基于BERT与多通道卷积神经网络的细粒度情感分类
2023-12-15诸林云范菁曲金帅代婷婷
诸林云, 范菁, 曲金帅, 代婷婷
(云南民族大学电气信息工程学院, 昆明 650031)
情感分析是计算机科学中的一个领域,它涉及识别和分类文本中隐含的情感和观点,使用自然语言处理来系统地识别、提取、量化和研究一个给定的文本,这个过程也被称为文本的上下文挖掘。从市场营销到客户服务再到医学,情感分析可以应用于广泛的领域,以分析人们所表达的不同观点的潜在情绪,并获得有价值的见解。除此之外,人们还会在网站上发表一些评论,包括政治、宗教和社会问题。近年来的研究表明,网络舆情反映了人们的社会政治态度,使用情感分析来识别公众意见对推进政府的工作非常有帮助,可为管理者提供决策依据。当突发网络舆情事件时,网民会在微博以及其他社交平台上面发表意见并进行交流,对网民意见进行情感分析,从而分析公民在突发事件面前的意见,可以为政府在防范舆论哗然、焦虑和压力的斗争中提供相关参考信息。
针对以上存在的问题,现提出融合 BERT 预训练语言模型和多通道卷积神经网络的深度学习方法。首先使用数据增强使数据类别达到平衡状态,接着使用BERT模型对输入的文本进行编码,再结合多尺度、多通道的卷积神经网络对文本进行细粒度情感分类。同时探究表情符号对细粒度情感分类模型的影响。该模型对句子中语义和远距离依赖的捕捉能力强,并且能够提取文本的深层次特征,进而提升模型在细粒度情感分类的性能,为政府在突发事件中引导公众的情绪做出参考。
1 相关研究内容
1.1 社交媒体文本的情感分析
近年来的研究表明,网民的情绪反映了人们的社会政治态度,因此研究网民情绪对网络舆情的趋势预测和评价具有重要意义,可为管理者提供决策依据。Georgiadou等[7]对推特帖子进行情绪分析以调查和聚合公众情绪对英国脱欧的结果。Falck等[8]使用“情感政治指南针”对报纸对政党的态度进行分类,旨在研究报纸里面的政治倾向对选民意见形成的影响。El Alaoui等[9]提出了一种适应性强的方法,它可以分析用户的社交媒体帖子,并使用大数据工具实时提取他们的观点。Bhagat等[10]旨在分析新型冠状病毒肺炎流行期间,公众对在线学习的看法,应用基于词典的方法,对通过网络抓取提取的文章进行情感分析。结果显示博客比报纸文章更积极。在探讨网民情绪对网络舆情的影响方面,朱晓卉等[11]使用结合词典和长短期记忆神经网络(long short-term memory,LSTM)的情感分析方法对公众的情感类型以及情感强度进行分类,结合事件进行分析讨论,从而得到能够使舆情转好的引导方法。 Lu 等[12]通过聚类信息来帮助分析公众的意见。收集天津端口爆炸相关的原始帖子和热门评论作为语料库,通过对聚类结果的分析,识别热点话题热点,探讨了公众舆论的演变模式。冯兰萍等[13]在“东方之星”沉船事故、天津滨海爆炸事故以及“长春长生疫苗”3个事件上验证其提出的突发事件网络舆情群体情绪演化模型的可行性。结果表明,该模型能够体现出在不同情绪下,政府的干预对主流情绪引导能力产生的影响。Jabalameli等[14]使用隐含狄利克雷分布(latent dirichlet allocation,LDA)方法的自然语言处理用于识别 Twitter 数据中的 11 个主题和 8 个子主题,以分析它们对公众舆论的影响。
1.2 基于深度学习的情感分类
深度学习已经被广泛地应用于情感分析中,Zhao等[15]将BERT预训练语言模型用于基于方面的情感分析。该模型通过将外部领域知识融入预训练语言模型以弥补有限的训练数据,从而能够以少量的训练数据获得更好的性能。Batra等[16]提出了3种不同的策略来分析基于 BERT 的情感分析模型,实验结果表明,基于 BERT 的集成方法和压缩的 BERT 模型在3个数据集上比基线模型在评价指标上提高了 6%~12%。Yan等[17]提出了一种注意力并行双通道深度学习混合模型来解决以往情感分析研究中难以很好地捕捉文本情感特征和识别词语歧义的问题。该模型使用BERT预训练语言模型对输入的文本进行编码。实验结果表明,该模型可以有效优化文本特征的表达,增强文本情感特征的提取能力,可以更好地进行网络舆情评论的情感分类。
针对基于用户评论的细粒度情感分析任务,李慧等[18]提出一种融合属性特征的多粒度卷积核CNN模型用于细粒度情感分析。得到的实验结果相较于传统情感分类模型在准确率、召回率和F1评价指标方面都有一定的提高。王义等[19]建立一种细粒度的多通道卷积神经网络模型。仿真结果表明,该模型较传统卷积神经网络模型在情感分类的准确率和F1上性能均有明显提升。Bian等[20]构建了一个改进的卷积神经网络模型,可以综合利用非结构化特征和结构化特征,提高AOP识别的性能,对从携程上抓取的酒店在线评论进行了实证研究。实证结果表明,该方法可以有效地从酒店的在线评论中识别客户偏好。张瑾等[21]提出了一种双向门控循环单元(bidirectional gated recurrent unit,BiGRU)与门控机制相结合的模型用于AI challenger 2018细粒度情感分析,所提模型的MacroF1score值达到了0.721 8,性能超过基线系统,获得了较好的实验结果。祝清麟等[22]提出一种结合金融领域情感词典和注意力机制的金融文本细粒度情感分析模型。该模型能有效获取金融领域词语的特征信息。最终在构建的金融领域实体级语料库上进行实验,取得了比对比模型更好的效果。Lai等[23]提出了一种基于语法的图卷积网络(graph convolutional networks,GCN)模型,以增强对中文微博不同语法结构的理解。实验结果表明,该模型可以有效地利用依赖解析的信息来提高情感检测的性能。
2 BERT与多通道卷积神经网络模型的构建
所提出的模型的总体结构如图1所示。首先是嵌入层,将处理完成的数据输入到模型之前,为了能够让计算机处理文本序列,则需要将文本序列转换成数值向量。序列的每一部都会被嵌入层投影到一个d维的连续向量空间中。给定一个标记化的序列X=(x1,x2,…,xn),xi表示序列中的第i个标记,n表示序列的长度。在词嵌入后,将得到一个n×d维数的矩阵。在每个序列的开始处添加一个特殊的“[CLS]”标记,并将句子嵌入添加到词嵌入中。为了捕获词序,还添加了位置嵌入。词嵌入、句子嵌入和位置嵌入的嵌入维度是相同的。

图1 BERT与多通道卷积神经网络的模型结构Fig.1 Model structure of BERT with multi-channel convolutional neural networks
输入序列在嵌入层完成后被送入BERT模块。BERT模块是由堆叠的Transformer组成的。Transformer模块主要由多头注意力机制模块和前馈神经网络模块组成。该模块在输入嵌入层加上了位置编码,然后再通过多头注意力机制模块计算多头自注意力,最后通过前馈神经网络模块以及残差连接和归一化层得到最后的输出。
一句话中同一个词会因为位置不同而导致意思完全相反,为了解决这个问题,Transformer加入了位置编码,位置编码与嵌入具有相同的维数,这样两者相加得到的向量就带有词的位置信息,位置编码的计算如式(1)和式(2)所示。
PE(pos,2i)=sin(pos/10 0002i/dmodel)
(1)
PE(pos,2i+1)=sin(pos/10 0002i/dmodel)
(2)
式中:pos为词在句子中的位置;i为维度;dmodel为位置编码的维度,位置编码的每个维度都对应于一个正弦曲线。不同的位置信息会随着不同的波长产生周期性的变化,波长的范围为2π~10 000×2π。接下来是多头注意力机制模块,通过不同的head就可以得到多组特征表达,然后再将多组特征表达进行拼接,如式(3)~式(5)所示。
MultiHead(Q,K,V)=Cancat(head1,
head2,…,headh)Wo
(3)

(4)

(5)

除了多头注意力机制模块外,Transformer的编码器和解码器中的每个层都包含一个全连接的前馈神经网络,利用前馈神经网络来丰富xi的语义信息。它由两个具有relu激活函数的线性变换组成,如式(6)所示。
FFN=relu(xW1+b1)W2+b2
(6)
式(6)中:W1、W2为权重矩阵;b1、b2为偏置项。通过计算,最终得到BERT的编码信息,如式(7)所示。
BERToutput1=[E(cls),E(x1),E(x2),…,
E(xi),…,E(xn)]
(7)
式(7)中:E(cls)为输入句子的语义向量;E(xi)(1≤i≤n)为发送的每个词的语义向量。为了在充分利用每个词的语义信息的同时对数据进行降维,本研究利用卷积神经网络中平均池化层的思想,对E(x1),E(x2),…,E(xi),…,E(xn)进行平均池化操作。此外,为了避免在训练过程中丢失BERT模型获得的语义向量,将平均池化操作得到词语义向量与句子语义向量E(cls)融合,BERToutput2作为输入多通道卷积神经网络的最终语义信息。如式(8)和式(9)所示。

(8)
BERToutput2=Eavg+E(cls)
(9)
研究使用具有多个不同大小的卷积核的并行卷积层来学习微博文本特征,设置多个卷积核,全面获取微博句子表达中的特征,降低特征提取过程中的偶然性。BERT预训练语言模型输出的最终语义信息BERToutput2作为多通道CNN模型的输入,来提取文本的深层特征,对于一个卷积核,一个特征值mi的计算公式如式(10)和式(11)所示。
mi=(WSi:i+k-1+b)
(10)
ci=relu(WSi:i+k-1+b)
(11)
式中:W为卷积核矩阵向量;i为卷积的第i步;k为卷积核的高度;b为偏置项;relu为激活函数;Si为一句话中的第i个词向量;mi为在第i步卷积操作过程中提取的特征值。mi在经过relu激活函数得到特征值ci。然后采用最大池化的方式选取主要特征作为输出特征。如式(12)和式(13)所示。
c=[c1,c2,…,cn-h+1]
(12)

(13)

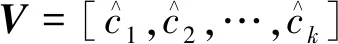
(14)
将得到的特征向量V输入一个全连接层中,并通过特征空间变换[24]将该特征向量映射到样本类别空间,如式(15)所示。
R=VW3+b3
(15)
式(15)中:W3为权重矩阵;b3为偏置项。最后使用softmax函数来预测文本的情感类别。假设r1,r2,…,ri,…,rk表示每个文本的概率(即R=[r1,r2,…,ri,…,rk]),特征向量R使用softmax函数转换为概率向量P,如式(16)和式(17)所示。
P=softmax(R)=[p1,p2,…,pi,…,pk]
(16)

(17)
式中:k为文本情感类别的总数;pi为文本的情感属于第i类的概率。
3 仿真实验分析
3.1 实验环境和数据集
基于Pytorch深度学习框架。该模型的优化函数是Adam,因为它可以为不同的参数设计独立的自适应学习速率,并加快网络的收敛速度。该模型的详细超参数设置如表1所示。

表1 参数设置Table 1 Parameter settings
为了评估本文方法的有效性,使用了SMP2020-EWECT数据集,该数据集一共包含两个数据集:①通用微博数据集,其中的微博数据是随机收集的包含各种话题的数据;②疫情微博数据集,其中的微博数据均与疫情相关。对以上两个数据集进行了全角转半角、繁转简、去除url、去除email、去除@以及保留表情符号等操作。该数据集包含以下6种情感:开心、愤怒、悲伤、恐惧、惊讶和无情绪。为验证本文模型的鲁棒性,将两个数据集合并对本文方法进行验证,各种情感样本总数如图2所示。

图2 各种情感样本数量Fig.2 The number of samples of various emotions
由图2可知,数据集存在明显的样本不均衡,恐惧和惊讶的样本较少,不平衡数据违反了大多数学习算法的相对均衡分布假设,这会显著降低分类性能。模型进行训练时很难从文本中提取所需要的特征,这可能导致过度拟合的情况。当用少量样本训练分类模型时,它们倾向于记忆训练集中的特征,而不是学习潜在的特征分布,导致泛化能力不足,采用数据增强的方式增加恐惧和惊讶的样本数量,对已有的恐惧和惊讶的样本通过同义词替换、随即插入、随机替换以及随机删除增加样本的数量。数据增强后的数据集如表2所示。

表2 数据规模Table 2 Data scale
3.2 评价指标
为了验证不同分类方法的性能,基于混淆矩阵评估所有分类方法。其中包括:真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)[25]。使用了3个多类别任务评估指标:加权准确度(WP)、加权召回(WR)、加权F1(WF1)[26]。
(18)

(19)

(20)
式中:N为样本总数;m为类别总数;ni为第i个类别的样本个数;TPi、FPi和FNi分别为在第i个类别中正向分类、正向错误分类和负向错误分类的模型样本;Pi和Ri分别为第i个类别的准确率P和召回率R。
3.3 实验结果与分析
所提出的模型以及基础模型在SMP2020-EWECT数据集上的实验结果如表3和图3所示。

表3 不同模型分类结果Table 3 Classification results of the different models
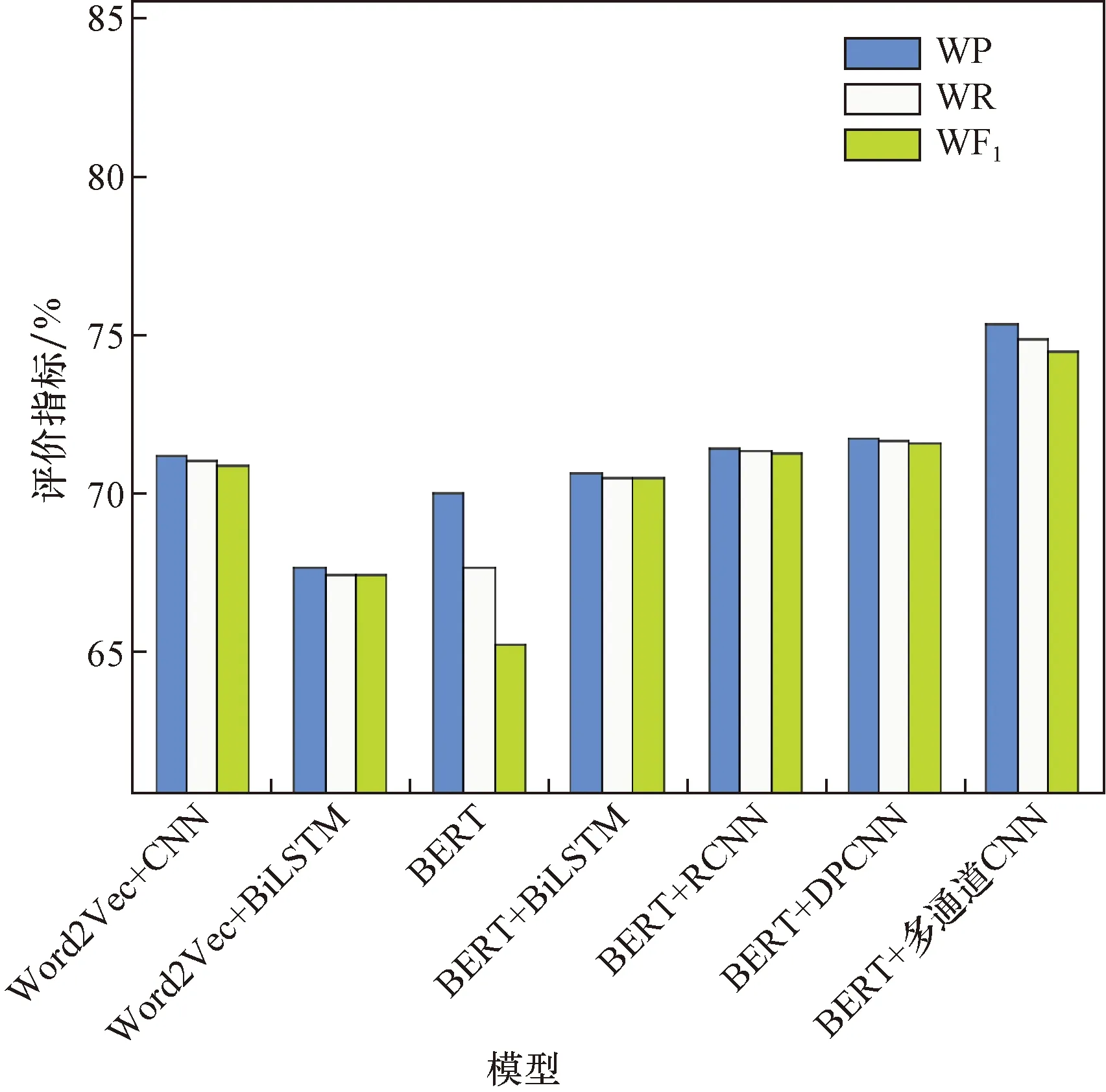
图3 各个模型结果对比Fig.3 Comparison of the results of each model
由表3可知,通过与CNN、BiLSTM、BERT、基于卷积神经网络特征的区域方法(regions with CNN features,RCNN)、深度金字塔卷积神经网络(deep pyramid convolutional neural networksfor text categorization,DPCNN)对比可知,所提出的融合BERT和多通道卷积神经网络的模型在各项评价指标上都有良好的分类效果,本文方法相较于单一的BERT模型,本文模型在加权准确度上提升了5.35%。说明利用多通道的卷积神经网络可以提取文本的深度情感特征。与Word2Vec+CNN相对比,本文模型在加权准确度上提升了3.56%,说明利用BERT预训练语言模型可以捕获词的上下文信息,增强文本的语义特征表示,进而提升分类器的细粒度情感分类性能。本文算法与BERT+BiLSTM、BERT+RCNN和BERT+DPCNN的分类结果相对比,本文模型在加权准确度上分别提升了4.71%、3.92%、3.61%。在预训练语言模型方面,BERT+平均池化+多通道CNN相较于Word2Vec+CNN在加权准确度上提升了3.56%,BERT+BiLSTM相较于Word2Vec+BiLSTM在加权准确度上提升了3%,说明BERT预训练语言模型能够很好地解决词的多义问题,对提升情感分类的性能有一定的帮助。
由于文本中包含许多表情符号,而且当前网民在网上发表观点时,更倾向于用表情来表达他们的感受,为探究表情符号对细粒度情感分类效果的影响,将表情符号按照网上现有的表情库转换成对应的文字,转换后的细粒度情感分类结果如表4和图4所示。
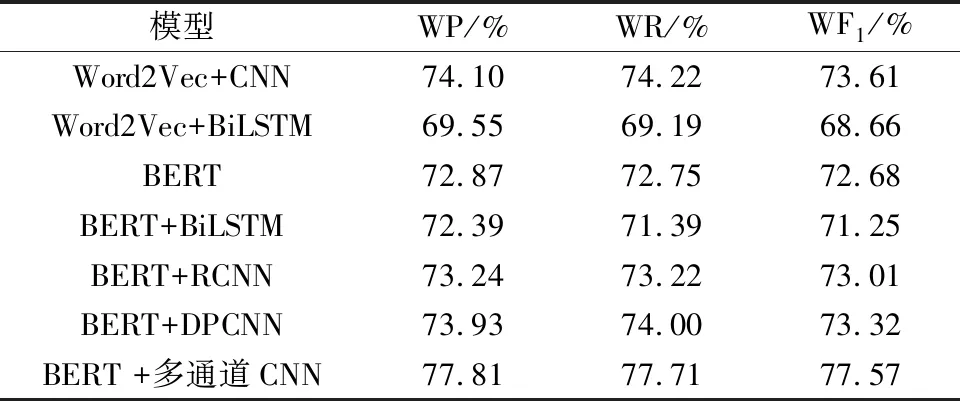
表4 表情符号转换后的实验结果Table 4 Results of the experiments after emoji conversion
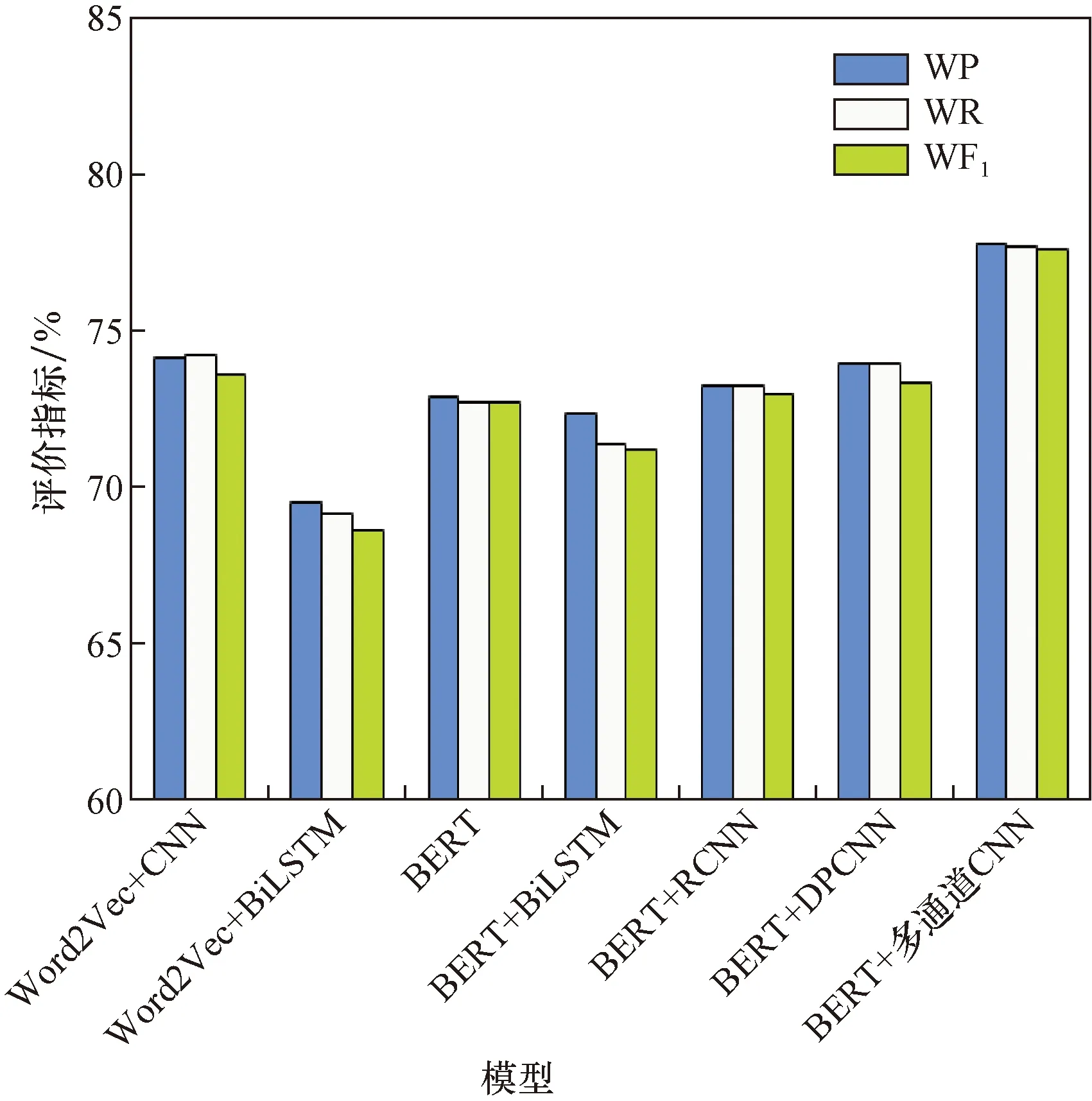
图4 表情符号转换成文字的结果对比Fig.4 Comparison of the results of emoji symbols converted into text
由表4可知,在将表情符号转换成文字之后,Word2Vec+CNN的加权准确度提升了2.82%,Word2Vec+BiLSTM的加权准确度提升了1.91%,BERT的加权准确度提升了2.87%,BERT+BiLSTM的加权准确度提升了1.75%,BERT+RCNN的加权准确度提升了1.81%,BERT+DPCNN的加权准确度提升了2.19%,本文方法的加权准确度提升了2.46%,说明表情符号转换为文字可以提高模型对文本情感特征的提取能力,对提升模型的分类性能有一定的帮助。
4 结论
探讨了使用多通道卷积神经网络进行微博细粒度情感分析的可行性。通过BERT预训练语言模型对输入的文本进行编码,以增强文本的语义特征表示,通过具有多个不同大小的卷积核的并行卷积层来学习微博文本特征,捕获文本的深层次特征,提升模型在细粒度情感分类的性能。该模型充分考虑了文本特征稀疏的特点。实验结果表明,本文方法在同等条件下的各项评价指标都高于基础模型。此外,还探索了文本中的表情符号对模型分类性能的影响,实验结果表明,将表情符号转换为文字可以有效地增强情感的表达,提高模型的分类性能。综上所述,该模型具有一定的实际意义,能够有效地提高微博文本的细粒度情感分类效果,进而为政府引导公众情绪提供更为准确的建议。未来,将考虑结合微博的多维特征进行情感分析,并对微博评论进行实时情感预测,提升舆情分析的效率。
