基于数据增强技术与CNN-BiLSTM-Attention的油田注水流量预测及效果
2023-12-14李艳辉王衍萌
李艳辉, 王衍萌
(1.东北石油大学环渤海能源研究院, 秦皇岛 066004; 2.东北石油大学电气信息工程学院, 大庆 163318)
在油田开采过程中,注水是一项被广泛采用的重要技术,一般通过向油层注水,有效补充地层能量,维持油层压力,从而提高采收率[1-2]。特别是在油田开发中后期,面临含水率上升、产量下降等问题,需要快速增加注水,以实现油田的稳定生产[3]。通过在不同产层分别注入适量的水,可以有效维持地层注水压力,提高油田可持续开发速度,保证原油产量,有效控制生产成本。精细化注水在石油工程中具有重要的应用价值,受到了中外工业界和学术界的广泛关注,因此如何确定精确的注水量成为了油田注水研究中亟待解决的难题[4]。为此,提出一种基于深度学习的注水流量预测方法。
在深度学习算法中,卷积神经网络(convolutional neural network,CNN)已被广泛应用于各种预测或分类问题[5]。循环神经网络(recurrent neural network, RNN)及长短期记忆网络(long short-term memory,LSTM)处理具有序列特征的数据非常有效,它们可以从数据中挖掘时序信息和语义信息,从而很好地处理非线性关系[6]。双向长短期记忆网络(bidirection long short-term memory,BiLSTM)由正向LSTM和反向LSTM组合而成,可以从序列的正、反两个方向拟合数据,以达到更高的预测精度[7]。同时,其扩展模型CNN-BiLSTM也广泛应用于各个领域,如视频压缩[8]、交通运输[9]和COVID-19诊断等[10]。
目前,许多基于CNN和LSTM融合的方法没有明确地关注每个特征的重要性,从而无法很好地捕捉到特征之间的关联性和影响程度。而注意力机制(attention mechanism,AM)可以动态地对不同特征赋予不同权重,使模型将重点放在那些在特定情境下更具信息价值的特征上,从而提高预测精度。因此,引入注意力机制可以弥补现有方法未考虑特征影响的不足,从而更有效地优化模型在处理时间序列数据时的性能[11]。
随着数据量的增长和计算性能的提高,深度学习被用在越来越多的领域。其在各种预测或分类问题上都取得了良好的效果,但需要大量的数据进行训练,如果训练的数据量不足,得到的结果就自然不准确。然而,在油田注水系统的实际运行中,往往难以获取足够的数据。因此,还应该考虑数据量较小的情况,这个问题可以通过人为增加数据量来解决[12]。
数据增强技术可以解决数据短缺的问题。林志鹏等[13]提出一种基于生成对抗网络(generative adversarial network,GAN)的数据增强技术,实现了宫颈细胞图像数据集的扩充,并取得了不错的效果。Mikojaajczyk等[14]提出了一种使用风格转移增强图像数据的方法,并将其与现有的增强技术(如旋转、裁剪和缩放)进行了比较。然而,数据增强技术较常见于二维视觉领域,在油田注水研究等一维时间序列数据上的应用较少[15]。现通过对现有数据应用抖动和缩放的技术来增加数据[16],提出一种引入数据增强的结合卷积神经网络、双向长短期记忆网络与注意力机制的油田注水流量预测方法。
首先,结合卷积神经网络加强长短期记忆网络对时空特征的学习,并结合注意力机制解决部分时刻数据的重要特征信息被忽略的问题;其次,采用双向长短期记忆网络,考虑了时间维度上历史数据的正、负方向,使其可以从前向和后向两个方向上拟合数据;最后,提出一种数据增强技术,通过抖动和缩放来增加一维时间序列的数据量,进而为解决实际工业场景中数据短缺问题提供参考依据。
1 CNN-BiLSTM-Attention油田注水流量预测模型构建
分层注水采油模型如图1所示,H1-H3表示不同地层,通过注水到不同地层中进行驱油,当岩石含水量达到一定程度时,在“水”“水油混合区”“油”内形成储层,随着注水量的增加,原油和注入的水被抽油机抽到地面。油田地层中含有多个具有不同渗透性的油藏,实际地层情况则更为复杂,因此精确的注水量是油田维持地层压力、保证水驱开发效果最基本的参数[17]。

H1、H2、H3表示不同地层,通过注水到不同地层中进行驱油,当岩石含水量达到一定程度时,在水、水油混合区、油内形成储层,随着注水量的增加,原油和注入的水被抽油机抽到地面
结合CNN,BiLSTM和Attention提出了一种新型组合油田注水流量预测模型框架CNN-BiLSTM-Attention,该模型主要由输入层、CNN层、BiLSTM层、Attention层、输出层构成,具体模型结构如图2所示。

图2 CNN-BiLSTM-Attention模型框架图Fig.2 CNN-BiLSTM-Attention model frame diagram
使用CNN-BiLSTM-Attention模型进行油田注水预测时,输入层负责将历史注水数据进行输入。油田注水流量在实际中会受到各种压力、温度与介质的密度等因素的叠加影响,但由于本次采集数据来源于同一油井,其温度等其他因素与注水流量之间的相关性较小,因此忽略不计。而油压与套压作为体现油井生产状况的重要指标,能够反映油井的井筒状况,进而反映地层能力保持状况和注采平衡关系。因此样本数据采集了影响注水流量的两种主要因素,即油压与套压。这里选取油压、套压两个变量作为模型的输入;CNN层用来提取历史油井特征;BiLSTM层分别通过前向和后向链式连接的多个LSTM单元进行训练和预测;Attention层将各油井特征赋予不同的权重,得到时间序列各项数据与预测值的相关性,使用softmax函数对注意力得分进行数值转换;dense层作为全连接神经网络层,用于维度变换,输出层对Attention层输出的数据进行输出计算,得到未来油田注水流量的预测值Y。
模型中每层工作原理描述如下。
(1)输入层。对长度为T的历史油田注水数据进行归一化,处理后的数据作为模型输入,表示为X=[x1,x2,…,xT]。
(2)CNN层。卷积神经网络主要由卷积层、池化层与全连接层组成。卷积层被视作CNN的核心,通过卷积窗口的滑动,依次进行内积操作,进而提取出输入数据的高层次特征。池化层对卷积层输出的向量进行降维处理,矩阵经过池化,网络中的参数随之减少,由此可降低计算复杂度,避免过拟合。全连接层通常在网络的最后,用于将提取到的特征进行整合,并将向量进行输出。CNN层计算过程如下。
C1=Relu(X⊗W1+b1)
(1)
P1=max(C1)+b2
(2)
Hc=Sigmoid(P1W2+b3)
(3)
式中:C1为卷积层输出;P1为池化层输出,卷积层的激活函数选择Relu,池化层选择最大池化方法,全连接层使用Sigmoid激活函数;Hc为经过全连接层后的最终输出结果;W1、W2为权重;b1、b2和b3为偏差;⊗为卷积运算。
(3)BiLSTM层。LSTM比RNN多了一个长期状态与3个门控单元,引入了遗忘门、输入门和输出门三道闸门,这3个门函数可以有效地解决RNN存在的梯度爆炸等问题,其中一个LSTM的结构如图3所示。
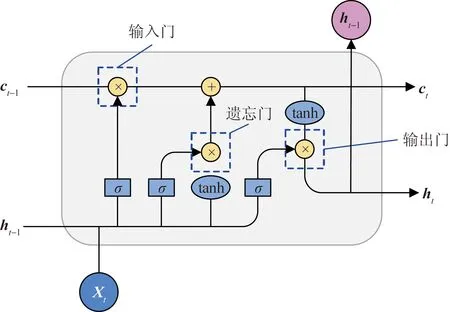
ht为当前时刻隐藏层输出信息;ht-1为上一时刻隐藏层输出信息;Xt为LSTM模型在t时刻的输入向量
遗忘门表示在上一时刻中有某些信息被选择性遗忘,输入门决定了某些新的信息可以交付至下一个状态中,输出门即确定从当前状态到下一个状态的输出。LSTM中不同细胞的方程为
it=σ(Wxixt+Whiht-1+bi)
(4)
ft=σ(Wxfxt+Whfht-1+bf)
(5)
ot=σ(Wxoxt+Whoht-1+bo)
(6)
(7)
(8)
ht=ot⊙tanh(ct)
(9)


图4 BiLSTM模型结构Fig.4 The structure of BiLSTM model
经过BiLSTM层后的输出ht可表示为
ht=BiLSTM(Hc,t-1,Hc,t),t∈[1,i]
(10)
式(10)中:Hc,t为CNN层在t时刻的输出。
(4)Attention层。注意力机制能够选择性地关注更为重要的信息,并分配不同时刻信息的重要性。因此,引入注意力机制后,LSTM可以在更长的时间序列中表现更好,避免无关信息对最终结果造成影响,从而对传统模型进行优化。Attention的计算过程如下。
et=tanh(Whht+bh)
(11)
(12)
(13)
式中:et为概率分布;Wh为Attention的权重;bh为Attention的偏差;v为注意力值;at为权重系数;st为Attention层在t时刻的输出。
(5)输出层。将Attention层t时刻的输出st作为输入,得到输出层在t时刻的输出yt,其表达式为
yt=sigmoid(wost+bo)
(14)
式(14)中:wo为权重。
所提出的预测模型结合CNN高效的特征提取能力与LSTM处理长时间序列的能力,同时引入的注意力机制通过赋予隐含层不同概率的权重,突出了重要信息对油田注水流量的影响。与传统模型相比,可以有效地解决之前存在的预测精度不佳、偏差较大等问题。
2 油田注水流量预测实例分析
为验证所提出的CNN-BiLSTM-Attention油田注水预测模型的可行性与优越性,选取中国某油田注水井2015年的历史注水数据(井深1 036.3 m,数据采集间隔为5 s)进行注水流量预测,样本数据共776组,选取其中80%的数据作为训练集,共计617条数据;另20%的数据作为测试集,共计154条数据。
2.1 数据归一化
为了消除不同量纲对预测结果产生的影响,防止梯度爆炸同时提高模型的计算精度,本文将使用的每个输入进行归一化处理,将数据归一化到0~1,计算公式为
(15)
式(15)中:x为变量的值;Max、Min分别为该类变量中的最大值与最小值;xnormal为归一化后的值。
2.2 数据增强
采用抖动与缩放两种数据增强技术进行对比实验,抖动是将一种添加随机值的技术,通过在原始数据的5%范围内添加噪声来创建新数据。缩放是一种将数据乘以随机标量值的技术,通过将其调整到原数据的10%范围内来创建新数据。目的是通过引入加性与乘性噪声,并且增加训练的数据量,进而有效提升模型的鲁棒性和泛化能力。将采集到的样本进行归一化操作后的数据如图5(a)所示,将归一化后的数据再通过抖动和缩放新创建的数据分别如图5(b)、图5(c)所示。

图5 原数据与通过数据增强创建的新数据Fig.5 Raw data and new data created through data augmentation
2.3 模型评估
以平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error, RMSE)、平均绝对百分误差(mean absolute percentage error,MAPE)和决定系数(coefficient of determination,R2)4个衡量尺度来评价本研究提出的预测模型的性能,运算过程如下。
(16)
(17)
(18)
(19)

MAE与RMSE用于衡量真实值与预测值的偏离的绝对大小,MAPE用于衡量偏离的相对大小,以上3个指标主要用于评估预测值的准确程度,R2主要用于衡量模型的拟合程度,值越接近1则认为模型质量越好。
2.4 模型参数设置
通过预实验获得模型参数,滑动窗口大小设为3,lstm_units参数即LSTM神经网络中包含的隐藏神经元个数设为64;卷积层中卷积核个数设为64个,卷积核大小为3*3,采用sigmoid函数激活;BiLSTM层中分别将两层输出维度设为32与64,激活函数为tanh,return_sequences设为True,用于返回整个序列;Attention维度设为128,激活函数采用sigmoid;以Adam算法作为优化器,batch_size代表模型训练中进行梯度下降的每个batch使用的样本数,这里设为10;epochs代表训练的总轮数;patience参数设为5,即训练中如果出现5次没有进步的轮数,在这之后就会停止训练;以RMSE作为损失函数。
确定了上述参数后,将卷积步长参数n′在[1,5]区间内分别取值进行调参实验,根据n′的不同取值,预测实验结果如表1所示。根据调参结果,卷积步长n′在取值为3时MAE与RMSE结果最优,分别为0.027与0.043。

表1 不同卷积步长调参结果Table 1 Different convolution steps tuning results
3 模型的预测性能验证
为验证所提出的CNN-BiLSTM-Attention油田注水流量预测模型的精度,分别训练了LSTM、CNN-LSTM、CNN-BiLSTM与CNN-BiLSTM-Attention 4种模型来进行仿真实验,得到的模型损失函数变化曲线如图6所示。

损失函数(Loss)用于定义单个训练样本与真实值之间的误差;Train Loss表示训练集的损失值;Test Loss表示测试集的损失值
所提出的预测模型的损失函数快速下降并趋于稳定,模型均得到较好的收敛效果,表明可较好地应用于油田注水流量的预测中。
采用四种方法对测试集进行预测并与真实值进行对比,结果如图7所示。通过实际值和预测值的比较,所提CNN-BiLSTM-Attention方法能够很好地实现预测结果与实际值的拟合,可以更准确地计算和预测注水量。

图7 4个模型的预测值和实际值的比较Fig.7 Prediction values of four models and actual values
4种模型的性能评价指标值如表2所示,结果表明,LSTM模型预测精度最低,其MAE、RMSE和MAPE值在4种模型中均为最高,分别为0.077、0.049和31.28,R2仅为0.797。相较于基础的LSTM模型,通过CNN对历史油井数据进行特征提取后的组合模型CNN-LSTM预测性能有所提高,其MAE、RMSE和MAPE分别下降了50.64%、16.32%和21.22%,R2提高了16.72%,表明经过特征提取过程可以有效地提高预测的精度。

表2 不同模型预测结果对比Table 2 Comparison of prediction results of different models
而相较于CNN-LSTM模型,CNN-BiLSTM模型预测效果也具有显著提升。这是由于双向运算的BiLSTM网络提取的时序特征包含时序数据的前后信息,提取的时序特征更加丰富、完整,模型性能更优。
所提出的CNN-BiLSTM-Attention预测方法,其MAE、RMSE和MAPE值分别为0.027、0.043和9.936,R2高达0.968,预测效果是4种模型中最好的。利用Attention对BiLSTM隐藏层产生的特征分配不同权重,使网络可以更有效地进行训练,解决了部分时刻数据的重要特征信息被忽略的问题,从而有效提高模型预测精度,表明其在油田注水预测中有较好的适用性,验证了所述方法的在油田注水预测应用方面的优越性,对于实际油田注水工程的实施具有重要意义。
CNN-BiLSTM-Attention模型在原数据与经过数据增强创造的新数据上运行10次的平均结果如图8所示,经对比可知,模型在经过缩放技术之后创造的新数据集上表现最好。由此可证明,通过数据增强技术引入加性与乘性噪声,并且增加训练的数据量,可以有效提升模型的鲁棒性和泛化能力。

图8 模型在原数据与新数据上的结果对比Fig.8 Comparison of model results on raw data and new data
4 结论
针对中国油田普遍存在的“注采失衡”的现象,为达到精细化分层注水的要求,将深度学习方法应用于油田精细化注水开发的实际工程中,提出一种基于数据增强技术与CNN-BiLSTM-Attention的油田注水流量预测方法,得出如下主要结论。
(1)对几种预测方法进行了对比实验,相比现有的单一预测模型如LSTM等,所提出的CNN-BiLSTM-Attention模型具有较高的预测精度,从而为油田精细化分层注水开发提供理论依据。
(2)将视觉领域常用的数据增强技术在一维时间序列数据上进行了应用。研究证实,采用数据增强技术可以有效提高模型的预测精度,进而为解决工业场景中数据短缺问题提供理论依据。
随着油田开采难度的增加,挖掘影响油田注采的主要因素,构建高精度的注水流量预测模型将作为未来重点研究方向。在未来的研究中,将对油田精细化分层注水技术的工业实际应用进行更细致的研究,并有望将数据增强技术应用于实际工业场景中的其他领域。
