基于电子病历的作物病虫害关联挖掘及智能诊断
2023-12-16徐畅张领先乔岩
徐畅,张领先*,乔岩
(1.中国农业大学信息与电气工程学院,北京市,100083;2.北京市植物保护站,北京市,100029)
0 引言
作物病虫害是制约农业可持续发展的主要因素之一,也是影响作物产量和品质的主要原因[1],借助人工智能技术研究作物病虫害自动检测问题已成为目前的研究热点。作物病虫害研究需要大量的实测数据,目前相关研究主要集中在两个方面,一是基于深度学习的计算机视觉技术[2],通过显微图像、多光谱图像、高光谱图像和遥感图像等成像技术无损地诊断作物病虫害;二是基于传统机器学习的多源数据融合技术,通过传感器、气象站和物联网等硬件技术监测作物病虫害的影响因子[3]。但是它们均会受到数据获取困难、技术实施成本高以及作物病虫害发生态势复杂等因素的限制。
由北京市“植物诊所”形成的电子病历为数字化赋能作物病虫害挖掘与决策提供了新的思路[4-5],也是小农户与现代农业有效衔接的重要措施。作物病虫害是病原物、寄主作物和环境条件相互作用而产生的(3 个要素的关系被称为作物病虫害三角关系,简称病三角原理)[6]。而电子病历中每条处方代表一个真实病虫害发生“点”,包含“病原物—寄主—环境”三者及其相关关系的重要信息。通过电子病历挖掘,可以多角度揭示作物病虫害关联关系及其变化规律。
目前生物医学研究领域已有较为深入的探索[7],多项研究证明处方数据具有回溯性和可预测性及辅助构建临床决策支持系统的能力[8]。但是,农业领域电子病历应用还处于起步阶段。PEMRs 作为一种未得到充分利用的多模态数据源,可以通过挖掘历史数据的潜在价值,发现新知识,因此对其进行深入挖掘具有一定的研究意义。中国农业大学张领先团队已在基于电子病历的作物病虫害智能诊断与处方推荐进行了初步探索[9],徐畅等[4,10]基于处方结构化信息出发,利用Stacking 集成学习和优化的LightGBM 实现了不同场景下番茄作物的病虫害诊断;丁俊琦等[5,11]和张领先等[12]基于处方的非结构化信息利用深度学习模型实现了多种作物的处方推荐。然而,作物病虫害发生原因复杂多变,各种因子相互关联、相互影响。因此仅从统计数据来确定特征和病虫害间更深层次的关系是一项困难的任务。如何高效地挖掘处方大数据并辅助后续作物病虫害研究,目前还是亟待解决的问题。
知识图谱、机器学习和预训练语言模型等人工智能技术发展为解决上述现实难点和痛点带来了新的契机,利用信息技术手段开展作物处方数据的管理和服务是一项前所未有的尝试。早期作物病虫害关联挖掘最常见的两种研究思路:一是利用Meta 等分析方法系统分析公开发表的研究[13];二是利用农业物联网和传感器采集温湿度、风、光照等环境因子,结合机器学习模型探究区域范围影响病虫害的关键因素[14-15]。
知识图谱(knowledge graph,KG)的本质是一个由大量实体及其之间的关系组成的大规模知识库,用于可视化描述知识资源及其载体,挖掘、分析、构建、绘制和展示知识及它们之间的相互联系[16]。知识图谱作为一种语义网络,具有可扩展性强、支持智能应用等优点[17-18]。随着大数据和深度学习的发展,改善了人工开具处方效率低和成本高的问题,以BERT[19]为代表的预训练语言模型可以利用大规模文本数据的自监督性质来构建预训练任务,辅助抽取出良好的文本特征为文本分类提供了有效的方法[20],为基于处方文本数据进行诊断提供了可行性。同时以K-近邻(K-nearest neighbor,KNN)为代表的机器学习算法可以快速从大量数据中挖掘能够代表一类事物的规律,从而对事物进行预测和分类[21]。
针对上述问题,基于电子病历中的结构化数据构建作物病虫害知识图谱,将复杂的数据可视化,利用半结构化数据和领域知识对知识图谱进行增强,并存储于Neo4j 图数据库。
进一步知识图谱的挖掘可从以下3 个方面展开:高发病虫害、病虫害间的关联关系、相似病虫害发现,转化为计算机领域的查找“热”(popular)的节点,联系链路发现、相似节点等关联挖掘问题,利用GDS 与机器学习模型相结合解决。在此基础上基于电子病历中的非结构化文本数据(问诊记录),将病虫害诊断转化为文本分类问题,利用BERT 算法挖掘文本特征后利用CNN 实现文本分类,模拟植物医生诊断思维模式[22]。
1 作物病虫害知识图谱的构建
1.1 作物病虫害多源数据采集与预处理
本研究数据主要包括3 部分,分别是:北京市植物保护站提供的作物病虫害处方数据,Plantwise 网站总结归纳的农业技术明白纸,百度百科、中国农业信息网、兴农网以及蔬菜网等权威网站。
1.1.1 处方数据
2012 年,北京首次引入了国际应用生物科学中心植物诊所的先进概念。植物医生基于双向信息流的原则和有害生物综合防治(integrated pest management,IPM)原则为农户提供个性化精准的作物病虫害问诊服务,问诊过程形成标准的处方,通过3 级数据验证程序后录入数据库。
1.1.2 农业技术明白纸
以动态数据为导向,处方数据库每年更新,明白纸每年进行动态开发和修订,共完成了覆盖全市22 种主要作物在内的127 种病虫害的明白纸,以农业防治和高效、低毒的化学农药等绿色防控技术为主,形成了一套动态、绿色、高效的病虫害解决方案库,基本实现了对主要作物常见病虫害问题的全覆盖。
1.1.3 权威网站
选择百度百科、中国农业信息网、兴农网以及蔬菜网等权威网站,利用XPath 解析网页提取结构化数据,作为知识图谱的补充数据。
针对以上多源数据,将其划分为结构化数据和文本数据两部分,借助深度学习、知识计算和可视化等大数据分析技术进行预处理,并转化为统一表示形式。对结构化数据进行数据清洗、描述统计、数据分析、图表展示、数据编码和特征提取等;对文本数据进行数据清洗、中文分词、去停用词、词频统计、特征处理和特征提取等。将预处理后的多源数据作为后续构建病虫害知识图谱、关联挖掘及智能诊断的数据源,整体流程如图1 所示。

图1 基于电子病历的作物病虫害知识图谱构建及关联挖掘Figure 1 Construction of crop pest knowledge graph and correlation mining based on electronic medical records
1.2 知识图谱构建整体流程
作物病虫害知识图谱的构建流程如图2 所示,将作物病虫害领域知识拓扑的构建归纳为数据获取、本体层构建、实体层构建和知识加工。作物病虫害领域知识图谱的构建过程分为4 步:首先,根据领域知识、文献阅读和病虫害三角原理初步设计本体层;第2 步通过实体识别、关系抽取等技术进行知识提取,从大量半结构化或非结构化的作物病虫害数据中提取知识图谱的元素,如实体和关系等,补充完善本体层;第3 步,通过知识融合消除歧义,并链接知识库和作物病虫害领域的实体,以此增强知识的逻辑和表达能力,并通过不断的调整和融合,完成实体层构建。最后,借助本体推理完成作物病虫害领域知识图谱的构建。
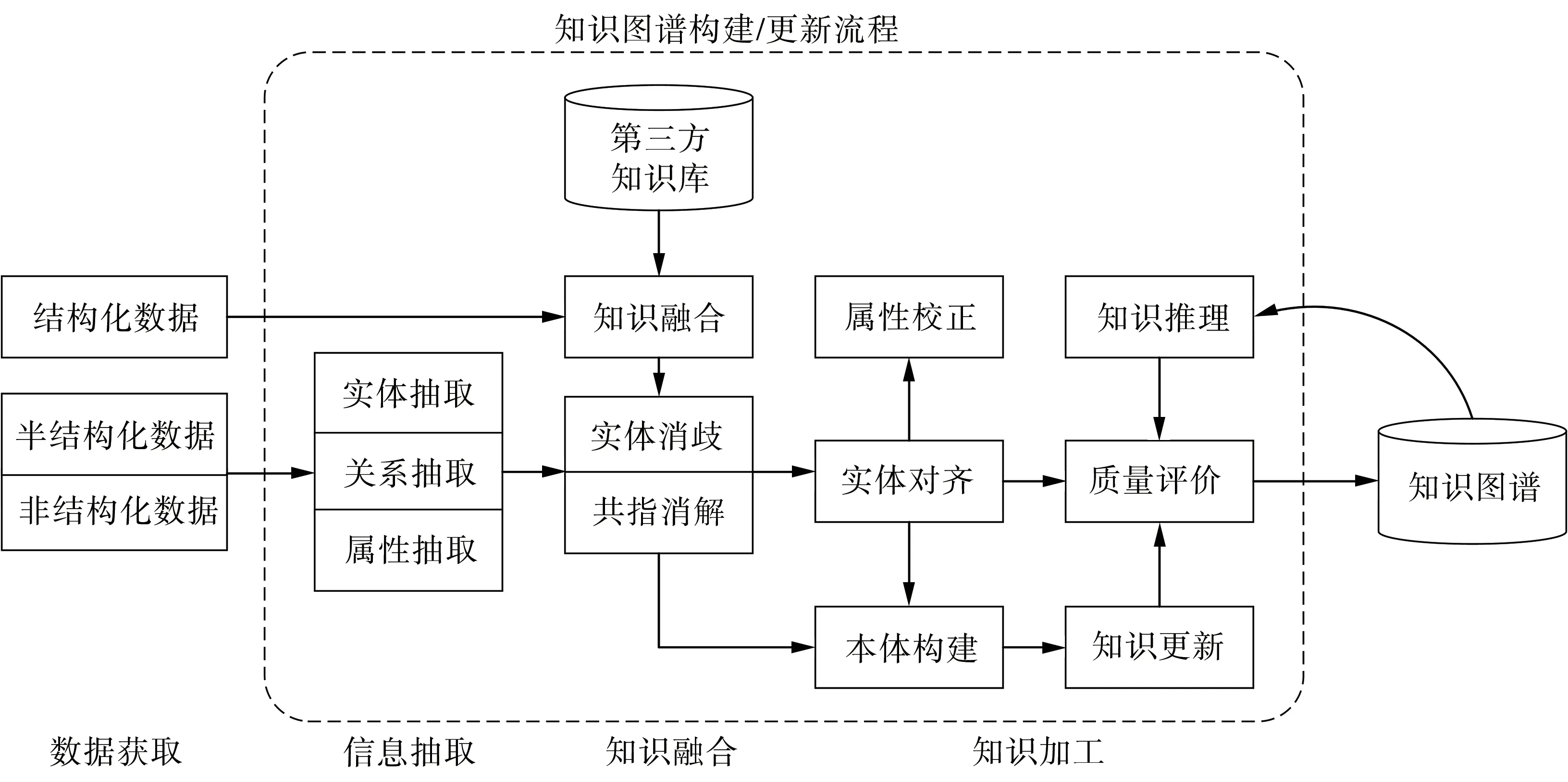
图2 作物病虫害知识图谱的构建流程Figure 2 Construction process of knowledge graph of crop pests and diseases
1.3 知识图谱本体层构建
以常见的20 种作物病虫害为主要研究对象,在充分参考主要数据源的基础上,通过设计全面细粒度揭示病虫害的本体概要模型,为进一步详细设计本体模型奠定了基础。
病虫害领域本体概要模型图如图3 所示。作物病虫害本体模型的设计与构建应与领域特点紧密结合,且该领域本体模型应具有可复用性。图3 从核心描述对象——作物病虫害出发,根据病虫害三角原理为核心向外扩展。

图3 作物病虫害领域本体模型概要图Figure 3 Summary of crop pest and disease domain ontology model
1.4 知识图谱实体层构建
将已有实体层数据进行清洗整理,按照1.3 节中设计的本体层框架导入。但是对于多源异构数据,通常会出现在实际场景中对应多种表达方式,例如缩写简写等,这种现象会导致融合后的数据存在大量冗余数据。
因此本研究进一步进行了实体消歧等数据处理操作。将清理整理后的数据,按照设计好的本体层框架导入,通过Neo4j 查询语言Cypher 来检索数据,得到知识图谱部分内容如图4 所示。
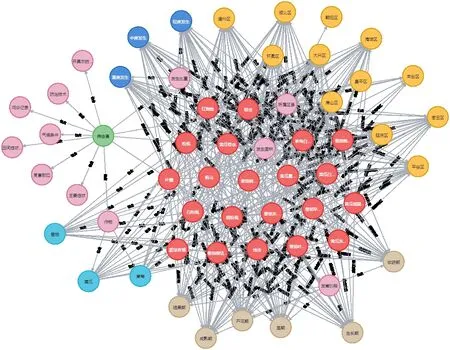
图4 作物病虫害知识图谱部分展示Figure 4 Part of the crop pest knowledge graph
2 基于知识图谱的关联挖掘
2.1 作物病虫害数据分析
基于知识图谱,结合对处方数据的统计分析,探究各种实体(作物病虫害、所属区、作物、发育阶段、受害部位、发生比重、主要症状、田间症状分布、诊断结果)之间的关系,利用Neo4j 图数据库实现高效的关联关系查询和挖掘,如图5 所示。根据知识图谱统计分析,管理者可以对北京市整体或区域施行宏观把控,例如:顺义区保护地蔬菜病虫害以番茄晚疫病、灰霉病、黄瓜霜霉病、角斑病为主,发生程度为轻—中等发生,其中春季保护地番茄病毒病轻度发生;白粉病、叶霉病、瓜类角斑病、瓜类霜霉病在部分棚室中等发生;其他病虫害偏轻发生。保护地虫害轻—偏重发生,其中烟粉虱春季轻发生,夏秋季轻—中等发生;红蜘蛛、蓟马、蚜虫等小型害虫中等至偏重发生。当前生产菜农预防意识增强,物理预防措施越来越完善。通过提前定植,错过害虫发生高峰期,生产上采取阻断传播途径,创造不利于病源、虫源繁殖和传播环境条件,对防止病虫害发生有一定作用。
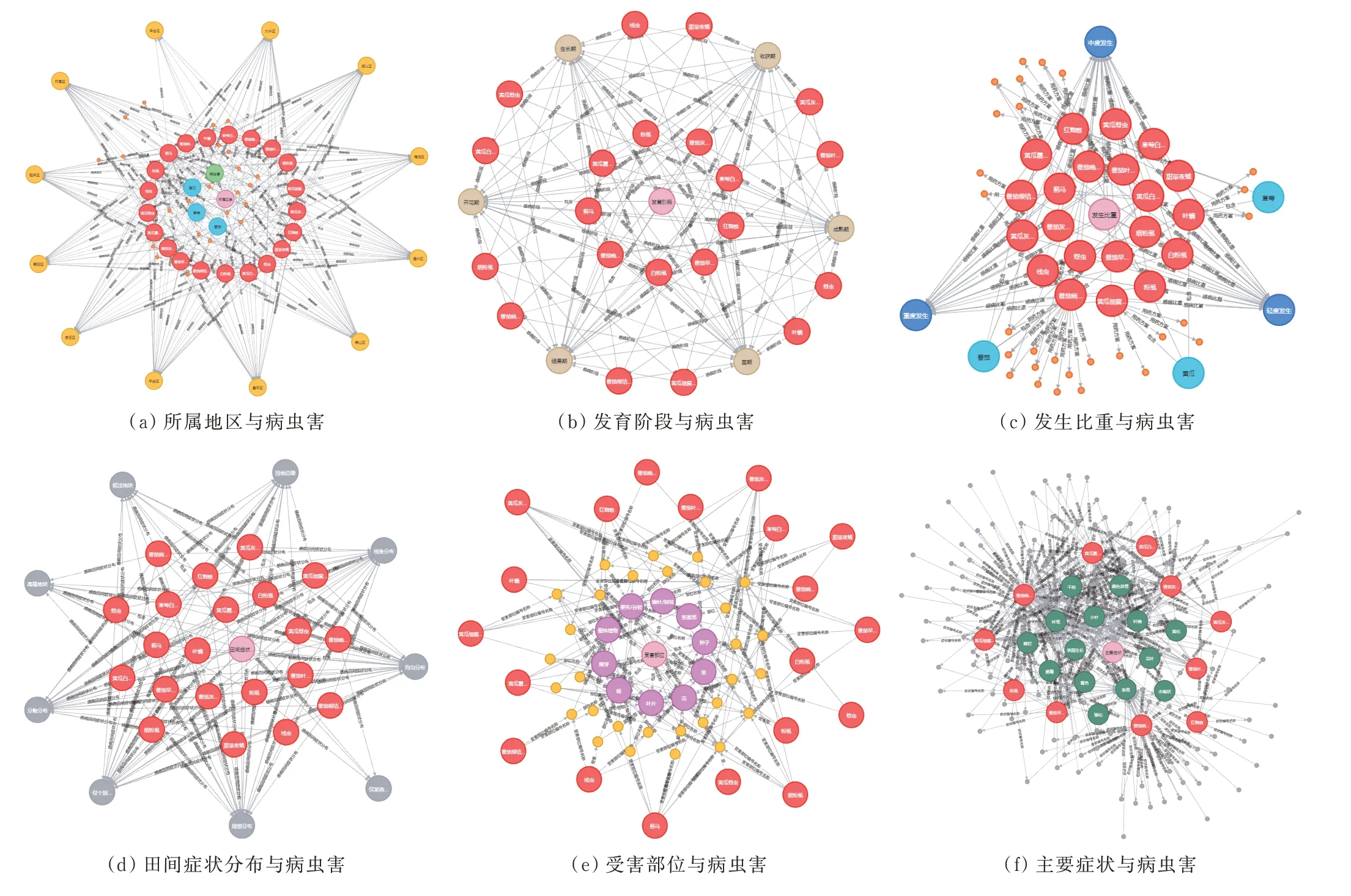
图5 作物病虫害知识图谱实体关系展示Figure 5 Demonstration of entity relationship of knowledge graph of pests and diseases
2.2 基于BERT-CNN 的文本分类算法
BERT 是采用Transformer Encoder block 进行连接的预训练语言模型,Transformer 中的多头注意力(Multi-Head)可以让网络捕捉更丰富的信息。BERT-CNN 模型是通过BERT 语言模型生成词向量,即得到每句的文本表示后(768 维向量),进一步使用CNN 提取文本特征,最后将每条文本经过全连接层进行分类输出,模型结构如图6 所示。

图6 BERT 算法框架Figure 6 Framework of BERT algorithm
输入文本X=[X1,X2…Xn],经过输入层得到向量形式E(X),在经过编码层后,得到基于BERT模型的动态词向量矩阵T=[T1,T2…Tn]。由于词向量维度过大,需要对其进行降维,以达到提取特征的目的。
将BERT 的输出Ti输入CNN 的卷积层,卷积核在动态词向量矩阵T=[T1,T2…Tn]上通过上下滑动来提取特征,其中卷积核的长度主要用于捕获d个词之间的关系,最后得到特征映射矩阵Ci=[C1,C2…Cn-d+1],计算公式如公式(1)所示。
利用CNN 的最大池化层提取主要的局部特征,得到文本特征Mi,最后输入全连接层中。
为避免过拟合,通常会在全连接层后接一个Dropout,其作用是以一定的概率丢弃神经元,将其置为0。
通过softmax(Mi)实现文本分类,如公式(3)所示。
式中:Wi——卷积核的权重矩阵;
b——偏置项。
2.3 基于Neo4j 和机器学习的关联挖掘
2.3.1 中心性与重要性——度中心性(Degree centrality)算法
度中心性是在网络分析中刻画节点中心性最直接的度量指标[23],一个节点的节点度越大就意味着这个节点的度中心性越高,由此可确定图中的最重要节点。对于一个拥有g个节点的无向图,节点i的度中心性是i与其他g-1 个节点的直接联系总数,节点i的度中心度表示如公式(4)所示。
2.3.2 目标最短路径——Dijkstra 算法
Dijkstra 算法是从一个顶点到其余各顶点的最短路径算法。它是从起始点开始,采用贪心算法的策略,每次遍历到起始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。输入有向图G=(V,E),起始顶点s∈V,并且每条边e∈E的长度e均为非负值,输出从s到v的最短路径的长度dist(s,v)。
2.3.3 相似性——KNN 算法
GDS 的KNN 可以用于大型图的全局推断,根据图中的接近程度,节点属性,社区结构,重要性等来确定节点之间的相似性。KNN 的度量选择由节点属性类型驱动,选择为jaccard 相似度进行相似度的计算,如公式(5)所示。
3 试验分析
3.1 试验环境及试验数据
以Neo4j 社区版5.5.0 为图数据库构建和存储知识图谱,Neo4j 图数据科学2.3 为Neo4j 图形算法版本,以Cypher 形式进行关联挖掘。BERT 相关模型使用NVIDIA Quadro P2000 GPU(5 GB)进行训练,并基于Pytorch 的Python 深度学习库实现,训练共4 个Epoch(每个Epoch 约1 800 次迭代),batch_size 设置为16,学习率设置为3×10-5。本研究选取2019 年3 月25 日至2021 年6 月13 日的45 833 条数据作为电子病历多模态数据的来源,并按照6:2:2 的比例划分训练集、验证集和测试集。
3.2 评价指标
基于GDS 实现的算法采用AUCPR(area under the precision—recall curve),即“精度—召回率曲线下面积”为评价指标。基于BERT 的病虫害多分类模型采用准确率(Accuracy)以及宏平均(Macro avg)和加权平均(Weighted avg)的精确度(Precision)、召回率(Recall)和F1值(F1-score)的作为评价指标。
3.3 试验结果与分析
3.3.1 基于度中心性算法的病虫害“热”点发现
在GDS 的应用中,需要计算外度(out-degree)中心性,即计算从一个节点发出的关系。表1 是使用度中心性来计算每种病虫害使用的药物处方数量,黄瓜霜霉病、黄瓜白粉病、蚜虫、番茄晚疫病和粉虱作为病虫害发生的“热”点,可进一步基于此提前实现病虫害预警或处方推荐。

表1 病虫害“热”点分析Table 1 Analysis of “popular” points of pests and diseases
3.3.2 基于Dijkstra 算法的病虫害间目标最短路径发现
基于构建的作物病虫害知识图谱,利用Dijkstra 算法可以挖掘存在联系的实体的所有链路。例如,涉及同一病虫害的症状可能不存在直接的关联,但通过最短路径的计算可以发现隐藏的联系链路,相应挖掘出重要的症状,为相似病虫害诊断提供关键路径。由于Dijkstra 算法支持加权关系,在比较路径时考虑了属性信息。图7(a)为使用Dijkstra 目标最短路径算法寻找到的病虫害“番茄灰霉病”和“番茄晚疫病”之间的最短路径,图7(b)为“蓟马”“粉虱”“白粉虱”和“烟粉虱”之间最短路径。
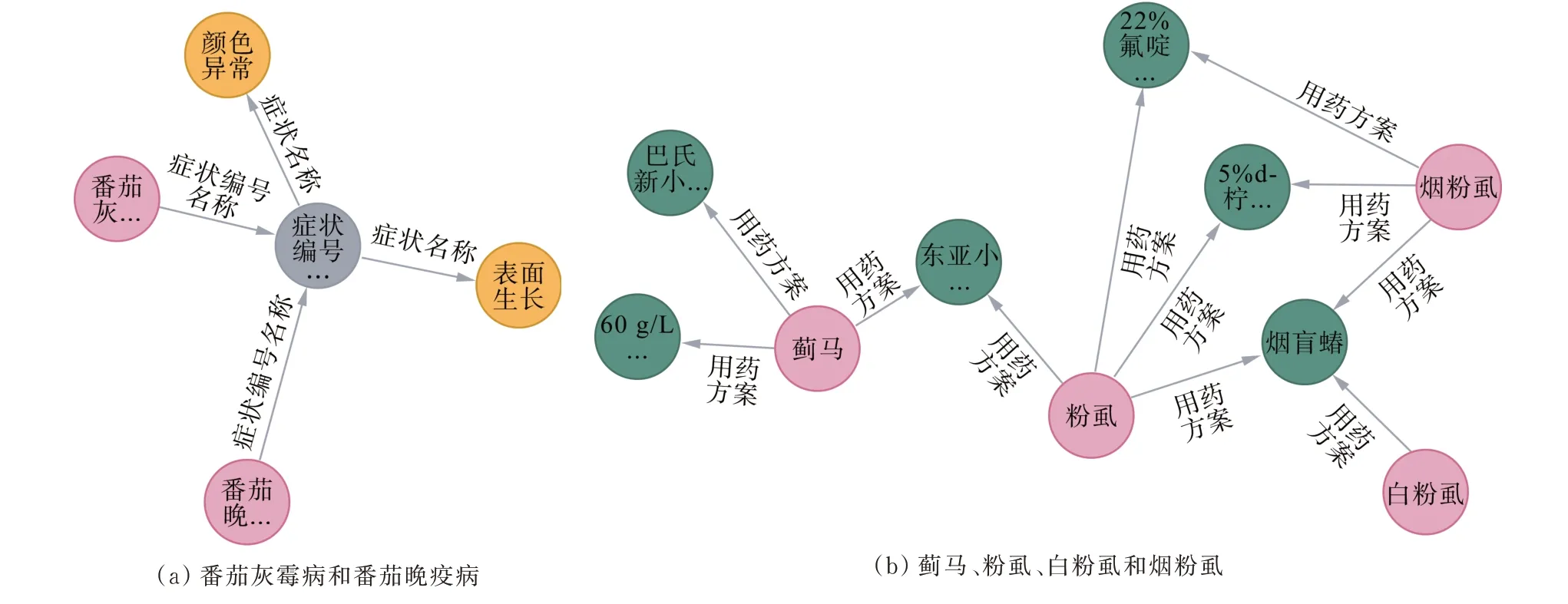
图7 病虫害间的最短路径图Figure 7 A map of the shortest paths between pests and diseases
3.3.3 基于KNN 算法的相似病虫害发现
在作物病虫害知识图谱应用中,首先利用快速随机投影(fast random projection,FastRP)算法实现图嵌入,进一步利用KNN 算法通过jaccard 计算某两个病虫害节点的相似性,将Top-K 限制为1,得到每个节点的最相似的配对,试验的结果见表2。

表2 病虫害相似度分析Table 2 Similarity analysis of pests and diseases
其中番茄晚疫病和黄瓜霜霉病以及粉虱和白粉虱都具有较高的相似性,高达0.8 以上。
3.3.4 基于BERT-CNN 的病虫害诊断
基于BERT 挖掘的文本信息作为CNN 和RNN 分类模型的输入,构建基于BERT-CNN 和BERTRNN 的多分类模型,实现作物病虫害的精准诊断。
试验结果如表3 所示,针对常见的20 种病虫害,BERT-CNN 在我们的特定任务上表现效果最好,其综合诊断准确率可以达到0.931 3,同时宏平均和加权平均的F1-score 达到0.876 5 和0.931 4,相比于原始的BERT 模型准确率、宏平均的F1-score 和加权平均的F1-score 分别提升0.48%、3.76%和0.57%,进一步说明能有效提取文本信息并实现分类。

表3 BERT、BERT-CNN 和BERT-RNN 的对比结果Table 3 Comparison of BERT,BERT-CNN and BERT-RNN
表4 展示了BERT-CNN 对20 种病虫害诊断的详细试验结果,其中75%的病虫害的诊断F1-score 可以达到80%以上,对于番茄根结线虫的诊断效果最佳,F1-score 可以高达0.984 2。

表4 基于BERT-CNN 的病虫害诊断结果Table 4 Diagnosis results based on BERT-CNN
对于表2 中相似度最高的番茄晚疫病和黄瓜霜霉病具有较好的区分能力,可以满足实际的诊断需求。
4 结论
针对作物品种及病虫害种类繁多、作物病虫害与特征间的关联关系复杂和研究数据获取困难等难点,结合电子病历多模态数据的特点,探究人工智能技术在作物病虫害关联挖掘中的应用。电子病历的数据包括结构化和非结构化数据,根据不同模态数据的优势对电子病历进行深入挖掘,其中利用结构化数据构建知识图谱,并结合非结构化数据和领域知识进行知识增强,可以直观可视化病虫害的概况。
为了挖掘潜在信息,进一步基于知识图谱进行关联挖掘,结合度中心性算法、Dijkstra 算法和KNN 算法实现“热”点发现、最短路径发现和相似病虫害发现,为后续诊断和推荐应用提供支撑。在此基础上,利用非结构化数据基于BERT-CNN 模型提取文本特征并实现病虫害诊断,并与BERT 和BERT-RNN 进行比较。试验证明BERT-CNN 模型的分类效果最优,对于常见的20 种病虫害的综合诊断准确率可以达到0.931 3。本文的主要创新点在于对电子病历大数据进行数据挖掘并辅助作物病虫害诊断,可以模拟植物医生的思维模式实现智能化服务,辅助早期智能决策与主动防控。未来将构建多模态数据集开展后续研究。
