化工污水处理大数据技术应用研究
2023-12-13段碧清
段碧清
(中化环境控股有限公司,北京 100071)
如今,全球掀起了以数字化转型升级为首要任务的新一轮工业变革,工业大数据作为引领这场变革的主要驱动力,已经成为当今工业领域的热点之一。新一代信息技术与工业的深度融合将促进工业领域的服务转型和产品升级,重塑全球制造业的产业格局。为紧紧抓住这一重大历史机遇,抢占新一轮竞争制高点,国家高度重视并作出长期性、战略性部署,要求“加快发展先进制造业,推动互联网、大数据、人工智能和实体经济深度融合”。工业大数据是工业领域的核心要素,以大数据工业互联网为基础,用云计算、大数据、物联网、人工智能等技术引领工业生产方式的变革,拉动工业经济的创新发展。工业大数据分析技术作为工业大数据的核心技术之一,可使工业大数据产品具备海量数据的挖掘能力、多源数据的集成能力、多类型知识的建模能力、多业务场景的分析能力、多领域知识的发掘能力等,对驱动企业业务创新和转型升级具有重大作用。
1 水务大数据平台建设的必要性
1.1 水务企业面临的挑战
结合水务行业自身的需求和特点,发现水务企业存在的主要问题和面临的挑战如下:①信息系统多且太分散,维护成本高;②数据标准不统一,无法实现统一共享,对数据的整合集成及互联互通造成了阻碍,增加了信息整合的复杂度;③数据质量存在不可靠问题;④数据来源复杂,终端多而分散,导致数据采集及存储安全存在问题;⑤数据众多,数据分析处理能力有限,无法有效进行更深层次的数据挖掘、利用和辅助决策支持。
1.2 水务大数据平台的建设目标和意义
水务大数据平台建设时通过应用新ⅠT 技术,融合水行业需求,把“数字化” 应用于公司治理与环境治理服务中,创造新型的管理与服务模式。在数据的价值创造与价值传递过程中,将价值链的更多环节转化为战略优势,实现技术、物质、资金、人才、服务等资源的优化配置,进一步提升管理精细化、为民服务精准化和水务企业管理现代化水平,数据驱动创新,将大数据技术能力转化为企业发展的新动力[1]。
2 大数据技术发展概述
数据是新时代重要的生产要素,是国家基础性战略资源。大数据是数据的集合,以容量大、类型多、速度快、精度准、价值高为主要特征,是推动经济转型发展的新动力,是提升政府治理能力的新途径,是重塑国家竞争优势的新机遇。“十四五” 时期是中国工业经济向数字经济迈进的关键时期,对大数据产业发展提出了新的要求,产业将步入集成创新、快速发展、深度应用、结构优化的新阶段。随着互联网、社交网络等信息通信技术的发展,描述和记录人类社会空间、信息空间和网络空间的数据快速增长,数据规模也越来越庞大。大数据的数据源包括网络&社交媒体、智能设备生成的数据(由硬软件自动生成的数据,无人干扰,如电脑、医疗设备等)、感知数据(几种传感装置用于测量物理量并将它转换成信号)、事务数据(涉及描述数据的时间维度的事件,如财务和工作数据)和物联网数据(大量通过网络连接的设备提供多种类型服务的同时,会产生大量的数据和信息)[2]。数据的形式包括结构化数据、半结构化数据和非结构化数据。而在大数据领域,目前采集到的数据85%以上为非结构化和半结构化数据,只有少量的结构化数据[3]。
大数据分析是运用云计算、机器学习算法等方法对大数据进行分析,从中找出可以帮助决策的隐藏模式和未知的相互关系及其他有用的信息过程[4]。此外,传统的数据显示方法也已不足以满足当前大数据分析结果输出的需求,因此为提升数据解释、展示能力,数据可视化也逐渐被引入了大数据领域。
综上所述,大数据具有数据量大、处理速度快及数据种类多样等特点,但尚无统一的定义。大数据理论强调以问题为导向,寻找事物之间的相关性。大数据的处理思路包括数据采集、数据处理与关联、数据分析、数据应用:通过相应采集技术对数据进行收集;运用人工智能方法对采集到的数据进行 “去噪” 及清洗处理,得到可靠的数据;运用云计算技术和机器学习等方法对数据进行分析,得到数据模型;将得到的数据模型发布后传递给用户,以帮助用户制定决策。
3 污水处理大数据分析过程
化工污水处理企业承担着中国化工园区上游企业化工污水处理任务,是化工污水排入生态环境的最后一道屏障,承担着保护生态环境的重要责任。利用大数据技术对化工污水处理企业日运行数据及历史数据进行分析建模,形成药剂、出水COD(化学需氧量)预测模型,从而预测和判断目前进出水流量、主要污染物指标与药剂添加量或电量能耗的关系,利用数据模型可以对水厂运营及药剂投加提供指导建议,达到卓越运营降本增效的目标。
3.1 大数据机器学习分析方法
机器学习是从数据中学习规律的过程,是从一系列原始数据中提取人们可以识别的特征,然后学习这些特征,通过不断迭代、优化,最终产生一个模型,使用这个模型可以实现机器代替人进行复杂问题的分析及决策。机器学习建模的方法,大致可以分为分析目标确立、数据处理与特征工程、模型建立及迭代、模型评估、模型应用。
3.2 机器学习建模过程
首先通过物联网传感器导出企业日运行数据,对数据格式、字段类型、数据完整性进行初步校验,然后以每月为单元对数据进行统计合并,形成以天为维度的统计分析数据。目前运营数据字段主要包括进水量、处理量、进水COD、进水SS(悬浮物)、进水氨氮、出水COD 等运营数据字段,详见表1。

表1 主要污染物指标表
目前运营数据字段26 个,本次实验以这部分数据作为基础数据进行测试。通过对原始数据的分析,并参考污水处理运行的一般规律对各个字段关联性、相关性进行分析字段的选择。进水数据与出水数据及加药量、活性炭、电耗等消耗数据必然存在一定关联,具备数据分析的基本逻辑,可以进行数据分析算法模拟,这些数据可以作为数据分析选定字段属性参与到数据建模中。本次实验将运用系统每日运营上报数据特征进行人工数据模拟,然后根据模拟数据进行模型训练、测试及验证,通过结合实际的数据分析对场景的理解,设想日常进水数据指标与出水数据指标存在数据关联,并对目前没有收集到的属性根据经验进行模拟评价,制作样本数据,利用已知的结果进行模型训练。评价方法是将历史项目数据与实际运营经验相互结合制订,随着数据的不断积累,属性字段需要不断进行优化调整。
3.2.1 构建预测模型
通过大数据平台,进行数据加载、预处理、模型算子、模型应用、性能评估,主要流程如下:原始数据导入→ⅠnceptorSQL 特征工程→Sophon 可视化建模→Sophon 输出学习模型→测试数据输入之前模型→最终结果。
3.2.2 数据建模
3.2.2.1 创建实验
数据准备与导入通过数据集对污水运营数据进行导入。新建一个实验项目,在实验中加载进化工污水企业运营数据作为本次实验的数据源,进行模型训练。化工污水企业运营数据是根据现有运营时间不断增加,目前有3 组数据,分别是1—4 月、1—5 月、1—6 月3 组不同数据,根据不同数据进行模型训练,不断增加数据量,提升模型准确性。
3.2.2.2 数据处理
对数据添加字符串索引、数据类型转换算子,为数据添加设置角色算子,然后对样本数据进行7∶3 切分,分为训练样本和测试样本,具体流程如图1所示。
图1 数据处理流程图
3.2.2.3 算法选择
利用人工智能算法预测药剂添加量与进水COD、出水量COD、处理量、其他污染物指标、能耗等多个特征之间的关联关系,通过对历史数据的学习,预测出特定条件下药剂的添加量。对于机器学习而言,可以分为分类、聚类、回归等分析方法,对本次实验预测类型进行评估,分别选择逻辑回归、XGBoost 回归、梯度提升回归、随机森林回归算法进行尝试,对计算结果与实际运营数据进行对比,然后进行模型预测准确度性能评估。首先选择随机森林回归算法进行计算,随机森林是以决策树为基础的一种更高级的算法,是目前机器学习分类问题中应用最广泛的算法之一。随机森林是用随机方式构建的一个森林,而这个森林是由很多的相互不关联的决策树组成。本质上属于机器学习的一个分支称为集成学习,集成学习通过建立几个模型组合来解决单一预测问题,它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测,这些预测最后结合成单预测,因此优于任何一个单分类作出预测,随机森林可以用于分类、回归,每个决策树都有一个自己的结果,选择投票数最多的结果作为其最终结果。比如要判断一个项目能否成功,会根据项目数据的特征生成很多个决策树,每个决策树都是独立的,然后让每个决策树对一个项目能否成功进行决策,最后把所有决策树的投票结果进行统计,得票最多的就作为该项目的最终计算结果,这个就是随机森林的基本算法原理。实验是想通过水质输入数据、处理完成输出数据,分析预测出添加PAC 药剂的量,所以将进水、出水的特征数据作为输入因子,添加药剂量作为输出因子,可以利用回归算法拟合一个函数,预测加药量与输入量(进水、出水等输入数据)之间的关系。通过XGBoost 回归算法、随机森林回归对化工污水数据进行分析,分析预测结果如表2、表3 所示。

表2 XGBoost 回归算法模型结果

表3 随机森林回归模型结果
3.2.2.4 性能评估
通过模型算法尝试,然后利用性能回归对模型进行性能评估,XGBoost 回归算法及随机森林回归算法模型误差对比如表4 所示。

表4 误差对比表
3.2.3 模型输出
训练好的模型,通过打包进行模型输出,用于发布APⅠ(应用程序编程接口),通过其他程序进行调用。
3.2.4 模型应用
使用测试数据、利用PAC 加药预测模型,将模拟的数据作为输入数据,将1—8 月的数据作为模型训练数据,通过学习与训练1—8 月数据,可以预测将来需要添加的药剂量,模型预测结果如图2 所示。将模拟数据作为输入数据,可以预测出某种特定条件下PAC药剂的投加量,基本达到了实验预期效果。
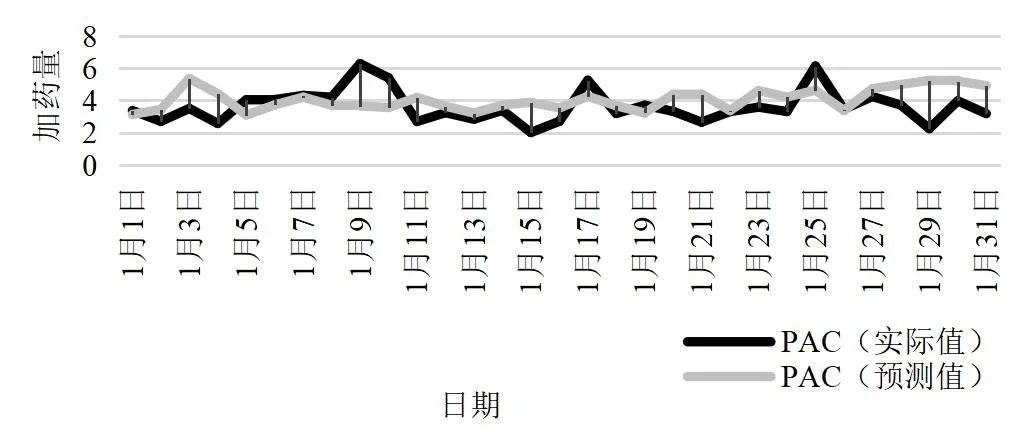
图2 模拟预测PAC 投加量计算结果
4 结论
通过从化工污水处理企业日常运营过程中获取原始数据,然后对原始数据进行加工处理,并结合实际业务应用场景的可能性进行数据特征选择,设计数据分析场景。由于目前数据还不够完整,数据量还不够丰富,在日常污水处理的可检测性、实时性等方面还存在很多不足及欠缺,所以本次实验人为模拟了部分数据。利用大数据机器学习平台,对数据进行分析处理、训练模型、模型测试,最后得到能够预测加药量的最终模型,使用最终训练后模型能够预测在特定工厂运行的前提下需要增加的药剂量。通过本次研究,验证了化工污水运营数据利用现有的大数据、人工智能、机器学习等工具进行处理和分析的可行性,但是目前运营数据积累还比较少,数据获取途径还比较单一,数据结构比较简单,数据量还不够大,可供测试的样本用例有限,未来伴随着企业数据收集手段、方法的不断更新,运营类型数据不断丰富,可分析场景会不断增加,耗电、耗水及出水指标、环保指标等都可以作为分析预测的对象。通过本次实验,对环保大数据分析方法、场景进行了有益的尝试,获得了较好的预测效果,但与实际业务运营的要求还是存在一定的距离,还需要在实际运营中不断优化完善。
