大数据驱动下的数据全生命周期安全监测方法
2023-12-05戴荣峰陶晓英徐文涛
戴荣峰 陶晓英 于 萌 郭 丞 徐文涛
(中国联合网络通信有限公司上海市分公司 上海 200082)
在当前社会全面数字化转型的背景下,海量数据正以指数级增长,但在发展的同时,信息安全事件频发,数据安全问题愈加突出[1],数据隐私安全也受到严重的威胁.根据IDC发布的“Data Age 2025”,全球数据总和在持续增长,2025年全球数据量综合将达到175ZB.另一方面,全球信息安全威胁在持续增加,例如2018年的WannaCry勒索病毒严重破坏了全球数据安全态势,影响了150个国家的20万台计算机,总损失超过数十亿美元.随着5G的普及、物联网的发展以及移动办公的兴起,企业内部的数据也在持续增长,数据资产的安全已经与企业安全深度融合,因此如何保护数据资产的安全成为亟待解决的问题.
由于大部分数据来源于独立的数据源,导致个别数据针对性的处理较为繁琐[2],传统的敏感数据识别方法只在数据的存储、加工环节进行敏感数据识别的操作,对于数据的采集、传输、交换[3-5]等步骤缺少覆盖性.当前采集敏感数据是通过正则表达式将目标数据转换为字符串,再实现敏感数据的提取、处理以及匹配验证.但是该方法只能处理结构化数据[6],无法处理半结构化的日志文件以及非结构化的PPT、图片、视频等数据.其次,在应用系统共享展现敏感数据时,通过模糊信息特征匹配并进行网络敏感数据动态抓取时[7],无法建立敏感数据与相对应的页面映射关系,缺少结构化识别应用系统中的敏感数据.在数据实时传输时,目前通常使用MapReduce[8]进行实时处理,但是需要从物理存储分布式文件系统(hadoop distributed file systems, HDFS)中加载数据,处理后再返回给物理存储,导致实时流数据的处理能力被降低.
综上,本文针对敏感数据采集识别、实时传输、数据共享、数据处理等方面,通过集成非结构化识别、自动化嗅探技术、自然语言处理、无监督训练等数据安全技术,提出了基于敏感数据特征解析识别、系统敏感内容分割、实时流敏感数据监测、文件敏感解析以及用户异常行为预测,从而提升了监测覆盖范围、提高了监测准确率和效率,保障了敏感数据的安全流转.
1 数据全生命周期的安全监测方法
1.1 数据全生命周期的风险分析
在数据的采集、存储、传输等生命周期环节中,通过数据嗅探、分析、关联,发现敏感数据的安全风险如下:在不同类型数据采集后,若未按敏感数据分类分级存储,会存在极大泄露风险;在数据传输环节,当源数据通过介质传输时,未脱敏的高风险数据会给业务系统带来潜在风险;在数据共享环节,当源数据通过应用系统前端页面展示时,会存在未处理的敏感数据暴露风险;在数据处理环节,当用户处理敏感数据时,存在违规恶意使用风险.
1.2 监测方法模型介绍
1.2.1 数据采集环节安全监测——基于特征解析的识别模型
在数据采集环节,针对网间流转的敏感数据无法自动发现、自动监测敏感数据访问情况等问题,面向数字资产内部所有类型的数据,基于敏感数据特征解析识别源数据.该模型实现流程主要包括抽取数据源、导入数据样例、聚类分析样例、自然语言处理、匹配敏感词库、自动识别敏感数据等步骤.
数据源的选取基于特定数字资产范围内使用的工具以及协议,如FTP协议、MySQL、CSV文件、PDF文件[9]等产生的数据.通过将数据源中提取出的元数据以及抽样数据导入聚类引擎,经过聚类分析[10]和自然语言处理[11],解析图片、视频等元数据的特征,最终提取出敏感词库.随后比对敏感词库中特殊字段和关键词库,筛选身份证号、手机号、银行卡号等数据,实现敏感数据自动识别.
基于特征解析的识别模型如算法1所示.首先遍历所有源数据的数据维度,抽取数据源为元数据M,将元数据进行聚类分析fk(M)和自然语言处理fNLP(M),将结果加入结果集Set中;之后遍历Set,在敏感关键词N中比对是否存在于结果集Set内,若存在,则加入敏感数据库x(t)中,最后输出x(t).
算法1.基于特征解析的识别模型.
输入:源数据S;数据维度D;敏感关键词N;
输出:敏感数据库x(t).
① fori=1 toDdo
②f(S(i))={S(i),S(i+1),…,S(D)};
/*提取数据源S(i)*/
③M=f(S(i));/*提取元数据M*/
④Set=fk(M);
/*聚类分析元数据输入词库集*/
⑤ addfNLP(M) toSet;
/*自然语言处理输入词库集*/
⑥ end for
⑦ forj=1 tolen(Set) do
⑧ fork=1 tolen(N) do
⑨ ifSet(j) matchN(j)
⑩ addSet(j) tox(t);
1.2.2 数据共享环节安全监测——内容分割模型
在数据共享环节,当应用系统上线后,一些尚未脱敏的数据有可能发布到公共网络空间,此时数据会被各方调取、使用或存储到本地,存在共享管理不明确、数据超范围共享、扩大数据暴露面等安全风险和隐患.因此,针对应用系统中尚未脱敏的页面,使用内容分割模型捕获其中的敏感数据.
敏感内容分割流程如图1所示.内容分割模型使用页面爬虫技术,爬取数据资产内部所有的应用系统页面,对获取的页面进行自动化区域分割,并识别各个区域的内容,实现敏感数据的智能解析.

图1 敏感内容分割流程
1.2.3 数据传输环节安全监测——实时数据监测模型
在数据传输环节,数据在互联网上进行文件传输、电子邮件商务往来存在许多未知风险,特别是涉及重要机密的文件传输.为了确保数据在公网上传输的安全,防止有用或私有化信息在网络上被拦截和窃取,需要对数据增加保护措施,因此针对内部网络实时穿梭的数据流资产,通过使用Spark和Flink实时流组件,高速监测实时数据流.
实时数据监测流程如图2所示,其通过从Kafka实时流、HDFS日志以及API网关中获取数据,API网关包括json接口、XML接口、HTTP函数、RESTful接口[12]以及HTML接口等.在获取数据后,使用行为画像模型、异常模型以及机器学习方法对数据进行实时分析处理.处理后的数据需要分发到各单元进行策略评估,最后发送告警报文.
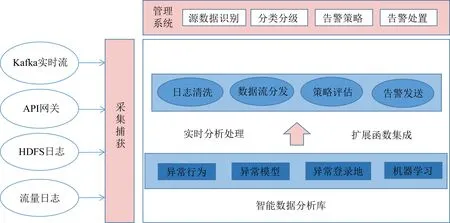
图2 实时数据监测流程
1.2.4 数据存储环节安全监测——文件解析检索模型
随着业务数据量的增加,数据存储在数据库或FTP服务器上有泄露风险,此时需要对数据进行分区存储管控,如图3所示,首先从源端,如API接口、数据库以及文件传输接口等获取数据,在数据的采集阶段完成敏感数据识别;其次,当数据中台进行数据归集清洗加工后,在数据下发数据租户和服务平台时对数据库表以及文件进行敏感识别;然后当数据进入数据租户和服务平台后,在数据交换使用时进行敏感数据识别;最后,在数据销毁时同样进行敏感数据识别.
在上述环节中,通过数据监测节点监控数据租户以及数据服务平台调用的日志流量,并在FTP服务器中部署文件监测引擎,对输入接口以及输出接口进行监控,实现存储环节敏感数据安全监测.
1.2.5 数据处理环节安全监测——用户异常行为预测模型
在数据处理环节,用户系统身份权限有可能被攻击者窃取,并在系统内部造成诸如数据泄露、设备宕机、远程控制等的安全威胁[13].因此,通过分析用户的行为模式[14],阻止用户窃权访问并对安全风险及时处置.
首先,采集多种数据源,如主机日志、数据库日志以及堡垒机日志,分析用户的行为日志,跟踪用户行为;其次,进行数据清洗、数据归类等数据预处理,将预处理后的数据传入密度聚类算法中进行聚类,并建立个体、群体以及场景行为基线,持续评估基线风险;然后,将基线数据输入神经网络中进行测试,进行异常行为打分,对用户、群体以及场景行为预测,及时发现潜在的安全威胁事件;最后,将高分基线行为发送到安全响应小组进行处置,人工动态干预用户潜在异常行为.
2 实验测试
2.1 测试环境
实验测试基于大数据驱动下的数据全生命周期安全监测方法搭建安全监测平台,所需的配置如下:CPU Intel i9-12900,内存64GB,硬盘8TB,操作系统Linux/2.6.32,数据库ElasticSearch/6.2.4.
2.2 测试流程
2.2.1 安全监测平台测试
首先将攻击主机、被攻击主机以及安全监测平台测试机放入同一网络域内,测试机用来测试误报率、漏报率等参数.在全双工的条件下,攻击主机从被攻击主机中以一定速率获取敏感数据.被攻击主机分别以64B,128B,512B,1518B大小的TCP,UDP和模拟真实的网络数据流量作为背景流量数据包,以满负荷背景流量的25%,50%,75%,99%作为背景流量强度,向攻击主机发送敏感数据.测试结果统计方法如式(1)所示,统计监测TCP,UDP的误报率和漏报率,其中N为全量数据包,P为UDP总流量包.
(1)
2.2.2 模型算法测试
首先将服务器和安全监测平台客户端放入同一网络域内,并部署特征解析识别算法、内容分割模型、实时数据监测算法以及文件解析检索算法.服务端使用不同的协议以及文件流向客户端发送数据,其中:敏感页面选取50个;每种数据源选取1000条高敏感数据项,包含管理员密码以及数据库截图等结构化和非结构化数据;选取1000条中敏感数据,包含身份证照片、手机号等敏感信息;选取1000条低敏感数据,包含姓名、IP地址等信息;1000条非敏感数据,向客户端端口发送.测试结果统计方法如式(2)所示:
(2)
其中TP敏感数据为不同协议文件监测的敏感数据,FP非敏感数据为全量样本下非敏感数据.
2.2.3 用户异常行为预测模型测试
首先,在安全监测平台部署用户异常行为预测模型,并录入1789名用户的20万条日志,其中213名为异常用户,1576名用户为正常用户.日志的类型包括上传文件、执行远程系统命令、发送邮件、登录系统等.日志数据包含日志产生时间、操作类型、源/目标IP、数据报文信息、链路层信息以及用户档案.其次,将所有数据导入MySQL数据库中.最后,用户异常行为预测模型对数据库中的文件进行训练.测试结果统计方法如式(3)所示:
accuracy=
(3)
TP真正、TN真异、FP假正、FN假异分别为真正常用户、真异常用户、假正常用户、假异常用户.
2.3 测试结果分析
2.3.1 安全监测平台测试结果
测试结果如表1所示.实验结果表明,本文方法平台可以监测TCP以及UDP这2种传输层协议报文.其中:本文方法在各背景流量和数据包下监测误报率为0;在背景流量超过75%时,本文方法的UDP报文误报率低于4.5%.

表1 安全监测平台测试结果
2.3.2 模型算法测试结果
如表2所示,基于本文方法的算法模型面对敏感页面内容、不同协议和文件流时,测试结果如下:对于50个包含敏感内容的页面实现全部解析;对于FTP协议数据源的4个安全等级,本文方法的识别准确率分别为95.6%,97.4%,96.8%,99.2%;对于MySQL数据源的识别准确率分别为96.1%,98.0%,95.2%,98.9%;对于Oracle数据源的识别准确率分别为97.1%,96.4%,91.6%,97.1%;对于CSV文件数据源的识别准确率分别为96.0%,95.3%,92.7%,99.0%;对于Kafka数据源的识别准确率分别为95.5%,94.6%,95.7%,97.6%;对于PDF文件的识别准确率分别为95.3%,94.9%,95.8%,96.6%;对于Hadoop数据的识别准确率分别为94.3%,94.7%,98.1%,95.6%;对于Restful API的识别准确率分别为95.3%,94.9%,98.4%,97.2%.

表2 本文方法测试结果
综上,特征解析识别算法、内容分割模型、实时数据监测算法以及文件解析检索算法总体准确率均高于92%,从而保障了敏感数据在各协议和文件流中的流转识别.
2.3.3 用户异常行为预测模型测试结果
通过预测模型检测出210名异常用户,其中真异常用户205名、假异常用户5名、检测准确率为93.2%、误报率2%;检测出1579名正常用户,其中真正常用户1571名、假正常用户8名、检测准确率为99.5%、误报率为0.5%,从而有效捕获了用户访问敏感数据的异常行为.
3 结 语
本文提出了一种基于数据全生命周期的数据安全监测方法,通过使用敏感数据特征解析、敏感内容分割、实时流敏感数据监测、文件敏感解析以及用户异常行为预测,提取分析敏感数据在各环节内的流转情况.该方法有效解决了监测覆盖范围小、精度低、自动化程度低等问题,有效保障数据资产的安全.实验结果表明,该方法的算法模型总体准确率高于92%且综合误报率低于2%,有效提高了对敏感数据的监测效率.
