改进的蒙特卡洛方法用于烟丝近红外光谱定量分析中奇异样本的识别
2023-12-15胡芸刘剑白兴阮艺斌张辞海姬厚伟李博岩
胡芸,刘剑,白兴,阮艺斌,张辞海,姬厚伟,李博岩
1 贵州中烟工业有限责任公司技术中心,贵阳市小河经济技术开发区开发大道96 号 550009;
2 贵州医科大学公共卫生与健康学院,贵阳市花溪大学城 550025
在烟草及烟草制品的总植物碱、总糖、总氮等化学组分的近红外光谱定量分析中,校正模型往往是在大量样本基础上建立的。模型质量在很大程度上依赖于建模样本数据的准确性。异常样本的存在会严重干扰定量模型质量,影响模型预测的准确性[1-4]。因此,奇异样本的识别是建立可靠准确的定量分析模型的前提。
奇异样本一般是指那些落在主体样本之外的样本,其观测数据常偏离主体样本呈现的模式。造成奇异样本的因素可能是实验操作误差、仪器误差、测量误差以及样本性质变化等。奇异样本的诊断与识别一直都是多元校正研究中的热点,涉及的方法主要有经典识别方法(如残差法、马氏距离法[5]、帽子矩阵法等)和稳健回归方法(如最小一乘估计、极大似然估计等)。诊断方法着重于先检测奇异样本,剔除后再用经典方法建模。稳健回归方法是在解析过程中估计数据分布的主体,然后构建稳健模型,从而降低数据中奇异样本对回归估计产生的不利影响。
刘智超等[6]基于样本在蒙特卡洛交叉验证中的统计规律,建立一定数量的模型,然后依据预测误差平方和预测残差平方和(PRESS)排序并统计每个样本在不同模型中出现的频次对异常样本进行识别。Cao等[7]通过研究样本在模型群中预测误差的分布,发现预测误差的统计特征可用于识别正常样本和奇异样本,由此提出蒙特卡洛方法奇异样本检测方法(MonteCarlo outlier detection, MCOD)。与传统方法相比,MCOD 在一定程度上降低了由掩蔽效应带来的模型风险,具有较高的奇异样本识别能力。在此基础上,Zhang 等[8-9]提出使用正常样本建模,对可疑异常样本进行二次验证,大大降低了可疑异常样本的误判和掩蔽效应带来的建模风险。
本文首次把改进的蒙特卡洛奇异样本(improved MonteCarlo outlier detection, IMCOD)识别方法应用于卷烟成品烟丝的化学成分(总植物碱、总糖、还原糖、总氮、钾和氯)的定量建模中,提高校正模型的稳健性与预测准确性,具有较大的应用意义。
1 材料与方法
1.1 仪器与材料
Antaris 傅立叶近红外分析仪(美国Thermo 公司)、Futura 型8 通道连续流动化学分析仪(法国Alliance公司)、FED260 型烘箱(德国Binder 公司)、410 型单通道火焰光度计、VELP 消化炉、ML204 型电子分析天平(梅特勒-托利多仪器上海有限公司)、HY-6 型双层调速多用振荡器(江苏金坛荣华仪器制造有限公司)。
192 个卷烟样品由贵州中烟工业有限责任公司提供。
1.2 实验方法
1.2.1 样品处理
每个卷烟样品取2 盒,然后剥开烟支取烟丝混合均匀后装入一次性密封袋低温(0℃~4℃)保存,待测。
1.2.2 化学值测定方法
按照烟草行业标准,测定了烟叶样品中总糖、还原糖、烟碱、总氮、氯和钾6 种常规化学成分的含量。相关标准如下:《YC/T 31—1996 烟草及烟草制品试样的制备和水分测定烘箱法》;《YC/T 468—2013 烟草及烟草制品总植物碱的测定连续流动(硫氰酸钾)法》;《YC/T 159—2002 烟草及烟草制品水溶性糖的测定连续流动法》;《YC/T 161—2002 烟草及烟草制品总氮的测定连续流动法》;《YC/T 217—2007 烟草及烟草制品钾的测定连续流动法》;《YC/T 162—2002 烟草及烟草制品氯的测定连续流动法》。
1.2.3 光谱采集与数据处理
实验室测试环境温度控制在(22±2)℃,相对湿度控制在(40±10)%。近红外仪器开机预热不低于1 h,用ValPro 程序校检合格后使用。低温保存过的烟丝样品应在实验室测试环境下平衡不少于4 h。将装有烟丝(压平后,样品厚度≥20 mm)的样品杯放置于旋转台,采用积分球漫反射的方式测量光谱,扫描范围为4000~10000 cm-1,分辨率为8 cm-1,扫描次数为64 次。每个样品重复扫描3 次,每次采集样品光谱前均须测量背景光谱。所使用的软件为仪器自带的RESULT-Integration 工作流(Workflow)设计软件、RESULT-Operation 操作软件和TQ Analyst 光谱分析软件。
1.3 算法
1.3.1 蒙特卡洛奇异样本检测方法
一般来说,稳健诊断方法多是基于评价模型残差,即拟合残差之上。但由于奇异点的存在,拟合残差对奇异点是不灵敏的,只有预测残差才对奇异点很敏感,它是拟合误差与Cook 距离之和。这就是蒙特卡洛采样方法检测奇异点的原理[7]。
图1 为蒙特卡洛采样方法的示意图。该方法对m个样本数据进行N 次采样,N 值可以设定为样本数的平方或者一个较大的数值。每次采样时,按照一个设定的比例(如70%~80%)随机选择样本,如图中白色标记的数据样本点,构建校正模型,再预测剩余的样本(黑色标记)。N 次采样后,可获得参数估计分布的蒙特卡洛近似分布,由此评估和分析样本预测误差。
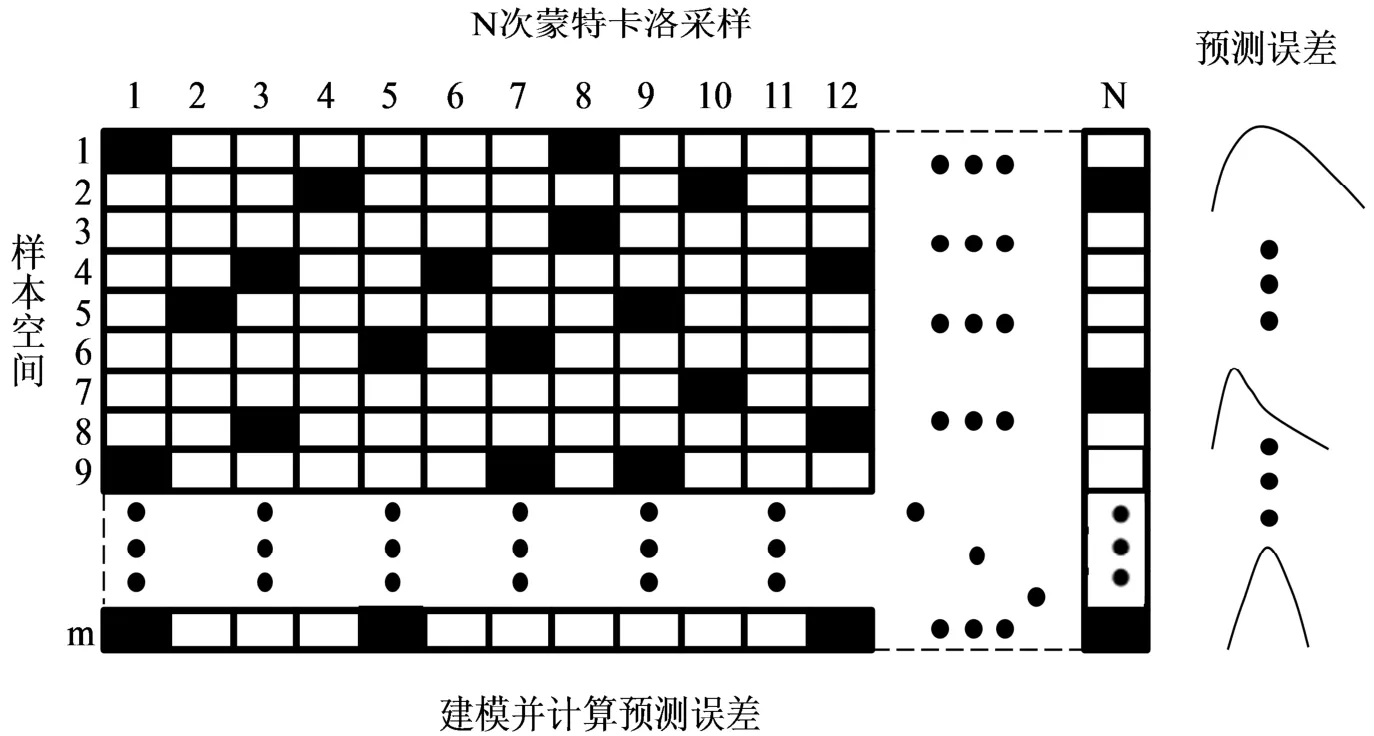
图1 蒙特卡洛采样示意图Fig.1 Schematic diagram of Monte Carlo Sampling
基于不同性质的样本点具有不同的分布,可以计算每个样本点预测误差分布的均值的绝对值(mean value)和标准偏差(standard deviation)。以预测误差的均值的绝对值为X 轴,预测误差的标准偏差为Y 轴作图,得到一个四区域散点图(图2)。其中,左下角区域涵盖了大部分的数据样本点,对应的均值和偏差值都比较小,表示正常样本;左上角区域是X 方向的奇异样本,具有较大的偏差和较小的均值;右下角区域是Y 方向的奇异样本或者模型奇异样本,对应小的偏差和大的均值;右上角区域是特殊的奇异样本或者不正常样本,可能是某些误差造成的。该区域散点图提供了奇异样本可视化诊断信息,可根据实际情况选择多数主体样本的预测误差和标准偏差均值的2~2.5倍作为区域划分的量化依据[7]。
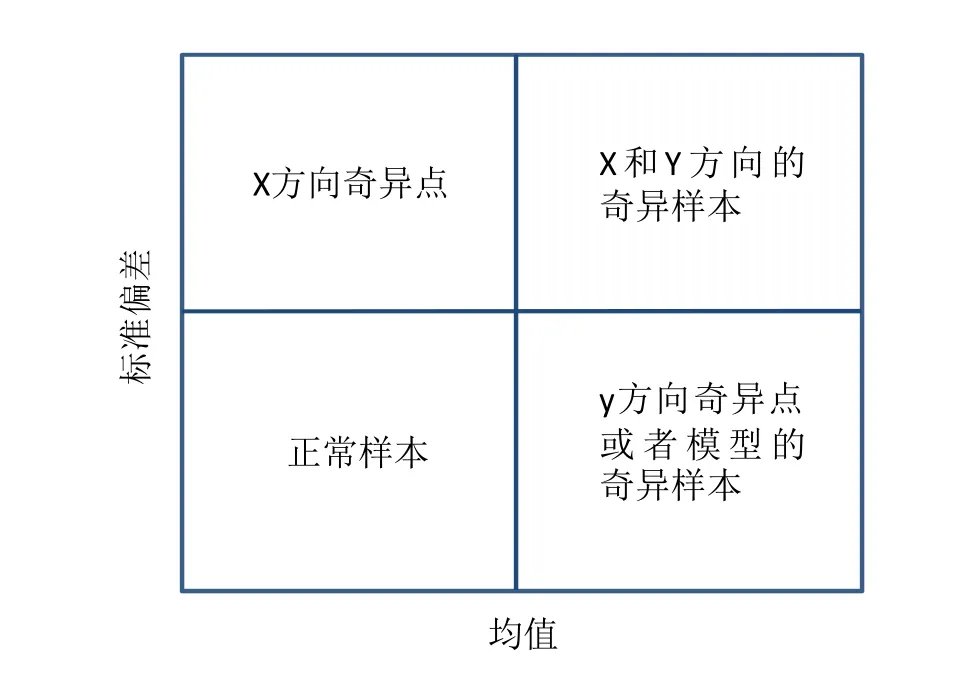
图2 基于样本预测误差统计的不同类型样本的判断Fig.2 Determinant of different types of samples based on statistics of prediction errors
1.3.2 改进的蒙特卡洛奇异样本检测方法
在利用蒙特卡洛奇异样本检测方法时,掩蔽效应的存在可能使得正常样本与异常样本的区域分界线不是很清晰。所谓的掩蔽效应是指多个奇异样本存在于数据时,一些奇异样本会使得其它奇异样本不能被检测方法诊断出来。因此,提出了改进的蒙特卡洛奇异样本检测方法。IMCOD 的基本步骤如图3 所示:(1)循环N 次MCOD 采样[7],计算全部样本的预测误差分布的均值与标准偏差;(2)将具有较小预测误差均值和标准偏差的样本视为正常样本,剩下的样本视为可疑样本;(3)按一定比例把正常样本数据集随机划分为训练集和验证集;(4)用训练集样本构建校正模型,然后预测验证集样本和可疑样本,计算预测误差并保存;(5)重复步骤(3)和(4)N 次后,得到正常样本和可疑样本的预测误差分布的均值和标准差,判断异常样本。这些样本预测误差是在正常样本建模的基础上产生的,故能有效降低掩蔽效应的影响,更加清晰地判断正常和异常样本的边界。值得注意的是与MCOD 方法相比,IMCOD 方法采用了已筛选出的正常样本构建模型来预测可疑样本,可能增加了模型的过拟合风险。针对该问题,使用蒙特卡洛交互验证方法[9],合理估计训练集正常样本校正模型的维度(即主成分数),以有效降低去除可疑样本后数据集中样本减少而带来的过拟合风险。一般来说,模型的主成分数越大,过拟合的可能性越大,模型越不稳健,预测能力越弱。样本数据的最后的回归模型应该是由去除IMCOD 方法检测的异常样本后,合并非异常样本与正常样本所构建的。
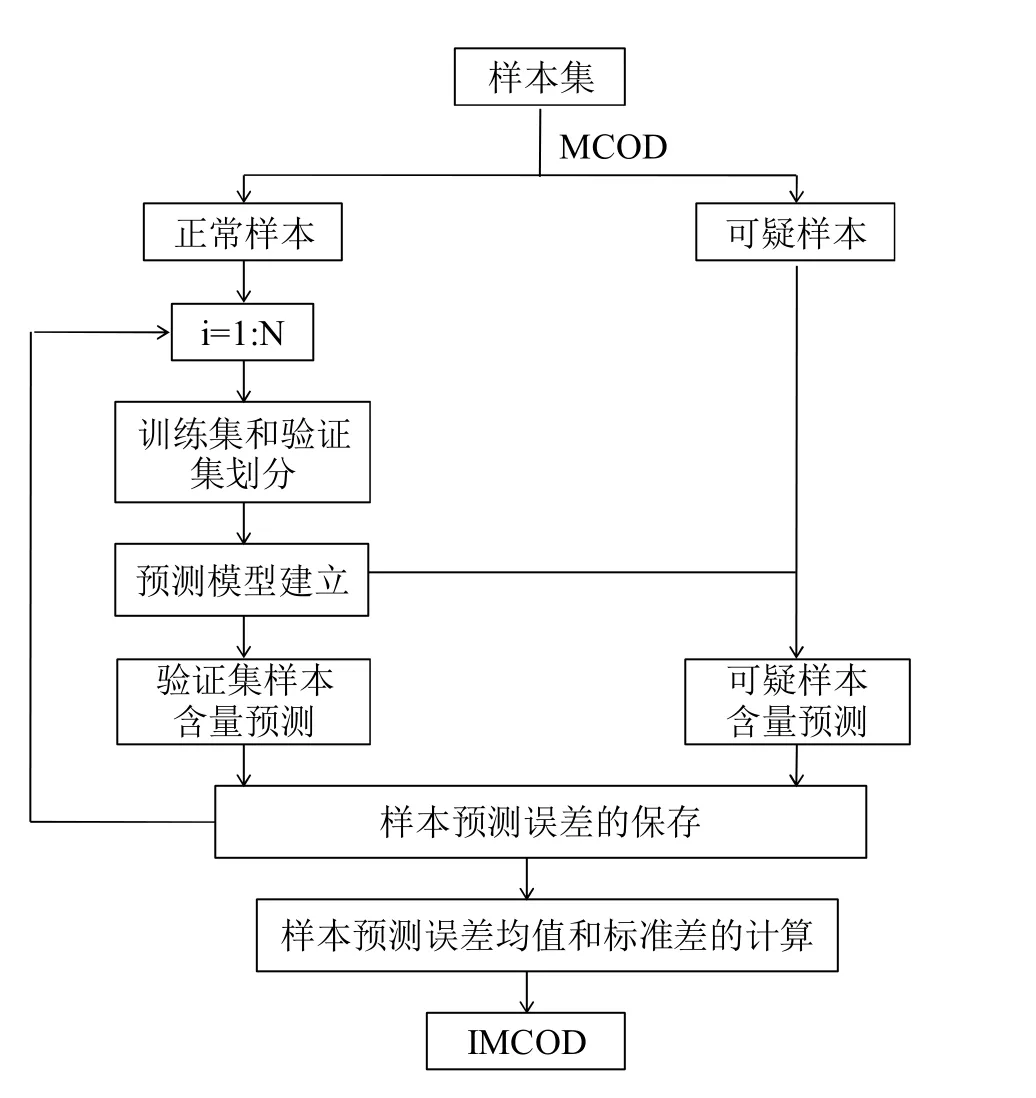
图3 改进的蒙特卡洛奇异样本检测方法的流程图Fig.3 Flowchart of IMCOD method
2 结果与讨论
2.1 卷烟样品的近红外光谱与化学参考值
近红外光谱的奇异样本主要涉及光谱异常和化学异常样本。光谱异常样本又称为自变量X方向的奇异样本,在高维变量空间中远离样本分布主体。一般来说,成品卷烟烟丝的近红外光谱比较复杂(图4),样本的颗粒大小及样本背景成分的差异均可以引起光谱差异,可能造成一些样本的光谱不属于样本的总体分布,成为奇异样本。另外,光谱的相似性高,若不借助化学计量学方法,很难直接快速识别光谱异常样本。近红外光谱定量分析模型建立的另一个关键要素是借助标准分析方法获得样本的化学参考值。这些数值的测量可能是有误的,从而形成化学异常样本,也称为响应变量Y方向的奇异样本。这类奇异样本经常远离化学指标Y的数据主体,在建模过程中经常会引起较大的预测误差。因此,化学异常样本的识别是建立一个稳定模型的关键因素。表1 列出了成品卷烟中6 种化学成分的含量信息。若仅从数据的角度看,很难得知样品中总植物碱、总糖、还原糖、氯、总氮和钾化学参考值是否正常。再者就是结合了以上两种性质的奇异点,即同时在X方向与Y方向的奇异点。在建立校正模型之前剔除奇异样本,能够建立稳健的校正模型,从而提高模型对样本的预测准确性。
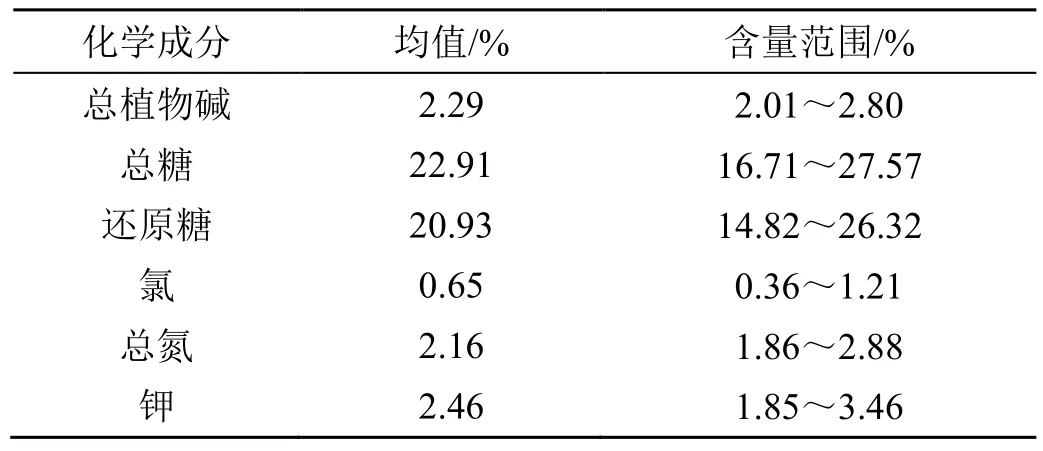
表1 卷烟样品中6 种化学成分的含量信息Tab.1 The contents of six components in cigarette cut samples

图4 卷烟烟丝样品的原始近红外光谱Fig.4 Original NIR spectra of cigarette cut samples
2.2 卷烟烟丝奇异样本识别
采用化学计量学多元散射校正(MSC)和SavGol一阶导数方法对卷烟烟丝样本的近红外光谱原始数据进行预处理,使用4200~7600 cm–1区域内的光谱数据构建定量分析模型(图4)。
对于烟丝中的6 种化学成分含量,依照上MCOD和IMCOD 方法检测步骤,分别选取80%的样本作为训练集,建立偏最小二乘(PLS)定量模型,预测剩余的样本的化学成分含量。随机采样2000 次,得到每个样本的预测误差,计算其对应的平均值的绝对值和标准偏差,如图5、6 所示。大部分样本都处于四分区图的左下角(零值附近),也就是说这些正常样本的预测误差的均值和标准偏差都很小。根据烟丝样本中化学成分的不同,选择预测误差的2.5~3.5 倍和标准偏差均值的1.5~2.0 倍作为判别正常样本与奇异样本的量化指标。
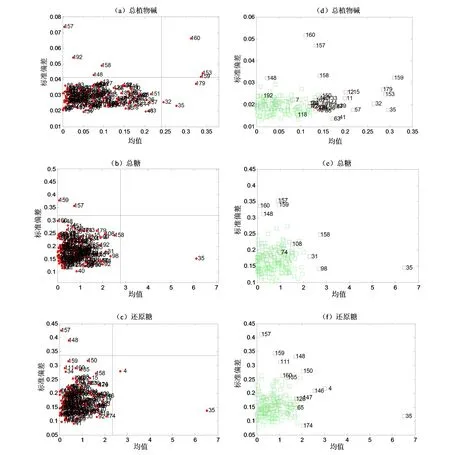
图5 MCOD(a、b、c)和IMCOD(d、e、f)方法诊断卷烟样品中总植物碱、总糖和还原糖的异常样本Fig.5 Outlier detection for total alkaloids, total sugars and reducing sugars in cigarette samples using by MCOD and IMCOD
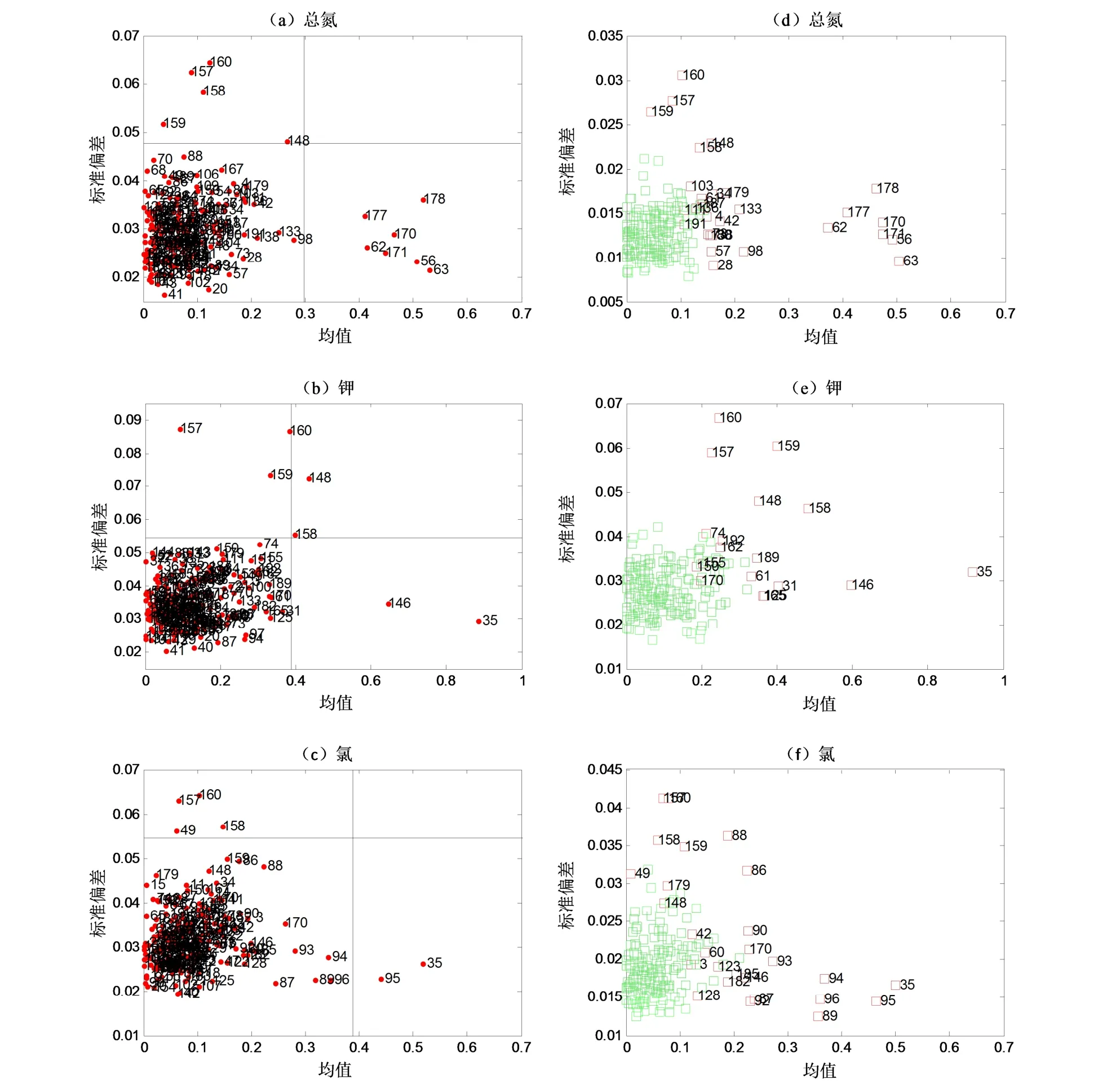
图6 MCOD(a、b、c)和IMCOD(d、e、f)方法诊断卷烟样品中总氮、钾和氯的异常样本Fig.6 Outlier detection for total nitrogen, potassium and chlorine in cigarette samples using by MCOD and IMCOD
图5a 中MCOD 方法检测总植物碱的结果表明8个样本(#148、#153、#157、#158、#159、#160、#179、#192)与左下方区域的正常样本差异明显,诊断为异常样本。样本#32 和#35 接近正常样本,不易识别。在此基础上,选取预测误差的均值小于0.15%和平均偏差小于0.04%的样本视为正常样本集,运行IMCOD方法得到图5d 的预测结果。可以看出,正常样本与异常样本的界限更加清晰,样本#32 与#35 和正常样本的区别更加显著。原先被视为异常样本的#192 样本的预测误差变小,分布在正常样本区域范围之内。样本#11、#12、#15 和#57 被识别为异常样本。
图5b 为总糖的MCOD 方法诊断异常样本结果:样本#157 和#159 的预测误差的标准偏差较大,可能为光谱异常点。样本#35 的预测误差的均值较大,判断为化学异常点。用IMCOD 方法则识别出8 个异常样本(图5e),#148 和#160 也为光谱方向的奇异样本。样本#31、#98 和#158 也是奇异样本。类似地,用MCOD和IMCOD 方法分别识别还原糖、总氮、钾和氯含量样品集中的奇异样本,除还原糖外,其他5 种化学成分相关的异常样本中都有样本#157、#158、#159 和#160。近红外光谱数据的主成分分析结果表明这些样本的光谱残差远大于主体样本的光谱残差(图7),验证这四个样本的光谱异常。实际上,奇异样本的识别并不容易。若实验条件允许,应通过重复筛选出的光谱异常或化学成分异常样本的光谱扫描和化学成分分析实验,来确证识别的正确性。
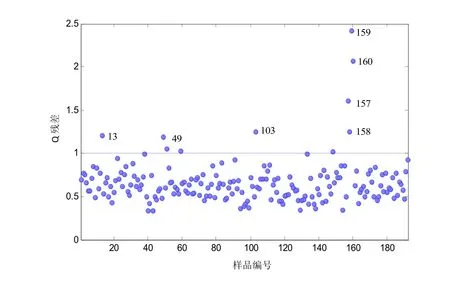
图7 192 个卷烟烟丝的主成分分析残差图Fig.7 Plot of PCA residuals of 192 cigarette cut samples
使用原始的全部样品建立PLS 定量模型,并与用MCOD 和IMCOD 方法剔除异常样本后建立的模型进行比较(表2)。MCOD 和IMCOD 方法剔除异常样本后,化学成分的定量分析模型的相关系数和校正均方根误差都得到明显改善和提高。例如,总糖含量模型的相关系数从0.936 提高到0.966,校正均方根误差从0.913%降到0.648%。IMCOD 方法检测奇异样本是基于正常样本建立预测模型基础上的,降低了多个奇异点的掩蔽效应,更加准确地识别异常样本。
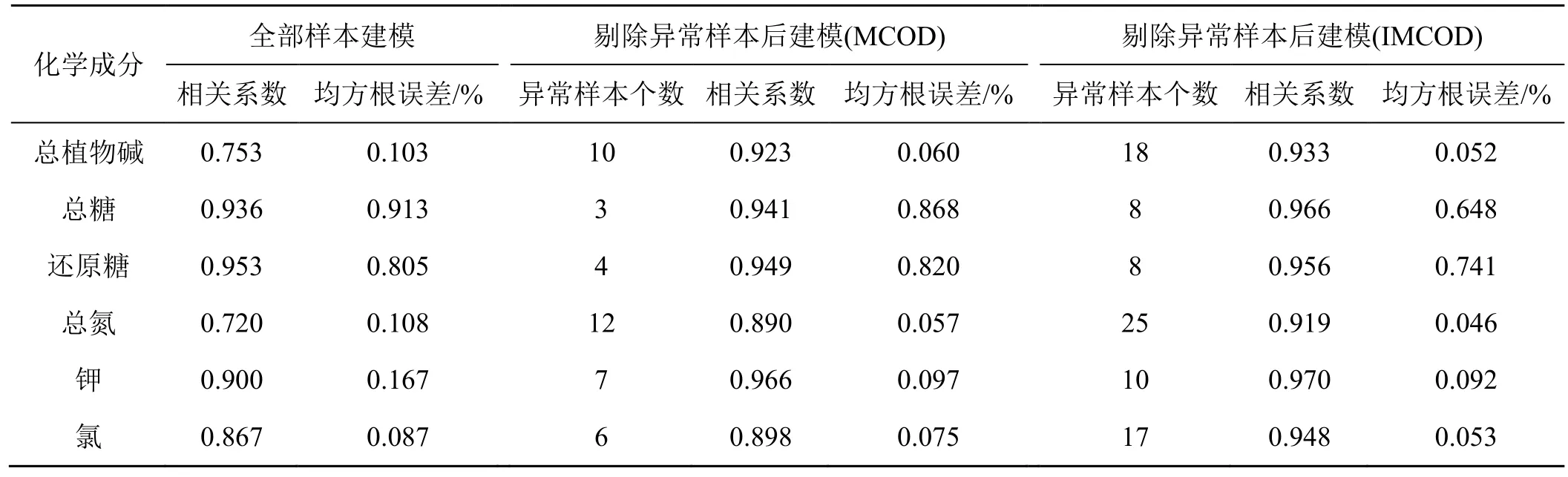
表2 全部样本建模和剔除异常样本建模的结果比较Tab.2 Comparison of modeling results between sample with outliers and sample without outliers
2.3 卷烟样品的近红外光谱定量模型
采用MCOD 和IMCOD 方法分别剔除异常样本后,优化和建立了成品卷烟烟丝的6 种化学成分的定量分析模型(表3)。由表可知,用IMCOD 方法剔除异常样本后,所建模型的相关系数得到提高,且校正集均方根误差(RMSEC)和预测集均方根误差(RMSEP)变小。IMCOD 方法将总氮含量的校正模型的相关系数从0.874 提高到0.919,预测均方根误差降低了14.8%,模型的预测能力得到很大改善。计算模型稳健性评价参数SEP/SEC 的值均小于1.2[10],表明模型对预测样本具有较好的稳定性。定量分析模型的相关系数(R)均大于0.91。这是因为样品粒径及其分布状态会影响近红外光谱的预测效果。固体样品的粒径大小改变了近红外光在样品粒子中的光程,影响近红外光对样品的反射性和穿透性,体现在样品对近红外光的吸收和散射强度。因此,粒径较大或粒径不均匀样品的预测准确性和精密性会差一些。在实际应用中,若使用烟丝模型预测未知样本的含量,虽然准确度有所降低,但考虑到烟丝的模型不需要样品制打磨步骤,可以大大节约时间和成本。
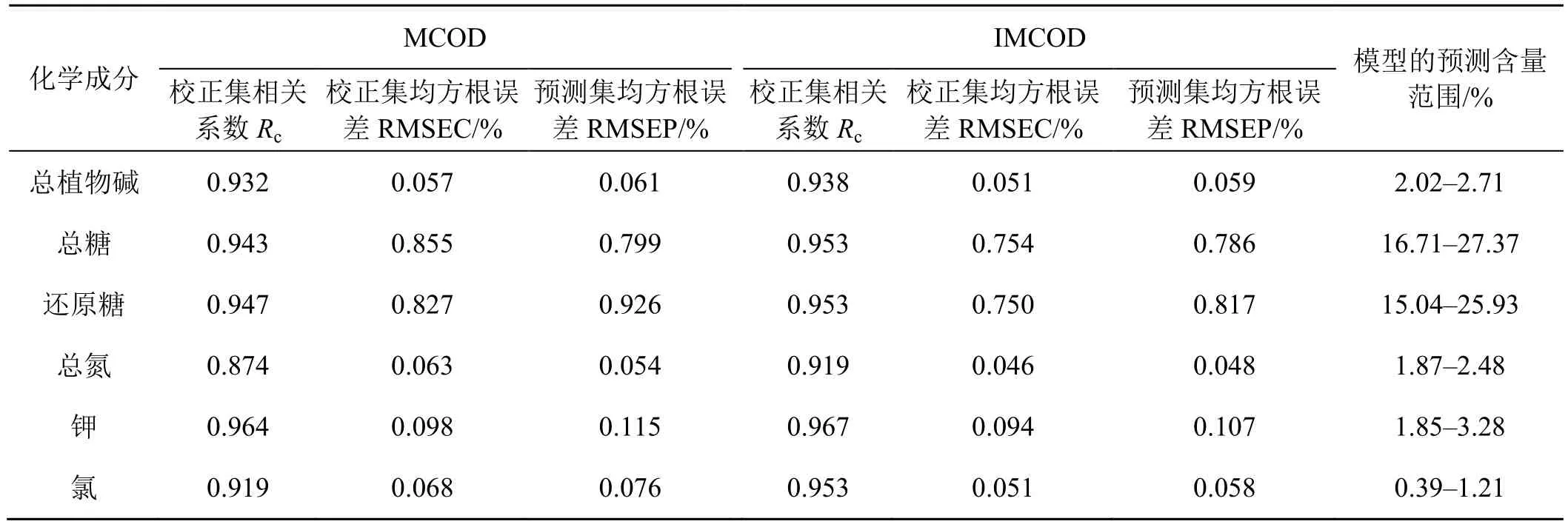
表3 卷烟烟丝样品中6 种化学成分的模型结果Tab.3 The model results of six components in cigarette cut samples
3 结论
改进的蒙特卡洛奇异样本检测方法主要是在正常样本的基础上构建N 个定量模型来获得全部样本预测误差的分布,通过样本分布间的差异性判断正常样本和奇异样本。方法的应用不仅能够得到正常样本与异常样本的区域散点图,还提供了奇异样本可视化的诊断信息,提高了奇异样本识别的准确性,有效降低了掩蔽效应带来的建模风险。卷烟成品烟丝中6 种化学成分的定量分析模型的建立和应用也证实了该方法的合理性和准确性。对于边界附近的异常样本,可以通过优化正常样本的预测误差平均值和标准偏差,增加运行次数等进一步确定。这也说明了在保证光谱数据和基础数据准确的前提下,才能建立准确的可靠的近红外分析模型。
