基于改进迁移学习的运动想象分类识别算法
2023-12-06杜义浩常超群张延夫曹添福
杜义浩, 常超群, 杜 正, 张延夫, 曹添福, 范 强, 谢 平
(燕山大学 电气工程学院,河北 秦皇岛 066004)
1 引 言
脑机接口(brain-computer interface, BCI)技术通过分析人的运动意图,从而实现对外部设备的直接控制[1,2]。近些年来,脑机接口技术发展迅速,在无人机控制、智能交通、智能家居和医疗康复领域有着广泛应用。其中,运动想象脑机接口技术已尝试运用于因脑卒中或脊髓损伤导致的语言交流和运动障碍患者中[3],如患者语音解码、触觉感知、运动辅助等方面[4]。
运动想象脑机接口应用中最为核心的问题是分类识别准确率,其直接影响因素是分类识别算法性能,而广泛应用的机器学习方法可以分为传统机器学习和迁移学习。传统的机器学习方法有支持向量机(SVM)、BP神经网络等[5],存在要求数据量大、训练时间久、耗费资源高以及分类准确率低等问题,导致运动想象脑机接口实用性较差。
迁移学习是近年来机器学习研究中最为热门的一个分支[6~10],可在训练样本较少情况下,利用已有数据样本快速扩充数据集,提高了分类识别的准确率,显著提升了运动想象脑机接口的实用性。迁移学习方法可以分为4大类:基于样本(instance)的迁移、基于特征(feature)的迁移、基于模型(model)的迁移、基于关系(relation)的迁移,其中样本迁移和特征迁移在运动想象脑机接口中应用较多。基于样本的迁移学习研究方面,如:基于KL散度度量共空间模式(CSP)特征空间之间的相似性,并进行特征数据加权,提高了运动想象分类准确率[11];基于DTW进行源域数据对齐,计算与目标域数据的KL散度,并通过源域数据加权处理,提高了目标域数据的分类识别准确率[12];利用欧式对齐(EA)源域数据,以提升BCI迁移学习效率,相较于黎曼空间对齐(RA)方法速度更快[13]。
上述研究通过在样本维度上进行度量和加权以提高分类识别准确率,更适用于样本数据量较大的情况,但在样本量小的情况下,迁移效果并不理想。基于特征的迁移学习研究方面,如:基于实验前脑电信号低维表征的迁移学习脑电信号解码框架,并用于提取受试者脑电低维特征,提高BCI的预测精度;将最大均值差异距离度量准则应用于运动想象脑电信号处理中,减少源域样本和目标域样本间的分布距离,以提高分类识别准确率[14];利用领域自适应方法(CMMS)捕捉目标样本固有的局部连通性,以减少迁移学习两域之间的分布差异[15]。上述研究通过在特征维度上进行度量以提高分类识别准确率,但忽略了样本本身。若源域数据和目标域数据存在较大的差异,特征迁移可能产生负迁移[16]。综上所述,基于样本的迁移和基于特征的迁移均存在不可避免的缺陷,尤其是样本量较少或源域数据和目标域数据差异较大的情况。因此,研究如何有效提升运动想象脑肌接口中迁移学习分类识别的准确率,避免样本迁移和特征迁移存在问题,是当前和未来运动想象脑机接口研究的核心问题。
本文基于EA和最小化最大均值差异思想改进CMMS方法构建迁移学习模型,将样本迁移和特征迁移的优势有机结合,以进一步提高运动想象脑机接口中迁移学习的分类识别准确率。通过EA减少源域样本和目标域样本的数据分布差异,以及利用最小化最大均值差异思想改进CMMS,并用于筛选源域样本以构建新的源域,进一步缩小源域和目标的分布差异。
2 基于EA和改进CMMS迁移学习的运动想象分类算法模型
本文构建的基于EA和改进CMMS迁移学习的运动想象分类算法模型原理图如图1所示。分别采集受试者的脑电信号(源域数据和目标域数据),经过预处理后进行欧式空间数据对齐处理,利用CSP算法分别提取源域和目标域的特征值,并将特征重映射到新的投影空间中,进一步基于最小化最大均值差异思想筛选源域样本以构建新的源域样本,采用新的源域进行目标样本分类识别。
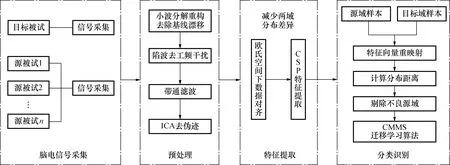
图1 基于EA和改进CMMS迁移学习的运动想象分类识别算法原理图Fig.1 Schematic diagram of the classification and recognition algorithm of motor imagination based on EA and improved CMMS migration learning
3 运动想象脑电信号处理
3.1 脑电信号预处理
由于脑电信号存在非平稳、能量微弱和随机性等特点,需要对脑电信号进行预处理,以提高脑电信号的信噪比[17]。预处理分为:去除基线漂移、去除工频干扰、带通滤波、独立成分分析(ICA)去伪迹,原始脑电信号和预处理后结果如图2和图3所示。如图所示,经预处理后的脑电信号质量显著改善。

图2 原始脑电信号Fig.2 Original EEG
图3 预处理后的脑电信号Fig.3 EEG after preprocessing
3.2 欧式空间数据对齐

(1)
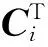
(2)
由式(1)和式(2)可得,n个试次对齐后的均值协方差矩阵为:

(3)
由式(3)可得,经过EA处理后,源域数据和目标域数据实现了对齐和白化,而且每个受试者的均值协方差矩阵等于单位矩阵,使得其数据分布变得更加一致,减少了源域数据和目标域数据的分布差异,进而有利于提高后续迁移学习的分类识别准确率。
4 运动想象脑电信号特征提取
基于EA对齐处理后的源域数据和目标域数据,利用CSP进行特征提取。CSP算法的原理是利用矩阵的对角化,寻找一组最优空间滤波器进行投影,使得二分类信号的方差值差异最大化,从而得到具有较高区分度的特征向量。
假设X、Y分别为二分类运动想象任务下多通道诱发的时空矩阵信号,其维数均为N×M。其中,N代表通道个数,M代表采样点数。CSP算法步骤如下:
1) 计算混合空间协方差矩阵:
X和Y经归一化处理后分别求取其协方差矩阵:
(4)
(5)
式中:XT表示X的转置;trae(XXT)表示求矩阵的迹,即对角线元素之和。
根据式(4)计算X、Y的混合协方差矩阵:
(6)

2) 计算白化特征矩阵
对式(6)进行特征值分解可得:
R=UλUT
(7)
式中:U是特征向量矩阵;λ是特征值矩阵。
由式(7)构建白化矩阵:
(8)
3) 构造空间滤波器
对RX,RY进行如下变换:
SX=PRXPT,SY=PRYPT
(9)
对SX,SY进行成分向量分解可得:
(10)
由式(8)、式(9)可得:
BX=BY=B
(11)
λX+λY=I
(12)
所求空间滤波器为:
W=BTP
(13)
4) 脑电信号特征提取
对X或Y进行空间滤波得到投影矩阵:
Z=W·X
(14)
对Z进行平方运算,得到var(Z2)最后进行对数运算,得到空域特征:
(15)
利用CSP空域特征向量描述运动想象脑电信号的源域数据和目标域数据特征,以用于后续运动想象脑电信号的分类识别。
5 改进CMMS迁移学习方法
CMMS是基于领域自适应的迁移学习方法[19],能够将知识从源域自适应迁移到目标域,并通过目标域局部流形自学习的方式,减少与源域数据的分布差异。CMMS方法步骤如下:
1) 目标数据k-means聚类
由于无监督迁移学习中目标域样本不带标签,CMMS采用经典的k-means算法获得聚类原型[20],并将其视为伪类心,得到目标域样本的分布结构信息。
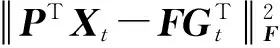
(16)
式中:P代表投影矩阵;F代表目标数据聚类质心;Gt代表目标伪标签矩阵。
2) 目标数据局部流形自学习
由于目标域数据的聚类原型实际上是其对应类质心的近似值,直接影响数据迁移的效果。因此,CMMS中引入局部流形自学习策略,根据目标数据投影低维空间中的局部连通性自适应学习数据的相似度:
(17)
式中:S代表目标邻接矩阵;δ表示超参数。
3) 源域数据类质心计算
基于目标域数据的聚类原型,将领域自适应中的分布差异最小化问题重新表达为类质心匹配问题。而源域数据的类质心可以通过计算同一类样本特征的均值得到。
4) 源域数据判别结构保留
源域数据中同类型样本在投影空间中尽可能接近,不同类样本尽可能远离,且保留源域的判别结构信息:
(18)
5) 两域类质心匹配
CMMS采用最近邻搜索法求解类质心问题,为每个目标域聚类质心寻找最近的源域聚类质心,并使其距离之和最小。两域的类质心匹配表述为:

(19)
式中:ES代表常数矩阵,用于计算源域数据在投影空间中类质心;XS代表源域数据。
最后,通过迭代更新得到目标域伪标签,实现目标域数据的分类。
然而,若迁移学习中源域数据和目标域数据的分布差异较大,则可能会出现负迁移现象。CMMS更多是对目标域数据进行处理,并未对源域数据做筛选,导致可能会出现由于源域和目标域数据差异较大而造成的负迁移。若能够有效剔除源域中不良数据,则可以避免负迁移或迁移效果差的情况。因此,本文基于最小化最大均值差异(maximum mean discrepancy, MMD)思想,通过最小化源域和目标域数据的MMD距离,减小两域之间的分布差异,重新构建新的源域,改进的CMMS方法原理如图4所示。
MMD是一种非参数计算方法,可以度量两个不同域在再生希尔伯特空间中的距离,属于核学习的一种[21]。
脑电信号的源域和目标域数据特征,脑电信号的源域和目标域数据特征,Ds={xs1,xs2,xs3…xsn}、Dt={xt1,xt2,xt3…xtn},最小化两域的输入样本特征,在无限维再生核希尔伯特空间中,有:
(20)
两域之间的MMD距离可表示为:
(21)
式中:Φ(·)是将原数据映射到再生希尔伯特空间的函数;xsi代表源域数据;xtj代表目标域数据;MMD值大小表征源域和目标域数据的分布差异情况。借
助核计算,式(21)改写为:
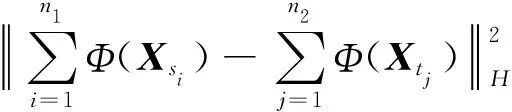
(22)
式中:K代表核矩阵。
(23)
将核矩阵K分解为(KK-1/2)(K-1/2K),并利用转移矩阵A将其降到m维空间。
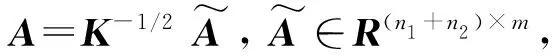
MMD=tr(ATKMKTA)
(24)
目标函数式(20)可以改写成:
(25)
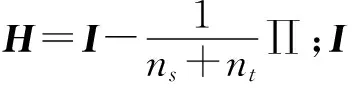
Lg=tr(AT(KMKT+μI)A)+tr((I-ATKHKA)Φ)
(26)
6 实验验证与结果分析
6.1 数据库离线验证
为了验证本文方法的有效性,基于BCI2008竞赛数据集进行离线仿真验证。竞赛数据为BCI-Ⅳ竞赛数据集中的Dataset-1,采样通道为64,采样频率为1 000 Hz,实验任务是左右手运动想象实验,分为7个试次。随机选取其中5名受试者的数据,采样通道为C3、C4,每位受试者样本总量为160,分别作为训练样本集和测试样本集,数据集信息如表1所示。

表1 数据集信息Tab.1 Datast properties
首先进行原始脑电数据预处理,利用EA进行源域和目标域数据对齐,运用CSP算法提取其空域特征,基于最小化最大均值差异进行源域数据筛选,进一步利用改进的CMMS方法得到目标域数据的分类识别结果,并与SVM、JDA、BDA、GFK、EasyTL、CMMS等6种算法进行对比,以验证本文方法的有效性,分类识别结果如表2所示。

表2 5名受试者数据测试结果对比Tab.2 comparison of 5 subjects
其中,tac表示本文方法的识别准确率,oac表示其它方法的识别准确率,(tac-oac )提升均值表示本文方法相对于其它方法提高的识别准确率。
由表2可见,源域和目标域来自同一个样本时(同一受试者的数据,以S1为例),SVM的分类准确率达到80%,但是当源域数据和目标域数据为不同的受试者时(S1做为源域数据,S2、S3、S4、S5为目标域数据),则SVM的分类识别准确率明显下降,最高为72.5%,最低为55.3%;经过EA数据对齐和MMD筛选源域数据之后,本文方法分类识别准确率最高为78.7%,最低也达到了72.8%。从平均分类识别准确率角度来看,SVM、JDA、BDA、EasyTL、GFK、CMMS分别为66.29%、71.34%、73.35%、68.01%、67.01%、72.67%,而本文方法为78.24%,识别准确率提升均值超过其它方法4.71%~11.95%,验证了本文方法的有效性。
6.2 在线实验验证
为了进一步验证本文方法的有效性和实用性,选取15名受试者(10名男性,5名女性,年龄平均为25岁)进行在线运动想象实验,所有受试者身体均健康,无神经性疾病,并签订了知情同意书以及通过了燕山大学伦理委员会的审查。要求受试者实验前24 h内未饮用任何含有酒精或者咖啡因的饮品,休息时间充足且精力充沛。实验选用64通道脑电帽(电极分布符合国际联合会10-20电极分布标准,阻抗小于5 kΩ)和Neuroscan系统采集C3、C4、Cz三个通道的脑电信号,采样频率为1 000 Hz。
每位受试者进行4组运动想象实验,每组实验后休息1 min,以避免受试者连续实验出现疲劳,每组实验分为20个试次,每个试次的时长为15 s(5 s准备时间和7 s运动想象)。实验环境要求安静、无干扰,实验过程中受试者身体姿势保持静止不动,尽量做到不眨眼,具体实验范式如图5所示。
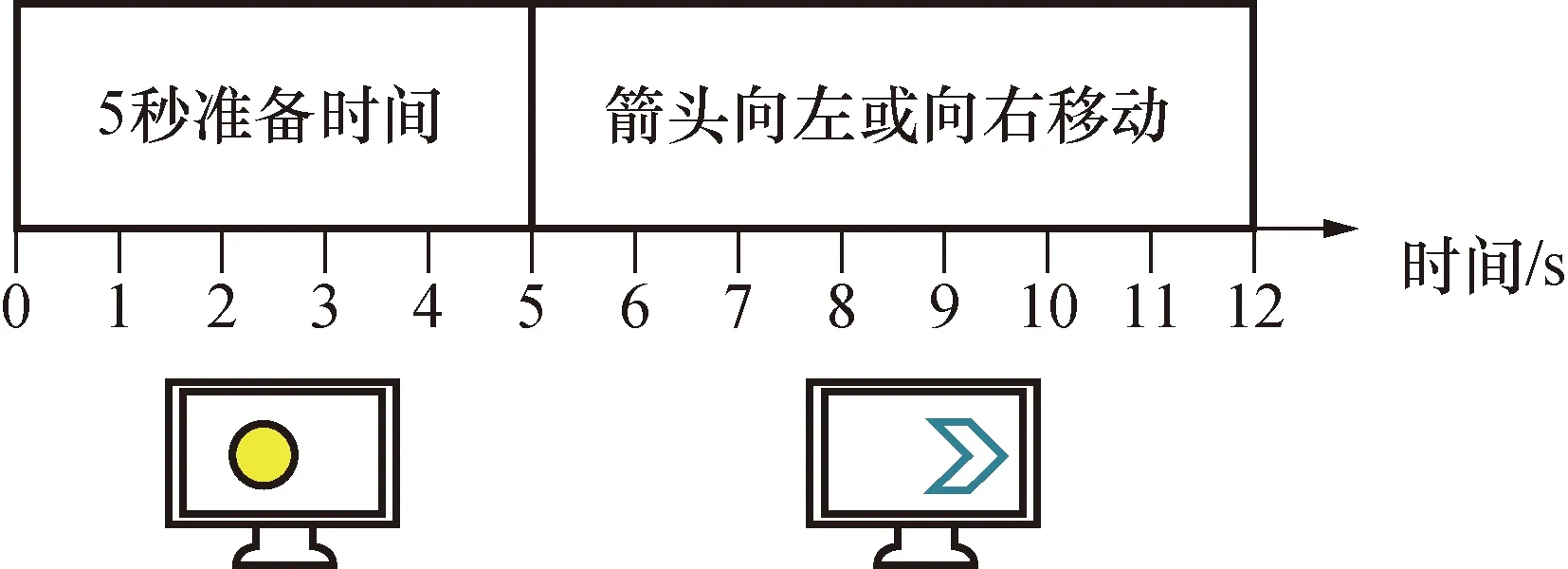
图5 单次运动想象实验范式Fig.5 Single motion imagination experiment paradigm
实验开始时,屏幕正中间出现黄色实心圆并不断闪烁,提示受试者集中精神即将开始实验,持续5 s;第5 s后实心圆消失,随机出现向右或向左移动的蓝色实心箭头,受试者需要根据箭头的移动方向进行右手或左手抓握运动想象;第12 s蓝色实心箭头消失,运动想象过程结束,之后被试者休息5 s,开始下一次运动想象过程。随机选取5名受试者(S6-S10),利用本文方法进行运动想象在线分类识别,结果如表3所示。
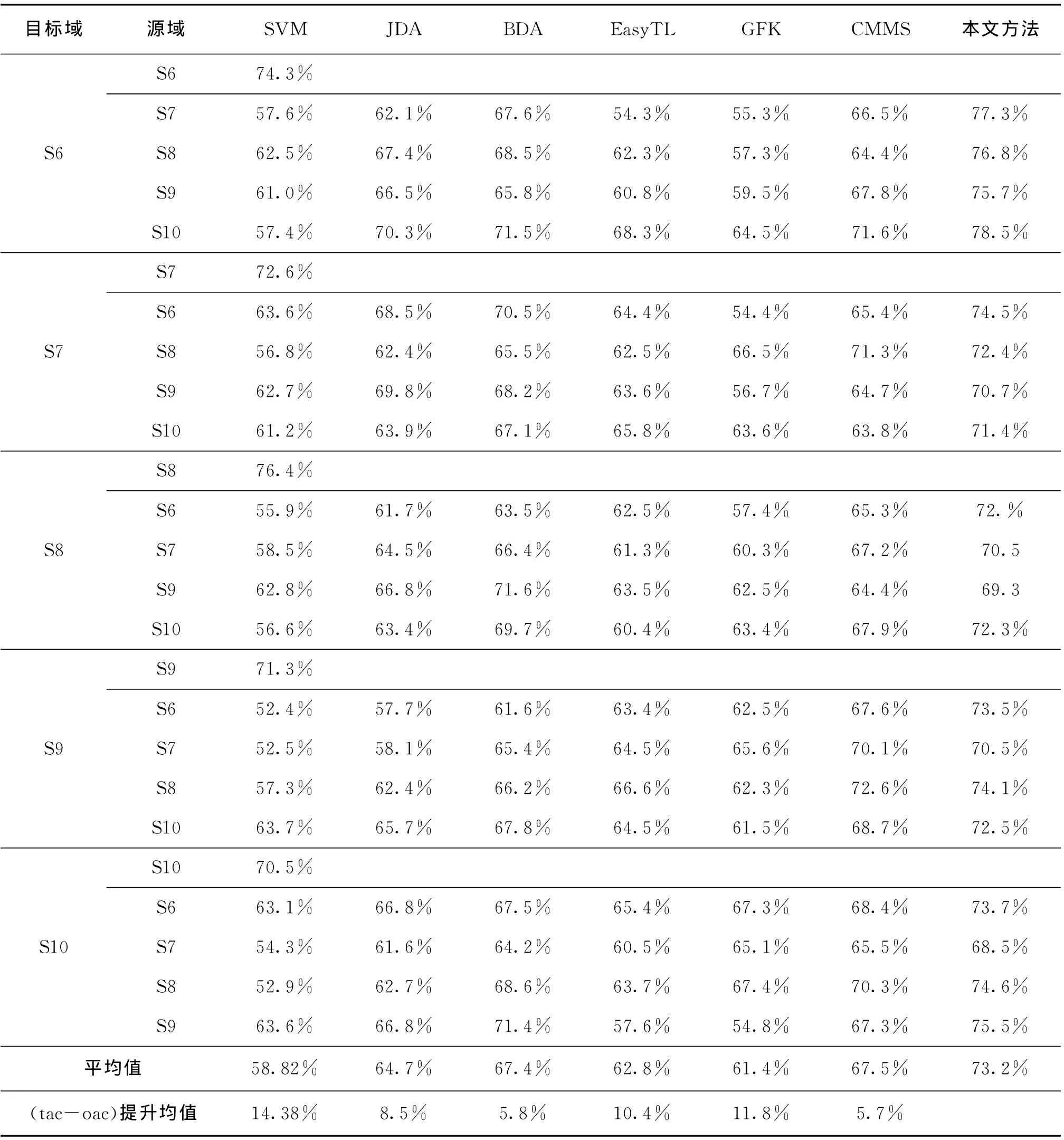
表3 5名受试者数据测试结果对比Tab.3 comparison of 5 subjects
由表3可见,5名受试者在线实验测试结果与BCI数据集离线实验测试结果表现相似。
源域和目标域来自同一受试者时,SVM的分类识别准确率最高达到76.43%,最低为70.5%;而源域和目标域来自不同的受试者时,SVM的分类识别准确率最高仅为63.7%,最低为52.4%;迁移学习方法JDA、BDA、EasyTL、GFK、CMMS的分类识别准曲率均有所提升,但效果不明显,其平均分类识别准确率分别为64.7%、67.4%、62.8%、61.4%、67.5%,而SVM仅为58.82%;本文方法平均分类识别准确达到了73.2%,相较于其它方法分类识别准确率提升均值5.7%~14.38%,充分验证了本文方法的有效性和运动想象脑机接口应用中的实用性。
7 结 论
本文提出了基于EA和改进CMMS迁移学习的运动想象分类识别方法,通过将预处理后的脑电信号进行欧式空间下的数据对齐,减少源域和目标域的数据分布差异,并基于最小化最大均值差异思想构建新的源域,以进一步减少两域数据的分布差异。分别利用BCI竞赛Dataset数据集离线测试和在线实验测试进行验证,并与SVM、JDA、BDA、EasyTL、GFK、CMMS等方法进行对比分析,结果充分说明了本文方法的有效性和运动想象脑机接口应用中的实用性。
