基于蕴含情感要素用户正负偏好的电影推荐方法
2023-12-14张彬董雅倩徐建民
张彬,董雅倩,徐建民
(河北大学 网络空间安全与计算机学院,河北 保定 071000)
随着在线视频平台中电影资源数量的不断增长,信息过载问题日益严重,用户无法快速有效地获取其感兴趣的电影.为缓解这一问题,电影领域的个性化推荐应运而生[1-2].合理的电影推荐不仅可以更好地满足用户需求,提升用户体验,而且可以帮助视频平台增加对用户的吸引力,提升平台的竞争力.
现有电影推荐一般借鉴其他领域的推荐方法,通过分析用户的历史行为数据来挖掘用户偏好,向用户推荐与其偏好相似的项目.目前常用的推荐方法包括基于内容的推荐、协同过滤推荐和混合推荐[3-4].基于内容的推荐方法利用用户或项目的属性分析挖掘用户偏好,通过用户偏好与项目内容的相似计算实现推荐[5];协同过滤推荐利用用户与项目的交互数据发现相似用户,将相似用户喜欢的项目推荐给用户[6];混合推荐将多种推荐方法结合于同一推荐系统,用以提升推荐效果[7].有研究表明,用户对项目的倾向不仅有正面倾向,也有负面倾向[8],而且负面倾向同样会影响用户的抉择[9].然而,传统的推荐方法在挖掘用户偏好时并未关注用户偏好的方向性,即未区分用户的正向偏好和负向偏好,使得用户偏好表征不够全面.因此,有研究者在推荐研究中综合考虑用户对物品的正面倾向和负面倾向,从而提升推荐的准确性[10].
用户对电影的评分能够直观地反映用户对相关电影的喜爱程度,可以用来区分用户对电影的情感倾向,已有学者基于用户的评分数据挖掘其正向偏好和负向偏好.张宇等[11]利用SVM分类超平面计算用户对电影的喜好程度,然后根据喜好程度选出用户不喜欢的电影,并直接过滤.Walek等[12]在推荐过程中基于用户的评分数据发现其不喜欢的电影类型,并用来实现对推荐结果的筛选.丁来旭等[13]利用改进后的LINE算法和DeepWalk算法学习用户的喜好特征、厌恶特征以及相似用户特征,并将三者拼接来构建用户的偏好特征.Chen等[14]利用用户的评分数据挖掘其喜欢和不喜欢的2种电影列表,并用于表示用户偏好.Zeng等[15]提供了一个可以识别用户正面偏好和负面偏好的模型,来实现对用户偏好更准确的捕捉.上述研究通过分析用户的历史评分数据,获得用户对电影的正向偏好和负向偏好,并在电影推荐时加以利用,提升了推荐方法的有效性.
用户评论是其观看电影后发表的关于电影评价的非结构化数据,可以较为清楚、细致地表达用户对电影的情感,是用户对电影偏好程度的真实体现.通过分析用户评论数据的情感,可以更准确地挖掘用户的兴趣偏好[16].但现有考虑用户正负偏好的推荐方法在挖掘用户偏好时仅考虑了用户的评分数据,并未对用户评论数据中隐含的用户情感偏好信息进行分析,用户偏好表征仍不够完善.
本文提出了一种基于蕴含情感要素用户正负偏好的电影推荐方法(movie recommendation method based on the positive and negative preferences of users with emotional factors, MRM-PNE),该方法利用电影领域情感词典从用户的评论数据中挖掘其情感偏好信息并计算得到评论情感得分,结合目标用户的评分和评论情感得分计算其对电影的喜好度,从而获得目标用户的正、负向偏好电影集合,然后依据电影特征向量构建目标用户正、负向偏好特征向量,最终通过候选电影特征向量与目标用户正、负向偏好特征向量的综合相似度计算候选电影的最终评分,实现电影推荐.本文的主要贡献如下:
1)提出了一种考虑评论情感的用户正负偏好挖掘方法.该方法在挖掘目标用户正负偏好特征时,不仅利用了用户的评分数据,同时还结合了用户评论中隐藏的情感信息,更准确地表征了用户偏好特征.
2)提出了一种基于蕴含情感要素用户正负偏好的电影推荐方法MRM-PNE.该方法从更准确地表征用户偏好的角度出发,利用考虑了评论情感的用户正负偏好实现推荐,提升了推荐效果.
3)将豆瓣电影平台的真实数据作为实验数据集,设置了多组对比实验,从不同方面验证了本文方法的有效性.
1 考虑评论情感的用户正负偏好挖掘
分别基于目标用户喜欢和不喜欢的电影挖掘其正向偏好特征和负向偏好特征:首先采用基于情感词典的分析方法实现对用户评论情感的挖掘与量化,得到用户评论的情感得分;然后依据用户的评分和评论情感得分计算目标用户对电影的喜好度,并用于挖掘目标用户的正向、负向偏好电影集合;最后基于这2个集合构建目标用户的正、负向偏好特征向量,挖掘得到考虑评论情感的用户正负偏好.
1.1 评论情感的挖掘与量化
目前电影领域没有专用的情感词典可以供研究者使用,而用户在对电影评论时会采用一些具有本领域特色的情感词(如“最佳影片”、“演技派”、“出戏”等),现有的通用情感词典并不能很好地实现对用户评论的情感分析.因此,本文首先从电影评论中发现领域内特有情感词,并结合基础情感词典构建电影领域情感词典,进而计算评论文本的情感得分,实现评论情感的挖掘与量化.
1.1.1 电影领域情感词典构建
1)领域情感词发现
电影评论中通常包含电影名称、演员名等特殊词语,主流的jieba分词并不能很好地识别这些词语.首先需要将这些特殊词语扩展至jieba分词中,利用扩展后的jieba分词实现对评论文本的分词;然后根据分词结果从中抽取形容词、副词、动词和名词4类词[17]作为候选情感词,利用SO-PMI算法实现候选情感词的情感倾向的判别,并进行人工标注,发现领域情感词.本文发现的领域情感词共863个,包含褒义词653个,贬义词210个.表1展示了部分领域情感词.
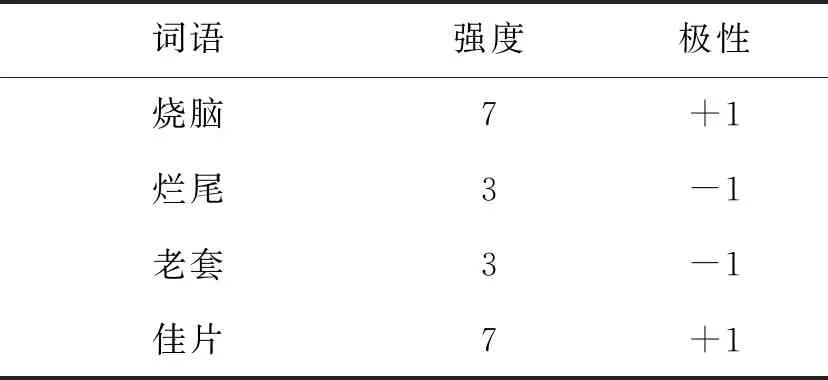
表1 部分领域情感词
2)基础情感词典
用户评论中除了能表明用户情感倾向的情感词外,还包括能改变用户情感强度与情感极性的程度副词与否定词.因此,本文将通用情感词典、程度副词词典以及否定词典作为基础情感词典.
通用情感词典:选用大连理工大学情感词汇本体库[18]构建通用情感词典.与HowNet[19]、NTUSD词典[20]仅仅标注了情感极性不同,该情感词汇本体库不仅标注了情感词的情感极性,还对情感强度进行了划分,且其中包含的情感词数量也相对较多,其基本格式如表2所示.

表2 情感词典本体库格式
程度副词词典:选用HowNet提供的程度副词构建程度副词词典,并为不同的程度词分配相应的权重,表示不同程度的情感,该类词语的存在会改变用户评论的情感强度.表3展示了部分程度副词.

表3 部分程度副词
否定词词典:选用HowNet提供的否定词构建否定词词典,并将其权值定为-1,电影评论的情感倾向会因否定词的存在发生改变.表4展示了部分否定词.

表4 部分否定词
1.1.2 评论情感得分计算
原始的电影评论数据一般由多个分句组成,且通常包含标点符号、代词等停用词,为后续的情感分析带来了一定的困难.因此,首先对评论数据进行分句处理,并去除每一分句中的停用词,并基于电影领域情感词典匹配获得评论中的情感词、程度副词和否定词等;然后计算每个分句的情感强度,并将每个分句的情感强度进行加和得到评论的情感得分.
对于用户的某条电影评论,其情感得分计算公式如式(1)所示.
(1)
其中,m表示评论C中的第m条分句;n表示分句m中的情感词数目;Wei(wj)表示情感词wj的情感强度;Adj(adv)表示出现在情感词wj附近的程度副词adv的权重;k表示出现在情感词wj附近的否定词数目.
1.2 正负偏好电影集合挖掘
有研究者将用户对未观看项目的预测评分作为伪评分来发现用户偏好[21-22],以缓解因用户历史数据稀疏而导致的用户偏好表征不准确的问题.因此,本文首先利用目标用户的评分和评论情感得分计算其对历史观看电影i的融合评分REu(i);然后基于融合评分计算目标用户对任意电影j的喜好度Ldeg(j);最后选取喜好度最高的K部电影构建目标用户的正向偏好电影集合(LMS),选取喜好度最低的K部电影构建目标用户的负向偏好电影集合DLMS.
1.2.1 融合评分计算
用户可通过评分或评论操作表达对电影的偏好,两者均体现了用户对电影的情感偏好程度,其中评分直观地表现了用户对电影的喜欢程度,评论则表达得更加细致.本文定义融合评分表示用户对历史观看电影的综合评价,计算公式如式(2)所示.
REu(i)=α×Rateu(i)+(1-α)×Emou,i(c),
(2)
其中,REu(i)表示用户u对其历史观看电影i的融合评分;α为融合系数,且0<α<1;Rateu(i)为用户u对电影i的评分;Emou,i(c)为用户u对电影i的评论c的情感得分,由公式(1)计算所得.
1.2.2 喜好度计算
喜好度表示用户对电影的喜好程度,利用用户对电影的融合评分计算得到.对于电影j,当目标用户u已观看时,用户u对电影j的融合评分即为用户对其的喜好度;当目标用户u未观看时,将利用融合评分预测得到的评分作为u对电影j的喜好度.
综上,用户u对电影j的喜好度Ldeg(j)的计算公式如式(3)所示.
(3)
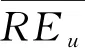
(4)
其中,M为用户u和用户v共同评价过的电影集合.
1.3 正负偏好特征向量构建
现有电影推荐方法通常利用用户历史观看电影的基本属性(如导演、演员等)构建用户偏好[23],然而,电影的评分与热门评论也是电影的重要属性,两者以不同的方式反映了电影的受认可程度,且同样能够影响用户的选择[24-25].因此,本文首先利用电影的评分和热门评论获得电影的认可度,然后结合电影的导演、编剧、演员(前2位)、类型和地区等基本属性信息[26]共同构建电影特征向量,最后利用用户的正、负向偏好电影集合构建正、负向偏好特征向量.
1.3.1 电影认可度
电影的评分和热门评论以不同的方式反映了电影被用户认可的程度,本文定义电影认可度对电影进行综合评价,如公式(5)所示.
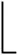
(5)
其中,Adeg(i)表示电影i的认可度;β表示融合系数,且0<β<1;MRate(i)表示电影i的评分;MCRate(i)表示电影i的热门评论得分.由公式(6)计算得到
(6)
其中,C表示电影i的热门评论集,n为热门评论集C的评论个数.
1.3.2 电影特征向量
电影的属性信息来源与结构存在较大差异,其中蕴含着丰富的知识关联,然而传统的向量表示方法只关注电影的属性值信息,忽略了属性之间的关联,存在一定的局限性.知识图谱表示方法在实现实体向量表示时,不仅可以保留实体和关系的内在信息,还能够将实体映射到低维向量空间,使用多维的连续数值向量有效地表示实体[27].因此,采用知识图谱对电影实体进行向量表示,可更加有效地表示电影特征,提升电影推荐的效果[28-29].
首先构建电影知识图MKG={E,R,S},图1展示了部分知识图,其中,E为节点类型集合,包括电影、
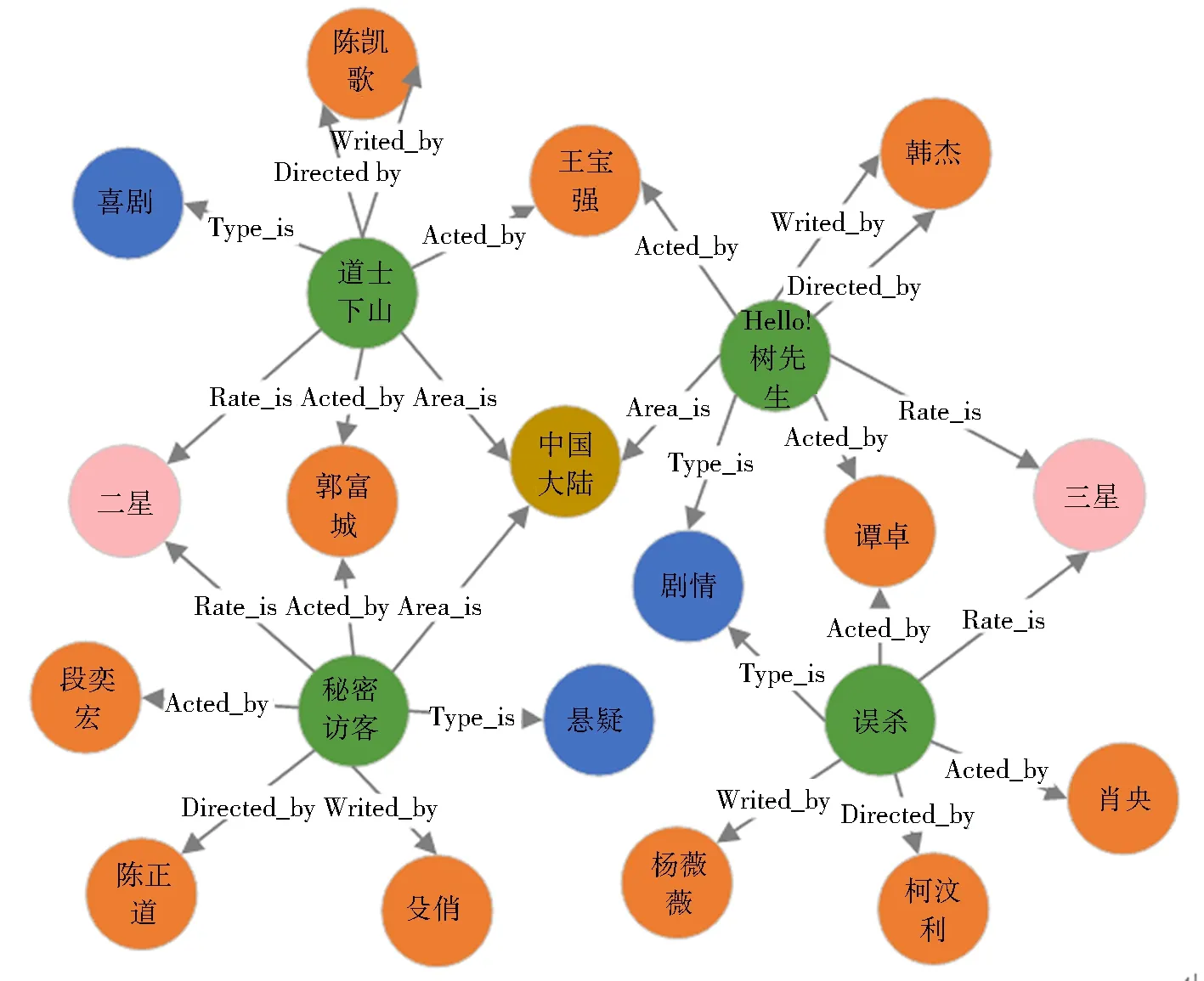
图1 电影知识图Fig.1 Movie knowledge graph
导演、编剧、演员(前2位)、类型、地区、认可度等7种节点类型,R为节点间关系类型集合.表5展示了所有的关系类型.S为由节点及其关系构成形如的三元组集合,如根据“电影《误杀》的导演为柯汶利,其认可度为三星”可得到三元组(误杀,Directed_by,柯汶利)和(误杀,Rate_is,三星).考虑到电影与属性间的关系多为一对一、一对多的关系,本文采用TransH算法[30]将电影知识图嵌入至低维向量空间,学习得到电影的特征向量VecM.
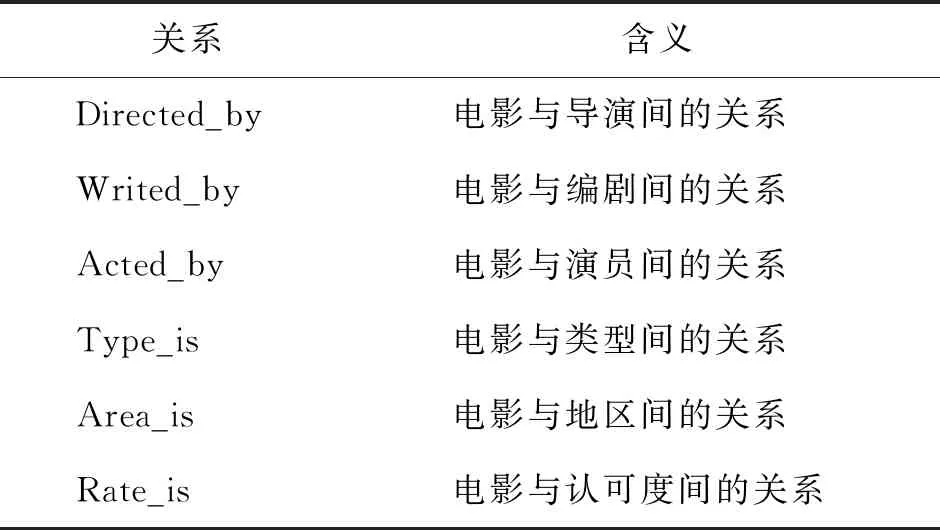
表5 关系类型
1.3.3 用户正负偏好特征向量
将目标用户u的正向偏好特征向量表示为其LMS集合中所有电影特征向量的平均向量;负向偏好特征向量表示为其集合中所有DLMS电影特征向量的平均向量.计算公式如式(7)和(8)所示.
(7)
(8)
其中,LVecu表示目标用户u的正向偏好特征向量;DLVecu表示目标用户u的负向偏好特征向量;K表示目标用户偏好集合的长度;VecMj为电影j的对应向量.
2 基于用户正负偏好的电影推荐
与传统电影推荐利用候选电影与用户正向偏好的相似度来实现推荐不同,本文利用候选电影与目标用户正、负向偏好的综合相似度来计算候选电影的最终评分,从而实现推荐.具体步骤如下:
步骤1计算候选电影i与目标用户u的正、负向偏好特征向量的综合相似度,如式(9)所示.
(9)
其中,VecMi表示候选电影的向量;L_Sim(VecMi,LVecu)表示目标用户u的正向偏好特征向量LVecu和候选电影i的相似度,即正向相似度,由式(10)计算得到;DL_Sim(VecMi,DLVecu)表示目标用户u的负向偏好特征向量DLVecu和候选电影i的相似度,即负向相似度,由式(11)计算得到.
(10)
(11)
(12)
其中,d(x,y)表示向量x与y的欧氏距离,k表示向量的第k维数值,l表示向量的维数.
步骤2规范化综合相似度值simu,i至区间[1,5]内,如式(13)所示.
(13)
其中,rateu,i表示规范化后的相似度,max表示所有综合相似度值中的最大值,min表示所有综合相似度值中的最小值.
步骤3计算目标用户u的评分偏差,如式(14)所示.
bu=Avg∀i(rateu,i)-Tu,
(14)
其中,bu为目标用户u的评分偏差,Tu表示目标用户u历史融合评分的平均值.
步骤4计算目标用户u对候选电影的最终评分,如式(15)所示.
Fratei=rateu,i-bu.
(15)
步骤5当候选电影i的Fratei大于等于评分阈值[14]时推荐给目标用户u.
3 实验
3.1 数据集
目前的主流数据集中不包含实验所需的用户评论数据与电影属性信息,本文从中国具有代表性的影视类评价网站(豆瓣电影平台)中采集电影数据集和用户历史影集,用户历史影集的采集时间范围为2020年08月01日至2021年07月31日.其中电影数据集包括6 829部电影的电影ID、电影名称、类型、导演、编剧、主演一、主演二、上映地区以及大众评价(即大众评分和前220条热门评论),每部电影的上映日期均在2021年07月31日之前;用户历史影集包括1 148个用户产生的共计72 546条评价数据(即评分、评论).将2020年08月01日至2021年04月30日的用户历史影集划分为训练集,2021年05月01日至2021年07月31日的用户历史影集划分为测试集.同时,为验证本文电影领域情感词典的有效性,将豆瓣电影平台中随机选用的1 000条用户评论数据作为语料集,并人工标注每条评论的情感倾向,得到正向评论数据607条,负向评论数据393条.
3.2 评价指标
3.2.1 情感词典评价指标
参考文献[31],将实际评论情感分类结果的正确率作为评价情感词典有效性的指标.正确率越大,表明分类结果越好;反之,表示分类结果越差.计算公式如(16)所示.
(16)
其中,RNum表示情感分类正确的评论数,ComNum表示评论总数.
3.2.2 推荐性能指标
为评价本文方法的推荐性能,采用准确率(precision)、召回率(recall)、F1值(F1)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)5个评价指标来检验模型的推荐效果.
假设推荐阈值为R,将真实评分不小于R且预测评分不小于R的电影数目表示为a,真实评分不小于R但预测评分小于R的电影数目表示为b,真实评分小于R但预测评分不小于R的电影数目表示为c.各评价指标计算方法如下所示:
1)准确率
准确率表示推荐列表中用户真正喜欢的电影所占的比重,计算公式如式(17)所示.
(17)
2)召回率
召回率表示推荐的电影占用户真正喜欢的电影的比重,计算公式如式(18)所示.
(18)
3)F1值
F1值是对准确率和召回率的综合评估,计算公式如式(19)所示.
(19)
4)平均绝对误差
MAE表示电影真实评分与预测评分之间绝对误差的平均值.真实评分与预测评分的误差越小,MAE越小,表示评分预测的更准确.计算公式如式(20)所示.
(20)
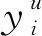
5)平均绝对百分比误差
MAPE用于表示电影真实评分与预测评分之间的相对误差,值越小,评分预测的越为准确.计算公式如式(21)所示.
(21)
3.3 实验结果及分析
3.3.1 电影领域情感词典有效性验证
本节将包括通用情感词典、否定词词典和程度副词词典在内的基础词典作为对比词典,分别比较使用电影领域情感词典与基础词典时情感分类结果的正确率Correct,实验结果如图2所示.

图2 情感分类结果Fig.2 Results of emotion classification
由图2可知,电影领域情感词典的正确率高于基础词典的正确率.原因是本文的电影领域情感词典中不仅包含基础词典,同时还包含了电影领域特有的情感词,对基础词典进行扩展后,可以更完整、准确地识别出电影评论中的情感词,从而更好地实现对电影评论的情感分析.
3.3.2 推荐方法有效性验证
为验证本文提出的推荐方法的有效性,参考文献[14]将推荐阈值R设置为4,当候选电影的最终评分大于等于4时向目标用户推荐该电影,否则不推荐该电影.同时将用户相似度阈值设置为0.9,当其他用户与目标用户的相似度超过0.9时,将其视为目标用户的相似用户.实验包含5部分:参数确定、评分融合的影响、电影认可度有效性分析、正负偏好有效性验证、与其他方法的对比实验.
1)参数确定
①融合参数α和β的确定 确定合适的融合参数α和β,以达到最好的推荐效果.对于用户融合评分的参数α与电影认可度的参数β,实验分别从0.1到0.9递增,以0.1为步长,对比不同参数组合下各推荐指标的最优结果,实验中前5组最优结果如表6所示.
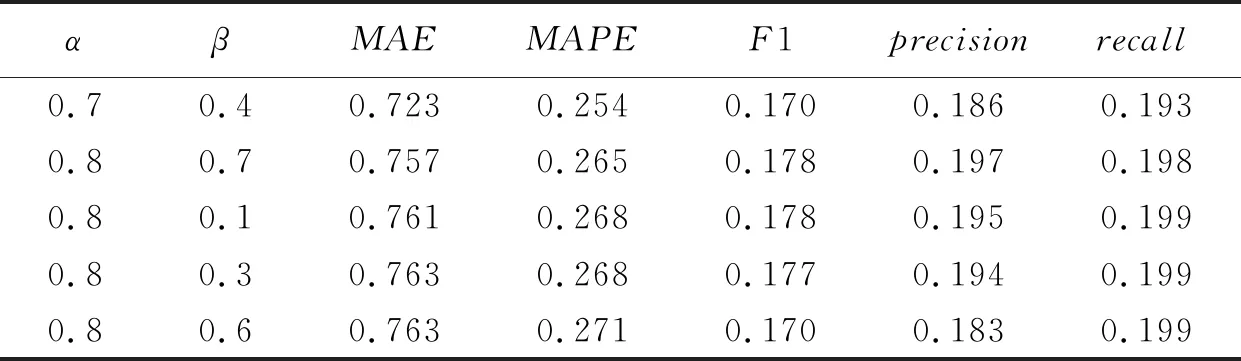
表6 最优结果
由表6可知,当参数组合为(0.7,0.4)时,MAE、MAPE指标最优,但其F1指标最差;当参数组合为(0.8,0.7)时,MAE、MAPE指标虽劣于参数组合,但优于其他参数组合,且F1指标要优于参数组合(0.7,0.4).因此,综合比较表中各指标的结果,选取α=0.8,β=0.7作为本文推荐方法的参数组合.
②K值的确定 集合长度K为用户正向、负向偏好电影集合的长度,不同的集合长度使得用户的偏好表征也不尽相同.表7展示了参数组合为(0.8,0.7)时F1、MAE、MAPE指标的5种最优结果.
表7 不同指标下的K值最优结果
由表7可知,针对不同的推荐目标可选择不同K值.如果想要获得更好的推荐效果及分类效果,K值的最佳取值范围为(1 550,1 850);若想要获得更准确的预测用户的评分,即更小的评分预测误差,K值的最佳取值范围为(1 400,1 600).
综上,为便于后续与其他实验进行对比,验证方法MRM-PNE的有效性,选取α=0.8,β=0.7,K=1 550作为最终的参数组合.
2)评分融合的影响
为验证挖掘用户正负偏好时考虑用户的评论情感能否更为准确地预测用户评分,降低评分预测的误差,参考文献[14]设置仅利用用户评分数据挖掘用户正、负偏好的推荐方法PN-UserRate作为对比实验.通过对比该方法与MRM-PNE方法在参数β=0.7和K=1 550下推荐性能,来验证融入评论情感的有效性,实验结果如图3所示.
由图3可知,MRM-PNE推荐方法相较于PN-UserRate方法MAE、MAPE指标性能提升明显,说明利用用户融合后的评分预测其对未观看电影的评分可有效降低评分预测的误差,即可更为准确地预测用户的真实评分.
3)电影认可度有效性分析
为验证构建电影特征向量时考虑电影的认可度是否在MRM-PNE方法中发挥作用,本文分别设置了利用电影基本属性与电影评分构建电影特征向量的推荐方法PN-MRate与仅利用电影基本属性构建电影特征特征向量的推荐方法PN-NoPublic作为对比实验,比较3种方法在α=0.8和K=1 550时各评价指标的结果,实验结果如图4所示.

图4 电影认可度的影响Fig.4 Influence of public emotion
通过分析图4中各项指标数据可知,MRM-PNE方法与PN-MRate方法在MAE、MAPE指标上均优于PN-NoPublic方法.综合3种指标结果,MRM-PNE推荐方法相较于其他2种方法推荐效果均有所提升,说明在构建电影特征向量时,考虑依据电影评分与热门评论获得的认可度能够更好的表示电影特征,提升推荐效果.
4)正、负偏好有效性验证
为验证同时考虑用户的正负偏好能否提升推荐效果,本文采用α=0.8,β=0.7和K=1 550的参数组合,设置仅利用用户正向偏好的推荐方法P和仅利用用户负向偏好的推荐方法N作为对比实验,比较P、N与MRM-PNE 3种推荐方法的实验结果,各指标的最优结果如图5所示.
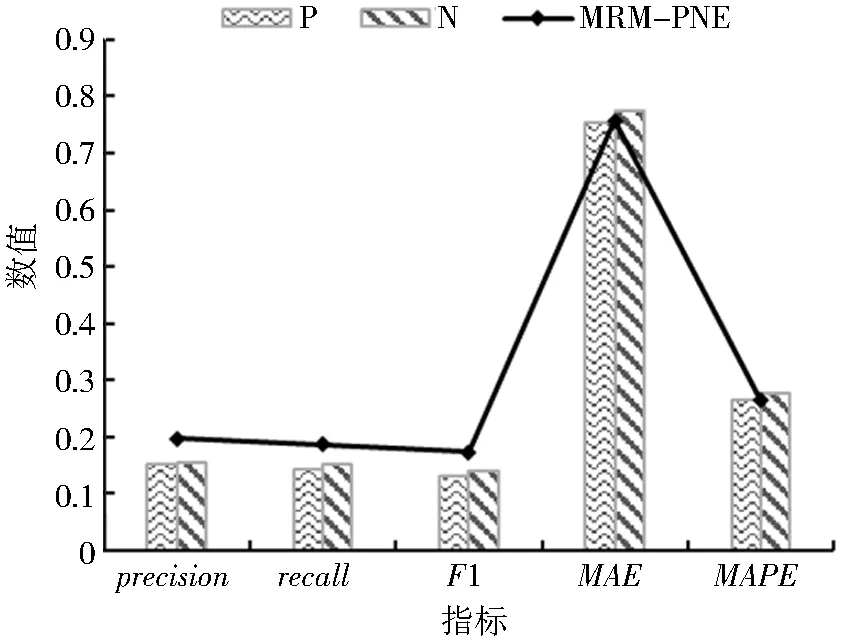
图5 P、N、MRM-PNE效果对比Fig.5 Comparison of effects of P,N and MRM-PNE
由图5的实验结果可知,同时考虑用户对电影正负偏好的MRM-PNE方法相较于其他2种仅考虑用户正向或负向偏好的推荐方法均有一定改善,提升了推荐效果.原因可能为MRM-PNE方法在计算候选电影与用户偏好的综合相似度时采用正向相似度除以负向相似度,这一操作使得MRM-PNE方法在推荐过程中过滤了用户可能不喜欢的电影,降低了错误预测电影评分的风险,使得获得的推荐列表顺序更加符合真实顺序.
5)与其他方法的对比实验
为验证本文提出的MRM-PNE方法相较于其他方法能否有效提升推荐性能,将经典的基于协同过滤、内容推荐方法以及现有的基于用户正负偏好的推荐方法进行复现,并与MRM-PNE方法进行对比.对比方法及简称如表8所示,实验结果如表9所示.

表8 不同的对比实验方法
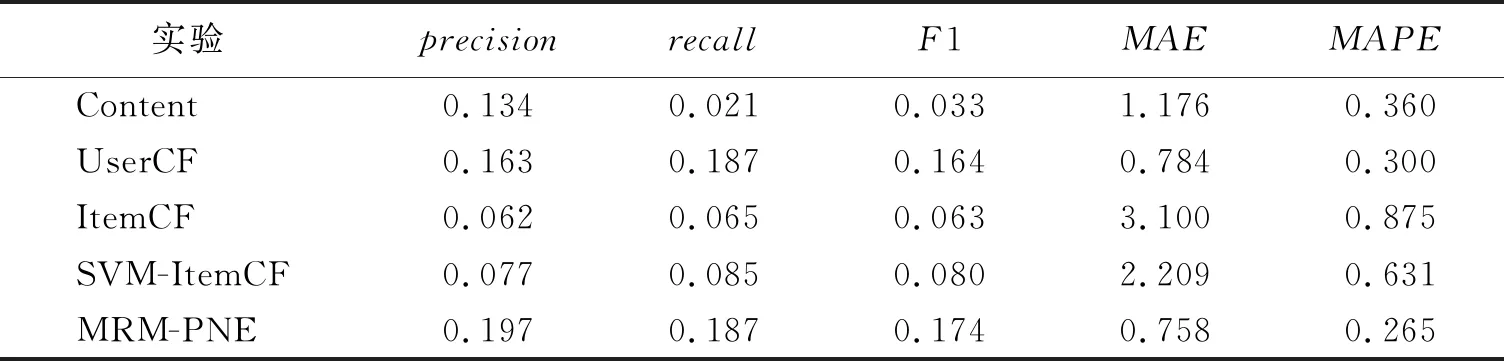
表9 对比实验结果
由表9可知,MRM-PNE模型相对于其他方法推荐效果有明显提升,其中相较于UserCF方法,F1指标最多提升6.10%,MAE指标最多提升3.32%,MAPE指标最多提升11.67%;相较于SVM-ItemCF方法,各项指标效果提升显著.
综合上述实验结果可知,本文推荐方法相对于传统推荐方法在各方面性能均有较大提升,同时,相较于仅利用用户评分挖掘用户正负偏好从而实现推荐的方法,本文方法能够降低评分预测误差,更为准确地预测用户评分,进一步验证了考虑评论中隐含的情感偏好信息来挖掘用户的正负偏好能够提升评分预测的准确性,可更准确地表征用户偏好,从而在推荐时降低评分预测的误差,获得更好的推荐效果.
4 结语
考虑到现有基于用户正负偏好的电影推荐方法在挖掘用户正负偏好时,并未对用户评论中隐含的情感信息进行分析,使得用户偏好表征仍不够准确,影响推荐效果,本文提出了一种基于蕴含情感要素用户正负偏好的电影推荐方法.在挖掘用户正负偏好时,利用用户的评分和评论情感信息计算用户对电影的喜好度,进而挖掘得到用户的正、负向偏好电影集合,然后结合蕴含了大众认可度的电影特征向量构建用户的正负偏好特征向量,获得了蕴含评论情感的用户正负偏好,使得用户偏好表征更加准确、全面;在实现电影推荐时,利用候选电影与用户的正向偏好和负向偏好的相似度计算得到最终评分,实现了将用户可能不感兴趣的电影过滤,提升了推荐效果.由于音乐、图书等商品均可被用户实施评分或评论操作,本文提出的推荐方法也适用于音乐、图书等商品推荐领域.在未来的工作中,将引入时间因素分析用户正、负偏好随时间变化的规律,从而获得更加准确的用户偏好,提升推荐方法的性能.
