融合预训练的港口吞吐量LSTM预测模型
2023-12-14张聪许浩然詹炜黄岚
张聪, 许浩然, 詹炜, 黄岚
(长江大学计算机科学学院, 荆州 434000)
随着国家对外经济的蓬勃发展,港口作为贸易的重要枢纽也在飞速建设与发展。港口吞吐量是衡量港口建设发展的重要指标,是指导港口作业部署的重要依据[1]。对港口吞吐量的准确预测有助于提前规划港口作业设施的工作任务,减少货物卸载与停留时间,提高港口使用效率,提升港口智能化程度。因此,如何精确预测港口吞吐量一直是学者们研究的热点问题[2-6]。
港口货物吞吐量变化具有一定的波动性和不规则性[7],易受政治、国际形势、腹地经济等外部客观不确定性因素以及港口地理位置等主观因素影响,导致算法预测港口吞吐量有一定挑战性。依据灰色系统理论可以处理不确定性问题的特点,黄跃华等[8]引进正弦和的灰度模型识别港口吞吐量周期震荡的特征,对上海港集装箱吞吐量进行预测。杜柏松等[9]提出用马尔科夫模型修正灰度模型计算结果的方法提升对时序特征的表示。王向前等[10]构建了多元自回归积分滑动平均模型(autoregressive integrated moving average model,ARIMA)结合支持向量回归(suport vector regression,SVR)的混合模型进行天津港的吞吐量预测。基于机器学习算法的港口吞吐量预测模型也从早期的支持向量机(support vector machines,SVM)[11-12]浅层模型逐渐发展为神经网络深层模型。陈端海[13]利用遗传算法优化BP(back propagation)模型参数提高了预测精度。李广儒等[14]采用AdaBoost集成学习算法改进Elman神经网络提升了宁波-舟山港吞吐量的预测精度。
长短时记忆神经网络(long short term memory,LSTM)[15]是循环神经网络(recurrent neural network,RNN)的典型代表,被广泛用于各种序列预测问题[16-17]。目前的研究大多将单个港口作为建模和预测对象,而单港口的数据总量小,且波动性大,导致深层神经网络模型如LSTM易出现过拟合,无法有效捕获港口吞吐量的快速变化情况,降低模型预测准确率。
针对上述问题,提出在LSTM模型中融入预训练技术,先用多港口的历史吞吐量数据对LSTM开展预训练,通过引入大量相关的、低成本的数据学习数据间的公共特征,以此为基础初始化LSTM模型,从而提升模型的泛化性。在中国15个大型港口近21年单月吞吐量数据上的对比实验结果显示,融入预训练能有效解决LSTM模型的过拟合问题,预测准确率明显高于传统的BP等4种基准时序预测模型。本文将预训练引入时序预测任务中,有效提升提高了时序模型的泛化性和精确度,为小数据时序预测任务提供了新思路。
1 港口吞吐量LSTM预测模型
1.1 LSTM神经网络模型
LSTM在传统RNN基础上隐含层改为了输入门、遗忘门、输出门等门结构,在序列传递过程中能有选择性地遗忘和保存信息,缓解了RNN训练过程中梯度消失的问题。
LSTM神经网络由多个LSTM神经元串联而成,单个神经元结构如图1所示,每个LSTM神经元的输入有:上一时间步LSTM单元传递来的上下文信息Ct-1、上一时间步输出Ht-1和当前时间步的输入Xt。输入信息通过遗忘门、输入门和输出门后,计算得到遗忘权重ft、输入权重it和输出权重ot,计算公式分别为
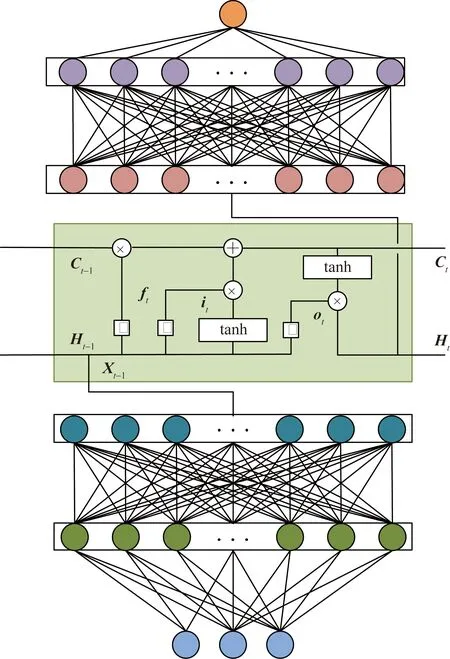
图1 LSTM吞吐量预测模型Fig.1 LSTM predict model for cargo throughput
ft=σ(Wf[Xt,Ht-1]+bi)
(1)
it=σ(Wi[Xt,Ht-1]+bi)
(2)
ot=σ(Wo[Xt,Ht-1]+bo)
(3)

(4)
式中:σ为sigmoid函数;Wf、Wi、Wo、Wc为不同门控机制的权重矩阵;bf、bi、bo、bc为不同门控机制的权重修正向量。
输入门有选择性地选择当前时间步候选上下文信息向量和遗忘门遗忘上一时间步上下文信息向量,将两者组合得到当前时间上下文信息向量Ct,再经tanh激活函数和输出门后得到当前LSTM单元的输出Ht,计算公式分别为
(5)
Ht=ottanh(Ct)
(6)
式(6)中:tanh为激活函数。
1.2 LSTM吞吐量预测模型
每个港口初始特征有:吞吐量、本月吞吐量增速和同比增速。本月吞吐量增速为本月增长量与上月吞吐量之比;同比增速为本月相较于去年同月的吞吐量增速。通过引入同比增速可以让模型获取吞吐量变化的周期信息。在数据输入LSTM模型之前,先用多层感知机(multilayer perceptron, MLP)模型对输入数据进行特征提取和转换,MLP模型的输出特征向量即为LSTM神经元的输入,再由LSTM学习港口上的时序特征,最后再经过MLP最终输出吞吐量预测值。
2 LSTM预测模型的过拟合情况分析及解决方案
2.1 实验数据
选取天津港、上海港、大连港、营口港等15个中大规模港口2001年1月—2021年12月每月的货物吞吐量为实验数据。所选港口的代表性强,时间跨度大,数据丰富,港口地理位置基本覆盖了中国的主要沿海地区。
数据集共包含252条记录,其中,18个月中部分港口的吞吐量数据存在缺失。在前人研究和前期实验基础上,采用式(7)填补缺失值,即以前两月的吞吐量均值乘以前两月吞吐量的增速,并考虑一定程度的衰减。
(7)
式(7)中:xt为港口当月吞吐量;xt-1、xt-2分别为前两个月的吞吐量;γ为上月的增速权值,实验中取值为0.85。
处理后各港口均有252条数据,取前204条记录作为训练集,后48条作为测试集。
2.2 模型训练与分析
LSTM预测模型的通用超参数及其取值如表1所示。在参数选择上,首先测试了网络结构大小对性能的影响,当3个隐藏层维度处于32~64时模型能取得最好性能,因此根据奥卡姆法则选择较小的结构,即维度为32。此时,模型共有23 952个参数,单个港口数据上训练单个周期平均用时0.09 s。学习率的初始值设置为0.01,并不断线性衰减至0.001,这样收敛速度快且所得到的损失值较低。在训练过程中最优值一般出现在100个周期内,因此将最大迭代周期设置为100。输入层和输出层均为两层MLP结构,激活函数为tanh函数,采用均方根差(root mean square error,RMSE)函数作为模型训练的损失函数。

表1 LSTM模型超参数Table 1 Hyper-parameter for LSTM
(8)
训练过程中损失函数取值变化如图2所示,其中蓝色实线与黄色虚线分别表示在训练集和测试集上的损失值变化。从中可以看出对于烟台港、青岛港、日照港、福州港和广州港[图2(a)~图2(e)]对应的5个港口,训练集上的损失值在不断下降,而测试集上的损失值却没有同步下降,说明LSTM模型在这些港口上出现了过拟合现象。
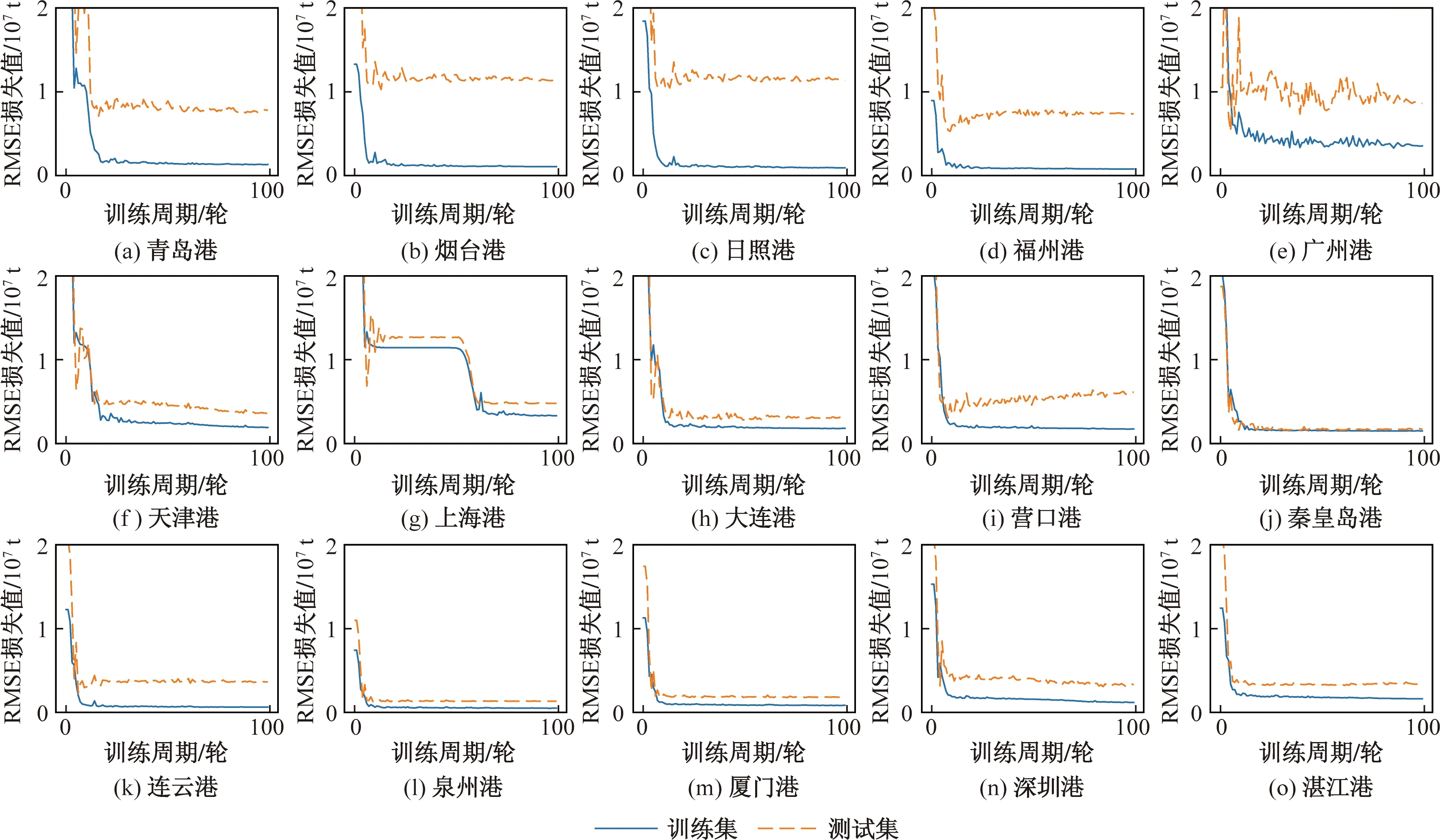
图2 港口训练损失值变化Fig.2 Changes in port training loss values
为探究基线LSTM模型在部分港口上出现过拟合现象的成因,图3依据是否出现过拟合现象对港口进行分类,并将其吞吐量数据进行了可视化,竖直虚线表示训练集与测试集的分隔线。图3(a)中港口吞吐量数据一直呈增长趋势,周期变化趋势不明显,图3(b)中港口则呈现出比较明显的周期性波动趋势。LSTM对时序波动规律的拟合能力很强,当测试数据中出现与训练数据差异较大的变化时,LSTM模型的预测性能降低,说明传统LSTM模型的泛化能力还有待提升。
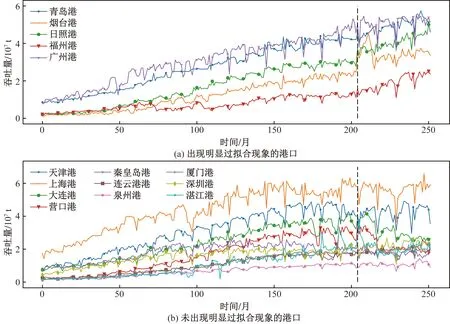
竖直虚线表示训练集与测试集的分隔线
深度学习模型由于结构复杂,需要训练的参数量庞大,导致其在规模较小的数据集上很容易出现过拟合现象,降低了模型的泛化能力。针对这一问题,提出在LSTM模型训练过程中融入预训练。预训练通过在大规模数据集上提前训练,从而更好地初始化模型参数,避免了过度拟合小数据集[18]。预训练技术兴起于自然语言处理,自然语言丰富的语义特征、广阔的语义空间,使得单个模型很难从单个自然语言数据集中得到充分的训练,因此,利用数据量庞大的通用语料库预训练语言模型,捕获广义数据集上的语义信息,已成为自然语言处理模型中不可缺少的一步和提升模型泛化性能的重要措施[19]。因此,提出将预训练引入港口吞吐量预测的LSTM模型(记为LSTMpre),以解决在部分港口上的过拟合问题,提升LSTM模型的整体泛化能力。预训练所使用的数据类型和结构与训练集相同,因此融入预训练的LSTMpre模型可以采用与基准LSTM模型(记为LSTMbase)同样的模型结构。LSTMpre先用所有港口的历史数据进行预训练,再以预训练所得模型作为单港口预测模型的初始值。
3 港口吞吐量预测实验与结果分析
3.1 实验设计
以BP、ARIMA、无预训练的LSTM模型、GNN-LSTM4种常用时序预测模型为比较基准,采用3种评价指标:相对预测残差分布、均方根误差(root mean squared error,RMSE)和平均绝对误差(mean absolute error,MAE)。相对残差分布是模型预测残差与真实值之比。RMSE常用于计算模型训练过程中的损失值,计算公式见式(8),易受异常值影响。平均绝对误差(mean absolute error,MAE)直观评估预测结果与真实值之间的平均误差,计算公式为
(9)
LSTMbase、LSTMpre和GNN-LSTM模型用PyTorch深度学习框架实现,BP、ARIMA模型采用MATLAB实现。LSTMpre模型的预训练阶段的学习率为0.001,批量大小为64,训练周期300个。
3.2 对比模型
BP模型是最经典的神经网络模型,又称为全连接网络,通过前向、反向传播来调整参数,从而拟合吞吐量变化曲线。选择3层BP网络模型,在模型维度上,隐藏层与LSTM一样选择32维。
ARIMA模型是一种基于数理统计的时序预测模型,有p、d、q参数,在每个港口上,先判断港口吞吐量是否是平稳数据,若不是则对数据进行差分直至数据平稳,参数d为数据差分次数。再用自相关函数(autocorrelation function,ACF)和偏自相关函数(partical autocorrelation coefficient,PACF)来确定模型的p、q参数。
GNN-LSTM是结合图神经网络(graph nerual network, GNN)的LSTM模型,近年来广泛应用于有空间位置信息的时序预测问题,参考文献[20]中实现的GNN-LSTM模型来进行港口吞吐量的预测。
3.3 结果对比与分析
图4对比了所有港口上的预测相对残差分布。4个模型除LSTMbase外,预测相对残差的中位数都在0附近,说明预测值比较贴近实际值。其中,LSTMpre模型的中位数最接近0,方差最小,表明其预测值的分布与真实值的分布最为贴近。ARIMA模型的分布最松散,说明模型鲁棒性有待提升。对比预训练后的LSTMpre和基础模型LSTMbase模型,LSTMpre提升明显,残差的上下四分位数与中位数的绝对值差异在10%以内,相对残差分布最紧凑,表示模型鲁棒性较好、预测可信度较高。
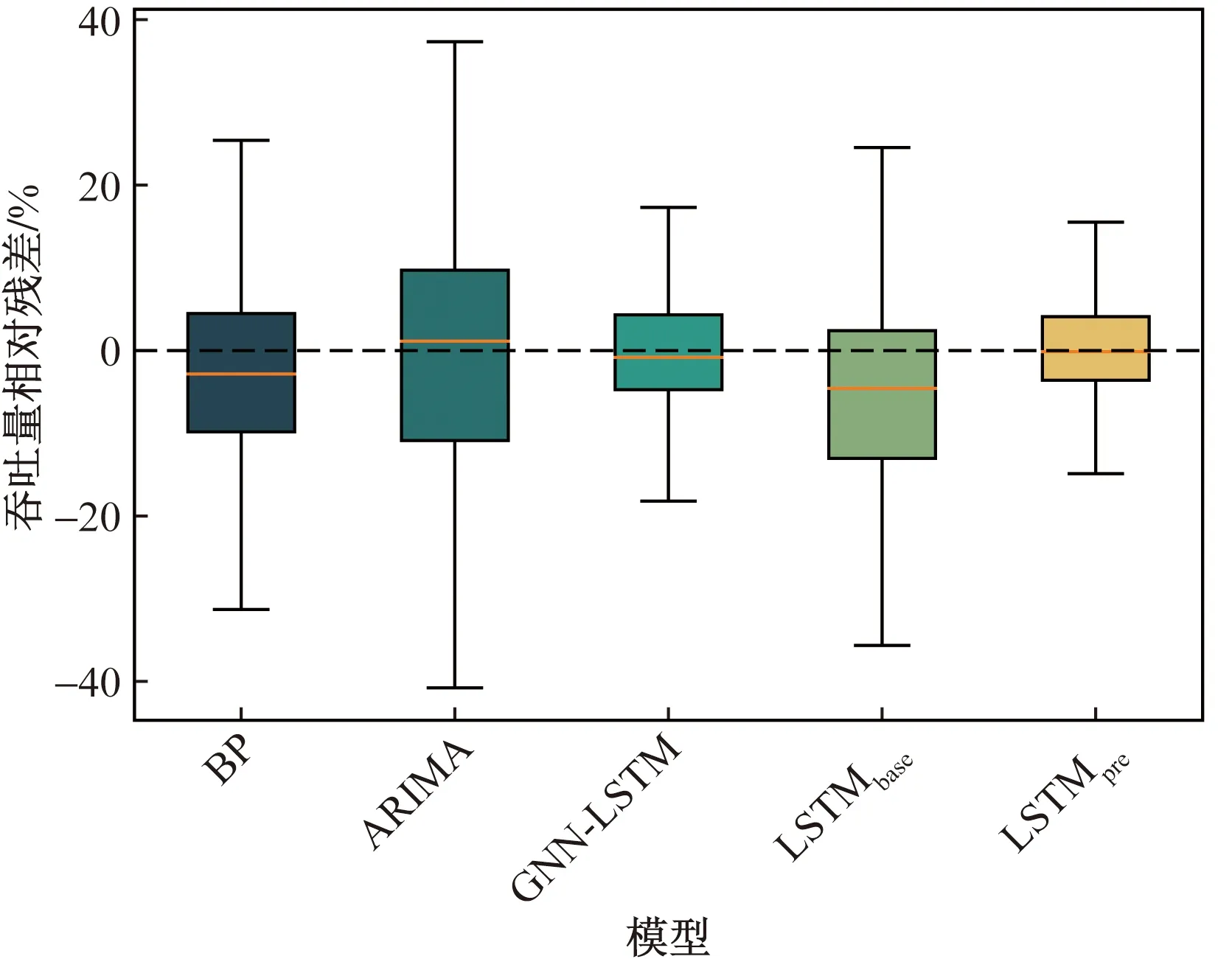
图4 各模型吞吐量相对残差对比Fig.4 Comparison of throughput relative residual among different models
BP、ARIMA、GNN-LSTM、LSTMbase和LSTMpre5个模型在所有港口上的RMSE值分别为:3.801、4.522、2.816、3.735和2.235。在平均RMSE指标上,所提出的LSTMpre模型相较于其他4个模型分别取得了41.2%、45.2%、20.6%和40.2%的降低,说明LSTMpre模型的有效性。
为深入分析5个模型在不同港口上的表现,表2列出了每个模型在每个港口上的预测精度。可以看出,与BP、ARIMA、GNN-LSTM、LSTMbase、模型相比,平均MAE指标值分别降低了42.0%、51.3%、13.7%和45.2%。为分析预训练的有效性,表2中最后一列给出了LSTMpre模型相较于LSTMbase的MAE值降低比率,加粗部分表示在该港口上LSTMpre预测结果要优于LSTMbase。可以看出,所提出的LSTMpre模型在绝大部分港口上的预测准确率更高,MAE损失最多降低80%,总体平均降低45.2%。
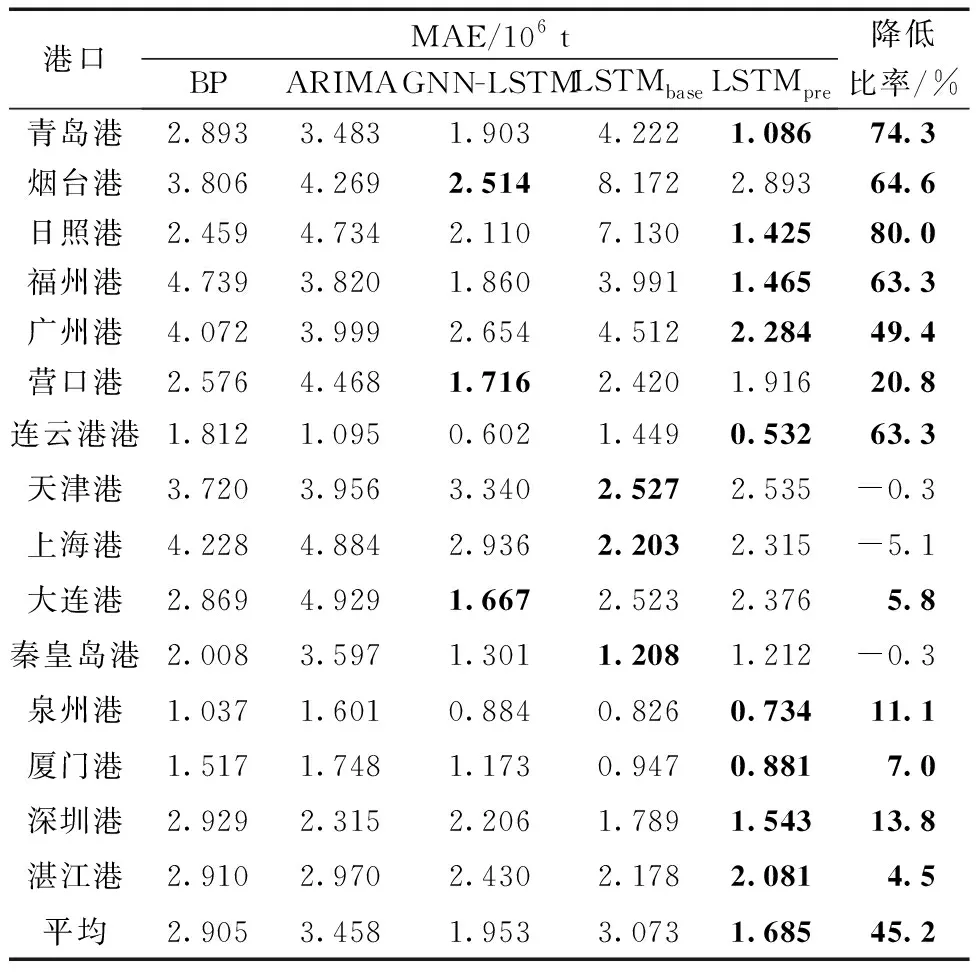
表2 各模型对不同港口吞吐量预测性能比较Table 2 Comparison of throughput prediction performance
在青岛港、烟台港、日照港、福州港、广州港、营口港、连云港港和大连港8个港口上,特别是在青岛港、烟台港、日照港、福州港和广州港5个出现过拟合港口上,GNN-LSTM模型的准确度要高于LSTMbase模型。这说明通过图模型来表示临近港口的吞吐量情况能从一定程度解决LSTMbase模型的过拟合问题。但在天津港、上海港、秦皇岛港、泉州港、厦门港、深圳港和湛江港7个港口上,图模型的有效性并不适用,GNN-LSTM模型的表现反而明显差于LSTMbase模型,说明这些港口的吞吐量变化并不受临近港口的影响。对比之下,所提出的LSTMpre模型在13个港口上均取得了显著优于LSTMbase模型的准确性。
4 结论
针对港口吞吐量预测任务,构建了LSTM模型,从实验角度验证了传统LSTM模型在数据量小、周期变化不明显数据上容易出现过拟合现象的问题。针对此类问题,借鉴自然语言处理领域发展,在LSTM模型中融入预训练阶段,先用多港口的信息预训练捕获全局信息,再用LSTM模型对单个港口精确建模。得出如下结论。
(1)基于预训练的LSTMpre模型,能有效解决单港口上数据特征不足导致的模型过拟合、预测准确度低的问题,在明显出现过拟合的青岛港、烟台港、日照港、福州港和广州港5个港口上的预测准确率平均提升66.3%,在所有港口上RMSE、MAE平均降低了40.2%、45.2%。相较于传统的BP、ARIMA模型以及目前流行的GNN-LSTM模型,所提出的模型在预测主要大型港口吞吐量任务上的平均RMSE值分别降低了41.2%、50.6%、20.6%;MAE分别降低42.0%、51.3%和13.7%。
(2)研究的主要不足之处在于:①由于小港口数据量较小,只选取中国主要中大型港口作为代表;②港口的规模受地域经济、中外形势影响较大,除港口吞吐量数据之外,融入港口所在城市GDP、人均收入、经济指标等外源数据,应可进一步提升模型预测的准确率和鲁棒性。
(3)本文提出的LSTMpre港口吞吐量预测模型仍存在两个有待完善之处。首先,目前模型没有直接表示和利用年度周期性变化信息,而港口吞吐量具有明显的年度周期性特征。其次,融合图结构的模型展示出了一定的有效性,地理信息对吞吐量预测的潜在作用仍有待挖掘,如何更有效地融入图结构和图神经网络也是本文模型未来的主要改进方向。
