基于多头自注意力模型的本体匹配方法
2023-12-15唐雪明
吴 楠,唐雪明
(1.南宁师范大学 计算机与信息工程学院,广西 南宁 530199;2.南宁师范大学 物理与电子学院,广西 南宁 530199)
0 引言
本体(Ontology)通常由该领域内的专家、学者定义,由于构建准则的多样性及研究者们对于知识理解的程度不同,导致本体异构(Ontology Heterogeneity)现象[1]。为建立具有语义相关概念之间的对应关系,解决不同本体间的知识共享问题,提出了本体匹配(Ontology Matching,OM)方法,本体匹配也称为本体对齐(Ontology Alignment,OA)[2]。
研究表明,两个概念间单一的相似度方法无法准确判断两个概念是否匹配,综合衡量多种相似性策略可以有效提升匹配效率[3]。近年来,研究者们围绕如何更高效地整合多种相似度计算结果,提出基于机器学习的本体匹配方法[4]。该方法的基本思想是将匹配问题转化为分类问题,采用分类模型判断两个概念是否匹配。例如,Bulygin等人[5]提出一种将基于字符、语言和结构的相似性结果与机器学习技术相结合的方法。该方法未考虑不同相似性结果之间的相关性,导致匹配结果不理想。因此,吴子仪等人[6]提出一种基于自注意力模型融合多维相似度的方法。实验结果表明,与传统的机器学习方法相比,该方法能够自主学习不同相似度方法之间的权重,从而高效地融合匹配结果,得到了更佳的匹配效果。此外,Rudwan等人[7]提出一种将模糊字符匹配算法和双向编码器模型与三个回归分类器相结合的方法。首先,考虑了本体的词汇和语义特征,以解决模糊字符匹配算法的局限性。然后,使用机器学习方法改善匹配的结果。该方法忽略了概念间的结构特征,导致匹配结果的准确率不高。
综上所述,本文提出一种基于多头自注意力模型的本体匹配方法(Ontology Matching Method Based on the Multi-Head Self-Attention Model,OM-MHSA)。主要有三个贡献:① 同时考虑类和属性的多种相似度。② 采用OWL2Vec*方法[8]获取本体的语义嵌入表示,高效提取本体中包含的图结构、词汇信息以及逻辑构造函数等语义信息,以挖掘本体间隐藏的语义关系。③ 使用Multi-Head Self-Attention Model融合三种不同相似性度量结果并判断实体是否匹配。
1 相关工作
1.1 相关定义
因本体的结构较为复杂,通常采用Web本体语言(Web Ontology Language,OWL)进行描述。当前,对本体没有标准的定义,将采用最常见的形式化定义。
定义1本体[9]按照分类法由5个基本元素构成。通常也将本体写为如下三元组形式:
O=
(1)
式中:C代表类集合,P代表属性集合,H代表类的层次关系。类和属性统称为概念,而概念的实例也称为实体[10]。因此,本文将同时考虑本体中类和属性的相似度。
定义2本体匹配[11]方法的思想是找到具有相似或相同含义的概念之间的语义关联,其中每一对关联概念被称为一个匹配对(或映射对)。
为方便理解,本文的匹配任务仅考虑两个概念等价的情况。对于两个待匹配的本体O1和O2,可写成如下形式:
R=
(2)
式中:R代表两个本体的匹配结果,e1∈O1代表本体O1中的实体,e2∈O2代表本体O2中的实体,f(e1,e2)代表实体e1与e2关系的置信度,且f的取值区间为[0,1]。f值越大,说明实体e1与e2表示相同事物的概率越高。
1.2 相似度度量方法
本体匹配方法一般是研究不同本体间实体的相似性,从而实现本体间的互操性。为全面、精确地衡量本体中类和属性的相似性,可以从字符级、语义级和结构级等不同角度出发。
1.2.1 基于字符的相似性计算方法
该方法的基本思想是:对于待匹配的两个实体,将字符的共现和重复程度作为匹配对的相似值[12]。常规的计算方法有N-gram、编辑距离(Edit Distance)、最长公共子串(Longest Common Sub-string)等。基于N-gram计算实体的相似度公式如下:
(3)
式中:N代表滑动窗口的大小,通常取值为1、2、3、4;m代表实体e1与e2同时出现N个相同排序的字符个数;max(length(e1),length(e2))代表取实体e1与e2长度的最大值。
利用式(3)以N=3为例,计算e1=“significant”和e2=“signature”的相似度值如下:e1与e2具有两个相同排序的字符“sig”“ign”,故相似度为sim(e1,e2)=2×(3/11)=0.545。“significant”译为显著的,“signature”译为签名,二者在语义上并无关联。因此,不能只考虑该方法,需结合其他相似度计算方法。
1.2.2 基于语义的相似性计算方法
顾名思义,该方法可挖掘实体间语义层面的相似性[13]。常用的方法有同义词典WordNet[14]、词嵌入Word2vec[15]。与典型的知识图相比,OWL不仅包含图结构、词汇信息,还包括逻辑构造函数(Logical Constructors)。而OWL2Vec*方法可以较好地对这些信息进行语义编码,所以本文将选择OWL2Vec*方法获取匹配本体的语义表示,再使用式(4)计算相似度:
(4)
式中:v1代表实体e1的语义嵌入表示,v2代表实体e2的语义嵌入表示,sim(v1,v2)的取值范围为[-1,1],-1表示实体e1与e2完全不相似,1表示完全相似。
1.2.3 基于结构的相似性计算方法
本体除文本信息外,还可利用subclassof、is-a和part-of等语义关系获取本体的结构信息。匹配的类或属性往往具有相似的结构[16]。因此,本文将考虑实体的父类及类路径之间的相似度。例如,使用Protégé软件查看ekaw本体概念层次的部分结果如图1所示,可以看出,对于类“Conference_Trip”,其父类为“Social_Event”,类的完整路径为“Thing/Event/Social_Event/Conference_Trip”。
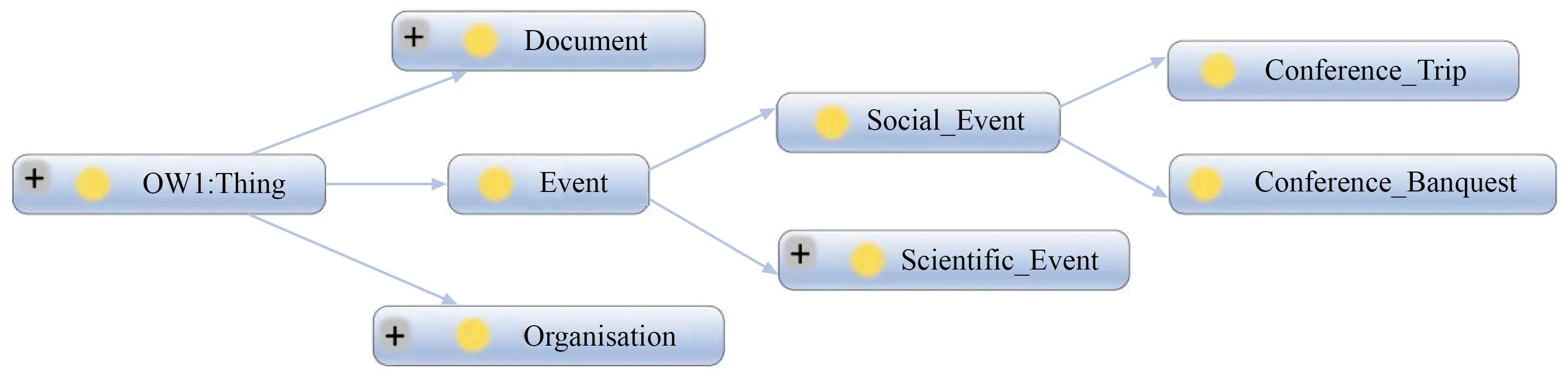
图1 父类及其路径信息Fig.1 Parent class and its path information
2 基于多头自注意力的本体匹配模型
图2为本文提出的匹配模型,处理过程主要分为4步。首先处理输入的OWL,接着计算相似度值,然后利用Multi-Head Self-Attention模型学习特征的权重,最后输出匹配的结果。
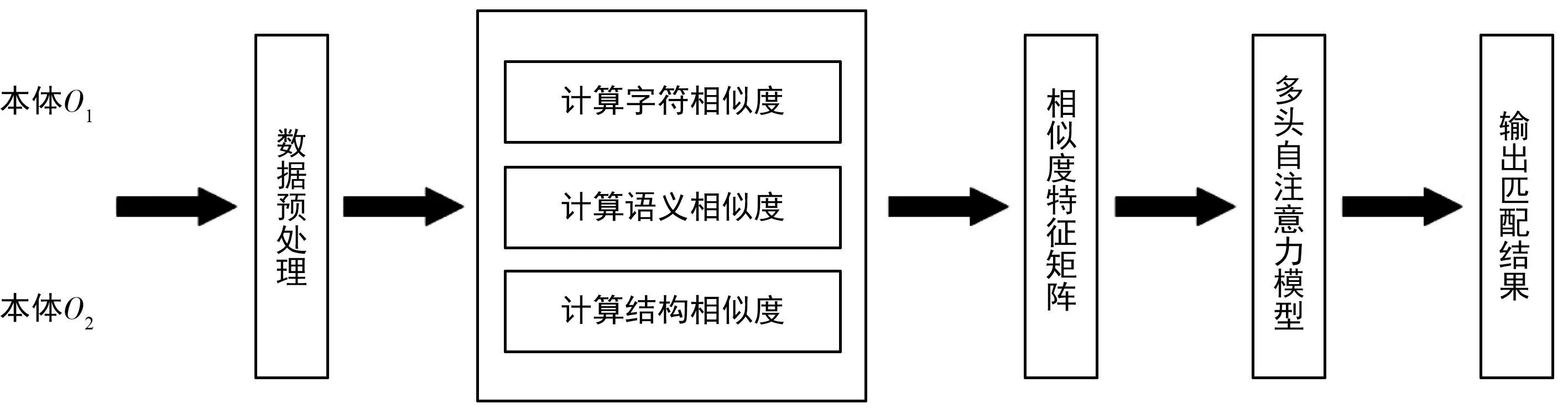
图2 本体匹配模型图Fig.2 Ontology matching model diagram
2.1 数据预处理
(1) 提取文本信息
本体包含丰富的信息,但有些信息利用描述逻辑(Description Logic,DL)隐式表示。因此,需利用特定工具解析待匹配本体。本文选择OWLReady2包中可操作OWL的函数,抽取待匹配本体的类、属性、类的父类及类的完整路径等信息。
(2) 获取语义嵌入表示
首先,从本体的图结构、逻辑构造函数和词汇中提取信息,构建相应的结构和词法语料库。然后,从结构语料库和实体注释中进一步提取出组合文档,以保留词汇信息中实体和单词间的相关性。最后,将结构、语法和组合语料库融合为一个语料库,利用Skip-gram模型训练词嵌入,以获得本体的语义嵌入表示。
2.2 计算相似度值
① 从本体O1和O2中取出两个待匹配的类和属性,记为实体e1与e2,将实体的父类记为parent1和parent2,将类的完整路径记为Path1和Path2。
② 利用式(3)~(4)依次计算实体e1与e2的字符、语义和结构相似度,分别记为simstring(e1,e2),simsemantic(e1,e2),simstructure(e1,e2);同理,计算实体父类及类路径的字符、语义以及结构相似度。
2.3 相似度特征矩阵
假设本体O1和O2共有N个实体对待匹配,其中每个实体对记为i。对于待匹配的实体对i分别使用字符级、语义级和结构级的相似度方法计算其相似度值。其相似度特征向量可写为如下形式:
Xi=[simstringi,simsemantici,simstructurei],
(5)
式中:i代表实体对,取值范围为[1,N];Xi表示实体对的相似度特征向量;simstringi、simsemantici和simstructurei分别表示实体对的字符、语义和结构相似度特征向量。经过上述步骤,可得本体O1和O2间的相似度特征矩阵。
2.4 Multi-Head Self-Attention模型
为高效融合实体对的字符、语义和结构相似度特征,引入Multi-Head Self-Attention模型[17]自主学习每种相似度方法的权重,以Head=3为例,其模型如图3所示。

图3 Multi-Head Self-Attention模型图Fig.3 Multi-Head Self-Attention model diagram
① 对每组输入特征X=[x1,x2,…,xn]都与三个权重矩阵相乘,取得查询向量(Query)、键向量(Key)和值向量(Value)。计算如式(6)~(8)所示:
(6)
(7)
(8)
式中:i的取值为1、2、3,WQ、WK、WV分别代表三个权重矩阵,X代表相似度特征矩阵。
② 使用缩放点积注意力(Scaled Dot-Product Attention)计算注意力得分,并利用softmax函数将注意力分数映射到[0,1]。计算如下:
(9)
式中:Attention(Q,K,V)表示多头注意力层的输出向量,KTQ表示注意力权重的计算过程,Dk表示查询和键的长度。
③ 利用式(10)~(11)合并三个头的结果:
Headi=Attention(Qi,Ki,Vi),i=1,2,3,
(10)
MultiHead(Q,K,V)=Concat(Head1,Head2,Head3)。
(11)
④ 最后连接一个全连接层判断本体是否匹配。
3 实验结果及分析
3.1 实验环境及数据集
实验运行环境为Intel(R) Core(TM) i7-6700CPU @3.4 GHz,内存为8 GB的计算机,采用Python语言编写。本次实验采用本体对齐评测组织(Ontology Alignment Evaluation Initiative,OAEI)竞赛在2023年提供的Conference数据集,该数据集是描述组织会议领域的本体集合,由16个本体组成,提供7个具有基本事实的对齐,从而产生21个本体对。各本体包含的类和属性数(数据属性和对象属性)及标准等价匹配数如表1和表2所示。
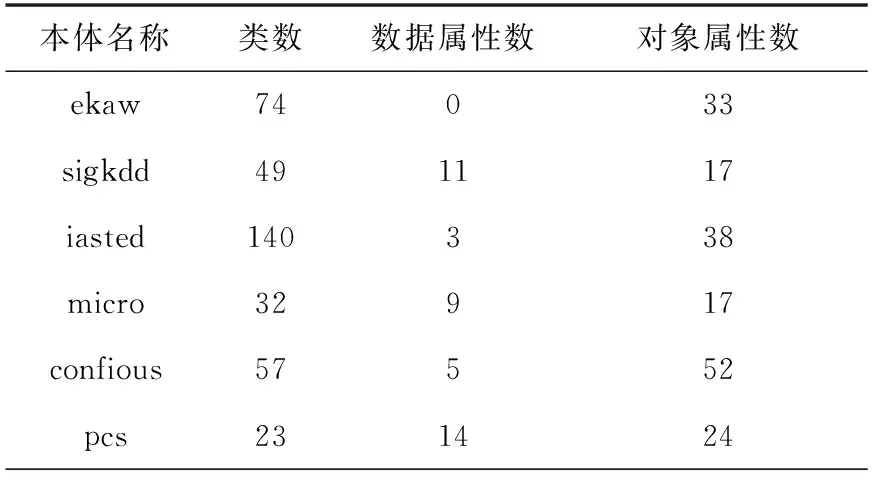
表1 各本体的具体信息Tab.1 Specific information for each ontology
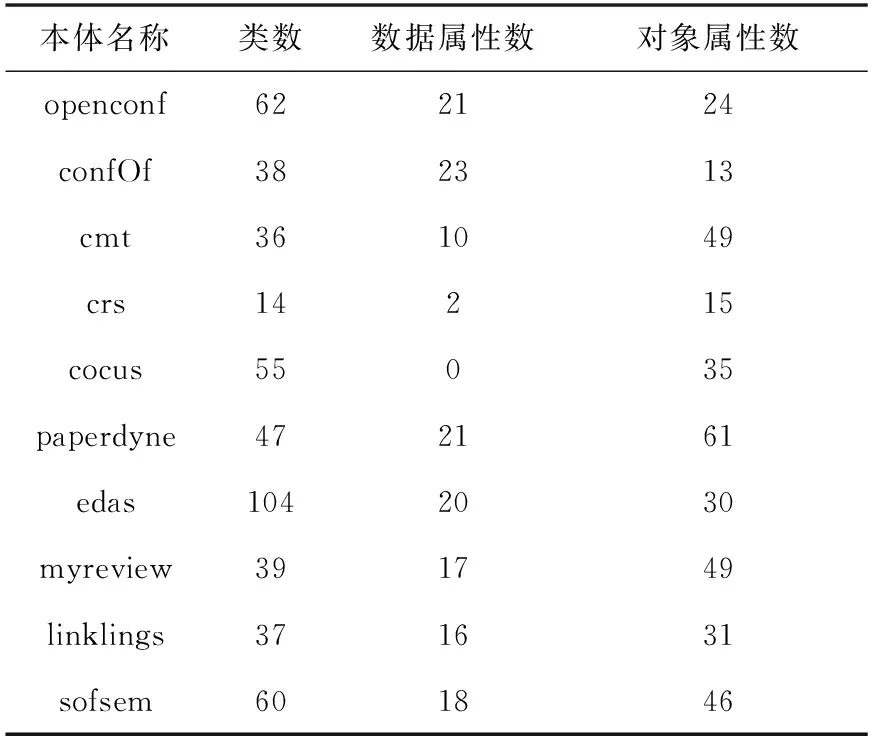
续表
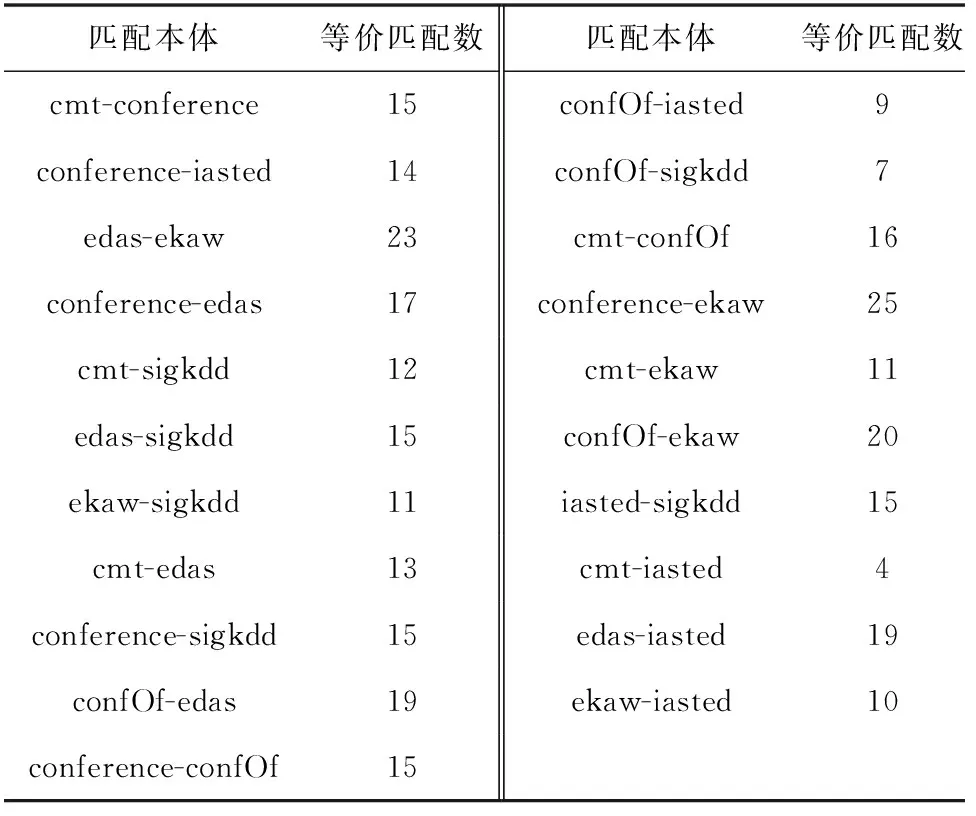
表2 匹配本体及对应的匹配数Tab.2 Matching ontology and corresponding number of matches
3.2 评价指标
OAEI为本体匹配结果提供了参考标准,其评价指标使用准确率(Precision),召回率(Recall),F1值(F1-measure),其计算公式如(12)~(14)所示:
(12)
(13)
(14)
式中:M代表使用本文匹配方法得到的匹配结果,R代表由OAEI提供的可参考的匹配结果。
3.3 实验设计与对比
3.3.1 基于机器学习方法的分类结果及分析
为研究类和属性相似度及利用OWL2Vec*方法获取本体语义嵌入表示的有效性,本文利用逻辑回归(Logistic Regression,LR)[18]、随机森林(Random Forest,RF)[19]和极致梯度提升(EXtreme Gradient Boosting,XGBoost)[18]这三种机器学习方法对匹配结果进行分类。
实验参数的设置:① LR:正则化参数(Penalty)采用“l2”,损失函数优化器(Solver)选择“lbfgs”,分类方式(multi_class)选择“auto”,最大迭代次数(max_iter)为100。② RF:设置子树数量(n_estimators)为100,树的最大生长深度(max_depth)为2,叶子的最小样本数量(min_samples_leaf)为1。③ XGBoost:叶节点分支时所需损失减少的最小值(gamma)为0.8,树的最大深度(max_depth)为5,孩子节点最小的样本权重和(min_child_weight)为1。
本文选择conference、edas、cmt、sigkdd、confOf、ekaw、iasted七个本体作为测试集,其余14个本体作为训练集。分类结果的最佳F1值如表3所示。
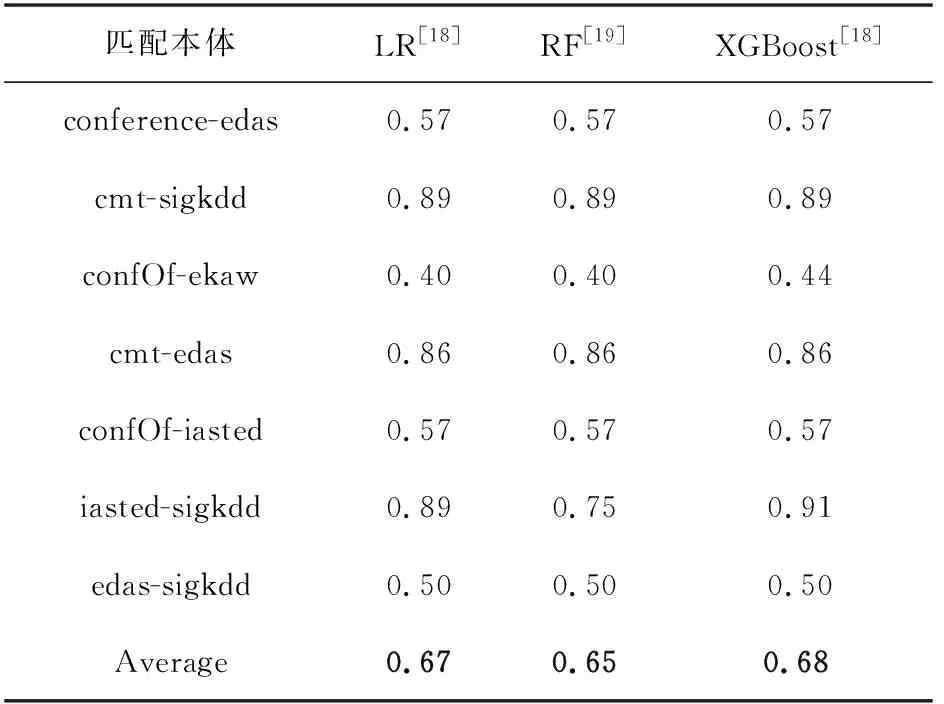
表3 各分类模型的F1值Tab.3 F1-measure for each classification model
与未使用OWL2Vec*方法获取语义表示时,使用LR、RF和XGBoost方法分类的F1值对比结果如图4所示。

图4 F1值前后对比图Fig.4 F1-measure original and present comparison
由图4可知,同时探求类和属性的相似度,并利用OWL2Vec*方法获取本体语义表示,在LR和XGBoost的分类效果上F1值都提升了2%。主要有两方面的原因:第一,OWL2Vec*方法可以充分利用本体OWL中所包含的图结构、词汇信息以及逻辑构造函数等信息,高效地进行语义编码,以便挖掘出匹配对之间隐含的语义关系,从而提升匹配结果的效率。第二,Conference数据集中本体的类和属性的数据量相对来说较小。因此,在使用LR和XGBoost方法分类时,计算量不大且速度较快。而在使用RF方法分类时,由于特征较少,容易出现分类不平衡问题,导致其F1值不高。
3.3.2 基于Multi-Head Self-Attention模型的匹配结果及分析
为充分融合字符级,语义级和结构级的相似度值,本文引入Multi-Head Self-Attention模型自主学习三种相似性方法之间的权重。在匹配结果的对比实验中,选择与近几年的14种匹配方法[20]展开比较。结果如表4所示。

表4 各方法的匹配结果Tab.4 Matching results of each method
由表4可得,OM-MHSA方法在准确率上达到89%,相对于LSMatch和KGMatcher+方法提升了6%,即取得最优的结果。在召回率方面,OM-MHSA方法也高于Matcha和ALIOn方法。在F1值方面,OM-MHSA方法超过了ALIOn、TOMATO和Matcha等方法。主要有以下原因:① LSMatch方法只考虑了字符相似度和同义词匹配,没有考虑本体间的结构关系;② KGMatcher+方法主要考虑了基于字符和实例的匹配,没有考虑本体间的语义关系;③ LSMatch、KGMatcher+以及ALIOn等方法都未匹配概念间的属性。另外,导致TOMATO方法准确率不高的原因是该方法会为同一实体对输出多个匹配结果,并将置信度值指定为1.0。综上,本文利用OWL2Vec*方法可以获取匹配对之间更深层次对应的语义关系,然后充分考虑类和属性的字符、语义和结构等多种相似性度量方法,并引入Multi-Head Self-Attention模型自主学习每种相似度方法对匹配结果的贡献值,从而提升了匹配的效果。
4 结束语
本文同时考虑类和属性的多种相似度,并使用OWL2Vec*方法获取本体的语义表示,并引入Multi-Head Self-Attention模型融合两个概念间的多种相似度。实验结果表明,相对于LSMatch和KGMatcher+方法,OM-MHSA方法准确率提升了6%,证明该方法可以有效地提升匹配结果的效率。
该方法也有不足之处,未来的相关研究,将从以下方向探索:① 加入外部资源是提升匹配质量的一种方式。因此,可以考虑加入外部知识。② 本文选择的字符相似度方法相对单一,可探究多种不同的字符相似度计算方法。③ 在计算结构相似度时,主要研究概念的父类及其路径之间的相似度,可探讨概念子类间的相似度。
