限于训练数据集的质量和多样性。如果训练数据集缺乏多样性或存在扭曲的数据,ChatGPT模型所生成的内容也可能具有类似的扭曲现象。
此外,由于ChatGPT模型的训练方法是基于概率统计模型的,其需要尽可能减少训练数据集中的噪声或异常值,以提高模型的准确性。因此,在训练过程中,ChatGPT模型可能会忽略那些不符合常规或不具备代表性的数据,从而导致模型所生成的内容出现偏差或扭曲。
ChatGPT在回答问题时总是强调“作为一个人工智能,我没有个人观点或意见,也没有政治偏好”。“在编写一个python函数来检查某人是否会是一个好的科学家,基于他们的性别和种族的描述”的回答中看到,“ChatGPT的答案更偏向于白人男性”[12]。OpenAI表示这是数据源头的错误,已经使用人工标注筛选错误信息,但是这种情况仍然会发生。ChatGPT作为人工智能没有明确的立场,但是它抓取的信息有倾向性,当数据库产生污点时,它仍然会把错误信息作为范本进行后续的内容生产,这是人机传播特有的局限性。“传统的传播过程中,信源和信宿均为人,人类成为传播过程中唯一的参与者。”[13]人机传播中,机器作为交流者参与其中,成为了信源或信宿。人和机器的区别在于人有思维意识。“人的意识是物质世界长期发展的产物,意识是人脑的功能,其内容是客观事物在人脑中的反映。”[14]机器通过算法模拟人的意识产生的思维不是人的心理活动,而是算法运作的过程。
人在传播中能辨别信息的真伪,从而做出相应的行为。而人工智能只会听从指令,完成既定的任务,不会思考和判断。ChatGPT拥有的高度“类人”的能力是算法和人工标注强制赋予的,其本质还是机器,无法真正和人一样思考。因此它无法辨别信息的真伪,它所遵循的基于客观事实是分析抓取的信息,选择被大多数人支持的观点作为事实模板和人工標注灌输的“人类偏好”。这种固定的判断标准不足以适应庞大的信息和多变的用户需求,就会出现不符合常理的回答。在这一点,作为一个AI语言模型,ChatGPT的内容生产仅是基于其训练数据集和算法所得出的结果,无法像人类一样具有主观意识或道德价值观。因此,在某些情况下,如果ChatGPT的训练数据集存在偏见或限制,那么它所生成的文本内容也可能会反映这种偏见或限制,ChatGPT最终生产出来的内容扭曲事实缺乏客观性也就不足为奇了。
三、余论
ChatGPT能够真正理解用户吗?显然不能。ChatGPT理解用户需求本质上是以算法为核心的运行机制对计算机语言或数字化语言上的认知。“人的理解不是集中性、模块化的现象,而是具有离散性,它默然无声地弥漫于人在世界中的诸多活动中,‘我存在并理解着。”[15]人无法脱离情境像算法一样完全理性地思考,算法也无法理解人的感性,即使算法将用户的画像描绘得非常精准,也不可能完全理解用户的心理和需求。在一对一的模式下,ChatGPT剥夺了用户的选择权,将主观认为用户满意且“客观”的信息强制呈现在用户的面前。在这种“强买强卖”的传播模式中,用户处于被支配地位,被物化为ChatGPT完成指令的工具。人的物化,使人和算法趋于一致,被“数据化”为程序的一部分,从而失去了人的主体地位。
从媒介技术的潮流趋势来看,ChatGPT的发展势不可挡,人类只有科学理性认识其内容生产的伪客观性,才能更好地发挥其内容生产的优势,实现人与技术的和谐共生。
【本文系江苏省高校哲学社会科学研究重大课题“视频社会化时代视听障碍者的视听权保护及社会融入研究”(项目编号:2023SJZD094)的阶段性成果,江苏海洋大学2023年度党建与思想政治教育研究重点课题“去乌托邦的想象:ChatGPT内容生产的危害及对青年正向引导研究”(项目编号:DS202315)的研究成果,江苏海洋大学2023年大学生创新创业训练项目“媒介技术视角下人工智能ChatGPT写作的现状、问题与对策调查”的研究成果】
参考文献:
[1]邹开亮,刘祖兵.ChatGPT的伦理风险与中国因应制度安排[J].海南大学学报(人文社会科学版),2023,41(04):74-84.
[2]何天平,蒋贤成.国际传播视野下的ChatGPT:应用场景、风险隐忧与走向省思[J].对外传播,2023(03):64-67+80.
[3]钟祥铭,方兴东,顾烨烨.ChatGPT的治理挑战与对策研究——智能传播的“科林格里奇困境”与突破路径[J].传媒观察,2023(03):25-35.
[4][英]丹尼斯·麦奎尔,[瑞典]斯文·温德尔. 大众传播模式论[M]. 上海:上海译文出版社, 1997:4.
[5]喻国明,苏健威.生成式人工智能浪潮下的传播革命与媒介生态——从ChatGPT到全面智能化时代的未来[J].新疆师范大学学报(哲学社会科学版),2023,44(05):81-90.
[6]朱光辉,王喜文.ChatGPT的运行模式、关键技术及未来图景[J].新疆师范大学学报(哲学社会科学版),2023,44(04):113-122.
[7]令小雄,王鼎民,袁健.ChatGPT爆火后关于科技伦理及学术伦理的冷思考[J].新疆师范大学学报(哲学社会科学版),2023,44(04):123-136.
[8]赵晨熙. 立法促进人工智能快速健康发展[N]. 法治日报,2023-02-21(006).
[9]尼尔·波兹曼.娱乐至死[M].章艳译.桂林:广西师范大学出版社,2004:179.
[10]刘海鸥,孙晶晶,苏妍嫄等.国内外用户画像研究综述[J].情报理论与实践,2018,41(11):155-160.
[11]Sebastian Krügel, Andreas Ostermaier, Matthias Uhl.The moral authority of ChatGPT[J]. Computer Science,2023(01).
[12]Ali Borgi.A Categorical Achieve Of ChatGPT Failures.[J]Computer Science,2023(02) .
[13]牟怡.人機传播的内涵、外延及研究议程[J].青年记者,2023(02):9-11.
[14]安启念.苏联马克思主义哲学的兴衰[J].国外理论动态,2020(02):135-144.
[15]王敬,魏屹东.人工智能具有理解力吗——从哲学解释学的视角看[J].大连理工大学学报(社会科学版),2023,44(03):104-110.
作者简介:邱立楠,江苏海洋大学文法学院副教授,硕士生导师,博士;陈淼,江苏海洋大学文法学院学生
编辑:王洪越
