基于LSTM-SVM 模型的河流流量预测
2023-12-14张琴琴刘文强陈之鸿郝永红
张琴琴,刘文强,陈之鸿,郝永红
(1.天津师范大学 天津市水资源与水环境重点实验室,天津 300387;2.天津师范大学地理与环境科学学院,天津 300387)
我国是水资源短缺的国家之一,经济社会的发展进一步加重了其水资源紧缺的态势[1]. 河流流量精确预测是水文学领域的重要研究内容,特别是在水资源稀缺的地区,预测河流流量有助于水资源的时空规划和分配.然而,由于自然地理要素和人类活动的随机性以及径流形成过程的复杂性,径流表现出高度非线性和非平稳性[2-5],这加剧了水文预报研究的困难程度.传统径流预测模型往往基于复杂的物理过程,需要通过大量参数和复杂的模型校准过程将不确定性降至最低,从而获得高精度的输出[6]. 汇流过程的复杂性以及参数计算的不确定性导致同一种模型可能出现不同结果,甚至产生异参同效等问题[7];同时,基于物理过程的数值模型成本高、时间长,且需要研究人员具备一定程度的模型专业知识和经验,模型的预测效果不理想,以致发展受限[8].
随着信息技术的不断发展,数据驱动模型近年来在水环境与水资源领域取得了广泛的应用.与传统预测模型相比,数据驱动模型的预测性能有所提升.常见的基于机器学习的数据驱动模型包括人工神经网络(ANN)、支持向量机(SVM)和随机森林等,基于深度学习的数据驱动模型包括卷积神经网络(CNN)、递归神经网络(RNN)和长短时记忆神经网络(LSTM)等[9].相关学者利用数据驱动模型做了大量研究,例如Zhang等[10]提出了一种ARIMA-ANN 混合模型,提高了预测精度;Taghi 等[11]利用时间滞后RNN 和BP 神经网络预测伊朗大坝每日流入量,结果表明2 种模型在预测日常流量时表现良好,但预测洪峰值的精度较低.
Wang 等[12]发现,SVM 模型比ANN 模型更易解决样本小、非线性和局部最小的问题,且具有良好的泛化能力;Christian 等[13]将优化后的SVM 与传统的时间序列模型(SARIMA)进行比较发现,在适当的输入数据条件下,优化后的SVM 模型能够提供良好的预测精度.LSTM 模型对时间序列数据的预测性能较好[14],例如Ouyang 等[15]运用LSTM 模型预测美国境内3 557个流域的降雨-径流,结果显示LSTM 模型不仅对小流域有很好的模拟效果,对最具挑战的大流域的预测结果也较好.
在不同使用场景下,LSTM 和SVM 模型的预测效果不同,主要有3 种情形:①LSTM 预测性能优于SVM[16-17],尽管SVM 可以提高模型的计算速率,但在处理海量数据和较低河流流量时表现不足,而LSTM 具有明显的优势,它可以快速、准确地模拟出不同时间尺度和低入流量情况下的结果,解决了SVM 耗时长的问题;②2 种模型性能相当,如Han 等[18]对俄罗斯河流域的径流预测的结果表明,LSTM 和SVM 模型在小时径流预测方面性能相当,均优于ANN 和基于分布式的物理模型的预测性能,且在丰水期的预测性能优于枯水期;③SVM 预测效果优于LSTM,Rahimzad 等[19]研究发现,在一些高流量的模拟情况中,SVM 的预测效果优于LSTM.
本研究基于LSTM 模型在处理长周期序列方面的优势以及SVM 良好的泛化能力,提出了LSTM-SVM混合模型,分别使用LSTM-SVM 模型和LSTM 模型预测大清河水系拒马河上游紫荆关水文站的逐日河流流量,比较所得结果,评估LSTM-SVM 在河流流量建模中的适用性,为中长期河流流量预测提供参考.
1 研究方法
1.1 LSTM 神经网络模型
基于人工智能的模型方法(包括人工神经网络和遗传算法)被认为是处理非线性数据的有效方法.然而,它们在处理数据中的依赖关系时存在缺陷[20-21].近年来,RNN 因能够学习时间序列数据的内在特征而被应用于水文预报研究中,但由于梯度消失问题,其很难学习到长周期序列间的因果规律[22].LSTM 是一种克服了传统RNN 长期依赖缺点的特殊RNN,最早由Hochreiter 等[23]提出,并被许多研究人员改进和推广[21].具体结构如图1 所示,通过专门设计的门结构(分别为遗忘门、输入门和输出门)和存储单元来确定何时忘记以及保留状态信息.

图1 LSTM 内部结构Fig.1 Structure of LSTM
由图1 可以看出,LSTM 单元共有2 条水平通道:①顶部从Ct-1到Ct为单元状态,是LSTM 的核心,通过简单的线性操作穿透整个时间序列数据;②底部由上一时刻输出的ht-1和当前输入的xt组成另一条通道.模型在t时刻的具体计算公式如下:
遗忘门
输入门
单元状态
输出门
式中:Wf、Wi以及Wo是映射到遗忘门、输入门和输出门的隐藏层的权重值;bf、bi及bo为偏置值;Ct-1和Ct是上一个时间步长以及下一个时间步长的单元状态;ot表示t时刻的输出;WC表示单元状态的权重值.
1.2 SVM 模型
SVM 模型是解决分类和回归问题方面的领先技术之一,且在许多领域表现出色,最早由Vapnik 等[24]提出.SVM 能够有效处理数据的非线性和非平稳性,因而在水文领域得到了广泛应用[25].SVM 的基本思想是通过一个非线性映射将样本映射到一个高维特征空间,并在该高维特征空间构造出最优分类超平面,最终完成分类预测.假设训练集输入{xi}和目标输出{yi},其中i∈R,则目标函数为
式中:y是预测值;w和b是函数的参数向量;φ(x)表示非线性变换函数.通过解决以下优化问题来估计参数的最佳值:
式中:C为惩罚系数,它表示权重分散和目标函数之间的权衡[26];ξi、ξi*为松弛变量,表示样本的离群程度;ε为不敏感损失函数.通过在对偶空间中引入拉格朗日乘子ai和ai*,最终可得到如下决策函数
式中:K(xi,xj)为核函数,本研究采用线性核函数,它具有参数少、速度快的优点,表达式为
1.3 LSTM-SVM 模型
根据当前LSTM 计算量大、耗时长等不足以及SVM 速度快、分类能力强等优势,本研究提出一种LSTM-SVM 混合模型,模型框架如图2 所示.
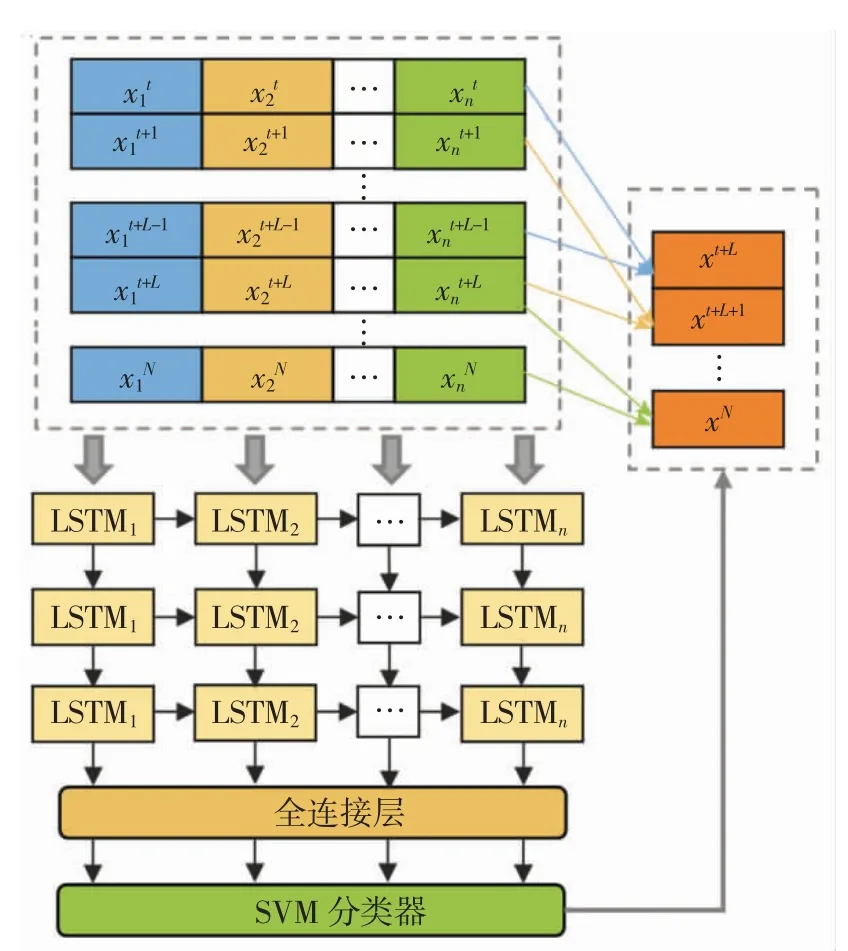
图2 LSTM-SVM 模型框架Fig.2 Prediction framework of LSTM-SVM
由图2 可以看出,本研究预测模型包含数据输入、LSTM 模型及SVM 3 个部分.第一阶段:给定输入序列X=(x1,x2,…,xn),主要包含降水、水位和水温3个水文要素及气温、气压、相对湿度、日照和风速5个气象要素.第二阶段:将数据提供给LSTM 层,通过3 层LSTM 堆叠对数据进行深度挖掘.从而确定后续单元需要保留的信息. LSTM 包含1 个tanh 层和3个sigmoid 函数.每层LSTM 都与其他层相互作用,主要连接上一层数据的输入以及当前数据的输出.第三阶段:修改LSTM 网络的softmax 层,在softmax 层使用SVM 分类器进行预测并直接输出预测值,进一步提升预测结果的准确性.
LSTM-SVM 模型的逻辑流程图如图3 所示.由图3可以看出,预测过程先对数据进行标准化处理,消除指标之间的量纲影响,再将数据集划分为70%的训练集和30%的预测集;然后将LSTM 和SVM 分类器进行组合,原始数据集通过LSTM 模型的记忆单元和遗忘门机制,将深度特征提取的数据输入给SVM;最后对组合模型进行数据训练并做预测,评估模型误差,当预测结果未达到模型评估标准时,重新调节参数,直至达到标准,输出序列,完成预测.

图3 LSTM-SVM 逻辑流程图Fig.3 Logic flow chart of LSTM-SVM
1.4 模型评价指标
为了评估模型的性能和准确性,本研究使用公式(12)—(15)作为评估标准.平均绝对误差(MAE)和均方误差(RMSE)越接近0,模型的性能越好;Nash-Sutcliffe 模型的效率系数(NSE)和决定系数(R2)越接近1,模型的性能越好.
式中:xi为观测值;为观测序列的均值;yi为模型的预测值;为统计模型的变量模拟值;n为样本数.参考文献[27-28],模型性能评级标准如表1 所示.

表1 模型的性能评级Tab.1 Performance ratings of model
2 研究区概况与数据来源
2.1 研究区概况
拒马河是海河流域大清河水系北支的主要河流,发源于河北省涞源县西北太行山麓,流经河北省易县、涞水县,至北京张坊分为南拒马河和北拒马河.北拒马河流经河北涿州、高碑店,在白沟镇与南拒马河汇合后称为大清河,最后流入天津海河,全长238 km,流域面积4 938 km2,如图4 所示.拒马河为重要的水源地,对下游白洋淀生态湿地和雄安新区有重要的水源供给和生态屏障作用.紫荆关水文站(北纬39°26′,东经115°10′)位于易县的紫荆关镇,是拒马河上游唯一的重要河道控制站,控制流域面积1 760 km2[29]. 流域内植被情况较差,水土流失严重,属温带半干旱大陆性季风气候,夏季炎热多雨,冬季寒冷干燥,汛期雨水暴涨暴落,水位流量较不稳定.
2.2 数据来源及模型参数
2.2.1 数据来源
本研究中紫荆关水文站数据来源于中华人民共和国水文年鉴《海河流域水文资料》(中华人民共和国水利部水文局刊印),包括逐日平均流量、水温、降水量和平均水位;研究流域上游无相应气象站,故选取与水文站点距离最近的气象数据为研究资料,数据来源于中国科学院地理科学与资源研究所的国家级地面气象观测站易县气象站(站号54507)日值数据集,包含5 项气象数据.以水温、降水、水位、气温、气压、相对湿度、日照、风速作为模型的输入变量,河流流量的预测值作为模型的输出量.由于洪水水文要素在一年中出现的次数较少,连续年间存在间断,故以小时为单位的数据存在不连续的现象,基于此,选用日尺度的水文时间序列数据进行水文模型的河流流量预测. 数据长度为2006 年1 月1 日—2019 年12 月31日,其中2006 年1 月1 日—2015 年9 月30 日为训练期,2015 年10 月1 日—2019 年12 月31 日为预测期.针对少量监测数据缺失的问题,取每年该月份的平均值进行填补,水文和气候资料如图5 所示.
2.2.2 模型参数
LSTM-SVM 模型在LSTM 部分的主要参数及参数值为:神经元数(32)、优化器(adam)、批量大小(64)、迭代次数(1200)、损失函数(mse)和随机丢弃值(0.5).模型在SVM 部分需要率定的主要参数为:模型结束标准的精度(tol)、惩罚系数(C值)和损失函数(ε).C值越大,对模型的的惩罚力度也越大,模型的精度更高但容易出现过拟合;ε 值越大表明模型容错越多,越易发生欠拟合[9].本研究中当tol = 10.1,C=16.1,ε = 0.1时,模型在预测集上的表现最好.
为验证LSTM-SVM 模型预测河流流量的优点,分别使用LSTM-SVM 模型和LSTM 模型对流量进行模拟,并对比分析模拟结果.为了便于比较,LSTM 模型的构建与LSTM-SVM 模型中的LSTM 模块一致.
3 结果与分析
由于水文气象因素对河流流量的影响具有一定的时效性,本研究分别选取1~7 d 的时间步长来模拟拒马河的流量,这种短时滞的选取方法在水文预报中也有应用[30-32],2 组模型在预测期内的各项性能指标如图6 所示.
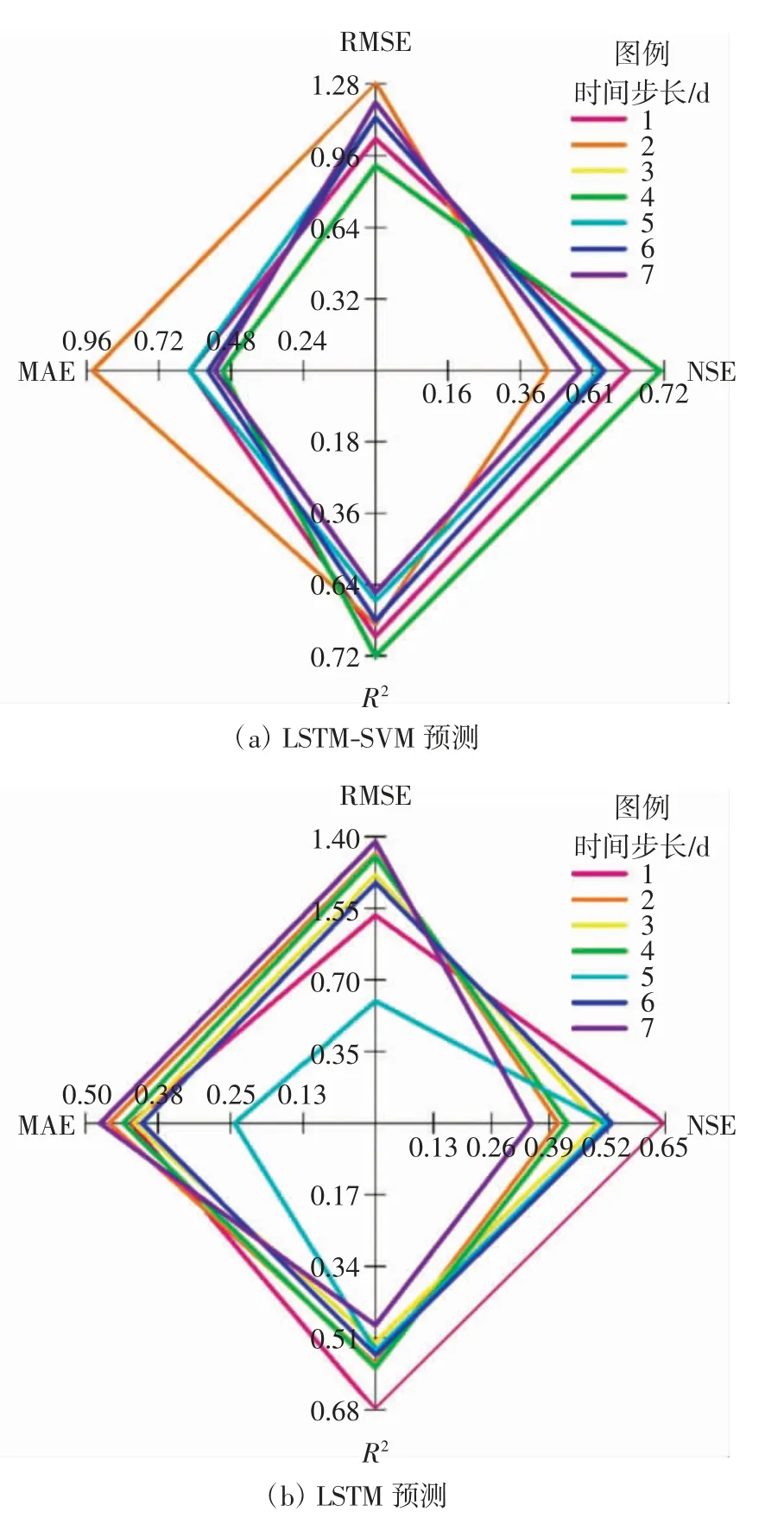
图6 预测期间模型在不同时间步长的各指标雷达图Fig.6 Radar chart of each indicator of the model at different time steps during the forecast period
由图6 可以看出,LSTM 和LSTM-SVM 混合模型的R2和NSE 值均有超过0.5 的情况,表明这2 种模型都取得了可接受的结果,可以成功应用于中长期逐日流量预测.混合模型在时间步长为4 d 时的RMSE 和MAE 最低,NSE 和R2最高,预测效果最好,在1~7 d预测期的总体性能呈现先上升后下降的趋势;LSTM模型在时间步长为1 d 时预测效果最好,在步长为7 d时的效果最差,在不同预测期的预测性能趋势不清晰.LSTM-SVM 模型在时间步长为4 d 时的R2和NSE 值均大于0.65,高于LSTM 模型.总体来看,2 种模型在不同时间步长下的预测结果中,时间步长为4 d 时的LSTM-SVM 模型预测性能表现最好,能准确地模拟出拒马河上游的河流流量.与LSTM 模型相比,LSTM-SVM模型预测性能更高,是模拟逐日低流量时间序列的有效方法.
2 种模型对拒马河上游的河流流量模拟结果如图7 所示.为了便于比较,图8 具体展示了预测期内连续30 d 的模型预测结果.

图7 LSTM-SVM 和LSTM 模型河流流量日模拟结果Fig.7 Daily simulation result of the river flow based on LSTM-SVM and LSTM

图8 预测期连续30 d 预测结果Fig.8 Results of testing period for 30 consecutive days
由图7 和图8 可以看出,2 种模型对低流量时间序列的预测效果良好,且能很好地捕捉到最高峰时段(2012 年)的河流流量,但对其他峰值的流量预测一般,总体预测效果较为理想.LSTM 模型在训练期预测效果好,在预测期的效果不佳(图7),多次高估了峰值的流量,原因可能是河流流量的峰值在中长期的时间序列上出现次数较少,模型对这一现象的捕捉程度较弱,模型在训练阶段的不稳定也可能导致预测期效果不佳.因此,在训练阶段对数据充分学习有利于提高模型预测结果的准确性.针对流域中长期径流预测存在高度非线性、复杂性等特征,LSTM-SVM 模型效果优于单独的LSTM 算法,原因可能是它不仅具备LSTM 学习长期依赖的技能,还具备支持向量机缩小结构误差、获得全局最优解的技能.
LSTM-SVM 和LSTM 模型在预测期中观测值与模拟值的散点图及残差图分别如图9 和图10 所示. 混合模型观测数据与预测数据之间的离散度相对较小,河流流量既没有被高估也没有被低估,残差值的范围更为合理,表明LSTM-SVM 模型在中长期的预测周期里比LSTM 模型更稳定,其模拟值与观测值之间的拟合程度更高且更具代表性.
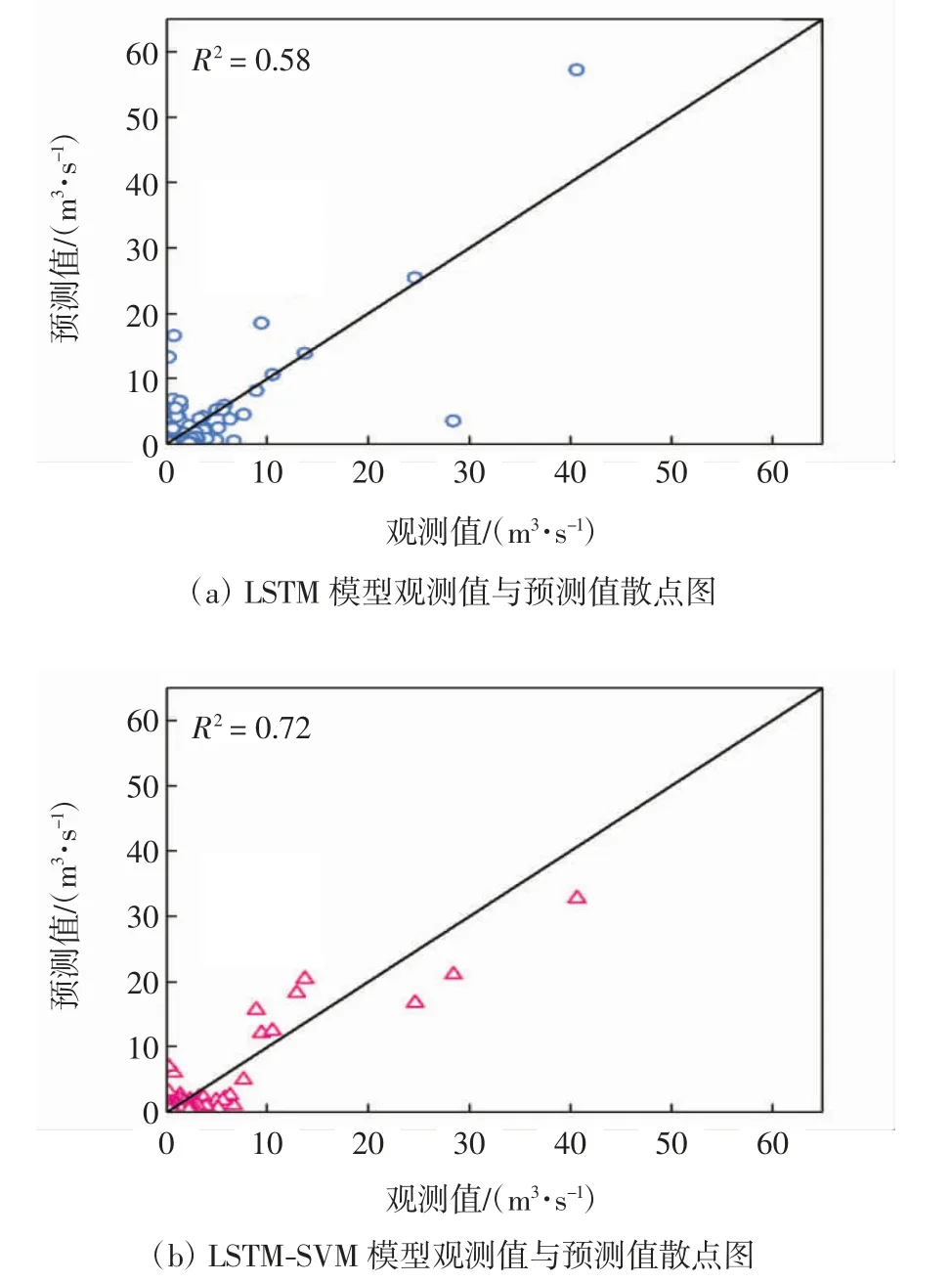
图9 预测期中观测值与模拟值散点图Fig.9 Scatter plots of observed and forecasted values during the testing period
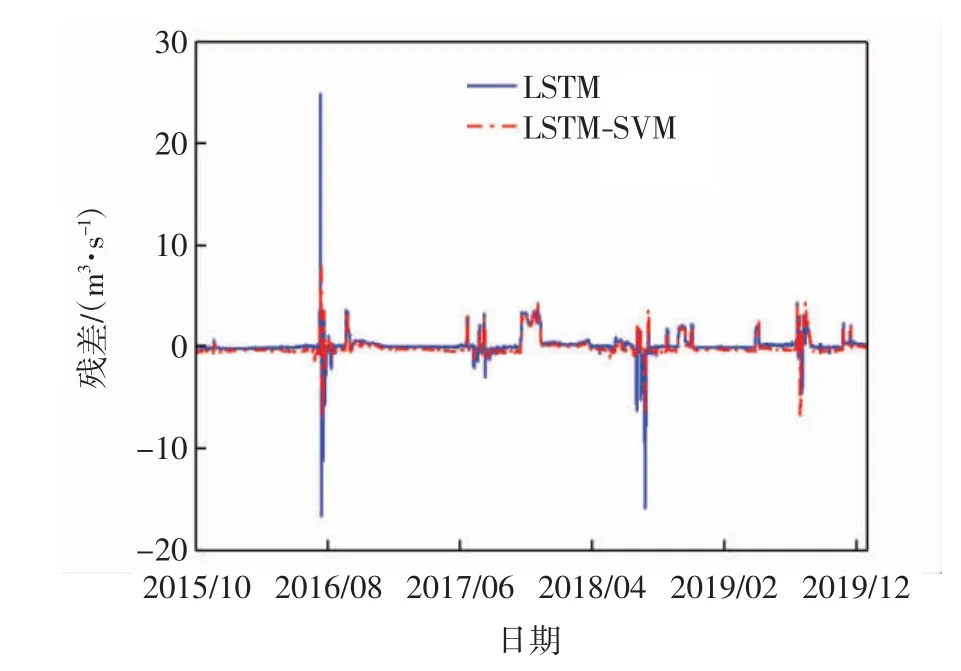
图10 预测期观测值与模拟值残差Fig.10 Residual of observed and simulated values during the testing period
4 总结
本研究基于紫荆关站逐日水文数据及气象数据,利用LSTM-SVM 混合模型和LSTM 模型对河流流量进行预测,评估并比较预测结果,探讨2 种模型对水文时间序列的适用性.主要结论如下:
(1)LSTM-SVM 和LSTM 模型都可以应用于河流流量预测.相同条件下,混合模型的R2和NSE 值普遍高于LSTM 模型,RMSE 值低于LSTM 模型. 因此,LSTM-SVM 模型比LSTM 模型预测精度更高.
(2)LSTM-SVM 和LSTM 模型在中长期河流流量预测中,对低流量的时间序列预测精度较高,对除最高峰外的其他峰值预测效果不高.与单独LSTM 模型相比,混合模型在峰值流量预测方面有显著优势,高估峰值的情况较少.
(3)对比2 个模型在预测期的散点图与残差图发现,LSTM-SVM 模型的预测值与观测值间的拟合程度更高且残差波动小,与LSTM 模型相比,LSTM-SVM 模型的预测前景更好.
以上结果表明,LSTM-SVM 混合模型对时间序列数据具有良好的非线性学习能力,在径流模拟中具有很大的应用潜力.但模型对峰值的预测效果不佳,预测精度还有待提高,在未来的研究中,应对模型的组合及参数选取进行深入研究,进一步提高模型的稳健性和适用性.
