基于WT-SLSTM 模型的交通流预测研究
2023-12-07席一丹白惠君周晓渊韩峰宇
张 瑞,席一丹,白惠君,周晓渊,韩峰宇
(太原工业学院,山西太原 030008)
0 引言
交通事故是一种严重的公共安全问题,对人民生命财产安全和社会稳定造成了巨大的影响。在当前交通管理的实践中,交通流预测是实现交通管控和优化交通系统运行的关键技术之一。交通流是指一定时间内通过道路或交通网络的车辆数量、速度和密度等交通参数的总体表现。通过对交通流进行预测,可以为路线规划、交通管理等方面提供决策支持。
自20世纪开始,部分国家开始投入大量精力对交通管控技术进行研究,于是,交通流预测的各种模型也就应运而生。目前,常用的预测模型主要包括传统统计学模型、机器学习模型、深度学习模型。传统统计学模型应用于交通流时间较早,包括时间序列模型(Time-Series Model)、卡尔曼滤波模型(Kalman Filtering Model)等。徐翠翠等人[1]使用ARIMA 模型进行城市交叉路口交通流预测建模,该模型能够准确地预测早高峰和晚高峰时段的交通流。为了提高交通流预测的准确性,杨紫煜等人[2]提出了一种新的方法,根据卡尔曼滤波理论,利用重构后的相位作为卡尔曼滤波的初始值进行预测。然而,由于统计学模型依赖于先验知识设定模型的参数,其算法结构相对简单,不能够深入挖掘交通流的深层次特征信息。与此相比,机器学习模型在处理非线性、非平稳序列方面具有优势。何祖杰等人[3]提出了一种基于IGWO-SVM 的短期交通流预测模型,通过与实际数据进行对比分析,结果表明该模型具有良好的预测能力。
深度学习是现在研究的焦点,自2010年以来热度增长迅速。深度学习模型应用于许多领域,包括空气污染预测[4]、股票市场预测[5]、物理[6]等。循环神经网络模型(Recurrent Neural Network,简称RNN)[7]在序列预测任务中取得了显著的成绩。Hochreater 和Schmidhuber[8]提出了长短期记忆(Long Short term Memory,简称LSTM)神经网络来解决RNN 的梯度爆炸和梯度消失问题。李雪梅等人[9]使用基于双向长短期记忆网络(Bi-direction Long Short Term Memory,简称Bi-LSTM)的预测模型利用雨天和非雨天、工作日和非工作日影响因子分别对交通流进行预测,并与LSTM 进行比较,结果表明Bi-LSTM 的预测效果较好。滕腾等人[10]采用堆叠式长短期记忆网络(Stack Long Short Term Memory Network,简称SLSTM)模型对长期状态进行处理。在SLSTM 模型中,存在多个隐藏LSTM 层,每层包含多个LSTM 单元,上层的LSTM 结构输出一个隐藏状态序列,输入到下一层结构中,可以更好地捕捉信息。李楷等人[11]提出了一种SLSTM 神经网络来对交通流进行短期预测,结果表明所提出方法优于常用的机器学习和经典的LSTM 方法。
然而,交通流的预测受到许多因素的影响。Niam Archana 等人[12]通过利用过去和当前的交通和天气信息捕捉交通和降雨数据之间的时空相关性,得出降雨对道路交通流预测具有影响。Attallah Mustafa 等人[13]提出了一种实时高分辨率天气雷达数据与交通流数据融合的预测模型,通过与无天气雷达数据模型对比,得出天气因素对交通流预测有较大影响。由于交通流的复杂性和不确定性,预测模型存在着预测精度不高和预测滞后等问题,因此需要寻求更加高效和精确的交通流预测方法,学者们对此问题展开了广泛的研究。刘兵等人[14]采用物联网与大数据相结合的模型,提高了预测精度,减小了预测滞后。陆百川等人[15]分析了交通流的时空特征和数据特征,建立了空间邻接矩阵;其次,通过时空相关性函数量化不同时间延迟对交通的影响,并结合神经网络构建了交通流预测模型,使预测结果更加精准。
尽管交通流预测已经取得了一定的成果,但其预测精度和预测滞后等问题仍然需要提高和改进。为了解决这些问题,本文提出了WT-SLSTM(Wavelet Transform and Stacked Long Short Term Memory)模型。具体而言,首先,采用小波变换将最初的短时交通流分解成在各个尺度空间和小波空间上的时间序列信号;接着,将各个时间序列信号传递到SLSTM 神经网络模型中,在调整学习率、滞后时间和批量大小等参数的基础上进行预测;最后,将各信号的预测值进行小波重组,得到最终预测值。为了证明WT-SLSTM 模型的优越性,本文对北京市出租车车流量数据进行了预处理,并使用预处理后的数据进行训练和预测;从常用评价指标和折线图两个方面对预测性能进行了比较。试验结果表明,WT-SLSTM 模型优于基准模型,极大地提高了交通流预测的精度。
1 模型说明
1.1 SLSTM 模型
LSTM 神经网络模型是RNN 的一种重要变体,由Hochreater 和Schmidhuber 于1997年首次提出。相比于传统的RNN 模型,LSTM 神经网络模型引入了输入门f(t),遗忘门i(t)和输出门o(t),以实现更好的信息处理和传递能力。在神经网络的训练过程中,通过门结构增添和遗忘信息,不同的神经网络可以通过其单元状态上的门结构来选择性地记住或遗忘哪些信息。f(t)、i(t)、o(t)分别对t时刻时上一单元的隐藏状态ht-1和当前输入xt进行初步特征提取。LSTM 模型单元运算包括以下几个步骤:首先,在遗忘门中输入信息并激活函数来选择要丢弃的信息,公式如式(1):
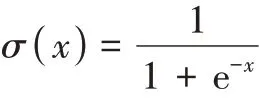
然后,输入门i(t)决定哪个状态要更新,将该状态与tanh激活函数所生成的向量c'(t)相加,计算公式如式(2)~式(4):
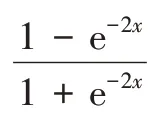
最后,输出门产生最终输出,计算公式如式(5)、式(6):
式中:Wf、Wt、Wo、Wc表示遗忘门、输入门、输出门和记忆单元的权重系数矩阵;bf、bt、bo、bc表示遗忘门、输入门、输出门和记忆单元的偏置条件。
1.2 SLSTM 模型
在2015年,Dyer 等学者[16]提出了SLSTM 模型,该模型是LSTM 模型的改进形式,由多个LSTM 层和一个Softmax 函数组成。由于单一的LSTM 神经网络在提取时间序列数据方面的能力有限,所以通常将多个LSTM单元组合起来进行训练以提高模型的精度。随着层数的增加,输入观察时间的抽象级别也增加。此外,多个LSTM 单元的输入值和输出值之间仅有一些微小的区别,在本质上仍然是一致的。相比于传统的LSTM,SLSTM 不仅考虑当前时刻的输入值,还考虑了上一时刻的输入值。因此,SLSTM 模型的隐藏层更加深入,比LSTM 内部的记忆单元更有助于预测。其3 层时序结构如图1所示。
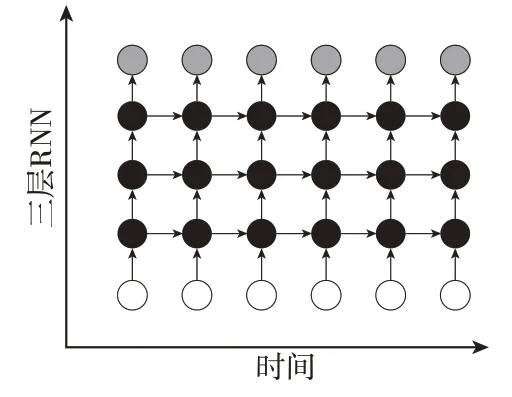
图1 3层LSTM 时序结构
1.3 小波变换
小波变换是一种基于多尺度分析的信号处理方法,其基本思想是通过取样频率和多分辨率分析确定原信号的近似空间Vj,以便更好地反映原信号的各种信息。通过对原信号进行分解,得到近似部分Ca1和细节部分Cd1。然后可选取近似部分或细节部分继续分解。小波变换的原理图如图2所示。如果需要对原信号进行数据压缩,则可以舍弃值比较小的Cdj-1分量,这不会明显改变原信号的特征,但可以大大提高数据压缩的效果。当Cdj-1分量被修改完成后,需要重构算法重新组装被过滤或压缩的信号。

图2 小波变换原理图
1.4 WT-SLSTM 模型
本文提出了一种新颖的混合WT-SLSTM 模型,用于预测短时交通流。该模型结合了数据分解手段和SLSTM 神经网络,可以分为3 个主要部分:数据分解、子信号预测和小波重组。图3 展示了整体预测框架。

图3 WT-SLSTM 模型流程图
首先,为了降低原始交通流数据的复杂度,同时提高预测精度,采用小波分解方法将原始交通流数据分解成k个子信号。接下来,每个子信号对应于一个通道,并利用SLSTM 神经网络分别预测各个子信号。在此过程中,调整SLSTM 神经网络的参数,并选择最佳拟合模型。最后,每个子信号的预测值被重构以实现最终的短时交通流预测。具体而言,每个子信号输出一个m维向量,采用小波重组获得最终交通流预测值。
1.5 模型预测性能度量指标
为了更准确地评估模型的预测能力和验证方法的有效性,本文采用平均绝对误差(Mean Absolute Error,记作MAE)、均方根误差(Root Mean Square Error,记作RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,记作MAPE)和相关系数(Coefficient of determination R squared,记作R2)作为预测性能指标。每个评估指标的计算公式如式(7)~式(10):
2 实证分析
2.1 数据预处理
本文采用北京市出租车轨迹数据,时间跨度为一周。数据采样时间间隔为100 s,选取东经116.4°至116.408°,北纬39.9°至39.906°的区域。为了确保数据的可预测性,夜间车流量几乎为零的时间段已被剔除。最终整理出该区域周一至周四每天从第10 000 s 至76 400 s 所对应的车流量数据,如图4所示。

图4 时间-车流量折线图
鉴于车流量数据在不同时段有不同数量级,为消除对预测结果的影响,将其进行标准化,公式如式(11)所示:
式中:mean(x)是样本均值;std(x)是样本标准差。
2.2 模型分析
经过预处理后,将车流量数据按照10∶1 的比例划分为训练集和测试集。首先,将训练集输入到SLSTM模型中,隐藏层状态变量的维度为128,学习率为0.001,迭代次数为200 次,使用PMSprop 优化器进行训练。预测结果与测试集数据进行比较,采用MAE、RMSE、MAPE、R2作为指标对模型进行综合评估。预测结果表明,MAE、RMSE和MAPE的值分别为2.44、3.02 和19.87,R2的值为0.12,拟合效果较差。
为了解决单个SLSTM 模型预测效果差的问题,引入小波变换,以此优化SLSTM 模型。于是,基于深度学习TensorFlow 框架,建立WT-SLSTM 神经网络模型。首先,对数据进行小波分解。将训练集分解为近似部分Ca1和细节部分Cd1,再将Ca1分解为近似部分Ca2和细节部分Cd2,继而将Ca2分解为近似部分Ca3和细节部分Cd3。分解结果如图5所示。接着,分别将Ca3,Cd1,Cd2和Cd3分别输入SLSTM 神经网络模型进行训练和预测。模型输入为各个小波分量,输出层为各分量预测值,滞后时间为4,时间步长为1,学习率为0.001,迭代次数为200 次,使用PMSprop 优化器进行训练。最后,将各小波分量预测值进行小波重组,并进行反标准化,从而得到出租车车流量的最终预测值。
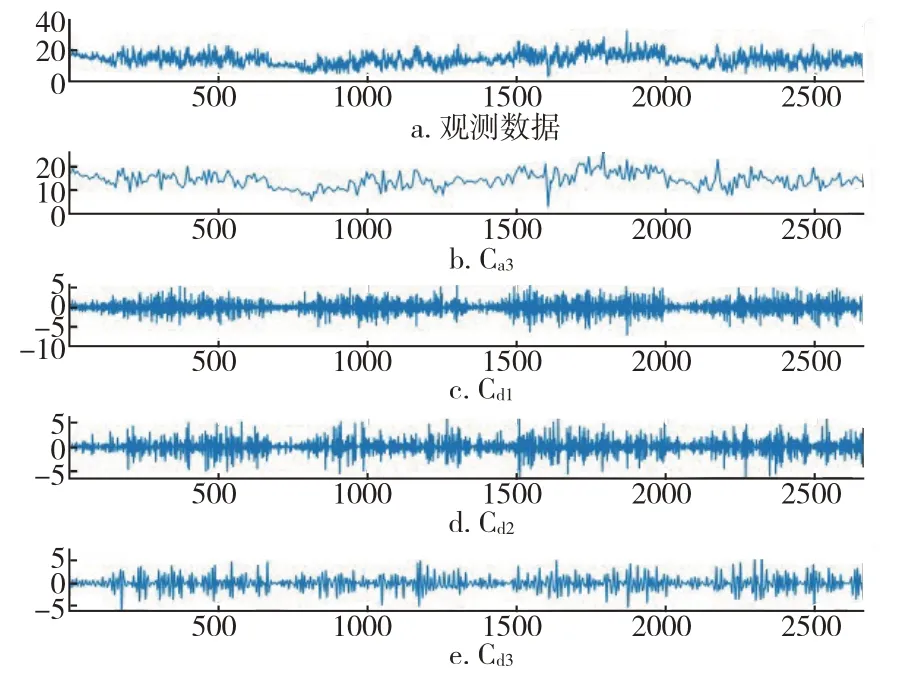
图5 小波变换预测结果
预测过程结束后,将预测结果和测试集数据进行比较,选取MAE、RMSE、MAPE、R2为度量指标来综合评估预测结果。为了验证WT-SLSTM 模型的有效性,将其与基准模型进行对比,包括决策树(DT)、随机森林(RF)、LSTM、SLSTM 模型。评估结果如表1所示。总体上,深度学习模型(LSTM、SLSTM、WT-SLSTM)优于机器学习模型(DT,RF)。在深度学习模型中,加入了小波变换后预测效果得到了显著提升。WT-SLSTM 模型与SLSTM 模型相比,MAE、RMSE、MAPE分别减小了49.18%,49.66%,9.47%,R2提升了6.41 倍;与LSTM 模型相比,MAE、RMSE、MAPE分别减小了50.59%,50.48%,10.18%,R2提升了8.55 倍。因此,WT-SLSTM 模型拟合效果优于基准模型。
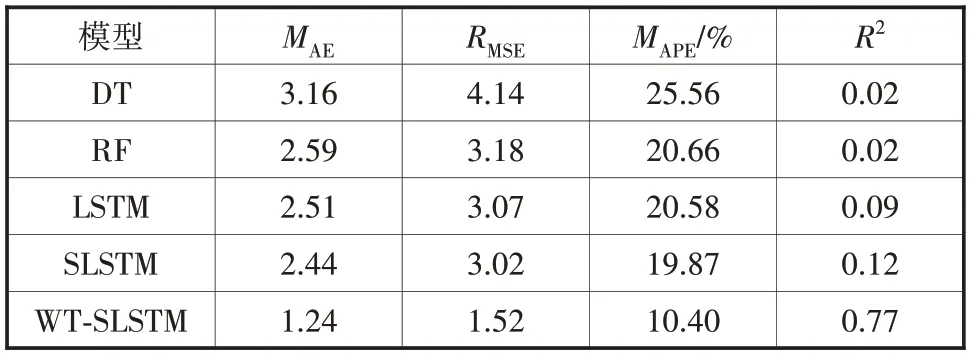
表1 预测性能评价表
为了进一步验证WT-SLSTM 模型的预测性能,绘制实际值和预测值的对比曲线图,如图6所示。DT、RF、LSTM 和SLSTM 模型的预测曲线存在滞后现象和伪峰现象。相比之下,WT-SLSTM 模型修正了这种现象,预测效果更佳。然而,同时也观察到WT-SLSTM 模型的预测峰值低于观测值。随着预测时间的增加,模型逐渐难以预测出与观测值高度一致的值,这可能是由于出租车扎堆现象较为少见所致。一方面,为了准确预测,模型需要大量的观测数据;另一方面,出租车扎堆现象并不常见,因此WT-SLSTM 模型难以学习到某些极端峰值,导致低估预测结果。

图6 对比折线图
综上所述,WT-SLSTM 模型的预测效果明显优于其他基准模型,具体表现在预测误差小、与真实值数据匹配度高、拟合程度更好。对于传统的LSTM 模型,SLSTM 模型提取和储存数据的效果更好、预测精度更高。然而SLSTM 模型对时间序列数据的提取能力有限,本文通过加入小波变换来弥补该问题。小波变换可以覆盖整个频域,对时间频率的局部化进行分析,还能通过伸缩平移运算对信号逐步进行多尺度细化。本文利用其高频处时间细分、低频处频率细分的特点,再结合SLSTM 模型,从本质上分析了交通流序列的频率构成,提高了预测精度,获得了较好的预测效果。
3 结语
本文结合小波变换与SLSTM 神经网络模型,对北京市出租车车流量进行预测研究。实证结果显示,与基准模型相比,WT-SLSTM 模型的预测效果明显提升,预测值更加接近真实值。因此,本文提出的WT-SLSTM 神经网络模型在交通流预测方面效果较好,性能更加稳定,可以更好地掌握交通动态,为交通部门制定和实施政策提供参考。
