基于近红外光谱和BYOL 对比学习的烟叶部位识别方法
2023-12-15杨德建赵辽英郝贤伟毕一鸣厉小润
杨德建,赵辽英,郝贤伟,毕一鸣,厉小润
1 杭州电子科技大学计算机学院,浙江杭州白杨街道1158 号 310018;
2 浙江中烟工业有限责任公司,技术中心,浙江杭州科海路118 号 310008;
3 浙江大学电气工程学院,浙江杭州浙大路38 号 310027
烟叶品质检测,对卷烟制品的配方设计与质量监控具有举足轻重的作用。随着当前烟草行业发展,传统检测方法已经不能够满足智能化检测和管控的需求。数字化转型是中国烟草科技创新发展的必然选择[1]。近红外光谱(Near Infrared Spectroscopy,NIR)分析技术具有高效、快速、无损和可在线等优点,已经在烟草行业得到广泛的研究和应用[2-4]。
不同部位的烟叶受到的光照、水分、温度不一样,会导致烟叶不同部位化学成分的不同,因此烟叶部位与烟叶品质有直接的关系。烟叶部位的识别,是烤烟烟叶收购与分级、卷烟配方设计的重要依据。烟叶部位的NIR 光谱定量分析有助于部位的识别,从而间接反映烟叶调拨、分选质量的年度间稳定性。目前用NIR进行烟叶品质检测主要是烟叶化学成分分析和产地识别[2-4],对烟叶部位的识别研究相对较少,且主要是基于传统机器学习方法。如马雁军[2]使用Projection of Basing on Principal Component and Fisher Criterion(PPF)投影方法分析样品间部位的相似性;王静[5]将深度信念网络(Deep Belief Network, DBN)的理论结合支持向量机(Support Vector Machine, SVM)建立近红外光谱多分类模型 DBN-SVM 识别烟叶部位。但是上述方法都是对实验室采集的粉末状烟叶光谱进行烟叶部位识别实验,烟叶光谱稳定,且不同部位烟叶光谱差异相对较明显。由于光照和环境的影响,烟叶不同部位的在线NIR 光谱不易区分,特征提取困难,因此需要研究特征增强或特征提取能力更强的方法。
卷积神经网络(Convolutional Neural Networks,CNN)作为典型的深度学习网络模型之一,具有很强的特征提取和模型表达能力,已被广泛应用于NIR 特征提取分析[5-6]。由于有标签的烟叶部位近红外光谱数据有限,影响了传统的CNN 模型在烟叶部位识别中的应用效果。对比学习(Contrastive Learning)是一种适用于无标签或少量标签样本的自监督学习方法,最近已在计算机视觉、自然语言处理和其他领域得到了应用[7]。BYOL(Bootstrap Your Own Latent,BYOL)[8]模型是一种通过两个神经网络自监督学习高维数据特征表示的对比学习模型,具有强特征提取和模型表达能力。
数据增强是BYOL 对比学习的关键步骤之一。文献[9]在基于对比学习的高光谱图像分类模型中,通过变分自编码器(Variational Auto-Encoder,VAE)[10]和对抗自编码器(Adversarial Autoencoders,AAE)[11]提取特征实现数据增强。但是VAE 和AAE 都由编码器、隐层和解码器组成,结构较复杂,并且都是通过优化的方法提取特征,时间复杂度高。NIR 的微分光谱波峰波谷特征明显,具有简单快速实现数据增强的作用,在很多研究中得到了应用,如杨双艳等[12]在基于近红外光谱的粒子群-支持向量机(PSO-SVM)模型中使用多元散射校正和二阶导数,对烟叶等级进行识别;胡涌等[13]在NIR 偏最小二乘定性判别模型中使用K-S 方法挑选样品从而提高了预测烟叶水分的准确度。但是现有文献都是将微分光谱作为数据预处理结果直接用于分类或判别,如何将微分光谱和原始光谱有效结合实现光谱数据增强未见报道。
本文提出一种基于近红外光谱和BYOL 对比学习的烟叶部位识别方法, 以NIR 微分光谱与原始NIR 光谱融合实现光谱数据增强,以卷积自编码器和多层感知器实现在线网络和目标网络,以两个网络输出的均方误差为对比损失,通过损失最小优化的编码值识别烟叶部位信息,分类识别烟叶部位。以我国4 个产地的1026 个样本的3078 条光谱数据为实验对象,对所建立NIR-BYOL 识别模型进行验证。结果表明,通过该方法可以对烟叶部位进行快速、准确识别,对维护卷烟产品的质量稳定性有重要意义。
1 实验部分
1.1 材料
共选取2018—2020 年,1026 个包含上部、中部、下部的原烟样本,由复烤厂专业人士按《42 级烟叶分级国家标准品质因素表》确定每个烟叶样本部位和等级,等级包括B2F、C1F、C2F、C3F、C4F、C2L、X2F 等。每个部位的样本数有342 个,分别来自贵州、湖北、云南、广东4 个产地,烟叶样本信息见表1。如图1 所示,每个原烟样本去除叶尖和叶基,将剩余部分垂直于叶脉剪切成宽为3~6 cm 的条状叶片,叶片未破碎,随机叠放后用手轻微压实,以避免叶片翘曲、弯曲等;使用光谱仪自带卤素灯光源,测量3 次,每次测完后取下样品,间隔约2 min 后放回样品再测,共3078 条光谱数据。相同ID 的光谱取平均值,共1026条平均光谱数据。

图1 光谱采集示意图Fig.1 Schematic diagram of spectral acquisition

表1 烟叶样本信息Tab.1 Information of tobacco leaf sample
1.2 仪器和光谱采集
实验用Carl Zeiss ARMOR 711 型近红外在线光谱仪(德国卡尔蔡司股份有限公司)。
光谱扫描条件:分辨率6 nm,光谱范围:910~2150 nm,扫描次数64 次,检测器InGaAs 阵列,分光系统PDA 阵列。样品距离:100~240 nm,测量斑点30 mm,工作温度范围5~65℃。
1.3 方法原理
1.3.1 微分光谱融合的数据增强
通过NIR 微分光谱与原NIR 光谱融合实现光谱数据增强。设第 条原始NIR 光谱为 ,分别对 求一阶微分和二阶微分得到一阶微分光谱 ̇ 和二阶微分光谱,经融合得到
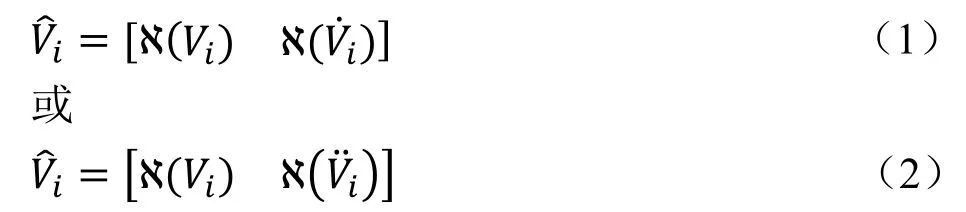
其中ℵ(·)表示归一化操作。
图2 给出了数据增强前后不同部位烟叶光谱数据曲线,其中上部、中部和下部烟叶光谱数据分别用蓝色、棕色和绿色所示,图2(a)为原始光谱数据,横坐标为波长信息,图2(b)和(c)表示原始光谱与微分光谱融合后的曲线,横坐标为波段序号。取各个部位的10 条光谱进行展示。由图2(a)可知,不同部位烟叶的近红外光谱形状几乎一样,只在近1200 nm 和1500 nm 附近有明显的吸收峰,在1100 nm、1300 nm 和1650 nm 附近有肩峰,而且无法根据幅值直接区分。而在经过一阶微分光谱融合和二阶微分光谱融合后,可以从图2(b)和图2(c)看出,融合后的光谱数据有了更多的波峰波谷信息。

图2 NIR 光谱曲线:(a)原始光谱; (b)一阶微分光谱融合结果;(c)二阶微分光谱融合结果Fig.2 NIR spectrum curve: (a) Original spectrum;(b) First-order differential spectrum fusion result;(c) Second-order differential spectrum fusion result
1.3.2 NIR-BYOL
BYOL 的核心思想是通过在线网络(Online 网络)和目标网络(Target 网络)分别提取两个增强样本的特征表示,使用均方误差衡量两个特征的接近程度,以均方误差最小为对比损失,通过优化使得BYOL 网络的编码器学习到较好的数据表达,用于下游任务。训练在线网络在不同的增强视图下去预测目标网络对相同样本的潜在表达,同时,使用在线网络的慢速移动平均线更新目标网络。通过在线网络和目标网络的交互学习,在线网络中的编码器可习得样本关键的潜在表达。
烟叶类别识别的NIR-BYOL 模型结构如图3 所示,其中x为输入的NIR 数据,v和v′分别表示对x光谱数据增强后的数据,fθ和fξ表示编码器,采用CNN实现,yθ和yξ′表示编码输出的编码向量,gθ和gξ表示投影器,采用多层感知机(Multilayer Perceptron, MLP)实现,zθ和zξ′表示投影器输出的投影向量,qθ表示预测器,采用MLP 实现,qθ(zθ)表示输出的预测向量。fθ、gθ和qθ构成online 网络,fξ和gξ构成target 网络。需要说明的是,NIR-BYOL 模型中的光谱数据增强可以用微分光谱融合的方法,也可以用其他数据增强方法。
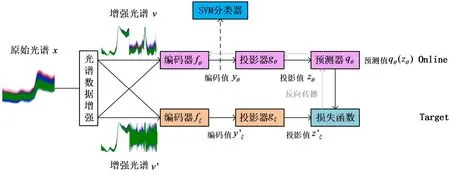
图3 NIR-BYOL 模型结构Fig.3 Structure of NIR-BYOL model
NIR-BYOL 模型的工作过程描述如下:v和v′分别输入online 和target 网络,两个网络分别输出各自的正则化数据q¯θ¯¯(zθ)和z¯ξ′,定义均方误差:
表示二者的相似程度。
进行分支数据交换,即输入target 网络的数据输入到online 网络,输入online 网络的数据输入到target网络,得到ℒθ,ξ。通过分支数据交换,使得target 网络和online 网络均能学习到同一个数据的两种增强形式的数据。定义损失函数:
通过优化损失函数使得编码器学习到较好的数据表达。
BYOL 模型最初应用于图像领域,其编码器结构适应的数据是图像格式如RGB 三通道格式。Encoder编码器结构参考文献[10]。为适应一维的光谱数据,需要对模型进行改进:修改输入层为两通道数据结构,例如(样本数,特征数),并且修改二维卷积为一维卷积。为此,设计了一个14 层的卷积神经网络用于烟叶近红外光谱的特征提取。包括1 个输入层,2 个反卷积层,3 个卷积层,4 个激活层,4 个BatchNorm 层。其编码器结构如图4 所示。
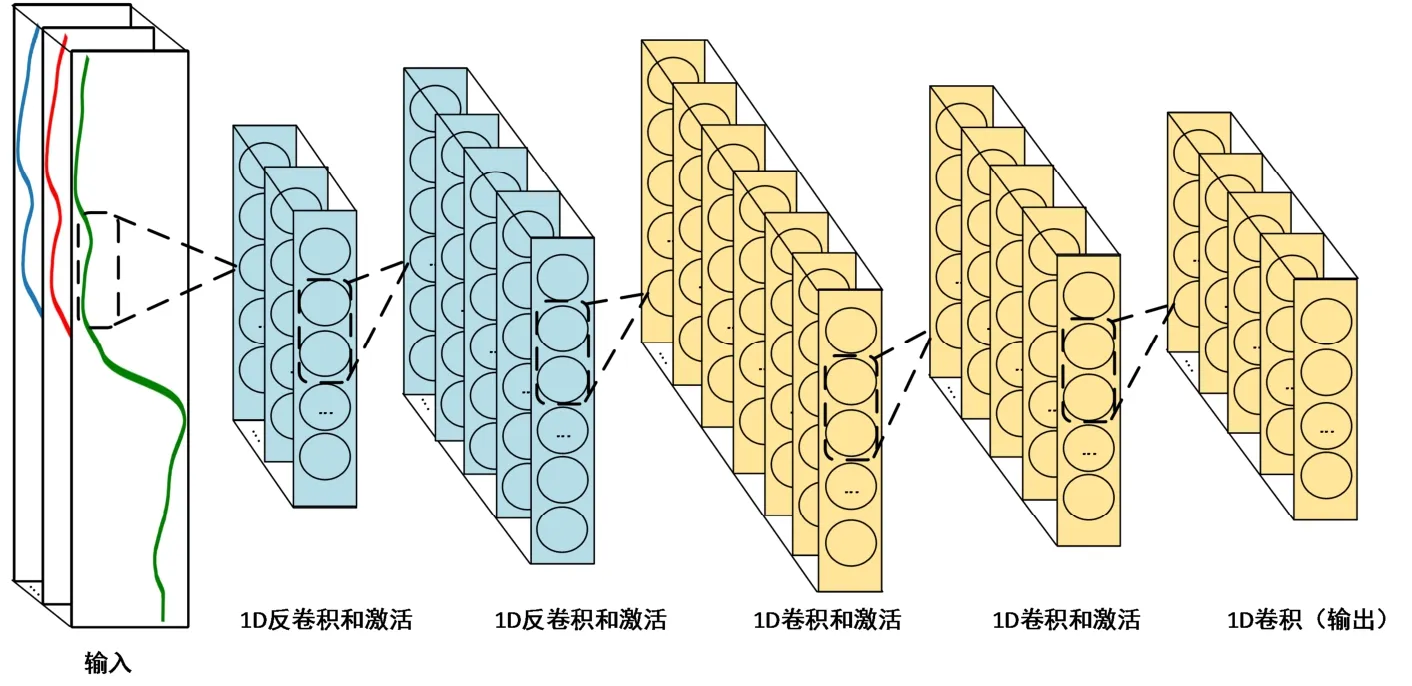
图4 编码器结构Fig.4 Encoder structure
编码器得到的编码值输入到分类器完成类别识别,具体过程为:用训练样本的编码值及部位标签对分类器进行训练,测试样本的编码值输入训练好的分类器,输出识别的类别信息。
不同的激活函数引入的非线性结构所有不同,NIR-BYOL 中实现编码器的激活函数可以用ReLU(Rectified Linear Unit)、Tanh、Sigmoid、ELU(Exponential Linear Units)等。
1.3.3 模型评价方法
通过准确率指标对所设计的模型进行性能评估。判别准确率 可表示为:
其中,e为判别正确的样本数, 为样品总数。
2 结果与讨论
每个样本有唯一标识的ID。所有实验中,根据ID号,将1026 个样本以8∶2 的比例划分为训练样本集和测试样本集。实验中采用样本的平均光谱。SVM 的最佳参数由网格搜索完成,网格搜索中设置参数为3折交叉验证。
2.1 数据增强方式对模型的影响
NIR-BYOL 模型中数据增强可以采用微分光谱融合的数据增强,即经公式(1)和(2)得到增强后的数据v和v′,也可以采用VAE、AAE 数据增强,即分别通过VAE 和AAE,将隐层编码得到的数据作为增强数据v和v′。
不同方式的数据增强在增加数据差异性方面有所不同。为了探索适应本数据集数据增强的最优方式,对数据增强方式进行组合实验,以最优实验结果对应的参数作为后续实验。一阶微分融合记作D1、二阶微分融合记作D2。因此,组合实验有VAE+AAE、VAE+D1、VAE+D2、AAE+D1、AAE+D2、D1+D2 共6组实验。实验采集的近红外光谱的波段从896 nm 到1690 nm,数据点有257 个。BYOL 模型默认参数为卷积核大小3*1,激活函数ELU。不同数据增强的实验结果如表2 所示。

表2 不同数据增强的NIR-BYOL 模型识别准确率Tab.2 Recognition accuracy of NIR-BYOL model with different data enhancement
比较VAE+D1、AAE+D1、D2+D1,可以看出在同样D1 数据增强下,对模型性能提升从高到底排序分别为VAE、D2、AAE;比较VAE+D2、AAE+D2、D1+D2,在D2 数据增强下,对模型性能提升从高到底排序分别为D1、VAE、AAE;比较D1+VAE、D2+VAE、AAE+VAE,在VAE 数据增强下,对模型性能提升从高到底排序分别为D1、D2、AAE;比较D1+AAE、D2+AAE、VAE+AAE,在AAE 数据增强下,对模型性能提升从高到底排序分别为D1、D2、VAE。同时,也可以看出在D2、VAE、AAE 数据增强下,D1 对模型性能提升均排名首位,说明D1 数据增强方法较适合本数据集。
从表2 还可看出,VAE+AAE 的数据增强方法所得到的上部、中部、下部准确率均较低,该组别和其他增强组别的明显区别在于是否有应用D1 或D2。D1或D2 是由原光谱微分得到,其体现了波段之间的关联性,其D1 光谱波形在一定程度上保留了原光谱的波形。而VAE 或AAE 是由隐层潜在特征作为光谱的数据增强方式,因此,有可能损失了其波形或波段间的联系,导致其识别效果不明显。除去VAE+AAE 方法,其他方法上部的取值范围在90%~94%,中部的取值范围在77%~83%,下部的取值范围在87%~90%。中部的准确率相对于上部和下部较低。因此,烟叶中部识别的精准性是模型性能好坏的关键。并且也考虑到VAE 模型的复杂程度,训练时间等因素,在高准确率的情况下,可综合考虑模型参数。因此,选择D1+D2 的数据增强方法作为后续模型的参数。
2.2 卷积核大小对模型的影响
当卷积核函数在整个红外光谱范围内移动时,卷积核函数会自动提取每个红外光谱窗口的局部特征。对于NIR 数据,重叠特征峰和独立特征峰的存在有可能导致模型结果对于卷积核大小及数目敏感,而且卷积核过小则难以提取窗口中的有效信息;卷积核过大则容易造成特征丢失。为确定最佳卷积核大小,分别讨论1~16 不同大小卷积核对模型的影响,BYOL 模型的激活函数默认为ELU。分类器使用SVM,SVM参数由网格搜索完成。模型的其他参数不变,仅改变卷积核大小,数据增强方法选择D1+D2。不同卷积核模型的准确率如表3 所示。

表3 不同卷积核大小NIR-BYOL 模型识别准确率Tab.3 Recognition accuracy of the NIR-BYOL model with different convolution kernel size
从表3 的数据可以看出,随着卷积核大小的增加,模型的平均准确率逐渐增大。但是增加到一定程度,准确率趋于平稳。在卷积核为3 时,平均准确率逐渐步入平稳阶段。而且从中可以看出,中部准确率波动幅度比上部和下部大,其可能是因为烟叶中部的判断标准比较宽泛,导致其被判别为上部或下部的概率增加。考虑到上部和下部的准确率比较平稳,因此中部准确率的高低很大程度上影响了模型的准确率。此外,卷积核越大,程序运行的时间越多。综合考虑模型性能和程序运行时间,选取卷积核为11 作为后续实验的模型参数。
2.3 激活函数对模型的影响
在神经网络中,若不使用激活函数或者仅使用线性激活函数,神经网络的每层只是做线性变换,多层输入叠加后也还是线性变换。为学习到数据中非线性特征,加入激活函数可使得网络引入非线性因素,神经网络就可学习到曲线进行超平面分割,提升神经网络表示能力。而常用的激活函数有ReLU(Rectified Linear Unit)、Tanh、Sigmoid、ELU(Exponential Linear Units)。不同的激活函数引入的非线性结构均不同。为检验激活函数对模型的影响,分别比较4 种不同激活函数网络模型预测效果。BYOL 模型参数为卷积核大小11*1。具体分析结果如表4 所示。
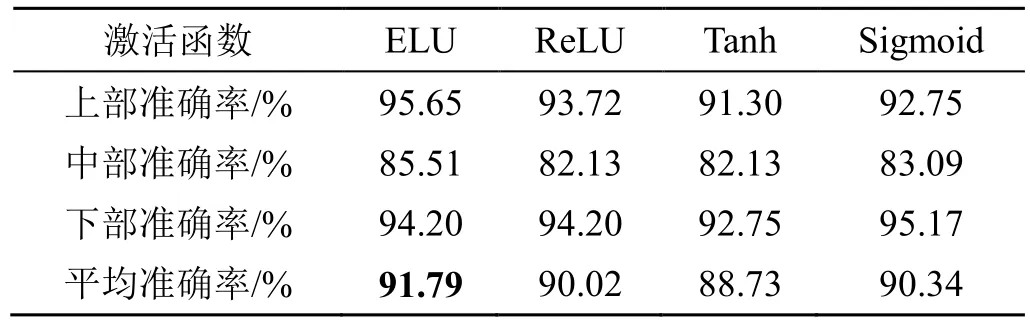
表4 不同激活函数NIR-BYOL 模型烟叶部位识别准确率Tab.4 Recognition accuracy of NIR-BYOL model using different activation functions
由表4 可知,就准确率而言,ELU 的准确率最高,达到91.79%,Sigmoid 次之,达到90.34%,ReLU 和Tanh 达到90.02%和88.73%。从中可以看出,各激活函数之间的准确率差距在3%以内,差距不大。因此NIR-BYOL 模型可能对激活函数的选择并不敏感。为此,选择平均准确率最高的ELU 作为NIR-BYOL 模型的激活函数。
2.4 模型对比
为验证该模型的性能,与常规的分类方法进行比较。采用相同的训练集和测试集,对采用高斯核的SVM、PLS-DA、PCA+SVM 和NIR-BYOL 模型分别进行实验。SVM 的参数是由网格搜索得到。PLS-DA的参数是主成分个数为8。PCA 的参数是主成分个数12。BYOL 模型参数为卷积核大小11*1,激活函数ELU。不同方法所建立的模型的分析结果如表5 所示。
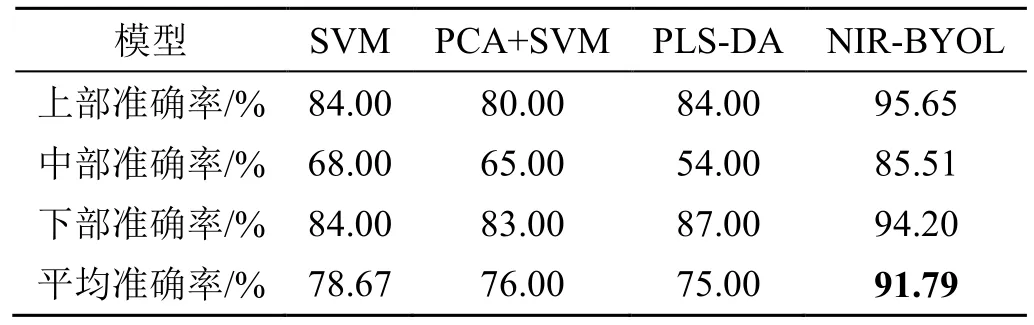
表5 不同方法的结果比较Tab.5 Accuracy of different modeling methods
分析结果表明,NIR-BYOL 模型得到的准确率最高,PLS-DA、SVM、PCA+SVM 模型得到准确率相近。其主要原因是SVM 和PCA 因其构造,能进行浅层的特征学习,PCA 进行特征提取时,仅考虑了数据的方差,忽略了数据间的联系;PLS-DA 是在偏最小二乘(PLS, Partial least squares)分析的基础上应用分类,但是PLS 不能很好地处理非线性问题,因此识别准确率受到数据高维的影响。而NIR-BYOL 模型编码器通过构建多层网络获得了深度结构,从而能够进行深度学习,提取出更具表达能力的特征。
2.5 不同部位烟叶判别结果分析
以最佳模型参数对应的模型进行实验预测,对烟叶部位判别结果如表6 所示。
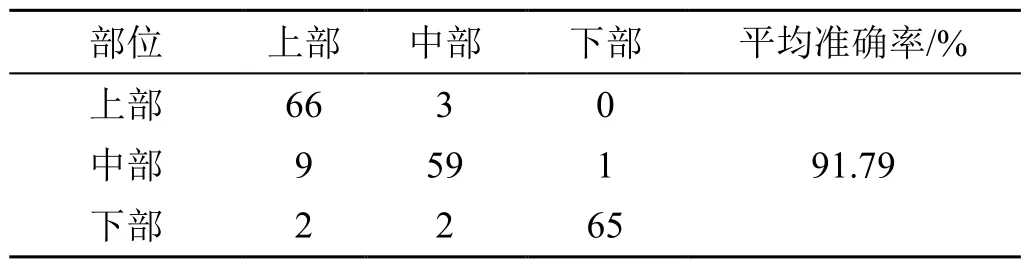
表6 NIR-BYOL 模型对不同部位烟叶的详细识别结果Tab.6 Detailed recognition accuracy of NIR-BYOL model for different tobacco parts
从表6 可以看出,NIR-BYOL 模型在测试集上的平均准确率达到91.79%,对3 个部位中的每一个部位都有较高的准确率,上部被预判为下部的个数为0,下部被预测为上部的个数为少量,中部有被预判为上部和下部的例子。也符合烟叶中部界定宽泛的现实。基于此,该模型可以较全面地描述烟叶部位特征,有较强的学习和判别能力。
最佳模型NIR-BYOL 对应的编码器参数如表7 所示。包括1 个输入层,2 个反卷积层,3 个卷积层,4个激活层,4 个BatchNorm 层。

表7 编码器参数Tab.7 Parameters of encoder
3 结论
本文就基于BYOL 的近红外光谱分类建模方法进行了研究,利用光谱微分技术和数据融合实现数据增强,建立了NIR-BYOL 模型用于烟叶部位识别,实验结果表明:(1)NIR-BYOL 模型可准确、可靠地鉴别烟叶部位;通过训练BYOL 网络从而获得高质量的编码器,该编码器可对烟叶光谱数据进行高质量的特征提取;(2)通过数据增强,尽可能多地添加烟叶光谱的特征从而提高关键性特征被提取的可能性,实验结果表明可有效提高模型的性能。
NIR-BYOL 模型结构其实是一个通用的基于NIR的类别识别模型,即当输入的原始光谱为烟叶NIR 光谱,分类器训练样本标签为烟叶产地类别信息时,分类器输出烟叶的产地信息;当输入的原始光谱为其他产品的NIR 光谱,分类器训练样本标签为相应产品的某种类别信息,分类器输出相应产品的对应类别。
后续研究,将进一步研究如何提升样本不平衡和小样本情况下模型的性能,实验验证NIR-BYOL 模型用于烟叶产地识别的性能和各个等级(B2F、C1F、C2F、C3F、C4F、C2L、X2F 等)样本的识别性能,实验验证烟叶部位识别结果用于烟叶收购时烟叶品质合格与否判定的效果,以及模型在其他类型产品品质分析中的应用。
