复杂场景下的改进YOLOv8n安全帽佩戴检测算法
2023-12-06雷源毅朱文球
雷源毅, 朱文球, 廖 欢
(湖南工业大学计算机学院, 湖南 株洲 412007)
0 引言(Introduction)
由于建筑行业施工环境复杂,高空物体坠落的伤害风险高,因此要求工人在施工现场佩戴安全帽,最大限度地降低工人被坠落物体伤害的风险,保护工人的生命安全。目前,用于工地经典的目标检测算法分为两种,即一阶段目标检测算法和两阶段目标检测算法。一阶段目标检测算法包括YOLO系列算法[1]、SSD(单激发多框检测)算法[2]等。两阶段目标检测算法包括R-CNN[3](基于区域的卷积神经网络)、Faster R-CNN[4]、Mask R-CNN等。YOLO系列算法是目前为止发展最快、最好的算法,尤其是2023年发布的最新的YOLOv8算法,达到了目前为止最高的检测准确率。然而,YOLO虽然检测全尺寸的目标效果较好,但是当目标为具有不同尺寸的特殊场景时,其性能不如当前的一些小尺寸目标检测算法。工地安全帽目标的尺寸较小,使得检测器很难准确、全面地提取其特征,并且当前各种算法对小物体的检测准确率普遍较低。
1 相关研究(Related research)
安全帽图像具有目标分布密集、目标尺度变化大及背景复杂等特点,给安全帽佩戴检测带来了很大的难度。孙国栋等[5]通过在Faster R-CNN中添加自注意力机制获取多尺度的全局信息,强化网络对小目标的表达信息,但该方法的检测速度较低。许凯等[6]使用参数量较少的轻量化模型YOLOv3-tiny,采用增加网络层数、添加注意力机制到特征金字塔中的方法,减少噪音等冗余信息对安全帽检测结果的影响,但在密集情况下,出现较多漏检情况。杜晓刚等[7]在YOLOv5的基础上选择性能更好的Swin Transformer作为主干网络,提取更深层次的语义信息,捕获更多的安全帽细节特征,但在颜色相同情况下存在误检问题。赵敏等[8]通过在YOLOv7-tiny的基础上设计参数量更少的tiny-BiFPN结构,作为原模型特征融合模块中的特征金字塔结构,增强模型多尺度特征融合,但在反光情况下漏检较多。上述改进算法的检测精度仍不够准确,背景特征提取也不够丰富,未能很好地解决建筑工地中小目标密集、安全帽和背部同色等场景下的漏检、误检问题。针对这些问题,提出一种改进的RDCA-YOLO方法,该方法能够提高建筑工地复杂场景中小目标的检测精度,对正常尺度目标的检测精度也有较大的提高,实现了工地工人安全帽佩戴的自动化检测。
2 YOLOv8算法(YOLOv8 algorithm)
Ultralytics于2023年发布了YOLOv8算法,与之前的网络相比,YOLOv8在减少网络参数量的同时,提高了检测精度和实时性。针对建筑工地实际场景,选择一个轻量版本的YOLOv8n作为基础网络进行改进。YOLOv8的特点在于融合了许多实时目标检测中优异的技术,仍然采用了YOLOv5中的CSP(跨阶段局部网络)思想、特征融合方法(PAN-FPN)和SPPF模块;其主要改进如下:(1)提供了全新的基准模型,包括分辨率为640×640的P5和分辨率为1 280×1 280的P6目标检测网络。为了满足不同项目的需求,还基于与YOLOv5相似的比例系数设计了不同比例的模型。(2)在保留YOLOv5原有思想的前提下,参考YOLOv7中的ELAN(高效层聚合网络)结构设计了C2f(跨阶段局域网络卷积块)模块。(3)检测头部分也采用了目前流行的方法,将分类头和检测头分开,其他大部分仍然是基于YOLOv5的思想。(4)分类损失使用BCE损失(多标签分类任务的损失函数),回归损失的形式为CIoU损失函数。与以往的YOLO算法相比,YOLOv8具有很强的扩展性。
在YOLOv8n算法的基础上,建立了一个RDCA-YOLO复杂建筑工地情况下的安全帽检测模型。通过改进Backbone主干结构,在网络中嵌入CBAM注意力机制,提出一种Coord-BiFPN结构,增强网络的特征融合能力,设计了一种OD-C2f结构代替head中的C2f组件,提出一种新的FR-DyHead检测头替换原始的Detect结构,其网络结构如图1所示,该方法可以适应建筑工地复杂场景,并获得了更好的安全帽检测精度。

图1 RDCA-YOLO网络结构图Fig.1 Diagram of RDCA-YOLO network structure
3 RDCA-YOLO安全帽检测模型(RDCA-YOLO helmet detection model)
3.1 改进Backbone结构
原始网络中的主干网络较为复杂,提取信息的能力较低,因此模型通过ResNet-18[9]网络改进原有的Backbone结构,该网络由一个卷积层和八个残差块组成,能够大幅度提高模型的特征提取能力,残差块是组成网络的基本结构,输出如公式(1)所示:
y=F(x)+x
(1)
其中:F(·)表示残差函数,x和y分别表示输入和输出。网络由17个卷积层、一个滤波器大小为3×3的最大池化层(max pooling)和一个全连接层组成。传统的ResNet-18模型涉及3 316万个参数,其中ReLU激活函数和批量归一化(Batch Normalization)应用于整个卷积层的后面,ResNet-18结构如表1所示。
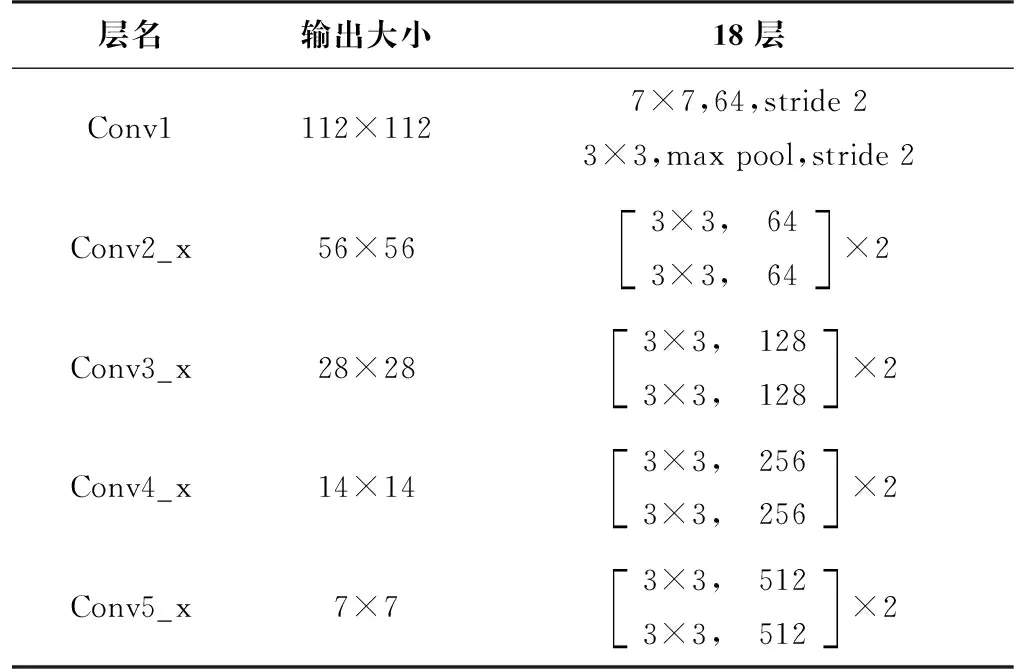
表1 ResNet-18结构表
3.2 注意力机制
通过在网络中Head前嵌入CBAM注意力机制[10],使网络更加关注感兴趣的目标,CBAM原理图如图2所示,其中x表示中间变量。

图2 CBAM原理图Fig.2 Diagram of CBAM principle
通道注意力实现原理:输入H×W×C的特征图,H和W表示输入图像的高和宽,C表示通道数,使用全局平均池化和最大平均池化收集空间信息,然后用两个1×1的卷积(MLP,多层感知机)和Sigmoid激活函数获得每个通道的权重,通道注意力模型结构图如图3所示。
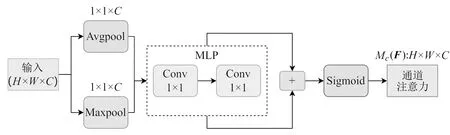
图3 通道注意力模型结构图Fig.3 Diagram of channel attention model structure
空间注意力实现原理:首先对通道信息进行最大池化和平均池化操作,并将结果连接起来,其次由一个7×7的卷积和Sigmoid激活函数得到每个点的坐标权重,设置填充Padding为3,空间注意力模型结构图如图4所示。
注意力模块的计算方法如公式(2)和公式(3)所示,F为输入特征矩阵,Mc(F)和Ms(F′)分别表示通道注意力和空间注意力所获得的权重,⊗表示逐元素相乘,F′表示通道加权结果,F″表示CBAM的最终结果。
F′=F⊗Mc(F)
(2)
F″=F′⊗Ms(F′)
(3)
空间注意力模块和通道注意力模块的具体计算方法如公式(4)和公式(5)所示,fn×n表示一个n×n的卷积。“⊕”表示拼接操作,“+”表示逐元素求和。
(4)
(5)
3.3 Coord-BiFPN结构
模型设计了一个Coord-BiFPN的颈部网络,融合添加了BiFPN[11]和CoordConv[12],增强了网络的特征融合能力和特征映射的鲁棒性。Coord-BiFPN的特点在于高效的双向跨尺度连接和加权特征融合(图5)。首先,从主干网络输入P1、P2、P3三个不同大小的特征图,P1和P3的特征直接融合到输出,这两个阶段中只有一个输出边缘,并且对合并不同的特征信息影响很小。其次,在P2层的输出节点上添加一条额外的边,融合更多特征的同时,也不会增加计算成本。最后,增加P3和P2的输入层与P1的输出层之间的连接,以获得更高级别的特征融合。

图5 Coord-BiFPN结构图Fig.5 Diagram of Coord-BiFPN structure
当融合不同分辨率的特征时,通常的做法是将它们调整到相同的分辨率,然后将它们相加。然而,当输入特征出现变化时,它们的输出特征的权重通常是不同的。向Coord-BiFPN的每个输入添加额外的权重,让网络学习每个输入特征的重要性,利用快速归一化融合调整Coord-BiFPN中的权重,如公式(6)所示:
(6)
其中:wi为可学习的权重,并且通过在每个wi后应用SiLU激活函数保证wi≥0,并且设置ε=0.000 1是为了防止值不稳定,归一化权重的每个值为0~1。Coord-BiFPN的每个模块的输出特征图可以表示如下:
(7)
(8)
(9)
(10)
其中,w1和w2为对应的权重。Coord-BiFPN在同一层的输入和输出特征之间增加了跳跃连接,由于尺度相同,因此增加跳跃连接可以更好地提取和传递特征信息。此外,使用加权特征融合可以融合不同分辨率的输入层,不同分辨率的输入层对应的权重也不同。将改进后的双向特征金字塔网络Coord-BiFPN模块引入特征融合部分,在不增加过多计算量的情况下,能够更好地实现多尺度特征融合。各输入层的权值参数通过网络自动学习,能更好地表示整体特征信息。
3.4 OD-C2f结构
动态卷积[13]基于卷积层的输入确定每个卷积核的权重,并且使用注意力机制对这些卷积核进行加权和求和,以获得适合该输入的动态卷积核,动态卷积输出可以表示如下:
Output(y)=x×(α1W1+α2W2+…+αnWn)
(11)
其中:x和y分别表示输入特征和输出特征变量,αi(i=1,2,…,n)为注意力标量,n为卷积核数量,并且每个卷积核Wi(i=1,2,…,n)具有与标准卷积核相同的大小。
多维动态卷积ODConv利用多维注意力机制和并行策略,学习沿着内核空间的所有四个维度的任何卷积层处卷积内核的互补注意力。四个注意力为卷积核的输入通道数量、卷积核的感受野、卷积核输出通道数以及卷积核数量。这四个注意力相互补充,并且按照位置、通道、滤波器和内核的顺序与卷积内核相乘,显著增强了对上下文信息的捕获,ODConv的输出可以用公式(12)表示:
Output(y)=x×(αw1⊙αf1⊙αc1⊙αs1⊙W1+…+αwn⊙αfn⊙αcn⊙αsn⊙Wn)
(12)
公式(12)中αwi、αfi、αci、αsi(i=1,2,…,n)表示四种注意力,卷积核Wi(i=1,2,…,n)为变量,表示卷积核沿着空间中不同维度进行乘法运算。
RDCA-YOLO安全帽检测模型在ODConv和C2f的基础上提出了一种新的OD-C2f结构,将C2f的Bottleneck的普通卷积优化为ODConv动态卷积,根据不同的输入图像数据自适应调整卷积核,并针对性地提取安全帽的特征,显著增强了模型的特征提取能力,加强了网络的学习能力,提高了模型的识别精度,OD-C2f结构如图6所示。

图6 OD-C2f结构图Fig.6 Diagram of OD-C2f structure
3.5 FR-DyHead检测头
在复杂的工地场景下,工人安全帽佩戴检测面临位置变化、角度切换、尺度变化的挑战。YOLOv8n的检测头不能很好地收集并融合多尺度信息、空间信息和任务信息。研究人员尝试改进已有目标检测器的检测头,以增强模型性能,导致不同的检测头对应不同对象检测器。然而,还没有一种方法可以标准化检测头的结构。
良好的目标检测头应该具有三种能力。一是尺度感知能力。图像中往往存在多个不同尺度的物体,一些物体检测器使用特征金字塔网络增强模型的尺度感知,但并不能提高检测头本身的尺度感知。二是空间感知能力。在不同的视点下,物体会发生变形和旋转,其轮廓和位置也会发生变化。增强空间感知能力可以使检测器具有更强的泛化能力。三是任务感知能力。由于待检测对象可以用不同的形式(锚框、中心点、角点)表示,这使得相应的检测头具有不同的结构和损失函数,增强模型的任务感知能力可以使模型检测不同形式的对象。FR-DyHead通过在每个维度使用三种不同的注意力机制进行统一分别为特征图、空间和通道三种感知,从而使模型能够以更深的尺度关注信息。动态检测头DyHead[14]是一个新颖的动态检测头结构,它使用了多个注意力。本研究在动态头DyHead的基础上设计了FR-DyHead检测头,运用FReLU[15]激活函数替换原有的ReLU激活函数,增强了模型对目标检测任务的适应性,提高了检测的精确度。改进的FR-DyHead结构如图7所示。

图7 FR-DyHead结构图Fig.7 Diagram of FR-DyHead structure
图7中,πL是尺度感知注意力;πS是空间感知注意力;πC是任务感知注意力;offset表示偏移量;(1,0,0,0)为超参数,用于控制激活阈值。
4 实验环境配置及数据准备(Experimental environment setting and data preparation)
4.1 实验环境部署
模型基于PyTorch框架,使用GPU进行训练,实验所使用的GPU为NVIDIA GTX 2070,CUDA版本11.1,PyTorch版本1.7.1,Python版本3.7,CPU为i5-9400F,操作系统为Windows 10家庭中文版。
4.2 数据准备
实验所用安全帽数据集为GDUT-HWD,该数据集共有3 174张图像,实验分别以7∶2∶1的比例将图片划分为训练集、验证集和测试集,共包含18 893个对象,包括建筑工地常见的大部分场景,代表性和广泛性较强。所有对象实例根据安全帽的颜色分为蓝色、白色、黄色、红色和无类别,不同颜色代表不同人员的工作属性,无类别表示个人未戴安全帽,共5个类别。设置实验迭代次数为200次,训练批次为8,学习率为0.01,优化器为SGD,decay(学习率衰减因子)为0.000 5。
4.3 评价指标
评估网络性能的指标主要有准确率(Precision,P),召回率(Recall,R),平均准确率(Average Precision,AP),平均准确率均值(mean Average Precision,mAP),计算方法如公式(13)和公式(14)所示:
(13)
(14)
其中:TP为预测正确的正样本数量,FP为预测错误的正样本数,FN为预测错误的负样本数。模型使用mAP@0.5作为评估模型准确性的指标,表示将IoU(Intersection over Union)阈值取50%时的mAP值,通过平均每个类别的AP计算得到,计算方法如公式(15)和公式(16)所示。

(15)
(16)
5 实验结果与分析(Experimental results and analysis)
5.1 消融实验和对比实验
针对GDUT-HWD数据集设计消融实验,均采用“4.2”小节中的实验参数,本文方法在GDUT-HWD数据集的消融实验结果比较如表2所示。其中:模型2表示改进Backbone结构,模型3表示嵌入CBAM注意力机制,模型4表示设计一种Coord-BiFPN结构,模型5表示在动态卷积的基础上设计了OD-C2f结构,模型6表示提出了一种新的FR-DyHead检测头替换原始的Detect结构。从表2中的数据可以看出,与原YOLOv8n算法相比,本文模型的mAP提高了2.6%。
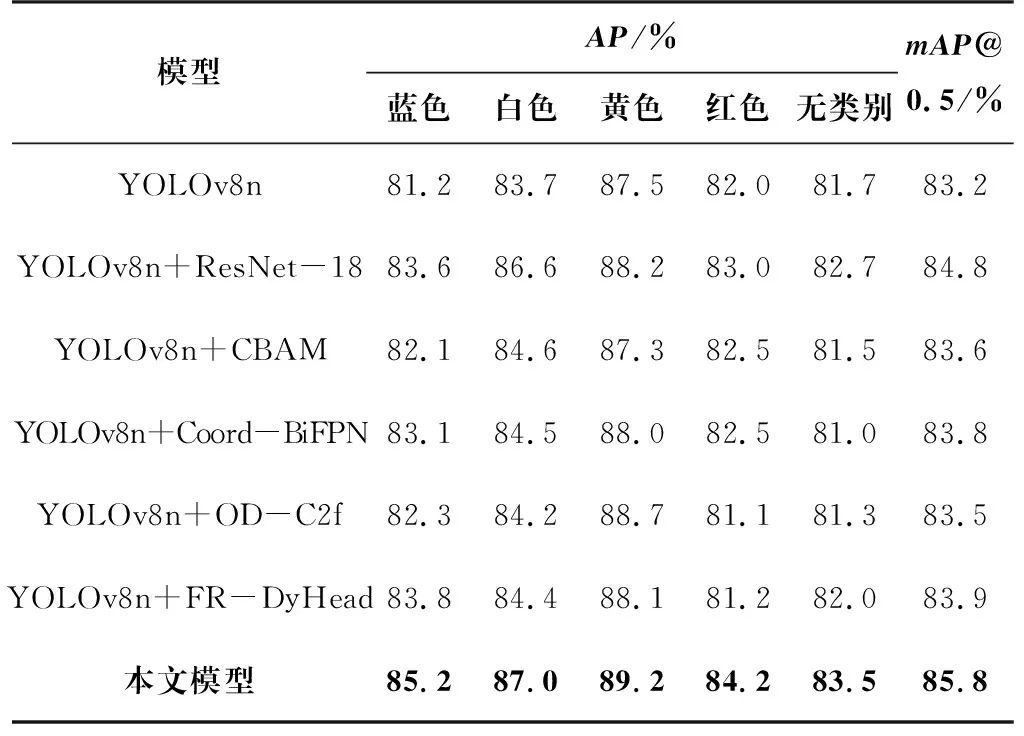
表2 本文方法在GDUT-HWD数据集的消融实验结果比较
为验证改进模型的有效性,采用相同的验证集做了相关对比实验,将其与目前主流的目标检测算法进行对比,不同算法在GDUT-HWD数据集的检测结果比较如表3所示,表明改进后的方法获得了最优的mAP值。

表3 不同算法在GDUT-HWD数据集的检测结果比较
5.2 改进前后检测效果对比
为更加直观地评价改进前后的效果,使用GDUT-HWD数据集中部分图片进行测试。对比图8(a)、图8(b)可以看出,YOLOv8n在密集目标场景下存在1处漏检,没有将图中远处的红色安全帽检测到。对比图8(c)、图8(d)可以看出,YOLOv8n在小目标场景下存在误检,将图中栏杆误检为红色安全帽。对比图8(e)、图8(f)可以看出,YOLOv8n在反光场景下存在漏检,没有将图中的白色安全帽检测到。对比图8(g)、图8(h)可以看出,YOLOv8n在黑暗场景下存在漏检,没有将图中没戴安全帽的人员情况检测到。可以看出,改进后的模型检测准确率更高,检测性能明显提升。

(a)YOLOv8n密集场景下检测结果
6 结论(Conclusion)
针对复杂工地场景下安全帽检测存在的模型识别精度低易出现漏检以及误检等问题。相比于原始的YOLOv8n模型,RDCA-YOLO模型在GDUT-HWD数据集上的mAP提升了2.6%、R提高了2.5%,证明本文所提方法在工人安全帽佩戴检测中有效,与其他目标检测模型相比具有显著优势,实现了工地工人安全帽佩戴的自动化检测。
